目录
编辑
1. ChatGPT到底是个啥?
1.1. 简介
1.2 玩法
1.2.1.生成公司理念、生成广告标语
1.2.2.写小说写故事写情书
1.2.3.生成自媒体文案
1.2.4.写代码
2.简析ChatGPT
2.1.ChatGPT核心能力
2.2.ChatGPT进化史
2.2.1.历史沿革
2.2.2.算法
2.3.ChatGPT特点和局限
3.评价
3.1.正面评价
3.2.负面反应
1. ChatGPT到底是个啥?
1.1. 简介
ChatGPT (Chat Generative Pre-trained Transformer ) 是由OpenAI开发的一个人工智能聊天机器人程序,于2022年11月推出。
该程序使用基于GPT-3.5架构的大型语言模型,并通过大量文本数据的强化学习训练,可以生成高质量的文本对话。它的训练数据来自互联网上的大量文本,因此它能够回答各种各样的问题,以及生成各种类型的文本,例如说明、文章和对话。
1.2 玩法
ChatGPT目前仍以文字方式交互为主,除了可与人类自然对话外,ChatGPT还可以用于相对复杂的语言工作,包括自动文本生成、自动问答、自动摘要等在内的多种任务。
在自动文本生成方面,ChatGPT可以根据输入的文本自动生成类似的文本(剧本、歌曲、企划等);
在自动问答方面,ChatGPT可以根据输入的问题自动生成答案。还具有编写和调试计算机程序的能力。
1.2.1.生成公司理念、生成广告标语

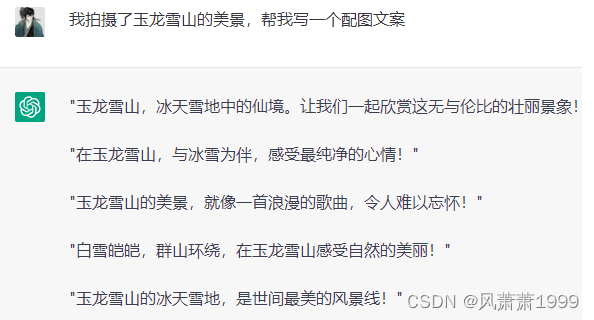
1.2.2.写小说写故事写情书
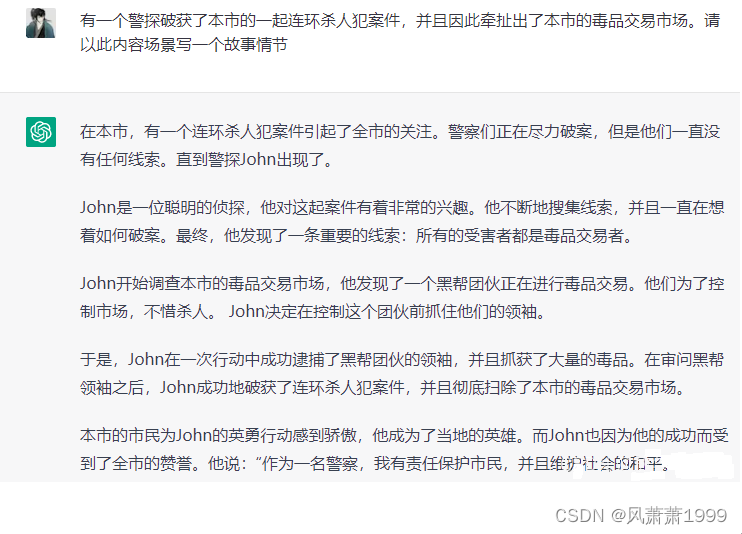
1.2.3.生成自媒体文案
1.2.4.写代码

