目 录
一 使用场景
1 大规模数据处理
2 复杂计算
3 并行搜索
4 并行排序
二 Fork/Join框架介绍
三 Fork/Join框架模块
四 Fork/Join框架核心思想
1分治思想(Divide-and-Conquer)
2 work-stealing(工作窃取)算法
五 Fork/Join框架执行流程
1 实现原理:
2 fork/join 整体任务调度流程
3 work-stealing 原理
六 Fork/Join框架源码解析
1 使用
2 具体原理实现
七 Fork/Join框架的陷阱和注意事项
八 Fork/Join在JDK8中的使用以及异常处理问题
九 Fork/Join实践问题
参考文献
一 使用场景
1 大规模数据处理
一个大型文件进行处理时候,可以用forkjoin将文件拆分成多个小块,然后并行处理这些小块,最终将结果合并起来。
2 复杂计算
大规模的图像处理时候,可以讲图像拆分成多个小块,然后并行处理,最后合并。
3 并行搜索
当需要在一个大型数据集中搜索某个元素时候,讲数据集拆分成多个小块,然后并行搜索这些小块,最后讲结果合并
4 并行排序
二 Fork/Join框架介绍
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
这种机制策略在分布式数据库中非常常见,数据分布在不同的数据库的副本中,在执行查询时,每个服务都要跑查询任务,最后在一个服务上做数据合并,或者提供一个中间引擎层,用来汇总数据:

三 Fork/Join框架模块
Fork/Join框架模块主要包含三个模块
1 任务对象ForkJoinTask (包括RecursiveTask,RecursiveAction ,CountedCompleter)
2 执行Fork/Join任务的线程: ForkJoinWorkerThread
3 线程池: ForkJoinPool
这三者的关系是: ForkJoinPool可以通过池中的ForkJoinWorkerThread来处理ForkJoinTask任务。

ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,RecursiveAction 是一个无返回值的 RecursiveTask,CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
四 Fork/Join框架核心思想
1分治思想(Divide-and-Conquer)
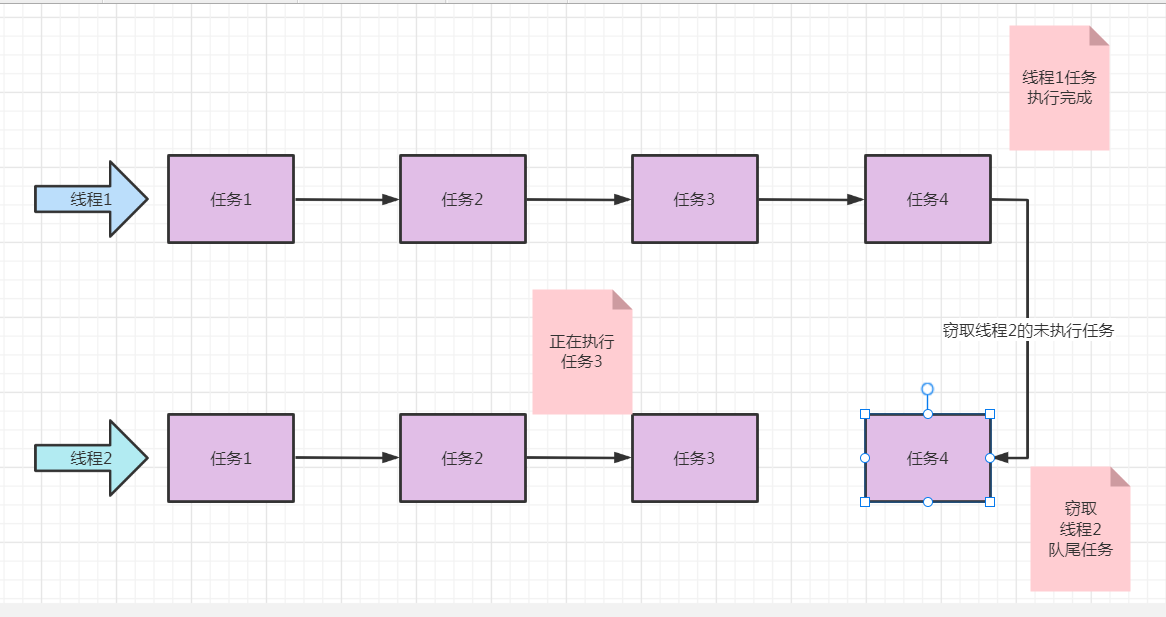
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制如下图所示:

2 work-stealing(工作窃取)算法
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
五 Fork/Join框架执行流程
fforkjoin 最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的 cpu,那么如何利用好这个空闲的 cpu 就成了提高性能的关键,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。work-stealing 可以充分地利用线程进行并行计算, 减少了线程之间的竞争
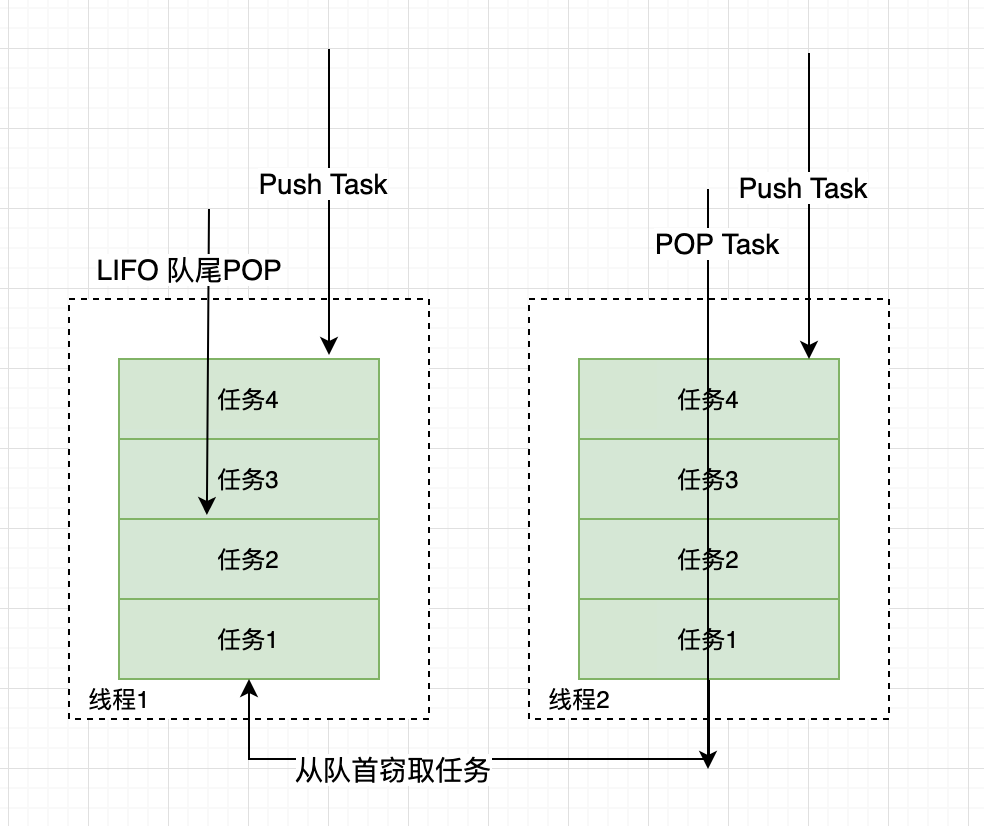
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
1 实现原理:
-
fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。
-
join():等待该任务的处理线程处理完毕,获得返回值。
这里并不会每个 fork 都会创建新线程, 也不是每个 join 都会造成线程被阻塞, 而是采取work-stealing 原理
2 fork/join 整体任务调度流程

3 work-stealing 原理
-
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
-
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
-
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
-
在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠
Fork/Join框架的核心来自于它的工作窃取及调度策略,可以总结为以下几点:
-
每个Worker线程利用它自己的任务队列维护可执行任务;
-
任务队列是一种双端队列,支持LIFO的push和pop操作,也支持FIFO的take操作;
-
任务fork的子任务,只会push到它所在线程(调用fork方法的线程)的队列;
-
工作线程既可以使用LIFO通过pop处理自己队列中的任务,也可以FIFO通过poll处理自己队列中的任务,具体取决于构造线程池时的asyncMode参数;
-
当工作线程自己队列中没有待处理任务时,它尝试去随机读取(窃取)其它任务队列的base端的任务;
-
