一.举例计算均值、方差
假设我们有以下一组数据:[10, 15, 20, 25, 30]首先,我们计算均值,即将所有数据相加后除以数据的数量:
**均值** = (10 + 15 + 20 + 25 + 30) / 5 = 100 / 5 = 20
1.1标准差
接下来,我们计算标准差,用来衡量数据的离散程度。标准差的计算公式如下:
**标准差** = sqrt( ( (x1 - 平均值)^2 + (x2 - 平均值)^2 + ... + (xn - 平均值)^2 ) / n )标准差 = sqrt( ( (10 - 20)^2 + (15 - 20)^2 + (20 - 20)^2 + (25 - 20)^2 + (30 - 20)^2 ) / 5 )= sqrt( (100 + 25 + 0 + 25 + 100) / 5 )= sqrt( 250 / 5 )= sqrt( 50 )≈ 7.071
二.对例子中的数据标准化
现在,让我们对数据进行标准化。标准化是将数据转换为均值为0,标准差为1的标准正态分布。
对于每个数据点,我们可以使用以下公式进行标准化:
2.1公式
标准化数据 = (原始数据 - 均值) / 标准差
对于我们的数据集,标准化后的结果如下:
(10 - 20) / 7.071 ≈ -1.414
(15 - 20) / 7.071 ≈ -0.707
(20 - 20) / 7.071 = 0
(25 - 20) / 7.071 ≈ 0.707
(30 - 20) / 7.071 ≈ 1.414因此,经过标准化后的数据集为:[-1.414, -0.707, 0, 0.707, 1.414]
2.2 标准化后的数据特点
均值为0,方差为1
2.3 将数据标准化有什么好处?
-
消除数据相差太大的影响:标准化后的数据具有相同的量纲,消除了原始数据中不同变量之间因量纲不同而引起的影响,确保各个变量对分析结果的贡献相对均等。
-
提高模型性能:在许多机器学习算法中,输入数据的标准化可以提高模型的训练效果和预测准确性。标准化后的数据分布更接近于标准正态分布,可以降低模型对异常值的敏感性,使模型更加稳定和可靠。
-
加速优化过程:某些优化算法(如梯度下降法)在处理标准化后的数据时更加高效。标准化可以使优化算法收敛更快,并且更容易找到全局最优解或更接近最优解的解。
-
减少计算开销:标准化后的数据具有较小的数值范围,可以减少计算时的数据溢出或欠溢问题,提高计算的稳定性和准确性。
2.4 为什么数据可以标准化?可视化标准化效果
** BatchNorm(归一化/标准化)**
归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
标准化前:
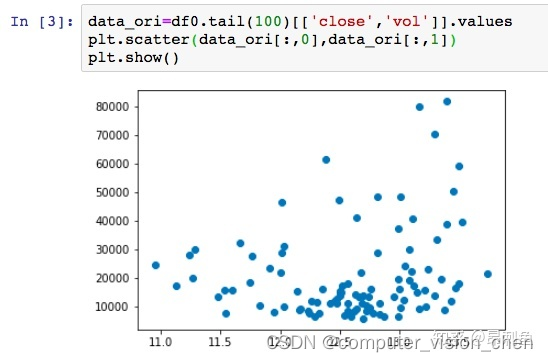
标准化后:
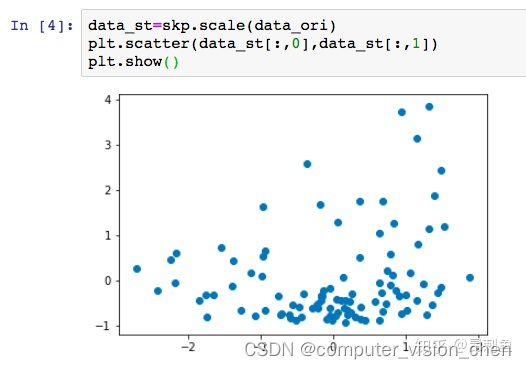
看到变化了吗,虽然各个点的相对位置看上去还是没变,但是坐标轴变了。均值是0,标准差为1。
参考文献:
数据预处理:标准化和归一化
https://zhuanlan.zhihu.com/p/63911364
三. 在模型中对小批次数据进行批量标准化
3.1 批量标准化公式

3.2 在模型的什么地方应用批量标准化?
