从OpenAI实践看分工必要性,核心关注工作流相关的基础软件工具栈
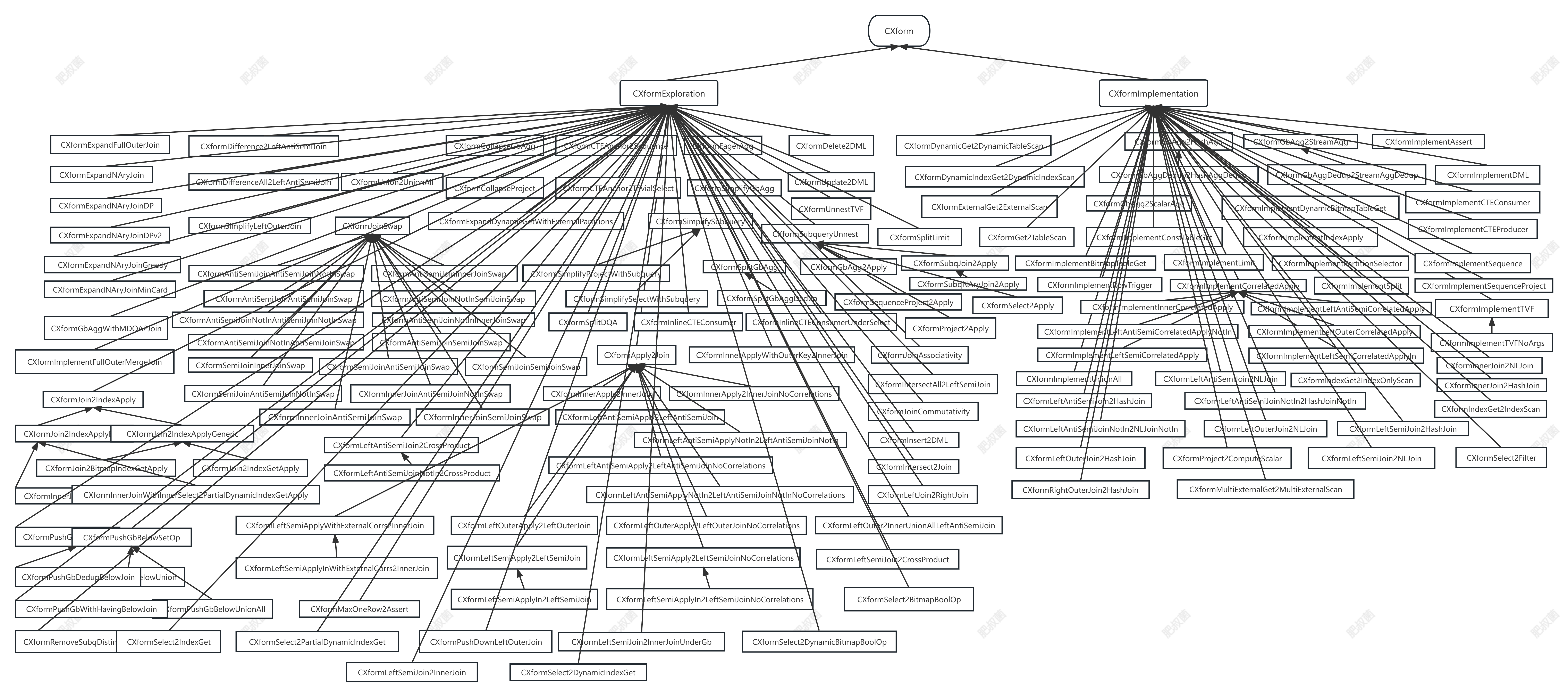
参考海外OpenAI的率先尝试,工作流分工、点工具加持助力成功。一方面,OpenAI在《GPT-4 Technical Report》论文中[1]中披露了参与GPT 4开发的人员分工,共249人,角色分工明确,预训练、强化学习和对齐、部署等6个大方向下又拆分成不同小组,其中数据集/数据基础设施、分布式训练基础设施、推理基础设施等分别对应工作流中的数据准备、模型训练、部署应用等环节;另一方面,OpenAI使用了Scale数据标注服务、Ray分布式计算框架和Weights and Biases(W&B)实验管理工具,且W&B的创立灵感就来自于其创始人之一在OpenAI的实习经历。我们认为,OpenAI的率先尝试经验一定程度上说明专业分工和AI Infra基础软件堆栈在大模型时代的必要性。
图表4:Open AI《GPT-4 Technical Report》中披露的人员分工明确

资料来源:《GPT-4 Technical Report》(OpenAI,2022),中金公司研究部
AI Infra广义上包含了基础模型和基础软