目录
1.背景
2.预期目标
3.系统设计和实现
3.1系统功能组成
3.2 数据智能生成
3.3 接口遍历测试
4.应用效果和收益
5.后续规划
1.背景
随着软件开发的迅速发展,测试数据管理变得越来越复杂。手动创建测试数据需要耗费大量时间和精力,同时容易出错。若缺乏测试数据,则会导致测试结果不够全面,甚至可能在线上环境中引发问题,从而给软件产品带来质量风险。因此,如何生成大量、真实、正确的测试数据成为了测试人员和研发人员所关心的重要问题。
在业务数据较为简单、常规的项目中,手动编写少量测试数据来跑完用例可能并没有太大问题。但是在接口性能测试和接口遍历测试时需要大量的测试数据,以确保测试结果的覆盖度和全面性。而且,在垂直行业领域中,业务数据往往具有特定的数据结构和约束条件。如果依赖手工创建测试数据或通过编写脚本生成数据,有如下弊端:1) 花费时间;2) 容易出错; 3)覆盖度不够,且缺乏完整性;4) 缺乏可维护性。
为解决这些问题,许多公司开始转向自动化测试数据生成。通过程序或脚本来快速生成符合特定业务场景的测试数据。这种方法相比手动创建测试数据更加高效。
然而,自动化测试数据生成也存在着一些问题和挑战。
需要考虑业务场景:为了生成真实的测试数据,需要对业务场景有充分的理解和掌握。否则,生成的测试数据可能不符合实际业务需求。
维度成本高:虽然自动化测试数据生成可以提高测试效率和准确性,但是针对具体业务测试数据生成工具需要一定的开发和维护成本。
为了解决这些痛点,TestDataLake应运而生,将复杂的测试数据准备工作简化为可视化的过程,是一种非常有效的数据管理工具,可以帮助测试人员快速、准确地生成符合预期的测试数据,并且可以提高测试效率和测试质量。
2.预期目标
为了帮助测试人员快速、准确地生成符合预期的测试数据,并降低脚本生成测试数据的成本,TestDataLake 目标是可以方便地生成覆盖度高、全面和真实的测试数据,用于日常的功能测试、性能测试和接口遍历测试。具体包括:
1)低成本、快速地造出高可用测试数据;
