文章目录
- 概要
- 端点注册
- 创建监听容器
- 启动监听容器
- 消息拉取与消费
- 小结
概要
本文主要从Spring Kafka的源码来分析,消费端消费流程;从spring容器启动到消息被拉取下来,再到执行客户端自定义的消费逻辑,大致概括为以下4个部分:
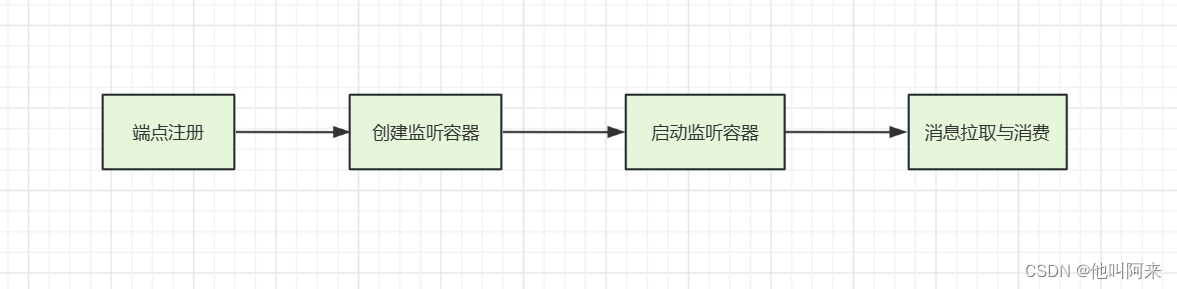
源码分析主要也是从以上4个部分进行分析;
环境准备
maven依赖如下:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.6.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
消费端代码:
@KafkaListener(topics = KafkaController.TOPIC_TEST_ERROR, groupId = "${spring.application.name}")public void replicatedTopicConsumer2(ConsumerRecord<String, String> recordInfo) {int partition = recordInfo.partition();System.out.println("partition:" + partition);String value = recordInfo.value();System.out.println(value);}
参数配置使用默认配置
端点注册
KafkaAutoConfiguration
与其他组件相同,spring-kafka的入口加载入口类也是以AutoConfiguration结尾,即:KafkaAutoConfiguration,由于本文重点分析消费者流程,自动类这里主要关注以下几个地方:
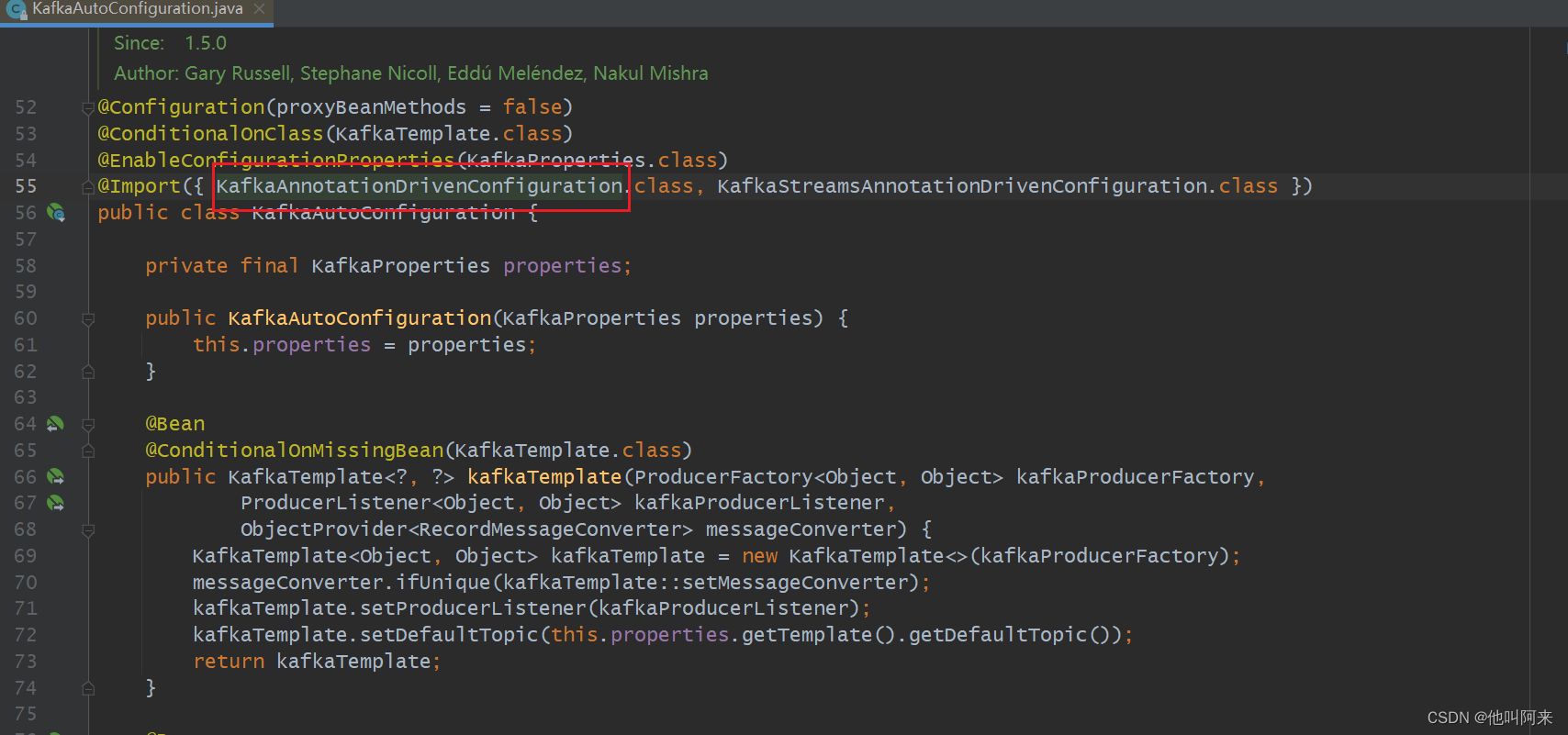
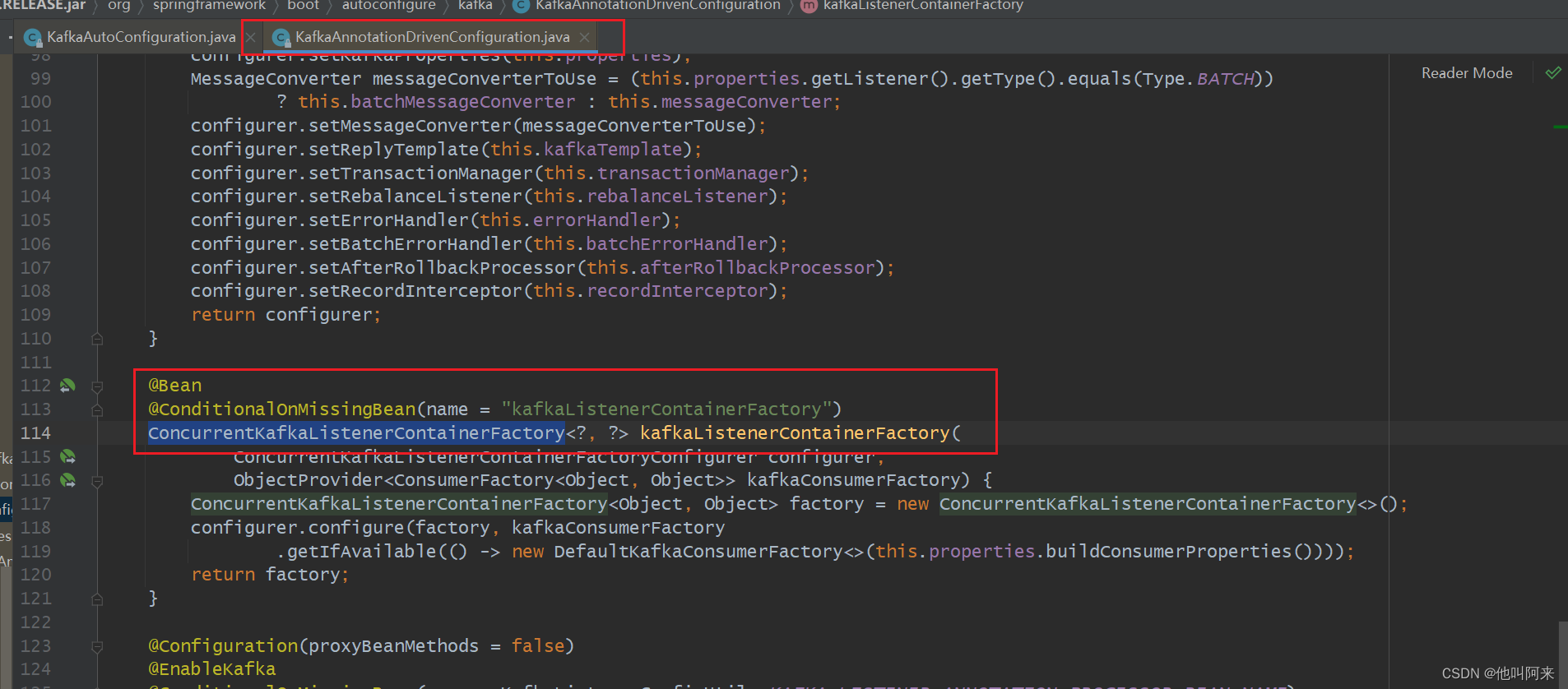
kafka启动后,会自动将ConcurrentKafkaListenerContainerFactory加载到容器中。
一般来说,消费端会使用到@KafkaListener注解或者@KafkaListeners注解,所以,我们的重点就是只要是关注,这两个注解是如何被识别,并且起到监听作用的,以下是类的加载流程:
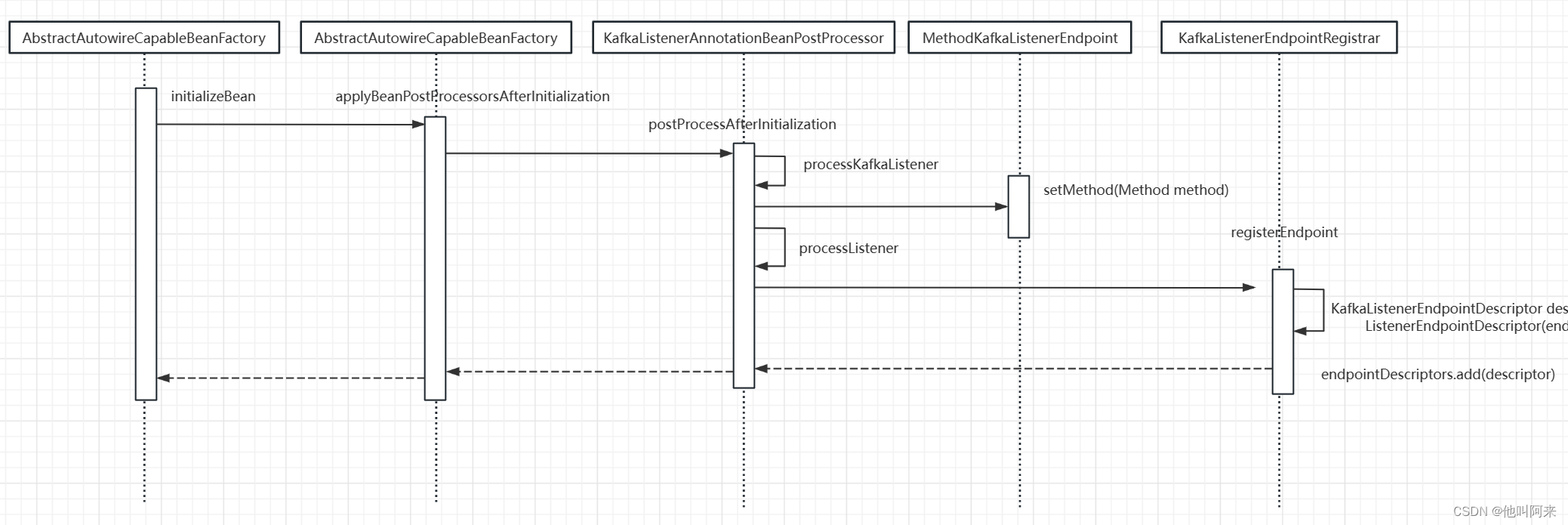
Bean在执行init方法后会调用,初始化后置处理方法,而KafkaListenerAnnotationBeanPostProcessor实现了BeanPostProcessor,KafkaListenerAnnotationBeanPostProcessor#postProcessAfterInitialization就会被触发执行,在该方法中,会读取该bean中标注了@KafkaListener和@KafkaListeners的方法
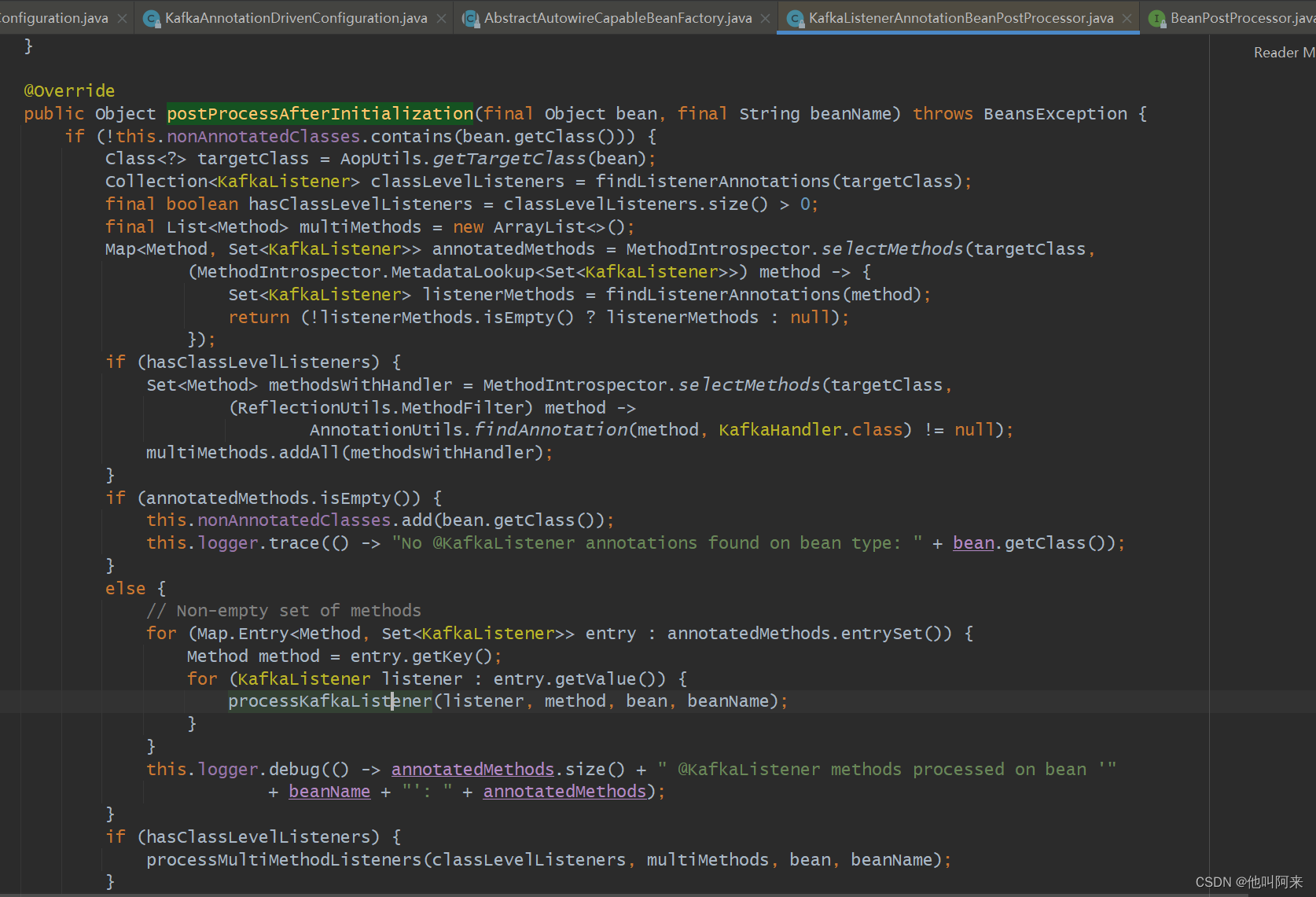
