参考B站up主【架构分析】嵌入式祼机事件驱动框架
感谢大佬分享
-
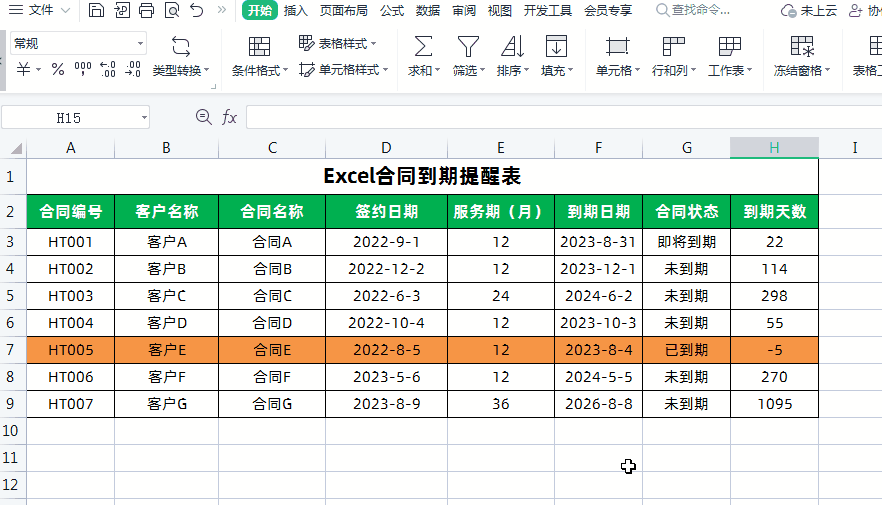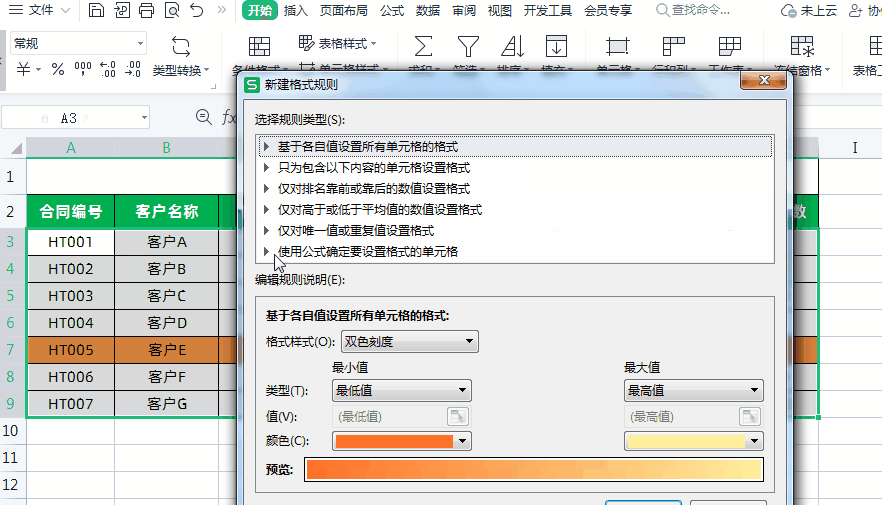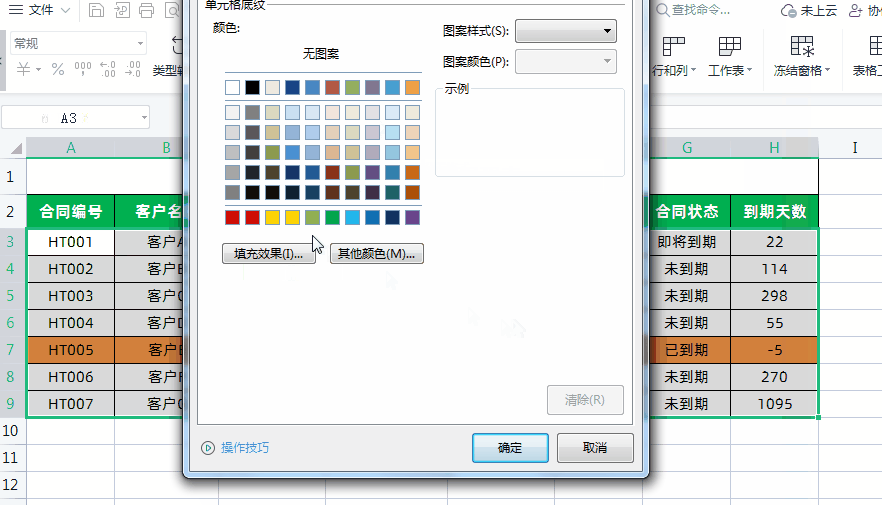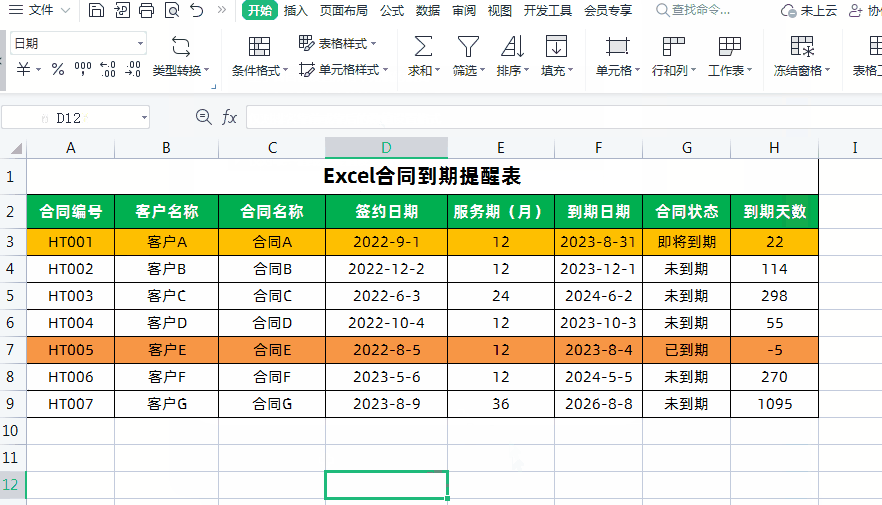
任务ID : TASK_XXX
TASK_XXX 在系统中每个任务的ID是唯一的,范围是 0 to 0xFFFE,0xFFFF保留为SYS_TSK_INIT。
同时任务ID的大小也充当任务调度的优先级,ID越大,优先级越高,越排在任务链表的最前面 -
事件ID :EVE_XXX
EVE_XXX和任务绑定,对于一个任务来说,一个任务的事件集有16位,最高位1<<15 保留为系统消息事件SYS_EVE_MSG,剩下的1<<0 到 1<<14由用户定义
对于不同的任务,EVE_XXX可以相同,但是对于某一个任务,EVE_XXX应是唯一的 -
消息事件ID : EVE_MSG_XXX
EVE_MSG_XXX被消息的bdy所携带,当将消息发送给任务时,会触发任务的系统消息事件SYS_EVE_MSG,然后在任务的事件处理函数handler中,取出消息事件EVE_MSG_XXX和数据data,根据EVE_MSG_XXX做不同的处理。
EVE_MSG_XXX与EVE_XXX是不同的,EVE_MSG_XXX是消息事件中的消息所携带的事件,EVE_XXX是某个任务事件集中的某个事件。
EVE_MSG_XXX的范围是 0 到 0xFFFF,尽可能使用不同的EVE_MSG_XXX
![![[Pasted image 20250123183033.png]]](https://i-blog.csdnimg.cn/direct/276fe6425bd6470ab95444fd07cbb5a6.png)
(注:此架构图来自B站up主的视频【架构分析】嵌入式祼机事件驱动框架)
创建任务,初始化(包括硬件方面,软件逻辑方面等)
也可以在初始化中创建软件定时器,软件定时器超时后会把对应任务的事件置位,即触发事件。
系统调度后在osal_system_start中会循环检查有没有触发事件的任务,有则通过task_handler处理
消息通过osal_send_msg发送消息到消息队列,因为消息其实是和任务task_id绑定起来的,消息发送到消息队列后会把对应的任务中的 SYS_MSG_EVE置位,即触发消息事件。然后在task_handler中通过osal_recv_msg读取 消息,把消息提取出来,然后释放消息内存
也可以直接通过调用osal_task_seteve触发指定任务的事件
核心就是任务task,应用层中 通过 task_id和event_id实现事件驱动的调度
中断中如何往OSAL中去集成
- 通过直接触发相应的事件osal_task_seteve
- 通过消息队列
如果数据比较少,可以直接通过消息队列发送。
或者使用数据缓冲层,在任务处理task_handler中取数据
在app.h中声明所有的任务id,事件id,以及处理接口ops
调度函数
osal_system_start
在主程序中调用osal_system_start
- 寻找触发事件的任务
- 执行任务事件处理函数
- 将执行完的事件在事件集中剔除掉
通过osal_task_active获取有效任务,即有事件触发的任务,将其事件集提取出来赋值给events变量。
将task_active->events给清理掉,最开始是一个多线程的考虑,在逻辑轮询中
调用任务的事件处理函数task_active->ops->handler,这个函数由用户提供,参数是任务id和事件集,在此函数中需要剔除掉对应的事件,然后将剔除事件 过后 的事件集 返回,然后将返回值 或上任务的事件集
![![[Pasted image 20250125200955.png]]](https://i-blog.csdnimg.cn/direct/7bbc529ea1df45cb94419232d050efe2.png)
(注:此架构图来自B站up主的视频【架构分析】嵌入式祼机事件驱动框架)
