目录
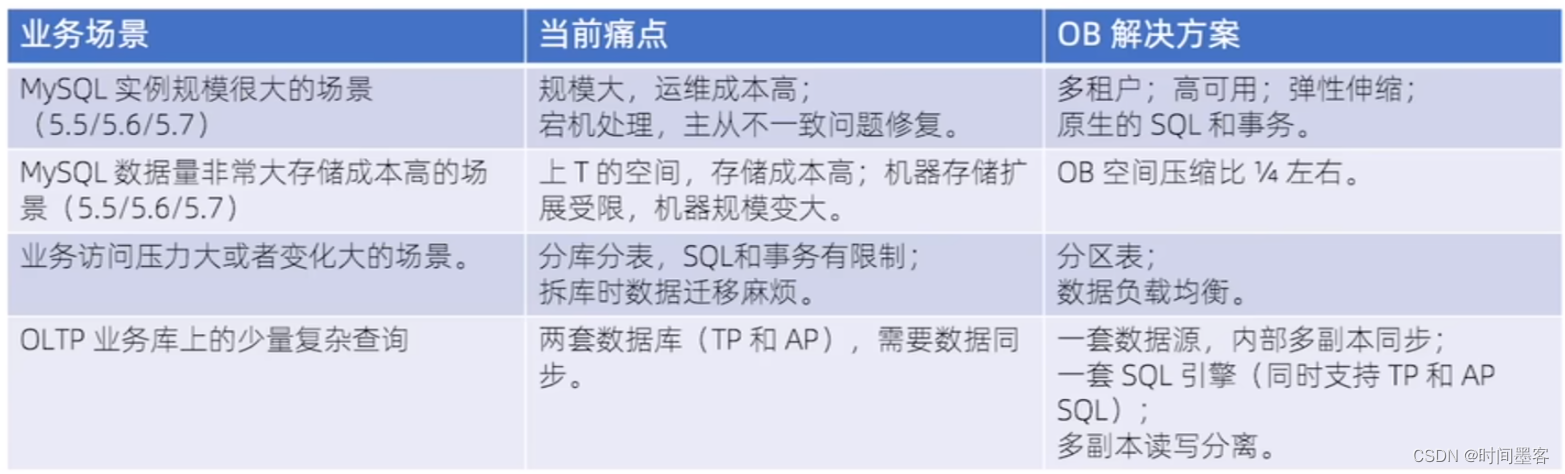
OB业务场景
公司使用理由:
常见 bootstrap 失败原因
常见OBD 部署 失败原因
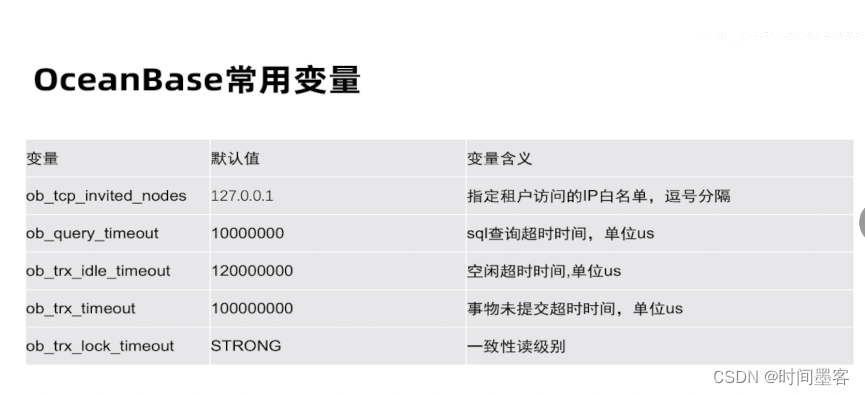
Grafana
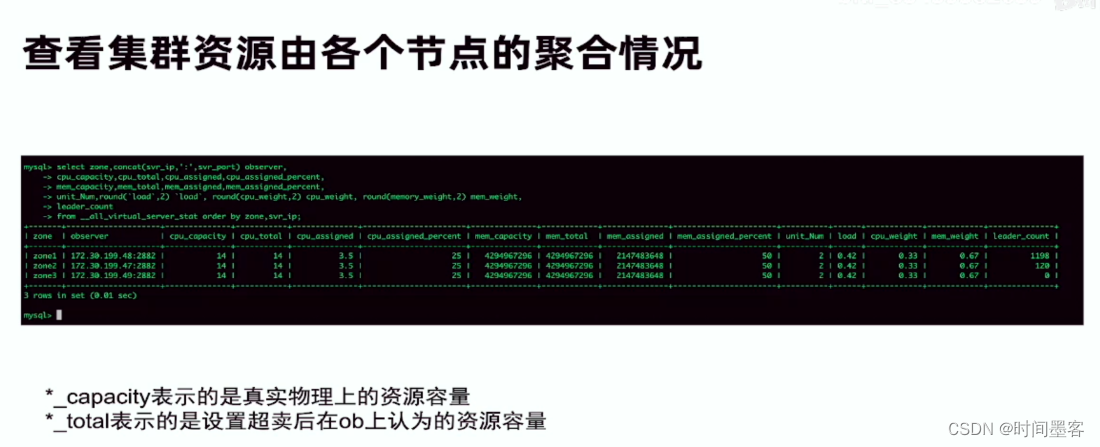
查看集群资源由各个节点的聚合情况
OB创建租户
表分组的场景
mysqldump到处数据库schema,数据库数据,表数据
数据同步框架 DATAX
obdumper使用注意事项
obdumper调优
obloader使用注意事项
什么是CDC
OMS 是什么
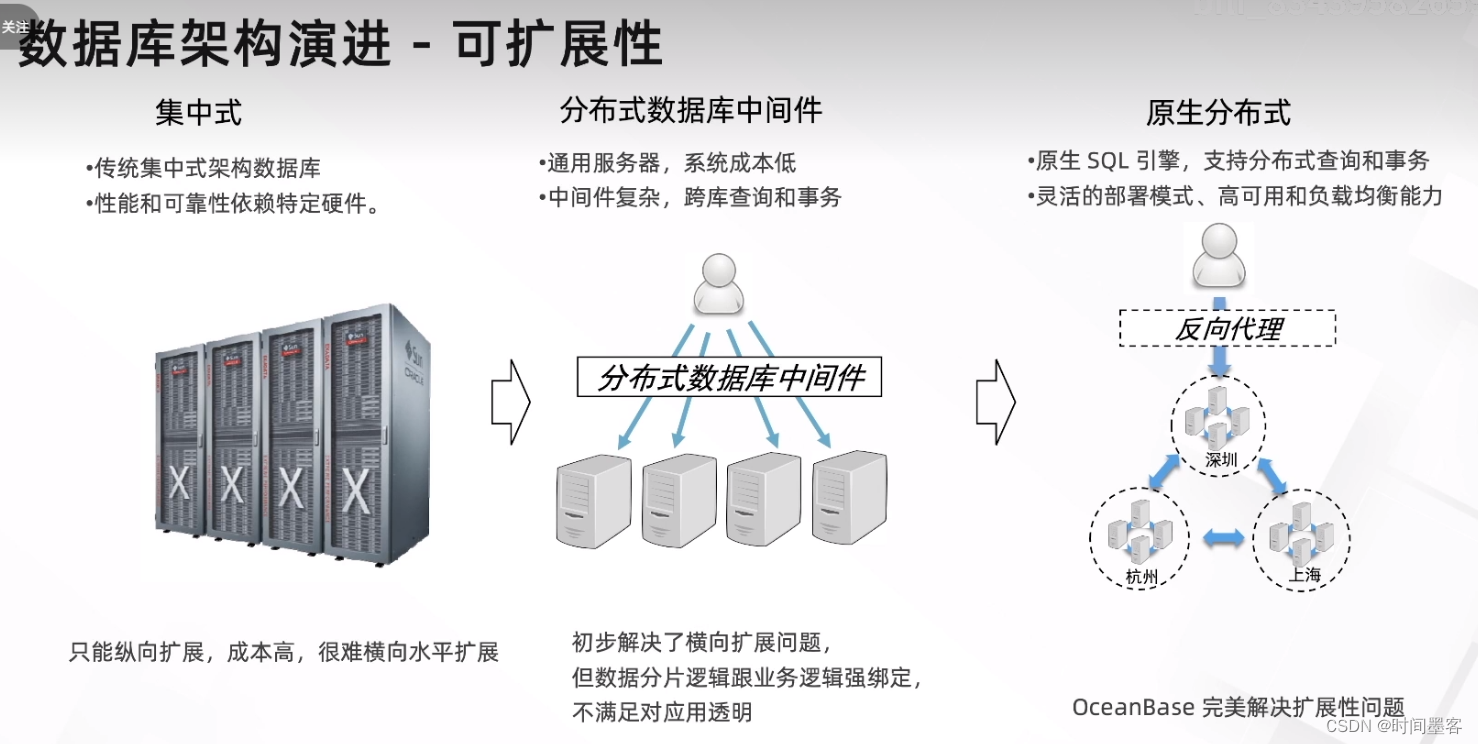
编辑 数据库架构演进
编辑 OceanBase 租户隔离原理
OceanBase 租户扩缩容场景
OB的UNIT均衡
备份步骤
恢复的步骤-3
恢复的步骤-4
恢复的步骤-5
OB内存结构
OB内存监控-使用情况
查看内存使用情况--SQL
编辑 OB内存调优:
离线升级
升级注意事项
Benchmark工具介绍
客户端工具优化
常见误区
Sysbench 测试步骤创建测试租户obd cluster tenant create 3-proxy
Sysbench 常用参数说明
Sysbench 测试FAQ
TPC-H测试FAQ
SQL执行流程
模块职责
SQL执行计划获取过程编辑
[G]V$SQL_AUDIT
[G]V$SQL_AUDIT重要字段含义说明
使用示例: [G]V$SQL_AUDIT
查看集群SQL请求流量是否均衡
获取业务模型
查看所有SQL中消耗CPU最多的SQL
分析RT突然抖动的SQL
SQL语句调优
计划绑定(Outline)
什么是HINT?
Outline生效
超时管理
OceanBase容灾:
同城三机房
三地五中心五副本
OB数据库产品家族
OB业务场景
公司使用理由:
1.新创改造,国家支持,全国产
2.成本低,负载均衡,
3.数据可靠性和服务可用性高,PAXOS分布式一致性协议(分布式数据库基本上都这协议)服务恢复时间(RTO)30秒内
4.数据节点和计算节点均可以在MPP架构下实现水平扩展没有数量限制(传统数据到一定量时插入数据变慢:1000万条数据 小于1小时,3000万条数据大于3小时)
加入OB:2020年

