目录
协程原理:
进程、线程和协程的区别和联系编辑
协程在IO多路复用中
协程的目的:
协程的优势:
协程原理:
(学习来源:幼麟实验室)
线程是进程中的执行体,拥有一个执行入口,以及从进程虚拟地址空间中分配的栈,包括用户栈和内核栈。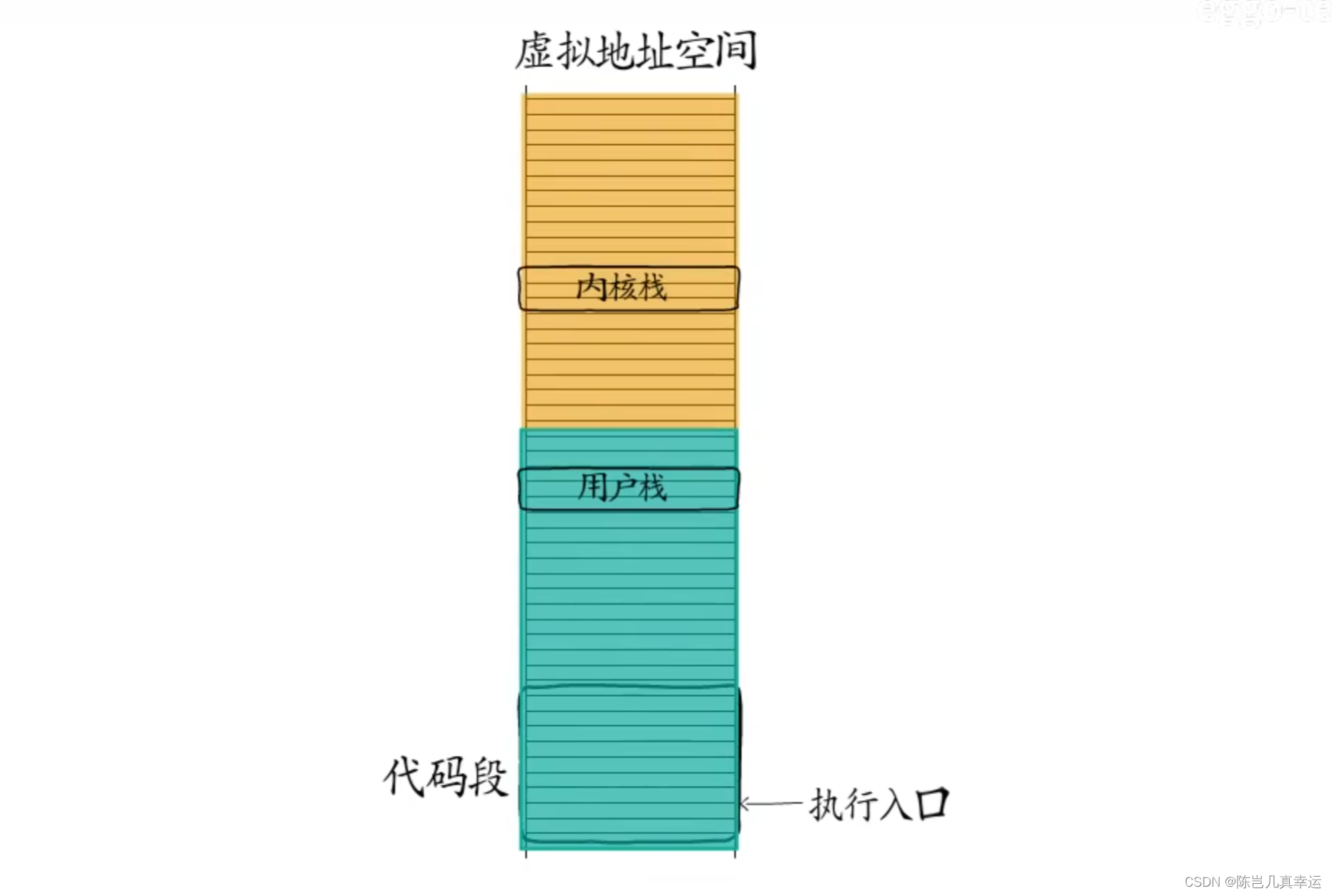
操作系统会记录线程控制信息,而线程获得CPU时间片以后才可以执行,此时CPU中的栈指针、指令指针等寄存器都要切换到对应的线程。
如果线程有创建几个执行体,给他们指定各自的执行入口,申请一些内存给他们用作执行栈,那么线程就可以按需调度这几个执行体了,为了实现这几个执行体的切换,线程也需要记录他们的控制信息(id、栈的位置、执行入口地址、执行现场)线程可以选择一个执行体来执行,此时CPU中指令指针就会指向这个执行体的执行入口,栈基和栈指针寄存器也会指向线程给它分配的执行栈。
