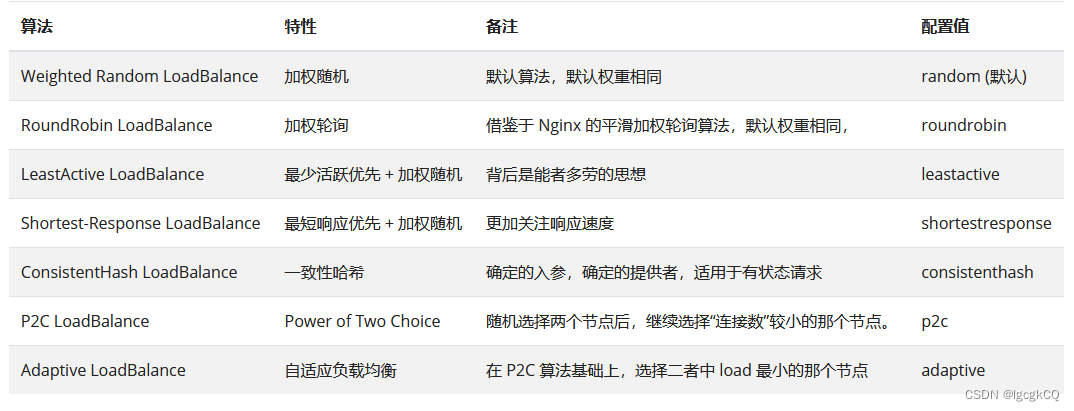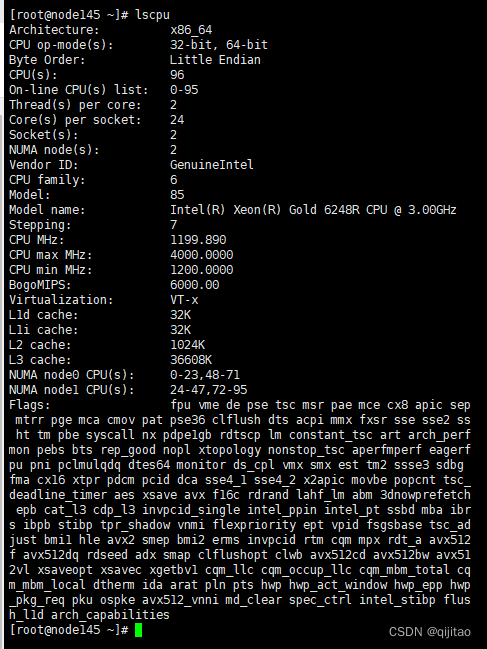
$ lscpu
Architecture: x86_64 #架构
CPU op-mode(s): 32-bit, 64-bit #运行方式
Byte Order: Little Endian #字节顺序
CPU(s): 96 #逻辑cpu数
On-line CPU(s) list: 0-95 #在线cpu
Thread(s) per core: 2 #每个核包含线程数(在linux中线程等于逻辑cpu,即运行程序的最小物理单元)
Core(s) per socket: 24 #每个CPU插槽(或物理CPU器件)包含核心数
Socket(s): 2 #主板上CPU插槽数(或物理CPU器件数量)
NUMA node(s): 2 #代表内存架构,是Non-uniform memory access的缩写,这里代表2个内存控制器,但是NUMA node和socket不是直接对应的,具体布局见最后两个参数,每个主板的布局可能不同。
Vendor ID: GenuineIntel #CPU厂商ID
CPU family: 6 #CPU系列
Model: 85 #型号编号
Model name: Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz #型号名称
Stepping: 7 #步进
CPU MHz: 1199.890 #默认主频
CPU max MHz: 4000.0000 #最大超频
CPU min MHz: 1200.0000 #最小频率
BogoMIPS: 6000.00
Virtualization: VT-x #CPU支持的虚拟化技术
L1d cache: 32K # 一级数据缓存
L1i cache: 32K # 一级指令缓存
L2 cache: 1024K # 二级缓存
L3 cache: 36608K # 三级缓存
NUMA node0 CPU(s): 0-23,48-71 # 逻辑cpu0-28和48-71在NUMA node0上;
NUMA node1 CPU(s): 24-47,72-95 #逻辑cpu24-47和72-95在NUMA node1上。
CPU(s)= Thread(s) per core * Core(s) per socket * Socket(s);
在本服务器中,96=2*24*2.