常见 bootstrap 失败原因
1.集群里observer节点之间网络延时超过200ms (建议在30ms以内)。
2.集群里observer 节点之间时间同步误差超过100ms (建议在5ms以内)。
3.主机ulimit 会话限制没有修改或生效
4.主机内核参数sysctlconf没有修改或生效
5.observer 启动用户不对,建议 admin 用户
6.observer启动目录不对,必须是~/oceanbase 。具体版本号会有变化
7.observer的可用内存低于8G。
8.observer的事务日志目录可用空间低于5%
9.observer 启动参数不对 (zone名称对不上,rootservice list 地址或格式不对,集群名不统一等)。
常见OBD 部署 失败原因
集群里observer 节点之间网络延时超过 200ms (建议在30ms以内)。
集群里 observer 节点之间时间同步误差超过 100ms (建议在5ms以内)。
主机ulimit会话限制没有修改或生效
主机内核参数 sysctl.conf 没有修改或生效
observer 启动用户不对,建议 admin 用户
·observer 启动目录不对,必须是~/eboroxy-3.2.0。具体版本号会有变化。
observer 的可用内存低于 8G。
observer 的事务日志目录可用空间不足 5%
observer 启动参数不对(zone名称对不上,rotservice list 地址格式不对,集群名不统一等)目录不为空 通常是第一次运行失败导致,此时清空所有相关目录(软件工作目录、数据文件目录、事务日志目录)即可
Grafana
nohup bin/grafana-server &
https://grafana.com/grafana/dashboards/15215
https://grafana.com/grafana/dashboards/15216
查看集群资源由各个节点的聚合情况
OB创建租户