要切换执行体时, 需要保存当前执行体的执行现场,然后切换到另外一个执行体,通过一样的方式也可以恢复到之前的执行体,这样就可以从上次中断的地方继续执行。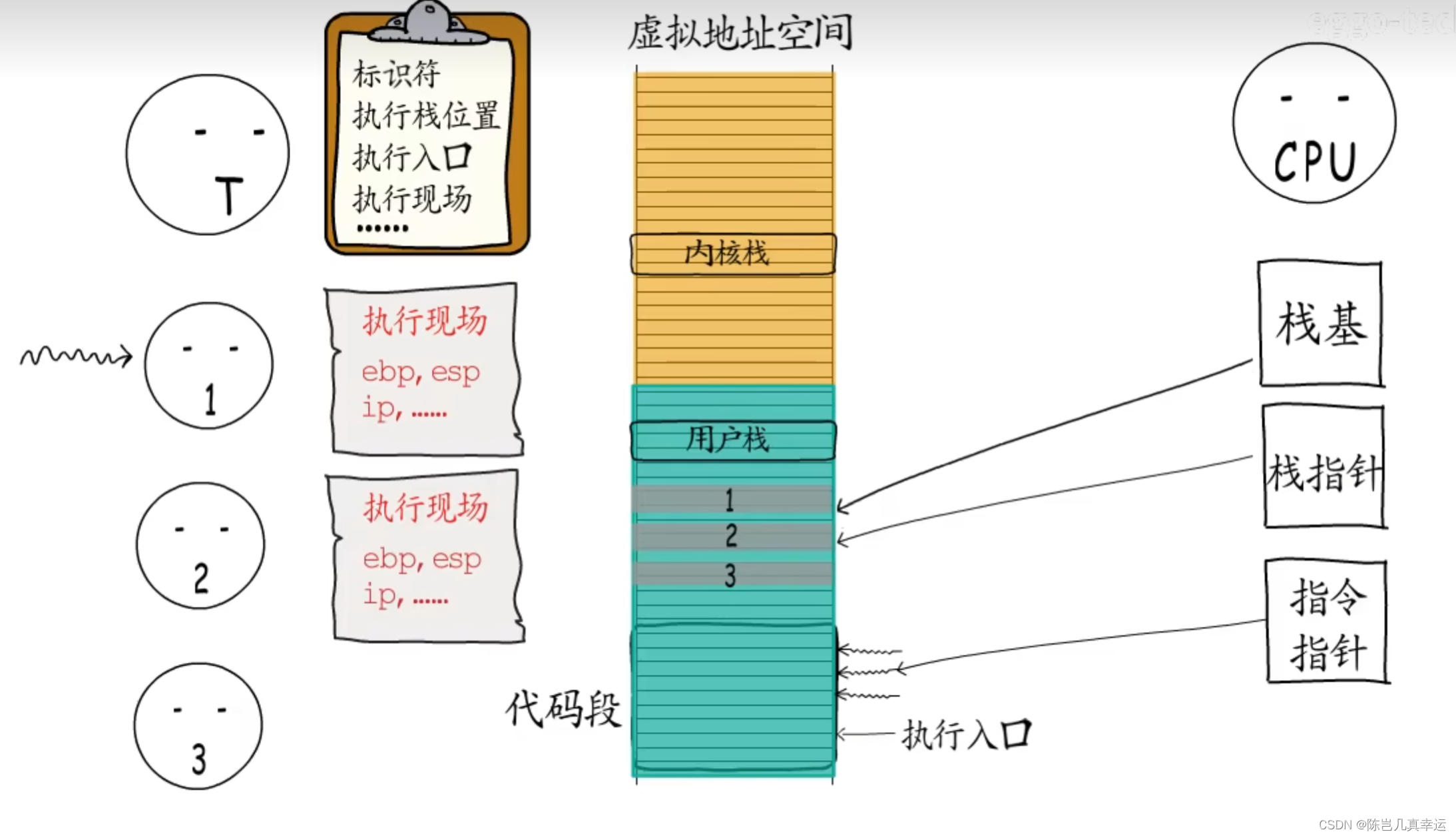
这些由线程创建的执行体就是协程。因为用户程序不能操作内核空间,所以只能给协程分配用户栈,而操作系统对协程一无所知,所以协程又被称为用户态线程。
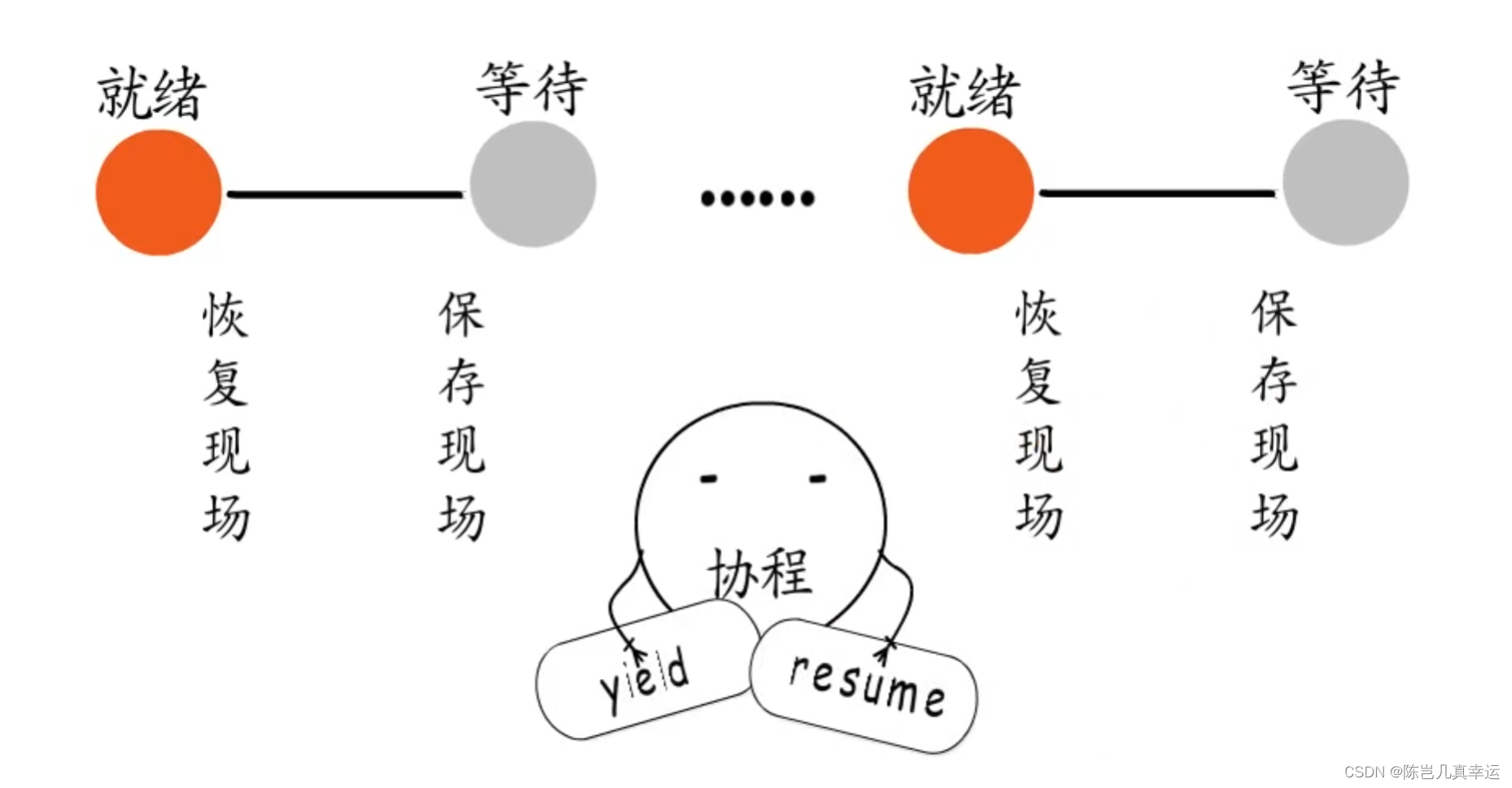
创建协程时,都要指定执行入口,底层都会分配协程执行栈和控制信息,用于实现用户态的调度,让出执行权时也要保存执行现场,用于从中断处恢复执行。协程思想的关键在于控制流的主动让出和恢复。
每个协程拥有自己的执行栈,可以保存自己的执行现场。可以由用户程序按需要创建协程,协程主动让出执行权时,会保存执行现场,然后切换到其他协程,协程恢复执行时,会根据之前保存的执行现场恢复到中断前的状态继续执行,这样就通过协程实现了即轻量级又灵活的,由用户态进行调度的多任务模型。