public class LineToColumn {public static void main(String[] args) {
// 定义一个二维数组int[][] arr = {{1,2,3,4},{5,6,7,8},{9,10,11,12}};// 行转列int[][] result = new int[arr[0].length][arr.length];for(int i = 0; i < arr.length; i++) {for(int j = 0; j < arr[0].length; j++) {result[j][i] = arr[i][j];}}// 打印结果for(int i = 0; i < result.length; i++) {for(int j = 0; j < result[0].length; j++) {System.out.print(result[i][j] + " ");}System.out.println();}}
}/*
输出结果:
1 5 9
2 6 10
3 7 11
4 8 12
*/
2.简析ChatGPT
2.1.ChatGPT核心能力
语言模型的工作方式是对语言文本进行概率建模,用来预测下一段输出内容的概率,形式上有些类似于文字接龙游戏。比如输入的内容是“你好”,模型可能就会在可能的结果中选出概率最高的那一个,用来生成下一部分的内容。
ChatGPT的核心能力归结为三点:
- 对于用户实际意图的理解有明显提升。对于使用过类似聊天机器人或者自动客服的同学,应该经常会遇到机器人兜圈子甚至答非所问的情况,用户体验感较差。ChatGPT在该方面有了显著提升,具有更加良好的用户体验。
- 具有非常强的上下文衔接能力。对于我们用户而言,用户不仅可以问一个问题,而且可以通过不断追加提问的方式,让其不断改进回答内容,最终达到用户期待的理想效果。
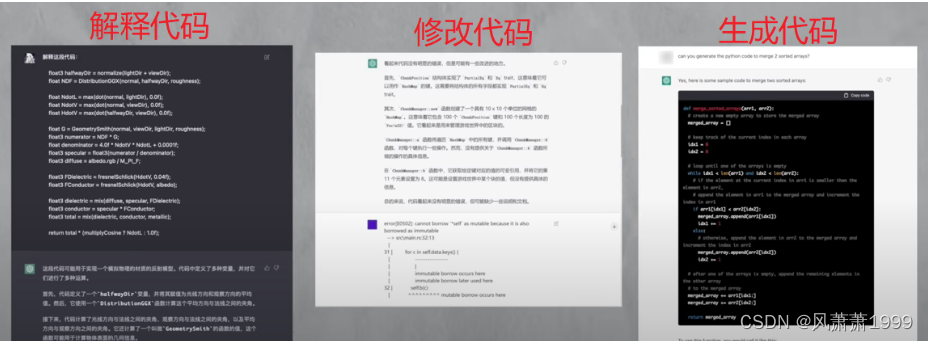
- 更强的对知识和逻辑的理解能力。当遇到某个问题,其不仅给出一个完整的回答,并且对追加细节也可以很好的解答。(这种兼容大量知识且富含逻辑的能力非常适合编程,目前网上已有很多如何解释、修改甚至生成完整代码的案例,具体详见下图。)
2.2.ChatGPT进化史
2.2.1.历史沿革
截止目前尚未发现ChatGPT的公开论文(如有请指出),但可以明确的是ChatGPT与Open AI此前发布的InstructGPT具有非常接近的姊妹关系,两个模型的训练过程也非常接近,因此InstructGPT有较为可靠的参考价值。

从演进关系来看,ChatGPT是OpenAI的另一款模型,InstrcutGPT的姊妹版本,其基于InstrcutGPT做了一些调整。具体的发展路线如下:

ChatGPT一个有趣的突破是来自于模型量级上提升。从GPT-1到GPT-3,模型参数量从1.17亿到15亿,再到1750亿。GPT-3相比于同类型的语言模型参数量增加了10倍以上。训练数据量也由从 GPT 的 5GB,增加到GPT-2的40GB,再到GPT-3的45TB。

从GPT-3到 InstrcutGPT的一个有趣改进是引入了人类的反馈。
引自OpenAI论文的说法,在InstrcutGPT之前,大部分大规模语言模型的目标都是基于上一个输入片段token来推测下一个输出片段,然而这个目标和用户的意图是不一致的,用户的意图是让语言模型能够有用并且安全地遵循用户的指令。此处的指令也就是InstrcutGPT名字的来源,也呼应了ChatGPT的最大优势,即对用户意图的理解。
为了达到该目的,引入了人类老师(即标记人员),通过标记人员的人工标记来训练出一个反馈模型,该反馈模型再去训练GPT-3。之所以没有让标记人员直接训练GPT-3,可能是由于数据量过大的原因。该反馈模型就像是被抽象出来的人类意志可以用来激励GPT-3的训练,整个训练方法即为基于人类反馈的强化学习。