为了彻底理解上面的参数,有必要了解处理器架构。
流水线和指令级并行
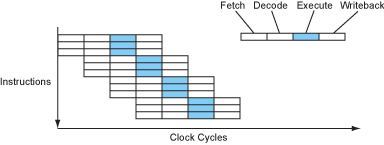
指令在处理器中是一个接一个的执行的,对吗?不完全对。这样的说法可能是直观的,但是并不是事实,实际上,从80年代开始,CPU就不再是完全顺序执行每个指令了。现代处理器可以同时执行不同指令的不同阶段,甚至有的处理器也可以完全同时地执行多个指令。
让我们来看一看一个简单的四级流水线是怎么构成的。指令被分成四个部分:取指、译码、执行和写回。
如果CPU完全顺序执行,那么每条指令需要花费4个周期才能执行完毕,IPC=0.25(Instruction per cycle)。当然,古老一点的时期更喜欢使用CPI,因为当时的处理器普遍不能做到每周期执行一条指令。但是现在时代变了,你能接触到的任何一个桌面级处理器都可以在一个周期内执行一条、两条甚至是三条指令。
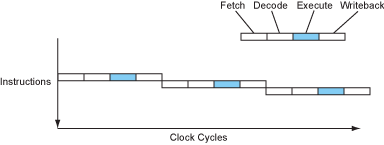
顺序执行的处理器
正如你所看到的,实际上CPU内负责运算的组件(ALU)十分的悠闲,甚至只有25%的时间在干活。什么?怎么压榨ALU?我看你很有资本家的天赋嘛…
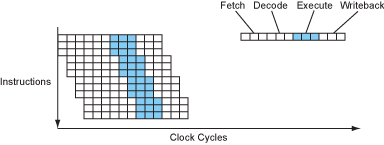
好吧,现代处理器确实有手段压榨这些ALU(对,现代处理器也不止一个ALU)。一个很符合直觉的想法就是既然大部分的阶段CPU都不是完全占用的,那么将这些阶段重叠起来就好了。确实,现代处理器就是这么干的。
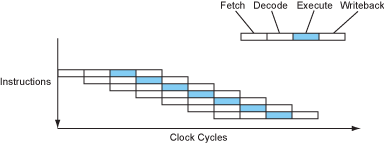
流水线执行的处理器
现在我们的处理器大多数时候一个周期可以执行一条指令了,看起来不错!这已经是在没有增加主频的情况下达到四倍的加速了。
从硬件的角度来看,每级流水线都是由该级的逻辑模块构成的,CPU时钟就像一个水泵,每次把信号(或者也可以说是数据)从一级泵到下一级,就像这样:
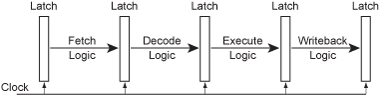
流水线微架构
事实上,现代处理器除了以上这样简单的结构,首先还有很多额外的ALU,比如整数乘法、加法、位运算、浮点数的各种运算等等,几乎每种常用的运算都有至少一个ALU。其次,如果前一条指令的结果就是下一条指令的操作数,那么为什么还要把数据写回寄存器呢?因此就出现了Bypass(前递)通路,用于在这种情况下直接将数据重新送到运算器的输入端口。综合起来,详细一点的流水线微架构应该长这样:
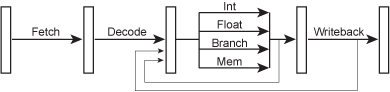
详细的流水线微架构
多发射——超标量处理器