2)保证测试数据的覆盖度、全面性和真实性;
3) 建立业务字典库和通用数据字典库,确保测试数据的时效性和准确性,并且可以灵活扩展业务字典;
4)智能化的依赖关系设计,轻松地从不同的数据字典中抽取字段,并组合成所需的测试数据。
3.系统设计和实现
TestDataLake具有多种功能模块,包括数据模型管理、数据智能生成模块、预览及导出模块、接口遍历测试、接口遍历报告、业务数据查询、数据源管理、数据字典维护等。这些功能模块可以为测试人员和研发人员快速地创建高可用测试数据,提高测试效率和节约测试成本。同时,这些功能模块还可以保证测试数据的覆盖度、全面性和真实性,建立业务字典库和通用数据字典库,确保测试数据的时效性和准确性,并且可以灵活扩展业务字典。最重要的是,可视化数据池平台提供了智能化的依赖关系设计功能,可以轻松地从不同的数据字典中抽取字段,并组合成所需的测试数据,大大提高了测试数据生成的质量和准确性,为开发和测试提供了有力的支持。
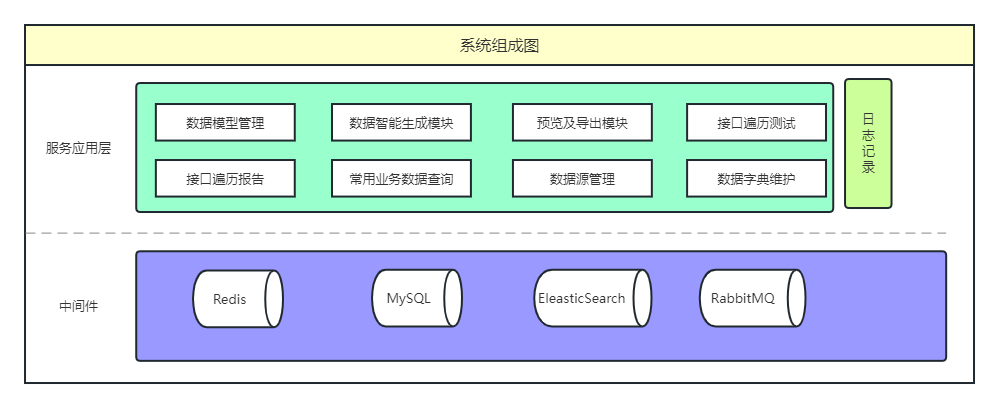
图1 TestDataLake系统组成图
3.1系统功能组成
数据模型管理和数据智能生成模块是TestDataLake提供的核心功能,数据模型管理以直观的可视化界面为用户提供了智能化的依赖关系设计功能。可以轻松地从不同的数据字典中抽取字段,灵活设定数据之间的依赖关系,并组合成所需的测试数据。这样,用户可以避免繁琐的手工编写测试数据工作,同时也可以提高测试数据的质量和准确性。数据智能生成模块可以根据不同的测试需求,自动化生成符合要求的测试数据。该功能模块内置了多种数据生成策略,如随机生成、序列生成、枚举生成、关联数据生成等。这些策略可以根据测试数据的需求进行配置,以产生更加符合实际场景的测试数据,并大大提高测试效率和节约测试成本。
预览及导出模块可帮助用户直观地查看和验证测试数据的正确性和完整性。用户可在该模块中对生成的测试数据进行预览,并可按所需选择导出数据的格式,例如Excel、CSV、SQL、JSON等。以方便后续在其他系统中使用。