进程、线程和协程的区别和联系
协程在IO多路复用中
通过操作系统记录的进程控制信息,打开文件描述符表,进程打开的文件、创建的socket等等都在这个表里。socket的所有操作都由操作系统来提供,通过系统调用来完成,每创建一个socket都会在对应打开的文件描述符表中添加一个记录,而返回给应用程序的只有一个socket描述符,用于识别不同的socket。
每个TCP socket在创建时,操作系统都会给他分匹配一个读缓冲区和一个写缓冲区,要获得响应数据就需要从内核的读缓冲区拷贝到用户空间的接收数据,同样的要通过socket发送数据也要先放到写缓冲区中。
问题:用户程序想要接收数据时,读缓冲区不一定有数据,发送数据时,写缓冲区不一定有空间?
①:阻塞式IO:让出CPU进到等待队列中,等socket就绪后再次获得时间片才可继续执行,处理一个socket就要占用一个线程。
②:非阻塞式IO:不需要让出CPU,但是需要频繁的检查socket是否就绪了,这是一种忙等待的方式,很难把握轮询的间隔时间,容易造成空耗CPU,加剧响应延迟
③:IO多路复用:操作系统提供支持,把需要等待的socket加入到监听集合,这样就可以通过一次系统调用,同时监听多个socket,有socket就绪了就可以逐个处理了,既不为等待某个socket而阻塞也不会陷入忙等待之中。
select:支持可读、可写、异常三类事件
可以设置要监听的描述符,也可以设置等待时间,当有准备好的fd或者超过等待时间select就会返回,最多可以监听1024(fs_Set是个unsigned long型的数据,16个元素),
等待有事件就绪或超时:每次调用select都要传递所有的监听集合,需要频繁的从用户态到内核态拷贝数据。
判断那个fd就绪:每次需要遍历所有集合
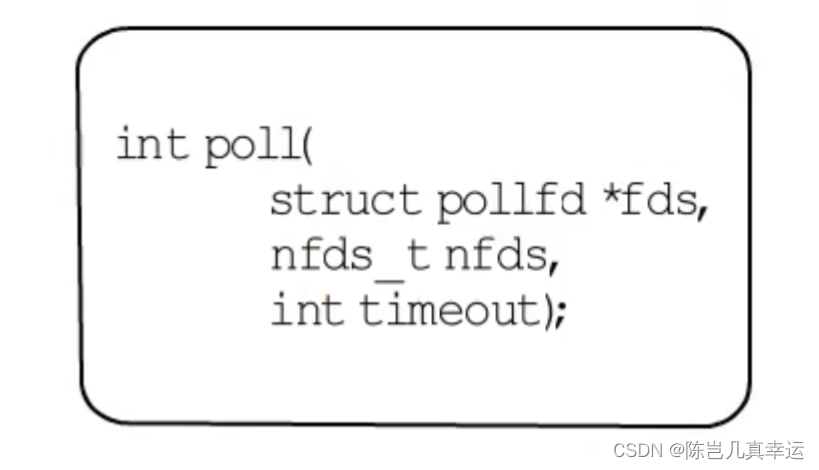
