序言
心若有阳光,你便会看见这个世界有那么多美好值得期待和向往。
决定开一个算法专栏,希望能帮助大家很好的了解算法。主要深入解析每个算法,从概念到示例。
我们一起努力,成为更好的自己!
今天第3讲,讲一下排序算法的选择排序(Selection Sort)
1 基础介绍
查找算法是很常见的一类问题,主要是将一组数据按照某种规则进行排序。
以下是一些常见的查找算法及其应用场景:
- 布隆过滤器(Bloom Filter):适用于判断一个元素是否存在于一个大规模的数据集中,时间复杂度为O(1),但有一定的误判率。
- 二分查找(Binary Search):适用于有序数组中查找元素,时间复杂度为O(log n);
- 哈希表查找(Hash Table):适用于快速查找和插入元素,时间复杂度为O(1),但需要额外的存储空间;
- 线性查找(Linear Search):适用于无序数组中查找元素,时间复杂度为O(n);
- 插值查找(Interpolation Search):适用于有序数组中查找元素,时间复杂度为O(log log n),但是对于分布不均匀的数据集效果不佳;
- 斐波那契查找(Fibonacci Search):适用于有序数组中查找元素,时间复杂度为O(log n),但需要额外的存储空间;
- 树表查找(Tree Search):适用于快速查找和插入元素,时间复杂度为O(log n),但需要额外的存储空间;
- B树查找(B-Tree):适用于大规模数据存储和查找,时间复杂度为O(log n),但需要额外的存储空间;
一、布隆过滤器介绍
1.1 原理介绍
布隆过滤器(Bloom Filter)是一种概率型数据结构,用于快速判断一个元素是否可能存在于一个集合中,同时具有高效的插入和查询操作。它的原理基于位数组和哈希函数。
布隆过滤器的核心是一个位数组(bit array)或称为位向量(bit vector),用于表示元素的存在状态。初始时,所有位都被置为0。
布隆过滤器使用一系列不同的哈希函数(hash functions),这些哈希函数将输入的元素映射为位数组中的不同位置。哈希函数的数量和定义根据具体的应用场景而定,通常会选择一些独立的哈希函数。
插入元素时,将元素经过哈希函数的映射,得到一系列位数组中的位置,然后将这些位置的位设置为1,表示对应的元素存在于布隆过滤器中。
查询元素时,将要查询的元素经过哈希函数的映射,得到一系列位数组中的位置,然后检查这些位置的位是否都为1。
如果有任何一个位置的位为0,则可以确定该元素一定不存在于布隆过滤器中;如果所有位置的位都为1,则该元素可能存在于布隆过滤器中,但不是确定存在。
因此,布隆过滤器的查询结果可能会有误判,即将不存在的元素误判为存在,但不会将存在的元素误判为不存在。
优点
由于布隆过滤器使用位数组和哈希函数,具有以下特点:
空间效率高:布隆过滤器只需使用位数组存储元素的存在状态,不需要存储元素本身,因此占用的空间相对较小。
查询效率高:布隆过滤器查询的时间复杂度是常数级别的,与集合中元素的数量无关。
插入效率高:布隆过滤器插入的时间复杂度也是常数级别的。
缺点
然而,布隆过滤器也存在一些缺点:
误判率(False Positive):布隆过滤器的查询结果可能会有误判,将不存在的元素误判为存在。
不支持元素的删除:布隆过滤器的设计目标是快速判断元素的存在性,不支持元素的删除操作。
难以扩展:一旦布隆过滤器被创建,就很难动态地调整其大小。
总的来说,布隆过滤器适用于对查询效率要求较高、可以容忍一定的误判率以及元素不经常变动的场景,如缓存、防止缓存击穿、爬虫的去重等应用。
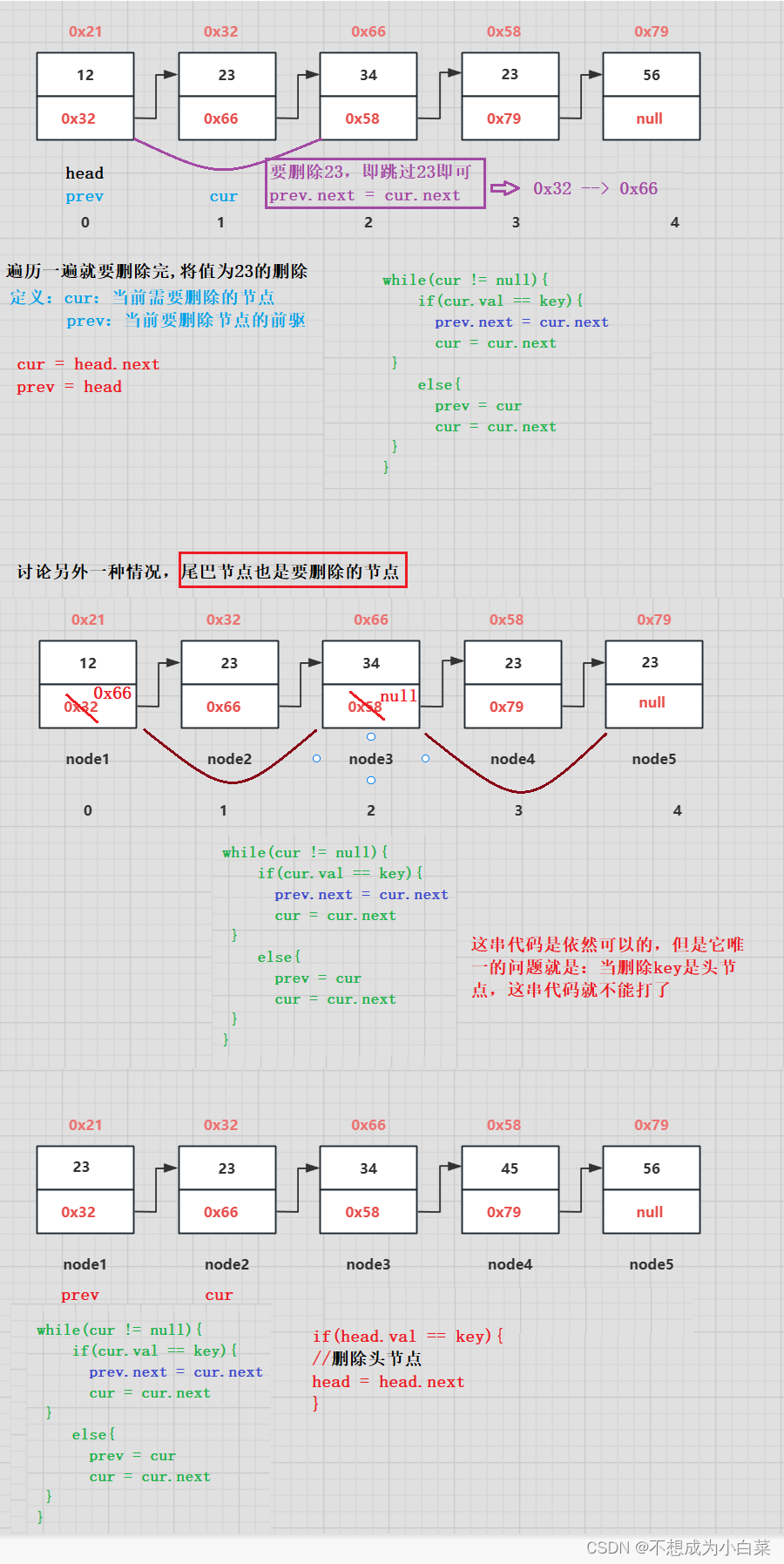
图解原理
以下是一个简单的图解布隆过滤器的示意图:
图表示一个初始状态的布隆过滤器,位数组中的所有位都被初始化为0。

接下来,我们插入一个元素 "apple" 和 "orange",假设我们选择了三个哈希函数,并且得到的哈希值分别为 1、5 和 7。我们将对应的位设置为1,表示这些位置上的元素存在。

