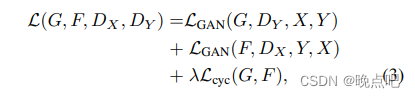文章目录
- 前言
- 一、优化和深度学习
- 1.1 优化的目标
- 1.2 深度学习中的优化挑战
- 1.2.1 局部最小值
- 1.2.2 鞍点
- 1.2.3 梯度消失
- 二、梯度下降
- 2.1 一维梯度下降
- 2.1.1 学习率
- 2.2 多元梯度下降
- 2.3 自适应方法
- 2.3.1 牛顿法
- 2.3.2 其他自适应方法
- 三、随机梯度下降
- 3.1 随机梯度更新
- 3.2 动态学习率
- 四、小批量随机梯度下降
- 五、动量法
- 六、AdaGrad--自适应学习率
- 七、Adam
- 总结
- 附录--参考资料
前言
本章我们主要讲解一下深度学习中的一些优化算法。
一、优化和深度学习
1.1 优化的目标
优化和深度学习的目标是根本不同的。前者主要关注的是最小化目标,后者则关注在给定有限数据量的情况下寻找合适的模型。
例如,训练误差和泛化误差通常不同:由于优化算法的目标函数通常是基于训练数据集的损失函数,因此优化的目标是减少训练误差。但是,深度学习(或更广义地说,统计推断)的目标是减少泛化误差。为了实现后者,除了使用优化算法来减少训练误差之外,我们还需要注意过拟合。
1.2 深度学习中的优化挑战
1.2.1 局部最小值
随着目标函数中的参数不断的迭代,目标函数的值可能陷入一个矩阵最小值,导致找不到目标函数的全局最小值。
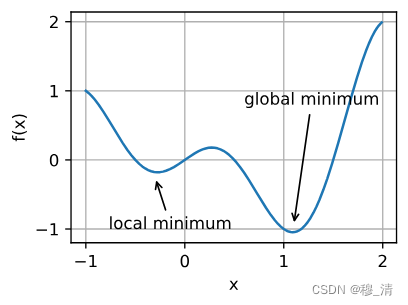
在这种情况下,小批量上梯度的自然变化能够将参数从局部极小值中跳出。
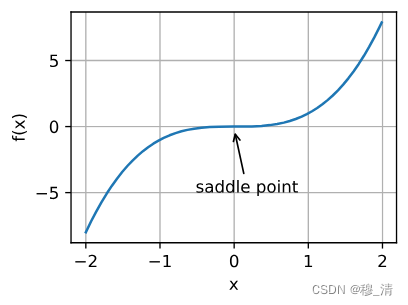
1.2.2 鞍点
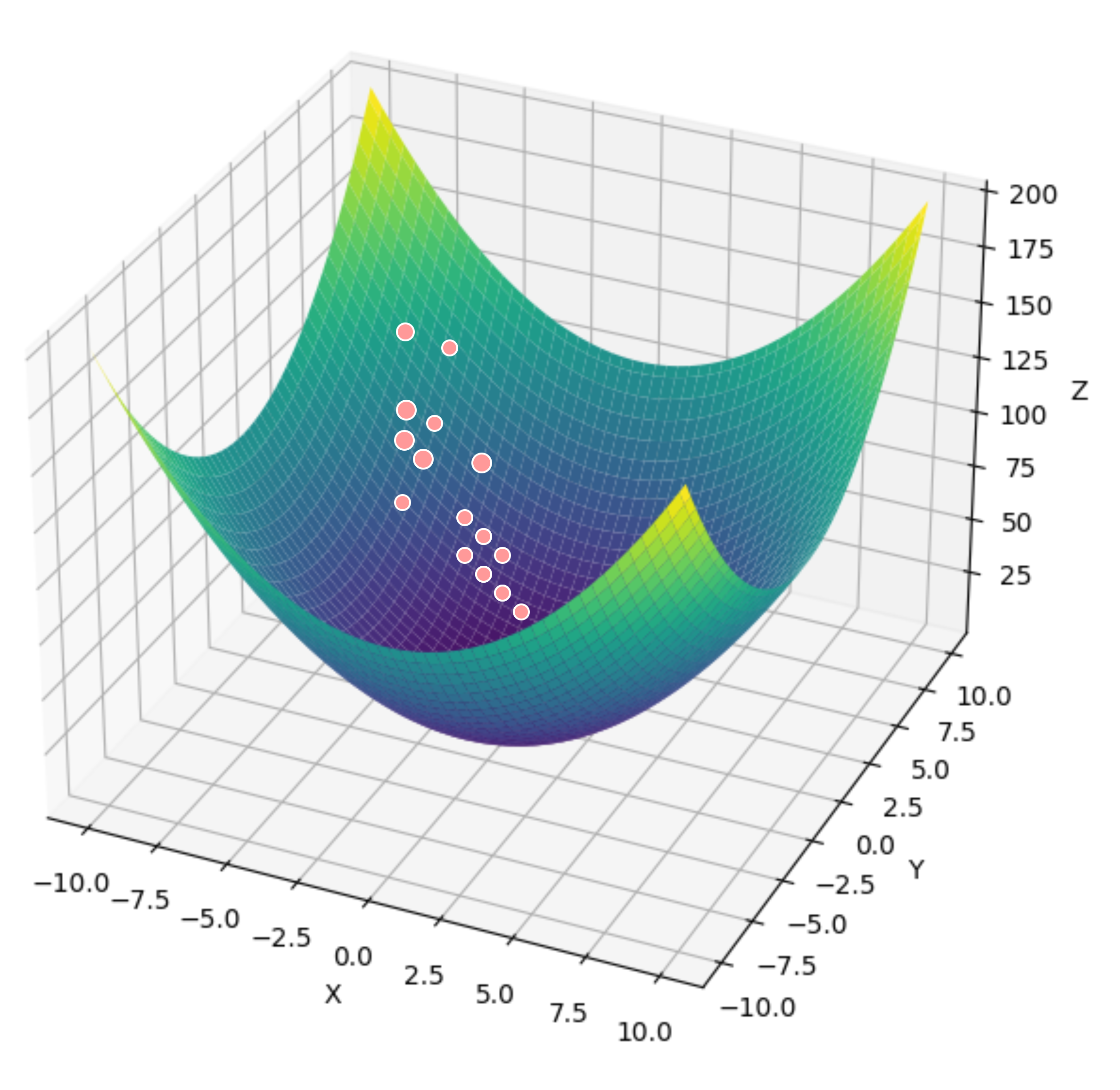
除了局部最小值之外,鞍点是梯度消失的另一个原因。鞍点(saddle point)是指函数的所有梯度都消失但既不是全局最小值也不是局部最小值的任何位置。
在二维情况下:
在三维情况下:
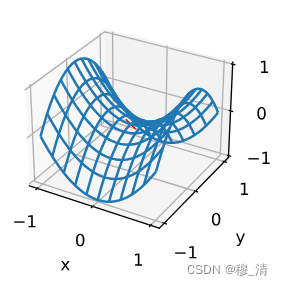
可以看到中间那个点是x方向的最小值,是y方向的最大值。
对于多维函数来说,判断一个该点是否是局部最小值、局部最大值还是鞍点。通常是通过海森矩阵的正定性来进行判断的。
一个多元函数的二阶泰勒展开式为:
f ( x ) = f ( a ) + ∑ i = 1 n f x i ( a ) ( x i − a i ) + 1 2 ∑ i = 1 n ∑ j = 1 n ( x i − a i ) ( x j − a j ) f x i x j ( a ) ] f(\mathbf{x}) = f(\mathbf{a}) + \sum_{i=1}^{n} f_{x_i}(\mathbf{a})(x_i - a_i) + \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} (x_i - a_i)(x_j - a_j) f_{x_i x_j}(\mathbf{a}) ] f(x)=f(a)+i=1∑nfxi(a)(xi−ai)+21i=1∑nj=1∑n(xi−ai)(xj−aj)fxixj(a)]
