前言
随着『GPT4多模态/Microsoft 365 Copilot/Github Copilot X/ChatGPT插件』的推出,绝大部分公司的技术 产品 服务,以及绝大部分人的工作都将被革新一遍
- 类似iPhone的诞生 大家面向iOS编程 有了App Store
- 现在有了ChatGPT插件/GPT应用商店,以后很多公司 很多人面向GPT编程(很快技术人员分两种,一种懂GPT,一种不懂GPT)
然ChatGPT/GPT4基本不可能开源了,而通过上篇文章《类ChatGPT模型LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE》可知,国内外各大公司、研究者推出了很多类ChatGPT开源项目,比如LLaMA、BLOOM
本文则侧重ChatGLM
第一部分 国内的GLM框架与类ChatGPT项目ChatGLM-6B
1.1 GLM: General Language Model Pretraining with Autoregressive Blank Infilling
1.1.1 GLM结构:微改transformer block且通过自定义attention mask兼容GPT BERT T5三种结构
在2022年上半年,当时主流的预训练框架可以分为三种:
- autoregressive,自回归模型的代表是单向的GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation),缺点是无法利用到下文的信息
- autoencoding,自编码模型是通过某个降噪目标(如掩码语言模型,简单理解就是通过挖洞,训练模型做完形填空的能力)训练的语言编码器,如双向的BERT、ALBERT、RoBERTa、DeBERTa
自编码模型擅长自然语言理解任务(natural language understanding tasks),常被用来生成句子的上下文表示,缺点是不适合生成任务 - encoder-decoder,则是一个完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,常用于有条件的生成任务 (conditional generation)
细致来说,T5的编码器中的注意力是双向,解码器中的注意力是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量
这三种预训练模型各自称霸一方,那么问题来了,可否结合三种预训练模型,以成天下之一统?这便是2022年5月发表的这篇论文《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》的出发点,它提出了GLM架构(下面三小节的内容主要参考自张义策关于GLM论文的解读之一 )
首先,GLM框架在整体基于Transformer基础上,做了以下三点微小改动
- 重新排列了层归一化和残差连接的顺序
- 针对token的输出预测使用单一线性层
- 用GeLU替换ReLU激活函数
考虑到我讲的ChatGPT技术原理解析课群内,有同学对这块有疑问,所以再重点说下
- 本质上,一个GLMblock其实就是在一个transformer block的基础上做了下结构上的微小改动而已
至于实际模型时,这个block的数量或层数可以独立设置,比如设置24层(具体见下述代码第48行) GLM/arguments.py at 4b65bdb165ad323e28f91129a0ec053228d10566 · THUDM/GLM · GitHubgroup.add_argument('--num-layers', type=int, default=24,- 比如,基于GLM框架的类ChatGPT开源项目「ChatGLM」便用了28个GLMBlock,类似gpt2 用的12-48个decoder-transformer block,BERT用的12-24个encoder-transformer block
- 有些文章 包括我那篇Transformer笔记,为举例,便用的N=6的示例,相当于编码器模块 用的6个encoder-transformer block,解码器模块 也用的6个decoder-transformer block

其次,考虑到三类预训练模型的训练目标
- GPT的训练目标是从左到右的文本生成
- BERT的训练目标是对文本进行随机掩码,然后预测被掩码的词
- T5则是接受一段文本,从左到右的生成另一段文本
为了大一统,我们必须在结构和训练目标上兼容这三种预训练模型。如何实现呢?文章给出的解决方法是结构上,只需要GLM中同时存在单向注意力和双向注意力即可
因为在原本的Transformer模型中,这两种注意力机制是通过修改attention mask实现的
- 当attention_mask是全1矩阵的时候,这时注意力是双向的
- 当attention_mask是三角矩阵的时候(如下图),注意力就是单向
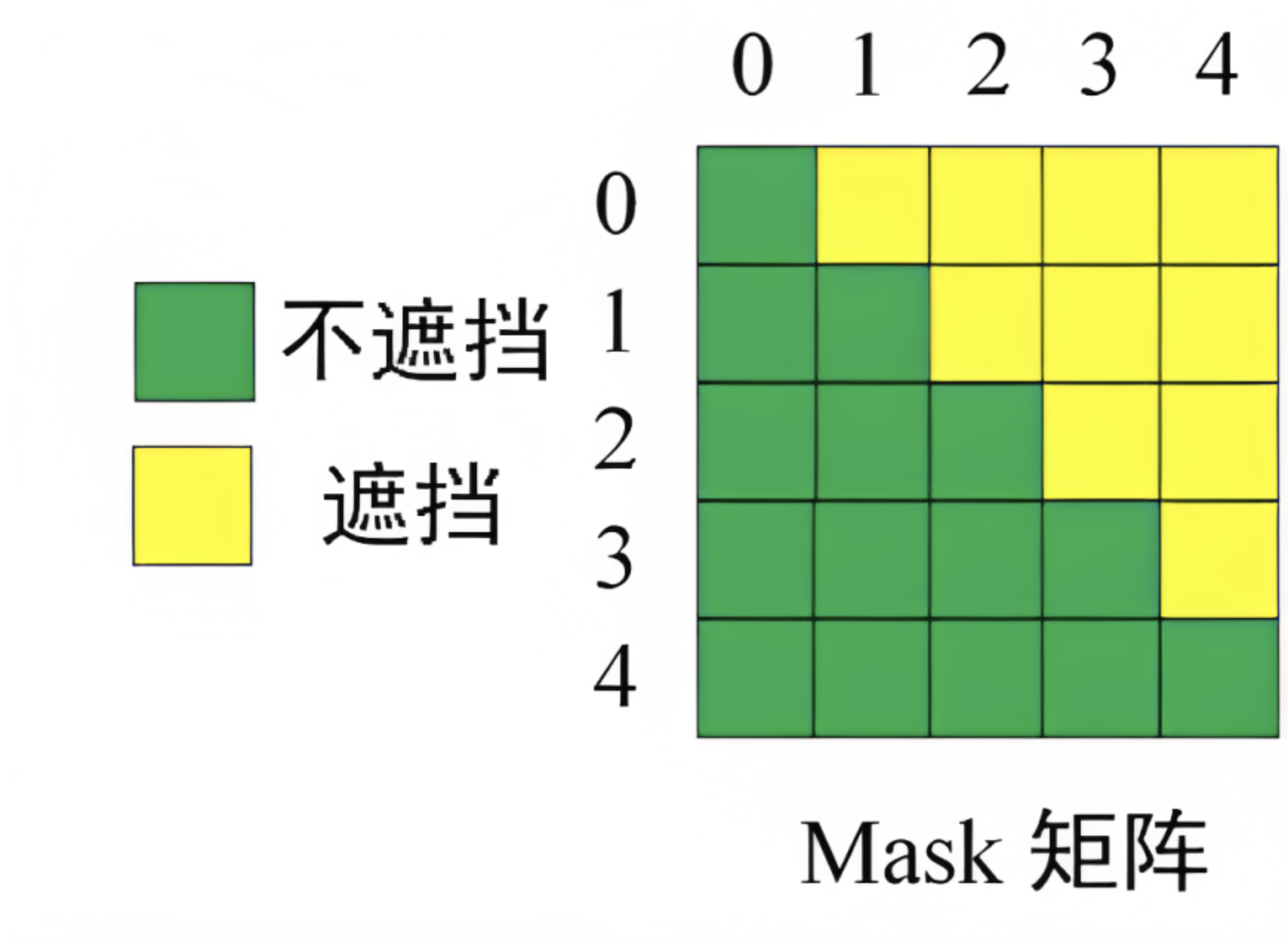
类似地,GLM可以在只使用Transformer编码器的情况下,自定义attention mask来兼容三种模型结构
具体怎么个兼容法呢?假设原始的文本序列为,采样的两个文本片段为
和
,那么掩码后的文本序列为
(以下简称Part A),如上图所示,拆解图中的三块分别可得

- 我们要根据第一个
解码出
,根据第二个
,那怎么从
和结束标记
了
- 我们从开始标记
在GLM中,位置向量有两个,一个 用来记录Part A中的相对顺序,一个 用来记录被掩码的文本片段(简称为Part B)中的相对顺序 - 此外,还需要通过自定义自注意掩码(attention mask)来达到以下目的:
双向编码器Part A中的词彼此可见,即图(d)中蓝色框中的区域
需要说明的是,Part B包含所有被掩码的文本片段,但是文本片段的相对顺序是随机打乱的
1.1.2 GLM的预训练和微调
训练目标上,GLM论文提出一个自回归空格填充的任务(Autoregressive Blank Infifilling),来兼容三种预训练目标
自回归填充有些类似掩码语言模型,首先采样输入文本中部分片段,将其替换为[MASK]标记,然后预测[MASK]所对应的文本片段,与掩码语言模型不同的是,预测的过程是采用自回归的方式

具体来说
- 当被掩码的片段长度为1的时候,空格填充任务等价于掩码语言建模,类似BERT
- 当将文本1和文本2拼接在一起,然后将文本2整体掩码掉,空格填充任务就等价于条件语言生成任务,类似T5/BART
- 当全部的文本都被掩码时,空格填充任务就等价于无条件语言生成任务,类似GPT
最终,作者使用了两个预训练目标来优化GLM,两个目标交替进行:
- 文档级别的预测/生成:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%
- 句子级别的预测/生成:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%
尽管GLM是BERT、GPT、T5三者的结合,但是在预训练时,为了适应预训练的目标,作者还是选择掩码较长的文本片段,以确保GLM的文本生成能力,并在微调的时候将自然语言理解任务也转化为生成任务,如情感分类任务转化为填充空白的任务
输入:{Sentence},prompt:It is really

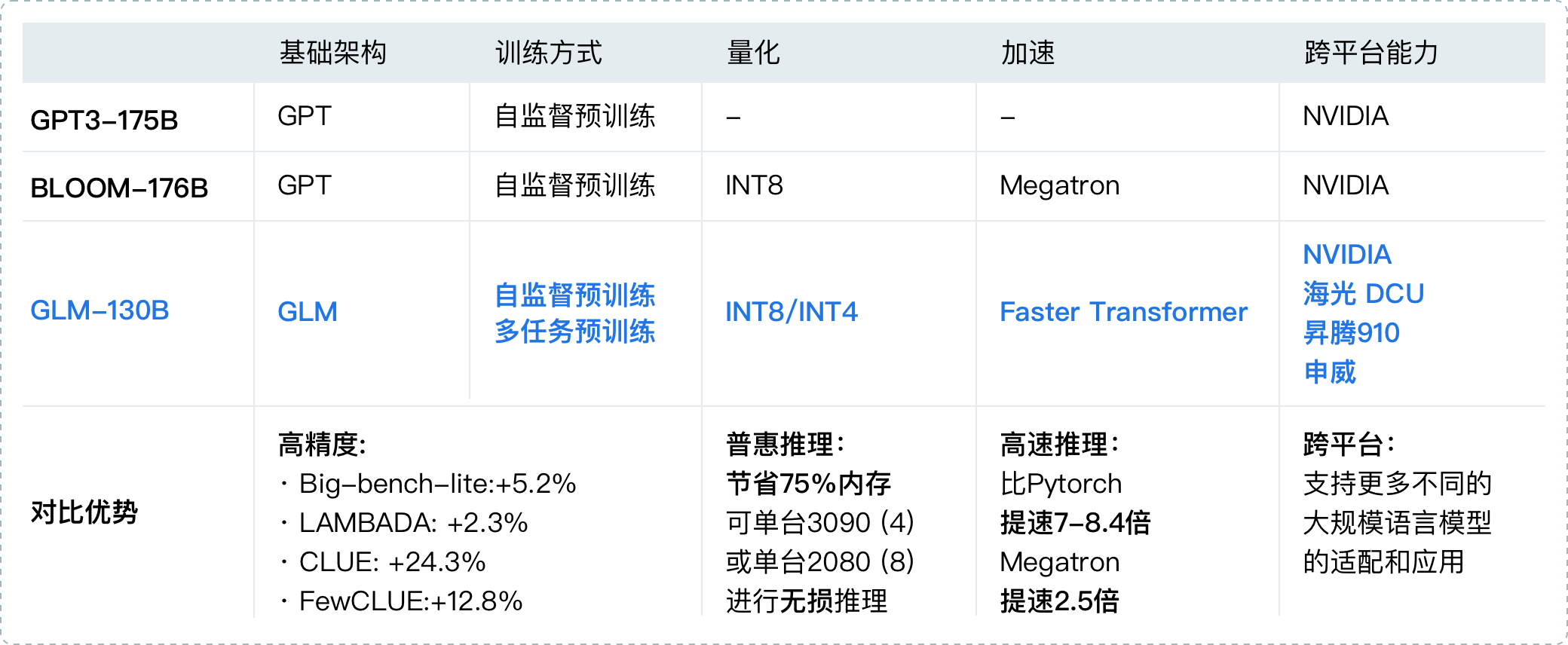
1.2 GLM-130B:国内为数不多的可比肩GPT3的大模型之一
2022年8月,清华背景的智谱AI基于GLM框架,正式推出拥有1300亿参数的中英双语稠密模型 GLM-130B(论文地址、代码地址,论文解读之一,GLM-130B is trained on a cluster of 96 DGX-A100 GPU (8×40G) servers with a 60-day,可以较好的支持2048个token的上下文窗口)
其在一些任务上的表现优于GPT3-175B,是国内与2020年5月的GPT3在综合能力上差不多的模型之一(即便放到23年年初也并不多),这是它的一些重要特点
1.3 ChatGLM-6B的训练框架与部署步骤
1.3.1 ChatGLM-6B的训练框架
ChatGLM-6B(介绍页面、代码地址),是智谱 AI 开源、支持中英双语的对话语言模型,其
- 基于General Language Model(GLM)架构,具有62亿参数,无量化下占用显存13G
INT8量化级别下支持在单张11G显存的 2080Ti 上进行推理使用(因为INT8下占用显存8G)
而INT4量化级别下部署的话最低只需 6GB显存(另基于 P-Tuning v2 的高效参数微调方法的话,在INT4 下最低只需 7GB 显存即可启动微调)
这里需要解释下的是,INT8量化是一种将深度学习模型中的权重和激活值从32位浮点数(FP32)减少到8位整数(INT8)的技术。这种技术可以降低模型的内存占用和计算复杂度,从而减少计算资源需求,提高推理速度,同时降低能耗量化等级 最低 GPU 显存(部署/推理) 最低 GPU 显存(高效参数微调) FP16(无量化) 13 GB 14 GB INT8 8 GB 9 GB INT4 6 GB 7 GB
量化的过程通常包括以下几个步骤:
1 量化范围选择:确定权重和激活值的最小值和最大值
2 量化映射:根据范围将32位浮点数映射到8位整数
3 反量化:将8位整数转换回浮点数,用于计算 - ChatGLM-6B参考了 ChatGPT 的训练思路,在千亿基座模型GLM-130B中注入了代码预训练,通过监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback)等方式等技术实现人类意图对齐,并针对中文问答和对话进行优化
- 最终经过约 1T 标识符的中英双语训练,生成符合人类偏好的回答
虽尚有很多不足(比如因为6B的大小限制,导致模型的记忆能力、编码、推理能力皆有限),但在6B这个参数量级下不错了,部署也非常简单,我七月在线的同事朝阳花了一两个小时即部署好了(主要时间花在模型下载上,实际的部署操作很快)
1.3.2 ChatGLM-6B的部署步骤
以下是具体的部署过程
- 硬件配置
本次实验用的七月的GPU服务器(专门为七月集/高/论文/VIP学员配置的),显存大小为16G的P100,具体配置如下:
CPU&内存:28核(vCPU)112 GB
操作系统:Ubuntu_64
GPU:NVIDIA Tesla P100
显存:16G - 配置环境
建议最好自己新建一个conda环境
pip install -r requirements.txt
(ChatGLM-6B/requirements.txt at main · THUDM/ChatGLM-6B · GitHub)
特别注意torch版本不低于1.10(这里安装的1.10),transformers为4.27.1
torch的安装命令可以参考pytorch官网:https://pytorch.org/
这里使用的pip命令安装的,命令如下
pip install torch==1.10.0+cu102 torchvision==0.11.0+cu102 torchaudio==0 - 下载项目仓库
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B - 下载ChatGLM-6B模型文件
具体而言,较大的8个模型文件可以从这里下载(下载速度快):清华大学云盘
其他的小文件可以从这里下载(点击红框的下载按钮即可):THUDM/chatglm-6b · Hugging Face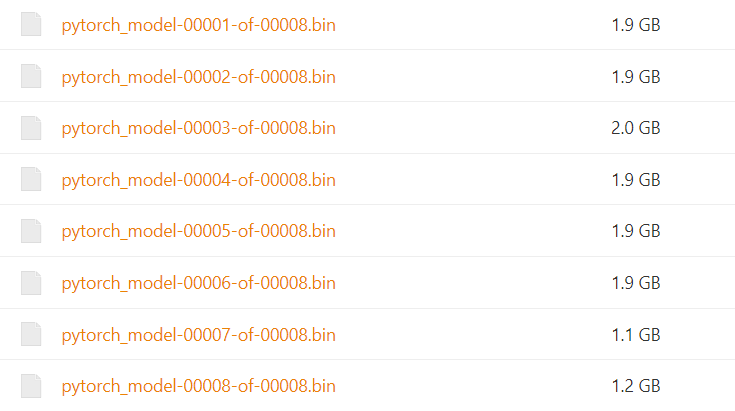

注意这里都下载在了/data/chatglm-6b下,在后面执行代码的时候需要将文件中的模型文件路径改为自己的
- 推理与部署
可运行的方式有多种
特别注意:运行代码前请检查模型文件路径是否正确,这里均改为了/data/chatglm-6b
代码运行demofrom transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("/data/chatglm-6b", trust_remote_code=True).half().cuda() model = model.eval() response, history = model.chat(tokenizer, "你好", history=[]) print(response) response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history) print(response)
命令行 Demo
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序
基于Gradio的网页版demo
运行web_demo.py即可(注意可以设置share=True,便于公网访问):python web_demo.py(注意运行前确认下模型文件路径)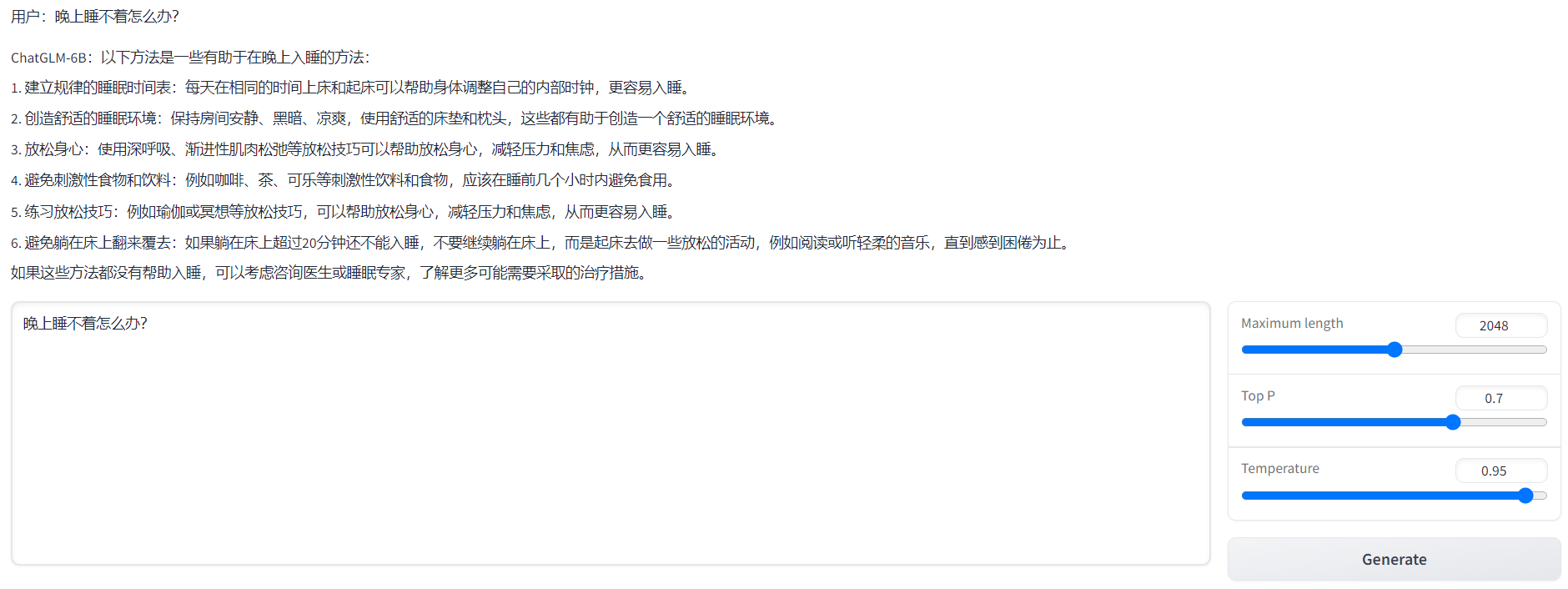
基于streamlit网页版 Demo
pip install streamlit
pip install streamlit-chat
streamlit run web_demo2.py --server.port 6006(可以将6006端口放出,便于公网访问)
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果显存有限,还可以考虑模型量化,目前支持4/8 bit 量化
此外,据介绍,GLM团队正在内测130B参数的ChatGLM,相信从6B到130B,效果应该能提升很多
1.4 微调ChatGLM-6B:针对各种数据集通过LoRA或P-Tuning v2
1.4.1 通过Stanford Alpaca的52K数据集基于LoRA(PEFT库)微调ChatGLM-6B
从上文可知,Stanford Alpaca的52K数据集是通过Self Instruct方式提示GPT3对应的API产生的指令数据,然后通过这批指令数据微调Meta的LLaMA 7B