当线程进入join操作,它也会去处理其它工作线程的队列中的任务(自己的已经处理完了),直到目标任务完成(通过isDone方法);
-
当一个工作线程没有任务了,并且尝试从其它队列窃取也失败了,它让出资源(通过使用yields, sleeps或者其它优先级调整)并且随后会再次激活,直到所有工作线程都空闲了——此时,它们都阻塞在等待另一个顶层线程的调用。
六 Fork/Join框架源码解析
Java7 提供了ForkJoinPool来支持将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果。
ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。利用分而治之的思想+工作窃取算法,实现的一种线程池;最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
1 使用
使用需要下面步骤
定义任务
普通任务:runnable接口,Callable接口等实现类
ForkJoinTask子类:CountedCompleter、RecursiveAction、RecursiveTask是其进一步实现封装的抽象类;用户选取上述类自行实现即可
提交任务
普通任务提交,必须使用ForkJoinPool
ForkJoinTask类型任务,可以fork来处理
获取结果
ForkJoinTask任务句柄,join方法处理
线程池invoke方法,提交并执行
普通任务这里就不给示例了,和ThreadPoolExecutor使用没有啥区别;下面举个 ForkJoinTask类型任务例子
定义任务
class Task(private val num : Int) : RecursiveTask<Long>() { override fun compute(): Long { if (num < 2) return 1L val t1 = Task(num - 1) val t2 = Task(num - 2) t1.fork() t2.fork() return t1.join() + t2.join() }}
RecursiveTask是有计算结果的任务,RecursiveAction无计算结果的任务;CountedCompleter后面会单独介绍
任务提交、结果获取
val task = Task(20) task.fork() print(task.join())
又或者线程池提交
print(ForkJoinPool(10).submit(Task(20)).join()) print(ForkJoinPool(10).invoke(Task(20))) print(ForkJoinPool.commonPool().invoke(Task(20)))
ForkJoinPool.commonPool()为通用的、已提供的ForkJoinPool实例;这里要注意join方法为阻塞方法;另外也要注意,fork方法虽然是提交任务,但是任务有可能被窃取执行,所以,join有可能立即获取结果;所以需要在合理的地方进行结果获取;也可获取提交任务句柄,在需要的地方进行获取值
使用是不是很简单,但是我说上面任务返回结果
return t1.join() + t2.join()
替换为
return t2.join() + t1.join()
执行效率会略高一些,你会信吗?这个和join方法内的逻辑有关,如果任务最后一个加入,则可以优先执行,而不必等待
CountedCompleter任务
复杂且使用比较灵活;它可以通过内部逻辑把自己转化为RecursiveTask、RecursiveAction任务,也可以更灵活的使用,并且最大的不同就是其只有一个任务需要join操作且任务间并不阻塞线程池内部的调用,任务间的联系需要通过相应回调来触发,其通过完成回调方法合并其依赖的结果;内部增加了如下两个成员变量
final CountedCompleter<?> completer; volatile int pending;
completer:依赖当前任务的节点;其像链表,但又不是,说是树可能更合适;最开始的那个任务,是树根节点,其依赖的为其孩子节点
pending: 当前节点依赖的节点个数,也可以说其孩子节点的个数;类中提供了一些列的方法操作,不介绍了;其内部方法调用时,都是先于0比较,然后,才会减少1,所以内部方法进行结束任务时,这个个数+1才是依赖的数目
一般情况下,我们不需直接对pending直接操作,可以使用其已经提供的一些方法进行操作,进而达到效果;方法有下面几个:
-
tryComplete:当前点为出发点,向依赖其节点进行循环处理,遇到以下情况会结束
-
pending为0且依赖其的节点为空:pending为0时,回调onCompletion完成处理方法;若依赖其节点为空,则调用quietlyComplete方法设置执行状态为完成
-
处理当前节点pending值-1成功
-
propagateCompletion方法,和tryComplete方法相比,无onCompletion方法回调调用,也即对于每个中间任务无需关注
-
quietlyCompleteRoot : 依照指针域去寻找根依赖节点,并为其设置正常结束状态;比较暴力的结束任务状态,这种适合于找到某一个结果就停止