改写成矩阵形式:
f ( x ) = f ( a ) + ( x − a ) T ▽ f ( a ) + 1 2 ( x − a ) T H ( x − a ) f(\mathbf{x}) = f(\mathbf{a}) + (\mathbf{x} - \mathbf{a})^T \bigtriangledown f(\mathbf{a}) + \frac{1}{2} (\mathbf{x} - \mathbf{a})^T \mathbf{H} (\mathbf{x} - \mathbf{a}) f(x)=f(a)+(x−a)T▽f(a)+21(x−a)TH(x−a)
其中H被称为海森矩阵。由于需要判断的点肯定是每个分量上的导数为0,所以上式可改写为:
f ( x ) = f ( a ) + 1 2 ( x − a ) T H ( x − a ) f(\mathbf{x}) = f(\mathbf{a}) + \frac{1}{2} (\mathbf{x} - \mathbf{a})^T \mathbf{H} (\mathbf{x} - \mathbf{a}) f(x)=f(a)+21(x−a)TH(x−a)
所以H的正定性决定了该点是什么样的点:
-
当函数在零梯度位置处的Hessian矩阵的特征值全部为正值时,我们有该函数的局部最小值;
-
当函数在零梯度位置处的Hessian矩阵的特征值全部为负值时,我们有该函数的局部最大值;
-
当函数在零梯度位置处的Hessian矩阵的特征值为负值和正值时,我们有该函数的一个鞍点。
对于高维度问题,至少部分特征值为负的可能性相当高。这使得鞍点比局部最小值更有可能出现。
1.2.3 梯度消失
可能遇到的最隐蔽问题是梯度消失。导致梯度消失的一个经典原因就是激活函数的选择问题。例如tanh激活函数在两端的梯度接近于哦,导致优化将会停滞很长一段时间。
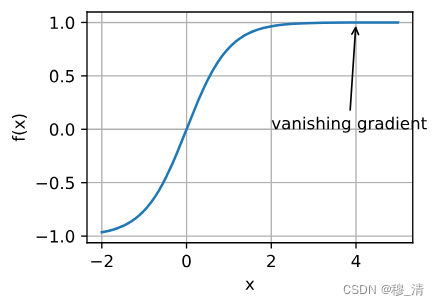
正如我们所看到的那样,深度学习的优化充满挑战。幸运的是,有一系列强大的算法表现良好,即使对于初学者也很容易使用。此外,没有必要找到最优解。局部最优解或其近似解仍然非常有用。
二、梯度下降
2.1 一维梯度下降
为什么梯度下降算法可以优化目标函数呢?我们可以先从一维梯度下降中观察。
首先一元函数在x点处的泰勒展开式为:
f ( x + ϵ ) = f ( x ) + ϵ f ′ ( x ) + O ( ϵ 2 ) . f(x + \epsilon) = f(x) + \epsilon f'(x) + \mathcal{O}(\epsilon^2). f(x+ϵ)=f(x)+ϵf′(x)+O(ϵ2).