查看集群资源由各个节点的聚合情况


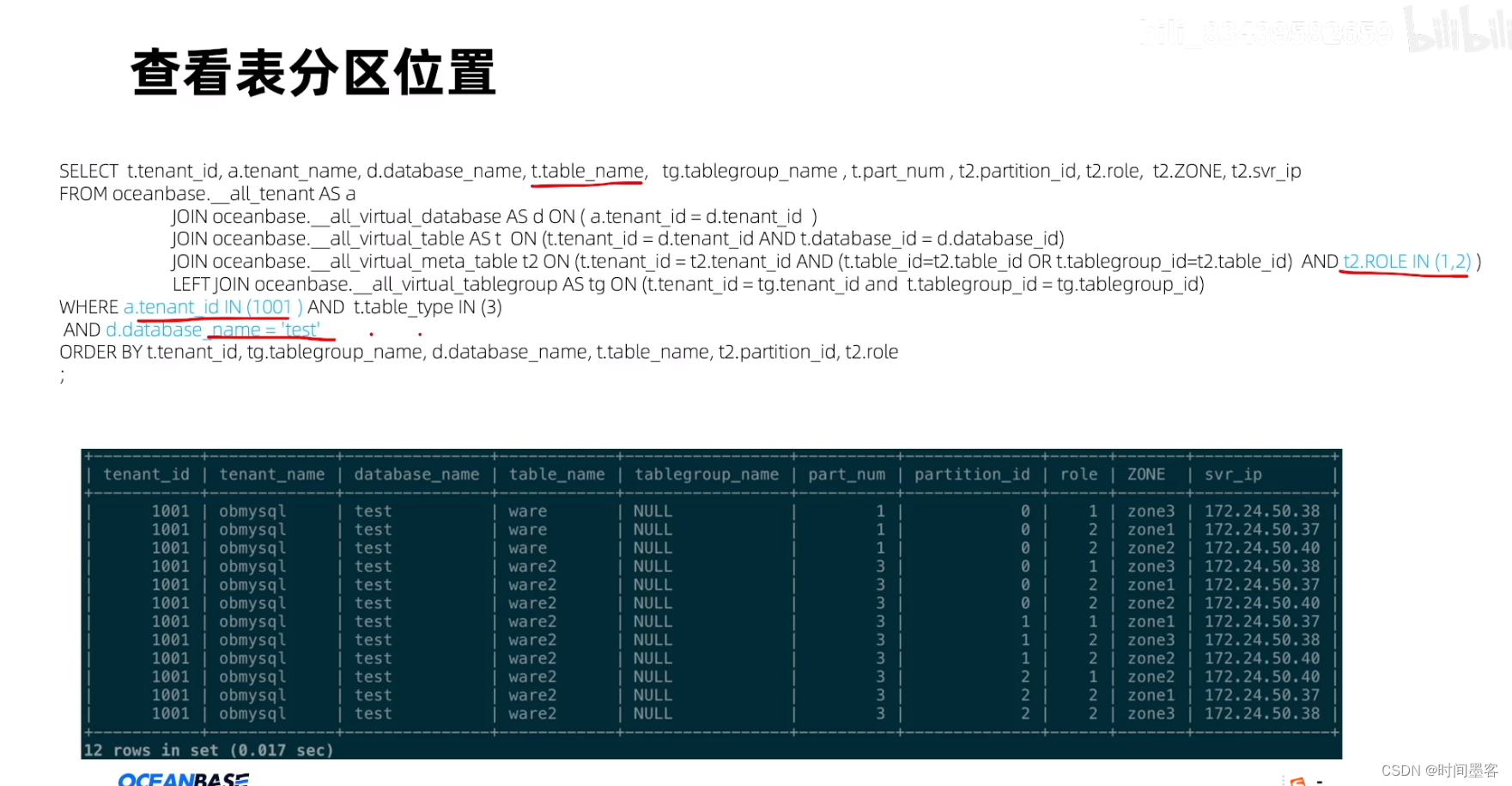
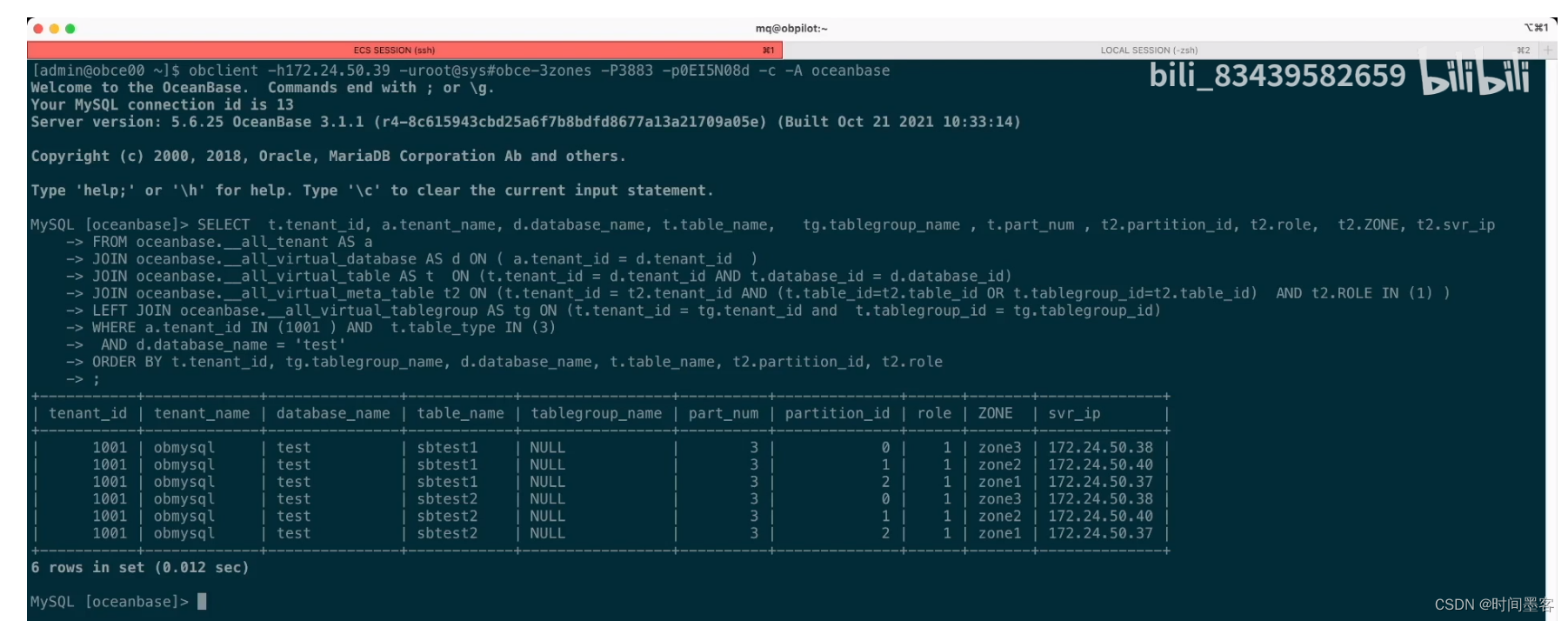
表分组的场景
业务表能按同一个业务属性做水平拆分能规避分布式事务。
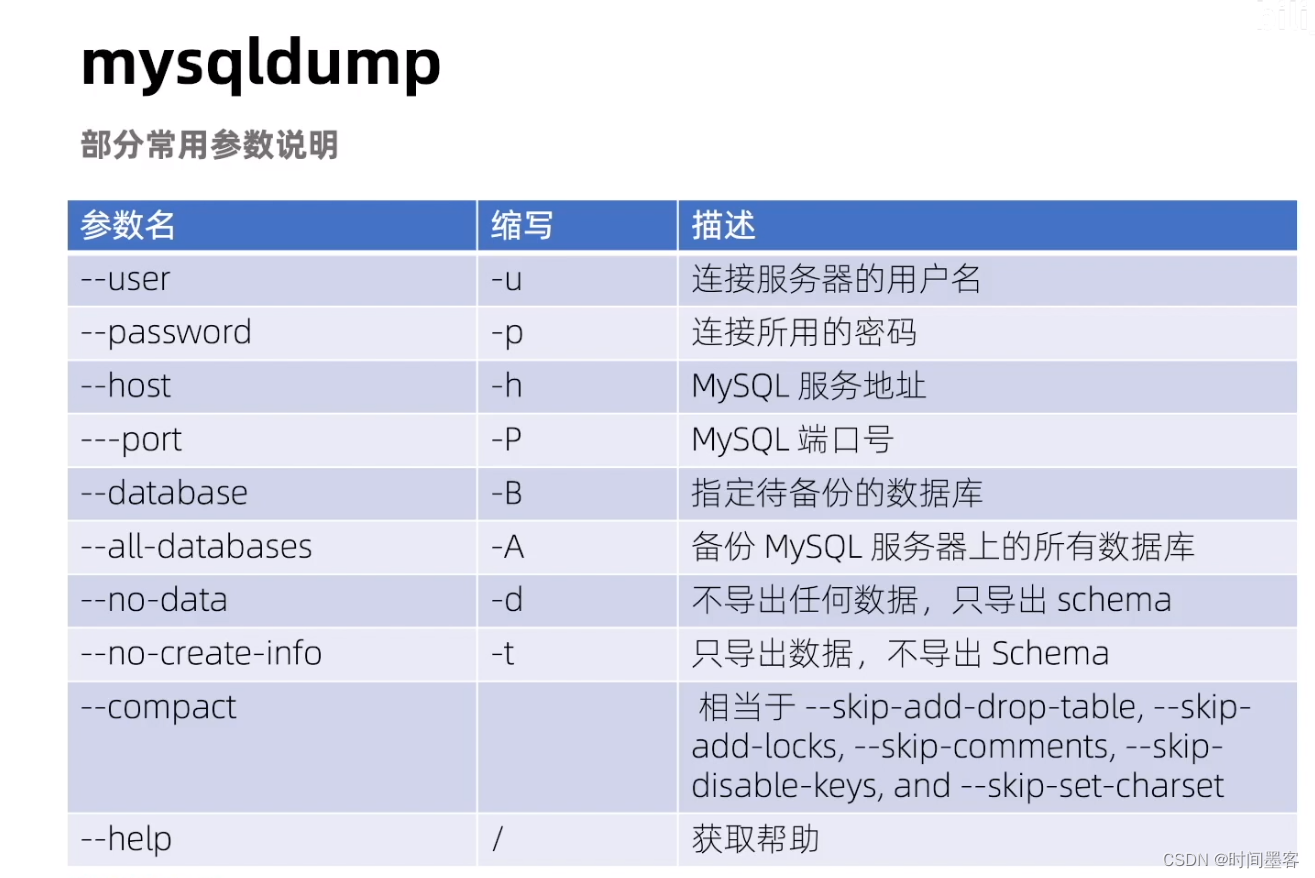
mysqldump到处数据库schema,数据库数据,表数据
导出整个数据库Schema,不包括数据导出整个数据库数据,不包括表结构
mysqldump -u admin -p -t migration > migrate_full_data.sql导出一个表Schema,不包括数据
mysqldump -u admin -p -d migration migrate_table --compact > migrate_table_ddl.sql导出一个表数据,不包括表Schema
mysqldump -u admin -p -t migration migrate_table > migrate_table_data.sql数据同步框架 DATAX
优势
可靠的数据质量监控:支持强数据类型转换、作业全链路流量和数据量实时监控、脏数据探测。
丰富的数据转换:支持数据脱敏、补全、过滤等转换功能。
精准的速度控制:支持通道(并发)记录流和字节流三种流控模式。
强劲的同步性能:支持多种切分策略,任务切分为多个task,单机多线程执行模型
健壮的容错机制:支持线程级别、作业级别多层次局部/全部重试。
极简的使用体验:易用(解压缩即可用)、详细(日志打印传输速度、性能、CPU、JVM、GC等信息)