onCompletion回调方法
这个方法是仅仅通知当前任务所有依赖已经完成,用于任务合并操作,但却在此方法中仅仅知道最后一个完成的依赖任务;
为何CountedCompleter要设置正常结束状态,这时由于ForkJoinTask在执行方法的逻辑
final int doExec() { int s; boolean completed; if ((s = status) >= 0) { try { completed = exec(); } catch (Throwable rex) { return setExceptionalCompletion(rex); } if (completed) s = setCompletion(NORMAL); } return s; }
也即是,现有ForkJoinTask的子类exec方法,均是返回true,只有CountedCompleter返回false,所以其需要设置正常结束状态,任务才会被结算成执行完毕,在任务fork等调用时,才会结束阻塞;如果你只是往里面添加一个任务这个则不处理也没有关系
类似RecursiveAction的效果
class Task(private val num : Int,private val end : Int, completer: Task? = null) : CountedCompleter<Void>(completer) { override fun compute() { if (end == num) { if (end % 2 == 0) println("odd $end") propagateCompletion() return } addToPendingCount(1) val middle = (num + end) / 2 Task(num, middle, this).fork() Task(middle + 1, end,this).fork() }}
类似RecursiveTask的效果
class Task(val num : Int,val end : Int, completer: Task? = null) : CountedCompleter<Int>(completer) { @Volatile public var mResult = 0 private var t1 : Task? = null private var t2 : Task? = null override fun compute() { if (end == num) { mResult = end tryComplete() return } addToPendingCount(1) val middle = (num + end) / 2 t1 = Task(num, middle, this).fork() as Task t2 = Task(middle + 1, end,this).fork() as Task } override fun onCompletion(caller: CountedCompleter<*>?) { if (this != caller && caller is Task) { mResult = (t1?.mResult ?: 0) + (t2?.mResult ?: 0) } } override fun getRawResult(): Int { return mResult } override fun setRawResult(t: Int?) { mResult = t ?: 0 }}
如果不通过根任务的join等方法获取结果,而是其它数据交流的办法(Rxjava 中发射、LiveData等),则可以不重写get/setRawResult方法
某个特殊结果寻找
class Task(val num : Int,val end : Int, completer: Task? = null) : CountedCompleter<Int>(completer) { @Volatile public var mResult = 0 override fun compute() { if (end % 7 == 0 && end % 5 == 0) { (root as Task).mResult = end quietlyCompleteRoot() return } else if (num == end) { return } addToPendingCount(1) val middle = (num + end) / 2 Task(num, middle, this).fork() Task(middle + 1, end,this).fork() } override fun getRawResult(): Int { return mResult } override fun setRawResult(t: Int?) { mResult = t ?: 0 }}
可能还有其它场景,但是这些场景的处理都是依据pending值和其引用来确定是否设置结束状态;
-
原子操作设置值:addToPendingCount、compareAndSetPendingCount等方法
-
利用设置状态方法来处理:propagateCompletion、tryComplete、quietlyCompleteRoot等