现在,我们查询元素 "apple" 和 "banana"。根据哈希函数得到的位位置分别为 1、4 和 7。我们检查这些位置上的位,如果其中有任何一个位为0,则可以确定该元素不存在于布隆过滤器中;如果所有位置上的位都为1,则该元素可能存在于布隆过滤器中。
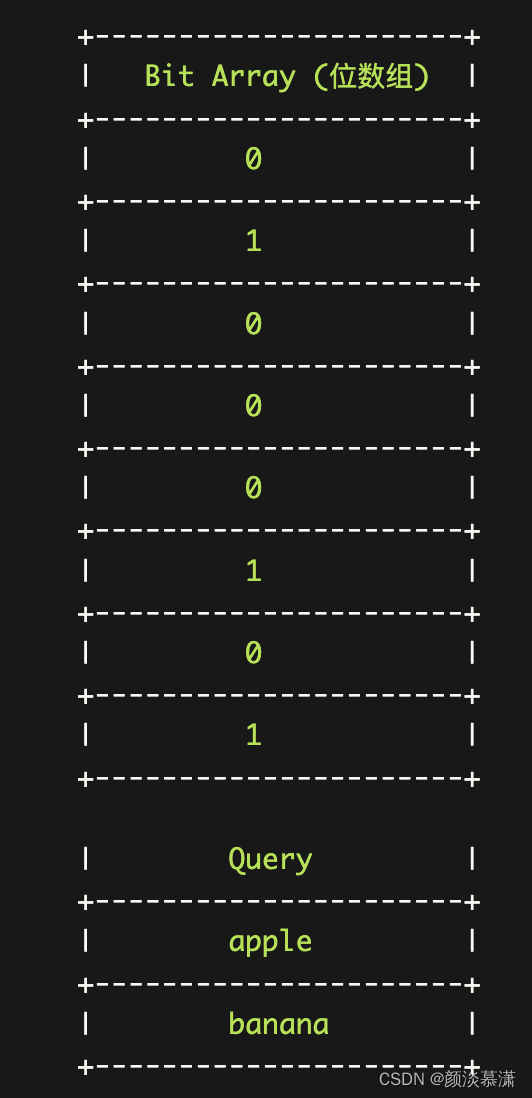
根据图示,我们可以确定 "apple" 可能存在于布隆过滤器中,因为对应的位置上的位都为1。而 "banana" 可能不存在于布隆过滤器中,因为其中一个位置上的位为0。
这就是布隆过滤器的基本原理。
通过使用位数组和哈希函数,布隆过滤器可以快速判断一个元素是否可能存在于一个集合中,具有高效的插入和查询操作。
1.2 复杂度
布隆过滤器的时间和空间复杂度如下:
时间复杂度:
- 插入操作的时间复杂度是O(k),其中k是哈希函数的数量。
- 查询操作的时间复杂度也是O(k)。
空间复杂度:
- 布隆过滤器的空间复杂度主要取决于位数组的大小和哈希函数的数量。通常情况下,位数组的大小取决于预期的元素数量和期望的误判率。位数组的大小会随着元素数量的增加而增加,以及期望的误判率的降低而增加。
1.3使用场景
布隆过滤器适用于以下场景:
数据量大,但内存有限:由于布隆过滤器只需要使用位数组来表示元素存在状态,相对于其他数据结构,它具有较小的内存占用。这使得它在内存有限的情况下能够存储大量的元素。
快速判断元素是否存在:布隆过滤器可以在常数时间内判断一个元素是否可能存在于集合中,无需实际存储元素本身,这使得它具有非常高的查询效率。它可以用于加速对大型数据集或数据库的查询操作。
容忍一定的误判率:布隆过滤器的查询结果可能会有误判,将不存在的元素误判为存在(即假阳性)。因此,它适用于那些可以容忍一定误判率的应用场景。例如,网页爬虫可以使用布隆过滤器来去重,避免重复爬取相同的网页;缓存系统可以使用布隆过滤器来判断某个数据是否已经缓存,从而避免无谓的IO操作。
不需要删除操作:布隆过滤器不支持元素的删除操作。一旦元素被插入到布隆过滤器中,就无法删除。因此,它适用于那些不需要频繁删除元素的场景。
需要注意的是,布隆过滤器在某些情况下可能会出现误判,将不存在的元素误判为存在。因此,在一些对准确性要求很高的场景下,布隆过滤器可能不适用。
二、代码实现
2.1 Python 实现
代码示例
import math
import mmh3
from bitarray import bitarrayclass BloomFilter:def __init__(self, num_items, false_positive_rate):self.num_items = num_itemsself.false_positive_rate = false_positive_rateself.bit_array_size = self.calculate_bit_array_size(num_items, false_positive_rate)self.num_hash_functions = self.calculate_num_hash_functions(self.bit_array_size, num_items)self.bit_array = bitarray(self.bit_array_size)self.bit_array.setall(0)def calculate_bit_array_size(self, num_items, false_positive_rate):numerator = num_items * math.log(false_positive_rate)denominator = math.log(2) ** 2return int(-(numerator / denominator))def calculate_num_hash_functions(self, bit_array_size, num_items):numerator = (bit_array_size / num_items) * math.log(2)return int(numerator)def add(self, item):for seed in range(self.num_hash_functions):index = mmh3.hash(item, seed) % self.bit_array_sizeself.bit_array[index] = 1def contains(self, item):for seed in range(self.num_hash_functions):index = mmh3.hash(item, seed) % self.bit_array_sizeif self.bit_array[index] == 0:return Falsereturn True代码讲解