Canal同步注意事项
同步的表必须有主键
无主键表 delete 和update 同步会有问题
支持 ddl同步
支持新建表、新增列、删除表等,
不支持后期新增主键、修改主键、修改列的类型
待反馈补充。
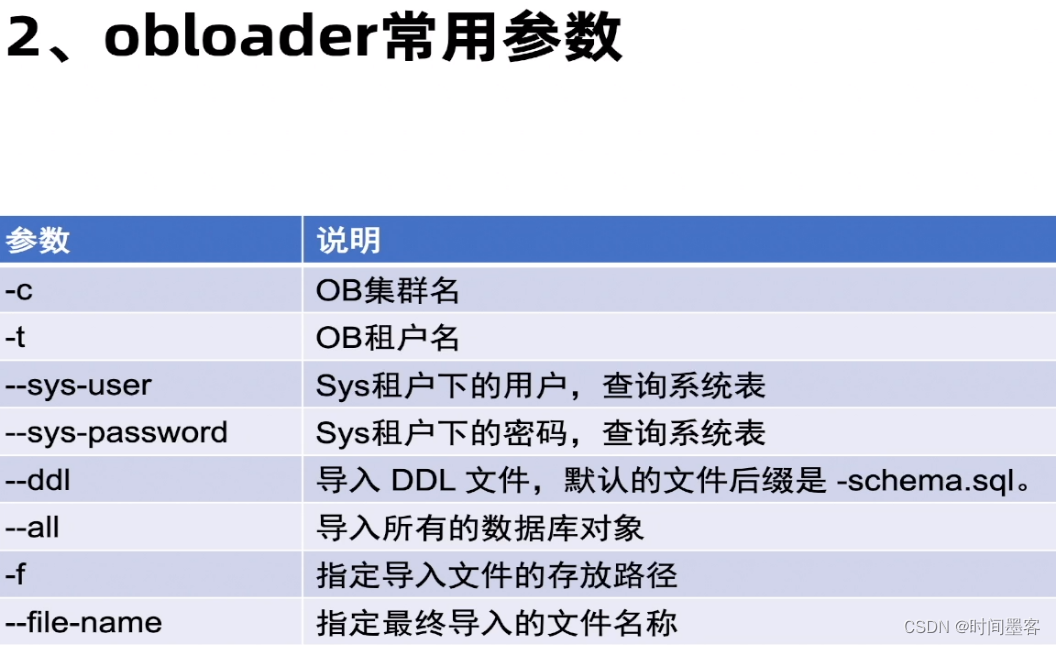
obdumper使用注意事项
执行obdumper的机器上需要安装idk1.8且设置JAVA HOME环境变量。
导出时候-f指定的目录必须先提前创建,并授权可以读写。
导出的时候-f指定的目录不能是非空的。
导出的时候-u指定的用户须有导出对象的select权限。
--sys-user和--sys-password指定的是sys租户下的用户,可以使用root用户或者proxyro帐密
--file-name须与--table 参数搭配使用,指定多个表的时候这里的--file-name无效。
数据量大,导出时间长,执行期间发生了转储,中途会报错如”error: Request to read too oldversioned data”需要将undo retention变量调大一些
obdumper调优
1、命令行配置项调优
--thread
--page-size
2、iava内存调优
50 JAVA OPTS="$JAVA OPTS -server -Xms4G -Xmx4GXX:MetaspaceSize=512M -XX:MaxMetaspaceSize=512M-Xss352K”
3、OB转储
在导出数据的时候,可以先手动执行一下转储的操作。
obloader使用注意事项
执行obloader的机器上需要安装idk1.8且设置JAVA HOME环境变量
导入数据前,库需要提前创建,不会在导入期间自动创建库。
导入使用的用户需要有对应读写的权限。
导入的时候目录需要选择正确。
数据库中存在有外键的表时,无法保证结构和数据按照依赖顺序导入,可能会导入失败
什么是CDC
CDC: change data capture,数据变更捕获,核心思想就是监测并捕获数据库的变动(包括数据表的插入更新,删除,修改等),将这些变更按发生的顺序完整记录下来,写入到目标数据库或消息中间件中来供其他服务进行订阅及消费。
https://en.wikipedia.org/wiki/Change data capture
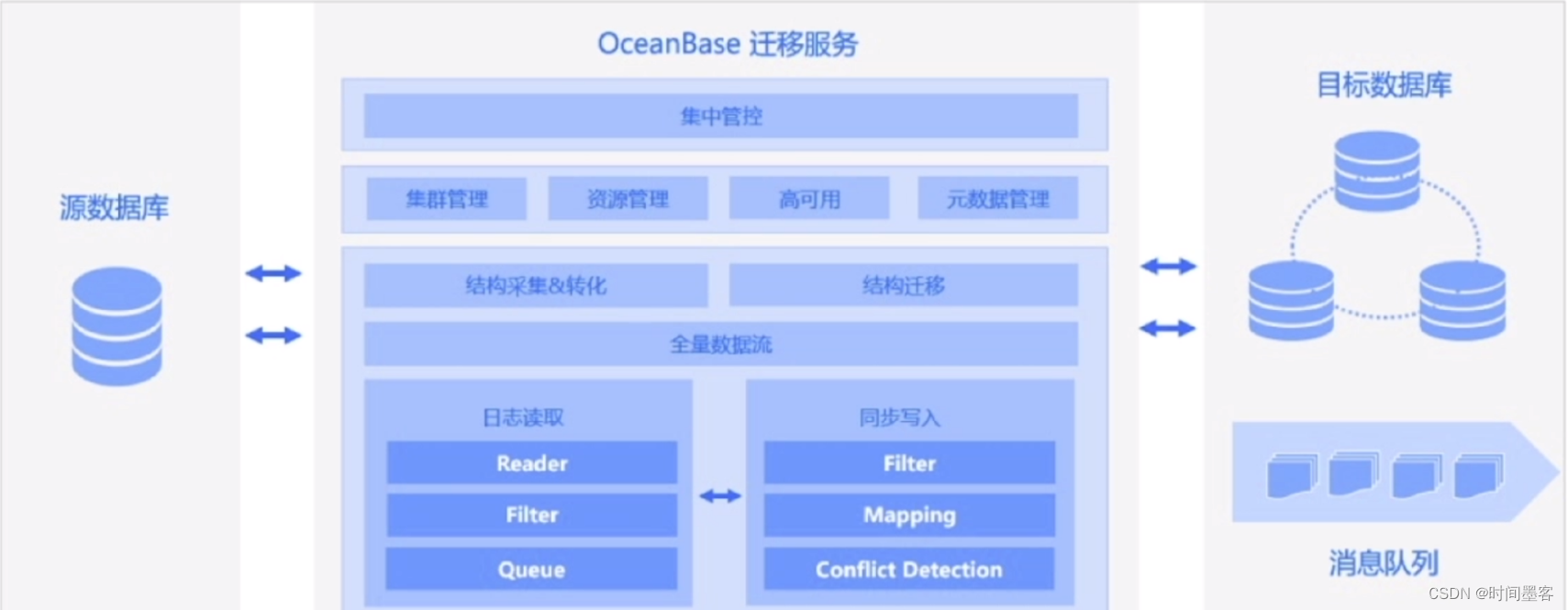
OMS 是什么
OceanBase数据迁移服务(OceanBase Migration Service,简称0MS)是OceanBase提供的一站式数据传输产品。它支持多种关系型数据库、大数据(OLAP)及消息队列等数据终端与0ceanBase之间的数据复制,是一种集数据迁移、实时数据同步和增量数据订阅于一体的数据传输服务。