protected void processKafkaListener(KafkaListener kafkaListener, Method method, Object bean, String beanName) {Method methodToUse = checkProxy(method, bean);MethodKafkaListenerEndpoint<K, V> endpoint = new MethodKafkaListenerEndpoint<>();endpoint.setMethod(methodToUse);processListener(endpoint, kafkaListener, bean, methodToUse, beanName);}
从上面看出,每个标注了KafkaListener注解的方法都会创建一个MethodKafkaListenerEndpoint,接着调用KafkaListenerEndpointRegistrar#registerEndpoint(KafkaListenerEndpoint,KafkaListenerContainerFactory<?>)进行注册
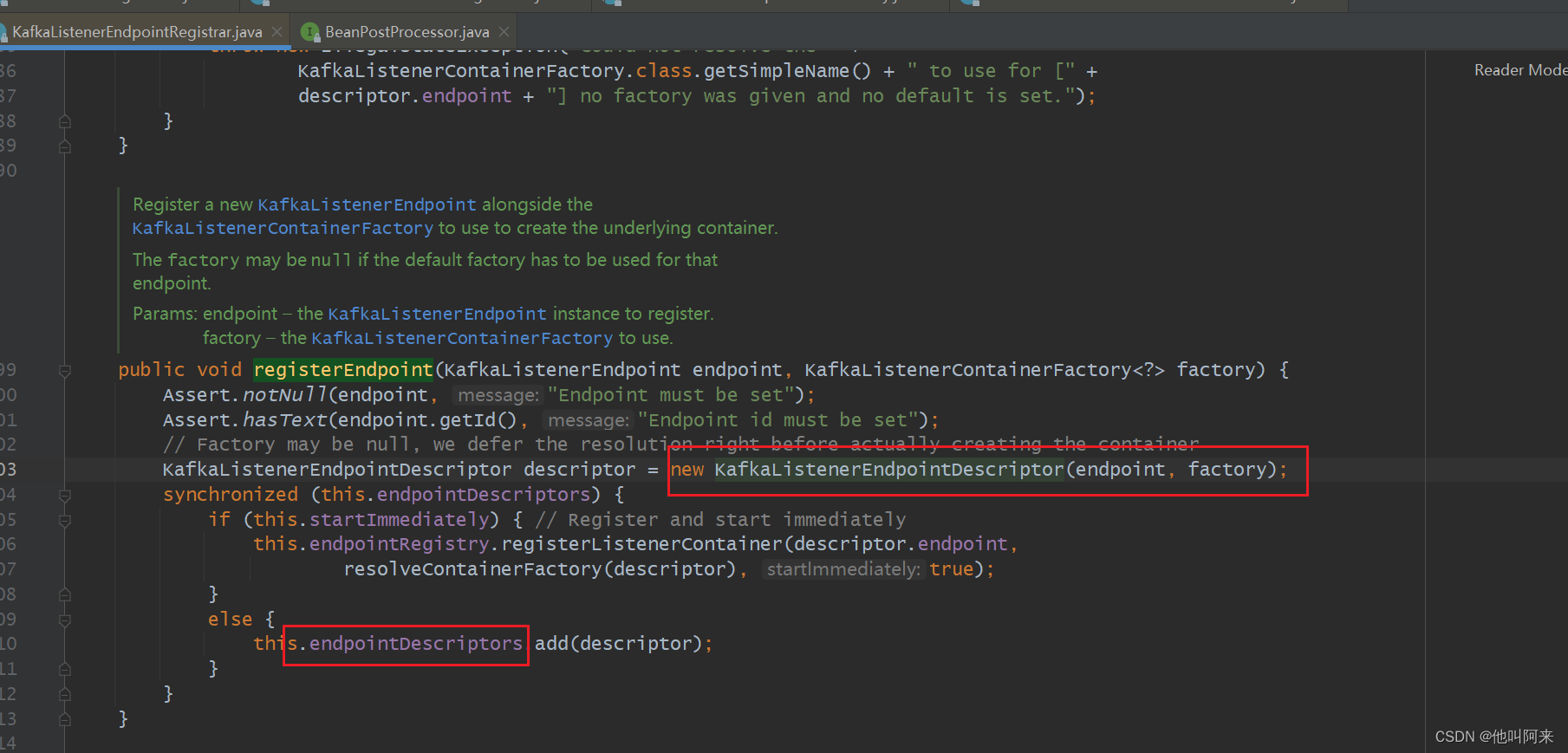
由MethodKafkaListenerEndpoint又得到KafkaListenerEndpointDescriptor,最后将有的KafkaListenerEndpointDescriptor放到endpointDescriptors集合中
这里需要注意的是,KafkaListenerAnnotationBeanPostProcessor中的KafkaListenerEndpointRegistrar registrar属性是new出来的,并没有在spring容器中,而后面的创建监听器时还会再用到。
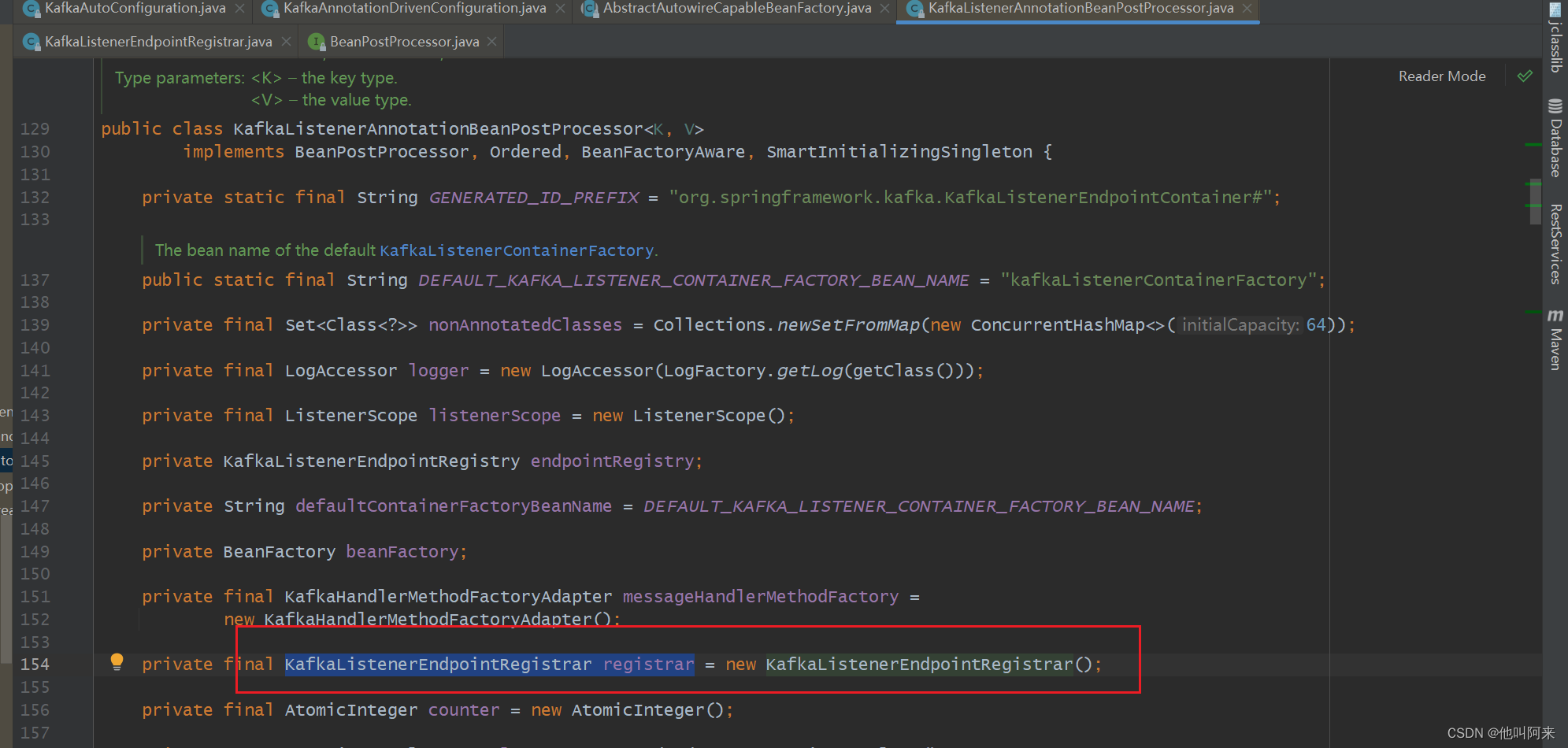
以上就是kafka端点注册流程。
创建监听容器
spring kafka把每个标注了KafkaListener注解的方法称为Endpoint,为每个方法生成了一个MethodKafkaListenerEndpoint对象,同时又为每个端点生成了一个MessageListenerContainer;以下是具体的生成流程
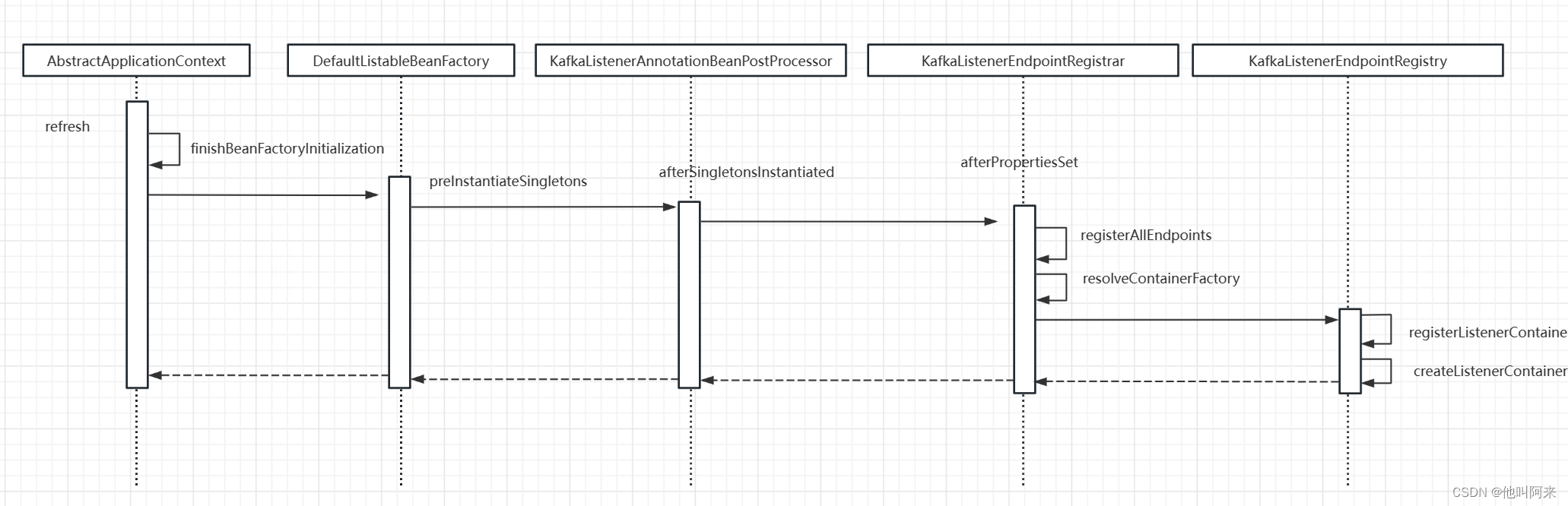
KafkaListenerAnnotationBeanPostProcessor实现了SmartInitializingSingleton,其中的方法afterSingletonsInstantiated会在bean初始化后进行执行
@Override
public void afterSingletonsInstantiated() {// 这个registrar没有放入到spring 容器中this.registrar.setBeanFactory(this.beanFactory);if (this.beanFactory instanceof ListableBeanFactory) {Map<String, KafkaListenerConfigurer> instances =((ListableBeanFactory) this.beanFactory).getBeansOfType(KafkaListenerConfigurer.class);for (KafkaListenerConfigurer configurer : instances.values()) {configurer.configureKafkaListeners(this.registrar);}}if (this.registrar.getEndpointRegistry() == null) {if (this.endpointRegistry == null) {Assert.state(this.beanFactory != null,"BeanFactory must be set to find endpoint registry by bean name");this.endpointRegistry = this.beanFactory.getBean(KafkaListenerConfigUtils.KAFKA_LISTENER_ENDPOINT_REGISTRY_BEAN_NAME,KafkaListenerEndpointRegistry.class);}this.registrar.setEndpointRegistry(this.endpointRegistry);}if (this.defaultContainerFactoryBeanName != null) {this.registrar.setContainerFactoryBeanName(this.defaultContainerFactoryBeanName);}// Set the custom handler method factory once resolved by the configurerMessageHandlerMethodFactory handlerMethodFactory = this.registrar.getMessageHandlerMethodFactory();if (handlerMethodFactory != null) {this.messageHandlerMethodFactory.setHandlerMethodFactory(handlerMethodFactory);}else {addFormatters(this.messageHandlerMethodFactory.defaultFormattingConversionService);}// 主要方法,注册端点并创建容器this.registrar.afterPropertiesSet();
}
···
**KafkaListenerEndpointRegistrar**```java
@Override
public void afterPropertiesSet() {registerAllEndpoints();
}protected void registerAllEndpoints() {synchronized (this.endpointDescriptors) {// 上一个阶段已经把所有的端点放入了endpointDescriptors集合中for (KafkaListenerEndpointDescriptor descriptor : this.endpointDescriptors) {this.endpointRegistry.registerListenerContainer(// 注意这个resolveContainerFactorydescriptor.endpoint, resolveContainerFactory(descriptor));}this.startImmediately = true; // trigger immediate startup}
}// 如果在KafkaListener注解中的属性containerFactory没有配置容器工厂的名字,就会默认获取ConcurrentKafkaListenerContainerFactory实现类作为容器工厂
