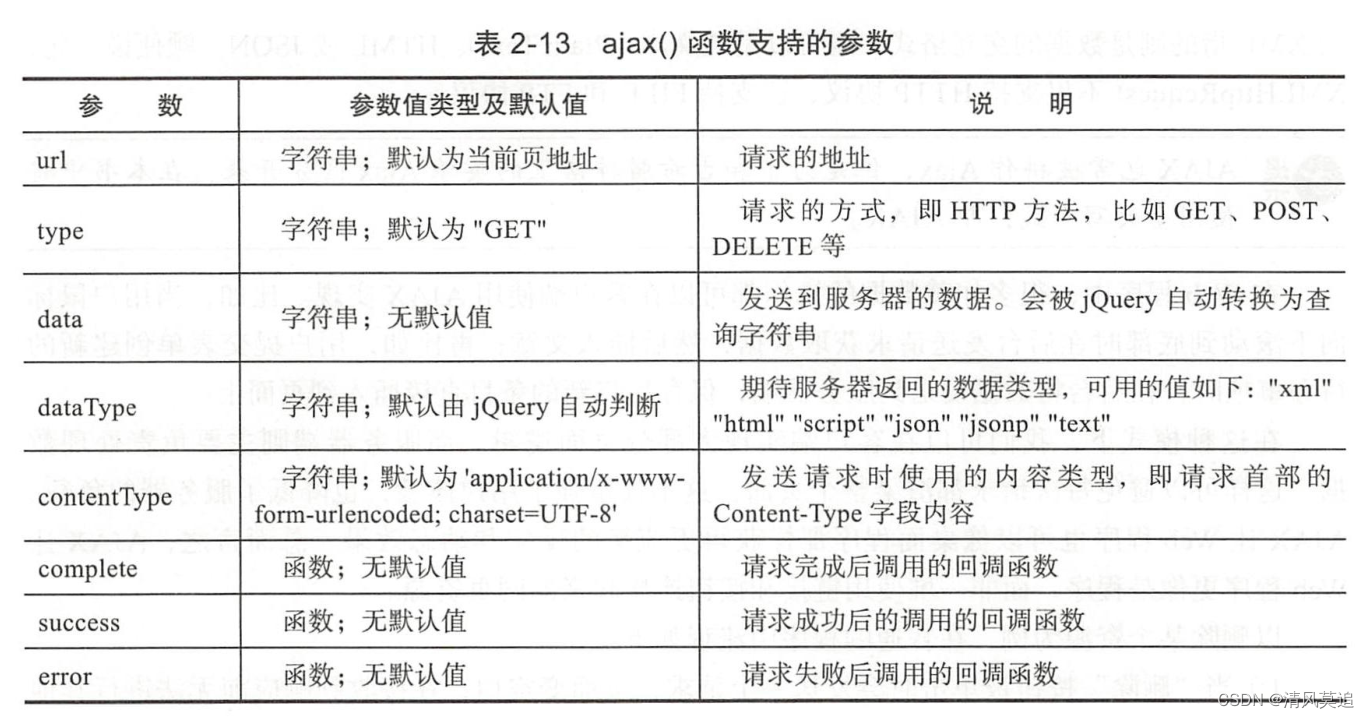
谱包络之pysptk和pyworld
谱包络可以直接用于语音的合成,常用的两个计算谱包络的库pysptk和pyword。
先看看代码:
一段语音x,采样率16000Hz
pysptk
import pysptkframe_length = 1024
hop_length = 80
order = 25
alpha = 0.41
frames = librosa.util.frame(x, frame_length=frame_length, hop_length=hop_length).astype(np.float64).T# Windowing
frames *= pysptk.blackman(frame_length)# Convert mel-cesptrum to MLSADF coefficients
mc = pysptk.mcep(frames, order, alpha)
b = pysptk.mc2b(mc, alpha);synthesizer = Synthesizer(MLSADF(order=order, alpha=alpha), hop_length)y_synthesized = synthesizer.synthesis(source_excitation, b)
world
import pyworld as pwnum_dim =25
sp = pw.cheaptrick(x, f0, temporal_positions, fs)
ap = pw.d4c(x, f0, temporal_positions, fs)
coded_sp = pw.code_spectral_envelope(sp, fs,num_dim)#合成时需要解码
fftlen = pw.get_cheaptrick_fft_size(fs)
decoded_sp = pw.decode_spectral_envelope(coded_sp, fs, fftlen)
y_synthesized = pw.synthesize(praatf0, sp, ap, fs, frame_period=5.0)
那这两个中的谱包络有什么区别呢?
pysptk中我们用到pysptk.mcep函数,pyworld中用到pyworld.code_spectral_envelope。
相关资料:https://github.com/r9y9/pysptk/issues/74
下面我们追溯到这两段代码的论文,来一探究竟。
pysptk.mcep
论文信息:
Tokuda, Keiichi et al. “Mel-generalized cepstral analysis - a unified approach to speech spectral estimation.” ICSLP (1994).