2.2.2.算法
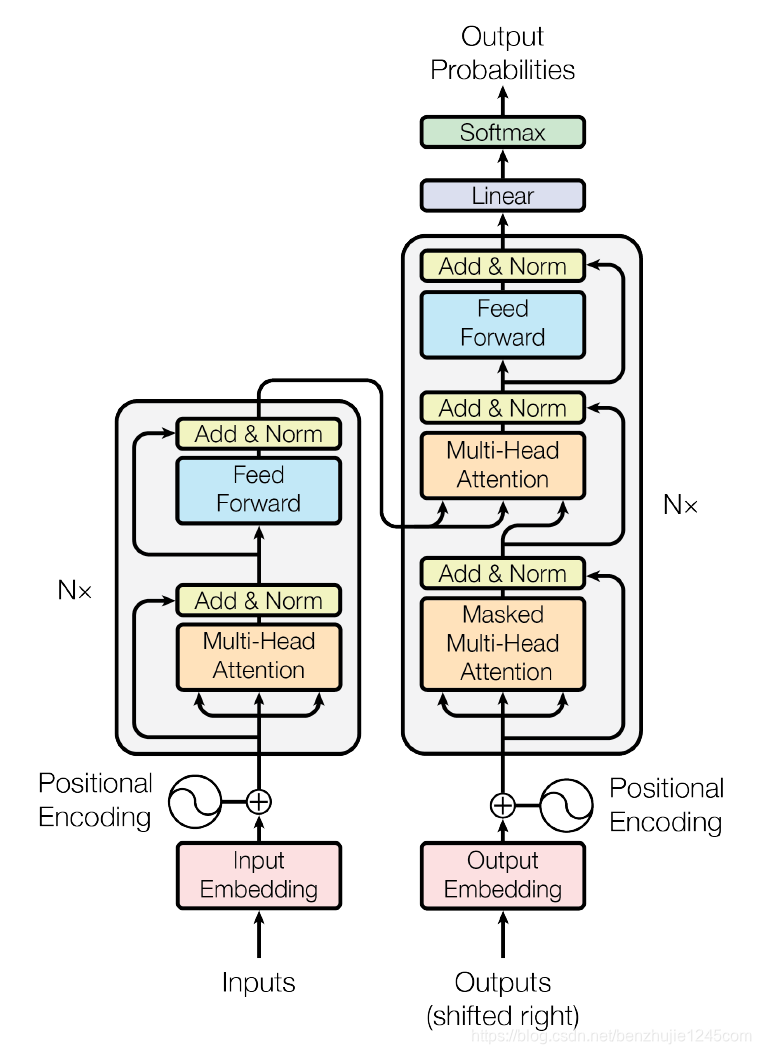
ChatGPT背后的算法基于Transformer架构,这是一种使用自注意力机制处理输入数据的深度神经网络。
Transformer架构广泛应用于语言翻译、文本摘要、问答等自然语言处理任务。以ChatGPT为例,该模型在大量文本对话数据集上进行训练,并使用自我注意机制来学习类人对话的模式和结构。这使它能够生成与它所接收的输入相适应且相关的响应。
Transformer 模型架构模式:
2.3.ChatGPT特点和局限
虽然聊天机器人的核心功能是模仿人类对话者,但ChatGPT用途广泛。
作为聊天机器人:ChatGPT可用于创建能与用户进行对话的聊天机器人。这可能对客户服务很有帮助,因为其可以提供信息,或者只是为了好玩。
作为一个问答系统:ChatGPT可以进行微调,以回答特定类型的问题,例如与特定领域或主题相关的问题。这对于创建虚拟助手或其他类型的信息提供系统很有帮助。
作为对话代理:ChatGPT可以用于创建与用户进行对话的虚拟代理或虚拟化身。这可能对社交媒体应用程序、游戏或其他类型的在线平台很有帮助。
作为文本生成工具:ChatGPT可用于根据输入数据生成类似人类的文本响应。这对于为社交媒体、网站或其他应用程序创建内容很有帮助。
ChatGPT试图减少有害和误导性的回复。例如:当InstructGPT接受“告诉我2015年克里斯托弗·哥伦布何时来到美国”的提问时,它会认为这是对真实事件的描述,而ChatGPT针对同一问题则会使用其对哥伦布航行的知识和对现代世界的理解来构建一个答案,假设如果哥伦布在2015年来到美国时可能会发生什么。ChatGPT的训练数据包括各种文档以及关于互联网、编程语言等各类知识。
与其他多数聊天机器人不同的是,ChatGPT能够记住与用户之前的对话内容和给它的提示。此外,为了防止ChatGPT接受或生成冒犯性言论,输入内容会由审核API进行过滤,以减少潜在的种族主义或性别歧视等内容。目前,有部分地区无法使用此项服务。
ChatGPT也存在一些局限。其奖励模型围绕人类监督而设计,可能导致过度优化,从而影响性能,即古德哈特定律。例如在训练过程中,不管实际理解或事实内容如何,审核者都会偏好更长的答案。训练数据有时也存在算法偏见,比如当程序接受到首席执行官之类的模糊描述时可能会假设此人是白人男性。
3.评价
3.1.正面评价
《纽约时报》称其为“有史以来向公众发布的最好的人工智能聊天机器人。据报道,Microsoft 必应计划在其搜索引擎中添加ChatGPT功能选项,时间可能在2023年3月左右。根据CNBC的报道,谷歌员工正在紧锣密鼓地测试一个名为“学徒巴德”(英语:Apprentice Bard)的聊天机器人,谷歌准备拿来这位“学徒”和ChatGPT竞争。
3.2.负面反应
在2022年12月的一篇评论文章中,经济学家保罗·克鲁曼写道,ChatGPT将影响对知识工作者的需求。
2023年1月,国际机器学习大会禁止在提交的论文中使用ChatGPT或其他大型语言模型来生成任何文本。纽约市公立学校禁止师生在校园网及设备上使用ChatGPT。