而GitHub上的这个微调ChatGLM-6B项目(作者:mymusise),则基于Stanford Alpaca的52K数据集通过LoRA(low-rank adaptation)的方式微调ChatGLM-6B
如上一篇文章所说,Huggingface公司推出的PEFT(Parameter-Efficient Fine-Tuning)库便封装了LoRA这个方法,具体而言,通过PEFT-LoRA微调ChatGLM-6B的具体步骤如下
- 第一步,配置环境与准备
先下载项目仓库
git clone https://github.com/mymusise/ChatGLM-Tuning.git
创建一个python3.8的环境
conda create -n torch1.13 python==3.8
conda activate torch1.13
根据requirements.txt配置环境
pip install bitsandbytes==0.37.1
安装1.13,cuda11.6(torch官网命令)
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
安装其他的包
遇到冲突问题:icetk 0.0.5 has requirement protobuf<3.19, but you have protobuf 3.19.5.pip install accelerate==0.17.1 pip install tensorboard==2.10 pip install protobuf==3.19.5 pip install transformers==4.27.1 pip install icetk pip install cpm_kernels==1.0.11 pip install datasets==2.10.1 pip install git+https://github.com/huggingface/peft.git # 最新版本 >=0.3.0.dev0
最后装了3.18.3的protobuf,发现没有问题
模型文件准备
模型文件在前面基于ChatGLM-6B的部署中已经准备好了,注意路径修改正确即可 - 第二步,数据准备
项目中提供了数据,数据来源为 Stanford Alpaca 项目的用于微调模型的52K数据,数据生成过程可详见:https://github.com/tatsu-lab/stanford_alpaca#data-release
alpaca_data.json,包含用于微调羊驼模型的 52K 指令数据,这个 JSON 文件是一个字典列表,每个字典包含以下字段:
instruction: str,描述了模型应该执行的任务,52K 条指令中的每一条都是唯一的
input: str,任务的可选上下文或输入。例如,当指令是“总结以下文章”时,输入就是文章,大约 40% 的示例有输入
output: str,由 text-davinci-003 生成的指令的答案
示例如下:[{"instruction": "Give three tips for staying healthy.","input": "","output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."},{"instruction": "What are the three primary colors?","input": "","output": "The three primary colors are red, blue, and yellow."}, ... ] - 第三步,数据处理
运行 cover_alpaca2jsonl.py 文件
python cover_alpaca2jsonl.py \ --data_path data/alpaca_data.json \ --save_path data/alpaca_data.jsonl \
处理后的文件示例如下:
运行 tokenize_dataset_rows.py 文件,注意:修改tokenize_dataset_rows中的model_name为自己的文件路径 :/data/chatglm-6b {"text": "### Instruction:\nGive three tips for staying healthy.\n\n### Response:\n1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.\nEND\n"} {"text": "### Instruction:\nWhat are the three primary colors?\n\n### Response:\nThe three primary colors are red, blue, and yellow.\nEND\n"}python tokenize_dataset_rows.py \--jsonl_path data/alpaca_data.jsonl \--save_path data/alpaca \--max_seq_length 200 \--skip_overlength \ - 第四步,微调过程
注意:运行前修改下finetune.py 文件中模型路径:/data/chatglm-6b
Nvidia驱动报错(如没有可忽略)python finetune.py \--dataset_path data/alpaca \--lora_rank 8 \--per_device_train_batch_size 6 \--gradient_accumulation_steps 1 \--max_steps 52000 \--save_steps 1000 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir output;
遇到问题,说明Nvidia驱动太老,需要更新驱动
UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 10020). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
解决:更新驱动即可,参考:Ubuntu 18.04 安装 NVIDIA 显卡驱动 - 知乎
BUG REPORT报错
参考:因为peft原因,cuda10.2报错 · Issue #108 · mymusise/ChatGLM-Tuning · GitHub
CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8()
考虑安装11以上的cudatooklit,参考下面链接,安装cudatooklit11.3(因为Ubuntu系统版本的原因,不能装11.6的)
Ubuntu16.04 安装cuda11.3+cudnn8.2.1 - 知乎
cudatooklit下载地址:
CUDA Toolkit 11.3 Downloads | NVIDIA 开发者
运行代码前先执行下面命令:
内存不够,考虑将per_device_train_batch_size设为1export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH export CUDA_HOME=/usr/local/cuda-11.3:$CUDA_HOME export PATH=/usr/local/cuda-11.3/bin:$PATH
报错:RuntimeError: expected scalar type Half but found Floatpython finetune.py \--dataset_path data/alpaca \--lora_rank 8 \--per_device_train_batch_size 1 \--gradient_accumulation_steps 1 \--max_steps 52000 \--save_steps 1000 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir output;
https://github.com/mymusise/ChatGLM-Tuning/issues?q=is%3Aissue+is%3Aopen+RuntimeError%3A+expected+scalar+type+Half+but+found+Float
解决方法:
一种是,不启用fp16, load_in_8bit设为True,可以运行,但loss为0;
一种是,启用fp16, load_in_8bit设为False,不行,应该还是显存不够的问题,至少需要24G左右的显存
1.4.2 ChatGLM团队:通过ADGEN数据集基于P-Tuning v2微调ChatGLM-6B
此外,ChatGLM团队自身也出了一个基于P-Tuning v2的方式微调ChatGLM-6B的项目:ChatGLM-6B 模型基于 P-Tuning v2 的微调
P-Tuning v2(代码地址,论文地址)意义在于:将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行

那具体怎么通过P-Tuning v2微调ChatGLM-6B呢,具体步骤如下:
- 第一步,配置环境与准备
地址:ChatGLM-6B/ptuning at main · THUDM/ChatGLM-6B · GitHub
安装以下包即可,这里直接在torch1.13的conda环境下安装的pip install rouge_chinese nltk jieba datasets - 第二步,模型文件准备
模型文件在前面基于ChatGLM-6B的部署中已经准备好了,注意路径修改正确即可
特别注意:如果你是之前下载的可能会报错,下面有详细的错误及说明 - 第三步,数据准备
ADGEN数据集的任务为根据输入(content)生成一段广告词(summary)
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
从Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN数据集,将解压后的AdvertiseGen目录放到本 ptuning 目录下即可 - 第四步,微调过程
修改train.sh文件
去掉最后的 --quantization_bit 4
注意修改模型路径,THUDM/chatglm-6b修改为/data/chatglm-6b
如果你也是在云服务器上运行,建议可以加上nohup后台命令,以免断网引起训练中断的情况修改后train.sh文件如下:
执行命令,开始微调PRE_SEQ_LEN=8 LR=1e-2CUDA_VISIBLE_DEVICES=0 nohup python -u main.py \--do_train \--train_file AdvertiseGen/train.json \--validation_file AdvertiseGen/dev.json \--prompt_column content \--response_column summary \--overwrite_cache \--model_name_or_path /data/chatglm-6b \--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \--overwrite_output_dir \--max_source_length 64 \--max_target_length 64 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 16 \--predict_with_generate \--max_steps 3000 \--logging_steps 10 \--save_steps 1000 \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN \>> log.out 2>&1 &
bash train.sh
如果报错:'ChatGLMModel' object has no attribute 'prefix_encoder'(如没有可忽略)
解决方案:需要更新 THUDM/chatglm-6b at main 里面的几个py文件(重新下载下这几个文件就可以了)
微调过程占用大约13G的显存
微调过程loss变化情况
微调完成后,output/adgen-chatglm-6b-pt-8-1e-2路径下会生成对应的模型文件,如下(这里生成了3个):
- 第五步,推理过程
只需要在加载模型的位置修改成微调后的路径即可
将 evaluate.sh 中的 CHECKPOINT 更改为训练时保存的 checkpoint 名称,运行以下指令进行模型推理和评测:
改这一行即可:--model_name_or_path ./output/$CHECKPOINT/checkpoint-3000
bash evaluate.sh
评测指标为中文 Rouge score 和 BLEU-4,生成的结果保存在
./output/adgen-chatglm-6b-pt-8-1e-2/generated_predictions.txt
我们可以对比下微调前后的效果
以命令行 Demo为例,只需修改cli_demo.py中的模型路径为:ptuning/out/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000,运行 cli_demo.py即可:
python cli_demo.py
用以下数据为例:
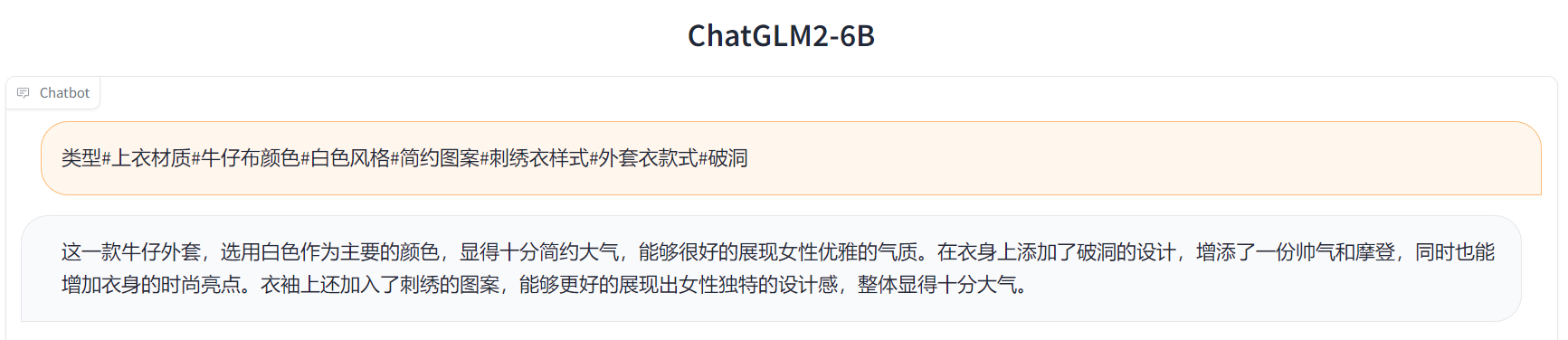
Input: 类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞 Label: 简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。 这件上衣的材质是牛仔布,颜色是白色,风格是简约,图案是刺绣,衣样式是外套,衣款式是破洞。
用户:根据输入生成一段广告词,输入为:类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞。
Output[微调前]:
Output[微调后]:

总结:建议使用官方提供的基于P-Tuning v2微调ChatGLM-6B的方式对自己的数据进行微调
1.5 通过Cursor生成微调ChatGLM的示例代码
可能有读者会有疑问,到底怎么微调ChatGLM-6B呢,接下来我们通过Cursor一步一步生成一份示例代码(且参考此文),如下所示
- 导入所需的库:PyTorch、TensorDataset 和 DataLoader(用于处理数据集)、transformers(加载预训练模型和分词器)、Lora(此处指Layer-wise Optimized Rate Adaptation,非另一个简称为LoRA的微调LLM的Low-Rank Adaptation)和 SummaryWriter(用于将训练和验证损失记录到 TensorBoard)
import torch from torch.utils.data import TensorDataset, DataLoader from transformers import AutoTokenizer, AutoModelForCausalLM from lora import Lora from torch.utils.tensorboard import SummaryWriter - 下载并加载预训练的 ChatGLM-6B 模型和相应的分词器
# Download and load the ChatGLM-6B model model_name = "TsinghuaAI/ChatGLM-6B" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) - 初始化Lora优化器,并设置学习率和秩(rank)
值得一提的是,关于学习率应该怎么设置更好# Initialize the Lora optimizer optimizer = Lora(model.parameters(), lr=1e-5, rank=16)
实际上,学习率的选择取决于你的模型和数据集
通常来说,学习率的初始值可以设置为1e-5或1e-4,然后根据模型在训练集和验证集上的表现来调整学习率如果模型在训练集上的表现很好,但在验证集上的表现很差,那么你可能需要降低学习率;
- 定义输入文本input_text,和输出文本output_text
并使用分词器将输入文本和输出文本转换为张量(tensor)# Define your input text input_text = "Hello, how are you?"# Tokenize the input text input_ids = torch.tensor(tokenizer.encode(input_text)).unsqueeze(0) attention_mask = torch.ones_like(input_ids)# Define your output text output_text = "I'm doing well, thank you for asking."# Tokenize the output text labels = torch.tensor(tokenizer.encode(output_text)).unsqueeze(0) - 将训练数据转换为 TensorDataset,并使用 DataLoader 创建批处理数据加载器
其中,batch_size参数指定了每个batch的大小,shuffle参数指定了是否打乱数据的顺序,当然,可以根据实际需要调整这些参数# Convert your training data to a TensorDataset train_dataset = TensorDataset(input_ids, attention_mask, labels)# Create a DataLoader to load # the data in batches batch_size = 32 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) - 定义验证数据,并将其转换为 TensorDataset 和 DataLoader
其中,nput_ids是一个包含输入文本的token ID的tensor# Define your validation data val_input_text = "How are you doing?" val_output_text = "I'm doing well, thank you for asking." val_input_ids = torch.tensor(tokenizer.encode(val_input_text)).unsqueeze(0) val_attention_mask = torch.ones_like(val_input_ids) val_labels = torch.tensor(tokenizer.encode(val_output_text)).unsqueeze(0) val_dataset = TensorDataset(val_input_ids, val_attention_mask, val_labels) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
attention_mask是一个指示哪些token是padding token的tensor
labels是一个包含输出文本的token ID的tensor
在这个示例中,我们首先加载了ChatGLM-6B模型的tokenizer
然后,我们定义了输入文本和输出文本,并使用tokenizer将它们转换成了input_ids和labels
其中,attention_mask被设置为一个与input_ids相同大小的tensor,其中所有的值都是1,表示所有的token都是有效的
当然,你可以根据自己的训练数据和tokenizer来调整这些代码
另外,要说明的是要判断模型是否过拟合或者没有收敛,你可以观察模型在训练集和验证集上的表现
如果模型在训练集上的表现很好,但在验证集上的表现很差,那么就说明模型过拟合了
如果模型在训练集和验证集上的表现都很差,那么就说明模型没有收敛
如果模型在训练集和验证集上的表现都很好,那么就说明模型训练得很好
也可以使用PyTorch的DataLoader和TensorDataset来加载训练集和验证集,并在每个epoch结束时计算模型在训练集和验证集上的损失值 - 定义训练损失和验证损失的列表
# Define your training and validation losses train_losses = [] val_losses = [] - 初始化 SummaryWriter,用于将损失写入 TensorBoard
# Initialize the SummaryWriter writer = SummaryWriter() - 对模型进行微调:
a. 在 10 个epoch内进行迭代
b. 在每个时期中,对训练数据进行遍历,并计算损失。使用优化器进行梯度更新for epoch in range(10):total_train_loss = 0total_val_loss = 0model.train()
首先,我们需要在每次迭代之前调用optimizer.zero_grad()来清空模型的梯度for batch in train_loader:optimizer.zero_grad()input_ids, attention_mask, labels = batchoutputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()# 每次迭代的loss可以帮助我们更好地了解模型的训练过程,以及每个batch的训练效果total_train_loss += loss.item()# 每轮的平均loss则可以帮助我们更好地了解模型的整体训练效果# 以及模型是否出现了过拟合或欠拟合的情况avg_train_loss = total_train_loss / len(train_loader)train_losses.append(avg_train_loss)
因为在每次迭代中,我们需要计算模型的梯度,并使用优化器来更新模型的参数。但是,在计算新的梯度之前,我们需要先清空之前的梯度。否则,新的梯度会与之前的梯度相加,导致模型的参数更新不正确
————————————————
在每次迭代中,我们需要计算模型的梯度,并使用优化器来更新模型的参数
loss.backward()会自动计算模型的梯度,并自动实现梯度的累积
————————————————
optimizer.step()是用来更新模型的参数的。在每次迭代中,我们需要使用优化器来更新模型的参数,以使模型的输出更接近于真实输出。optimizer.step()会根据模型的梯度和优化器的参数来更新模型的参数。具体来说,它会根据模型的梯度和学习率来计算参数的更新量,并将更新量加到模型的参数中
c. 在每个时期结束时,评估模型在验证数据上的表现,并计算损失
其中,model.eval()是用来将模型设置为评估模式的。在评估模式下,模型的行为会有所不同。具体来说,评估模式下,模型不会计算梯度,也不会更新模型的参数。这是因为,在评估模式下,我们只需要使用模型来进行预测,而不需要对模型进行训练total_val_loss = 0model.eval()with torch.no_grad():for batch in val_loader:input_ids, attention_mask, labels = batchoutputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.losstotal_val_loss += loss.item()avg_val_loss = total_val_loss / len(val_loader)val_losses.append(avg_val_loss)
因此,为了提高模型的预测性能,我们需要将模型设置为评估模式。在这个示例中,我们在计算验证集上的损失值时,将模型设置为评估模式,以确保模型的参数不会被更新
————————————————
with torch.no_grad():是一个上下文管理器,它可以临时禁用PyTorch的自动求导功能。在这个上下文中,所有的计算都不会被记录在计算图中,也不会影响模型的梯度。这个上下文通常用于评估模型或者进行推理时,因为在这些情况下,我们不需要计算梯度,也不需要更新模型的参数。禁用自动求导功能可以提高计算效率,并减少内存消耗。在这个示例中,我们在计算验证集上的损失值时,使用了with torch.no_grad():上下文,以提高计算效率
————————————————
outputs.loss是模型在当前batch上的损失值。在这个示例中,我们使用了AutoModelForCausalLM模型,它是一个自回归语言模型,可以根据输入文本生成输出文本。在每个batch中,我们将输入文本和输出文本传递给模型,模型会根据输入文本生成输出文本,并计算输出文本与真实输出文本之间的交叉熵损失。这个交叉熵损失就是outputs.loss,我们可以使用这个损失来更新模型的参数,以使模型的输出更接近于真实输出
d. 打印训练损失和验证损失
e. 将训练损失和验证损失写入 TensorBoardprint(f"Epoch {epoch+1} train loss: {avg_train_loss:.4f} val loss: {avg_val_loss:.4f}")# Write the training and validation losses to TensorBoardwriter.add_scalar("Training loss", avg_train_loss, epoch)writer.add_scalar("Validation loss", avg_val_loss, epoch) - 关闭 SummaryWriter
# Close the SummaryWriter writer.close()
第二部分 ChatGLM-6B的代码架构与逐行实现
ChatGLM-6B(介绍页面、代码地址),是智谱 AI 开源、支持中英双语的对话语言模型。
话不多说,直接干,虽然6B的版本相比GPT3 175B 不算大,但毕竟不是一个小工程,本文就不一一贴所有代码了,更多针对某个文件夹下或某个链接下的代码进行整体分析/说明,以帮助大家更好、更快的理解ChatGLM-6B,从而加速大家的类ChatGPT复现之路

其中,pytorch_model-00001-of-00008.bin 到 pytorch_model-00008-of-00008.bin: 这些文件是PyTorch模型的权重文件,相当于一个大模型被分割成多个部分以方便下载和使用
2.1 模型的核心实现: chatglm-6b/modeling_chatglm.py
2.1.1 导入相关库、编码器、GELU、旋转位置编码(第1-239行)
- 首先,代码导入了许多需要的库,如torch、torch.nn.functional等,它们为模型实现提供了基本的功能。
脚本中设置了一些标志,以便在运行时启用JIT(Just-In-Time)编译功能 - 定义了InvalidScoreLogitsProcessor类,它继承自LogitsProcessor。该类用于处理可能出现的NaN和inf值,通过将它们替换为零来确保计算的稳定性
- load_tf_weights_in_chatglm_6b函数,用于从TensorFlow检查点加载权重到PyTorch模型中。这对于迁移学习和在PyTorch中使用预训练模型非常有用
- PrefixEncoder类是一个编码器,用于对输入的前缀进行编码。它根据配置使用一个两层的MLP(多层感知器)或者直接进行嵌入,输出维度为(batch_size, prefix_length, 2 * layers * hidden)
- gelu_impl函数是一个GELU(高斯误差线性单元)激活函数的实现,这是一个常用的激活函数,尤其在Transformer模型中
# 使用PyTorch的JIT编译器,将Python函数转换为Torch脚本,以便优化和加速执行 @torch.jit.script # 定义名为gelu_impl的函数,接受一个参数x def gelu_impl(x):# 返回GELU激活函数的计算结果,这里使用了一种近似计算方法return 0.5 * x * (1.0 + torch.tanh(0.7978845608028654 * x *(1.0 + 0.044715 * x * x)))# 定义名为gelu的函数,接受一个参数x def gelu(x):# 调用gelu_impl函数并返回结果return gelu_impl(x)
- RotaryEmbedding类实现了旋转位置编码(第177-239行)。旋转位置编码是一种新型的位置编码方法,相比于传统的位置编码,它在大序列长度和多头注意力上具有更好的性能
# 类的前向传播方法,接收三个参数def forward(self, x, seq_dim=1, seq_len=None): # 如果没有提供序列长度,则从输入张量的形状中获取序列长度if seq_len is None: seq_len = x.shape[seq_dim]# 如果缓存的最大序列长度不存在,或者提供的序列长度大于缓存的最大序列长度if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):# 更新缓存的最大序列长度self.max_seq_len_cached = None if self.learnable else seq_len # 创建等差序列t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype) # 计算频率张量freqs = torch.einsum('i,j->ij', t, self.inv_freq)# 将频率张量沿最后一个维度进行拼接,形成旋转嵌入emb = torch.cat((freqs, freqs), dim=-1).to(x.device)# 如果精度为bfloat16,将旋转嵌入转换为float类型if self.precision == torch.bfloat16:emb = emb.float() # 计算旋转嵌入的余弦值和正弦值,形状为 [sx, 1 (b * np), hn]cos_cached = emb.cos()[:, None, :]sin_cached = emb.sin()[:, None, :]if self.precision == torch.bfloat16:# 如果精度为bfloat16,将余弦值转换为bfloat16类型cos_cached = cos_cached.bfloat16() # 如果精度为bfloat16,将正弦值转换为bfloat16类型sin_cached = sin_cached.bfloat16() # 如果旋转嵌入是可学习的if self.learnable: # 返回余弦值和正弦值return cos_cached, sin_cached # 更新缓存的余弦值和正弦值self.cos_cached, self.sin_cached = cos_cached, sin_cached # 返回截取后的余弦值和正弦值,以匹配输入序列的长度return self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]# 使用PyTorch的JIT编译器,将Python函数转换为Torch脚本,以便优化和加速执行 @torch.jit.script # 定义一个名为apply_rotary_pos_emb_index的函数,接收五个参数 def apply_rotary_pos_emb_index(q, k, cos, sin, position_id): # 通过position_id获取cos和sin的嵌入表示# cos.squeeze(1)和sin.squeeze(1)用于去除多余的维度# 而unsqueeze(2)则用于重新添加所需的维度# 从而将cos和sin的形状从[sq, 1, hn]变为[sq, b, np, hn],以便后续q和k进行运算cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)# 计算旋转位置编码后的q和k,将q和k与cos和sin进行点积运算q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)# 返回旋转位置编码后的q和kreturn q, k
2.1.2 SelfAttention的PyTorch模块:实现自注意力机制(第242-551行)
定义了一个名为SelfAttention的PyTorch模块,它实现了自注意力机制。这个模块在许多自然语言处理任务中都被用作基本构建块。以下是代码中的关键部分:
- attention_fn方法:这个方法实现了自注意力的核心计算过程,包括计算注意力分数、注意力概率和上下文层。这些计算对于实现许多自然语言处理任务,如语言建模、命名实体识别等,都是非常重要的
为方便大家更好、更快、更一目了然的理解,我花了个把钟头,一如上面的 依然把下面每一行代码都逐行加上了注释,且关键的部分加了额外的解释说明# 定义attention函数 def attention_fn(self,query_layer, # 查询层张量key_layer, # 键层张量value_layer, # 值层张量attention_mask, # 注意力掩码张量hidden_size_per_partition, # 每个分区的隐藏层大小,每个分区可能包含2或4或8个头layer_id, # 当前层的IDlayer_past=None, # 保存过去的键和值的张量,用于解码器的自回归任务scaling_attention_score=True, # 是否缩放注意力分数,默认为Trueuse_cache=False, # 是否使用缓存,默认为False ):# 如果layer_past不为空,则获取然后拼接过去的key和valueif layer_past is not None:past_key, past_value = layer_past[0], layer_past[1]key_layer = torch.cat((past_key, key_layer), dim=0)value_layer = torch.cat((past_value, value_layer), dim=0)# 获取key_layer的形状信息# 包括序列长度sq、批大小b、注意力头数(np,原代码为nh,应该是笔误)、每个注意力头的隐藏层大小hnseq_len, b, nh, hidden_size = key_layer.shape# 如果使用缓存,则设置present为key和value的元组,否则为Noneif use_cache:present = (key_layer, value_layer)else:present = None# 计算查询-键层缩放系数query_key_layer_scaling_coeff = float(layer_id + 1)# 如果需要缩放注意力分数,对查询层进行缩放if scaling_attention_score:query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)# 设置输出张量的大小,计算原始注意力分数的形状:[b, np, sq, sk]output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))"""解释下:query_layer 的原始形状为[seqlen, batch,num_attention_heads,hidden_size_per_attention_head],简写为[sq,b,np,hn]故query_layer.size(1)对应b, query_layer.size(2)对应np, query_layer.size(0)对应sqkey_layer 的原始形状为[seklen,batch,num_attention_heads,hidden_size_per_attention_head],简写为[sk,b,np,hn]所以key_layer.size(0)对应sk"""# 通过之前第39行的output_size[b, np, sq, sk],重塑查询层和键层张量 好进行矩阵相乘# [sq, b, np, hn] -> [sq, b * np, hn]query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)# [sk, b, np, hn] -> [sk, b * np, hn]key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)"""上面那两行再解释下,因为需要计算每个批次中每个注意力头的注意力分数,为此将批次大小(batch)和注意力头数量(num_attention_heads)合并到一个维度中以便于执行矩阵乘法因此,我们将 query_layer 的形状从[sq,b,np,hn]调整为 [sq, b * np, hn]同理,对于 key_layer,将 key_layer 的形状从[sk,b,np,hn]调整为 [sk, b * np, hn]"""# 初始化乘法结果张量matmul_result = torch.zeros(1, 1, 1,dtype=query_layer.dtype,device=query_layer.device,)# 计算查询层和键层的乘积matmul_result = torch.baddbmm(matmul_result,# 将 query_layer 的形状从 [sq, b * np, hn] 转换为 [b * np, sq, hn]query_layer.transpose(0, 1), # 将 key_layer 的形状从 [sk, b * np, hn] 转换为 [b * np, hn, sk]# 相当于对key_layer 进行了两次转置操作,得到形状为 [b * np, hn, sk] 的张量key_layer.transpose(0, 1).transpose(1, 2), beta=0.0,alpha=1.0,)# 上面最终query_layer为[b * np, sq, hn]# 上面最终key_layer 为[b * np, hn, sk]# 现在,沿用之前第39行的output_size的注意力分数张量[b, np, sq, sk]attention_scores = matmul_result.view(*output_size)# 使用缩放掩码Softmax计算注意力概率if self.scale_mask_softmax:self.scale_mask_softmax.scale = query_key_layer_scaling_coeffattention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())else:# 如果掩码不全为0,应用注意力掩码if not (attention_mask == 0).all():attention_scores.masked_fill_(attention_mask, -10000.0)# 转换注意力分数张量的数据类型为浮点数dtype = attention_scores.dtypeattention_scores = attention_scores.float()# 缩放注意力分数attention_scores = attention_scores * query_key_layer_scaling_coeff# 对注意力分数执行Softmax操作以获取注意力概率attention_probs = F.softmax(attention_scores, dim=-1)# 将注意力概率张量的数据类型恢复为原始数据类型attention_probs = attention_probs.type(dtype)"""计算上下文层[sq, b, hp]"""# 对原始value_layer做下转换得到新的output_size:[sk, b, np, hn] --> [b, np, sq, hn]output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))# 对原始value_layer的中间两个维度做下合并 [sk, b, np, hn] -> [sk, b * np, hn]value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)# 调整注意力概率:对之前得到的前两个维度做下合并:[b, np, sq, sk] =》[b * np, sq, sk]attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)# 对上一行得到的attention_probs[b * np, sq, sk]# 乘以『value_layer即[sk, b * np, hn]的转置』,即[b * np, hn, sk]# 相当于[b * np, sq, sk] x [b * np, hn, sk],最终得到[b * np, sq, hn]context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))# 上行得到context_layer的[b * np, sq, hn]通过上面第116行的新output_size调整为4个维度的# [b, np, sq, hn]# 使其更直观地表示批量大小b、注意力头数np、查询序列长度sq以及每个注意力头的隐藏层大小hncontext_layer = context_layer.view(*output_size)# [b, np, sq, hn] --> [sq, b, np, hn],使其与查询层(query_layer)的形状一致context_layer = context_layer.permute(2, 0, 1, 3).contiguous()# [sq, b, np, hn] --> [sq, b, hp],此举的作用在于前两个维度(sq 和 b)不变# 同时将后两个维度(np 和 hn)合并成单个维度,即每个分区的隐藏层大小(hp)new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)context_layer = context_layer.view(*new_context_layer_shape)# 将上下文层、当前的键值对(present)以及注意力概率(attention_probs)打包成一个元组outputs = (context_layer, present, attention_probs)return outputs - default_init函数:这个函数是一个初始化辅助函数,用于创建类的实例。
SelfAttention类定义:这个类实现了自注意力机制,包括定义类的初始化方法和成员变量。类的初始化方法包括设置各种属性,如hidden_size,num_attention_heads,layer_id等。类还包含一个名为rotary_emb的RotaryEmbedding实例,用于处理位置编码。此外,query_key_value和dense是用于计算查询、键和值的线性层。
- attention_mask_func方法,将注意力掩码应用于Transformer模型中的注意力得分(到了第407行)
@staticmethoddef attention_mask_func(attention_scores, attention_mask):# 使用掩码 (attention_mask) 更新注意力得分 (attention_scores)# 对于掩码值为0的位置,将注意力得分设置为-10000.0attention_scores.masked_fill_(attention_mask, -10000.0)# 返回更新后的注意力得分张量return attention_scores - split_tensor_along_last_dim 方法
该方法沿着张量的最后一个维度将其分割成多个部分。参数包括输入张量 tensor、要将张量分割成的分区数 num_partitions,以及布尔值 contiguous_split_chunks,用于确定分割后的张量是否需要在内存中连续。函数首先计算最后一个维度的大小,然后使用torch.split将输入张量分割成多个子张量。如果需要连续的分割块,将每个子张量转换为连续张量 - SelfAttention 类的 forward 方法:
该方法负责计算自注意力。它接收以下参数:hidden_states(输入序列的隐藏状态)、position_ids(位置编码)、attention_mask(注意力掩码)、layer_id(层ID)、layer_past(上一层的隐藏状态),以及use_cache(布尔值,表示是否使用缓存)和output_attentions(布尔值,表示是否输出注意力概率)。方法首先将隐藏状态传递给查询键值 (query, key, value) 层,然后将这些层分割成独立的张量。接下来,应用旋转位置编码,计算注意力概率,并得到上下文表示。最后,返回输出张量、隐藏状态以及注意力概率(如果需要的话)。
2.1.3 GLMBlock类、ChatGLMPreTrainedModel类(第554-784行)
GLMBlock 类:这是一个包含多个子模块的Transformer层,如层归一化 (LayerNorm)、自注意力 (SelfAttention) 和门控线性单元 (GLU)
// 第554到第569行
class GLMBlock(torch.nn.Module):def __init__(self,hidden_size,num_attention_heads,layernorm_epsilon,layer_id,inner_hidden_size=None,hidden_size_per_attention_head=None,layernorm=LayerNorm,use_bias=True,params_dtype=torch.float,//相当于有28层或28个GLMBlocknum_layers=28,position_encoding_2d=True,empty_init=True):GLMBlock 类的 forward 方法接收与SelfAttention的forward方法类似的参数,如输入序列的隐藏状态、位置编码、注意力掩码等。在这个方法中
- 首先应用层归一化
- 然后计算自注意力,接着应用第二个层归一化,最后通过门控线性单元 (GLU) 计算输出。在每个步骤之间,都有残差连接来保留之前的信息
- 最后,返回输出张量、隐藏状态以及注意力概率(如果需要的话)
接下来第661-729行,定义了一个名为 ChatGLMPreTrainedModel 的类,它继承自 PreTrainedModel。这个类是用于处理权重初始化以及简化下载和加载预训练模型的接口。
- 类变量包括:
is_parallelizable:表示该模型是否可并行化,默认为 False
supports_gradient_checkpointing:表示该模型是否支持梯度检查点,默认为 True
config_class:模型配置类,这里使用了 ChatGLMConfig
base_model_prefix:设置为 "transformer"
_no_split_modules:一个包含 "GLMBlock" 的列表 - 类方法包括:
__init__:构造函数,调用父类的构造函数
_init_weights:初始化权重的方法,这里没有具体实现
get_masks:根据输入生成注意力掩码
get_position_ids:根据输入和掩码位置生成位置编码,支持二维和非二维位置编码
_set_gradient_checkpointing:根据给定的值(默认为False)设置梯度检查点。
此外,还定义了一个名为 CHATGLM_6B_START_DOCSTRING 的变量,包含有关 ChatGLM6BConfig 的文档字符串,描述了如何使用这个 PyTorch 模型
2.1.4 ChatGLMModel类(第785-1029行)
定义了一个名为ChatGLMModel的类,它继承自ChatGLMPreTrainedModel。这是一个基于transformer的模型,能够作为编码器(仅使用自注意力机制)或解码器。解码器的情况下,会在自注意力层之间添加一个跨注意力层。模型的结构遵循论文Attention is all you need中描述的结构。
ChatGLMModel类的forward方法负责执行模型的前向传播。这个方法接收一系列输入参数,如input_ids、attention_mask、past_key_values等。根据这些输入,方法将执行以下操作:
- 如果没有提供inputs_embeds,使用word_embeddings将input_ids转换为嵌入向量
- 如果没有提供past_key_values,使用get_prompt方法获取提示
- 如果没有提供attention_mask,生成一个全零的张量
- 如果没有提供position_ids,使用get_position_ids方法获取位置ID
- 使用注意力掩码更新输入
- 对于模型中的每个层,执行以下操作:
更新隐藏状态
如果需要,保存当前层的隐藏状态
更新注意力权重 - 对最后一层应用层归一化。
- 如果需要,保存所有隐藏状态。
- 如果需要,返回一个包含所有输出的元组,否则返回一个BaseModelOutputWithPast对象。
这个模型的设计可以在序列到序列(Seq2Seq)任务中使用,这时需要将is_decoder和add_cross_attention参数设置为True,并在前向传播时提供encoder_hidden_states。
2.1.5 ChatGLMForConditionalGeneration的类(第1031-1436行)
定义了一个名为ChatGLMForConditionalGeneration的类,,它用于条件生成任务,如文本生成。这个类继承自ChatGLMPreTrainedModel,主要包括初始化方法、模型的前向传播逻辑以及生成过程中需要的输入预处理方法。
主要部分的解释如下:
- __init__方法是类的构造函数,用于初始化该类的实例。它接受两个参数:config(一个ChatGLMConfig实例,包含模型的配置信息)和empty_init(一个布尔值,表示是否跳过模型参数的初始化)。构造函数首先调用父类的构造函数,然后根据empty_init的值选择初始化方法。接着,它初始化一些实例变量,例如max_sequence_length和position_encoding_2d。最后,它初始化transformer和lm_head两个关键组件
- get_output_embeddings和set_output_embeddings方法分别用于获取和设置lm_head的权重。
- _update_model_kwargs_for_generation方法用于在生成过程中更新模型的关键字参数,包括更新past_key_values、attention_mask和position_ids。
- prepare_inputs_for_generation方法在生成过程中准备模型的输入,包括input_ids、past_key_values、attention_mask和position_ids等。此外,该方法还处理了遮罩位置和gmask的使用。
- forward方法实现了模型的前向传播逻辑。它接受一系列可选参数,例如input_ids、position_ids、attention_mask、past_key_values等,并根据这些输入调用transformer模块。接着,它将hidden_states传递给lm_head,并计算lm_logits。如果提供了标签(labels),则计算损失函数。最后,根据return_dict的值,返回一个包含损失、logits、隐藏状态等信息的元组或字典。此时到了1231行
- _reorder_cache 方法:在执行束搜索 (beam search) 或者束采样 (beam sample) 时用于重新排序 past_key_values 缓存,以便将 past_key_values 与正确的 beam_idx 匹配。
- process_response 方法:处理模型生成的回应,将其中的训练时间替换为 "2023年",同时将英文标点符号替换为中文标点符号。
- chat 方法:根据给定的查询和聊天历史生成回应。通过 tokenizer 对查询和聊天历史进行编码,并将其输入到模型中。然后,对模型生成的回应进行解码和处理,最后将新的回应添加到聊天历史中并返回。
- stream_chat 方法:与 chat 方法类似,但使用生成器函数 (generator function) 以流式方式生成回应。
- stream_generate 方法:一个生成器函数,用于生成回应。它首先将输入的 query 和聊天历史进行编码,然后根据生成配置 (generation_config) 进行一系列的准备工作。接着,在满足停止条件之前,通过模型的多次迭代来生成回应。
- quantize 方法:量化模型的权重,以减少模型的内存占用和计算资源。这对于在资源有限的设备上部署模型非常有用。
该类中还包括一些辅助方法,例如 _get_logits_processor, _get_stopping_criteria, _get_logits_warper, prepare_inputs_for_generation, 和 _update_model_kwargs_for_generation,这些方法用于处理生成过程中的各种设置和参数。
2.2 分词代码的实现:tokenization_chatglm.py
2.2.1 TextTokenizer:处理文本和词条之间的转换
TextTokenizer:这个类主要处理文本和词条之间的转换,包括将文本转化为词条列表的分词(tokenize),将词条列表转化为文本的解码(decode),以及获取词条的ID和从ID获取词条(convert_tokens_to_ids, convert_ids_to_tokens)等操作。此外,它还包含了处理特殊词条和填充的功能
这些处理是许多自然语言处理(NLP)任务,如文本分类、命名实体识别、问答系统、机器翻译等的基础步骤
当然,TextTokenizer还依赖下面的SPTokenizer进行文本的分词和解码操作,而将复杂的操作封装在了自己的接口之下,同时添加了对特殊词条和填充的处理。
# 导入相关库和模块
from typing import List, Optional, Union
import osfrom transformers.tokenization_utils import PreTrainedTokenizer # 从 transformers 包导入预训练的词条化工具类
from transformers.utils import logging, PaddingStrategy # 导入 transformers 的日志和填充策略工具类
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding # 导入词条化相关工具类
from typing import Dict # 导入字典类型
import sentencepiece as spm # 导入 sentencepiece,一个开源的词条化工具
import numpy as np # 导入 numpy,用于科学计算logger = logging.get_logger(__name__) # 创建一个日志记录器# 定义预训练位置嵌入大小的常量
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"THUDM/chatglm-6b": 2048,
}class TextTokenizer:def __init__(self, model_path):self.sp = spm.SentencePieceProcessor() # 创建一个 SentencePieceProcessor 实例self.sp.Load(model_path) # 加载模型self.num_tokens = self.sp.vocab_size() # 获取模型的词汇表大小def encode(self, text):return self.sp.EncodeAsIds(text) # 将文本编码为ID序列def decode(self, ids: List[int]):return self.sp.DecodeIds(ids) # 将ID序列解码为文本def tokenize(self, text):return self.sp.EncodeAsPieces(text) # 将文本分割为词条序列def convert_tokens_to_string(self, tokens):return self.sp.DecodePieces(tokens) # 将词条序列解码为文本def convert_tokens_to_ids(self, tokens):return [self.sp.PieceToId(token) for token in tokens] # 将词条序列转换为ID序列def convert_token_to_id(self, token):return self.sp.PieceToId(token) # 将单个词条转换为IDdef convert_id_to_token(self, idx):return self.sp.IdToPiece(idx) # 将ID转换为词条def __len__(self):return self.num_tokens # 返回词汇表大小2.2.2 SPTokenizer:包装了SentencePiece库的分词器
SPTokenizer:这个类是一个包装了SentencePiece库的分词器。SentencePiece是一个开源的自然语言处理库,用于神经网络模型的不规则文本分词,这个类主要提供了一些接口来利用SentencePiece库进行分词、解码等操作
class SPTokenizer:def __init__(self,vocab_file,num_image_tokens=20000,max_blank_length=80,byte_fallback=True,):assert vocab_file is not None # 检查词汇表文件是否存在self.vocab_file = vocab_file # 保存词汇表文件路径self.num_image_tokens = num_image_tokens # 保存图像词条数量self.special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", "<unused_0>", "<sop>", "<eop>", "<ENC>", "<dBLOCK>"] # 定义特殊词条self.max_blank_length = max_blank_length # 定义最大空白长度self.byte_fallback = byte_fallback # 设置字节回退标记self.text_tokenizer = TextTokenizer(vocab_file) # 创建文本词条化工具def _get_text_tokenizer(self):return self.text_tokenizer # 获取文本词条化工具@staticmethoddef get_blank_token(length: int):assert length >= 2return f"<|blank_{length}|>" # 获取空白词条@staticmethoddef get_tab_token():return f"" # 获取制表符词条@propertydef num_text_tokens(self):return self.text_tokenizer.num_tokens # 获取文本词条数量@propertydef num_tokens(self):return self.num_image_tokens + self.num_text_tokens # 获取总词条数量@staticmethoddef _encode_whitespaces(text: str, max_len: int = 80):text = text.replace("\t", SPTokenizer.get_tab_token()) # 替换制表符for i in range(max_len, 1, -1):text = text.replace(" " * i, SPTokenizer.get_blank_token(i)) # 替换多个连续空格return textdef _preprocess(self, text: str, linebreak=True, whitespaces=True):if linebreak:text = text.replace("\n", "<n>") # 替换换行符if whitespaces:text = self._encode_whitespaces(text, max_len=self.max_blank_length) # 编码空白字符return textdef encode(self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True) -> List[int]:"""文本编码方法"""text = self._preprocess(text, linebreak, whitespaces) # 预处理文本if not add_dummy_prefix:text = "<n>" + texttmp = self._get_text_tokenizer().encode(text) # 编码文本tokens = [x + self.num_image_tokens for x in tmp] # 将文本词条ID转换为包含图像词条ID的序列return tokens if add_dummy_prefix else tokens[2:]def postprocess(self, text):text = text.replace("<n>", "\n") # 替换换行词条text = text.replace(SPTokenizer.get_tab_token(), "\t") # 替换制表符词条for i in range(2, self.max_blank_length + 1):text = text.replace(self.get_blank_token(i), " " * i) # 替换空白词条return textdef decode(self, text_ids: List[int]) -> str:ids = [int(_id) - self.num_image_tokens for _id in text_ids] # 将包含图像词条的ID序列转换为文本词条ID序列ids = [_id for _id in ids if _id >= 0] # 删除非文本词条IDtext = self._get_text_tokenizer().decode(ids) # 解码ID序列为文本text = self.postprocess(text) # 对文本进行后处理return textdef decode_tokens(self, tokens: List[str]) -> str:text = self._get_text_tokenizer().convert_tokens_to_string(tokens) # 将词条序列解码为文本text = self.postprocess(text) # 对文本进行后处理return textdef tokenize(self, text: str, linebreak=True, whitespaces=True, add_dummy_prefix=True) -> List[str]:"""文本分词方法"""text = self._preprocess(text, linebreak, whitespaces) # 预处理文本if not add_dummy_prefix:text = "<n>" + texttokens = self._get_text_tokenizer().tokenize(text) # 分词return tokens if add_dummy_prefix else tokens[2:]def __getitem__(self, x: Union[int, str]):if isinstance(x, int):if x < self.num_image_tokens:return "<image_{}>".format(x) # 如果是图像词条,返回词条形式else:return self.text_tokenizer.convert_id_to_token(x - self.num_image_tokens) # 如果是文本词条,返回文本词条elif isinstance(x, str):if x.startswith("<image_") and x.endswith(">") and x[7:-1].isdigit():return int(x[7:-1]) # 如果是图像词条形式,返回词条IDelse:return self.text_tokenizer.convert_token_to_id(x) + self.num_image_tokens # 如果是文本词条,返回包含图像词条的IDelse:raise ValueError("The key should be str or int.") # 如果不是整数或字符串,抛出异常2.2.3 字节级字节对编码(Byte-Pair Encoding,BPE)分词器类
下面这段代码定义了一个ChatGLM的字节级字节对编码(Byte-Pair Encoding,BPE)分词器类,包含了一些分词器的基础操作,例如文本预处理、分词、词条解码、填充等
具体而言,以下的代码包括了对输入文本的预处理,将文本转化为词条序列的分词,以及将词条序列转化为文本的解码,等一系列分词器常用的操作。同时,这个分词器还支持添加特殊词条,以及在分词器的左边或右边进行填充,以满足模型输入的需要
class ChatGLMTokenizer(PreTrainedTokenizer): # 基于PreTrainedTokenizer定义一个新的分词器类"""Construct a ChatGLM tokenizer. Based on byte-level Byte-Pair-Encoding.Args:vocab_file (`str`):Path to the vocabulary file."""vocab_files_names = {"vocab_file": "ice_text.model"} # 设定词汇表文件名称max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES # 预设模型输入的最大尺寸model_input_names = ["input_ids", "attention_mask", "position_ids"] # 预设模型输入的名称列表def __init__( # 定义初始化函数self,vocab_file, # 词汇表文件路径do_lower_case=False, # 是否对文本做小写转换remove_space=False, # 是否移除文本中的空格bos_token='<sop>', # 文本开头的特殊词条eos_token='<eop>', # 文本结尾的特殊词条end_token='</s>', # 文本结束的特殊词条mask_token='[MASK]', # 遮蔽词条gmask_token='[gMASK]', # gMASK词条padding_side="left", # 填充侧(左侧填充或右侧填充)pad_token="<pad>", # 填充词条unk_token="<unk>", # 未知词条num_image_tokens=20000, # 图像词条的数量**kwargs # 其他参数) -> None:super().__init__( # 调用父类的初始化函数do_lower_case=do_lower_case,remove_space=remove_space,padding_side=padding_side,bos_token=bos_token,eos_token=eos_token,end_token=end_token,mask_token=mask_token,gmask_token=gmask_token,pad_token=pad_token,unk_token=unk_token,num_image_tokens=num_image_tokens,**kwargs)self.do_lower_case = do_lower_case # 是否进行小写转换self.remove_space = remove_space # 是否移除空格self.vocab_file = vocab_file # 词汇表文件self.bos_token = bos_token # 文本开头的特殊词条self.eos_token = eos_token # 文本结尾的特殊词条self.end_token = end_token # 文本结束的特殊词条self.mask_token = mask_token # 遮蔽词条self.gmask_token = gmask_token # gMASK词条self.sp_tokenizer = SPTokenizer(vocab_file, num_image_tokens=num_image_tokens) # 初始化SPTokenizer# 以下部分是定义了一些属性和方法@propertydef gmask_token_id(self) -> Optional[int]: # 获取gmask词条的idif self.gmask_token is None: # 若不存在,则返回Nonereturn Nonereturn self.convert_tokens_to_ids(self.gmask_token) # 返回gmask词条对应的id@propertydef end_token_id(self) -> Optional[int]: # 获取end词条的idif self.end_token is None: # 若不存在,则返回Nonereturn Nonereturn self.convert_tokens_to_ids(self.end_token) # 返回end词条对应的id@propertydef vocab_size(self): # 获取词汇表的大小return self.sp_tokenizer.num_tokens # 返回词汇表的大小def get_vocab(self): # 获取词汇表vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)} # 将词汇表转化为字典形式vocab.update(self.added_tokens_encoder) # 更新添加的词条编码器return vocab # 返回词汇表def preprocess_text(self, inputs): # 文本预处理函数if self.remove_space: # 若需要移除空格outputs = " ".join(inputs.strip().split()) # 则移除多余的空格else:outputs = inputs # 否则保持不变if self.do_lower_case: # 若需要进行小写转换outputs = outputs.lower() # 则转换为小写return outputs # 返回预处理后的文本def _tokenize(self, text, **kwargs): # 分词函数text = self.preprocess_text(text) # 对文本进行预处理seq = self.sp_tokenizer.tokenize(text) # 对文本进行分词return seq # 返回分词结果def convert_tokens_to_string(self, tokens: List[str]) -> str: # 将词条转化为字符串return self.sp_tokenizer.decode_tokens(tokens) # 解码词条def _decode(self,token_ids: Union[int, List[int]],**kwargs) -> str:# 对id进行解码if isinstance(token_ids, int): # 如果输入是单个idtoken_ids = [token_ids] # 则将其转化为列表if len(token_ids) == 0: # 如果输入为空return "" # 则返回空字符串if self.pad_token_id in token_ids: # 如果填充id在输入中token_ids = list(filter((self.pad_token_id).__ne__, token_ids)) # 则移除填充idreturn super()._decode(token_ids, **kwargs) # 返回父类的解码函数def _convert_token_to_id(self, token): # 将词条转化为idreturn self.sp_tokenizer[token] # 使用sp_tokenizer进行转换def _convert_id_to_token(self, index): # 将id转化为词条return self.sp_tokenizer[index] # 使用sp_tokenizer进行转换def save_vocabulary(self, save_directory, filename_prefix=None): # 保存词汇表到指定目录# 将词汇表及特殊词条文件保存到目录if os.path.isdir(save_directory): # 如果保存目录存在vocab_file = os.path.join(save_directory, self.vocab_files_names["vocab_file"]) # 则构建vocab文件路径else:vocab_file = save_directory # 否则vocab文件就是保存目录with open(self.vocab_file, 'rb') as fin: # 打开vocab文件proto_str = fin.read() # 读取文件内容with open(vocab_file, "wb") as writer: # 打开待写入的文件writer.write(proto_str) # 写入内容return (vocab_file,) # 返回保存的文件路径# 以下是与特殊词条有关的方法def build_inputs_with_special_tokens(self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None) -> List[int]:# 构建带有特殊词条的输入gmask_id = self.sp_tokenizer[self.gmask_token] # 获取gmask的ideos_id = self.sp_tokenizer[self.eos_token] # 获取eos的idtoken_ids_0 = token_ids_0 + [gmask_id, self.sp_tokenizer[self.bos_token]] # 添加gmask和bos到第一部分的尾部if token_ids_1 is not None: # 如果存在第二部分token_ids_0 = token_ids_0 + token_ids_1 + [eos_id] # 则将第二部分及eos添加到token_ids_0的尾部return token_ids_0 # 返回结果# 以下是与填充有关的方法def _pad(self,encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],max_length: Optional[int] = None,padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,pad_to_multiple_of: Optional[int] = None,return_attention_mask: Optional[bool] = None,) -> dict:# 对编码后的输入进行填充bos_token_id = self.sp_tokenizer[self.bos_token] # 获取bos的idmask_token_id = self.sp_tokenizer[self.mask_token] # 获取mask的idgmask_token_id = self.sp_tokenizer[self.gmask_token] # 获取gmask的idassert self.padding_side == "left" # 断言填充在左边required_input = encoded_inputs[self.model_input_names[0]] # 获取所需的输入seq_length = len(required_input) # 获取序列长度if padding_strategy == PaddingStrategy.LONGEST: # 如果填充策略是最长的max_length = len(required_input) # 则最大长度为输入的长度if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of # 如果最大长度不是pad_to_multiple_of的倍数,则进行相应的调整if max_length is not None and seq_length < max_length: # 如果最大长度存在且序列长度小于最大长度difference = max_length - seq_length # 计算差值if self.padding_side == "right": # 如果填充在右边if return_attention_mask: # 如果需要返回注意力掩码encoded_inputs["attention_mask"] = [1] * seq_length + [0] * difference # 则构建注意力掩码encoded_inputs[self.model_input_names[0]] = ([bos_token_id] + [mask_token_id] * difference + required_input + [gmask_token_id]) # 构建输入else:if return_attention_mask: # 如果需要返回注意力掩码encoded_inputs["attention_mask"] = [0] * difference + [1] * seq_length # 则构建注意力掩码encoded_inputs[self.model_input_names[0]] = ([gmask_token_id] + required_input + [mask_token_id] * difference + [bos_token_id]) # 构建输入return encoded_inputs # 返回编码后的输入跟分词相关的还有一个tokenizer_config.json:这个文件通常包含分词器的配置信息,例如预训练模型使用的特殊令牌(如[CLS],[SEP]等)
{"name_or_path": "THUDM/chatglm-6b","bos_token": "<sop>","eos_token": "<eop>","end_token": "</s>","gmask_token": "[gMASK]","mask_token": "[MASK]","pad_token": "<pad>","unk_token": "<unk>","remove_space": false,"do_lower_case": false,"tokenizer_class": "ChatGLMTokenizer","num_image_tokens": 0,"auto_map": {"AutoTokenizer": ["tokenization_chatglm.ChatGLMTokenizer",null]}
}2.3 quantization:模型量化——减小模型大小和推理时间
quantization.py: 这是一个Python脚本,可能包含了对模型进行量化的代码,量化是一种减小模型大小和推理时间的技术
2.3.1 compress_int4_weight等类
from torch.nn import Linear # 从torch.nn模块导入Linear线性模块
from torch.nn.parameter import Parameter # 从torch.nn.parameter模块导入Parameter参数模块import bz2 # 导入bz2模块,该模块支持bzip2压缩和解压缩
import torch # 导入torch模块,这是一个深度学习框架
import base64 # 导入base64模块,该模块提供了将二进制数据转换为ASCII字符的方法
import ctypes # 导入ctypes模块,该模块提供了一种强大的工具来创建、访问和操纵C数据类型
from transformers.utils import logging # 从transformers.utils模块导入logging日志模块from typing import List # 从typing模块导入List,可以用于注解变量的类型
from functools import partial # 从functools模块导入partial,可以用来固定函数的部分参数,返回新的partial对象logger = logging.get_logger(__name__) # 创建一个logger,名字为当前模块的名称try:# 从cpm_kernels.kernels.base模块导入LazyKernelCModule,KernelFunction和round_upfrom cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up class Kernel: # 定义一个名为Kernel的类def __init__(self, code: bytes, function_names: List[str]): # 定义类的初始化函数,接收一个字节类型的code和一个字符串列表类型的function_names作为参数self.code = code # 将传入的code参数赋值给self.codeself._function_names = function_names # 将传入的function_names参数赋值给self._function_namesself._cmodule = LazyKernelCModule(self.code) # 使用传入的code创建一个LazyKernelCModule对象,并赋值给self._cmodulefor name in self._function_names: # 遍历_function_names列表setattr(self, name, KernelFunction(self._cmodule, name)) # 为self设置一个属性,属性名为name,值为KernelFunction对象quantization_code = "$QlpoOTFBWSZTWU9yuJUAQHN......"# 尝试加载一组用于权重压缩和解压的 CUDA kernels# 其中,kernels 中包括四种不同的操作:# "int4WeightCompression","int4WeightExtractionFloat",# "int4WeightExtractionHalf","int8WeightExtractionFloat",# "int8WeightExtractionHalf"kernels = Kernel(bz2.decompress(base64.b64decode(quantization_code)),["int4WeightCompression","int4WeightExtractionFloat","int4WeightExtractionHalf","int8WeightExtractionFloat","int8WeightExtractionHalf",],)# 如果在加载过程中出现任何异常,kernels 设为 None,并记录警告信息except Exception as exception:kernels = Nonelogger.warning("Failed to load cpm_kernels:" + str(exception))# 定义一个自定义的 PyTorch autograd 函数,表示一种线性操作
# 这种操作在前向传播过程中使用的是量化后的权重,而在反向传播过程中则使用的是半精度浮点数的权重
class W8A16Linear(torch.autograd.Function):@staticmethoddef forward(ctx, inp: torch.Tensor, quant_w: torch.Tensor, scale_w: torch.Tensor, weight_bit_width):# 保存输入的形状、权重的位宽以及权重的量化值和量化尺度等信息,供后向传播时使用ctx.inp_shape = inp.size()ctx.weight_bit_width = weight_bit_widthout_features = quant_w.size(0)inp = inp.contiguous().view(-1, inp.size(-1))# 提取权重的半精度浮点数表示weight = extract_weight_to_half(quant_w, scale_w, weight_bit_width)ctx.weight_shape = weight.size()# 计算输出output = inp.mm(weight.t())# 保存必要的信息,供后向传播时使用ctx.save_for_backward(inp, quant_w, scale_w)return output.view(*(ctx.inp_shape[:-1] + (out_features,)))@staticmethoddef backward(ctx, grad_output: torch.Tensor):# 提取前向传播时保存的信息inp, quant_w, scale_w = ctx.saved_tensors# 提取权重的半精度浮点数表示weight = extract_weight_to_half(quant_w, scale_w, ctx.weight_bit_width)grad_output = grad_output.contiguous().view(-1, weight.size(0))# 计算输入和权重的梯度grad_input = grad_output.mm(weight)grad_weight = grad_output.t().mm(inp)return grad_input.view(ctx.inp_shape), grad_weight.view(ctx.weight_shape), None, None# 定义一个函数,用于将权重压缩为 int4 格式
def compress_int4_weight(weight: torch.Tensor): # (n, m)with torch.cuda.device(weight.device):n, m = weight.size(0), weight.size(1)assert m % 2 == 0m = m // 2out = torch.empty(n, m, dtype=torch.int8, device="cuda")stream = torch.cuda.current_stream()gridDim = (n, 1, 1)blockDim = (min(round_up(m, 32), 1024), 1, 1)# 调用 CUDA kernels 进行权重压缩kernels.int4WeightCompression(gridDim,blockDim,0,stream,[ctypes.c_void_p(weight.data_ptr()), ctypes.c_void_p(out.data_ptr()), ctypes.c_int32(n), ctypes.c_int32(m)],)return out# 定义一个函数,用于将量化的权重转换为半精度浮点数格式
def extract_weight_to_half(weight: torch.Tensor, scale_list: torch.Tensor, source_bit_width: int):if source_bit_width == 8:func = kernels.int8WeightExtractionHalfelif source_bit_width == 4:func = kernels.int4WeightExtractionHalfelse:assert False, "Unsupported bit-width"with torch.cuda.device(weight.device):n, m = weight.size(0), weight.size(1)out = torch.empty(n, m * (8 // source_bit_width), dtype=torch.half, device="cuda")stream = torch.cuda.current_stream()gridDim = (n, 1, 1)blockDim = (min(round_up(m, 32), 1024), 1, 1)# 调用 CUDA kernels 提取权重func(gridDim,blockDim,0,stream,[ctypes.c_void_p(weight.data_ptr()),ctypes.c_void_p(scale_list.data_ptr()),ctypes.c_void_p(out.data_ptr()),ctypes.c_int32(n),ctypes.c_int32(m),],)return out2.3.2 QuantizedLinear
# 定义一个名为 QuantizedLinear 的类,该类继承自 PyTorch 中的 Linear 类
class QuantizedLinear(Linear):# 初始化函数,接受一些参数,包括权重的位宽、权重张量、偏置张量等def __init__(self, weight_bit_width: int, weight_tensor=None, bias_tensor=None, empty_init=False, *args, **kwargs):# 调用父类的初始化函数super(QuantizedLinear, self).__init__(*args, **kwargs)# 保存权重的位宽self.weight_bit_width = weight_bit_width# 获取权重的形状,并删除父类中的权重shape = self.weight.shapedel self.weight# 如果未指定权重张量,或者指定了空初始化,则初始化权重和权重的量化尺度if weight_tensor is None or empty_init:self.weight = torch.empty(shape[0], shape[1] * weight_bit_width // 8, dtype=torch.int8, device=kwargs["device"])self.weight_scale = torch.empty(shape[0], dtype=kwargs["dtype"], device=kwargs["device"])else: # 否则,计算权重的量化值和量化尺度self.weight_scale = (weight_tensor.abs().max(dim=-1).values / ((2 ** (weight_bit_width - 1)) - 1)).half()self.weight = torch.round(weight_tensor / self.weight_scale[:, None]).to(torch.int8)# 如果权重的位宽为 4,压缩权重if weight_bit_width == 4:self.weight = compress_int4_weight(self.weight)# 将权重和权重的量化尺度设置为参数,并指定它们不需要梯度self.weight = Parameter(self.weight.to(kwargs["device"]), requires_grad=False)self.weight_scale = Parameter(self.weight_scale.to(kwargs["device"]), requires_grad=False)# 如果指定了偏置张量,将偏置设置为参数,并指定它不需要梯度if bias_tensor is not None:self.bias = Parameter(bias_tensor.to(kwargs["device"]), requires_grad=False)else: # 否则,偏置设为 Noneself.bias = None# 定义前向传播函数def forward(self, input):# 应用 W8A16Linear 函数计算输出output = W8A16Linear.apply(input, self.weight, self.weight_scale, self.weight_bit_width)# 如果存在偏置,将偏置加到输出上if self.bias is not None:output = output + self.biasreturn output# 定义一个函数,用于将模型中的线性层替换为量化的线性层
def quantize(model, weight_bit_width, empty_init=False, **kwargs):"""Replace fp16 linear with quantized linear"""# 遍历模型中的每一层for layer in model.layers:# 将每一层中的 query_key_value 替换为量化的线性层layer.attention.query_key_value = QuantizedLinear(weight_bit_width=weight_bit_width,weight_tensor=layer.attention.query_key_value.weight.to(torch.cuda.current_device()),bias_tensor=layer.attention.query_key_value.bias,in_features=layer.attention.query_key_value.in_features,out_features=layer.attention.query_key_value.out_features,bias=True,dtype=torch.half,device=layer.attention.query_key_value.weight.device,empty_init=empty_init)# 将每一层中的 dense 替换为量化的线性层layer.attention.dense = QuantizedLinear(weight_bit_width=weight_bit_width,weight_tensor=layer.attention.dense.weight.to(torch.cuda.current_device()),bias_tensor=layer.attention.dense.bias,in_features=layer.attention.dense.in_features,out_features=layer.attention.dense.out_features,bias=True,dtype=torch.half,device=layer.attention.dense.weight.device,empty_init=empty_init)# 将每一层中的 dense_h_to_4h 替换为量化的线性层layer.mlp.dense_h_to_4h = QuantizedLinear(weight_bit_width=weight_bit_width,weight_tensor=layer.mlp.dense_h_to_4h.weight.to(torch.cuda.current_device()),bias_tensor=layer.mlp.dense_h_to_4h.bias,in_features=layer.mlp.dense_h_to_4h.in_features,out_features=layer.mlp.dense_h_to_4h.out_features,bias=True,dtype=torch.half,device=layer.mlp.dense_h_to_4h.weight.device,empty_init=empty_init)# 将每一层中的 dense_4h_to_h 替换为量化的线性层layer.mlp.dense_4h_to_h = QuantizedLinear(weight_bit_width=weight_bit_width,weight_tensor=layer.mlp.dense_4h_to_h.weight.to(torch.cuda.current_device()),bias_tensor=layer.mlp.dense_4h_to_h.bias,in_features=layer.mlp.dense_4h_to_h.in_features,out_features=layer.mlp.dense_4h_to_h.out_features,bias=True,dtype=torch.half,device=layer.mlp.dense_4h_to_h.weight.device,empty_init=empty_init)return model// 待更..