前端可以通过使用 JavaScript中的 fetch 或者 XMLHttpRequest 来下载文件;
- 使用fetch进行文件下载;
fetch('http://example.com/file.pdf').then(response => response.blob()).then(blob => {// 创建一个临时的URL对象const url = window.URL.createObjectURL(blob);// ...});
- 使用XMLHttpRequest进行文件下载;
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://example.com/file.pdf', true);
xhr.responseType = 'blob';xhr.onload = function() {if (xhr.status === 200) {// 获取服务器返回的blob数据const blob = xhr.response;// 创建一个临时的URL对象const url = window.URL.createObjectURL(blob);// ...}
};xhr.send();
上面两种方法均只展示到了创建临时的URL对象,临时URL可以视作下载链接,点击a标签,href指向URL,下载即可成功;
那创建了临时URL对象之后,该如何操作,这里用一个实例来说明:
// 调用createDownloadUrl函数
// data表示下载接口返回的数据流
this.createDownloadUrl(data, 'application/xml', file_name);
// createDownloadUrl函数
// 第1个参数表示数据流
// 第2个参数表示待下载文件的类型
// 第3个参数表示待下载文件的名称
createDownloadUrl(data: any, type: string, templateName: string) {const blob = new Blob([data], {type,});// 创建临时的URL对象const url = URL.createObjectURL(blob);this.downloadFileByUrl(url, templateName);
}downloadFileByUrl(url: string, templateName: string) {// 创建一个隐藏的<a>标签,设置其href属性为临时URLconst templateDownlod = document.createElement('a');const isSafariBrowser =navigator.userAgent.indexOf('Safari') !== -1 &&navigator.userAgent.indexOf('Chrome') === -1;if (isSafariBrowser) {templateDownlod.setAttribute('target', '_blank');}templateDownlod.setAttribute('href', url);templateDownlod.setAttribute('download', templateName); // 设置下载的文件名templateDownlod.style.visibility = 'hidden';document.body.appendChild(templateDownlod);templateDownlod.click();// 清理临时的URL对象URL.revokeObjectURL(url);// 移除a标签document.body.removeChild(templateDownlod);
}
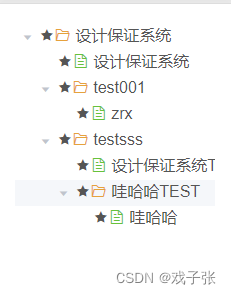
下载展示结果: