今天我们来学习DeepLearning.AI的在线课程:Building Generative AI Applications with Gradio,该课程主要讲述利用gradio来部署机器学习算法应用程序, 今天我们来学习第一课:Image captioning app,该课程主要讲述如何从图片中读取图片的内容信息,如下图所示:

今天我们会使用huggingface的Salesforce/blip-image-captioning-base模型来实现对图片内容的读取,blip-image-captioning-bas是一个用1400W参数训练出来的模型,该模型在huggingface的大小有990M,有两种方式使用该模型,一种是通过API调用的方式,前提是必须在云环境中事先部署好该模型的应用服务,然后提供api key和 Inference Endpoint来供调用,这种方式不占用本地存储空间资源,但会占用网络资源,第二种方式是将blip-image-captioning-bas模型下载到本地,这样就无需访问网络,离线也能使用,缺点是会占用本地存储空间和内存。这里我们会对重点讲解第二种方式,对于第一种方式我也会讲解调用api的方法,至于在云环境中部署blip-image-captioning-bas模型需要读者自行去研究。
方法一:API调用
当我们在云环境中部署要blip-image-captioning-bas的应用程序以后,我们会得到一个访问模型服务的地址也就是endpoint_url和一个huggingface的api key。下面我们就利用api key 和endpoint_url来实现图片内容的读取,首先我们将api_key和endpoint_url存储在一个本地配置文件.env中,然后在代码中我们利用python的os包来读取这个配置文件内的api_key和endpoint_url的信息:
import os
import io
import IPython.display
from PIL import Image
import base64
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
hf_api_key = os.environ['HF_API_KEY']接下来我们来实现读取图片内容的函数get_completion,该函数通过参数ENDPOINT_URL和hf_api_key 来加载云端的应用服务然后读取web图片内容
# Helper functions
import requests, json#Image-to-text endpoint
def get_completion(inputs, parameters=None, ENDPOINT_URL=os.environ['HF_API_ITT_BASE']): headers = {"Authorization": f"Bearer {hf_api_key}","Content-Type": "application/json"}data = { "inputs": inputs }if parameters is not None:data.update({"parameters": parameters})response = requests.request("POST",ENDPOINT_URL,headers=headers,data=json.dumps(data))return json.loads(response.content.decode("utf-8"))接下来我们在jupyter notebook中测试一下get_completion函数,这里我们给出一个web图片的url地址,然后调用get_completion来实现web图片内容的读取:
image_url = "https://free-images.com/sm/9596/dog_animal_greyhound_983023.jpg"
display(IPython.display.Image(url=image_url))
get_completion(image_url)