假设我们已知往负梯度方向可以减少f的值(这个可以去看梯度的推导),我们选择固定步长 η > 0 \eta > 0 η>0,然后取 ϵ = − η f ′ ( x ) \epsilon = -\eta f'(x) ϵ=−ηf′(x)。可得泰勒展开式: f ( x − η f ′ ( x ) ) = f ( x ) − η f ′ 2 ( x ) + O ( η 2 f ′ 2 ( x ) ) . f(x - \eta f'(x)) = f(x) - \eta f'^2(x) + \mathcal{O}(\eta^2 f'^2(x)). f(x−ηf′(x))=f(x)−ηf′2(x)+O(η2f′2(x)).
我们总可以找到足够小的 η \eta η使得高阶项变得无关,因此 f ( x − η f ′ ( x ) ) ⪅ f ( x ) . f(x - \eta f'(x)) \lessapprox f(x). f(x−ηf′(x))⪅f(x).
这时,我们使用 x ← x − η f ′ ( x ) x \leftarrow x - \eta f'(x) x←x−ηf′(x)来进行迭代x就能让f的值越来越小。
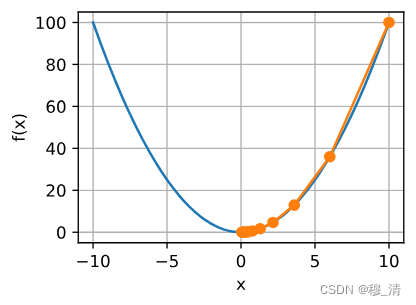
2.1.1 学习率
学习率(learning rate)决定目标函数能否收敛到局部最小值,以及何时收敛到最小值。这个学习率 η \eta η可由我们自己设定。
- 如果设置过小,将导致x的更新非常慢,需要多次迭代。
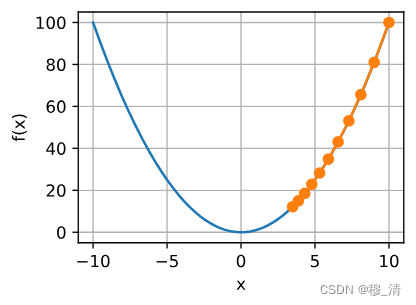
- 如果设置的过大,泰勒展开式的高阶项可能会变大,导致函数的结果不来回波动,或者陷入局部最小值。
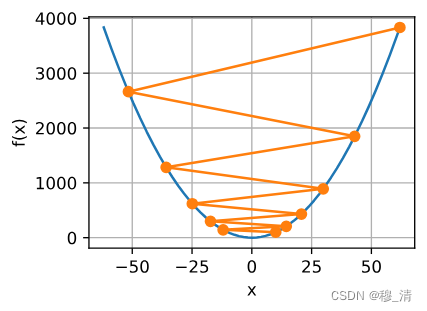
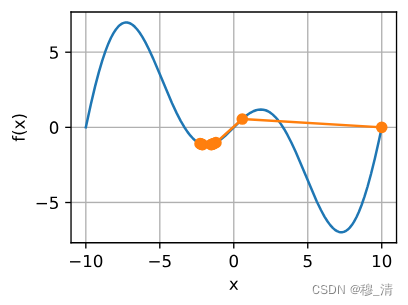
2.2 多元梯度下降
对于多元函数来说,它的在 x = [ x 1 , x 2 , … , x d ] ⊤ \mathbf{x} = [x_1, x_2, \ldots, x_d]^\top x=[x1,x2,…,xd]⊤的泰勒展开可以写为:
f ( x + ϵ ) = f ( x ) + ϵ ⊤ ∇ f ( x ) + O ( ∥ ϵ ∥ 2 ) . f(\mathbf{x} + \boldsymbol{\epsilon}) = f(\mathbf{x}) + \mathbf{\boldsymbol{\epsilon}}^\top \nabla f(\mathbf{x}) + \mathcal{O}(\|\boldsymbol{\epsilon}\|^2). f(x+ϵ)=f(x)+ϵ⊤∇f(x)+O(∥ϵ∥2).
其中梯度为: ∇ f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x d ] ⊤ . \nabla f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_d}\bigg]^\top. ∇f(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xd∂f(x)]⊤.
