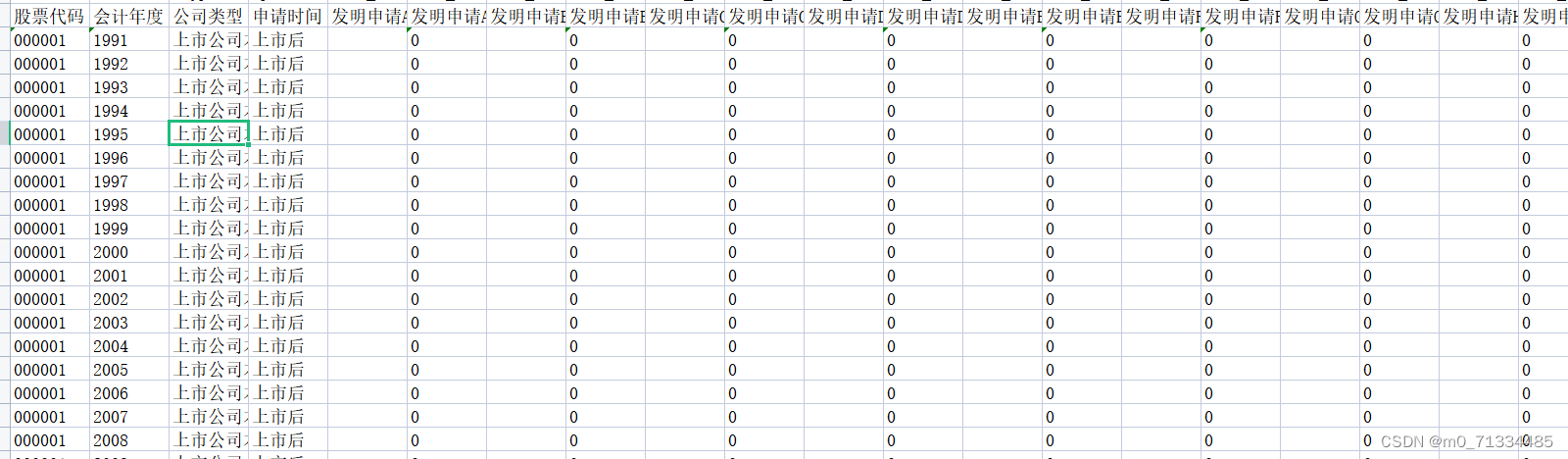
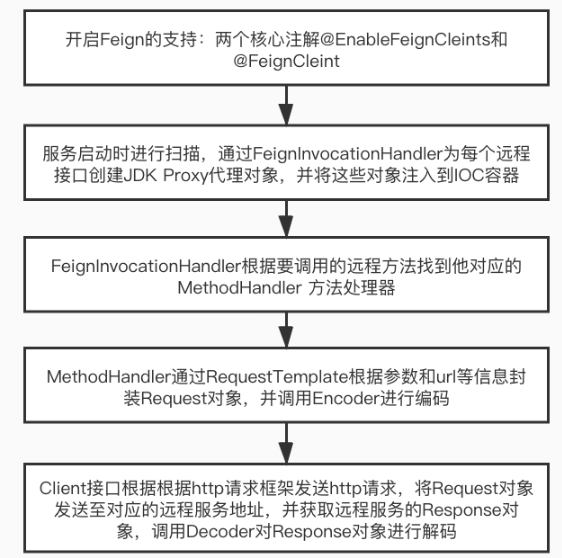
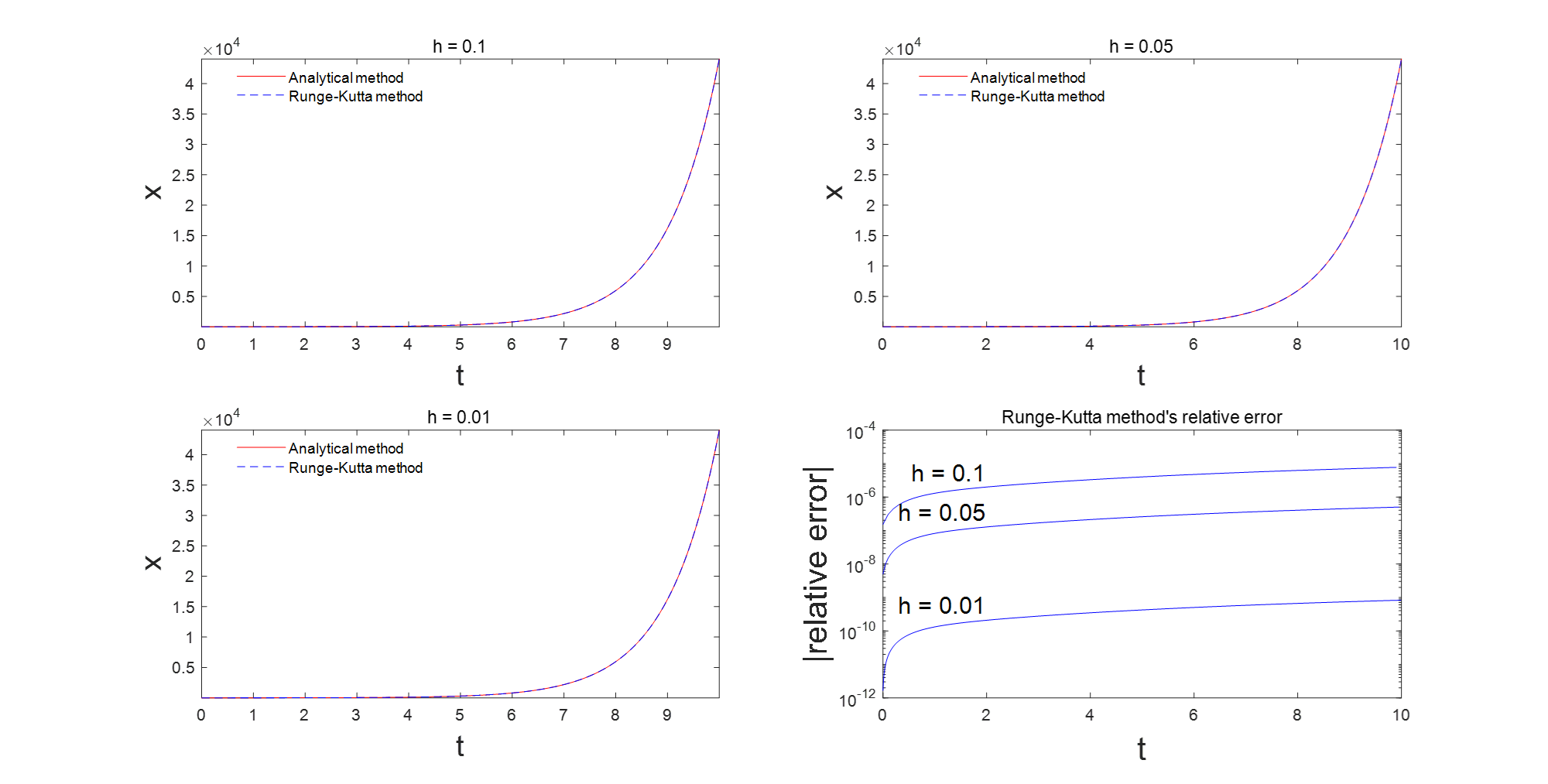
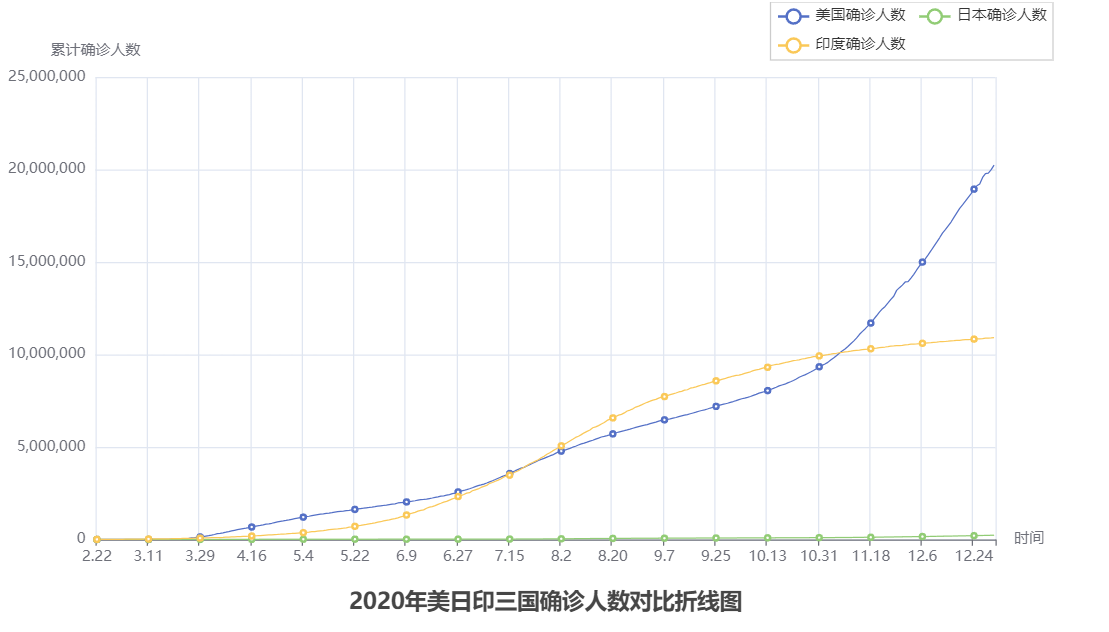
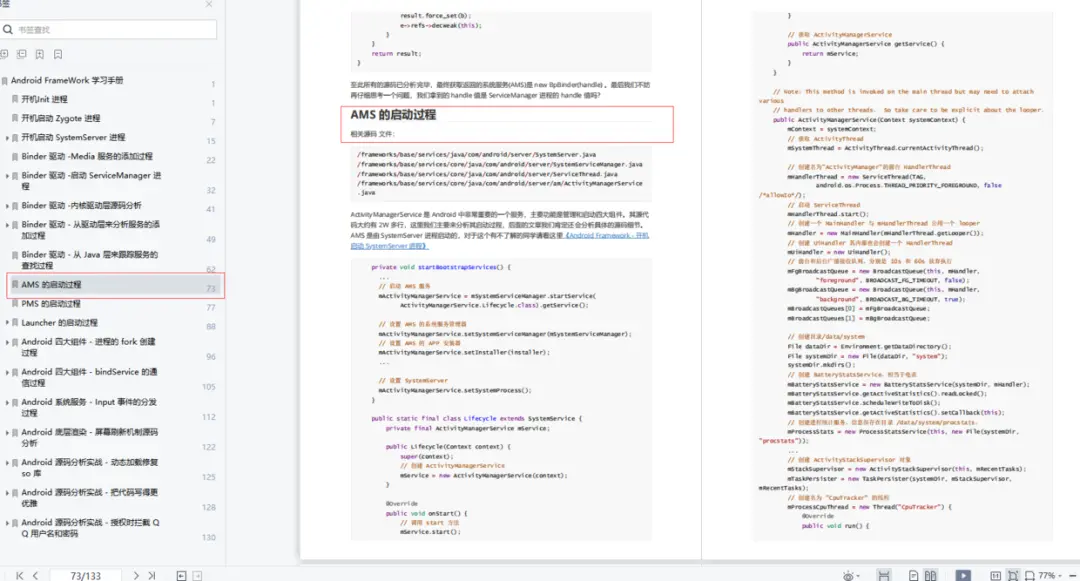
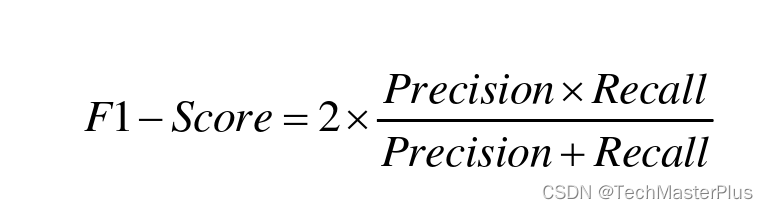对于分类模型的性能评估通常采用混淆矩阵的方式和计算准确率、正确率、召回率和 F1 分数。本文详细介绍图像分类的测评指标