OMS产品架构
 数据库架构演进
数据库架构演进
 OceanBase 租户隔离原理
OceanBase 租户隔离原理
Docker 或虚拟机隔离主要有以下几个问题
虚拟机运行环境的开销太重,OceanBase数据库需要支持轻量级租户
虚拟机迁移开销比较大,OceanBase 数据库希望租户的规格变化和迁移尽量快
虚拟机不便于租户间的资源共享,例如,对象池的共享
虚拟机资源隔离很难定制,例如,租户内的优先级支持
虚拟机的实现不便于暴露统一视图
为了确保租户间不出现资源争抢保障业务稳定运行,OceanBase设计了更加轻量的租户隔离
OceanBase 把Unit 当作给租户分配资源的基本单位,一个Unit 可以类比于一个 Docker容器。个0BServer 上可以创建多个Unit,在0BServer上每创建一个Unit都会占用一部分该0BServer的CPU、内存等物理资源
OBServer 的资源分配情况会记录在内部表中以便 DBA:
SELECT*FROM all virtual server stat
一个租户可以在多个0BServer上放置多个Unit,但一个特定的租户在某个0BServer 上只能有一个Unit资源隔离,就是0BServer 控制本地多个Unit 间的资源分配的行为,它是0BServer 本地的行为OceanBase 数据库并没有依赖 Docker 或虚拟机技术,而是在数据库内部实现资源隔离。
OceanBase 租户扩缩容场景
租户新增副本
OceanBase 集群通常三个ZONE 分布在同城三个机房,租户数据有三份简称三副本当要建设异地容灾机房的时候,可能会选择从三个ZONE 扩容到五个ZONE(即五副本)
1.新增zone
alter system add zone 'ZONE4'alter system add zone'ZONE5'2.给新增的ZONE添加节点
alter system add server'11166.87.5:2882' zone 'zone4'alter system add server'11.16687.6:2882' zone 'zone5'3.为租户在新增节点上分配资源池
create resource pool test_pool_z4 unit='unit_test' , unit_num=1, zone_list=('ZONE_4')create resource pool test_pool_z5 unit='unit_test' , unit_num=1, zone_list=('ZONE_5')4.给租户增加新增的资源池
alter tenant a resource_pool_list=('test_pool_z1','test_pool_z2','test_pool_z3','test_pool_z4');
alter tenant a resource_pool_list=('test_pool_z1','test_pool_z2','test_pool_z3','test_pool_z4','test_pool_z5');OB的UNIT均衡
UNIT均衡资源单元(Unit)是 多租户架构分布式架构下的重要概念。RS 模块需要对资源单元进管理,并通过把资源单元在多个 0BServer 间调度,对系统资源进行有效利用,RS对资源单元的管理包括:
资源单元的分配,即新建一个资源单元时,RS需要决定这个 Unit 分配到哪个 OBServer 上
资源单元的均衡,即在系统运行过程中,RS 根据 Unit 的资源规格等信息对 Unit 进行再平衡的一个调度过程
CPU单一资源的均衡示例
示例背景:假设存在两个OBServer:OBS0(10个CPU)和OBS1(10个CPU)。其中OBSO 上6个Unit每个Unit 的贷源规格为1个CPU;OBS1上包含4个Unit,每个 Unit 的资源规格为1个 CPU。
均衡目标:
通过在 OBServer 间迁移 Unit,使得各 OBServer 的 CPU 占用率尽可能接近
均衡过程:
从该示例场景可以看到OBS0的CPU 占用率为(6/10)*100%= 60%BS1的CPU 占用率为(4/10)* 100%=40%
两个OBServer 的 CPU 占用率差值为 0.2,将OBSO上的-Unt 移到 OBS1上 后的 OBSO BS1的 CPU 占用率都为 5 /10)*100%=50%,与迁移Unit前相比,两个OBServer 的资源占用率更平均。
多种资源均衡算法
即为参与分配和均衡的每种资源分配一个权重,作为计算OBServer 总的资源占用率时该资源所占的百分比某种资源使用的越多,则该资源的权重就越高。
案例:某集群中总的 CPU 资源为 50个CPU,Unit 共用20个CPU则CU 总的占用率为0%。该集群中总的 Memory 资源为1000 GB,Unit 共占用 Memory 资源100 GB,则 Memory 占用率为10%,集群中没有其他资源参与均衡,归一化后,CPU和 Memory 资源的权重分配为 80% 和 20%,各0BServer 根据该权重计算各自的资源占用率然后再通过迁移降低各OBServer 之间的资源占用率差值。

