什么是图像金字塔?
图像金字塔(Image> Pyramid)是一种用于多尺度图像处理和分析的技术,它通过构建一系列不同分辨率的图像,从而使得图像可以在不同尺度下进行处理和分析。图像金字塔在计算机视觉、图像处理和计算机图形学等领域中广泛应用,可以用于目标检测、特征提取、图像匹配、尺度不变特征变换(SIFT)等任务。
图像金字塔通常分为两种类型:高斯金字塔和拉普拉斯金字塔。
-
高斯金字塔(Gaussian Pyramid):高斯金字塔通过不断降采样(缩小)原始图像来构建,每一层图像都是前一层图像的一半大小。降采样可以通过平均像素值或使用高斯滤波器来实现。高斯金字塔在图像缩放、分割、模糊等任务中有用。
-
拉普拉斯金字塔(Laplacian Pyramid):拉普拉斯金字塔是通过从高斯金字塔中的每一层图像减去其上一层的上采样图像得到的。这一过程使得每一层图像包含了高频成分,即图像细节。拉普拉斯金字塔在图像增强、压缩、图像融合等方面有用。
使用图像金字塔,可以在不同尺度下对图像进行处理,从而能够更好地应对图像中存在的不同尺度的特征。例如,在目标检测中,可以使用图像金字塔来检测不同大小的目标物体。在SIFT等特征提取方法中,金字塔可以帮助提取出尺度不变的特征点。
总之,图像金字塔是一种重要的多尺度处理工具,能够在图像分析和处理中提供更丰富的信息,以适应不同尺度的特征和任务。
应用场景:
图像金字塔在计算机视觉、图像处理和计算机图形学等领域中有许多应用场景,下面列举了一些常见的应用场景:
-
目标检测:在目标检测任务中,物体可能以不同的尺度出现在图像中。使用图像金字塔可以在不同尺度下进行检测,从而识别不同大小的目标物体。
-
特征提取:一些特征提取方法,如尺度不变特征变换(SIFT)、尺度不变特征点检测(SURF)等,需要在不同尺度下提取特征。图像金字塔可以帮助提取出尺度不变的特征点和描述符。
-
图像匹配与对准:在图像配准和匹配任务中,图像可能存在缩放、旋转等变换。使用图像金字塔可以在不同尺度下进行匹配和对准,提高匹配的准确性和鲁棒性。
-
图像融合:将两幅图像融合成一幅图像时,可能需要考虑图像的尺度和细节。图像金字塔可以帮助在不同尺度下融合图像,实现平滑的过渡和自然的融合效果。
-
图像增强与去噪:在图像增强和去噪任务中,可以通过图像金字塔在不同尺度下对图像进行处理,实现局部增强和噪声抑制。
-
缩放与旋转:对于图像的缩放和旋转操作,图像金字塔可以帮助实现平滑的过渡和保留图像细节。
-
纹理分析:在纹理分析任务中,不同尺度下的纹理特征可能会影响分析结果。图像金字塔可以用于提取不同尺度下的纹理特征。
-
图像压缩:在图像压缩中,可以使用金字塔结构来分析图像的不同尺度特征,从而更有效地进行压缩编码。
实现原理:
图像金字塔是由一幅图像的多个不同分辨率的子图所构成的图像集合。该组图像是由单个图像通过不断地降采样所产生的,最小的图像可能仅仅有一个像素点。