private KafkaListenerContainerFactory<?> resolveContainerFactory(KafkaListenerEndpointDescriptor descriptor) {if (descriptor.containerFactory != null) {return descriptor.containerFactory;}else if (this.containerFactory != null) {return this.containerFactory;}else if (this.containerFactoryBeanName != null) {Assert.state(this.beanFactory != null, "BeanFactory must be set to obtain container factory by bean name");this.containerFactory = this.beanFactory.getBean(this.containerFactoryBeanName, KafkaListenerContainerFactory.class);return this.containerFactory; // Consider changing this if live change of the factory is required}else {throw new IllegalStateException("Could not resolve the " +KafkaListenerContainerFactory.class.getSimpleName() + " to use for [" +descriptor.endpoint + "] no factory was given and no default is set.");}}
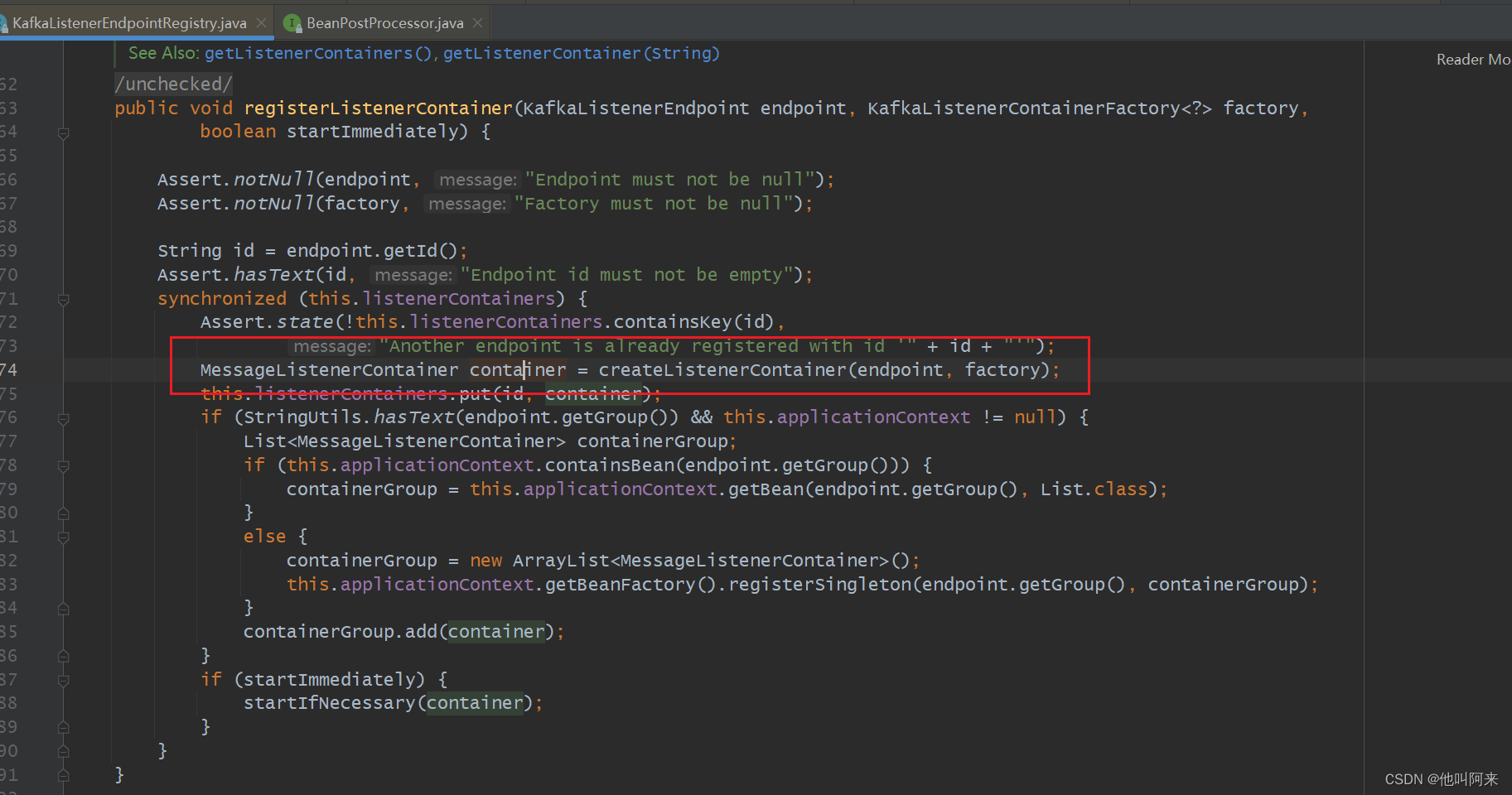
以上截图是真正创建容器的地方,并把创建好的容器添加到Map<String, MessageListenerContainer> listenerContainers,后面起动时会用到。
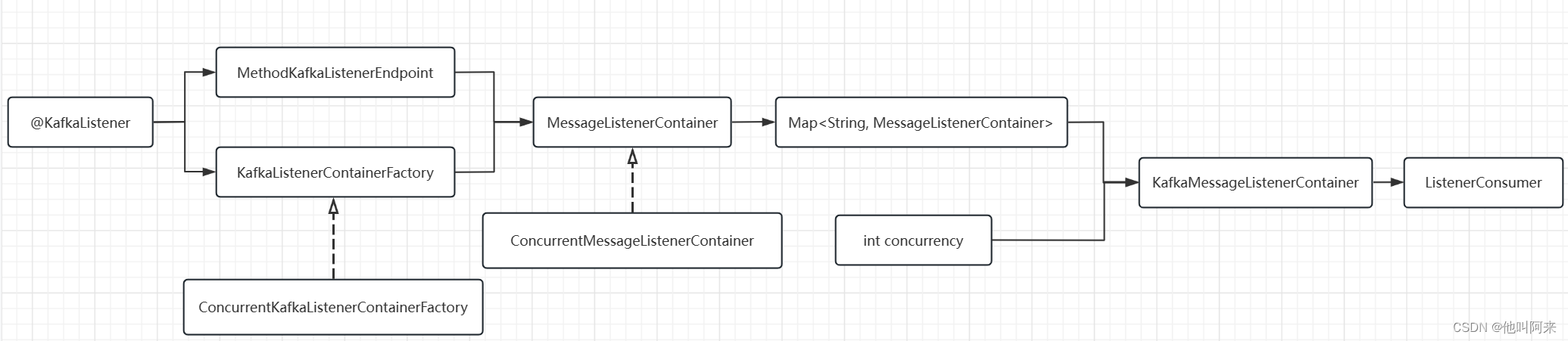
至此,kafka监听容器创建完成,整理下主要类之间的关系,如下
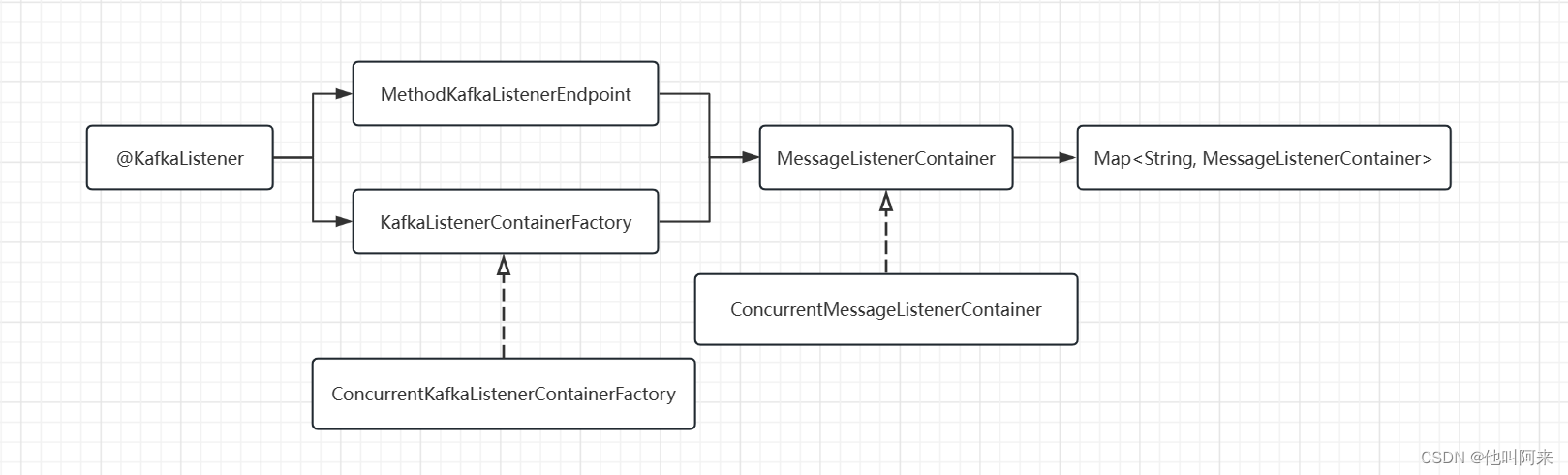
一个@KafkaListener注解标注的方法,就可以得到一个MethodKafkaListenerEndpoint,再使用默认的ConcurrentKafkaListenerContainerFactory就会创建出一个MessageListenerContainer监听容器,有几个方法标注了@KafkaListener 就可以得到几个ConcurrentMessageListenerContainer
启动监听容器
上面的流程知道,所有创建的容器放到了`Map<String, MessageListenerContainer> listenerContainers``
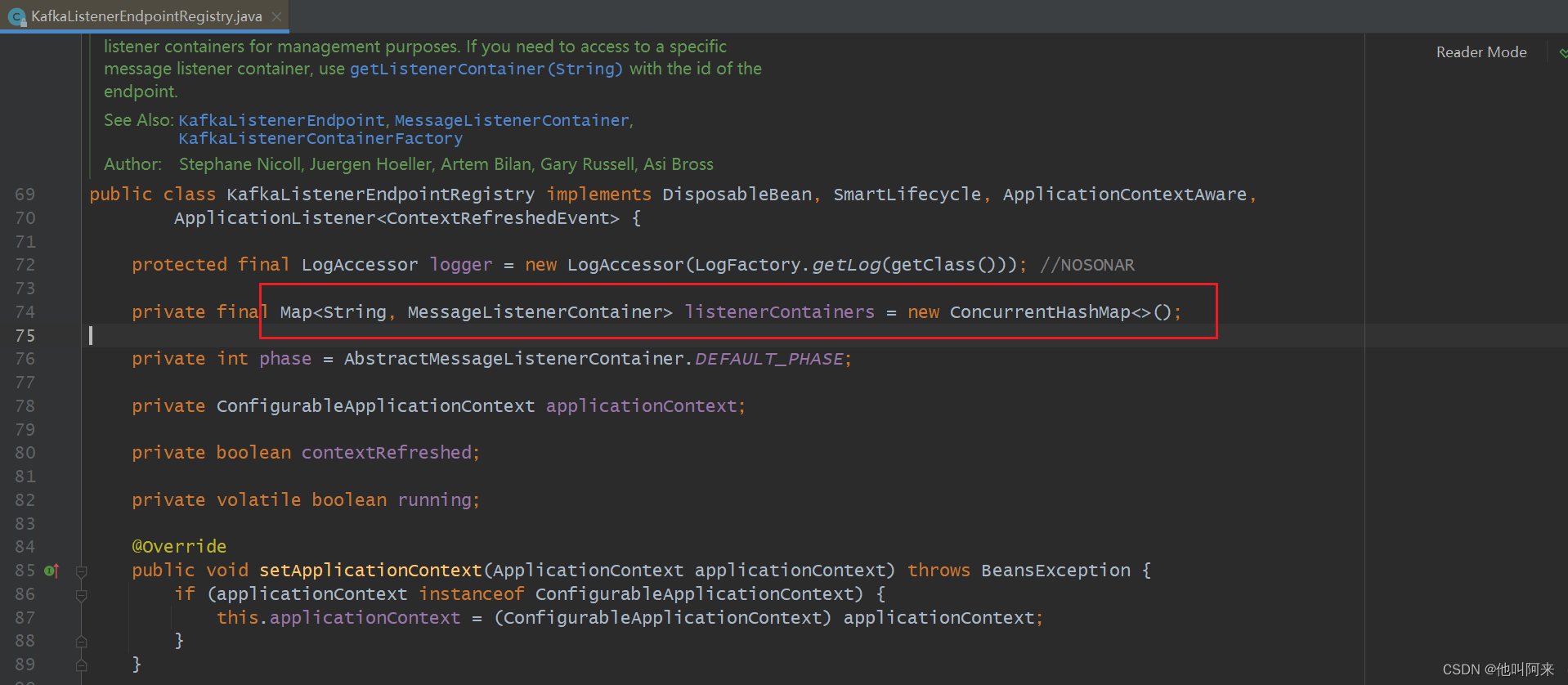
KafkaListenerEndpointRegistry实现了Lifecycle,其中的start()方法会在bean加载的最后一个阶段中被执行到