/********************************************************************* * @fn osal_system_start * * @brief * * This function is the main loop function of the task system. It * will look through all task events and call the task_event_processor() * function for the task with the event. If there are no events (for * all tasks), this function puts the processor into Sleep. * This Function doesn't return. * * @param void * * @return none *//*可以考虑不加临界区,直接用原子操作,减少开销*/
void osal_system_start(void)
{ event_asb_t events,ret_events; osal_task_t *task_active; while(1) { task_active = osal_task_active(); if ( task_active != NULL ) { OSAL_ENTER_CRITICAL(); events = task_active->events; task_active->events = SYS_EVE_NONE; OSAL_EXIT_CRITICAL(); if(events != SYS_EVE_NONE) { if(task_active->ops->handler != NULL) { ret_events = task_active->ops->handler(task_active->task_id,events); OSAL_ENTER_CRITICAL(); task_active->events |= ret_events; OSAL_EXIT_CRITICAL(); } } } }
}
osal.h
#ifndef OSAL_H
#define OSAL_H //#include "heap.h"
#include "stm32h7xx_hal.h" #define OSAL_ERROR 0
#define OSAL_SUCCESS 1
#define INVALID_TASK 2
#define INVALID_MSG_POINTER 3
#define INVALID_EVENT_ID 4
#define INVALID_TIMER 5 //芯片硬件字长
typedef unsigned int halDataAlign_t; // Unsigned numbers
typedef unsigned char osal_bool_t;
typedef unsigned char osal_byte_t;
typedef unsigned char osal_uint8_t;
typedef unsigned short osal_uint16_t;
typedef unsigned int osal_uint32_t; // Signed numbers
typedef signed char osal_int8_t;
typedef signed short osal_int16_t;
typedef signed int osal_int32_t; #define osal_container_of(ptr, type, member) ((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member))) /**进入临界区和退出临界区**/
//#define CLI() __set_PRIMASK(1) // Disable Interrupts
//#define SEI() __set_PRIMASK(0) // Enable Interrupts
#define CLI() __disable_irq() // Disable Interrupts
#define SEI() __enable_irq() // Enable Interrupts #define OSAL_ENABLE_INTERRUPTS() SEI() // Enable Interrupts
#define OSAL_DISABLE_INTERRUPTS() CLI() // Disable Interrupts
#define OSAL_ENTER_CRITICAL() CLI()
#define OSAL_EXIT_CRITICAL() SEI() /**内存管理**/
//#define osal_mem_alloc pvHeapMalloc