接口遍历测试基于智能数据生成的结果,实现全面覆盖的接口测试。可帮助用户发现系统接口中的潜在问题和漏洞,全面测试系统的接口功能,并根据测试结果生成相应的报告。该功能模块可以尽可能地覆盖到所有场景,包括正常情况、异常情况以及边界情况等。过去,测试人员需要准备大量的测试用例和脚本来进行测试,这是一项繁琐且耗费时间的任务。现在,在TestDataLake的帮助下,利用智能数据生成的数据作为接口遍历的数据源,测试团队可以更好地管理测试数据,并提高接口遍历测试的效率和准确性,从而提高系统的稳定性和可靠性。在接口遍历测试中,断言是非常关键的一步。通过断言,测试人员可以验证每个接口是否按照预期工作,并找到可能存在的问题。为了简化测试人员手动编写断言代码的工作量,TestDataLake提供了常见的断言模板示例,进一步提升了测试的效率和准确性。
日常工作中,产品运营人员及测试人员查询数据成本很高,常用业务数据查询正是为了解决这个痛点。基于建立的业务数据池,可方便用户快速查询和使用常用的业务数据。该功能模块支持自定义查询条件,并提供多种查询方式和结果展示方式,以帮助用户更快地查找和使用数据。
数据源管理可方便地连接和管理各种数据源,例如数据库、API等。数据字典维护可帮助用户建立业务字典库和通用数据字典库,灵活地扩展业务字典,并根据需要添加新的数据字典,并对不同类型的数据进行分类和归档。数据字典支持定期更新,以确保测试数据的时效性和准确性。
3.2 数据智能生成
数据智能生成是可视化数据池平台核心的功能。它将复杂的测试数据准备工作简化为可视化的过程。可以轻松地从不同的数据字典中抽取字段,灵活设定数据之间的依赖关系,并组合成所需的测试数据。这样,用户可以避免繁琐的手工编写测试数据工作,同时也可以提高测试数据的质量和准确性。数据智能生成模块还可以根据预设的规则自动化生成大量数据来模拟用户请求,为接口遍历测试、接口压力测试等系统提供数据,减轻了测试数据准备工作量,从而便于对系统的稳定性和性能进行验证。整体业务流程如图2所示。