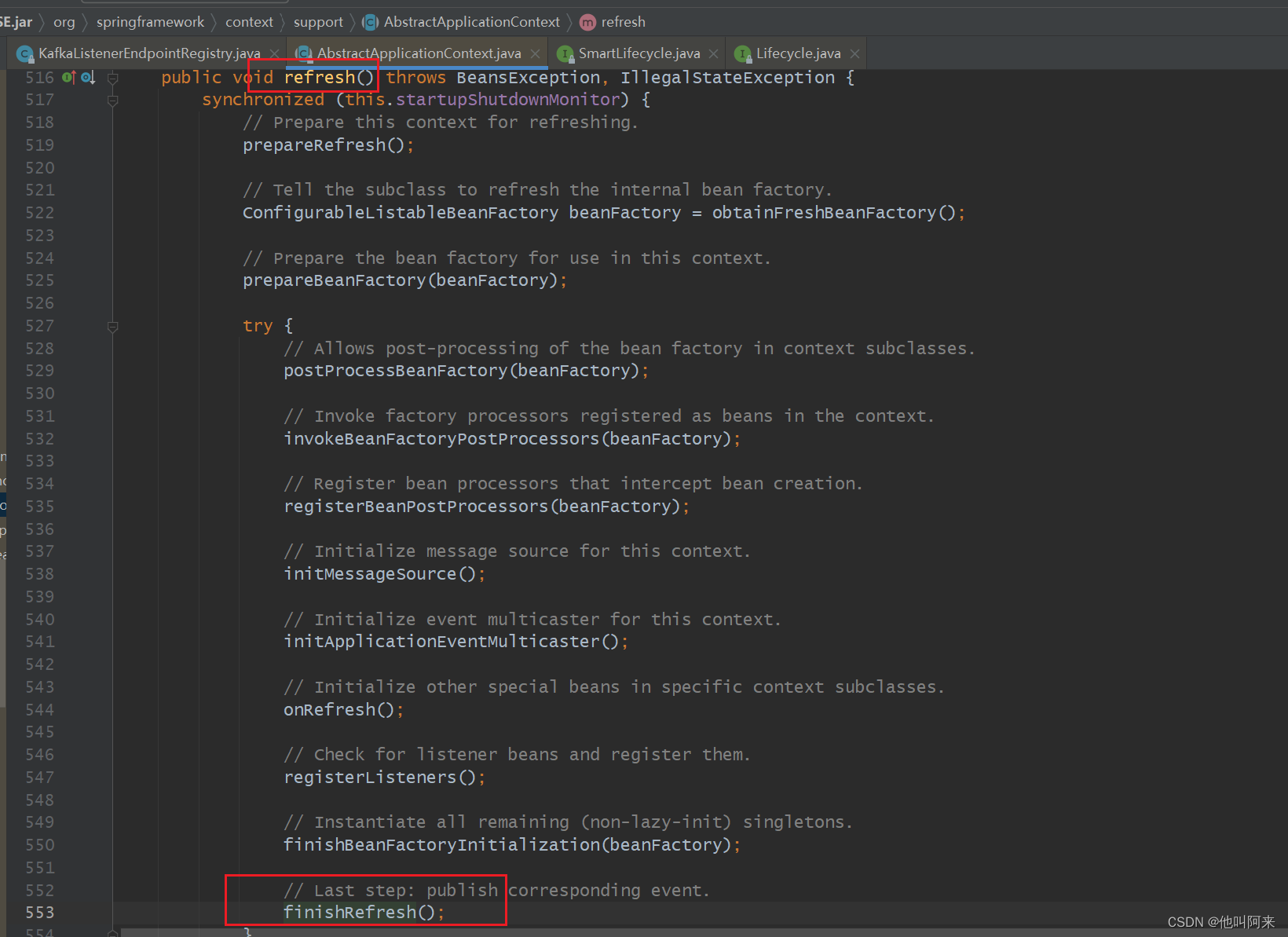
以下是执行流程
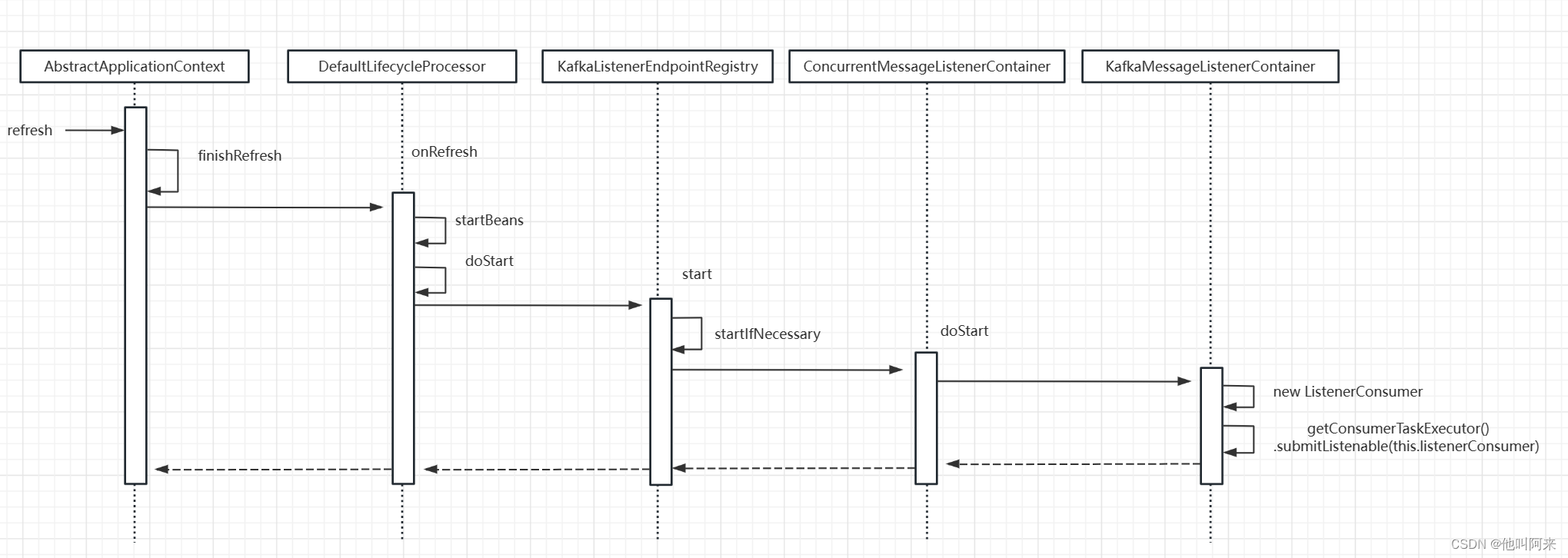
其中org.springframework.kafka.listener.KafkaMessageListenerContainer#doStart如下
@Override
protected void doStart() {if (isRunning()) {return;}if (this.clientIdSuffix == null) { // stand-alone containercheckTopics();}ContainerProperties containerProperties = getContainerProperties();checkAckMode(containerProperties);Object messageListener = containerProperties.getMessageListener();if (containerProperties.getConsumerTaskExecutor() == null) {SimpleAsyncTaskExecutor consumerExecutor = new SimpleAsyncTaskExecutor((getBeanName() == null ? "" : getBeanName()) + "-C-");containerProperties.setConsumerTaskExecutor(consumerExecutor);}GenericMessageListener<?> listener = (GenericMessageListener<?>) messageListener;ListenerType listenerType = determineListenerType(listener);// ListenerConsumer的构造函数中创建了真正的Consumer<K, V> consumerthis.listenerConsumer = new ListenerConsumer(listener, listenerType);setRunning(true);this.startLatch = new CountDownLatch(1);// ListenerConsumer 实现了Runnable,调用submitListenable是就会开启新的线程执行其中的run方法this.listenerConsumerFuture = containerProperties.getConsumerTaskExecutor().submitListenable(this.listenerConsumer);try {if (!this.startLatch.await(containerProperties.getConsumerStartTimout().toMillis(), TimeUnit.MILLISECONDS)) {this.logger.error("Consumer thread failed to start - does the configured task executor "+ "have enough threads to support all containers and concurrency?");publishConsumerFailedToStart();}}catch (@SuppressWarnings(UNUSED) InterruptedException e) {Thread.currentThread().interrupt();}