MCEP是一种广义的倒谱分析方法。
广义倒谱分析方法是对倒谱方法和线性预测方法的统一,其中模型谱根据参数γ的值从全极到倒谱连续变化。由于人耳在低频时具有高分辨率,引入了与模型频谱相似的特征,我们可以更有效地表示语音频谱。
基础理论
线性预测是一种公认的获得语音全极表示的方法。然而,在某些情况下,谱零点也很重要,需要更一般的建模过程。虽然倒谱建模可以用相等的权重表示极点和零点,但使用少量倒谱系数的倒谱方法高估了共振峰的带宽。为了克服这一问题,我们提出了广义倒谱分析方法。当参数γ分别为0和-1时,广义倒谱系数与倒谱系数和AR系数相同。因此,利用广义倒谱表示,我们可以根据γ的值得到连续变化模型谱,从全极谱到倒谱表示的谱。
由于人耳在低频时具有高分辨率,我们引入了与模型频谱相似的特征,可以更有效地表示语音频谱。梅尔广义倒谱表示的频谱,即变换后的广义倒谱,在适当选择参数α值的情况下,具有与人耳相似的频率分辨率。因此,我们期望混合广义倒谱系数对语音频谱表示有用。
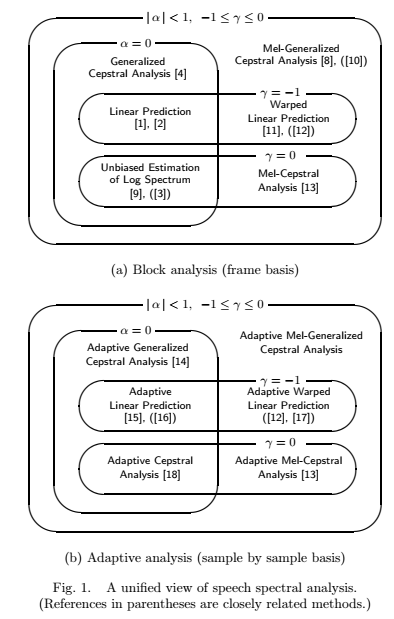
谱模型及其规范
广义对数函数[6]是对数函数的自然推广:
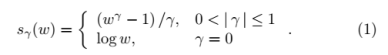
实序列x(n)的倒谱c(m)定义为,对数谱的傅里叶反变换,而广义倒谱Cα,γ(m)定义为在规整频率标度βα(ω)上计算的广义对数谱的傅里叶反变换。
广义倒谱:

其中X(ejω)是X(n)的傅里叶变换。规整频率尺度βα(ω)定义为全通系统的相位响应。
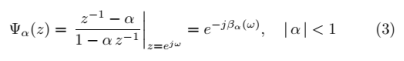
其中,
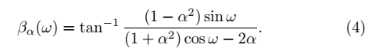
相位响应βα(ω)在适当选择α时,可以很好地近似于听觉频率尺度。
在本文中,我们假设一个语音频谱H(ejω)可以用M + 1维的 mel广义倒谱系数来建模,如下所示:
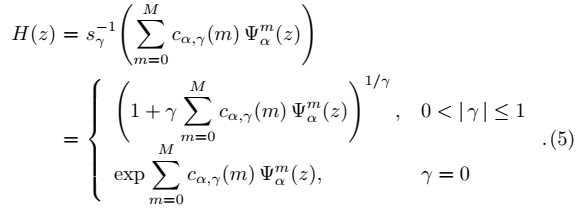
可以看出,
当(α,γ) =(0,1)时,模型谱采用全极表示形式,当(α,γ) =(0,-1)时,就是全零点。
当(α,γ) =(0,0)时,模型谱与倒谱表示的谱相同。(倒谱)
模型谱的形式与(α,γ)值的关系:
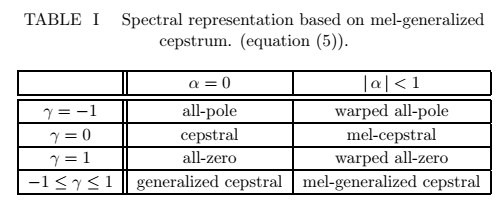
所以当α,γ取不同的值,可以得到更适合的谱模型。
采样率1KHz,α=0.35;
采样率16KHz,α=0.41;
其他采样率,α=0.5;
pyworld.code_spectral_envelope
论文信息:
Morise, Masanori et al. “Low-Dimensional Representation of Spectral Envelope Without Deterioration for Full-Band Speech Analysis/Synthesis System.” Interspeech (2017).
