Transformer出自于论文《attention is all you need》。
一些主流的序列模型主要依赖于复杂的循环结构或者CNN,这里面包含了编解码器等。而Transformer主要的结构是基于注意力机制,而且是用多头注意力机制去替换网络中的循环或者CNN(换言之就是transformer这个网络模型是不需要循环结构和CNN,只用注意力机制就行)。
一些循环神经网络,比如LSTM,GRU等都是由编码器-解码器构成。以RNN为例,在计算序列的时候(比如一个句子),会一个词一个词的计算,对于第t个词,会计算一个隐藏状态叫ht。该隐藏状态是由前面一个词的隐藏状态ht-1和当前位置的第t个词决定的,也就是计算当前词的时候和之前的历史状态是有关系的。但这就带来了一些问题:
(1)比如这种方法无法并行计算(在计算当前t词的时候,需要把之前的词全部计算完),这样就会导致很多资源的浪费
(2)还有就是因为隐藏状态是不断积累的,如果序列比较长那么之前的一些状态可能会丢失
(3)如果想要存储之前的ht状态,在序列长的时候会对内存开销比较大
在之前的一些的网络,比如ConvS2S等,这些对于长序列是比较难以建模的,这是因为卷积网络就是一个段窗口的滤波器,那么对于长序列是不友好的。而如果是使用transformer的话,使用注意力机制,那么就可以看到这一层的所有信息(或者可以理解为transformer是一个超大的卷积,可以涵盖所有的像素),卷积看的是局部信息,transformer是全局信息,但卷积也有一个优势就是它是多通道多维度的(提取多维度的特征),因此transformer借鉴了卷积的思想,提出了多头注意力机制(Multi-Head Attention),用Multi-Head Attention去模拟卷积多通道的特点。
transformer是第一个只用self-attention来做encoder-decoder的模型,因此在学习transformer的时候需要把自注意力机制看明白。
通常的模型会含有编解码器(encoder-decoder)。编码器指的是将一个输入长度为n的x1~xn的序列编码成一个长度也为n的zn序列,每个zt对应于xt特征表示,就是把你的输入变成机器学习可以理解的向量(这就好比把计算机的一些输入变成0101这样的,就是编码),解码器就是编码器的逆过程,只是要注意的是,解码器的输出长度为m,这个m不一定等于n的长度。但要注意的是在解码输出的时候,比如做翻译的时候,是一个词一个词的往外蹦,过去时刻的输出会成为当前时刻的输入,这个就是叫自回归(auto-regressive)。就是说输入的时候编码是一整段的话,但输出的时候是一个字一个字的出。
transformer也是使用的encoder-decoder的架构,是将一些self-attention、point-wise、fully connected layer进行的组合(堆叠)。
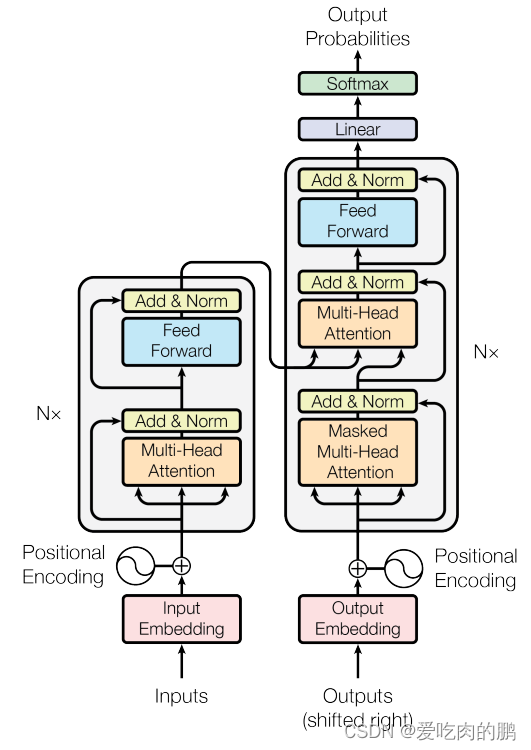
上面的图就是transformer的一个结构,是编码器和解码器构成的。可以看到在编解码器均有一个输入,编码器的输入是Input,解码器的输入是Output。解码器在做预测的时候是没有输入的!实际上是解码器在之前时刻的一些输出作为输入。
编码器构成
图中的Nx就是一个transformer block[就和ResNet 中的残差块类似]。

