从源代码编译构建Apach Spark3.2.4
- 编译说明
- 编译Apache Spark
- 下载源码
- 构建环境准备
- 使用本地Maven构建
- 更改Scala版本
- 下载Jar包
- 构建可运行的发行版
- 构建异常
- 构建成功
- 运行测试
编译说明
对于大多数用户来说,使用官方预编译版本的Spark已经足够满足日常需求。只有在特定的场景和需求下,重新编译Spark才是必需的。
编译Spark源代码的场景、原因如下:
1.定制需求:
如果需要根据特定的业务需求对Spark进行定制,例如添加自定义的优化规则、改进数据源支持或针对特定硬件进行优化,重新编译Spark将可以满足您的需求,并允许在自定义版本的Spark中应用这些定制内容。
2.新特性和改进:
如果希望使用最新版本的Spark,以享受新特性和改进所带来的好处,但官方发布的预编译版本尚未包含这些内容,重新编译Spark可以使用最新版本并获取这些新特性。
3.针对特定环境的优化:
不同的硬件、操作系统和配置可能需要不同的优化参数和适配。如果拥有具体的硬件或环境要求,并且希望对Spark进行深层优化以充分发挥其性能,重新编译Spark可以进行相关的编译配置和参数调整。
4.调试和开发:
如果是一个 Spark开发者或希望参与Spark社区的贡献,重新编译Spark将获取源代码、构建工具和开发环境,以便进行调试、修改和开发工作。
编译Apache Spark
下载源码
下载源码:https://spark.apache.org/news/index.html
构建文档参考:https://spark.apache.org/docs/latest/building-spark.html
构建环境准备
构建Apache Spark环境要求:
1.基于Maven构建Apache Spark,需要Maven3.8.6和Java 8。
2.Spark需要Scala 2.12/2.13版本,注意Spark3.0.0中删除了对Scala2.11的支持。
3.建议设置Maven的内存使用
打开命令行终端或控制台,设置 MAVEN_OPTS 环境变量:
Linux操作系统:
export MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"
Windows操作系统:
set MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"
注意:
这将在当前会话中设置MAVEN_OPTS环境变量,如果关闭终端或控制台,设置将会失效。当运行Maven命令时,它将自动应用这些参数。
如果希望永久设置MAVEN_OPTS环境变量,可以将上述命令添加到操作系统的配置文件中(例如 .bashrc 或 .bash_profile)。
使用本地Maven构建
Spark附带了一个独立的Maven安装,在构建源代码时,其会自动下载并设置所有必要的构建要求(例如:Maven、Scala)。
打开spark-3.2.4\dev\make-distribution.sh文件,手动设置使用本地Mavn进行构建
#MVN="$SPARK_HOME/build/mvn"
MVN=/d/Development/Maven/bin/mvn
更改Scala版本
可以针对Spark版本使用指定的Scala版本进行构建,例如使用Scala2.13
注意:
这步可选,根据具体场景选择,例如将Spark作为Hive的执行引擎,Hive使用Scala版本2.13,为了兼容性,这里也应该使用Scala2.13版本
./dev/change-scala-version.sh 2.12
下载Jar包
1.使用IDEA开发工具打开该项目,会自动下载项目相关JAR。
2.使用mvn clean package或mvn dependency:resolveMaven命令,将解析项目的pom.xml文件对应的依赖关系,并下载所需的JAR文件到本地仓库。
3.使用mvn dependency:purge-local-repositoryMaven命令,该命令会遍历项目pom.xml中关联本地仓库中的Jar依赖,并删除其中所有已下载的依赖项。
构建可运行的发行版
构建参数说明:
--name hadoop3.1.3-without-hive: 指定生成的Spark分发包的名称。--tgz: 指定生成的分发包的格式为tar.gz压缩文件。-Pyarn: Maven profile配置项,用于启用YARN支持。YARN是Apache Hadoop的资源管理器,用于在集群上分配和管理资源。-Phadoop-provided: Maven profile配置项,用于指定使用外部提供的Hadoop依赖。这意味着Spark将使用系统中已安装的Hadoop而不是内置的Hadoop。-Dhadoop.version=3.1.3: 指定所使用的Hadoop版本。-Phive: Maven profile配置项,用于启用Hive支持。Hive是建立在Hadoop之上的数据仓库基础设施,它提供了类似于SQL的查询语言(HiveQL)来查询和分析存储在 Hadoop 分布式文件系统中的数据。-Phive-thriftserver: Maven profile配置项,用于启用Hive Thrift服务器支持。Hive Thrift服务器允许通过Thrift 口访问Hive 的功能,从而可以通过远程客户端连接到Hive并执行查询操作。-Dscala.version=2.12.17 是一个用于编译 Spark 时指定 Scala 版本的参数。
构建命令:
./dev/make-distribution.sh --name hadoop3.1.3-without-hive --tgz -Pyarn -Phadoop-provided -Dhadoop.version=3.1.3
构建异常
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:4.3.0:compile (scala-compile-first) on project spark-tags_2.12: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:4.3.0:compile failed: An API incompatibility was encountered while executing net.alchim31.maven:scala-maven-plugin:4.3.0:compile: java.lang.NoSuchMethodError: org.fusesource.jansi.AnsiConsole.wrapOutputStream(Ljava/io/OutputStream;)Ljava/io/OutputStream;
[ERROR] -----------------------------------------------------
[ERROR] realm = plugin>net.alchim31.maven:scala-maven-plugin:4.3.0
[ERROR] strategy = org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy
[ERROR] urls[0] = file:/D:/Development/Maven/Repository/net/alchim31/maven/scala-maven-plugin/4.3.0/scala-maven-plugin-4.3.0.jar
[ERROR] urls[1] = file:/D:/Development/Maven/Repository/org/apache/maven/maven-builder-support/3.3.9/maven-builder-support-3.3.9.jar
[ERROR] urls[2] = file:/D:/Development/Maven/Repository/com/google/guava/guava/18.0/guava-18.0.jar
[ERROR] urls[3] = file:/D:/Development/Maven/Repository/org/codehaus/plexus/plexus-interpolation/1.21/plexus-interpolation-1.21.jar
[ERROR] urls[4] = file:/D:/Development/Maven/Repository/javax/enterprise/cdi-api/1.0/cdi-api-1.0.jar
原因:
Maven依赖冲突或版本不兼容引起的
解决方案:
更换Spark项目中使用的scala-maven-plugin插件版本,将版本由3.4.0改成4.8.0
<groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><!-- SPARK-36547: Please don't upgrade the version below, otherwise there will be an error on building Hadoop 2.7 package --><version>4.8.0</version></groupId>
注意:更改的插件版本需要根据安装的Maven版本进行适当调整,直到没有这个错误即可。
构建成功
[INFO] Replacing D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4.jar with D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-shaded.jar
[INFO] Dependency-reduced POM written at: D:\WorkSpace\BigData\spark-3.2.4\external\avro\dependency-reduced-pom.xml
[INFO]
[INFO] --- maven-source-plugin:3.1.0:jar-no-fork (create-source-jar) @ spark-avro_2.12 ---
[INFO] Building jar: D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-sources.jar
[INFO]
[INFO] --- maven-source-plugin:3.1.0:test-jar-no-fork (create-source-jar) @ spark-avro_2.12 ---
[INFO] Building jar: D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-test-sources.jar
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Spark Project Parent POM 3.2.4:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 4.208 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 27.903 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 14.615 s]
[INFO] Spark Project Local DB ............................. SUCCESS [ 11.059 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 14.750 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 13.361 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 18.919 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 18.429 s]
[INFO] Spark Project Core ................................. SUCCESS [05:13 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 35.943 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 41.485 s]
[INFO] Spark Project Streaming ............................ SUCCESS [01:16 min]
[INFO] Spark Project Catalyst ............................. SUCCESS [03:13 min]
[INFO] Spark Project SQL .................................. SUCCESS [05:24 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:43 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 9.124 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:56 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 27.047 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 26.742 s]
[INFO] Spark Project YARN ................................. SUCCESS [03:02 min]
[INFO] Spark Project Assembly ............................. SUCCESS [ 2.647 s]
[INFO] Kafka 0.10+ Token Provider for Streaming ........... SUCCESS [ 26.049 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 45.183 s]