现在逐行解释代码的各个部分:
导入所需的模块:代码使用了
math模块来进行数学计算,mmh3模块用于实现哈希函数,bitarray模块用于表示位数组。
BloomFilter类的初始化方法:在初始化过程中,我们需要指定预期的元素数量num_items和期望的误判率false_positive_rate。根据这两个参数,我们通过调用calculate_bit_array_size和calculate_num_hash_functions方法来计算位数组的大小和哈希函数的数量。然后,我们创建一个位数组bit_array,并将所有位初始化为0。
calculate_bit_array_size方法:根据预期元素数量和期望的误判率,使用公式-num_items * log(false_positive_rate) / (log(2) ** 2)计算位数组的大小,并将结果转换为整数。
calculate_num_hash_functions方法:根据位数组的大小和预期元素数量,使用公式(bit_array_size / num_items) * log(2)计算哈希函数的数量,并将结果转换为整数。
add方法:用于向布隆过滤器中添加元素。对于每个元素,我们使用不同的种子值(从0到num_hash_functions-1)来计算哈希值,并将对应的位数组位置设置为1。
contains方法:用于检查元素是否存在于布隆过滤器中。对于每个元素,我们使用与添加操作相同的种子值来计算哈希值,并检查对应的位数组位置。如果任何一个位置上的位为0,则可以确定元素不存在于布隆过滤器中;否则,我们认为元素可能存在于布隆过滤器中。这就是一个简单的布隆过滤器的 Python 实现。你可以根据自己的需求进行调整和扩展。请注意,这个实现中并没有考虑动态调整布隆过滤器大小或删除元素的功能。
测试代码
import randomdef generate_random_string(length):letters = "abcdefghijklmnopqrstuvwxyz"return ''.join(random.choice(letters) for _ in range(length))num_items = 1000
false_positive_rate = 0.01bloom_filter = BloomFilter(num_items, false_positive_rate)# 添加元素
for _ in range(num_items):item = generate_random_string(10)bloom_filter.add(item)# 检查元素是否存在
positive_count = 0
for _ in range(1000):item = generate_random_string(10)if bloom_filter.contains(item):positive_count += 1false_positive_rate_actual = positive_count / 1000
print("实际误判率:", false_positive_rate_actual)我们首先定义了预期的元素数量
num_items和期望的误判率false_positive_rate。然后,我们创建了一个BloomFilter实例并使用add方法向布隆过滤器中添加了随机生成的元素。接下来,我们使用
contains方法进行随机测试。我们随机生成了1000个字符串,并检查它们是否存在于布隆过滤器中。我们计算了实际的误判率,即在这1000个随机字符串中错误判断为存在的比例,并将其打印出来。测试结果会输出一个实际的误判率,应该接近于设定的期望误判率。