图 11-1 是一个图像金字塔的示例。从图中可以看到,图像金字塔是一系列以金字塔形状排列的、自底向上分辨率逐渐降低的图像集合。
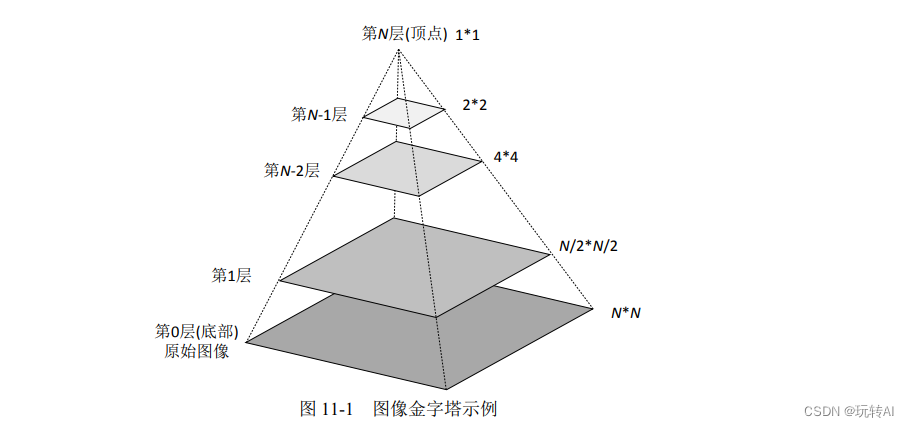
通常情况下,图像金字塔的底部是待处理的高分辨率图像(原始图像),而顶部则为其低分辨率的近似图像。向金字塔的顶部移动时,图像的尺寸和分辨率都不断地降低。通常情况下,每向上移动一级,图像的宽和高都降低为原来的二分之一。
图像金字塔是同一图像不同分辨率的子图集合,是通过对原图像不断地向下采样而产生的,即由高分辨率的图像(大尺寸)产生低分辨率的近似图像(小尺寸)。
最简单的图像金字塔可以通过不断地删除图像的偶数行和偶数列得到。例如,有一幅图像,其大小是 NN,删除其偶数行和偶数列后得到一幅(N/2)(N/2)大小的图像。经过上述处理后,图像大小变为原来的四分之一,不断地重复该过程,就可以得到该图像的图像金字塔。
也可以先对原始图像滤波,得到原始图像的近似图像,然后将近似图像的偶数行和偶数列删除以获取向下采样的结果。有多种滤波器可以选择。例如:
- 邻域滤波器:采用邻域平均技术求原始图像的近似图像。该滤波器能够产生平均金字塔。
- 高斯滤波器:采用高斯滤波器对原始图像进行滤波,得到高斯金字塔。这是
OpenCV 函数 cv2.pyrDown()所采用的方式。
高斯金字塔是通过不断地使用高斯金字塔滤波、采样所产生的,其过程如图 11-2 所示。
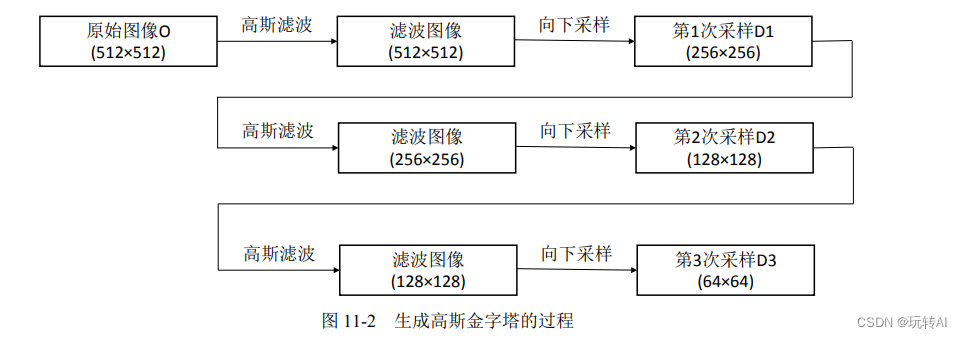
经过上述处理后,原始图像与各次向下采样所得到的结果图像共同构成了高斯金字塔。
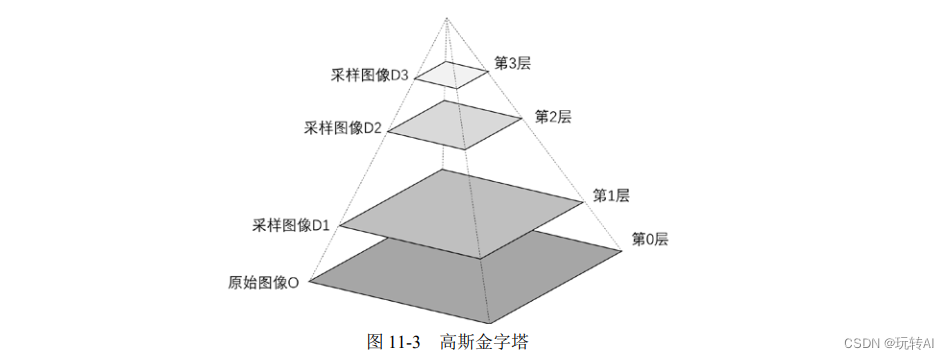
例如,可以将原始图像称为第 0 层,第 1 次向下采样的结果图像称为第 1 层,第 2 次向下采样的结果图像称为第 3 层,以此类推。上述图像所构成的高斯金字塔如图 11-3 所示。在本章中为了便于表述,统一将图像金字塔中的底层称为第 0 层,底层上面的一层称为第 1 层,并以此类推。
---------------------------------------------------------------------
在向上采样的过程中,通常将图像的宽度和高度都变为原来的 2 倍。这意味着,向上采样的结果图像的大小是原始图像的 4 倍。因此,要在结果图像中补充大量的像素点。对新生成的像素点进行赋值,称为插值处理,该过程可以通过多种方式实现,例如最临近插值就是用最邻
近的像素点给当前还没有值的像素点赋值。
有一种常见的向上采样,对像素点以补零的方式完成插值。通常是在每列像素点的右侧插入值为零的列,在每行像素点的下方插入值为零的行。在图 11-4 中,左侧是要进行向上采样的4 个像素点,右侧是向上采样时进行补零后的处理结果。