既然整数的运算器和浮点数的运算器以及其它的的一些ALU互相之间都是没有依赖的,自己做自己的事情,那为什么不进一步压榨它们,让他们尽可能地一起忙起来呢?这就出现了多发射和超标量处理器。多发射的意思是处理器每个周期可以“发射”多于一条的指令,比如浮点运算和整数运算的指令就可以同时执行且互不干扰。为了完成这一点,取指和译码阶段的逻辑必须加强,这就出现了一个叫做调度器或者分发器的结构,就像这样:

超标量处理器微架构
或者我们来看一张实际的Intel Skylake架构的调度器,图中红圈的就是负责每周期“发射”指令的调度器。
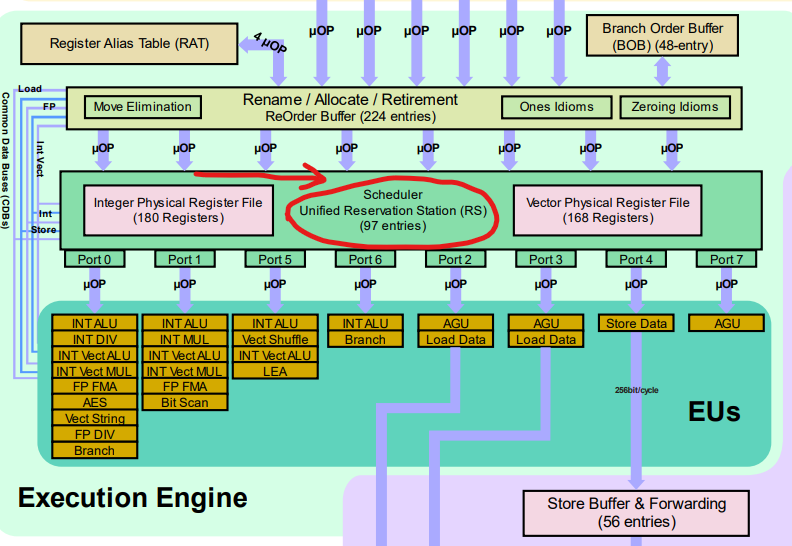
Skylake 调度器
当然,现在不同的运算有了不同的“数据通路”,经过的运算器也不同。因为不同的运算器内部可能也分不同的执行阶段,于是不同的指令也就有了不同的流水线深度:简单的指令执行得快一些,复杂的指令执行得慢一些,这样可以降低简单指令的延迟(我们很快就会涉及到)。某些指令(比如除法)可能相当耗时,可能需要数十个周期才能返回,因此在编译器设计中,这些因素就变得格外重要了。有兴趣的读者可以思考梅森素数在这里的妙用。
超标量处理器中指令流可能是这个样子的:
现代处理器一般都有相当多的发射端口,比如上面提到的Intel Skylake是八发射的结构,苹果的M1也是八发射的,ARM最新发布的N1则是16发射的处理器。
显式并行——超长指令集
当兼容性不成问题的时候(很不幸,很少有这种时候),我们可以设计一种指令集,显式地指出某些指令是可以被并行执行的,这样就可以避免在译码时进行繁复的依赖检验。这样理论上可以使处理器的硬件设计变得更加简单、小巧,也更容易取得更高的主频。
这种类型的指令集中,“指令”实际上是“一组子指令”,这使得它们拥有非常多的指令,进而每个指令都很长,例如128bits,这就是超长指令集(VLIW)这个名字的来源。
超长指令集处理器的指令流和超标量处理器的指令流十分的类似,只是省去了繁杂的取指和译码阶段,像这样:
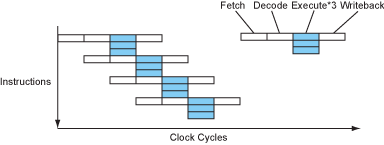
VLIW指令流
除了硬件结构,超长指令集处理器和超标量处理器十分的相似,尤其是从编译器的角度来看(我们很快也会谈到)。
但是,超长指令集处理器通常被设计成不检查依赖的,这就使得它们必须依赖编译器的魔法才能保证结果的正确,而且,如果发生了缓存缺失,那它们不得不整个处理器都停下来,而不是仅仅停止遇到缓存缺失问题的那一条指令。编译器会在指令之间插入“nops”(no operations)——即空指令,以保证有数据依赖的指令能够正确地执行。这无疑增加了编译器的设计难度和编译所需的时间,但是这同时节省了宝贵的处理器片上资源,通常也能有略好的性能。
