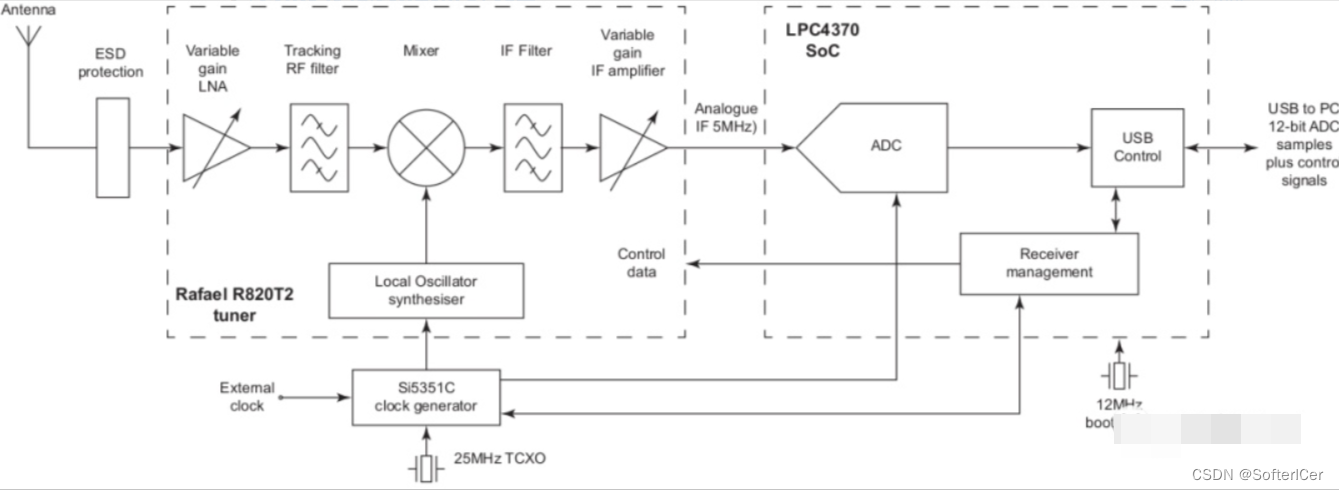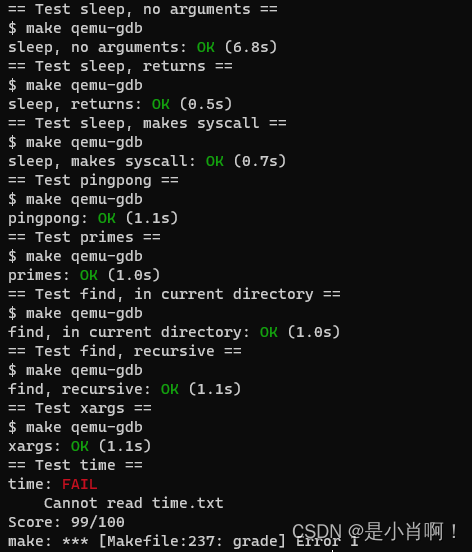
测试和运行
参考大佬
- 修改
grade-lab-util文件中的python为python3 - xv6.out这个文件的所有者可能是root,需要修改为用户,
sudo chown woaixiaoxiao xv6.out
每完成一个函数,执行下面的步骤 - 在Makefile中加入新增的程序
$U/_sleep\ make qemu,顺便可以自测一下命令是否有效./grade-lab-util sleep
sleep
要求
- 为
xv6实现sleep函数,用户可以指定暂停多少个tick - 在
user/sleep.c中实现,这个文件要自己创建
思路
- 首先根据argc和argv判断指令是否输入正确,并提取出sleep的tick数量
- 然后使用系统调用
sleep函数- 这里我一开始很疑惑,既然都有了一个sleep系统调用了,干嘛还要我们自己实现一个。
- 并且我发现只需要引用
user/user.h头文件就可以使用这个系统调用,但是我没有发现user/user.c文件,目前我还看不太懂这个系统调用是如何实现的。 - 看了一些博客后,发现后面会讲,所以现在就把这些系统调用当做黑盒子来用就行了。
- 系统调用必须通过程序来使用的,也就是说就算我们有了sleep系统调用,但是我们依然需要写一个比如说c语言程序sleep来调用这个系统调用
注意点
- 头文件的顺序是有讲究的,因为user.h中使用了types.h中定义的变量,因此必须也包含types.h并且需要放到user.h前面
代码实现
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int main(int argc, char** argv) {if (argc < 2) {printf("usage: sleep time_val...\n");exit(1);}int tick = atoi(argv[1]);sleep(tick);exit(0);
}pingpong
要求
- 在父子进程之间利用两个管道进行通信,每个管道负责一个方向
- 只需要传输一个字节的数据,父子进程在收到数据后应该打印信息
- 顺序上应该父进程先发送,子进程后发送
思路
- 按照题目要求的来就行了,顺序上通过read自带的阻塞就可以让子进程在收到父进程发送数据之后再发给父进程了
注意点
- 对于管道,可以看成是已经open的文件,不需要open,直接read和write
- read和write需要给出size,而c语言里的字符串往往是通过一个0来结尾的,那在调用read或者write时的size需要加上这个0吗?答案是不需要,只需要给出有效数据的size。而这个0只需要在我们创建buf数组的时候考虑即可
- 可以定义宏来表示0和1,这样在使用管道的时候更加清晰
实现
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"#define SIZE 1int main() {// p1 父写子读int p1[2];pipe(p1);// p2 子写父读int p2[2];pipe(p2);// 子进程if (fork() == 0) {// 子进程阻塞p1的写端,p2的读端close(p1[1]);close(p2[0]);char buf[SIZE + 1];read(p1[0], buf, SIZE);printf("%d: received ping\n", getpid());write(p2[1], buf, SIZE);exit(0);} else {// 父进程close(p1[0]);close(p2[1]);char buf[SIZE] = "1";write(p1[1], buf, SIZE);read(p2[0], buf, SIZE);printf("%d: received pong\n", getpid());}exit(0);
}
primes
题意
- 要我们输出35以内的所有质数(实验文档给的参考资料是求1000以内的,但是好像因为xv6资源的限制,搞不了这么多,所以只需要求35以内的)
- 需要用到一种很神奇的方法
- 我们会用到很多进程,每个进程之间用一个管道相连接
- 每个进程会收到上一个进程发来的很多数字,其中第一个数字一定是质数,后面的数字有两种情况
- 如果是第一个数字的倍数,那肯定不是质数,不需要管了
- 如果不是第一个数字的倍数,则传给下一个进程,让下一个进程去处理
思路
- 解题的方法以及比较明确了,关键是如何实现这个过程?
- 我们最开始只有一个main进程,而我们需要很多的进程,并且这些进程之间是串联的,最重要的是逻辑都一样,所以可以用递归
- 这些进程是通过管道进行通信的,那么最简单的方法就是将管道作为递归函数的参数进行传递,这样就把所有的进程给串起来了
注意点
- 因为xv6的文件描述符是有限的,所以我们最好在能够关闭管道的时候都给它关了