- 在全连接层的激活函数之前
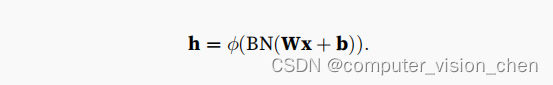
-
卷积层之后的非线性的激活函数之前
-
预测过程中的批量标准化
我们需要对逐个样本预测,我们需要移动估算整个训练数据集的样
本均值和⽅差。
四.代码
import torch
from torch import nn
from d2l import torch as d2l
import time
# eps是上面公式由于标准差在分母的位置,所以加入一个常量eps,防止分母为0
def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum):# 通过is_grad_enabled方法来判断当前模式是训练模式还是预测模式if not torch.is_grad_enabled():# 如果是预测模式,直接使用传入的移动平均所得的均值和方差X_hat = (X-moving_mean) / torch.sqrt(moving_var+eps)else:assert len(X.shape) in (2,4)if len(X.shape)==2: # 使用全连接层的情况,计算特征维上的均值和方差# 对每行求平均值mean = X.mean(dim=0)var = ((X-mean)**2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持X的形状以便后面可以做广播运算mean = X.mean(axis=(0, 2, 3), keepdims=True)var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True)# 训练模式下用当前的均值和方差做标准化X_hat = (X - mean) / torch.sqrt(var + eps)moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * varY = gamma * X_hat + beta # 缩放和移位return Y, moving_mean.data, moving_var.data
BatchNorm类 & BatchNorm(卷积层的输出通道数, num_dims=2或4)
BatchNorm(卷积层的输出通道数, num_dims=2或4),由于BatchNorm只出现在全连接层的激活函数之前和卷积层的激活函数之前,所以规定2表示全连接层,4表示卷积层。