请注意,由于布隆过滤器的特性,即使在没有添加的情况下,也可能会有一定的误判率。因此,实际误判率可能略高于设定的期望误判率。
运行结果
实际误判率: 0.0092.2Java实现
代码示例
import java.util.BitSet;
import java.util.Random;public class BloomFilter {private BitSet bitSet;private int size;private int numHashFunctions;private Random random;public BloomFilter(int expectedNumItems, double falsePositiveRate) {size = calculateBitSetSize(expectedNumItems, falsePositiveRate);numHashFunctions = calculateNumHashFunctions(size, expectedNumItems);bitSet = new BitSet(size);random = new Random();}public void add(String item) {for (int i = 0; i < numHashFunctions; i++) {int hash = hash(item, i);bitSet.set(hash, true);}}public boolean contains(String item) {for (int i = 0; i < numHashFunctions; i++) {int hash = hash(item, i);if (!bitSet.get(hash)) {return false;}}return true;}private int hash(String item, int seed) {random.setSeed(seed);return Math.abs(random.nextInt()) % size;}private int calculateBitSetSize(int expectedNumItems, double falsePositiveRate) {int size = (int) Math.ceil((expectedNumItems * Math.log(falsePositiveRate)) / Math.log(1.0 / (Math.pow(2.0, Math.log(2.0)))));return size;}private int calculateNumHashFunctions(int size, int expectedNumItems) {int numHashes = (int) Math.ceil((size / expectedNumItems) * Math.log(2.0));return numHashes;}
}代码讲解
解释一下以上代码的各个部分:
BloomFilter类的构造函数:在构造函数中,我们传入预期的元素数量expectedNumItems和期望的误判率falsePositiveRate。然后,我们使用calculateBitSetSize和calculateNumHashFunctions方法计算位集合的大小和哈希函数的数量。接着,我们创建一个位集合bitSet,并初始化一个Random对象。
add方法:用于向布隆过滤器中添加元素。对于每个元素,我们使用不同的种子值(从0到numHashFunctions-1)来计算哈希值,并将对应的位设置为1。
contains方法:用于检查元素是否存在于布隆过滤器中。对于每个元素,我们使用与添加操作相同的种子值来计算哈希值,并检查对应的位是否为1。如果任何一个位为0,则可以确定元素不存在于布隆过滤器中;否则,我们认为元素可能存在于布隆过滤器中。
hash方法:用于计算哈希值。我们使用种子值作为随机数种子,并使用Random对象生成一个哈希值。然后,我们对哈希值取绝对值,并对位集合大小取模,以确保哈希值在位集合范围内。