接下来,使用向下采样时所用的高斯滤波器(高斯核)对补零后的图像进行滤波处理,以获取向上采样的结果图像。但是需要注意,此时图像中四分之三像素点的值都是零。所以,要将高斯滤波器系数乘以 4,以保证得到的像素值范围在其原有像素值范围内。
例如,针对图 11-4 右侧的像素点,其对应的是 8 位图像,像素值的范围是[0, 255]。由于其中四分之三的像素点的值都为零,如果直接使用高斯滤波器对其进行卷积计算,会导致像素值的范围变为[0, 255*1/4]。
所以,要将所使用的高斯滤波器系数乘以 4,以保证得到像素值的范围仍旧在[0, 255]内。
或者,从另一个角度理解,在原始图像内每个像素点的右侧列插入零值列,在每个像素点的下一行插入零值行,将图像变为原来的两倍宽、两倍高。接下来,将补零后的图像用向下采样时所使用的高斯滤波器进行卷积运算。最后,将图像内每个像素点的值乘以 4,以保证像素值的范围与原始图像的一致。
通过以上分析可知,向上采样和向下采样是相反的两种操作。但是,由于向下采样会丢失像素值,所以这两种操作并不是可逆的。也就是说,对一幅图像先向上采样、再向下采样,是无法恢复其原始状态的;同样,对一幅图像先向下采样、再向上采样也无法恢复到原始状态。
pyrDown 函数及使用
OpenCV 提供了函数 cv2.pyrDown(),用于实现图像高斯金字塔操作中的向下采样,其语法形式为:
dst = cv2.pyrDown( src[, dstsize[, borderType]] )
其中:
- dst 为目标图像。
- src 为原始图像。
- dstsize 为目标图像的大小。
- borderType 为边界类型, 默认值为 BORDER_DEFAULT , 且这里仅 支 持BORDER_DEFAULT。
默认情况下,输出图像的大小为 Size((src.cols+1)/2, (src.rows+1)/2)。在任何情况下,图像尺寸必须满足如下条件:
|dst. width ∗ 2 − src. cols|≤2
|dst. height ∗ 2 − src. rows|≤2
cv2.pyrDown()函数首先对原始图像进行高斯滤波变换,以获取原始图像的近似图像。比如,高斯滤波变换所使用的核(高斯滤波器)为:

在获取近似图像后,该函数通过抛弃偶数行和偶数列来实现向下采样。
代码示例
使用函数 cv2.pyrDown()对一幅图像进行向下采样,观察采样的结果。
import cv2
o=cv2.imread("lena.png",cv2.IMREAD_GRAYSCALE)
r1=cv2.pyrDown(o)
r2=cv2.pyrDown(r1)
r3=cv2.pyrDown(r2)
print("o.shape=",o.shape)
print("r1.shape=",r1.shape)
print("r2.shape=",r2.shape)
print("r3.shape=",r3.shape)
cv2.imshow("original",o)
cv2.imshow("r1",r1)