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层def __init__(self, num_features, num_dims):super().__init__()if num_dims == 2:shape = (1, num_features)else:shape = (1, num_features, 1, 1)# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0self.gamma = nn.Parameter(torch.ones(shape))self.beta = nn.Parameter(torch.zeros(shape))# 非模型参数的变量初始化为0和1self.moving_mean = torch.zeros(shape)self.moving_var = torch.ones(shape)def forward(self, X):# 如果X不在内存上,将moving_mean和moving_var# 复制到X所在显存上if self.moving_mean.device != X.device:self.moving_mean = self.moving_mean.to(X.device)self.moving_var = self.moving_var.to(X.device)# 保存更新过的moving_mean和moving_varY, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)return Y
sigmoid激活函数版本模型
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10)
)
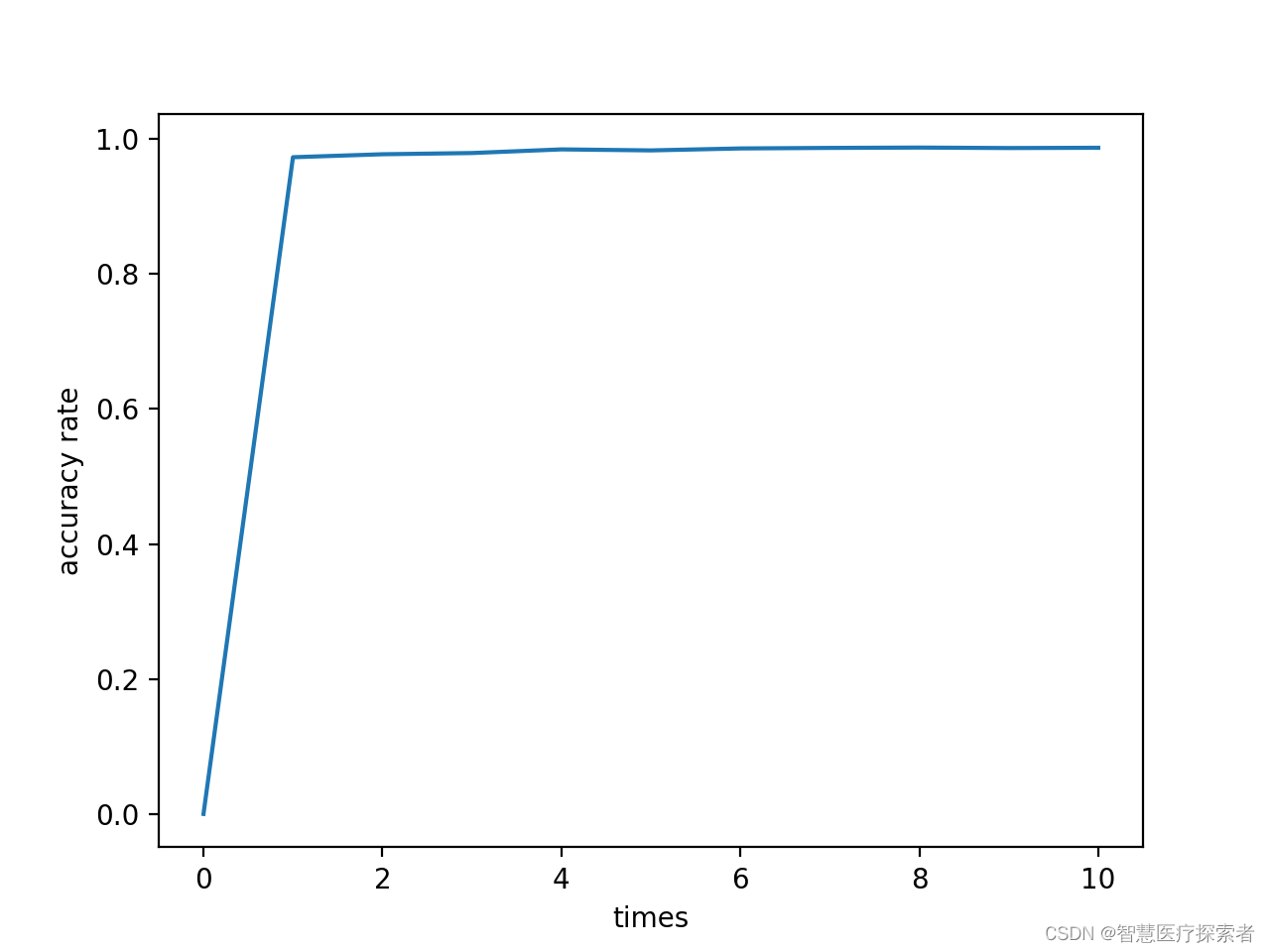
库中的训练函数 train_ch6 没有取最优的准确率,自己实现一个
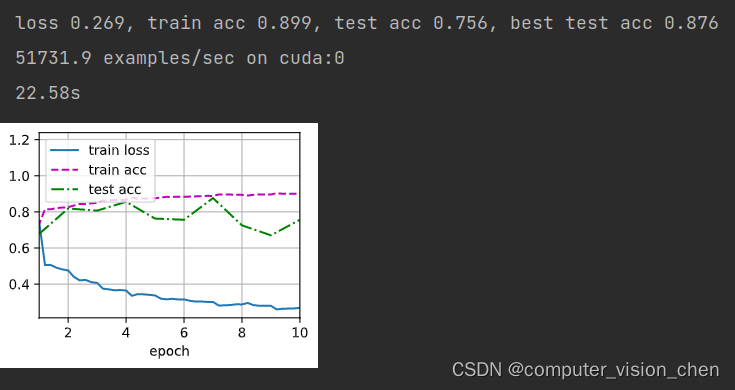
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""Train a model with a GPU (defined in Chapter 6).Defined in :numref:`sec_lenet`"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)best_test_acc = 0for epoch in range(num_epochs):# Sum of training loss, sum of training accuracy, no. of examplesmetric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)if test_acc>best_test_acc:best_test_acc = test_accanimator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}, best test acc {best_test_acc:.3f}')# 取的好像是平均准备率print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
开始训练
'''开始计时'''
start_time = time.time()# 配置参数
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time)<60:print(f'{round(run_time,2)}s')
else:print(f'{round(run_time/60,2)}minutes')
sigmoid激活函数版本结果
将sigmoid换成relu的版本结果
# 换成Relu()
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.ReLU(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10)
)
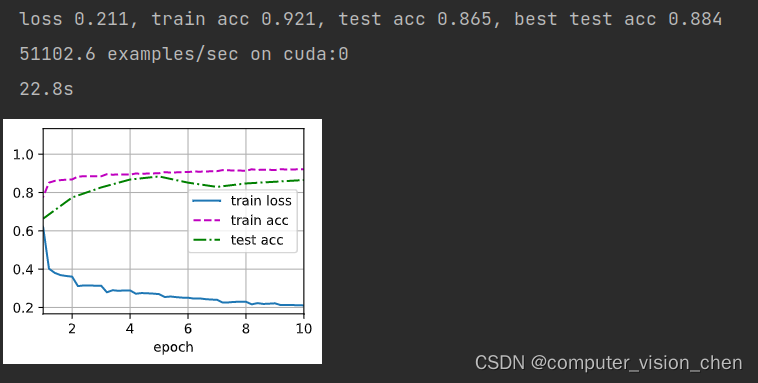
将sigmoid激活函数换成relu和把平均池化AvgPool2d换成最大值池化MaxPool2d版本结果
学习率用的是1
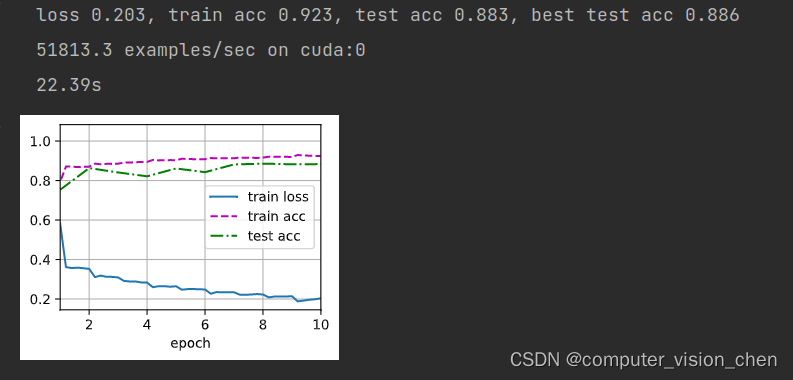
# 换成Relu()+最大值池化
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.ReLU(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10)
)
保持如上网络不变,学习率换成1.3的结果