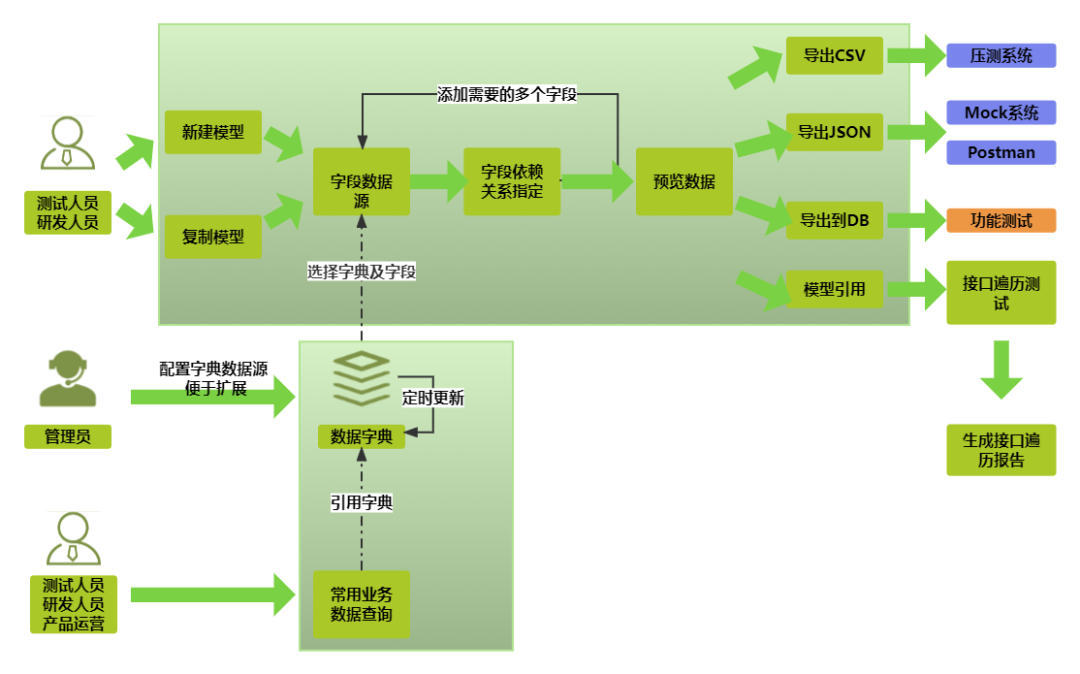
图2 TestDataLake业务流程图
下面来介绍一下数据智能生成的流程。只需点击新增,填写易于理解的名称和用途即可创建指定环境的数据模型。在创建好的数据模型中,您可以轻松指定要生成的字段信息以满足不同场景下的需求。该工具支持使用频率较高的业务字典,如品牌车系车型城市经销商和顾问等,让您快速生成符合要求的测试数据。例如生成一份包含车系ID、车型名称、店铺ID和店铺名称的测试数据,其中店铺和车系字段存在依赖关系,只需要3分钟即可完成。

图3 数据模型字段信息映射
通过智能化的依赖关系设计,省去了以往人工造测试数据时关联自断的复杂工作量。
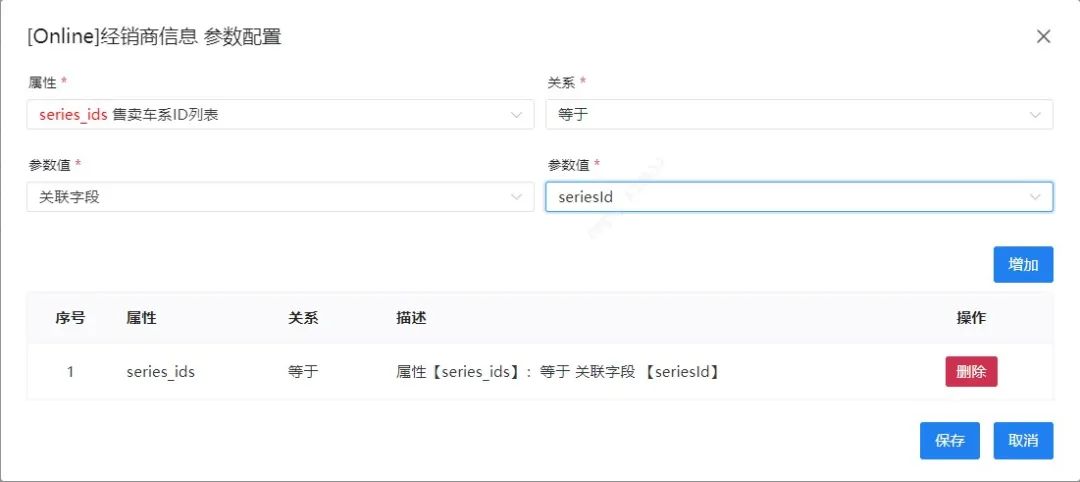
图4 数据模型字段依赖关系维护
配置好所需要的字段信息后,您可以通过预览功能实时生成少量数据来确认这些数据是否符合预期。确认数据无误后,就可以生成大量测试数据,并将数据导出为Excel格式,方便您在接口压力测试、接口遍历测试及其它系统中进行导入和使用。
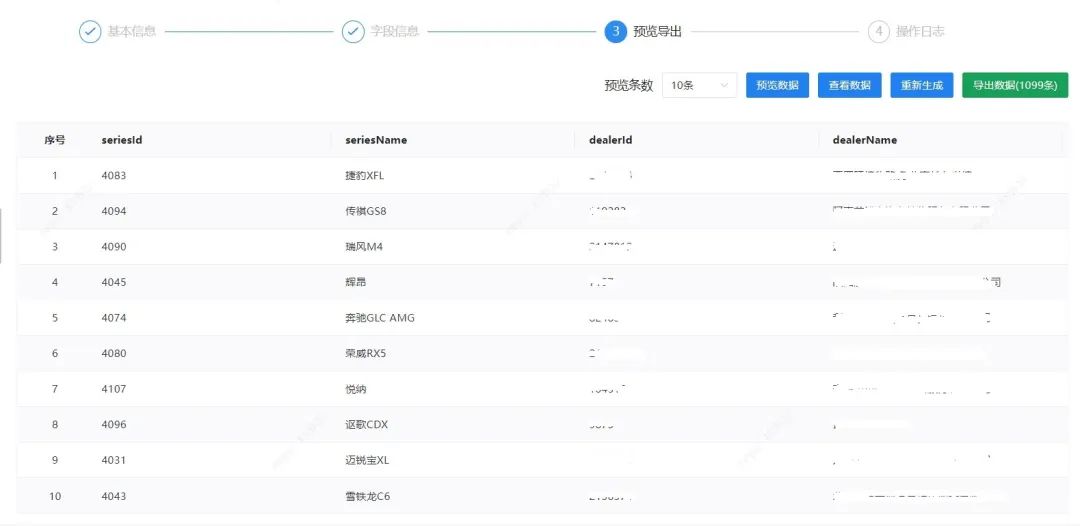
图5 数据模型生成数据预览
3.3 接口遍历测试
拥有了更多更真实的测试数据,TestDataLake在智能数据生成的基础上,帮助测试团队轻松实现接口遍历测试。为了保证接口遍历测试的效果,需要覆盖到所有的场景,测试人员必须准备大量的测试用例和脚本,这是一项繁琐且耗费时间的任务。TestDataLake将智能数据生成的数据作为接口遍历的数据源,帮助测试团队更好的管理测试数据,并提升接口遍历测试的效率和准确性。当我们将前面生成的数据模型作为接口测试的数据源时,系统支持属性名智能提示,从而方便将接口输入参数与模型中的属性名对应。可以轻松的完成输入参数的赋值工作。
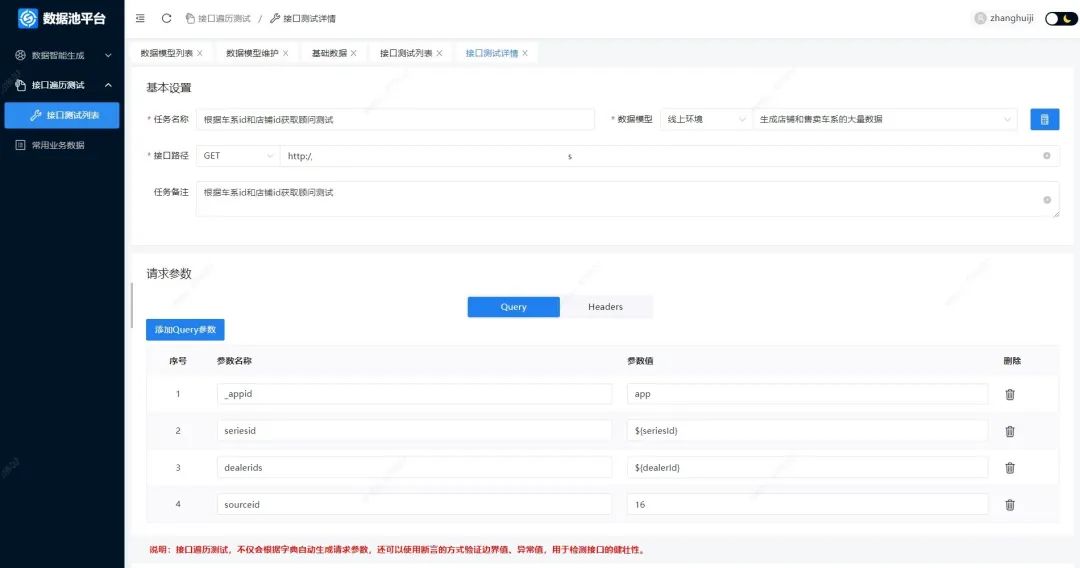
图 6 接口遍历任务维护界面