}
每个监听容器ConcurrentMessageListenerContainer中都会创建一个出一个ListenerConsumer或多个(跟concurrency参数配置有关)ListenerConsumer,真正从kafka服务端拉去消息的逻辑在ListenerConsumer的run方法中。
到这里,主要类跟参数之间的对应关系如下
消息拉取与消费
这一阶段只要关注,消息的拉取到触发用户自定义方法流程与自动位移提交
不断循环拉去消息,并反射调用用户自定义方法:
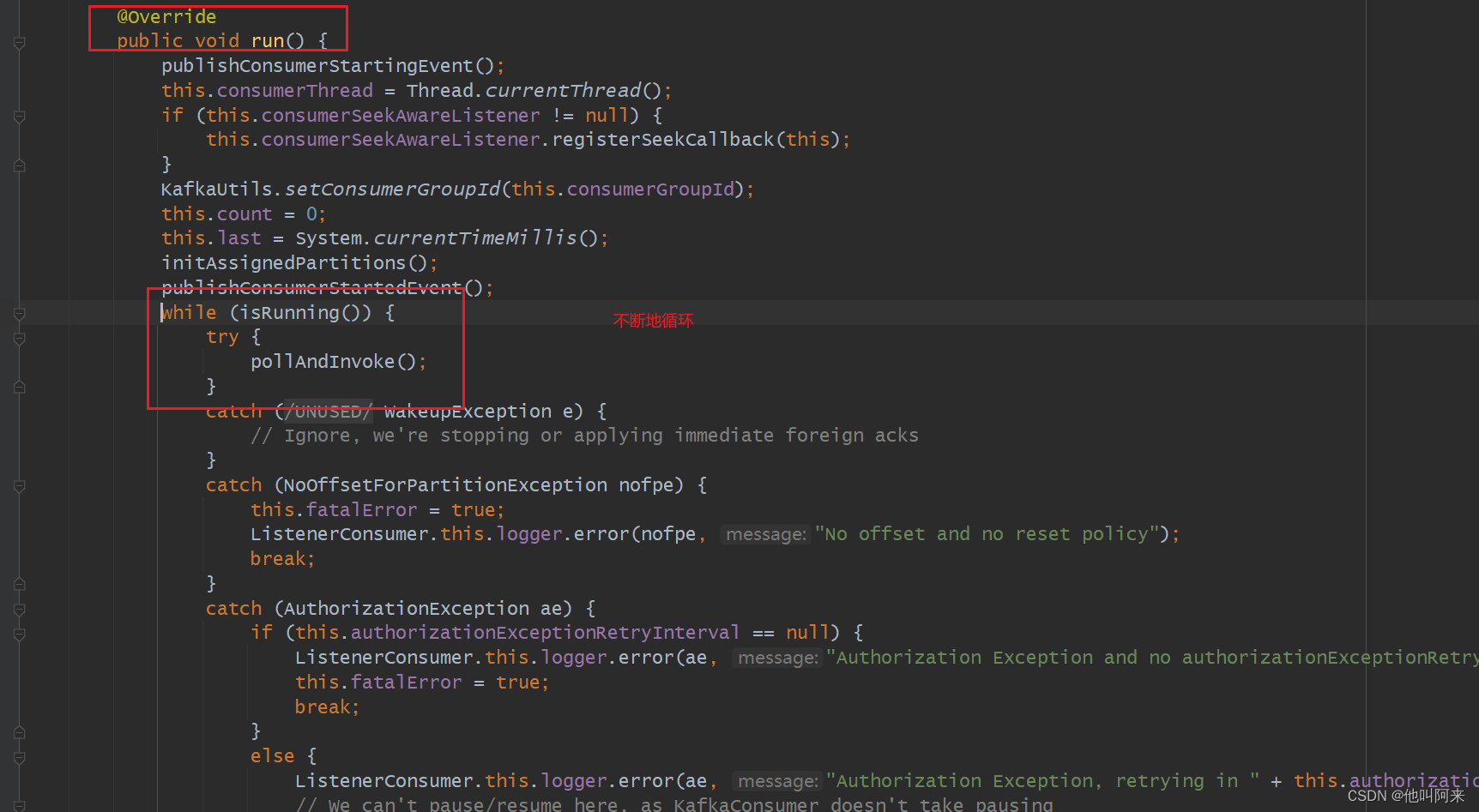
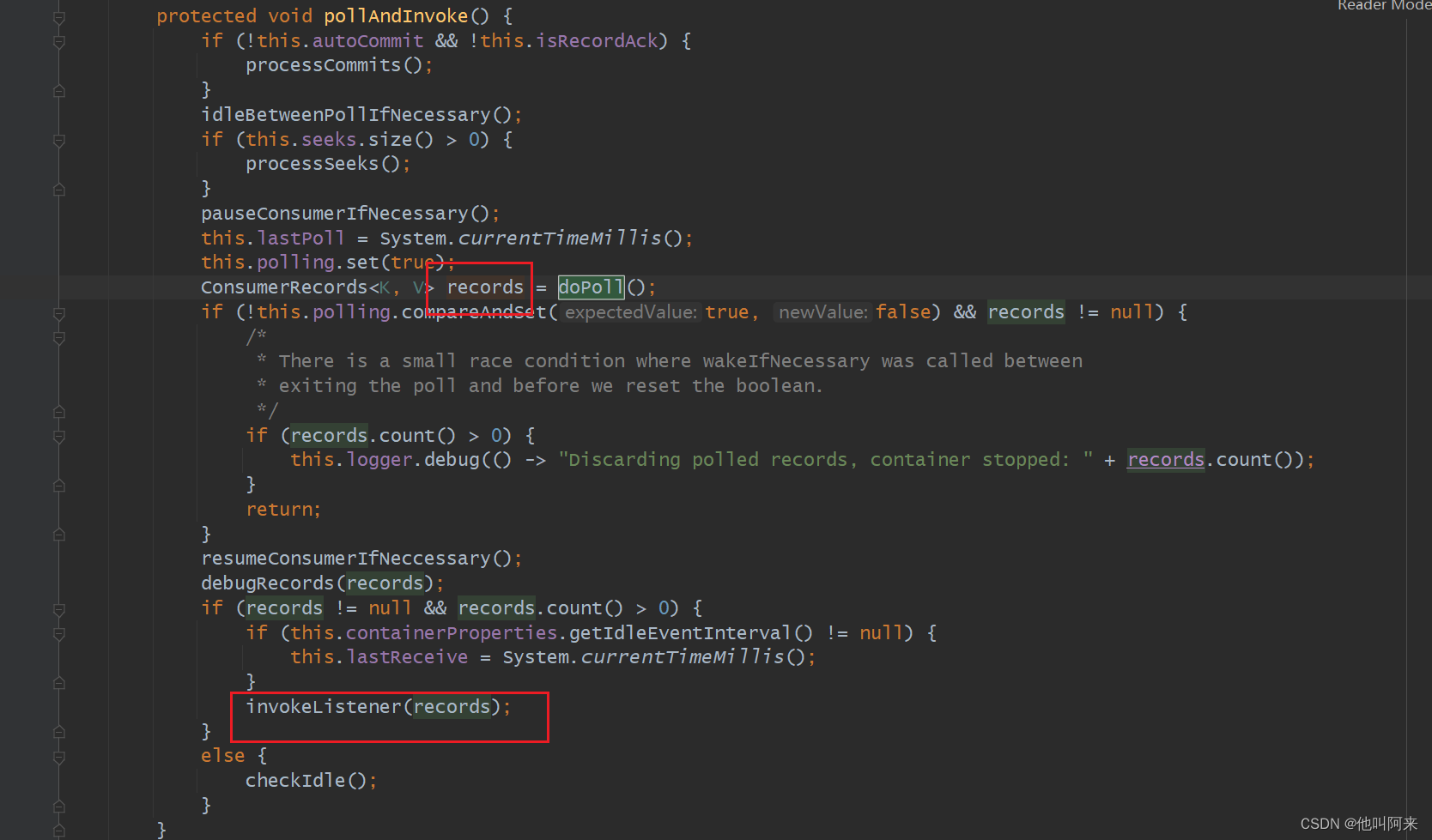
protected void pollAndInvoke() {if (!this.autoCommit && !this.isRecordAck) {processCommits();}idleBetweenPollIfNecessary();if (this.seeks.size() > 0) {processSeeks();}pauseConsumerIfNecessary();this.lastPoll = System.currentTimeMillis();this.polling.set(true);// 调用kafka原生api进行拉取ConsumerRecords<K, V> records = doPoll();if (!this.polling.compareAndSet(true, false) && records != null) {/** There is a small race condition where wakeIfNecessary was called between* exiting the poll and before we reset the boolean.*/if (records.count() > 0) {this.logger.debug(() -> "Discarding polled records, container stopped: " + records.count());}return;}resumeConsumerIfNeccessary();debugRecords(records);if (records != null && records.count() > 0) {if (this.containerProperties.getIdleEventInterval() != null) {this.lastReceive = System.currentTimeMillis();}// 获取消息后,触发@KafkaListener标注地方法invokeListener(records);}else {checkIdle();}
}
下面先关注消费者位移在dopoll方法中什么时候触发提交地
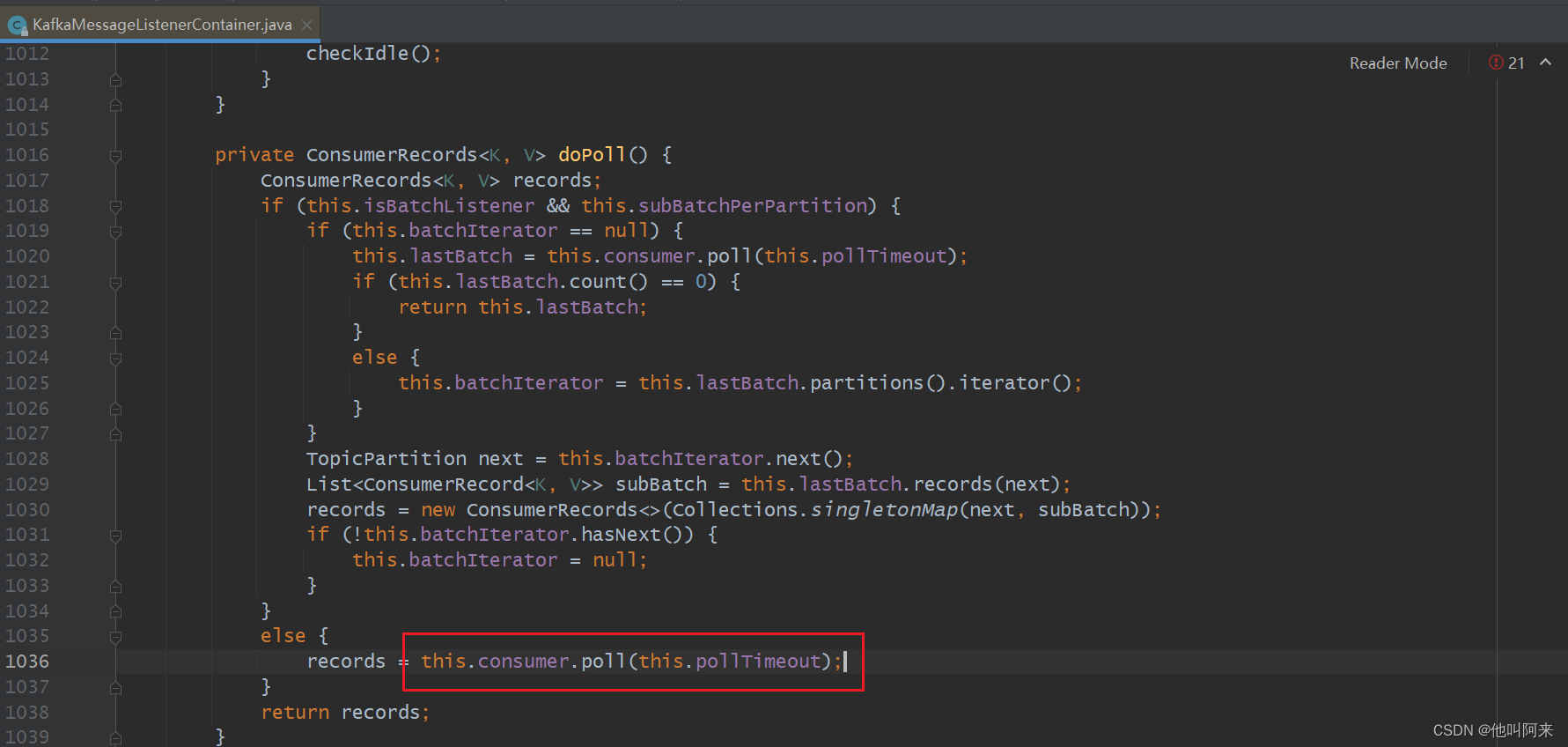
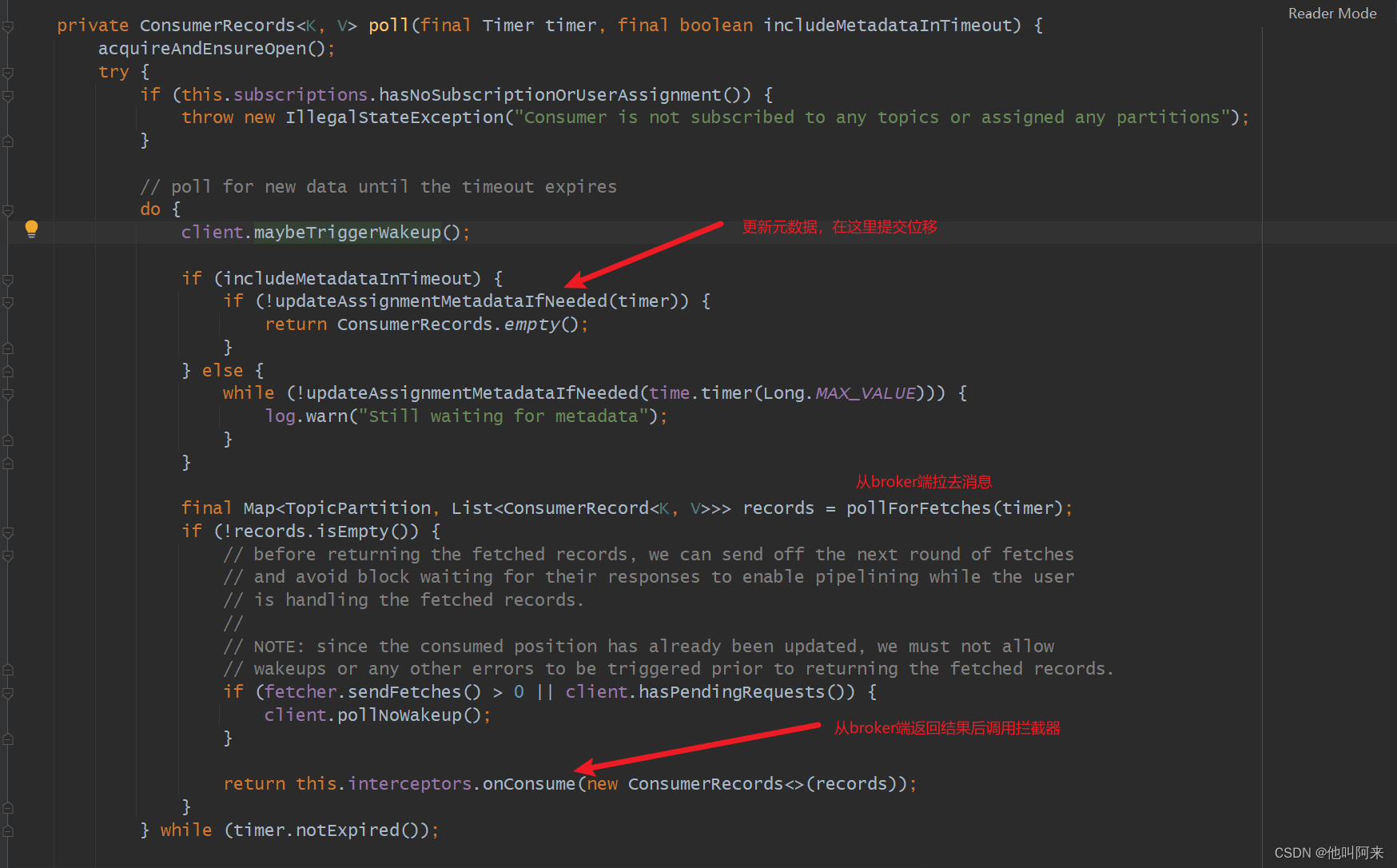