在二分类问题中,样本有正负两个类别,模型对样本的预测结果存在四种组合:真阳性,即预测为正,实际也为正(True Positive,TP);假阳性,即预测为正,实际为负(False Positive,FP);假阴性,即预测为负,实际为正(False Negative,FN);真阴性,即预测为负,实际也为负(True Negative,TN)。

混淆矩阵
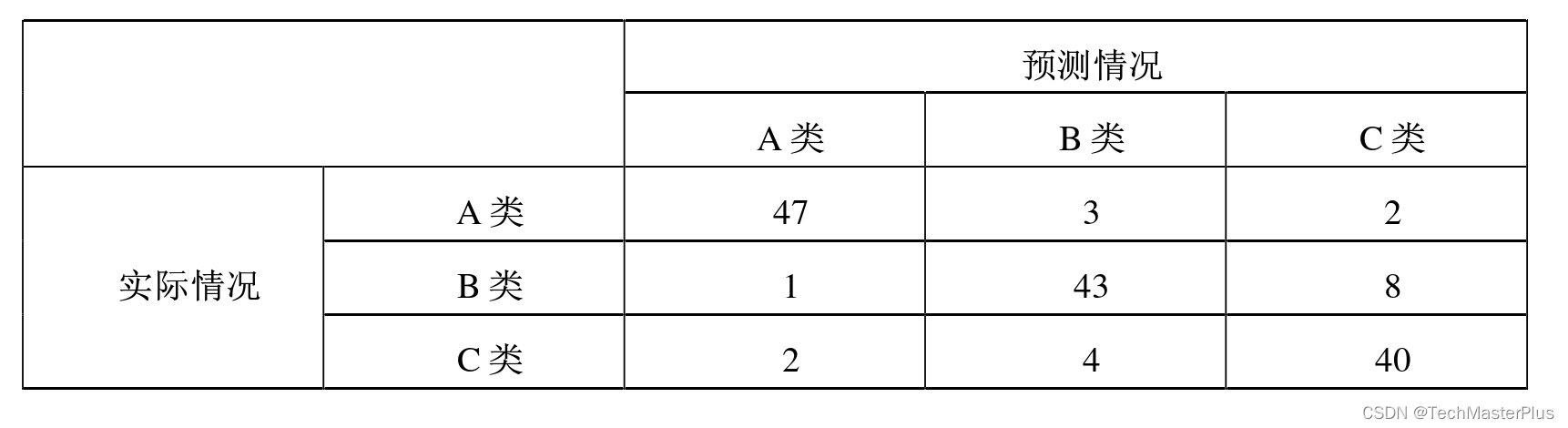
混淆矩阵是将所有类别的分类状况列出,包含真实值、预测值以及各种分类情况,主要由 TP、FP、FN、TN 四个主要参数表示。