calculateBitSetSize方法:根据预期元素数量和期望的误判率,使用公式(expectedNumItems * log(falsePositiveRate)) / log(1.0 / (Math.pow(2.0, Math.log(2.0))))计算位集合的大小,并返回结果。
calculateNumHashFunctions方法:根据位集合的大小和预期元素数量,使用公式(size / expectedNumItems) * log(2.0)计算哈希函数的数量,并返回结果。这是一个简单的布隆过滤器的 Java 实现。你可以根据自己的需求进行调整和扩展。注意,这个实现中没有考虑动态调整布隆过滤器大小或删除元素的功能。
测试代码
public class Main {public static void main(String[] args) {int expectedNumItems = 1000;double falsePositiveRate = 0.01;BloomFilter bloomFilter = new BloomFilter(expectedNumItems, falsePositiveRate);// 添加元素bloomFilter.add("apple");bloomFilter.add("banana");bloomFilter.add("orange");// 检查元素是否存在System.out.println(bloomFilter.contains("apple")); // 输出: trueSystem.out.println(bloomFilter.contains("banana")); // 输出: trueSystem.out.println(bloomFilter.contains("orange")); // 输出: trueSystem.out.println(bloomFilter.contains("grape")); // 输出: falseSystem.out.println(bloomFilter.contains("melon")); // 输出: false}
}运行结果
true
true
true
false
false三、图书推荐
图书名称:
- 《漫画算法:小灰的算法之旅》
图书介绍

本书是《漫画算法:小灰的算法之旅》的续作,通过主人公小灰的心路历程,用漫画的形式讲述了多个数据结构、算法及复杂多变的算法面试题目。
第1章介绍了几种典型的排序算法,包括选择排序、插入排序、希尔排序、归并排序、基数排序。
第2章介绍了“树”结构的高级应用,包括二叉查找树、AVL树、红黑树、B树和B+树。
第3章介绍了“图”结构的概念,以及深度优先遍历、广度优先遍历、单源最短路径、多源最短路径算法。
第4章介绍了“查找”相关的算法和数据结构,包括二分查找算法、RK算法、KMP算法,以及“跳表”这种用于高效查找的数据结构。
第5章介绍了多种职场上流行的算法面试题目及详细的解题思路,例如螺旋遍历二维数组、寻找数组中第k大元素、求股票交易的更大收益等。
等不及的小伙伴,可以点击下方链接,先睹为快:漫画算法2
参与方式
图书数量:本次送出 4 本 !!!⭐️⭐️⭐️
活动时间:截止到 2023-08-11 12:00:00抽奖方式:
- 评论区随机抽取小伙伴!
留言内容,以下方式都可以:
- 根据文章内容进行高质量评论
参与方式:关注博主、点赞、收藏,评论区留言
中奖名单
🍓🍓 获奖名单🍓🍓
中奖名单:请关注博主动态
名单公布时间:2023-08-11 下午



![ParallelCollectionRDD [0] isEmpty at KyuubiSparkUtil.scala:48问题解决](https://img-blog.csdnimg.cn/09dcfa699ce941da918f243e63ffcbe0.jpeg)
![[CKA]考试之检查可用节点数量](https://img-blog.csdnimg.cn/9b0b748b5f6645efa58455eae291736c.png)