文章目录
- 问题背景
- 前言
- 实现
- 基于MySQL实现
- 唯一索引
- 乐观锁
- 悲观锁
- 基于Redis
- 基于Zookeeper
- 原理
- 使用Curator框架实现ZK分布式锁
- 缺点
问题背景
研究有哪几种方案可以实现分布式锁,技术选型的场景下能用到。
前言
- 本文参考过的文章有分布式锁的几种实现方式
- 方式大致分为3种:基于磁盘存储的关系型数据库MySQL;基于内存的数据库Redis;基于Zookeeper
实现
基于MySQL实现
基于MySQL也有3种方式:基于唯一索引;基于MySQL行锁的乐观锁;基于悲观锁
唯一索引
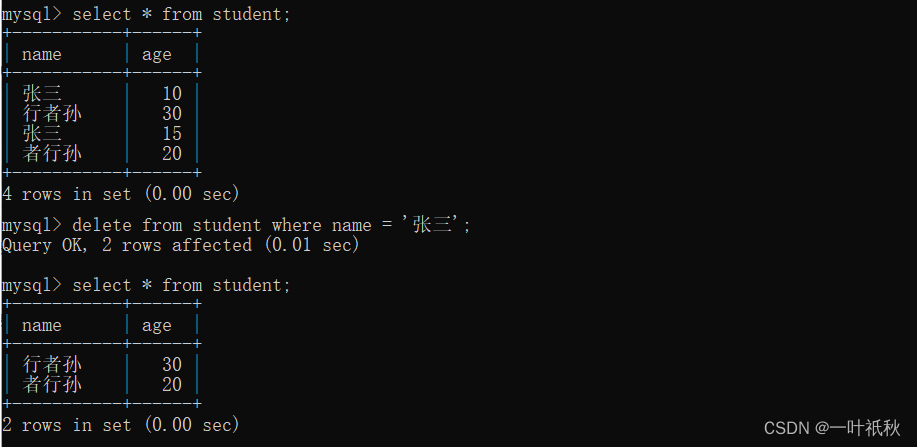
利用唯一索引,在竞争锁时用insert操作,insert成功表示获取锁成功。下面专门创建一张表实现分布式锁:
CREATE TABLE `database_lock` (`id` BIGINT NOT NULL AUTO_INCREMENT,`resource` int NOT NULL COMMENT '锁定的资源',`description` varchar(1024) NOT NULL DEFAULT "" COMMENT '描述',PRIMARY KEY (`id`),UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
通过insert操作竞争锁,通过delete操作释放锁。
优点:实现简单,复杂度低
缺点:
- 锁没有过期时间。可以利用RocketMQ的延时消息或者延时线程池、利用定时任务使锁过期。
- 强依赖于数据库。建议设置备库或者集群,避免的单点数据库挂了,提高可靠性。
- 非阻塞。竞争锁失败则会继续往下执行业务,不会继续重试获取锁,也不会阻塞等待。可以使用 for、while实现阻塞等待或循坏尝试竞争锁。
- 非可重入。数据库表没有记录获取到锁的唯一信息(比如线程信息、进程信息、主机信息),增加字段记录这些信息实现可重入。竞争锁时根据自身的信息(线程信息、进程信息、主机信息)查询表,表中有记录则获取锁成功,实现了可重入。
- 如果并发高,则会有大量请求失败或者大量写压力给到数据库。
乐观锁
利用mysql自带的行锁机制,前提是本身就要在数据库里面有数据
CREATE TABLE `optimistic_lock` (`id` BIGINT NOT NULL AUTO_INCREMENT,`resource` int NOT NULL COMMENT '锁定的资源',`version` int NOT NULL COMMENT '版本信息',`created_at` datetime COMMENT '创建时间',`updated_at` datetime COMMENT '更新时间',`deleted_at` datetime COMMENT '删除时间', PRIMARY KEY (`id`),UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
实现的SQL如下:
update optimistic_lock set resource = xx, version = newVersion where id = xx and version = oldVersion;
解释:需要通过主键id去加行锁,否则会走范围锁或者表锁。更新时不仅要更新资源值,也要更新版本信息。查询需要带上版本号信息。
优缺点与唯一索引是宪法方式一样。大量并发下会有大量请求失败或者写压力很高,不适合高并发。
悲观锁
利用MySQL的X排他锁
在查询语句后面增加FOR UPDATE,数据库会在查询过程中给数据库表增加悲观锁,也称排他锁。当某条记录被加上悲观锁之后,其它线程也就无法再改行上增加悲观锁。
在使用悲观锁时,我们必须关闭MySQL数据库的自动提交属性(参考下面的示例),因为MySQL默认使用autocommit模式
mysql> SET AUTOCOMMIT = 0;
这样在使用FOR UPDATE获得锁之后可以执行相应的业务逻辑,执行完之后再使用COMMIT来释放锁。
优点:
在悲观锁中,每一次行数据的访问都是独占的,只有当正在访问该行数据的请求事务提交以后,其他请求才能依次访问该数据,否则将阻塞等待锁的获取。悲观锁可以严格保证数据访问的安全。
缺点:
-
每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性。另外,悲观锁使用不当还可能产生死锁的情况。
-
使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
基于Redis
详情见笔者写的大厂的Redis分布式锁是如何设计的
基于Zookeeper
原理
利用ZK的临时顺序节点实现分布式锁。
- ZooKeeper的每一个节点都是一个天然的顺序发号器。在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面会加上一个顺序编号。这个顺序编号是在上一个生成的顺序编号加1。
- ZooKeeper节点的递增有序性可以确保锁的公平。一个ZooKeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程都在这个节点下创建个临时顺序节点。由于Zk节点是按照创建的顺序依次递增的,为了确保公平,可以简单地规定,编号最小的那个节点表示获得了锁。因此,每个线程在尝试占用锁之前,首先判断自己的排号是不是当前最小的,如果是,则获取锁。
- ZooKeeper的节点监听机制可以保障占有锁的传递有序而且高效。ZooKeeper内部优越的机制,能保证由于网络异常或者其他原因造成集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用锁的ZNode客户端与ZooKeeper集群服务器失去联系,这个临时ZNode也将自动删除。排在它后面的那个节点也能收到删除事件,从而获得锁。所以,在创建取号节点的时候,尽量创建临时ZNode节点,
- ZooKeeper的节点监听机制能避免羊群效应。ZooKeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是一个节点挂掉了,所有节点都去监听,然后作出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才作出反应。
使用Curator框架实现ZK分布式锁
详情见笔者写的SpringBoot基于Zookeeper实现分布式锁
Curator提供的InterProcessMutex是分布式锁的实现。acquire方法用户获取锁,release方法用于释放锁。
缺点
- 性能上: 性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有的Follower机器上。
- 并发问题: 使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。(所以,选择一个合适的重试策略也比较重要,要在锁的粒度和并发之间找一个平衡。)