- 在我的实现中,递归程序很早的就fork了,但是因为在fork之前先执行了一个read操作,因此,不会导致无限增殖,一个进程想要fork,起码也需要它获得了一个值
代码实现
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"#define INT_SIZE 4
#define RD 0
#define WR 1
#define NULL 0void recursion(int p[]) {// 首先关闭写端close(p[WR]);// 读取base数字int base;int temp = read(p[RD], &base, INT_SIZE);// 压根没有输入到这个进程if (temp == 0) {return;}printf("prime %d\n", base);// 创建管道,并和子进程联动int p2[2];pipe(p2);if (fork() == 0) {recursion(p2);exit(0);}// 关闭读端close(p2[RD]);// 开始不断接受父进程的输入,判断之后传递给子进程int rec, res;while (1) {res = read(p[RD], &rec, INT_SIZE);// 父进程结束写了if (res == 0) {break;}// 如果这个数字不是base的倍数,那么写给子进程if (rec % base != 0) {write(p2[WR], &rec, INT_SIZE);}}// 写完了,关闭自己的写端close(p2[WR]);// 关闭父进程给的管道的读端close(p[RD]);wait(NULL);
}int main() {int p[2];pipe(p);// 子进程if (fork() == 0) {recursion(p);exit(0);}// 父进程close(p[RD]);for (int i = 2;i <= 35;i++) {write(p[WR], &i, INT_SIZE);}close(p[WR]);// 等待子进程结束wait(NULL);exit(0);
}find
题意
- 实现
find指令,find dir filename的作用是找到dir目录中(包括所有子目录中),所有文件名为filename的文件 - 因此,我们要做的就是取出dir目录的每一项,如果是文件,那就比较这个文件的名称,如果是目录,那我们就递归进去
思路
- hints里提示我们去看
ls.c文件是如何访问目录的- 首先,我们需要根据目录的路径打开目录。目录也是一个文件,所以方法和打开普通的文件一样,并且得到一个文件描述符
- 通过文件描述符去read,但是这个时候要用
dirent这个结构去读取每一个目录项 - 通过
dirent的name以及当前目录的path,可以构造出这个目录项的path - 通过这个目录项的
path和stat函数,可以把这个目录项的信息给读到stat结构中 - 通过
stat结构体的type可以区分目录和文件- 文件则直接比较名字
- 目录如果不是
.和..,那就递归进去
注意点
- 打开的文件描述符最好自己记得把它给关了
实现代码
#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/fs.h"
#include "user/user.h"#define O_RDONLY 0
#define MAX_PATH 512void search(char* dir, char* filename) {// 获取当前目录的文件描述符int fd = open(dir, O_RDONLY);// 不断读取目录项,进行判断// 这个p是用来拼接这个目录中的子项的路径的char buf[MAX_PATH];strcpy(buf, dir);char* p = buf + strlen(buf);*p = '/';p++;// 正式读取每一行,并根据目录还是文件进行讨论struct dirent de;struct stat st;while (read(fd, &de, sizeof(de)) == sizeof(de)) {// 无效if (de.inum == 0) {continue;}// 拼接出目录的这一项的pathmemmove(p, de.name, DIRSIZ);p[DIRSIZ] = 0;// 取出这一项的信息stat(buf, &st);// 如果是文件if (st.type == T_FILE) {// 文件名相同,打印pathif (strcmp(de.name, filename) == 0) {printf("%s\n", buf);}} else if (st.type == T_DIR) {// 这一项是目录,只要不是 . 或者 .. 那就递归进去if (strcmp(de.name, ".") != 0 && strcmp(de.name, "..") != 0) {search(buf, filename);}}}// 记得关闭文件描述符close(fd);