我们同样可以使用 x ← x − η ∇ f ( x ) . \mathbf{x} \leftarrow \mathbf{x} - \eta \nabla f(\mathbf{x}). x←x−η∇f(x).来进行迭代。
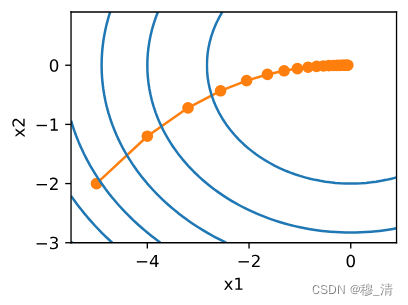
等高图观察如下:
2.3 自适应方法
选择“恰到好处”的学习率 η \eta η是很棘手的。 如果我们把它选得太小,就没有什么进展;如果太大,得到的解就会振荡,甚至可能发散。
因此,我们可以考虑目标函数的值以及梯度和曲率的二阶方法,帮助我们自适应这个学习率。
2.3.1 牛顿法
一个多元函数f在x点 ϵ \epsilon ϵ领域内的泰勒展开:
f ( x + ϵ ) = f ( x ) + ϵ ⊤ ∇ f ( x ) + 1 2 ϵ ⊤ ∇ 2 f ( x ) ϵ + O ( ∥ ϵ ∥ 3 ) . f(\mathbf{x} + \boldsymbol{\epsilon}) = f(\mathbf{x}) + \boldsymbol{\epsilon}^\top \nabla f(\mathbf{x}) + \frac{1}{2} \boldsymbol{\epsilon}^\top \nabla^2 f(\mathbf{x}) \boldsymbol{\epsilon} + \mathcal{O}(\|\boldsymbol{\epsilon}\|^3). f(x+ϵ)=f(x)+ϵ⊤∇f(x)+21ϵ⊤∇2f(x)ϵ+O(∥ϵ∥3).
我们令 H = d e f ∇ 2 f ( x ) \mathbf{H} \stackrel{\mathrm{def}}{=} \nabla^2 f(\mathbf{x}) H=def∇2f(x),其中 H \mathbf{H} H也被称为海森矩阵或者黑塞矩阵。
为了使得函数在这个领域内最小,我们需要令f的梯度为0,两边对 ϵ \epsilon ϵ求导,并忽略掉高阶项,得:
∇ f ( x ) + H ϵ = 0 and hence ϵ = − H − 1 ∇ f ( x ) . \nabla f(\mathbf{x}) + \mathbf{H} \boldsymbol{\epsilon} = 0 \text{ and hence } \boldsymbol{\epsilon} = -\mathbf{H}^{-1} \nabla f(\mathbf{x}). ∇f(x)+Hϵ=0 and hence ϵ=−H−1∇f(x).
所以我们迭代的时候直接令
x ← x − H − 1 ∇ f ( x ) x \leftarrow x -\mathbf{H}^{-1} \nabla f(\mathbf{x}) x←x−H−1∇f(x)
但是我们需要注意一下,如果二阶导数为负值,即逼近曲线开头向下,f的值可能会增加。这是这个算法的致命缺陷!
这发生了惊人的错误。我们怎样才能修正它? 一种方法是用取Hessian的绝对值来修正,另一个策略是重新引入学习率。 这似乎违背了初衷,但不完全是——拥有二阶信息可以使我们在曲率较大时保持谨慎,而在目标函数较平坦时则采用较大的学习率。
2.3.2 其他自适应方法
比如预处理、线搜索等。
三、随机梯度下降
3.1 随机梯度更新
在深度学习中,目标函数通常是训练数据集中每个样本的损失函数的平均值。给定n个样本的训练数据集,我们假设 f i ( x ) f_i(\mathbf{x}) fi(x)是关于索 i i i
的训练样本的损失函数,其中 x \mathbf{x} x是参数向量。然后我们得到目标函数:
f ( x ) = 1 n ∑ i = 1 n f i ( x ) . f(\mathbf{x}) = \frac{1}{n} \sum_{i = 1}^n f_i(\mathbf{x}). f(x)=n1i=1∑nfi(x).
可以看出反向传播的计算代价随着n线性增长,因此,当训练数据集较大时,反向传播代价高。