停掉待重建的observer节点的进程
1、直接使用kill -9 'pidof observer'
2、确认observer进程的工作目录

备份步骤
1、设置备份目的端
alter system set backup_dest='file:///data/nfs':
2、(可选)发起一次转储
alter system minor freeze
3、启动日志归档
alter system archivelog;
4、确认日志备份是否已开启
SELECT*FROM CDB_OB_BACKUP_ARCHIVELOG_SUMMARY:当 STATUS 为 DOING 时,表示日志备份任务已开始。
5、发起一次合并操作
alter system major freeze
查看合并进度
SELECT*FROM __all_zone WHERE name='merge status'
6、发起备份任务
alter system backup database;
7看正在备份的任务
SELECT*FROM CDB_OB_BACKUP_PROGRESS
查看备份任务的历史SELECT*FROM CDB_OB_BACKUP_SET_DETAILS
8、增量备份
ALTER SYSTEM BACKUP INCREMENTAL DATABASE
恢复的步骤-3
开启租户恢复参数
参数restore_concurrency 指定了恢复线程的并发数,默认是0,不恢复。需要修改为大于0的值。
通常开启恢复命令后默认还会等待一段时间才开始恢复,整个恢复期间会有三次等待。每次等待时间是由内部参数 _restore_idle_time 设置,默认值是60s 。注意,隐含参数未来版本可能会发生变化。在生产环境不建议去调整这个参数。
测试环境可设置为10s,生成不建议修改
恢复的步骤-4
开始恢复
恢复命令稍微比较复杂,是:
ALTER SYSTEM RESTORE <dest_tenant_name> FROM <source_tenan_tname> at 'uri' UNTIL
'timestamp' WITH 'restore_option';

恢复的步骤-5
查看恢复进度

OB内存结构

多租户共同使用红色部分内存
OB内存监控-使用情况

查看内存使用情况--SQL
select now(),t.tenant_name,m.svr_ip,m.active_memstore_used / 1073741824 active_G,m.total_memstore_used / 1073741824 total_G,m.major_freeze_trigger / 1073741824 trigger_G,m.memstore_limit / 1073741824 imit_G,m.total_memstore_used / m.memstore_limit*100 used_rate from __all_virtual_tenant_memstore_info m,_all_tenant t where t.tenant id = m.tenant id having used_rate >1 order by used_rate;

SELECT tenant_id, svr_ip,sum(hold)/1024/1024/1024 hold_G FROM _all_virtual_memory_info WHERE tenant_id>1000 AND hold<>0 AND mod_name IN('OB_KVSTORE_CACHE','OB_MEMSTORE) GROUP BY tenant_id,svr_ip ORDER BY tenant_id;

日志查看租户内存使用情况
 OB内存调优:
OB内存调优:
合理调整memory_limit_percentage大小
freeze_trigger_percentage 控制了内存转储的时间,应该根据实际的内存大小和业务写入速度调整学会查看__all_virtual_memory_info
离线升级
1、在可以联网的机器上下载需要升级的组件对应的rpm包
2、关闭远程镜像源obd mirror disable remote
3、将第一步中下载好的镜像加入到local中obd mirror clone *.rpm
4、obd cluster upgrade 部署名 -c 组件名 -V 目标版本号
升级注意事项
1、obd的版本需要是1.2.1
2、如果是刚新部署的新集群测试升级,需要先做一次合并操作。
3、一次只能升级一个组件,并且必须指定目标版本
4、升级的时候建议先升级obproxy再升级oceanbase-ce。
5obproxy从3.1.0升级到3.2.0的时候需要在root@proxysys下调整,否则升级后无法登录
alter proxyconfig set skip_proxy_sys_private_check = true;
6、升级的快慢跟集群的规模(并非数据量)和规格有关系
7、如果集群规模是1-1-1,升级前先修改租户的全局变量ob_create_table_strict_mode=0
Benchmark工具介绍
sysbench
介绍说明:
Sysbench 是一个基于 LualIT可编写脚本的多线程基准测试工具,常用于评估测试各种不同系统参数下的数据库负载情况。
特点:测试场景简单、灵活测试各类业务基本性能但无法模拟复杂业务模型
性能指标:RT、TPS、QPS

TPC-H 模拟决策支持类应用的测试集

使用 OBD
无需困于各种 Benchmark 工具安装依赖编译、摆脱繁琐操作步骤
自动根据OceanBase 集群所在环境进行数据库调优包括调优参数下发、schema 适配等等
支持 svsbench、tpch、bmsal等常见的benchamrk 测试
OceanBase 社区
常见Benchmark调优操作