cv2.imshow("r2",r2)
cv2.imshow("r3",r3)
cv2.waitKey()
cv2.destroyAllWindows()
使用 cv2.pyrDown()函数进行了 3 次向下采样,并且用 print()函数输出了每次采样结果图像的大小。cv2.imshow()函数显示了原始图像和经过 3 次向下采样后得到的结果图像。
运行结果:
o.shape= (512, 512)
r1.shape= (256, 256)
r2.shape= (128, 128)
r3.shape= (64, 64)
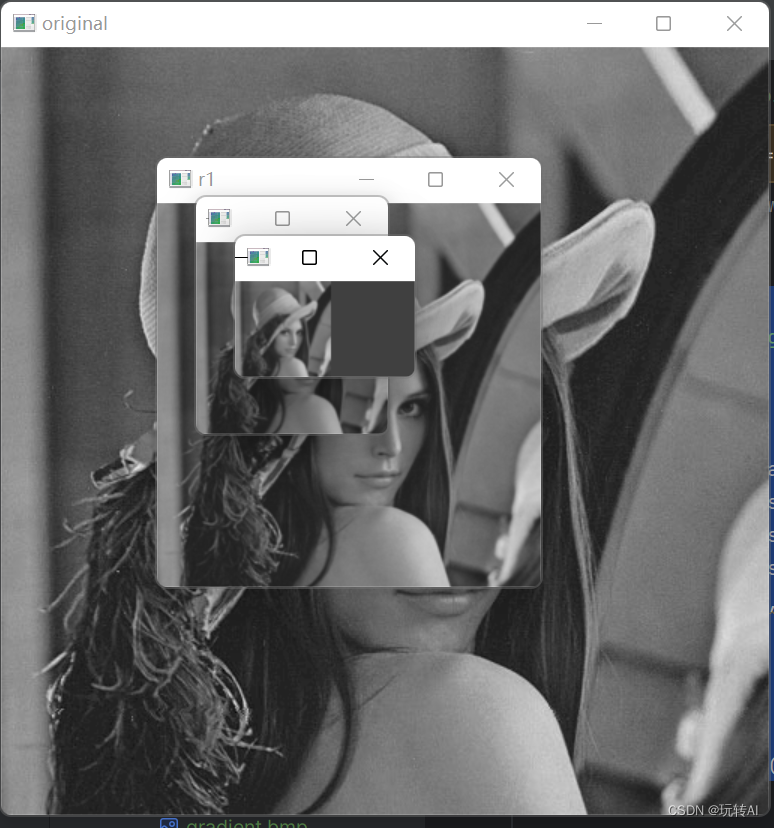
从上述结果可知,经过向下采样后,图像的行和列的数量都会变为原来的二分之一,图像整体的大小会变为原来的四分之一。这里为了便于比较,将它们调整成了等高格式展示。通过图像的比例关系,可以推断出各个图像的大致尺寸比例
pyrUp 函数及使用
OpenCV 中,使用函数 cv2.pyrUp()实现图像金字塔操作中的向上采样,其语法形式如下:
dst = cv2.pyrUp( src[, dstsize[, borderType]] )
其中:
- dst 为目标图像。
- src 为原始图像。
- dstsize 为目标图像的大小。
- borderType 为边界类型, 默认值为 BORDER_DEFAULT , 且这里仅 支 持BORDER_DEFAULT。
默认情况下,目标图像的大小为 Size(src.cols*2, src.rows*2)。
在任何情况下,图像尺寸需要满足下列条件:
|dst. width − src. cols ∗ 2|≤mod(dst. widh, 2)
|dst. height − src. rows ∗ 2|≤mod(dst. height, 2)
对图像向上采样时,在每个像素的右侧、下方分别插入零值列和零值行,得到一个偶数行、偶数列(即新增的行、列)都是零值的新图像 New。接下来,用向下采样时所使用的高斯滤波器对新图像 New 进行滤波,得到向上采样的结果图像。需要注意的是,为了确保像素值区间在向上采样后与原始图像保持一致,需要将高斯滤波器的系数乘以 4。
上一段描述的是 OpenCV 函数 cv2.pyrUp()所实现的向上采样过程。了解上述过程,有助于我们更好地理解和使用该函数。
但是,OpenCV 库的目的就是要让我们忽略这些细节,直接使
用函数 cv2.pyrUp()完成向上采样。所以,在刚开始的学习阶段,我们也可以先忽略这些细节。
代码示例:
import cv2
o=cv2.imread("lena.png")
r1=cv2.pyrUp(o)
r2=cv2.pyrUp(r1)
r3=cv2.pyrUp(r2)
print("o.shape=",o.shape)
print("r1.shape=",r1.shape)