现在仍在生产的现代处理器中并没有采用VLIW指令集的处理器。Intel曾经大力推行过的IA-64架构就是一个超长指令集(VLIW)架构,由此设计的“Itanium”系列处理器在当时也被认为是x86的继承者,但是由于市场对这个新架构并不感冒,所以最终这个系列没有发展下去。现代硬件加速最火热的方向是GPU,其实GPU也可以看作是一种VLIW架构的的处理器,只不过它将VLIW架构更进一步,使用“核函数”代替指令,大大增加了这种体系结构的可扩展性,有兴趣的读者也可以了解相关方面的内容。
多线程
在处理器设计中,有两种方法以较少的资源需求来增加芯片并行性:一种是尝试利用指令级并行性(ILP)的超标量技术;另一种是利用线程级并行性(TLP)的多线程方式。
超标量意味着在一个处理器芯片内以线程级并行性(TLP)同时执行多个线程的多个指令。有很多方法来支持芯片内的多个线程,即:
- 交叉多线程:交错发出不同线程的多个指令,也称为时间多线程(Temporal multithreading)。它可以进一步分为细粒度多线程与粗粒度多线程,这取决于交错发出的频率。细粒度多线程——例如在一个桶处理器——在每个周期后发出不同线程的指令,而粗粒度多线程仅在当前执行线程导致一些长延迟事件(如页错误等)时才切换到从另一线程的发出指令。粗粒度多线程对于线程之间较少的上下文切换是更常见的。例如,英特尔的Montecito处理器使用粗粒度多线程,而Sun的UltraSPARC T1使用细粒度多线程。对于每个内核只有一个流水线的处理器,交叉多线程是唯一可能的方法,因为它在每个周期最多发出一条指令。
- 同时多线程(SMT, https://en.wikipedia.org/wiki/Simultaneous_multithreading):在一个周期中发出多个线程的多个指令。处理器必须为超标量。
- 芯片上多处理器(CMP,Chip multiple processors,多核心处理器):将两个或多个处理器集成到一个芯片,每个处理器独立地执行线程。
- 任何多线程/SMT/CMP的组合。
区分它们的关键因素是查看处理器在一个周期中可以发出多少条指令以及指令来自哪些线程。例如,Sun Microsystems的UltraSPARC T1(2005年11月14日发布之前称为“Niagara”)是一个多核处理器,它结合了细粒度多线程技术而不是同时多线程,因为每个核心一次只能发出一条指令。
同时多线程SMT
在多核,虚拟或逻辑cpu之类的概念之前,在奔腾处理器时代,大多数计算机安装在他们的主板上的单个芯片相当大,我们称之为微处理器、处理器或简称CPU。只有少数企业计算机或需要更多处理能力的大型服务器可以在同一块板上安装2个或更多这些芯片:它们是多处理器系统。 这些芯片通过连接器或插槽与其他主板元件通信。 计算很简单:这么多连接器或插槽有一块板,一台电脑最多只能有这么多cpu。如果你想要更多的处理能力,你只需要寻找一个拥有更多处理器的主板板。
但随后英特尔意识到多处理器系统的不同处理器之间的通信效率非常低,因为它们必须通过系统总线完成,而系统总线通常以低得多的速度工作。这通常导致出现瓶颈,使得无法充分利用每个CPU提供的计算能力。