2 具体原理实现
ForkJoinPool线程池,其执行任务的线程对象是ForkJoinWorkerThread子类,任务均被包装为ForkJoinTask的子类
ForkJoinWorkerThread类
Thread子类,其中主要内容有:线程队列创建、销毁、执行
ForkJoinWorkerThread线程队列创建
在构造器中通过
ForkJoinPool.registerWorker方法为当前线程关联队列,队列位置为线程池队列数组的奇数位置
ForkJoinWorkerThread线程的销毁
通过
ForkJoinPool.deregisterWorker方法进行销毁
ForkJoinWorkerThread线程的运行
run方法内为其主要逻辑,不贴代码了;需要在其线程队列建立后,持有数据还未申请空间之前进行线程执行,否则不做任何处理
回调方法onStart,表示线程开始执行;通过ForkJoinPool.runWorker方法来执行任务;onTermination回调方法接收异常处理;
ForkJoinTask类
抽象类,实现了Future、Serializable接口;其主要内容:任务异常收集、fork-join执行流程(join也可以是invoke、get等操作,但这里就依据join来讲解)
task有以下几种状态
volatile int status; static final int DONE_MASK = 0xf0000000; static final int NORMAL = 0xf0000000; static final int CANCELLED = 0xc0000000; static final int EXCEPTIONAL = 0x80000000; static final int SIGNAL = 0x00010000; static final int SMASK = 0x0000ffff;
-
NORMAL:结束状态,正常结束,负数
-
CANCELLED:结束状态,用户取消,负数
-
EXCEPTIONAL:结束状态,执行异常,负数
-
SIGNAL:等待通知执行状态,正数
-
0 : 起始状态
异常收集
异常数据收集,是根据弱引用机制来处理;弱引用任务节点结构如下:
static final class ExceptionNode extends WeakReference<ForkJoinTask<?>> { final Throwable ex; ExceptionNode next; final long thrower; final int hashCode; ExceptionNode(ForkJoinTask<?> task, Throwable ex, ExceptionNode next, ReferenceQueue<Object> exceptionTableRefQueue) { super(task, exceptionTableRefQueue); this.ex = ex; // 原始异常 this.next = next; // 相同hash的节点指针域 this.thrower = Thread.currentThread().getId(); // 线程标识 this.hashCode = System.identityHashCode(task); // 与对象地址相对应的hash } }
弱引用节点相关数据结构
private static final ExceptionNode[] exceptionTable; // 异常数据 private static final ReentrantLock exceptionTableLock; // 异常节点锁 private static final ReferenceQueue<Object> exceptionTableRefQueue; // 弱引用回收队列
采用的数组存储,并利用hash进行映射,单链表进行冲突解决;并在需要处理异常时,实时去除已经销毁的task节点异常;常用操作如下:
-
记录异常:recordExceptionalCompletion方法,在任务未完成的情况才会记录
-
清除当前节点异常:clearExceptionalCompletion方法
-
获取异常:getThrowableException,非当前线程异常,需要进行包装转换
-
清理无效task相关联异常:expungeStaleExceptions静态方法,清除掉回收队列中task所有相关异常节点
fork-join逻辑
fork方法用于向队列中保存任务;偶数任务队列中未依赖于线程,奇数队列为线程私有
public final ForkJoinTask<V> fork() { Thread t; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this); else ForkJoinPool.common.externalPush(this); return this; }
当前在ForkJoinWorkerThread线程中执行,则调用workQueue.push方法存入队列放入线程池中队列数组中偶数位置的队列中
join方法用于阻塞获取结果