Schema优化
使用分区表
OceanBase的分区表主要有两个作用
分区表的使用可以在特定的SOL操作中减少数据读写的总量以减少响应时间
解决单机处理性能瓶颈,将海量请求分散到不同分区,不同分区主副本可以分散在不同节点
TPCH/bmsal推荐使用,svsbench如果采用分区表,有大量的分布式查询,性能不比非分区表好
使用tablearoup
0ceanBase 数据库会优先把属于同一个Table Group 的相同分区号的分区,调度到同一台节点上,以减少跨节点分布式事务TPCH/bmsal推荐使用,svsbench测试模型都是单表,使用ta没有意义
Sal并发查询
般来说,当并行度提高时,查询的响应时间会缩短,更多的 CPU、10 和内存资源会被用于执行查询命令select /*+ parallel(96)*/
客户端工具优化
客户端并发
调整压测并发数到一个最优的值
Svsbench的threads、bmsal的terminals等
客户端部署
如果想让Benchmark测试获得比较好的预期结果,客户端工具、obproxy、observer不建议共部署

常见误区
使用sys租户进行Benchmark测试
0ceanBase 数据库默认存在一个 sy 租户。sys 租户主要用于存储集群元数据信息,主要用于集群内部管理,运维人员会经常访问使用。sys租户下不建议建表存储数据。
导入数据后不做合并
Major 合并将当前大版本的 SSTable 和 MemTable 与前一个大版本的全量静态数据进行合并,使存储层统计信息更准确,生成的执,行计划更稳定。
MySQL[(none)]> use oceanbase
Database changed
MySQL [oceanbase]> alter system major freeze;
Ouery OK,0 rows affected
没有做预热
所谓的预热也就是cache命中机制,比如执行tpch的select语句,命中执行计划可以执行更快
Sysbench 测试步骤
创建测试租户
obd cluster tenant create 3-proxy
清理数据
./src/sysbench ./src/lua/oltp_point_select.lua --mysql-host=172.30.199.115 --mysql-port=2883--mysql-db=test --mysql-user=root@test --table size=1000000 --tables=30 --threads=150--report-interval=10--time=60 cleanup
准备数据
./src/sysbench ./src/lua/oltp point elect.lua --mysql-host=172.30.199.115 --mysql-port=2883--mysql-db=test --mysql-user=root@test --table size=1000000 --tables=30 --threads=150--report-interval=10--time=60 prepare
测试
/src/sysbench ./src/lua/oltp point select.lua --mysal-host=172.30.199.115 --mysql-port=2883-mysal-db=test --mysa-user=root@test --table size=1000000 --tables=30 --threads=150 --report-interval=10--time=60 --db-ps-mode=disable run
OBD测试
obd test sysbench 3-proxy --sysbench-bin=/data/sysbench-1.0.20/src/sysbench --script-name=/data/sysbench-1.0.20/src/lua/oltp_point-select.lua table size=1000000 --tables=30 --threads=150 --interval=10 --time=60
Sysbench 常用参数说明
--tables: 指定表的数量
--table_size:指定表的数据量。
--threads: 指定并发数
--mysql-ignore-errors : 指定忽略的错误号,忽略后就继续跑。否则,报错就中断
--time: 指定运行时间
--report-interval :报告间隔测试结果:

Sysbench 测试FAQ
drv_mysql.c:35:19: fatal error: mysql.h: No such file or directory
操作系统没有安装 MySQL的 lib 库。运行以下命令安装
yum install mysgl-community-devel.x86 64
TPC-H测试FAQ
导入数据报错。
报错信息:ERROR 1017 (HY000) at line 1: File not exist
数据表要放在 observer 上,不能放在obproxy上
导入数据报错。报错信息:ERROR 1227(42501)at line 1:Access denied
需要授予用户访问权限。运行以下命令,授予权限
!grant file on *.* to tpch_100g_part;
set global secure file priv='';


#!/bin/bash
TPCH_TEST="obclient -h 172.30.199.115 -P 2883 -uroot@test -Dtest -c"
#warmup预热
#for i in [1..22}
#do# sql1="source db${i}.sql"#echo $sql1| $TPCH_TEST >db${i}.log ret=1
#done
#正式执行
format_time=`date +%s%N`
for i in {1..22}
dostarttime=`date +%s%N`echo `date '+[%Y-%m-%d %H:%M:%S]'` "BEGIN Q${i}"sql1="source db${i}.sql"echo $sql1 |$TPCH_TEST >db${i}.log || ret=1stoptime=`date +%s%N`costtime='echo $stoptime $starttime | awk '[printf "0.2f\n", ($1 - $2) / 1000000000)'`echo ` date '+[%Y-%m-%d %H:%M:%S]'` "END,COST $[costtime}s"
done
end_time=`date +%s%N`
totaltime='echo $end_time $format_time | awk '[printf "%0.2f\n", ($1 - $2) /1000000000)'
echo "total cost:$totaltime"obd test tpch 3-proxy --dbgen-bin=/data/TCP-H_Tools_v3.0.0/dbgen --dss-config=/data/TPC-H_Tools_v3.0.0/dbgen/ --r emote-tbl-dir=/home/admin/tpch1 --test-only --disable-transfer
SQL执行流程

模块职责

SQL执行计划获取过程
[G]V$SQL_AUDIT
作用 :记录了每一次SQL请求的来源、执行状态及统计信息
每个机器每个租户分别管理SQL AUDIT记录
淘汰机制
先进先出自动淘汰
触发内存高水位线时淘汰,到内存低水位线停止淘汰
触发900w条记录时触发淘汰,到500w条记录时停止淘汰
开关控制
集群设置: alter system set enable_sql_audit = true/false;
租户设置: set global ob_enable_sql_audit = true/false;
当集群设置和租户设置均为true时才生效
[G]V$SQL_AUDIT重要字段含义说明


