介绍
大型语言模型(llm)作为高能力的人工智能助手,在复杂的推理任务中表现出色,这些任务需要广泛领域的专家知识,包括编程和创意写作等专业领域。它们可以通过直观的聊天界面与人类进行交互,这在公众中得到了迅速而广泛的采用。
 法学硕士的能力是显著的考虑到训练的表面上简单的性质方法。自回归变压器在广泛的自监督数据语料库上进行预训练,然后通过强化学习(Reinforcement Learning with human)等技术与人类的偏好保持一致反馈(RLHF)。虽然训练方法简单,但对计算量的要求很高将法学硕士的发展限制在少数参与者。已经公开发布了预先培训的法学硕士(如BLOOM (Scao et al., 2022)、LLaMa-1 (Touvron et al., 2023)和Falcon (Penedo et al., 2023))与封闭预训练的竞争对手如GPT-3 (Brown et al., 2020)和Chinchilla的表现相当(Hoffmann et al., 2022),但这些模型都不适合替代封闭的“产品”法学模型,如如ChatGPT, BARD和Claude。这些封闭的产品法学硕士经过大量微调,以与人类保持一致,这大大提高了它们的可用性和安全性。这一步可能需要大的成本计算和人工注释,并且通常不透明或不易再现,限制了内部的进度推动人工智能校准研究。
法学硕士的能力是显著的考虑到训练的表面上简单的性质方法。自回归变压器在广泛的自监督数据语料库上进行预训练,然后通过强化学习(Reinforcement Learning with human)等技术与人类的偏好保持一致反馈(RLHF)。虽然训练方法简单,但对计算量的要求很高将法学硕士的发展限制在少数参与者。已经公开发布了预先培训的法学硕士(如BLOOM (Scao et al., 2022)、LLaMa-1 (Touvron et al., 2023)和Falcon (Penedo et al., 2023))与封闭预训练的竞争对手如GPT-3 (Brown et al., 2020)和Chinchilla的表现相当(Hoffmann et al., 2022),但这些模型都不适合替代封闭的“产品”法学模型,如如ChatGPT, BARD和Claude。这些封闭的产品法学硕士经过大量微调,以与人类保持一致,这大大提高了它们的可用性和安全性。这一步可能需要大的成本计算和人工注释,并且通常不透明或不易再现,限制了内部的进度推动人工智能校准研究。
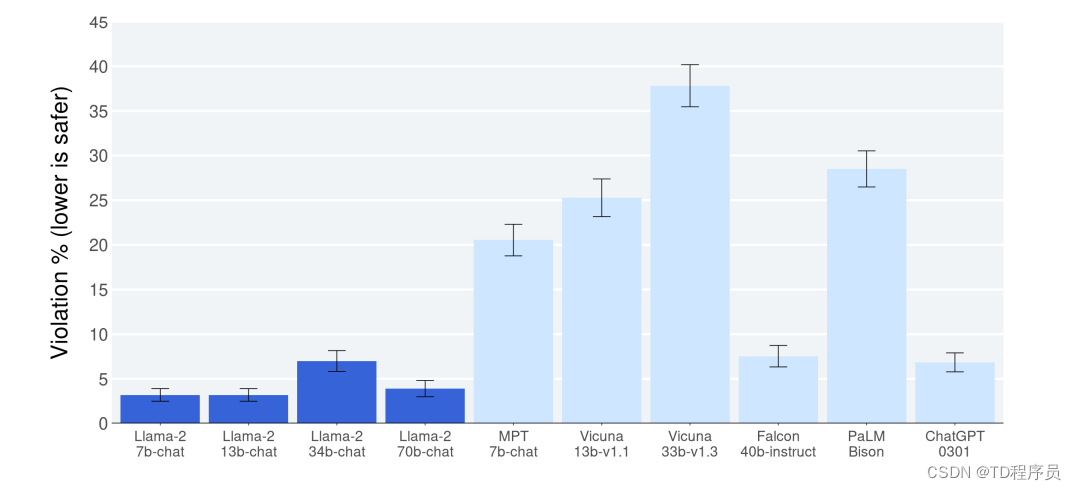
与其他开源和闭源模型相比,Llama 2-Chat的安全性人类评估结果。人类评判员判断了大约2000个对抗性模型的安全违规行为提示包括单轮和多轮提示。更多细节可以在4.4节中找到。它是重要的是要注意这些安全性结果与LLM评估的固有偏差,由于局限性提示集,主观性的