//#define osal_mem_free vHeapFree #define osal_delay(ms) HAL_Delay(ms) osal_uint8_t osal_init_system(void);
void osal_system_start(void); int osal_strlen( char *pString );
void *osal_memcpy( void *dst, const void *src, unsigned int len );
void *osal_revmemcpy( void *dst, const void *src, unsigned int len );
void *osal_memdup( const void *src, unsigned int len );
osal_uint8_t osal_memcmp( const void *src1, const void *src2, unsigned int len );
void *osal_memset( void *dest, osal_uint8_t value, int len ); #endif
osal.c
/********************************************************************* * @fn osal_init_system * * @brief * * This function initializes the "task" system by creating the * tasks defined in the task table (OSAL_Tasks.h). * * @param void * * @return ZSUCCESS */osal_uint8_t osal_init_system( void )
{ // Initialize the Memory Allocation System
#if OSALMEM_METRICS osal_mem_init();
#endif return ( OSAL_SUCCESS );
} /********************************************************************* * @fn osal_system_start * * @brief * * This function is the main loop function of the task system. It * will look through all task events and call the task_event_processor() * function for the task with the event. If there are no events (for * all tasks), this function puts the processor into Sleep. * This Function doesn't return. * * @param void * * @return none *//*可以考虑不加临界区,直接用原子操作,减少开销*/
void osal_system_start(void)
{ event_asb_t events,ret_events; osal_task_t *task_active; while(1) { task_active = osal_task_active(); if ( task_active != NULL ) { OSAL_ENTER_CRITICAL(); events = task_active->events; task_active->events = SYS_EVE_NONE; OSAL_EXIT_CRITICAL(); if(events != SYS_EVE_NONE) { if(task_active->ops->handler != NULL) { ret_events = task_active->ops->handler(task_active->task_id,events); OSAL_ENTER_CRITICAL(); task_active->events |= ret_events; OSAL_EXIT_CRITICAL(); } } } }
}












![【PyTorch][chapter 29][李宏毅深度学习]Fine-tuning LLM](https://i-blog.csdnimg.cn/direct/e165375e18e641bd9a394d2cdf40fed0.png)