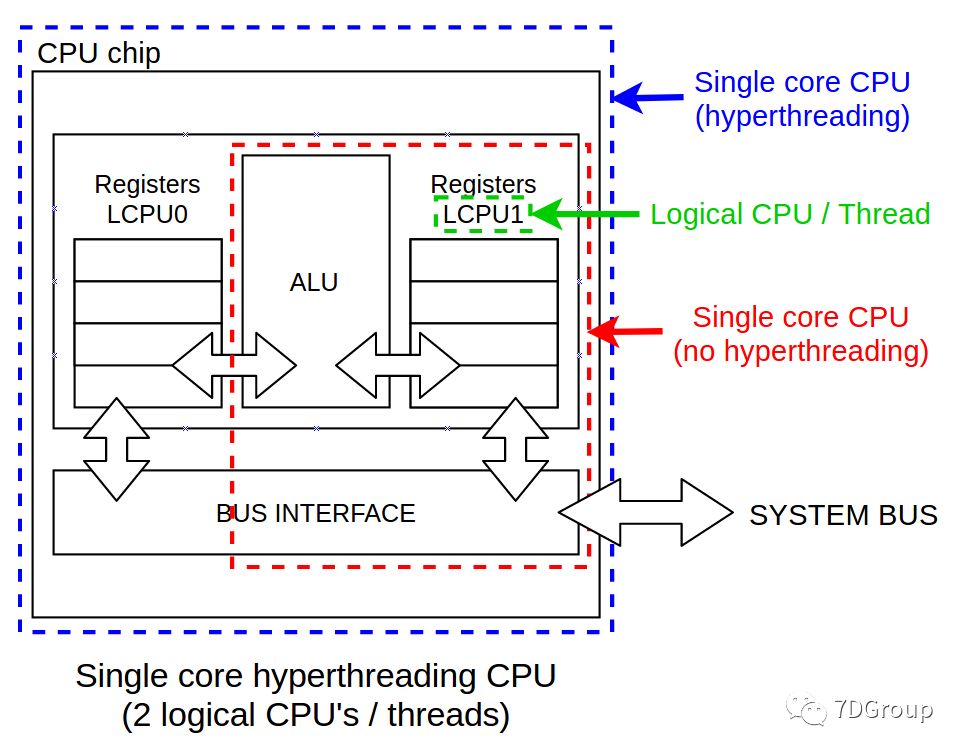
为了改善这种情况,intel开发了超线程技术(HT,hyperthreading),而更广泛的叫法是同时多线程(SMT,simultaneous multithreading)。如果程序中有足够并行的、没有相互依赖的指令,那么不同的程序之间肯定是没有数据依赖的(指令级数据依赖),那么在同一个物理核心上同时运行两个线程,互相填补流水线的空缺,岂不美哉?这就叫做同步多线程(SMT),它提供了线程级的并行化。这两个执行线程作为独立的处理单元呈现给操作系统,对操作系统而言仿佛CPU数量多了一倍似的,因此人们也把它俩叫做虚拟核心(或逻辑cpu)。
从硬件角度来说,同步多线程的实现需要将所有与运行状态有关的结构数量都翻倍,比如寄存器,PC计数器,MMU和TLB等等。幸运的是,这些结构并不是CPU的主要部分,最复杂的译码和分发器,运算器和缓存都是在两个线程之间共享的。
当然,真实的性能不可能翻倍,理论上限还是取决于运算器的数量,同步多线程只是能够将运算器更好地利用而已。因此在例如游戏画面生成这样地并行度本来就很高地任务中,SMT几乎没有任何地效果,反而因为偶尔地线程切换而带来一定地性能损失。
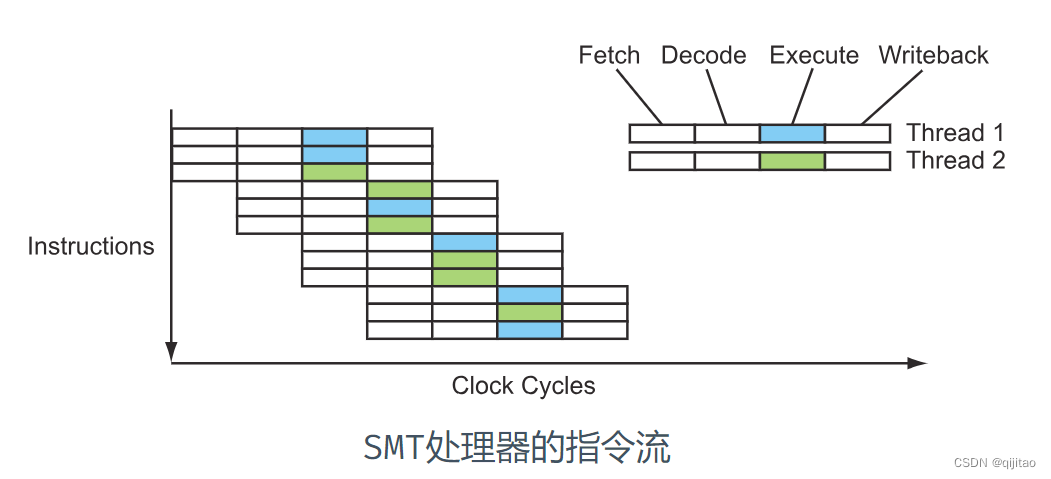
SMT处理器的指令流看起来大概是这样的:
Socket
它就是CPU插槽,如下图所示:
https://i.stack.imgur.com/sOqkS.jpg
NUMA nodes:
“NUMA 节点”代表内存架构;“NUMA”代表“非统一内存架构”。在您的系统中,每个插槽都连接到某些 DIMM (https://en.wikipedia.org/wiki/DIMM)插槽,每个物理 CPU 包都包含一个内存控制器,用于处理总 RAM 的一部分。因此,并非所有物理内存都可以从所有 CPU 平等地访问:一个物理 CPU 可以直接访问它控制的内存,但必须通过另一个物理 CPU 才能访问其余内存。在本系统中,逻辑内核 0–23 和 48–71 位于一个 NUMA 节点中,其余内核位于另一个节点中。NUMA 布局取决于内存控制器,而不是直接对应CPU插槽(直接);每个CPU插槽可以有一个内存控制器(如当前至强),或每个插槽有多个内存控制器,甚至可以使用外部内存控制器。
逻辑cpu和内存布局:
lscpu的输出表明我的 CPU 架构是英特尔 x86-64,还显示了 所有缓存的大小。 它没有显示的一件重要事情是缓存到 CPU 关联,即不同的缓存类型如何与每种缓存类型相关联 中央处理器。仍然可以通过传递 -p 标志来检索此信息 (或者,等效地,--parse)到 lscpu:
lscpu -p
这里列举了另一个笔记本处理器的输出
# The following is the parsable format, which can be fed to other
# programs. Each different item in every column has an unique ID
# starting from zero.
# CPU,Core,Socket,Node,,L1d,L1i,L2,L3
0,0,0,0,,0,0,0,0
1,1,0,0,,1,1,1,0
2,0,0,0,,0,0,0,0
3,1,0,0,,1,1,1,0其中各个参数的含义:
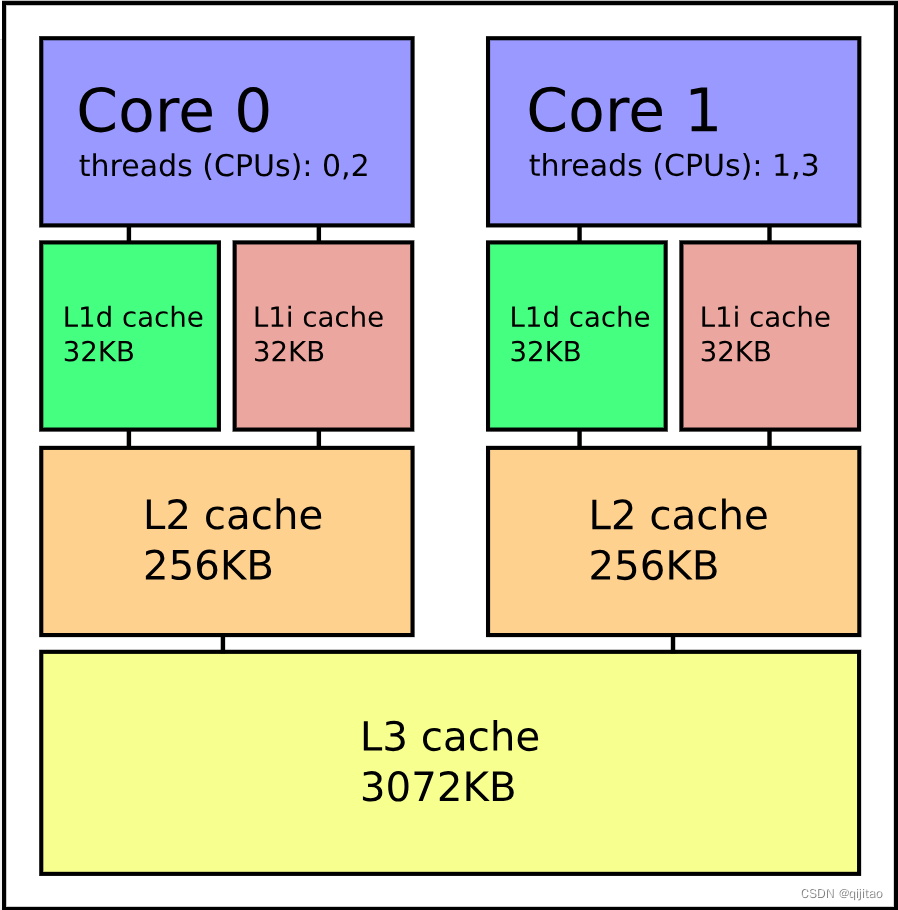
| 中央处理器核心(逻辑CPU) | CPU 索引,即线程的索引 执行;由于我的笔记本电脑总共有四个线程,因此这些值的范围从 0 到 3 |
| 物理核心(Core) | 物理核心的索引,其中 线程属于;由于我的笔记本电脑只有两个物理内核,我们看到 CPU 0 和 2 是线程 从内核 0 开始,而 CPU 1 和 3 是从内核 1 开始的线程 |
| 主板CPU插槽 (Socket) | 物理插座的编号 CPU 所属的;由于我的笔记本电脑只有一个物理插槽,因此所有 CPU 属于插槽 0(技术上是笔记本电脑 没有插槽,因为它们的 CPU 封装是表面安装的,但是 Linux 将这种类型的 CPU 包视为单个插槽) |
| NUMA node | 其 NUMA 套接字节点的编号 中央处理器属于;由于我的笔记本电脑没有单独的 NUMA 节点,因此所有 CPU 属于 NUMA 节点 0 |
| book number | 逻辑书号 的CPU(处理器书籍存在于极少数架构中); 我的笔记本电脑没有书籍,所以此字段对于所有 CPU 都是空的 |