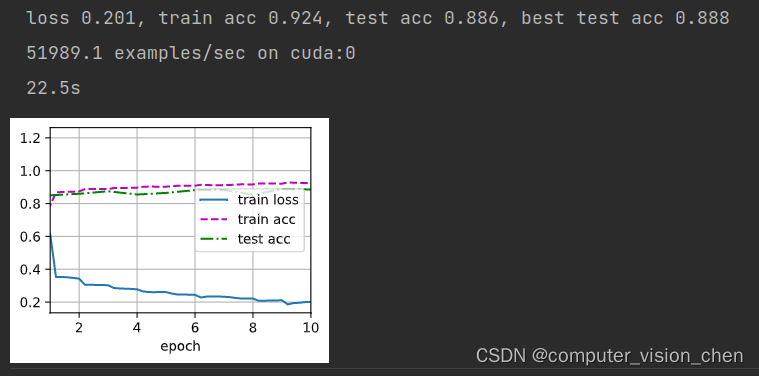
五.补充
5.1 方差和标准差公式
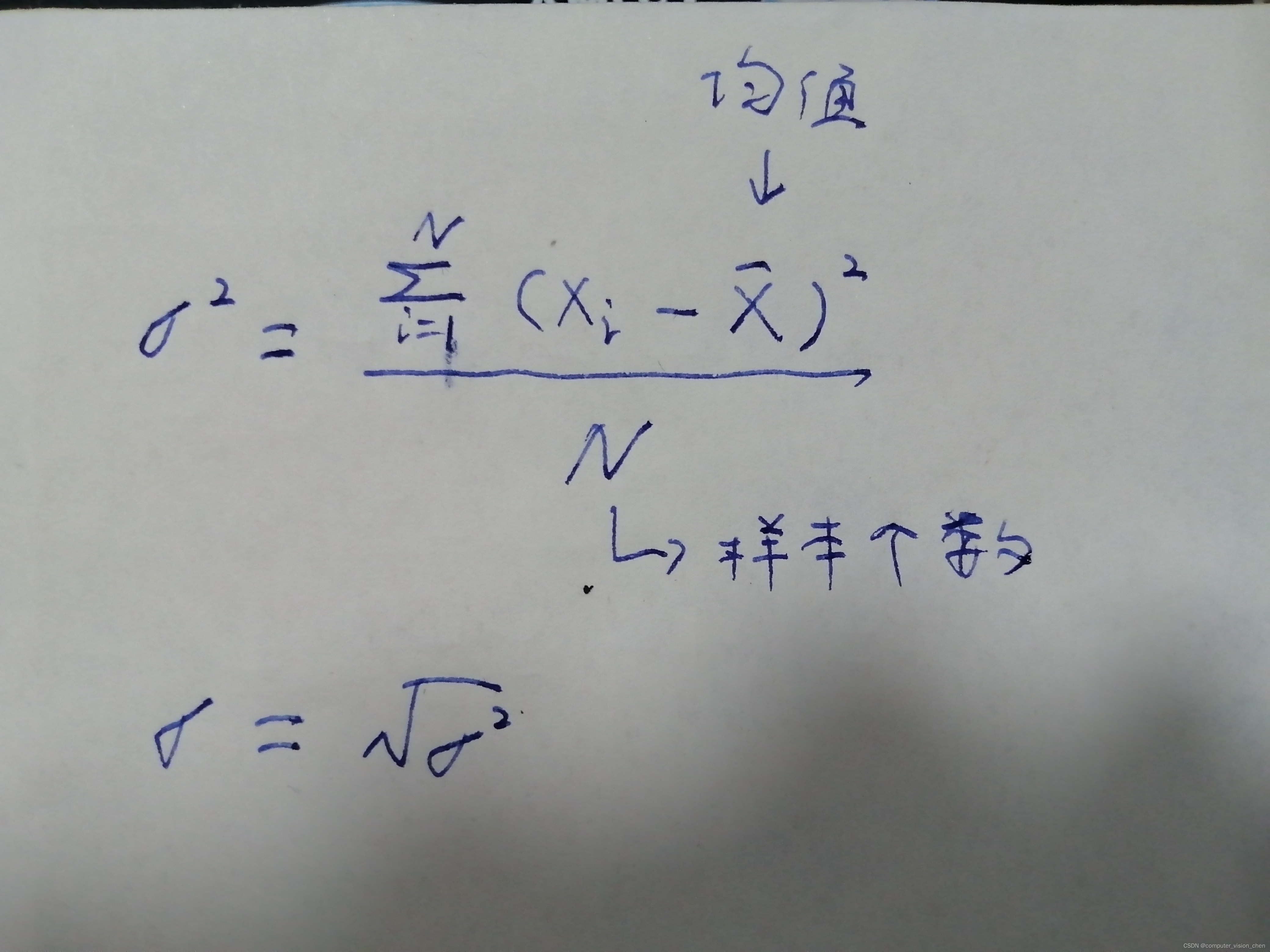
5.2 对某个维度取平均值
X.mean(dim=0),表示对每个列取平均值,保留行
import torch
# X = torch.rand(size=(2,2))
X = torch.tensor([[1.0, 1.0],[-1.0, -1.0]])
mean = X.mean(dim=0)
mean,mean.shape
输出结果:
(tensor([0., 0.]), torch.Size([2]))
X.mean(dim=1),表示对每个行取平均值,保留列
mean = X.mean(dim=1)
mean,mean.shape
(tensor([ 1., -1.]), torch.Size([2]))
X.mean(dim=(0,2,3),keepdim=True),表示对维度0(样本),维度2(行数),维度3(列数)求平均。保留维度1(通道)
keepdim=True,表示保留维度
X = torch.tensor([[[[1.0, 2.0],[0.0, 4.0]]]])
X.shape
# 按通道数求均值就是 把二维矩阵求和/矩阵大小。 如上方 1+2+0+4=7,7/4=1.75
mean = X.mean(dim=(0,2,3),keepdim=True)
mean,mean.shape
(tensor([[[[1.7500]]]]), torch.Size([1, 1, 1, 1]))
怎么理解使用大小为 1 的小批量应用批量归一化,我们将无法学到任何东西
1.请注意,如果我们尝试使用大小为 1 的小批量应用批量归一化,我们将无法学到任何东西。 这是因为在减去均值之后,每个隐藏单元将为 0。 所以,只有使用足够大的小批量,批量归一化这种方法才是有效且稳定的。 请注意,在应用批量归一化时,批量大小的选择可能比没有批量归一化时更重要”,请问怎么理解呢?这里的批量请问是网络训练的batch吗?
指batch_size,notebook上设置为256。如果batch_size为1,那么这个小批量的均值就是这个样本值本身,则样本值减去均值就为0了,也即文中所说的”每个隐藏单元将为 0“,所以batch_size要足够大,但也不要太大
参考链接:https://blog.csdn.net/qq_60567866/article/details/125608162