具体而言,混淆矩阵中的每一行的标签表示样本的真正类别标签,每一行样本数量的总和表示为该类别样本的数量总和;每一列的标签表示样本的预测类别标签,每一列样本数量的总和表示为预测为该类别的样本数量总和。混淆矩阵的简单示例如表 4.5 所示,表4.5 中的数据非真实数据表示。
例:若共有 150 个样本数据,预测为 A、B、C 类各 50 个,分类任务结束后得到的混淆矩阵为:
准确率(Precision)
表示预测为正的样本中有多少时是真正的正样本。其中预测为正类样本存在两种情况:一种是把正类样本预测为正类样本(TP),另一种则是把负类样本预测为正类样本(FP)。

正确率(Accuracy)
表示正确预测的比例,即表示所有样本中被预测正确的样本数。其中预测正确的样本存在两种情况:一种是把正类样本预测为正类样本(TP),另一种是把负类样本预测为负类样本(TN)。

召回率(Recall)
召回率是针对样本类别而言,即表示样本中的正例有多少被预测正确。其中样本中正例存在两种情况:一种是把原始的正类样本预测为正类样本(TP),另一种则是把原始的正类样本预测为负类样本(FN)。

F1 分数(F1-Score)
F1 分数综合了准确率(Precision)和召回率(Recall),是Precision 和 Recall 的加权平均,它的最大值是 1,最小值是 0。