使用示例: [G]V$SQL_AUDIT
查看集群SQL请求流量是否均衡
select t2.zone,t1.svr_ip, count(*) as QPS from oceanbase.gv$sql_audit t1,__all_server t2 where t1.svr_ip = t2.svr_ip and t1.tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 1000000)and request_time < time_to_usec(now()) group by t1.svr_ip order by OPS;
获取业务模型
select usec_to_time(request_time), query_sql, elapsed_time from oceanbase.gv$sql_audit where sid = 3221499326
order by request_time;
查看所有SQL中消耗CPU最多的SQL
select sql_id,substr(query_sql,1,20) as query_sql,sum(elapsed_time - queue_time) sum_t, count(*) cnt,avg(get_plan_time), avg(execute_time) from oceanbase.gv$sql_audit where tenant_id=1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now()) group by sqlid order by sum t desc limit 10;
查询某段时间内请求次数排在TOP N的SQL
select SQL_ID,count(*) as QPS,avg(t1.elapsed_time) RT from oceanbase,gv$sql_audit t1 where tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 1080000 and request_time < time_to_usec(now()) group by t1.sql_id order by QPS desc limit 10;
分析RT突然抖动的SQL
1.在线上如果出现RT抖动,可以考虑在抖动出现后,立刻将sql audit关闭,从而确保该抖动的SOL请求在sql audit中存在;然后通过sqlaudit查询抖动附近那段时间RT TOP N的请求,分析有异常的SQL。
2.1如果在sql audit中找到了对应的RT异常请求,则可以分析该请求在sql audit中记录:
查看retry次数是否很多(如果次数很多,则是否考虑是否有锁冲突或切主等情况)
查看queue time是不是很大(QUEUE TIME字段)
查看获取执行计划时间(GET_PLAN_TIME),如果时间很长,一般会伴随IS_HIT_PLAN = 0,表示没有命中计划缓存
查看EXECUTE TIME是否很长,如果很长,则
a.查看是否有很长等待事件耗时
b.查看访问的行数是否很多,看SSSTORE_READ_ROW_COUNT,MEMSTORE_READ_ ROW_COUNT两个字段,比如大小账号场景可能导致rt抖动
c.确定执行计划是否为合理
2.2如果在sql audit中RT抖动的请求数据已淘汰,则需要查看observer中抖动时间点是否有慢查询的trace日志如果有则分析trace日志;
[G]V$PLAN_CACHE_PLAN_STAT
记录每个计划的具体信息及执行统计信息 ,每个plan在该视图中一条记录

[G]V$PLAN_CACHE_PLAN_EXPLAIN
记录一条SQL在计划缓存中的执行计划
查询gv$plan_cache_plan_explain时,需要给定ip,port, tenant_id,plan_id。这几个信息可以在gv$plan_cache_plan_stat或者gv$sqlaudit中查到

查看一条SQL的实际执行计划
select plan_line_id, operator, name, rows, cost from oceanbase.gv$plan_cache_plan_explain where ip ="100.83.51.133"
and port = 30042
and tenant_id = 1001
and plan id = 248;
SQL语句调优
根据SQL执行计划分析SQL的性能瓶颈
执行计划中具体那些步骤执行时间特别慢
充分利用已有的脚本和工具来简化分析过程
优化性能瓶颈点
创建合适的索引,调整连接算法(比较简单 )
调整连接顺序( 难度比较大 )
检查OB是否做了错误的查询改写/缺少合适的查询改写机制( 难度比较大)
开启并行执行等机制(比较简单)
计划绑定(Outline)
什么是HINT?
是一种机制,通过HINT,可以指定优化器的行为,控制SQL执行计划:
explain basic
select * from tl, t2 where t1.c3 = t2.c3;
explain basic
select /*+ use_nl(t1, t2) */ * from tl, t2
where t1.c3 = t2.c3; 
作用:应用可以不需要修改SQL,通过数据库创建outline,可控制执行计划:
创建outline
CREATE OUTLINE otl_idx_c2 ON '5F5BE712CB1A4533654E442C13F81D27' USING HINT /*+ index(t1 idx_c2)*/;
Outline生效

超时管理
jdbc超时
socketTimeout: 蚂蚁内部为5s
connectTimeout: 连接超时参数
observer超时
ob_query_timeout: SQL执行超时10sSQL没有执行完成,则超时
ob_trx_timeout: 事务超时
wait_timeout:空闲超时
tcp参数
keepalive 参数
NO_DELAY参数
OceanBase容灾:
同城三机房
同城3个机房组成一个集群(每个机房是一个Zone),机房间延迟一般在0.5 ~ 2ms之间
机房级灾难时,剩余的两份副本依然是多数派,依然可以同步Redo-Log日志,保证RPO=0
但无法应对城市级的灾难

三地五中心五副本
三个城市,组成一个5副本的集群
任何一个IDC或者城市的故障,依然构成多数派,可以确保RPO=0
由于3份以上副本才能构成多数派,但每个城市最多只有2份副本,为降低时延,城市1和城市2应该离得较近,以降低同步Redo-Log的时延
为降低成本,城市3可以只部署日志型副本(只有日志)

OB数据库产品家族

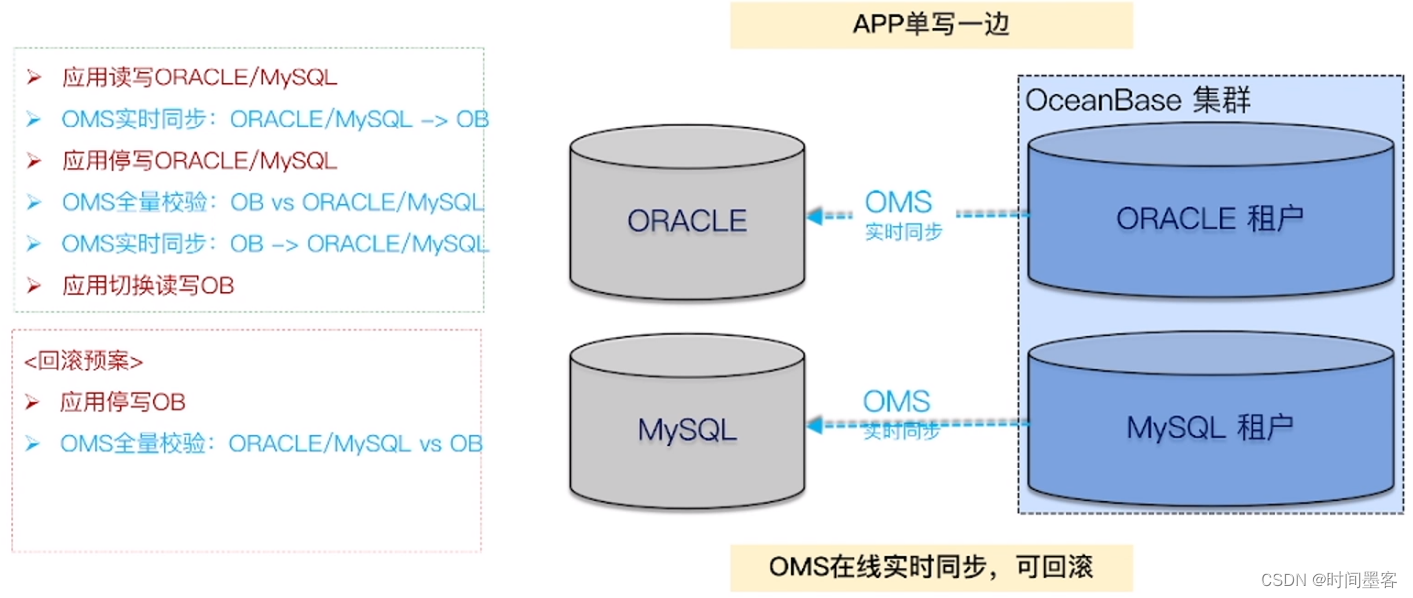
利用OMS实现平滑去O迁移方案: 数据实时同步 + 快速切换+回滚预案
清华图书库查看:http://www.tup.com.cn/