全频带语音是指采样频率在40khz以上,其奈奎斯特频率覆盖可听频率范围的语音。在以往的工作中,语音编码一般集中在采样频率低于16khz的窄带语音上。另一方面,统计参数语音合成目前使用的是全频带语音,使用的是语音参数的低维表示。本研究的目的在于实现全频带语音的无损编码。我们专注于高质量的语音分析/合成系统和梅尔-倒谱分析使用频率规整。在频率规整函数中,我们直接使用了三个听觉尺度。我们使用WORLD声码器进行了主观评估,发现最佳的维度数是50左右。频率规整对音质的影响不显著。
频谱包络中的语音编码
窄带语音编码的研究已经取得了一些进展。线性预测编码(Linear predictive coding, LPC)[11]是其中的主要算法之一,线谱对(line spectral pairs, LSP)[12]在电信系统中得到了广泛的应用。倒频谱[13]也是一种基本算法,以及几种改进算法。首先,提出了广义倒谱分析[14],几年后又提出了梅尔-倒谱分析[15,16]。
mel -广义倒谱分析[17]广泛应用于语音合成研究。它有一个频率规整参数,用户可以优化窄带语音的参数。在全频带语音的SPSS中,也有关于规整线性预测的研究[18]。提出了GlottDNN[7]。
在梅尔倒谱分析中,梅尔对数谱近似(mel-log spectrum approximation, MLSA)滤波器[19]可以直接从梅尔倒谱合成语音波形。相反,在基于声码器的合成中,我们是从解码的频谱包络线合成语音。因此,我们建议在听觉尺度的基础上直接使用频率规整函数。编码的目的是为全频带语音分析/合成系统获得无损的频谱包络。
具体流程:

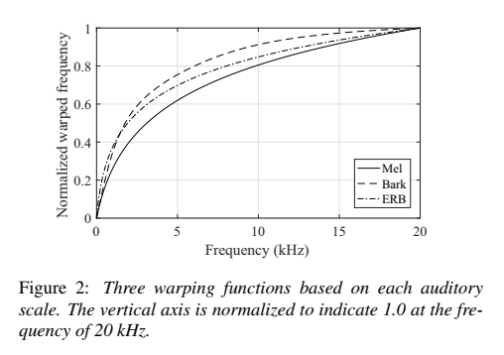
1.在频率规整中,有三种基于听觉尺度(梅尔、BARK、ERB尺度)的规整函数。
(1) Mel尺度:是最流行的尺度,是对音高的感知音阶。

(2)BARK尺度:是一种主观测量响度的心理声学量表。
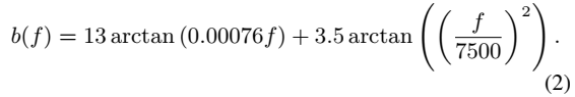
(3)等效矩形带宽(ERB)尺度:也是一种心理声学量表,它给出了人类听觉系统中过滤器带宽的近似值。
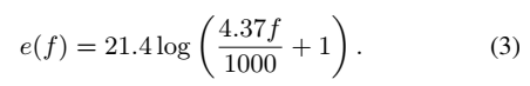
这三种规整函数与对数规整函数相似,但主要区别在于低频段,图2显示了它们之间的区别。垂直轴被归一化为在20khz频率下表示1.0。规整函数决定了从低频到高频的分辨率分布。
2.在规整的频率轴上进行等间隔采样
在规整的频率轴上以等间隔采样。这一步有三个参数:下限和上限频率以及采样次数。我们设置下限频率为40(跟根据F0的下限为40Hz),设置频率上限为20000Hz,这是人类可听到的频率范围的上限。
采样次数与梅尔倒谱维数的最大值有关,并影响解码频谱包络的精度。我们使用WORLD,全频带语音的FFT大小为2048。根据抽样理论,我们知道有效值是1025,所以我们使用1024,它接近这个值。用简单线性插值法计算采样所用频率处的值。
3.谱包络的低维表示
对采样序列进行离散余弦变换(DCT),然后进行提升提取低维系数。提取的维数是决定编码效率的参数。当维数设置为N时,提取0 ~ N-1的系数,也就是将谱包络压缩到N/1025。提取的系数通过反向DCT变换到规整频率轴上的对数谱包络。通过规整函数的反函数将规整的频谱包络重新扭曲到线性频率轴上。
4.输入功率谱
梅尔倒谱分析的输入通常是由FFT计算的对数功率谱。然而,即使谱包络是时间不变的,计算的功率谱也取决于时间位置[24]。在语音分析/合成系统中,这种时变分量会导致音质恶化。为了克服这个问题,提出了一种时域静态的谱包络表示。
STRAIGHT[5]是最流行的声码器之一,它具有获得时间静态频谱包络的算法,它利用补偿时间窗去除时变分量。TANDEM- straight[24,25]和WORLD分别使用TANDEM窗口和CheapTrick[26,27]。其他算法,如f0自适应多帧积分分析[28]也被提出去除了时变成分。
本文展示基于功率谱谱包络提取,与由STRAIGHT和WORLD估计的频谱包络提取相比,该表征获得了最好的音质。
总结
一个是mel广义谱表示,转换成MLSA声码器能够合成的语音参数,就能直接合成语音;一个是对语音频谱包络进行编码,需要再解码成普参数再合成语音。