public final V join() { int s; if ((s = doJoin() & DONE_MASK) != NORMAL) reportException(s); return getRawResult(); } private int doJoin() { int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w; return (s = status) < 0 ? s : ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ? (w = (wt = (ForkJoinWorkerThread)t).workQueue). tryUnpush(this) && (s = doExec()) < 0 ? s : wt.pool.awaitJoin(w, this, 0L) : externalAwaitDone(); }
同样需要根据线程类型判断
状态小于0,也即任务已结束,则直接返回,如果是异常则会抛出异常未执行时,不是ForkJoinWorkerThread线程内执行,以当前任务实例为锁对象,进行等待(更具体的逻辑在externalAwaitDone方法内分析)未执行时,ForkJoinWorkerThread线程内执行;如果任务为当前线程队列的顶部(也就是最后一个提交的)且执行后处于结束状态,则返回线程池内awaitJoin进行等待(其时可能存在窃取其它任务队列进行执行)
externalAwaitDone方法
首先尝试执行,如果满足下面条件,则会执行doExec方法(调用exec()方法进行具体执行)
CountedCompleter任务类型,则common线程池方法externalHelpComplete返回true其它任务类型,common线程池tryExternalUnpush方法返回true
如果未执行,则通过staus原子操作+synchronized锁,进行等待
ForkJoinPool类
这里主要有一些常量的意义、队列结构、执行流程、窃取线程思路;
ForkJoinPool类状态成员变量
volatile long ctl; volatile int runState; final int config;
ct1,64位,分为4段,每相邻16位为一段
高16位,正在处理任务的线程个数;初始化为并行数的负值(构造器中线程的并行线程数,一般来说为能创建的最大线程数)次高16位,线程总数,初始化为并行数的负值次低16位,线程状态,小于0时需要添加新的线程,或者说48位的位置为1时,需要添加线程低16位,空闲线程对应的任务队列在队列数组的索引位置
runState,有下面几种状态,默认态为0
private static final int STARTED = 1; private static final int STOP = 1 << 1; private static final int TERMINATED = 1 << 2; private static final int SHUTDOWN = 1 << 31;
config:低16位代表 并行度(parallelism),高16位:队列模式,默认是后进先出
ForkJoinPool类线程队列
volatile WorkQueue[] workQueues
数组结构,分为线程队列和非线程队列,随机寻找位置进行创建与查找;达到WorkQueue均匀处理,以减少WorkQueue同步开销
volatile int scanState; // 负数:inactive, 非负数:active, 其中奇数代表scanning int stackPred; // sp = (int)ctl, 前一个队列栈的标示信息,包含版本号、是否激活、以及队列索引 int nsteals; // 窃取的任务数 int hint; // 一个随机数,用来帮助任务窃取,在 helpXXXX()的方法中会用到 int config; // 配置:二进制的低16位代表 在 queue[] 中的索引,高16位:mode可选FIFO_QUEUE(1 << 16)和LIFO_QUEUE(1 << 31),默认是LIFO_QUEUE volatile int qlock; // 锁定标示位:1: locked, < 0: terminate; else 0 volatile int base; // index of next slot for poll int top; // index of next slot for push ForkJoinTask<?>[] array; // 任务列表
WorkQueue中数据结构主体:任务数组、任务队列头部、尾部;以及线程操作同步标志,使用原子操作+volatile来实现,-1表示不允许操作了、0表示可以操作、1表示正常操作
因此其方法可以分为线程安全方法、非线程安全方法;线程安全方法用于窃取,非线程安全方法用于线程内任务执行
push方法:队列尾部加入数据,非线程安全growArray方法:数组扩容,2被扩容,非线程安全pop方法:从尾部取出数据,原子操作保证线程安全,但不保证成功pollAt方法:从头部取出数据,原子操作保证线程安全,但不保证成功poll: 从头部取出数据,原子操作+自旋,保证线程安全nextLocalTask:根据策略,进行取出数据(根据congfig来进行处理),线程安全peek:根据出队模式返回队头或者队尾元素,但不取出,非线程安全tryUnpush:尝试判断是否为队尾任务,线程安全,但结果不一定准确sharedPush:共享队列(偶数位置的WorkQueue实例),队尾增加数据方法,使用qlock原子操作来实现线程安全,但不保证结果准确,其中队列扩容通过growAndSharedPush方法处理并增加数据trySharedUnpush:判断任务是否处于队尾,原子操作保证线程安全,不保证结果准确cancelAll: 取消所有任务localPopAndExec:从队尾开始执行任务,原子操作+自旋来保证线程安全,存在线程竞争时,则退出,不进行处理localPollAndExec:从队头开始执行任务,原子操作+自旋来保证线程安全,存在线程竞争时,则退出,不进行处理runTask:执行窃取任务,并依据出队某事调用localPopAndExec或者localPollAndExec来继续本线程队列任务处理tryRemoveAndExec:自旋+原子操作,尽可能执行线程私有队列中的任务;非队尾数据,原子操作为EmptyTaskpopCC:取出队尾的CountedCompleter任务,原子操作+自旋保证线程安全pollAndExecCC:取出队头CountedCompleter任务,并执行,原子操作+自旋保证线程安全
ForkJoinPool类调用流程
主要有下面三个流程提交任务流程、线程执行流程、获取结果流程
提交任务
从类的角度来看
-
线程池提交任务
-
ForkJoinTask类的fork
从功能角度来看
-
Fork线程内部提交任务
-
非Fork线程提交任务,第一个任务肯定是这种方式
外部提交任务

内部提交任务,直接调用线程私有WorkQueue对象,push方法加入队尾
线程执行
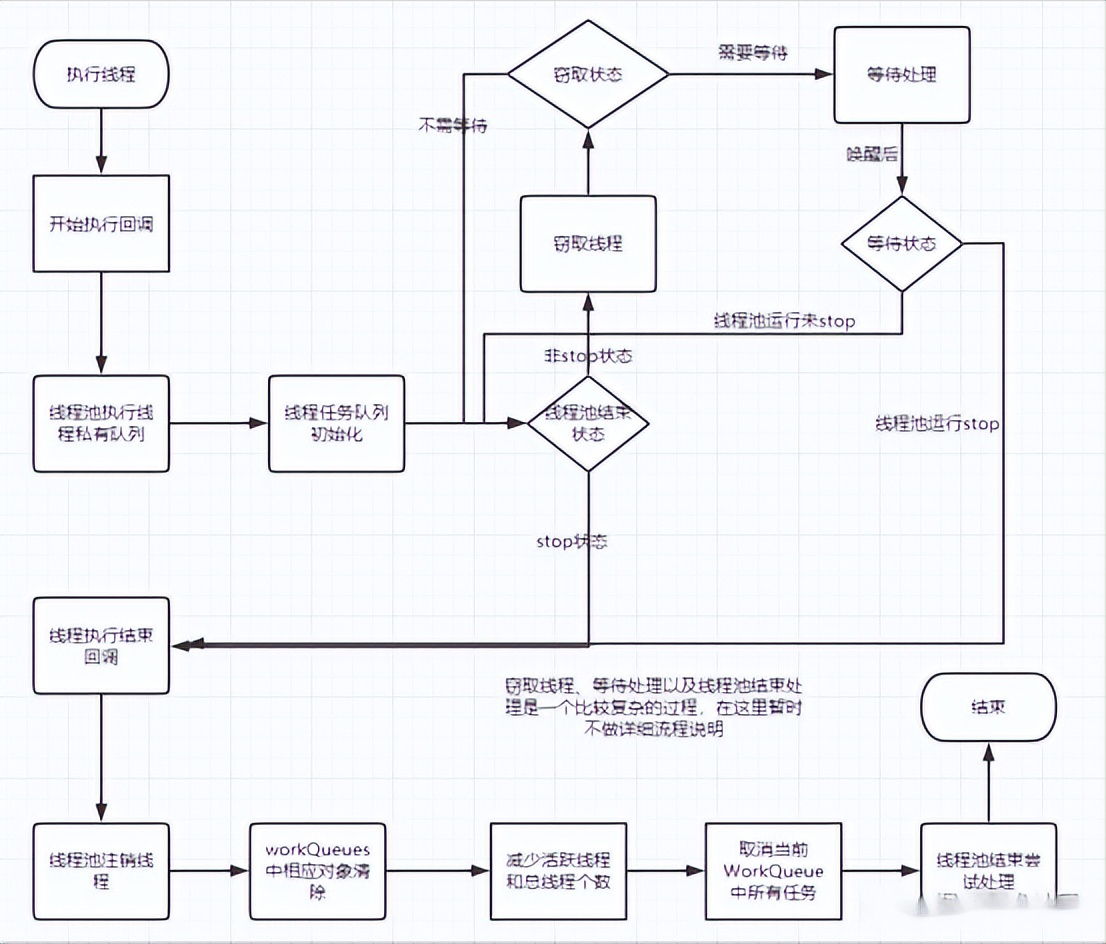
join获取任务结果

从上面三个流程能够大致知道处理的流程,但是偷取的具体的逻辑还是不清楚的;有下面方法需要仔细研读,掌握思想精髓
-
scan方法:fork线程窃取任务,fork线程的第一个任务都是窃取而来
-
awaitJoin方法:线程池内等待,不可被处理时,自己偷自己的任务
-
CountedCompleter任务与其它任务处理的区别,CountedCompleter任务不会相互阻塞
-
锁等待机制:图中可能存在错误;闲置线程,才会线程暂停或者启用,任务的暂停等待则是Object的wait方法,且其执行结束后会notifyAll唤醒所有
-
位运算运用,以及各种状态之间的判断处理,以及这些对性能的一些追求
七 Fork/Join框架的陷阱和注意事项
使用Fork/Join框架时,需要注意一些陷阱, 在下面 斐波那契数列例子中你将看到示例:
避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的fork()方法。
表面上看上去两个子任务都fork(),然后join()两次似乎更自然。但事实证明,直接调用compute()效率更高。因为直接调用子任务的compute()方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务”快得多。
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的invokeAll方法,因为使用它们能避免不必要的fork()。
注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
right.fork(); // 计算右边的任务 long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算) long rightAns = right.join(); // 等待右边的结果 return leftAns + rightAns;
如果我们写成:
left.fork(); // 计算完左边的任务 long leftAns = left.join(); // 等待左边的计算结果 long rightAns = right.compute(); // 再计算右边的任务 return leftAns + rightAns;
或者
long rightAns = right.compute(); // 计算完右边的任务 left.fork(); // 再计算左边的任务 long leftAns = left.join(); // 等待左边的计算结果 return leftAns + rightAns;
这两种实际上都没有并行。
选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并不一定比顺序执行任务的效率高: 如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是: 任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”。
和其他Java代码一样,Fork/Join框架测试时需要“预热”或者说执行几遍才会被JIT(Just-in-time)编译器优化,所以测试性能之前跑几遍程序很重要。