poll: 相比于select没有文件描述符数量限制,fd数目等于最多可打开的文件描述符个数
任然有每次调用poll都要从用户态到内核态拷贝,遍历集合找就绪fd
epoll:没有这些问题
epoll_create :创建epoll 获取句柄 创建一个白板 存放fd_events。
epoll_ctl :添加或者删除fd对应的事件信息,用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上。
除了指定fd和要监听的事件类型(EPOLLIN、EPOLLOUT等)还可以传入event_data:按需要定义一个数据结构用于处理对应的fd,每次只需要传入要操作的一个fd,无需传入所有监听集合,而且只需要注册一次。
epoll_wait:通过该函数得到的fd都是已经就绪的,不需要再遍历监听集合了 通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,

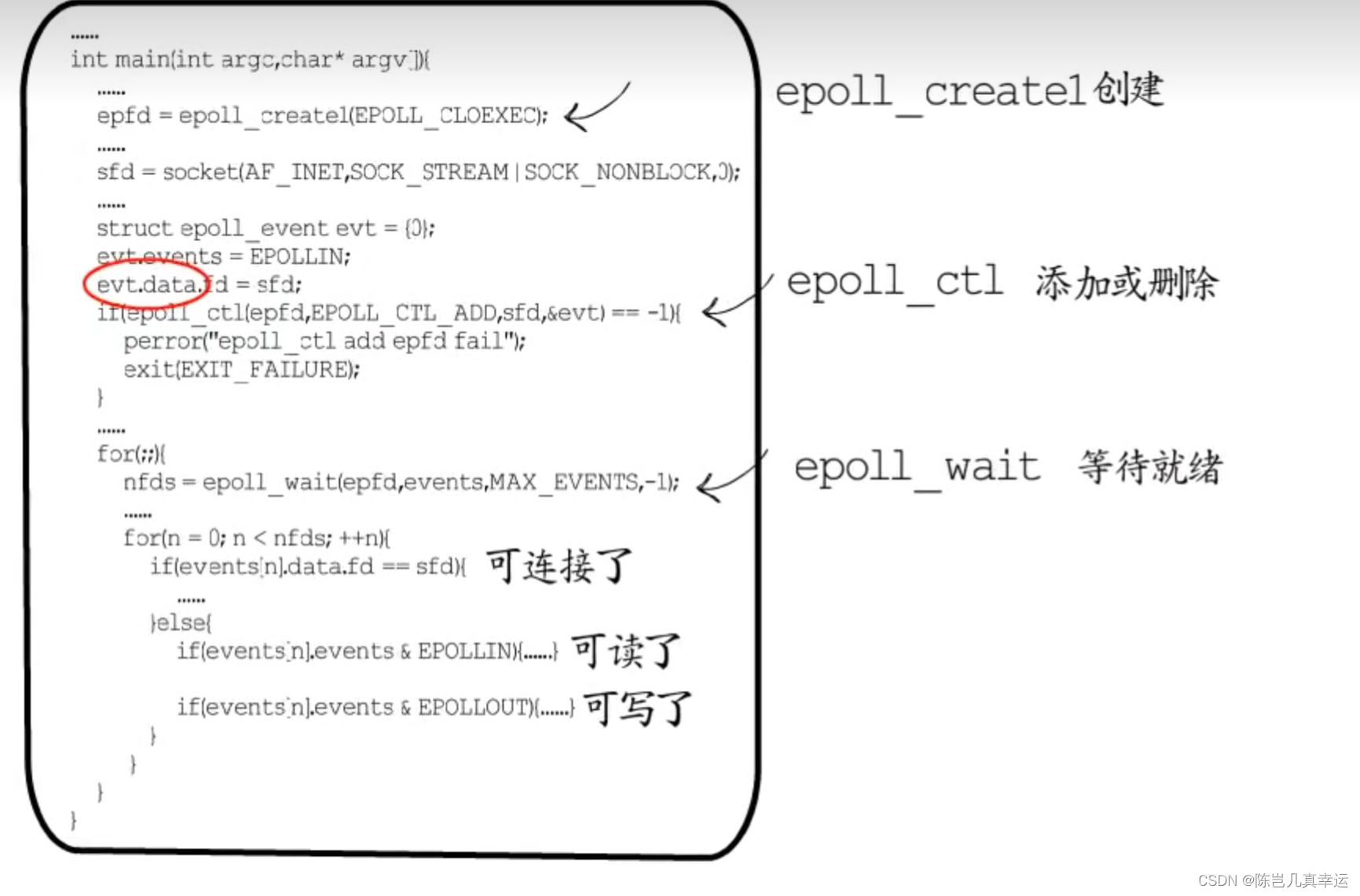
两种触发模式:
LT:水平触发
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
ET:边缘触发
和 LT 模式不同的是,通知之后进程必须立即处理事件。
下次再调用 epoll_wait() 时不会再得到事件到达的通知。很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。在ET模式下,当进程没有及时处理时,只有再下次该文件描述符上再发生事件时才会得到事件通知。
问题:假如一个socket可读了,但是只读到了半条请求,也就是说需要再次等待这个socket可读,再继续处理下一个socket之前,需要记录下这个socket的处理状态,下一次这个socket可读时,也需要恢复上次保存的现场。