排序算法介绍
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列
粗暴理解
将杂乱无章的数据元素,通过一定的方法按照关键字顺序排列的过程叫做排序
排序分内部排序和外部排序,若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序
反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序
十大经典排序分别是冒泡排序,插入排序,选择排序,希尔排序,计数排序,基数排序,桶排序,快速排序,归并排序和堆排序。
算法的分类
十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。

常见的排序
-
冒泡排序(Bubble Sort):这是一种简单的排序算法,它多次遍历待排序的元素,每次比较相邻的两个元素并交换顺序,直到整个序列有序。
-
插入排序(Insertion Sort):插入排序通过逐步构建有序序列,将未排序的元素逐个插入到已排序的序列中的适当位置。
-
选择排序(Selection Sort):选择排序每次从待排序的元素中选择最小(或最大)的元素,然后将其放置在已排序部分的末尾。
-
快速排序(Quick Sort):快速排序是一种高效的分治算法,通过选择一个基准元素,将序列分为两个子序列,分别对子序列进行排序,然后合并结果。
-
归并排序(Merge Sort):归并排序也是一种分治算法,它将序列分为较小的子序列,分别对子序列进行排序,然后将排序后的子序列合并为一个整体有序序列。
-
堆排序(Heap Sort):堆排序利用堆数据结构来进行排序,通过构建最大(或最小)堆来实现元素的有序排列。
-
基数排序(Radix Sort):基数排序根据元素的位数进行排序,从低位到高位依次排序,逐渐得到有序结果。
-
计数排序(Counting Sort):计数排序适用于一定范围内的整数排序,它通过统计每个元素出现的次数来实现排序。
排序的稳定性
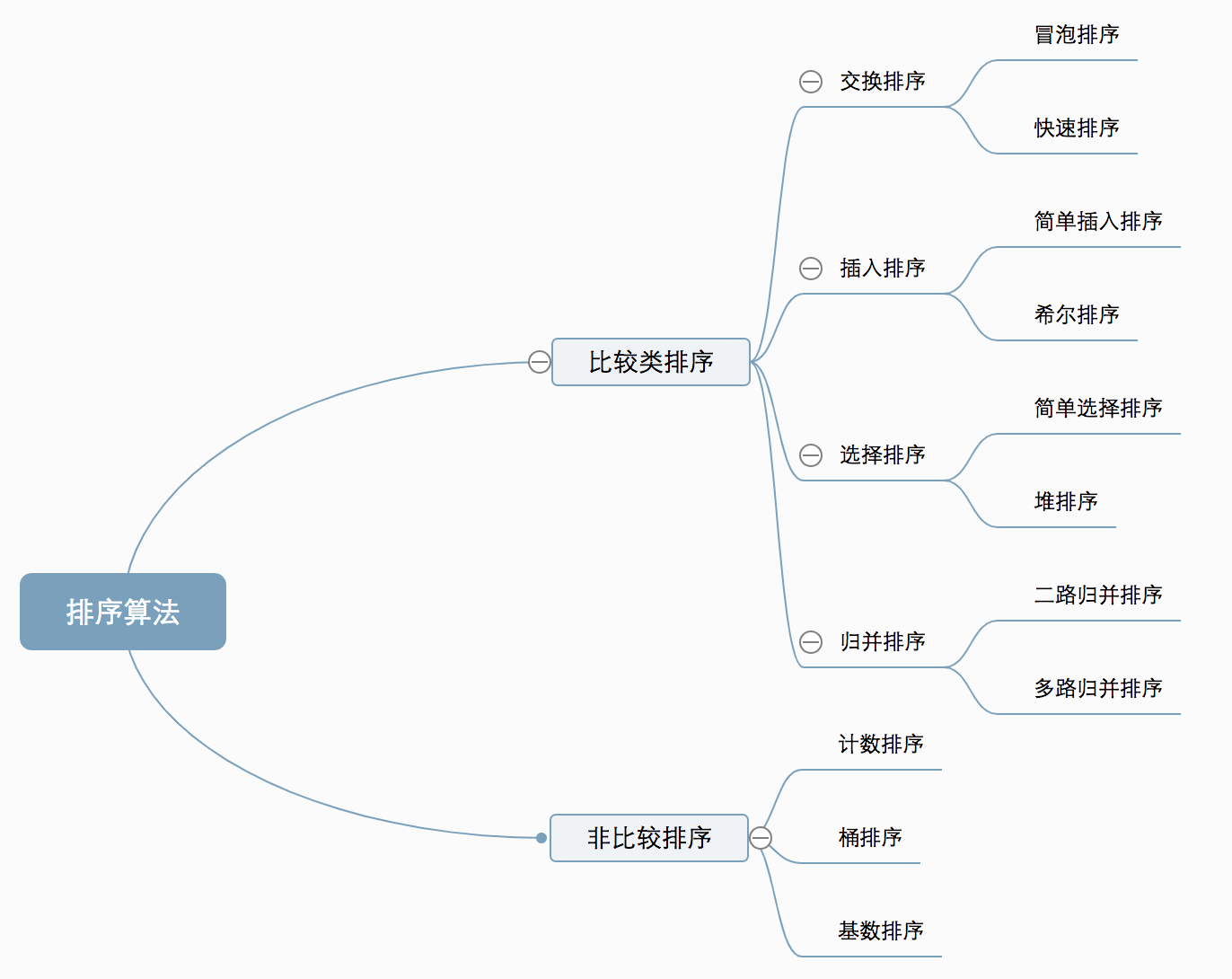
排序按照稳定性分为稳定的排序算法和不稳定的排序算法
- 快速排序,堆排序,选择排序和希尔排序是不稳定的排序算法;
- 基数排序,冒泡排序,插入排序,计数排序,归并排序和桶排序为稳定的排序算法。
-
稳定排序:假设在待排序的文件中,存在两个或两个以上的记录具有相同的关键字,在
用某种排序法排序后,若这些相同关键字的元素的相对次序仍然不变,则这种排序方法
是稳定的。
-
不稳定排序:假设在待排序的文件中,存在两个或两个以上的记录具有相同的关键字,在用某种排序法排序后,若这些相同关键字的元素的相对次序发生了变化,则这种排序方法是不稳定的。