避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销。
八 Fork/Join在JDK8中的使用以及异常处理问题
Java8在Executors工具类中新增了两个工厂方法:
// parallelism定义并行级别 public static ExecutorService newWorkStealingPool(int parallelism); // 默认并行级别为JVM可用的处理器个数 // Runtime.getRuntime().availableProcessors() public static ExecutorService newWorkStealingPool();
关于Fork/Join异常处理
Java的受检异常机制一直饱受诟病,所以在ForkJoinTask的invoke()、join()方法及其衍生方法中都没有像get()方法那样抛出个ExecutionException的受检异常。
所以你可以在ForkJoinTask中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) { if (ex != null) ForkJoinTask.<RuntimeException>uncheckedThrow(ex); } @SuppressWarnings("unchecked") static <T extends Throwable> void uncheckedThrow(Throwable t) throws T { throw (T)t; // rely on vacuous cast }
关于Java你不知道的10件事中已经指出,JVM实际并不关心这个异常是受检异常还是运行时异常,受检异常这东西完全是给Java编译器用的: 用于警告程序员这里有个异常没有处理。
但不可否认的是invoke、join()仍可能会抛出运行时异常,所以ForkJoinTask还提供了两个不提取结果和异常的方法quietlyInvoke()、quietlyJoin(),这两个方法允许你在所有任务完成后对结果和异常进行处理。
使用quitelyInvoke()和quietlyJoin()时可以配合isCompletedAbnormally()和isCompletedNormally()方法使用。
九 Fork/Join实践问题
采用Fork/Join来异步计算1+2+3+…+10000的结果
public class Test { static final class SumTask extends RecursiveTask<Integer> { private static final long serialVersionUID = 1L; final int start; //开始计算的数 final int end; //最后计算的数 SumTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { //如果计算量小于1000,那么分配一个线程执行if中的代码块,并返回执行结果 if(end - start < 1000) { System.out.println(Thread.currentThread().getName() + " 开始执行: " + start + "-" + end); int sum = 0; for(int i = start; i <= end; i++) sum += i; return sum; } //如果计算量大于1000,那么拆分为两个任务 SumTask task1 = new SumTask(start, (start + end) / 2); SumTask task2 = new SumTask((start + end) / 2 + 1, end); //执行任务 task1.fork(); task2.fork(); //获取任务执行的结果 return task1.join() + task2.join(); } } public static void main(String[] args) throws InterruptedException, ExecutionException { ForkJoinPool pool = new ForkJoinPool(); ForkJoinTask<Integer> task = new SumTask(1, 10000); pool.submit(task); System.out.println(task.get()); } }
-
执行结果
ForkJoinPool-1-worker-1 开始执行: 1-625 ForkJoinPool-1-worker-7 开始执行: 6251-6875 ForkJoinPool-1-worker-6 开始执行: 5626-6250 ForkJoinPool-1-worker-10 开始执行: 3751-4375 ForkJoinPool-1-worker-13 开始执行: 2501-3125 ForkJoinPool-1-worker-8 开始执行: 626-1250 ForkJoinPool-1-worker-11 开始执行: 5001-5625 ForkJoinPool-1-worker-3 开始执行: 7501-8125 ForkJoinPool-1-worker-14 开始执行: 1251-1875 ForkJoinPool-1-worker-4 开始执行: 9376-10000 ForkJoinPool-1-worker-8 开始执行: 8126-8750 ForkJoinPool-1-worker-0 开始执行: 1876-2500 ForkJoinPool-1-worker-12 开始执行: 4376-5000 ForkJoinPool-1-worker-5 开始执行: 8751-9375 ForkJoinPool-1-worker-7 开始执行: 6876-7500 ForkJoinPool-1-worker-1 开始执行: 3126-3750 50005000
实现斐波那契数列
斐波那契数列: 1、1、2、3、5、8、13、21、34、…… 公式 : F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
public static void main(String[] args) { ForkJoinPool forkJoinPool = new ForkJoinPool(4); // 最大并发数4 Fibonacci fibonacci = new Fibonacci(20); long startTime = System.currentTimeMillis(); Integer result = forkJoinPool.invoke(fibonacci); long endTime = System.currentTimeMillis(); System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms."); } //以下为官方API文档示例 static class Fibonacci extends RecursiveTask<Integer> { final int n; Fibonacci(int n) { this.n = n; } @Override protected Integer compute() { if (n <= 1) { return n; } Fibonacci f1 = new Fibonacci(n - 1); f1.fork(); Fibonacci f2 = new Fibonacci(n - 2); return f2.compute() + f1.join(); } }
当然你也可以两个任务都fork,要注意的是两个任务都fork的情况,必须按照f1.fork(),f2.fork(), f2.join(),f1.join()这样的顺序,不然有性能问题,详见上面注意事项中的说明。
官方API文档是这样写到的,所以平日用invokeAll就好了。invokeAll会把传入的任务的第一个交给当前线程来执行,其他的任务都fork加入工作队列,这样等于利用当前线程也执行任务了。
{ // ... Fibonacci f1 = new Fibonacci(n - 1); Fibonacci f2 = new Fibonacci(n - 2); invokeAll(f1,f2); return f2.join() + f1.join(); } public static void invokeAll(ForkJoinTask<?>... tasks) { Throwable ex = null; int last = tasks.length - 1; for (int i = last; i >= 0; --i) { ForkJoinTask<?> t = tasks[i]; if (t == null) { if (ex == null) ex = new NullPointerException(); } else if (i != 0) //除了第一个都fork t.fork(); else if (t.doInvoke() < NORMAL && ex == null) //留一个自己执行 ex = t.getException(); } for (int i = 1; i <= last; ++i) { ForkJoinTask<?> t = tasks[i]; if (t != null) { if (ex != null) t.cancel(false); else if (t.doJoin() < NORMAL) ex = t.getException(); } } if (ex != null) rethrow(ex); }
参考文献
https://blog.csdn.net/raoyanhui_java/article/details/99209918
https://blog.csdn.net/qq_35029061/article/details/86762672
https://baijiahao.baidu.com/s?id=1747820985784366091&wfr=spider&for=pc
https://www.cnblogs.com/yaochunhui/p/15448042.html
https://blog.csdn.net/w903328615/article/details/113058322