[INFO] Kafka 0.10+ Source for Structured Streaming ........ SUCCESS [ 54.219 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 43.172 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 9.504 s]
[INFO] Spark Avro ......................................... SUCCESS [ 45.400 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 31:01 min
[INFO] Finished at: 2023-08-09T10:10:41+08:00
[INFO] ------------------------------------------------------------------------
+ rm -rf /d/WorkSpace/BigData/spark-3.2.4/dist
+ mkdir -p /d/WorkSpace/BigData/spark-3.2.4/dist/jars
+ echo 'Spark 3.2.4 built for Hadoop 3.1.3'
+ echo 'Build flags: -Pyarn' -Phadoop-provided -Dhadoop.version=3.1.3

运行测试
启动spark-shell
spark-shell --master local
异常1:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/log4j/spi/Filterat java.lang.Class.getDeclaredMethods0(Native Method)at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)at java.lang.Class.privateGetMethodRecursive(Class.java:3048)at java.lang.Class.getMethod0(Class.java:3018)at java.lang.Class.getMethod(Class.java:1784)at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:650)at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:632)
Caused by: java.lang.ClassNotFoundException: org.apache.log4j.spi.Filterat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
修改spark-env.sh文件
# jdk路径
export JAVA_HOME=/usr/local/program/jdk8# 关联Hadoop
export HADOOP_HOME=/usr/local/program/hadoop
export HADOOP_CONF_DIR=/usr/local/program/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/program/hadoop/bin/hadoop classpath)
异常2:
org.apache.spark.SparkException: Could not find spark-version-info.propertiesat org.apache.spark.package$SparkBuildInfo$.<init>(package.scala:62)at org.apache.spark.package$SparkBuildInfo$.<clinit>(package.scala)at org.apache.spark.package$.<init>(package.scala:93)at org.apache.spark.package$.<clinit>(package.scala)at org.apache.spark.SparkContext.$anonfun$new$1(SparkContext.scala:193)at org.apache.spark.internal.Logging.logInfo(Logging.scala:57)at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56)at org.apache.spark.SparkContext.logInfo(SparkContext.scala:82)at org.apache.spark.SparkContext.<init>(SparkContext.scala:193)at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2700)at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:949)at scala.Option.getOrElse(Option.scala:189)at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:943)at org.apache.spark.repl.Main$.createSparkSession(Main.scala:112)
运行build/spark-build-info命令,它会生成一个spark-version-info.properties文件
build/spark-build-info ./目录路径
该文件内容如下:
version=
user=
revision=
branch=
date=2023-08-10T01:42:10Z
url=
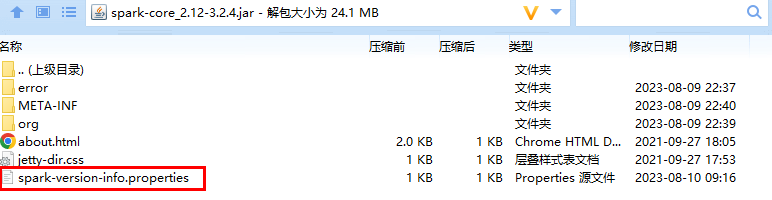
将生成的spark-version-info.properties文件复制到spark-core_2.11-2.4.0-SNAPSHOT.jar。将修改的JAR包放到spark/jars目录,替换原来的JAR
重新启动Spark Shell,同时执行数据库查询
Spark context Web UI available at http://node01:4040
Spark context available as 'sc' (master = local, app id = local-1691675436513).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.2.4/_/Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_371)
Type in expressions to have them evaluated.
Type :help for more information.scala> spark.sql("show databases").show
+---------+
|namespace|
+---------+
| default|
+---------+