| 一级数据缓存 (L1d) | 一级数据缓存的索引 与中央处理器相关联;我的笔记本电脑有两个 L1d 缓存:每个物理缓存一个 核心,因此来自同一内核的线程共享单个 L1d 缓存 |
| L1 指令高速缓存 (L1i) | 一级指令高速缓存的索引 与中央处理器相关联;我的笔记本电脑有两个 L1i 缓存:每个物理缓存一个 核心,因此来自同一内核的线程共享单个 L1i 缓存 |
| 二级缓存 | 与 关联的二级缓存的索引 中央处理器;我的笔记本电脑有两个二级缓存:每个物理缓存一个 核心,因此来自同一内核的线程共享单个二级缓存 |
| 二级缓存 | 与 关联的 L3 缓存的索引 中央处理器;我的笔记本电脑有一个由所有CPU共享的L3缓存,因此 所有这些的 L3 缓存索引均为 0 |
使用 lscpu 命令获取的 CPU 体系结构信息。
我的服务器获取的体系结构信息如下表所示:
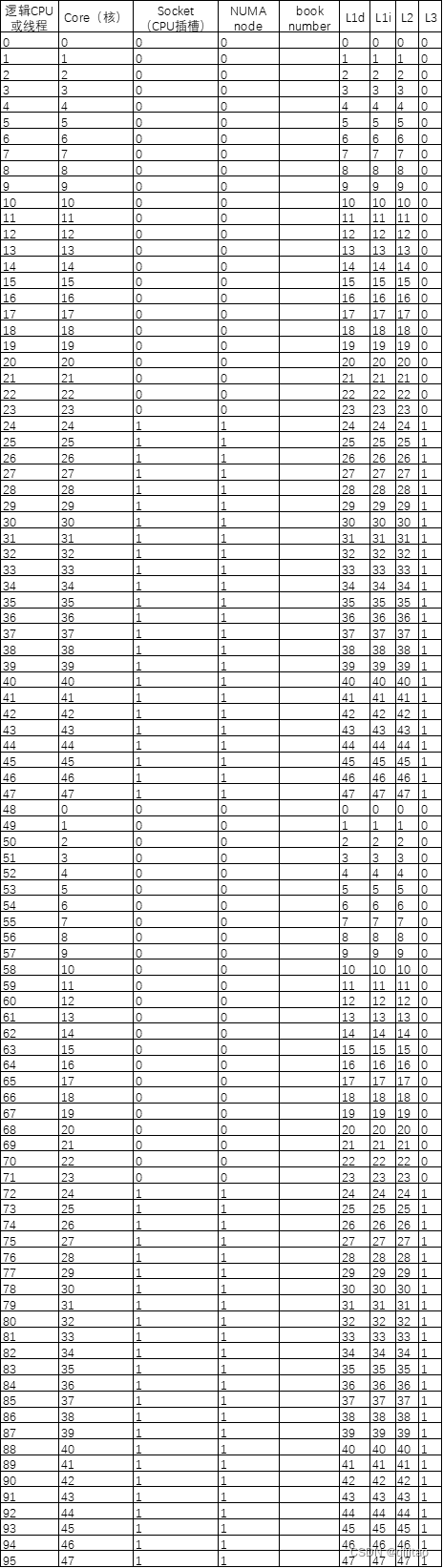
也就是core0包含逻辑cpu0和48,core1包含逻辑cpu1和49,以此类推。
参考文献:
cpu - Understanding output of lscpu - Unix & Linux Stack Exchange
Getting CPU architecture information with lscpu - Diego Assencio
现代处理器结构 | Easton Man's Blog
处理器三个概念理解及延伸(socket,core,thread,SMT,CMP,SMP)-liujunwei1234-ChinaUnix博客
https://en.wikipedia.org/wiki/DIMM
cpu - Understanding output of lscpu - Unix & Linux Stack Exchange