// 每个消费组都有一个消费者协调器coordinator,在coordinator.poll方法中会判断是否需要自动提交位移
boolean updateAssignmentMetadataIfNeeded(final Timer timer) {if (coordinator != null && !coordinator.poll(timer)) {return false;}return updateFetchPositions(timer);}public boolean poll(Timer timer) {maybeUpdateSubscriptionMetadata();invokeCompletedOffsetCommitCallbacks();if (subscriptions.partitionsAutoAssigned()) {// Always update the heartbeat last poll time so that the heartbeat thread does not leave the// group proactively due to application inactivity even if (say) the coordinator cannot be found.// 唤醒心跳检测线程,触发一次心跳检测pollHeartbeat(timer.currentTimeMs());if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {return false;}if (rejoinNeededOrPending()) {// due to a race condition between the initial metadata fetch and the initial rebalance,// we need to ensure that the metadata is fresh before joining initially. This ensures// that we have matched the pattern against the cluster's topics at least once before joining.if (subscriptions.hasPatternSubscription()) {// For consumer group that uses pattern-based subscription, after a topic is created,// any consumer that discovers the topic after metadata refresh can trigger rebalance// across the entire consumer group. Multiple rebalances can be triggered after one topic// creation if consumers refresh metadata at vastly different times. We can significantly// reduce the number of rebalances caused by single topic creation by asking consumer to// refresh metadata before