这里我们看到对于像上面这张图片,模型返回的信息是 :there is a dog wearing a santa hat and scarf 翻译成中文就是:一只狗戴着圣诞老人的帽子和围巾,这个信息相当准确。接下来我们使用gradio框架来开发一个基本blip-image-captioning-bas模型web服务的图片信息读取app,这里我们会调用gradio的Interface方法来实现我们的app, Interface 是 Gradio 的主要高级类,它允许您用几行代码围绕机器学习模型(或任何 Python 函数)创建基于 Web 的 GUI/演示。Interface方法包含至少三个主要的参数:
- fn:包装接口的函数。 通常是机器学习模型的预测函数。 函数的每个参数对应于一个输入组件,并且函数应返回单个值或值的元组,元组中的每个元素对应于一个输出组件。
- inputs:单个 Gradio 组件或 Gradio 组件列表。 组件可以作为实例化对象传递,也可以通过其字符串快捷方式引用。 输入组件的数量应与 fn 中参数的数量相匹配。 如果设置为 None,则仅显示输出组件。
- outputs:单个 Gradio 组件或 Gradio 组件列表。 组件可以作为实例化对象传递,也可以通过其字符串快捷方式引用。 输出组件的数量应与 fn 返回的值的数量相匹配。 如果设置为 None,则仅显示输入组件。
import gradio as gr def image_to_base64_str(pil_image):byte_arr = io.BytesIO()pil_image.save(byte_arr, format='PNG')byte_arr = byte_arr.getvalue()return str(base64.b64encode(byte_arr).decode('utf-8'))def captioner(image):base64_image = image_to_base64_str(image)result = get_completion(base64_image)return result[0]['generated_text']gr.close_all()
demo = gr.Interface(fn=captioner,inputs=[gr.Image(label="Upload image", type="pil")],outputs=[gr.Textbox(label="Caption")],title="Image Captioning with BLIP",description="Caption any image using the BLIP model",allow_flagging="never",examples=["christmas_dog.jpeg", "bird_flight.jpeg", "cow.jpeg"])demo.launch(share=True, server_port=55354)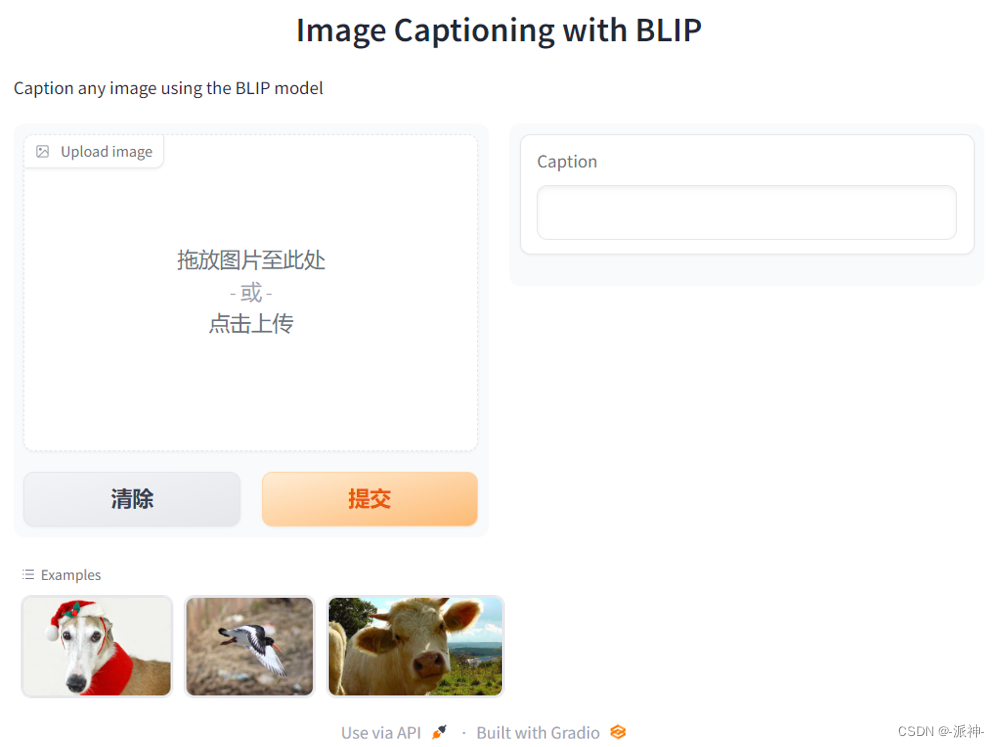
接下来我们点选底部Examples种的任意一张图片,然后点提交:

这里我们可以看到,当我们点选了底部Examples种的图片,然后再点提交按钮,右侧的Caption文本框中就会出现该图片内容的文本信息。
方法二:本地调用
要实现本地调用,我们需要将模型下载到本地,将模型下载到本地有2中方法,第一种方法是使用pipeline方法,当使用pipeline方法下载模型时,模型会被默认保存在 c 盘的当前用户文件夹的.cache文件夹内,这样对模型的管理非常的不方便,并且占用了c盘的空间,第二种方法使用手动方法是去huggingface的模型所在的页面,手动将所需要的模型文件及其配套文件都下载下来,发布在huggingface上的模型一般会有两个版本,一个是pytorch的版本,另一个是tensorflow的版本,如果你的机器上装的是pytorch只要下载pytorch版本的模型就可以了,如果装的是tensorflow,那就只要下载tensorflow版本的模型就可以了。
这里我主要是先通过pipeline的方法将模型及其配套文件全部自动下载下来,然后我将这些模型文件全部拷贝到指定的文件夹中进行统一管理,下面是通过pipeline方法来下载模型:
from transformers import pipelineget_completion = pipeline("image-to-text",model="Salesforce/blip-image-captioning-base")当执行了pipelien命令以后模型会被下载到本地c盘的当前用户文件夹下的.cache的子文件中,下面是模型在我机器上的默认保存路径:
C:\Users\tzm\.cache\huggingface\hub\models--Salesforce--blip-image-captioning-base\snapshots\89b09ea1789f7addf2f6d6f0dfc4ce10ab58ef84

这里我们看到pytorch_model.bin 就是模型文件,它有966M,不到1G, 接下来我把这些模型及其配套文件全部拷贝到程序的工作目录下的model文件夹下面,然后我们就可以加载本地模型了,同样我们用gradio来实现图片内容的读取,这里我们定义了一个模型存储路径的变量model_path,加载模型的代码来自于huggingface的模型主页:
from transformers import BlipProcessor, BlipForConditionalGeneration
import gradio as gr model_path = './model/' processor = BlipProcessor.from_pretrained(model_path)
model = BlipForConditionalGeneration.from_pretrained(model_path)def captioner(raw_image):inputs = processor(raw_image, return_tensors="pt") out = model.generate(**inputs)caption = processor.decode(out[0], skip_special_tokens=True)return captiongr.close_all()
demo = gr.Interface(fn=captioner,inputs=[gr.Image(label="Upload image", type="pil")],outputs=[gr.Textbox(label="Caption")],title="Image Captioning with BLIP",description="Caption any image using the BLIP model",allow_flagging="never",examples=["christmas_dog.jpeg", "bird_flight.jpeg", "cow.jpeg"])demo.launch(share=True, server_port=8080)
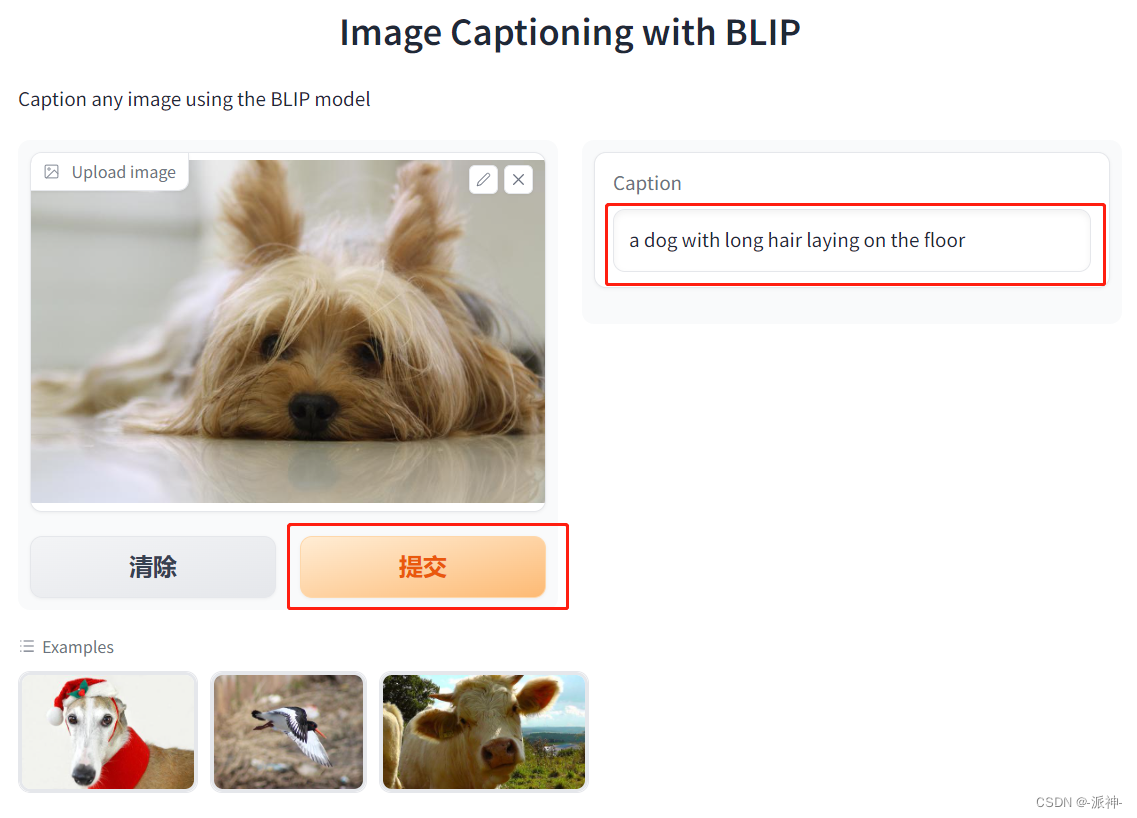
这里 当服务启动以后我们在浏览器中输入:http://127.0.0.1:8080 后就会打开app的页面,如上图所示,这次我们从外部加载了一张图片,然后点击提交按钮,右侧的Caption文本框就出现了该图片内容的信息。
总结
今天我们学习了如何通过blip-image-captioning-bas模型来读取图片内容信息,使用该模型一般有两种方法,一种是api调用的方式,但是需要在云端部署模型的应用程序,另一种是将模型下载到本地,然后在本地加载模型,两种方法都有各自的优缺点。另外我们还学习了如何使用gradio来开发一个基于blip-image-captioning-bas模型的读取图片内容的web app,同时我们还学习了gradio的主要方法Interface及其主要参数。希望今天的内容对大家学习gradio有所帮助。
参考资料
Gradio
Salesforce/blip-image-captioning-base · Hugging Face
Inference Endpoints - Hugging Face
Gradio Interface Docs
https://arxiv.org/pdf/2201.12086.pdf







![[git] git基础知识](https://img-blog.csdnimg.cn/fc5274d6c7af4208bd83544644ef01bc.png)