为了解决上述问题,我们提出了随机梯度下降(SGD)(注:我们常常把小批量梯度下降算法也称为SGD)。
随机梯度下降算法,不再计算完所有样本的损失函数再反向传播进行迭代了,而是随机抽取所有样本中的一个样本计算损失并反向传播更新参数。
3.2 动态学习率
在随机梯度下降中,对学习率敏感,因此,我们可以采用动态调节学习率的方式改变学习率。以下是根据时间动态调整学习率的策略:
η ( t ) = η i if t i ≤ t ≤ t i + 1 分段常数 η ( t ) = η 0 ⋅ e − λ t 指数衰减 η ( t ) = η 0 ⋅ ( β t + 1 ) − α 多项式衰减 \begin{split}\begin{aligned} \eta(t) & = \eta_i \text{ if } t_i \leq t \leq t_{i+1} && \text{分段常数} \\ \eta(t) & = \eta_0 \cdot e^{-\lambda t} && \text{指数衰减} \\ \eta(t) & = \eta_0 \cdot (\beta t + 1)^{-\alpha} && \text{多项式衰减} \end{aligned}\end{split} η(t)η(t)η(t)=ηi if ti≤t≤ti+1=η0⋅e−λt=η0⋅(βt+1)−α分段常数指数衰减多项式衰减
四、小批量随机梯度下降
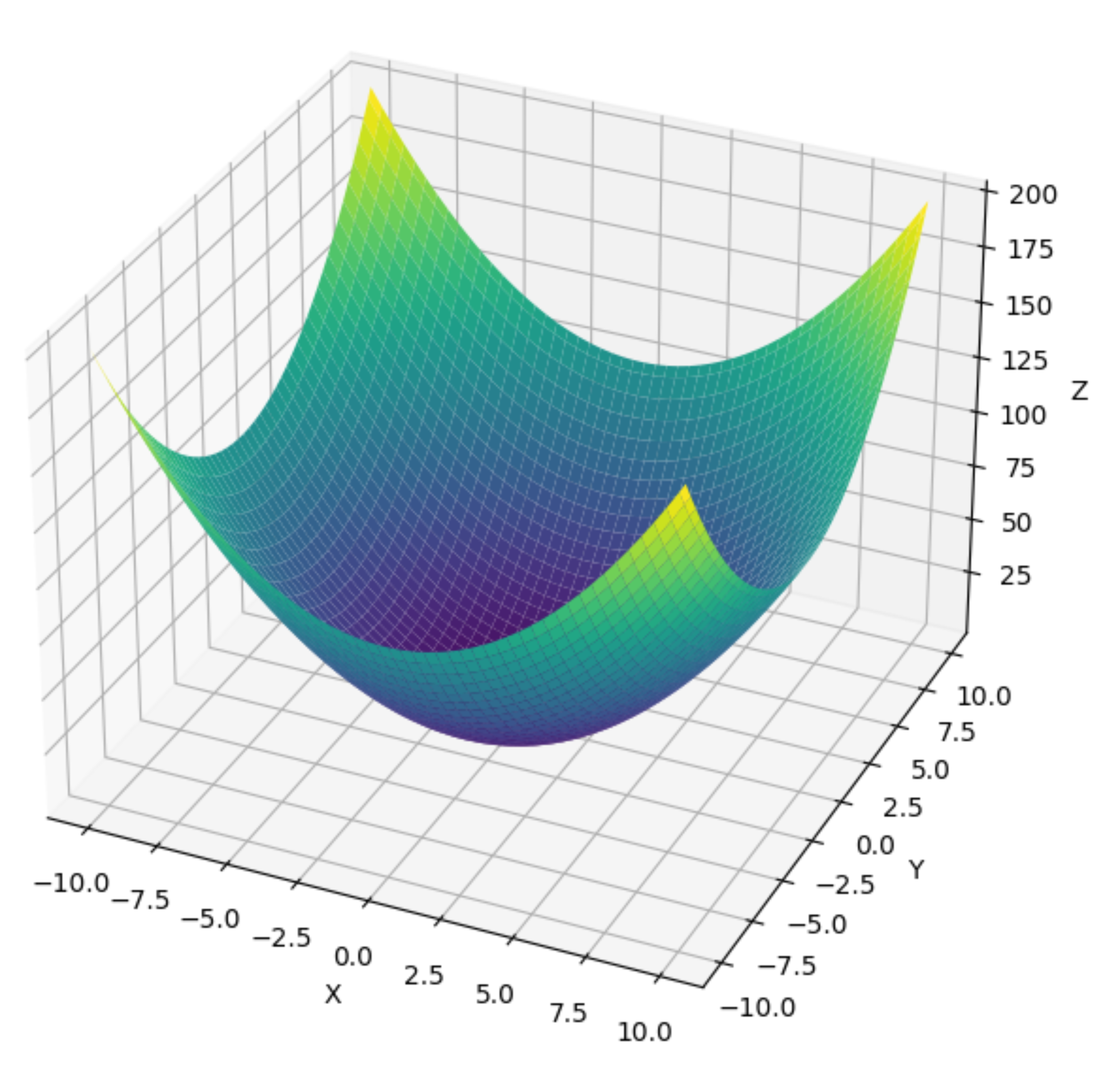
随机梯度下降使用完整数据集来计算梯度并更新参数, 随机梯度下降算法一次处理一个训练样本来取得进展。 二者各有利弊:每当数据非常相似时,梯度下降并不是非常“数据高效”。 而由于CPU和GPU无法充分利用向量化,随机梯度下降并不特别“计算高效”。 这暗示了两者之间可能有折中方案,这便涉及到小批量随机梯度下降(minibatch gradient descent)。
加入损失函数的最终全貌图像如下:
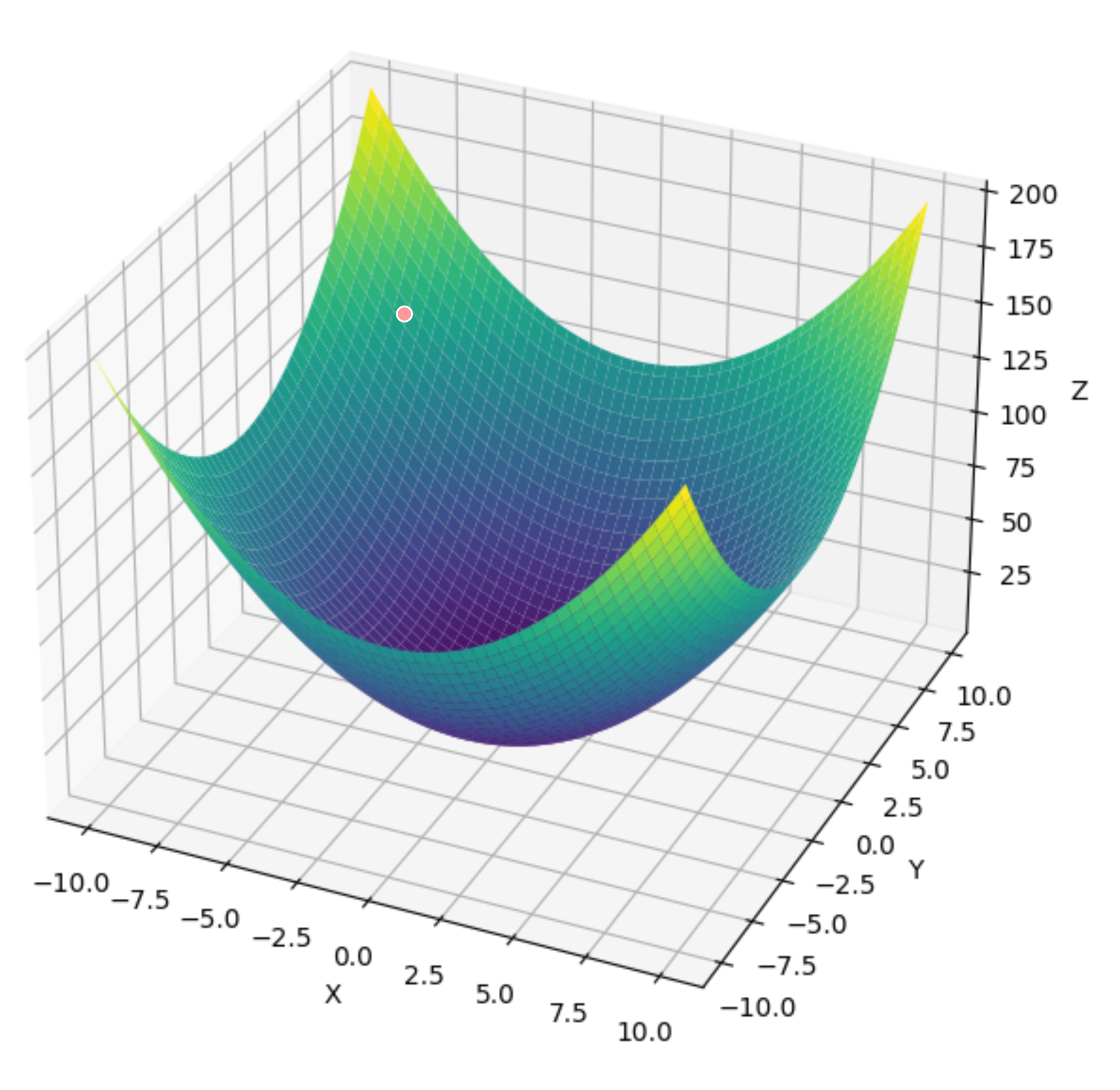
假设我们当前参数所在位置在红点:
如果我们考虑了所有样本的损失函数的梯度变化情况,那么它就会找到当前点的最优梯度下降方向,最终情况可能如下:
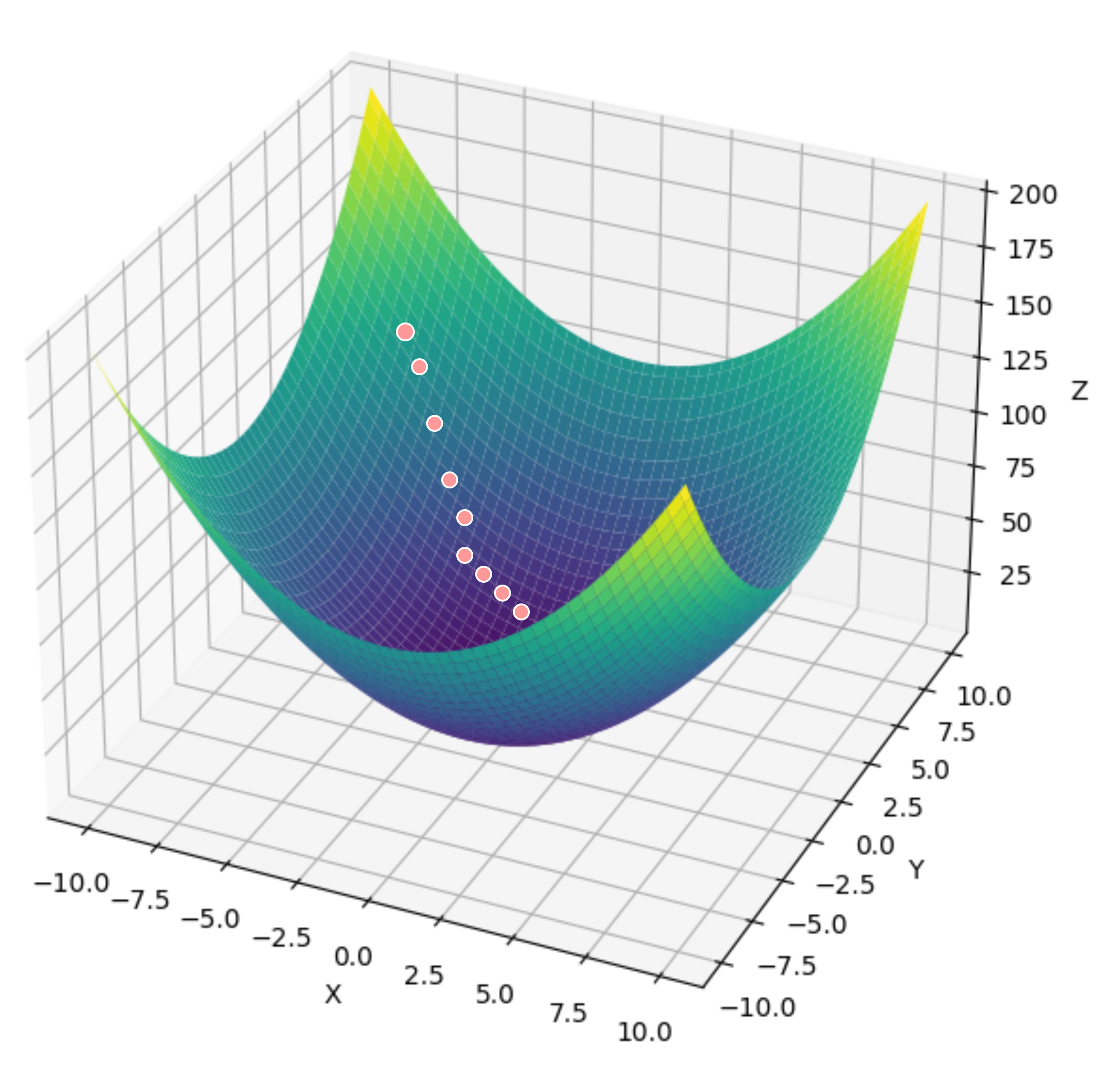
每次方向找的是最优的,但是计算损失函数以及计算梯度太慢。
而如果随机找一个样本就更新参数,虽然迭代速度很快,但是过于随机可能需要很多次迭代才能降低。
而小批量梯度下降算法就是他们的折中,可参考下面代码:
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_lossfor epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
其中 l l l是一个向量,每个元素都是小批量中每个样本的损失,在本代码中我们使用了sum累加所有损失并反向传播,那么它会对每个样本的损失函数中的每一个参数求偏导并对应加到一起,当然我们除了使用sum也可以使用平均损失函数,pytorch中的MSELoss用的就是平均损失。在迭代器中,我们还需要去除batch_size对梯度的影响。如:
def sgd(params, lr, batch_size): #@save"""小批量随机梯度下降"""with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()
五、动量法
之前我们都是把所有维度的梯度同时考虑并优化,那么我们能不能在每个维度上分别做不同程度的优化呢?答案是可行的,这就是我们要讲的动量法,考虑一种“惯性”。
我们可以先考虑两个参数的梯度下降优化。
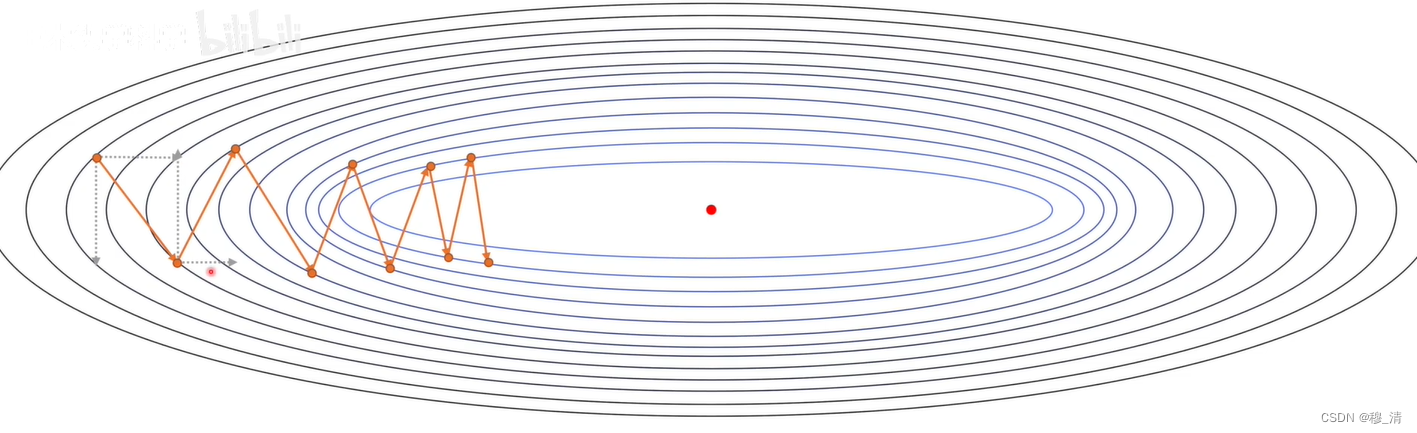
我们可以看到它一方向的梯度大体是对的,而另一个轴的方向波动很大。