}int main(int argc, char** argv) {if (argc != 3) {printf("usage: find dir filename\n");exit(1);}char* dir = argv[1];char* filename = argv[2];search(dir, filename);exit(0);
}xargs
题意
- 实现xargs函数,
xargs a b代表执行a程序,a程序的第一个参数是b,xargs会从标准输入中按行读取,将每一行作为a的其他参数,假如读入了某一行是c d,那么说明a程序有三个参数,依次是b c d xargs按行读取的意思是,对于每一行,它都会读取这一行所有被空格分开的值,将它作为a程序的参数。假如有n行,就会执行n次a程序- 实验文档里给的示例
echo hello too | xargs echo bye- 这里面
|的作用是把它前面的运行结果给放到后面这个函数的标准输入中 - 在这个例子里,就是把
hello too作为一行放到了xargs函数的标准输入里,也就是说,如果xargs能够调用scanf函数,就可以读到hello too
- 这里面
思路
- 从标准输入中不断地读取,以每一行为单位进行fork和exec
- 每一行以
\n为结束符,实验文档推荐我们每一次读一个字节,这样比较好判断\n,可以通过read函数实现读取 - 读取的每个字节有三种情况
- 是空格,则说明空格前那个参数已经被读取完了,加入到之后要调用的exec函数的args数组中
- 是换行符,首先也要加入前面的参数,然后记得给args数组封尾,即放一个null在最后,之后fork,exec,并进入新一行的读取
- 如果read失败,说明读完了,跳出整个循环,wait等到所有子进程结束
注意点
- 我们不断从标准输入中读取,其实就是为了给exec函数准备参数数组,这里用args表示,一开始xargs的main函数的argv数组就包括了要执行的程序的一些信息,所以应该将其挪到args数组中
- 当我们成功从某一行中读取一个参数的时候,这里是把这个参数边读边存到input_line字符串中,不能直接将这个字符串放到args数组,因为这个字符串被重复使用,所以我们要进行深拷贝,这里手写了一个strdup函数完成这个效果
- 然后就是注意各种字符串的操作,要给它封住尾巴
- 最后通过这个操作等待所有子进程结束
while (wait(0) != -1)
实现代码
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"#define stdin 0
#define NULL 0
#define MAX_SIZE 1024
#define CHAR_SIZE 1char* strdup(char* p) {char* temp = (char*)malloc(strlen(p) + 1);memcpy(temp, p, strlen(p));return temp;
}int main(int argc, char* argv[]) {// 初始化我们要传递给execute函数的参数char* args[MAXARG + 2];for (int i = 1;i < argc;i++) {args[i - 1] = argv[i];}int arg_count = argc - 1;// 从标准输入一行一行地读char input_line[MAX_SIZE];while (1) {// 最外层的这个while循环,每循环一次代表要execute一次// 因此arg_count和p都应该重置,其中p用来操作input_linearg_count = argc - 1;char* p = input_line;// 用read从标准输入端读int res;while ((res = read(stdin, p, CHAR_SIZE)) > 0) {// 如果读入的既不是空格也不是换行,那就让p++,继续读入这个参数if (*p != ' ' && *p != '\n') {p++;// 读入的是空格,说明第一个参数已经完成了// 那么我们可以将这个参数写入args,并且修改p指针} else if (*p == ' ') {*p = '\0';args[arg_count] = strdup(input_line);arg_count++;p = input_line;// 读入的是换行,说明已经完全读完了// 存当前的这个参数到args,并且为args增加一个结尾标志null// 然后fork,exec} else if (*p == '\n') {*p = '\0';args[arg_count] = strdup(input_line);arg_count++;args[arg_count] = NULL;// 子进程,去execif (fork() == 0) {exec(args[0], args);exit(0);}// 父进程,现在应该去读新的一行了,breakbreak;}}// 读完了if (res <= 0) {break;}}// 等待所有子进程结束while (wait(0) != -1) {}exit(0);
}