接下来看看这个transformer block。可以看到里面有个多头注意力机制,前馈网络(Feed Forward),或者就是说是个MLP吧。
综上,编码器的构成就是一个多头注意力机制+MLP+残差边+norm。
在论文中说,编码器是由6个重复的layer构成,其实就是上面说的transformer block。然后每个layer中又有两个sub-layers,第一个sub-layer叫多头注意力机制,上面已经提到了,第二个sub-layer是position-wise fully connected feed-forward network[实际就是个MLP]。对每个子层(sub-layer)采用了一个残差的链接,然后又添加了一个layer-norm的东西。因此每个子层的公式为:
LayerNorm(x+Sublayer(x))
每个层的输出维度为512[方便残差连接]。
因此这里的调参就直接调两个就行,一个是重复layer的数量,一个是输出维度。
layerNorm
与batchNorm相比,变长的情况下使用LayerNorm,batchNorm可以在一个mini-batch中将我的特征(也就是说通道维度上)分布变为一个均值为0,方差为1的标准分布当中。layernorm是对每个样本变成标准分布。
个人理解,batchnorm是考虑通道维度上每个特征向量的分布,layernorm是考虑每个样例维度上的分布(这样的就可以把每个样例的所有特征向量均考虑进去,这样对不定长的序列比较好)。
注意力机制
注意力机制可以描述为一个query和一些key-value对 映射成的一个输出的函数。具体来说output是你的value的一个加权和。因此输出的维度和value的维度是一样的。value的权重是对应的Key和query的相似度来计算的。该注意力机制的作用是处理序列中不同位置之间的关系。这种机制可以使得Transformer能够同时考虑不同位置之间的关系,从而捕捉上下文信息。
Query、key、value的理解
query:指当前位置(或当前单词)的表示,用来寻找与其他位置的关联程度。
key:表示其他位置的信息,与Q计算关联度。
value:是位置的实际表示或信息,通常是transformer中每个位置的原始嵌入表示,注意力分数计算完毕后(Q和K的内积),通过对Value进行加权平均,得到当前位置的注意力加权表示。
这里举个例子:
将英语"I love coding"翻译为法语。
在Transformer模型中,每个输入句子被嵌入为一系列向量,其中每个单词都由一个嵌入向量表示。在自注意力机制中,Query、Key和Value的作用如下:
1.Query:对于每个单词,我们会产生一个Query向量。例如,对于英文句子中的"love"这个单词,会生成一个Query向量,它包含了关于"love"这个单词的信息。
2.Key:对于每个单词,同样会生成一个Key向量。Key向量用来衡量其他单词与当前单词之间的关系。在我们的例子中,对于"love"这个单词,也会生成一个Key向量。
3.Value:每个单词都有对应的Value向量,这个向量包含了单词的原始嵌入表示。"love"这个单词也会有一个对应的Value向量。
现在,我们需要计算注意力分数(权重)。具体步骤如下:
-
对于"love"这个单词的Query向量,会与输入句子中的其他单词的Key向量进行点积,得到每个单词与"love"之间的关联分数(衡量其他单词与当前单词的关联性)。这反映了每个单词与"love"之间的相似程度。
-
注意力分数经过一些归一化操作,最终用于对所有单词的Value向量进行加权平均。这个加权平均得到了"love"这个单词的注意力加权表示。
这个过程对于句子中的每个单词都会执行一遍,从而为每个单词生成一个对应的注意力加权表示。在翻译任务中,这些注意力加权表示可以被用来生成目标语言的翻译结果。
总之,Query、Key和Value在Transformer中是为了捕捉序列中不同位置之间的关系,并用于计算注意力加权表示。这个机制使得Transformer能够在处理序列数据时更好地理解上下文信息。
在transformer中query和keys是等长的,等于,value的长度为
.然后是对query和keys两个向量做内积,如果内积的值越大,说明向量夹角越小,两个特征越相似。然后再用这个内积的结果除以
(就是向量的长度)【可以防止梯度消失或爆炸】,再经过一个softmax得到权重(也叫做注意力分数)。【比如给一个query,n个keys value,那么就会算出n个值,因为每个q会和k做内积,算出来后再放如softmax就会得到n个非负的而且加起来和等于1的一个权重】,然后将这个权重作用在我们的value上就会得到相应的输出了,但是这种方法实际计算起来比较慢,因为需要一个个的计算,因此可以用矩阵乘法来计算即可。
这里的Mask是为了避免在第t时间看到以后时间的东西,可以在qt和kt之后的那些值给一个非常大的负数,这样可以保证后面的这些数在经过softmax的时候输出接近0.