在接口遍历测试中,断言是非常关键的一步。系统提供了常见的断言模板,测试人员可以根据实际情况进行修改和定制,简化了测试人员手动编写断言代码的工作量。
系统还提供了一个直观明了的接口遍历测试报告,直观的柱状图清晰地展示出结果的分布情况,如成功率失败率,还提供了详细的测试结果列表,测试人员可以查看每个用例的执行状态,请求和响应信息等,帮助测试和研发人员快速定位问题并及时解决,提高测试效率和质量。
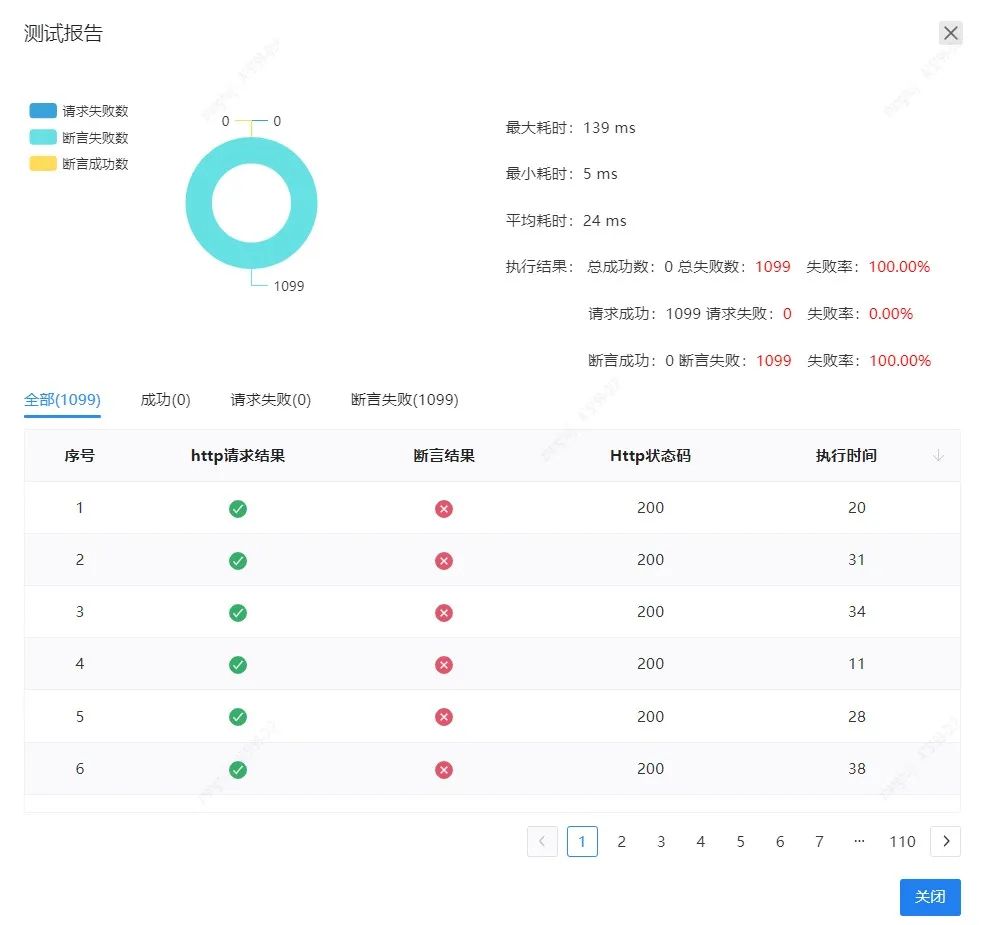
图7 接口遍历测试报告
4.应用效果和收益
TestDataLake以数据为核心的解决方案,可以帮助测试人员管理和维护测试数据,提高测试效率和质量。根据不同的测试需求,可以快速地生成符合实际场景的测试数据,避免了手动编写测试数据的繁琐工作,提高了测试效率和节约了测试成本。以往测试人员准备1次性能测试所需要的数据,大约需要1小时,甚至半天时间,如今只需要几分钟就可以实现,效率提升10余倍。接口遍历测试以往由于接口数量庞大,需要花费很多时间和精力准备测试数据和脚本,才能完成遍历测试。这需要测试人员具备一定的编程技能和经验。苦于门槛和成本比较高,一直无法广泛使用。TestDataLake在智能数据生成的基础上,帮助测试团队轻松实现全面覆盖的接口遍历测试,对于保证产品质量和用户满意度非常重要。
5.后续规划
TestDataLake已经在接口压力测试和接口遍历测试方面,有效地提高了测试效率和质量。然而对于一些复杂的业务流程需要定制,比如,在C端生成订单数据,并在B端跟踪的整体复杂流程。目前需要根据业务流程编写相关代码。是否可以通过灵活编排实现个性化的数据生成流程,满足不同的测试需求呢?后续我们将重点研究灵活编排业务流程的实现方案,进一步提高测试效率和系统的适用性。
以下是我收集到的比较好的学习教程资源,虽然不是什么很值钱的东西,如果你刚好需要,可以评论区,留言【777】直接拿走就好了


各位想获取资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~