排序的作用
-
搜索和查找操作的优化: 排序可以使数据按照一定的顺序排列,从而在执行搜索和查找操作时能够更快地定位目标元素。例如,如果一个列表是有序的,可以使用二分搜索等算法来加速查找操作。
-
数据的可视化和呈现: 排序可以将数据按照一定的顺序排列,从而使其更容易理解和分析。在图表、图形和报告中,有序的数据能够更好地传达信息。
-
提高算法和数据结构的效率: 许多算法和数据结构的性能依赖于输入数据的有序程度。通过使用排序,可以优化其他算法的执行效率,从而减少计算时间和资源消耗。
-
数据库查询: 数据库中的记录经常需要按照某种顺序进行查询和显示。排序可以帮助数据库系统更高效地处理这些操作,从而提高数据库的性能。
-
数据分析和统计: 在数据分析领域,排序可以帮助整理和分析大量数据,以便识别模式、趋势和异常。
-
合并操作: 排序可以使合并操作更加高效。例如,在合并两个有序列表时,可以使用合并算法,而不需要重新排序。
-
任务调度和优先级处理: 在操作系统和任务管理中,排序可以用于调度任务或处理不同优先级的任务。
-
排名和比赛结果: 排序可以用于排名竞赛结果、学术成就等,使得参与者按照某种标准进行排序。
-
数据压缩和加密: 某些数据压缩和加密算法利用了有序性,从而实现更高效的压缩和加密过程。








![[足式机器人]Part4 机械设计 Ch00/01 绪论+机器结构组成与连接 ——【课程笔记】](https://img-blog.csdnimg.cn/74d59e1eaea643a8b8721b6172615477.png)