也就是说再IO复用中是实现业务逻辑时,我们需要随着事件的等待和就绪而平凡的保存和恢复现场。 适合使用协程
适合使用协程
在IO多路复用这里, 事件循环依然存在,依然要在循环中逐个处理就绪的fd,但处理过程却不是围绕具体业务而是面向协程调度。
如果是用于监听端口的fd就绪了,就建立连接创建一个新的fd,交给一个协程来处理,协程执行入口就指向业务处理函数入口,业务处理过程中需要等待时就注册IO事件,然后让出,这样执行权就会切换到该协程的地方继续执行。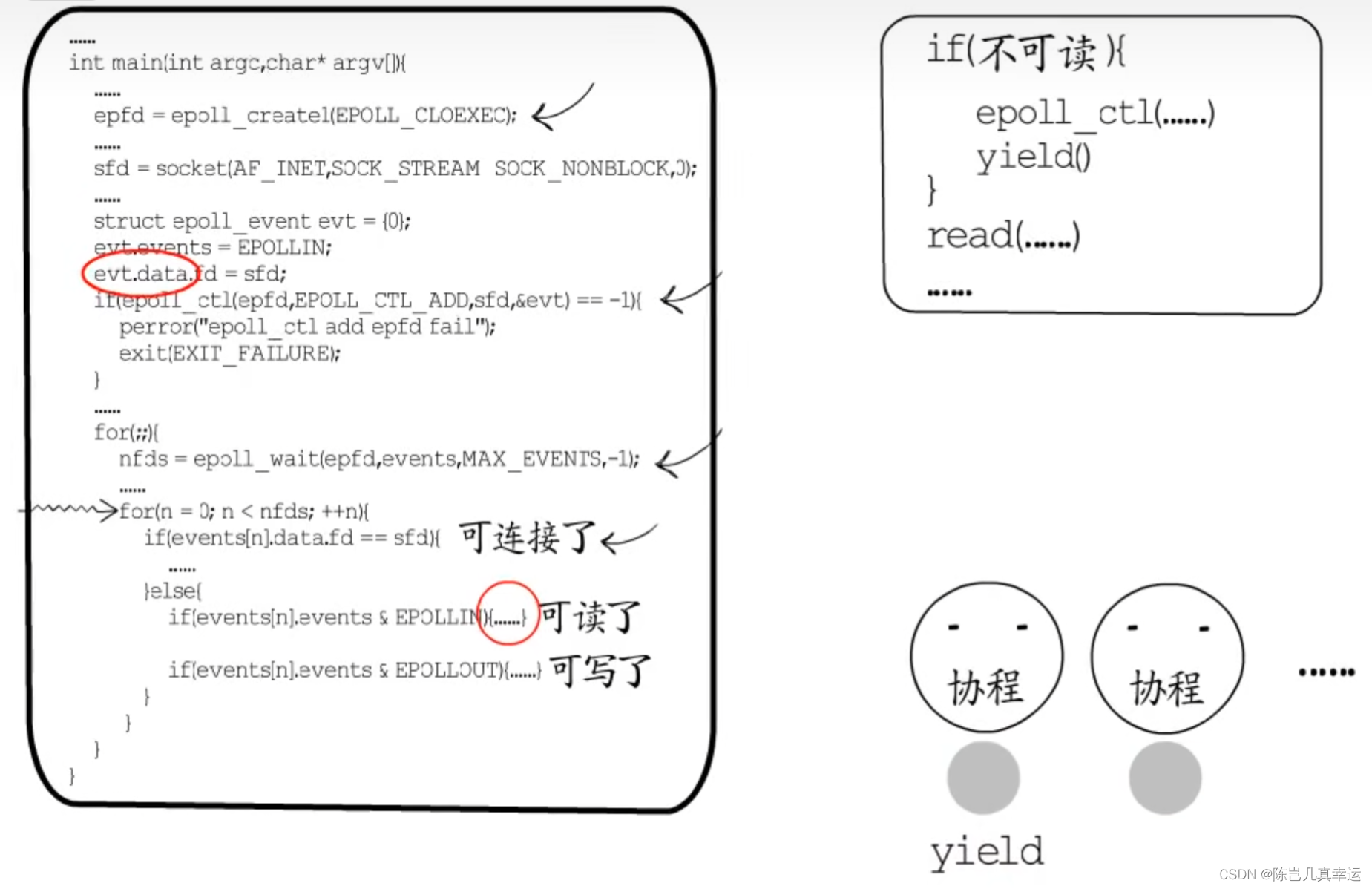
如果是其他等待IO事件的fd就绪了,只需要恢复关联的协程即可,协程拥有自己的栈,要保存和恢复现场都很容易实现。
IO多路复用这一层的事件循环就和具体的业务逻辑解耦了,可以把res,write,connect等可能要等待的函数包装一下,在其中实现IO事件的注册与主动让