print("r2.shape=",r2.shape)
print("r3.shape=",r3.shape)
cv2.imshow("original",o)
cv2.imshow("r1",r1)
cv2.imshow("r2",r2)
cv2.imshow("r3",r3)
cv2.waitKey()
cv2.destroyAllWindows()
运行结果:
o.shape= (512, 512, 3)
r1.shape= (1024, 1024, 3)
r2.shape= (2048, 2048, 3)
r3.shape= (4096, 4096, 3)
从上述输出结果可知,经过向上采样后,图像的宽度和高度都会变为原来的 2 倍,图像整体大小会变为原来的 4 倍。
采样可逆性的研究
图像在向上采样后,整体尺寸变为原来的 4 倍;在向下采样后,整体尺寸变为原来的四分之一。
图 11-7 展示了图像在采样前后的大小变化关系。一幅 MN 大小的图像经过向下采样后大小会变为(M/2)(N/2);一幅 MN 大小的图像经过向上采样后大小会变为(2M)(2N)。
一幅图像在先后经过向下采样和向上采样后,会恢复为原始大小,如图 11-8 所示。
虽然一幅图像在先后经过向下采样、向上采样后,会恢复为原始大小,但是向上采样和向下采样不是互逆的。也就是说,虽然在经历两次采样操作后,得到的结果图像与原始图像的大小一致,肉眼看起来也相似,但是二者的像素值并不是一致的。
代码示例:
使用函数 cv2.pyrDown()和 cv2.pyrUp(),先后将一幅图像进行向下采样、向上采样,观察采样的结果及结果图像与原始图像的差异。
import cv2
o=cv2.imread("lena.png")
down=cv2.pyrDown(o)
up=cv2.pyrUp(down)
diff=up-o #构造 diff 图像,查看 up 与 o 的区别
print("o.shape=",o.shape)
print("up.shape=",up.shape)
cv2.imshow("original",o)
cv2.imshow("up",up)
cv2.imshow("difference",diff)
cv2.waitKey()
cv2.destroyAllWindows()
运行结果:
o.shape= (512, 512, 3)
up.shape= (512, 512, 3)

- 左图是原始图像 o。
- 中间图是对图像 down(通过对原始图像 o 向下采样得到)进行向上采样后获得的结果图
像 up。 - 右图是对图像 up 和原始图像 o 进行减法运算的结果(差值)图像 diff。图像 diff 反映的是图像 up 和原始图像 o 的差值。
本例在尝试向大家说明,原始图像先后经过向下采样、向上采样后,所得到的结果图像与原始图像的大小一致,看起来也很相似,但是它们的像素值并不是一致的。