多头注意力机制
这里的线性层(Linear)就是做一个低维度的映射,然后经过一个上面的注意力机制,然后重复h次(就是有h个注意力,即注意力的头数),然后把这些输出进行合并(concat),最后再经过一个Linear的映射。这个就是有点模拟CNN中的多个输出的意思。

公式如下:

自注意力机制
可以看一下这个注意力层。
自注意力机制通过直接建模任意两个位置之间的关系,能够更好地捕捉长距离的依赖,使得模型能够理解远处位置的上下文信息。不同头(多头注意力)可以捕捉不同距离的关系,一些头可能更关注近处的关系,而另一些头可能更关注远处的关系。这样的多头机制使得模型能够更好地适应不同范围内的关联信息。

可以看到在编码器的输入,在输入到Multi-Head attention的时候分别复制了三份,q,k,v。而此时的q,k,v实际是一个东西,这个东西就是叫自注意力机制。
解码器构成
masked多头注意力机制
与编码器不同的是,解码器的block中多了一个Masked多头注意力机制。
解码器是由三个部分组成,masked多头注意力机制,多头注意力机制,前馈网络(MLP)。然后将最后的输出经过一个softmax得到输出。
解码器和编码器很相似,只不过在解码器是有三个子层。多了一个masked 多头注意力机制。另外在解码器当中做了一个自回归,当前输出的输入集是上面一些时刻的输出,在解码器训练的时候,在预测第t个时刻的输出时候,是不应该看到t时刻以后的那些输入的,实现这种的做法是加入了masked 多头注意力机制。
然后看一下解码器的这里,如下图。可以看到此时的多头注意力机制的输入也有三个,其中两个输入是编码器的输出(k,v),query是来自于你解码器下一个attention的输出。
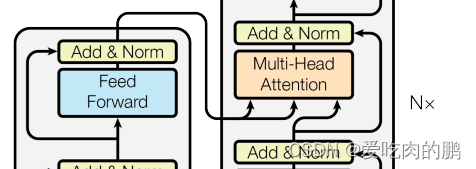
masked多头注意力机制的作用:
Masked多头注意力机制通过遮盖(masking)部分输入信息,限制了模型在预测未来位置时的访问能力,从而用于处理顺序性任务,如语言模型和序列生成。
1.顺序性任务处理: 在一些任务中,特别是语言建模和序列生成任务,模型需要逐步生成输出序列,而每个时间步只能访问已生成的部分。为了模拟这种场景,需要使用Masked多头注意力机制,其中注意力分数在计算时会被限制为仅考虑当前时间步及之前的位置,而忽略未来的位置。这使得模型能够逐个时间步地生成序列,而不会在生成时候透视未来信息。
2.遮盖未来信息: 在处理顺序性任务时,如果模型可以访问未来位置的信息,可能会导致信息泄露和过拟合问题。Masked多头注意力机制通过在计算注意力分数时设置一些位置为无效(或很小的)注意力分数,从而遮盖了未来位置的信息,确保模型只能看到当前时间步及之前的信息。
3.自回归生成: 在自然语言生成任务中,例如语言模型或文本生成,模型需要根据之前的生成部分来预测下一个词。Masked多头注意力机制允许模型根据已生成的部分计算注意力,以更好地决定下一个生成的词。
4.避免信息泄露: 在某些情况下,训练和推理过程需要模型能够对未来位置做出预测。但在一些应用中,未来信息不应该在预测时出现。Masked多头注意力机制通过限制模型的未来访问能力,防止了未来信息泄露。







![[RoarCTF 2019Online Proxy]sql巧妙盲注](https://img-blog.csdnimg.cn/img_convert/6a6d822b864f6daedf6cd34bb01e6007.png)