出,这样就可以在业务逻辑层面使用这些包装函数按照常规的顺序来实现业务逻辑了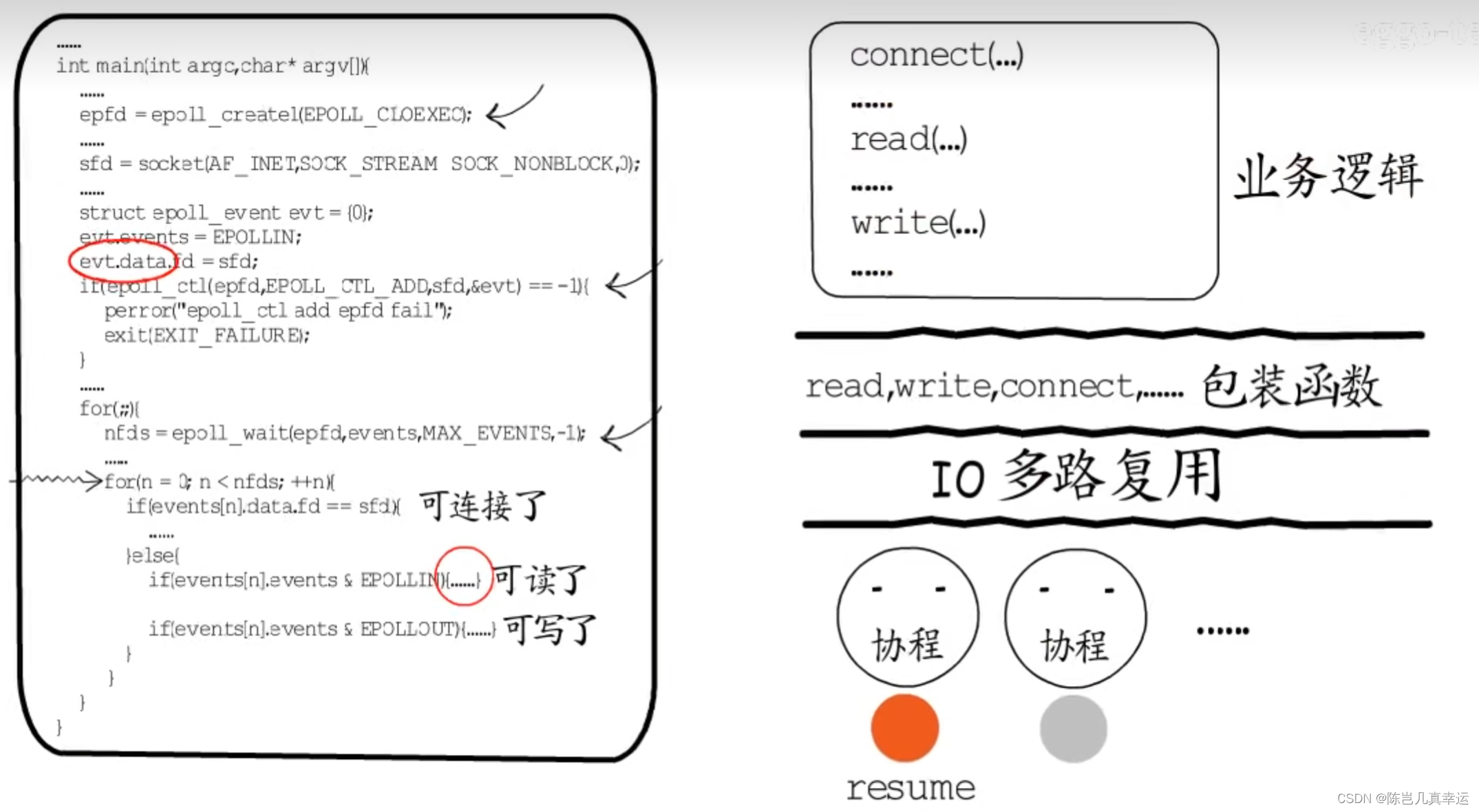
这写包装函数在需要等待时会注册IO事件,然后让出协程,这样在我们实现业务逻辑时完全不用关心保存与恢复现场的问题了,协程与IO多路复用的结合保存了IO多路复用的高并发性能还解放了业务逻辑的实现。
协程的目的:
协程主要是用来编写异步逻辑的,在有协程之前想要异步做并发要么要开多线程、要么要写函数回调非阻塞的代码。
协程的优势: 
 协程切换开销比线程开销小百倍,协程可以在单线程上轻松实现并发任务。
协程切换开销比线程开销小百倍,协程可以在单线程上轻松实现并发任务。








![[保研/考研机试] 约瑟夫问题No.2 C++实现](https://img-blog.csdnimg.cn/a6f6e7f24e9244a9993053e684b781f4.png)