re-joining the group as long as the refresh backoff time has// passed.if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {this.metadata.requestUpdate();}if (!client.ensureFreshMetadata(timer)) {return false;}maybeUpdateSubscriptionMetadata();}if (!ensureActiveGroup(timer)) {return false;}}} else {// For manually assigned partitions, if there are no ready nodes, await metadata.// If connections to all nodes fail, wakeups triggered while attempting to send fetch// requests result in polls returning immediately, causing a tight loop of polls. Without// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.// When group management is used, metadata wait is already performed for this scenario as// coordinator is unknown, hence this check is not required.if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {client.awaitMetadataUpdate(timer);}}// 判断是否需要自动提交位移maybeAutoCommitOffsetsAsync(timer.currentTimeMs());return true;
}
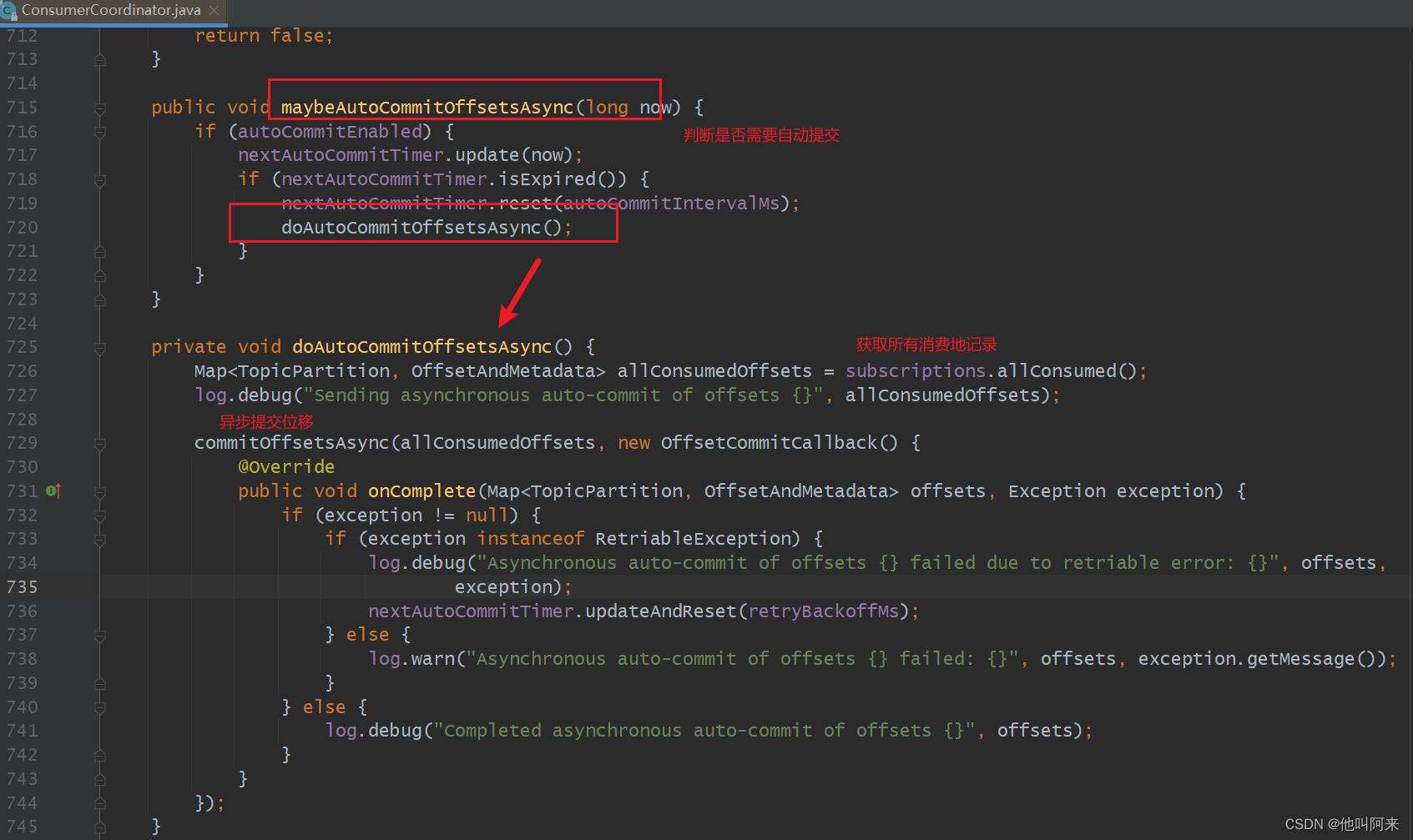
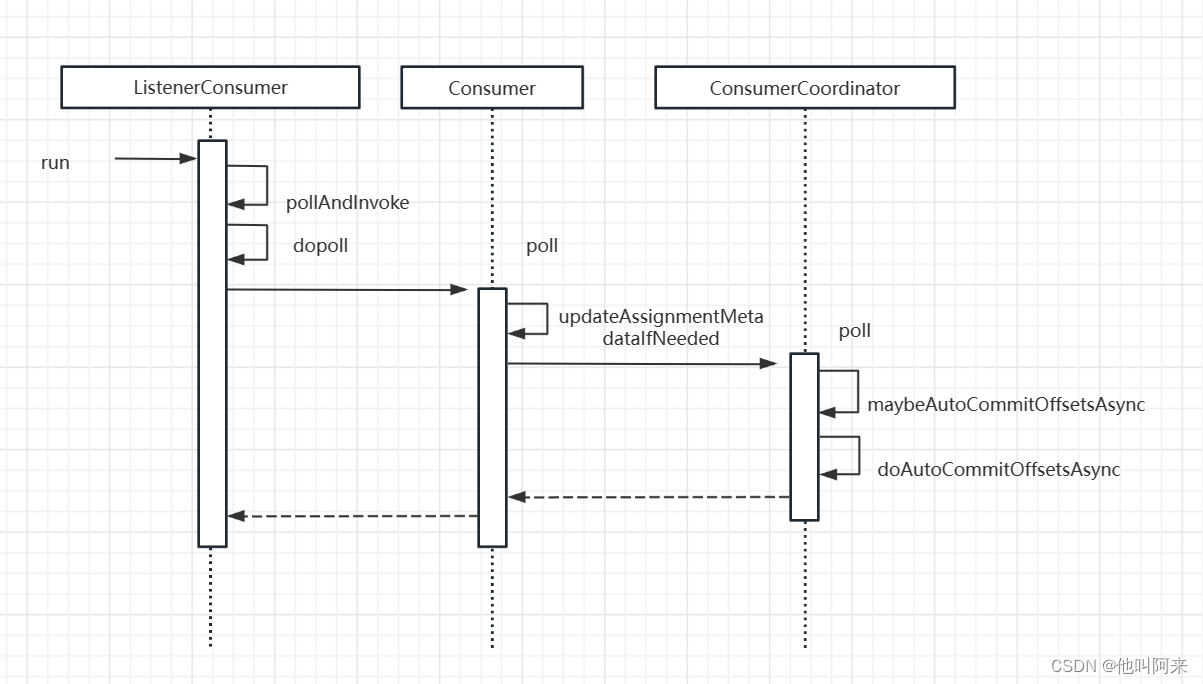
以下就是消息拉去义位移自动提交地处理流程
记录返回后,会调用用户自定义地处理逻辑
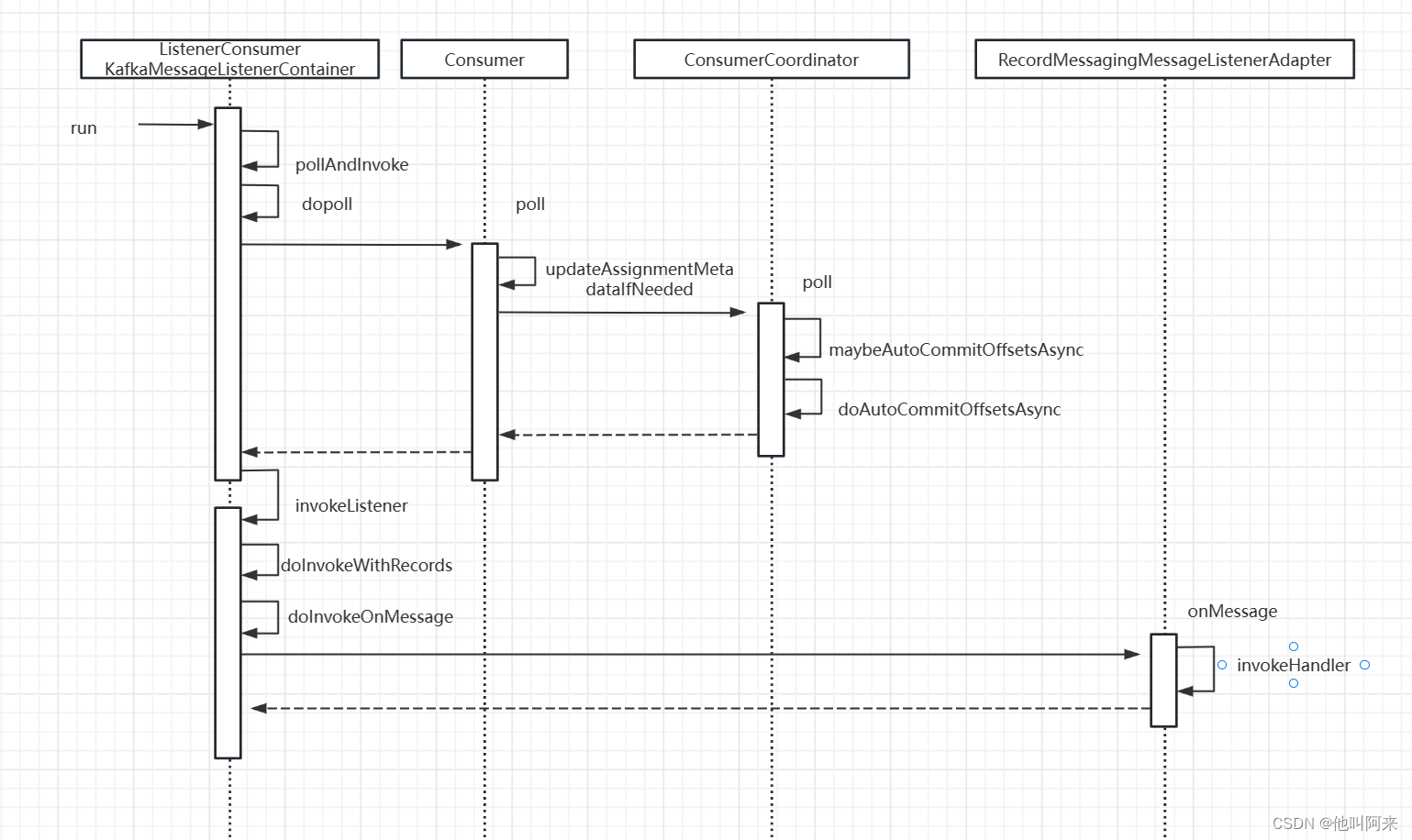
以下时具体地调用流程
小结
1、kafka spring消费者端点注册、创建监听容器、启动监听容器阶段,有两个重要的类KafkaListenerAnnotationBeanPostProcessor和KafkaListenerEndpointRegistry,他们对应的方法postProcessAfterInitialization和 start在spring容器启动时会被执行,从而实现了kafka的监听容器的创建与启动
2、kafka自动提交位移时在poll方法中进行的,也就是每次获取新消息时,会先提交上次消费完成的消息;
3、拉取消息跟用户标注了@KafkaListener注解方法的处理逻辑用的是同一个线程,自动提交时间auto.commit.interval.ms默认是5s,假如用户的方法逻辑处理时长是10s,那么位移自动提交是在10s后再次调用poll方法时才会提交,而不是5s后就准时提交。