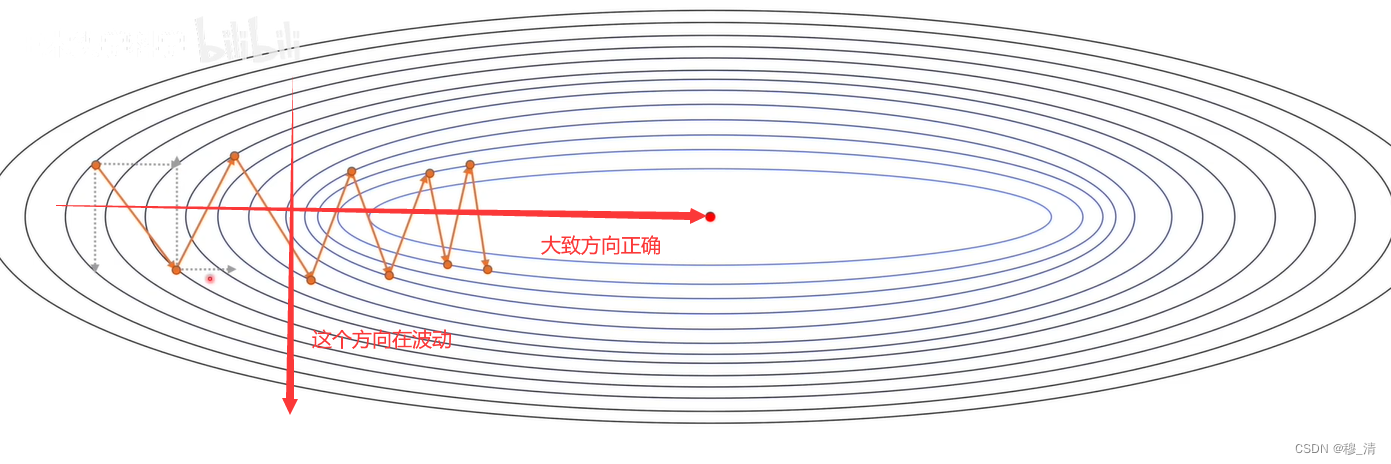
我们可以用当前点的梯度方向加上上个点的梯度方向,如果当前点的一个梯度分量与上个点的对应梯度分量方向相同,就会促进这个方向的变化,如果相反则会抑制它。
而动量法这是利用了这个特性,只不过动量法是考虑了前面所有的梯度并进行加权求和,而不是仅仅考虑上一个点。

这里的加权是用了指数加权平均法,这个我们在批量归一化那里也有说过。举个例子:

六、AdaGrad–自适应学习率
AdaGrad是一种优化算法,用于训练机器学习模型。它是基于梯度下降的一种自适应学习率方法,旨在解决传统梯度下降算法中学习率难以选择的问题。
AdaGrad通过自适应地调整学习率,可以在训练过程中逐渐减小对稀疏特征的学习率,而对频繁出现特征的学习率保持较大。具体而言,它会根据每个参数的历史梯度大小来动态地调整学习率。
公式如下:
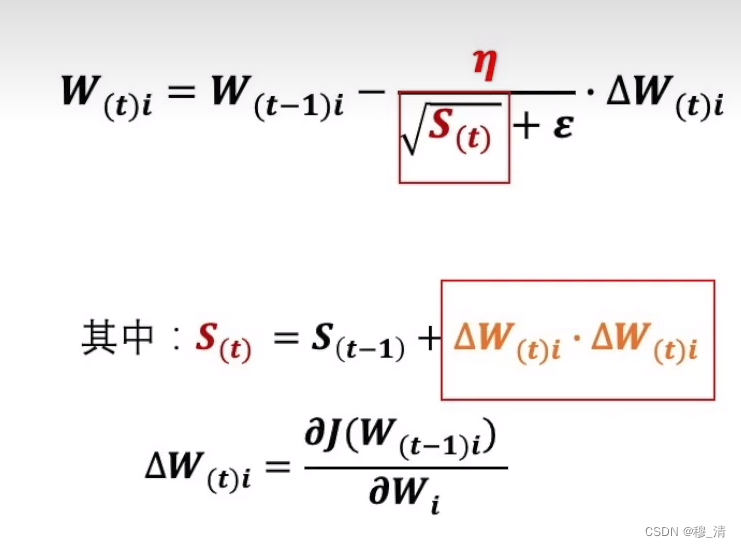
Adagrad优化算法就是在每次使用一个 batch size 的数据进行参数更新的时候,算法计算所有参数的梯度,那么其想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上。
Adagrad特别适合稀疏数据,所谓的稀疏数据更多的是指某个特征有或者没有,而稠密数据是指都有这些特征,具体区别是特征数值的大小。
有这样一个规律,随着维度的增加,你遇到稀疏数据的可能性越高。
AdaGrad也有一个缺点,就是它会考虑前面所有的历史梯度,这样的话可能会对当前学习率的调整不够准确。改进的方法就是使用指数加权只考虑最近的一些历史梯度。----------此方法就叫做RMSprop方法
七、Adam
我们可以结合动量法与RMSprop方法,修正动量的同时,自适应学习率。
具体公式如下:
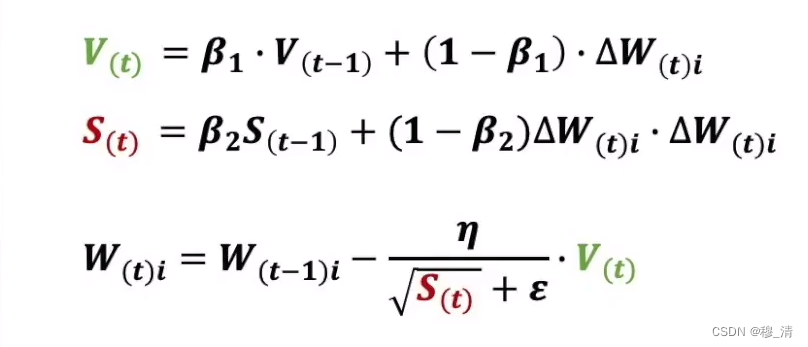
总结
附录–参考资料
- 各种优化算法总结
- 可视化软件