目录
- 0.导读
- 1.背景介绍
- 1.1基础架构
- 1.2目标函数
- 1.2.1对比式学习
- 1.2.2生成式学习
- 1.3预训练
- 1.3.1预训练数据集
- 1.3.2微调
- 1.3.3提示工程
- 2.基于文本提示的基础模型
- 2.1基于对比学习的方法
- 2.1.1基于通用模型的对比方法
- 2.1.2基于视觉定位基础模型的方法
- 2.2基于生成式的方法
- 2.3基于对比学习和生成式的混合方法
- 2.4基于对话式的视觉语言模型
- 3.基于视觉提示的基础模型
- 3.1视觉基础模型
- 3.1.1 CLIPSeg
- 3.1.2 SegGPT
- 3.1.3 SAM
- 3.1.4 SEEM
- 3.2 SAM的改进与应用
- SAM for Medical Segmentation
- SAM for Tracking
- SAM for Remote Sensing
- SAM for Captioning
- SAM for Mobile Applications
- 3.3 通才模型
- Painter
- VisionLLM
- Prismer
- 4.综合性基础模型
- 4.1基于异构架构的基础视觉模型
- 4.1.1 CLIP 与异构模态的对齐
- 4.1.2 学习共享表示的多模态模型
- 4.1.3 视频和长篇幅文本的处理
- 4.2 基于代理的基础视觉模型
- 4.2.1 机器人操控
- 4.2.2 持续学习者
- 4.2.3 导航规划
- 5.总结
- 参考文献
0.导读
众所周知,视觉系统对于理解和推理视觉场景的组成特性至关重要。这个领域的挑战在于对象之间的复杂关系、位置、歧义、以及现实环境中的变化等。作为人类,我们可以很轻松地借助各种模态,包括但不仅限于视觉、语言、声音等来理解和感知这个世界。现如今,随着 Transformer 等关键技术的提出,以往看似独立的各个方向也逐渐紧密地联结到一起,组成了“多模态”的概念。
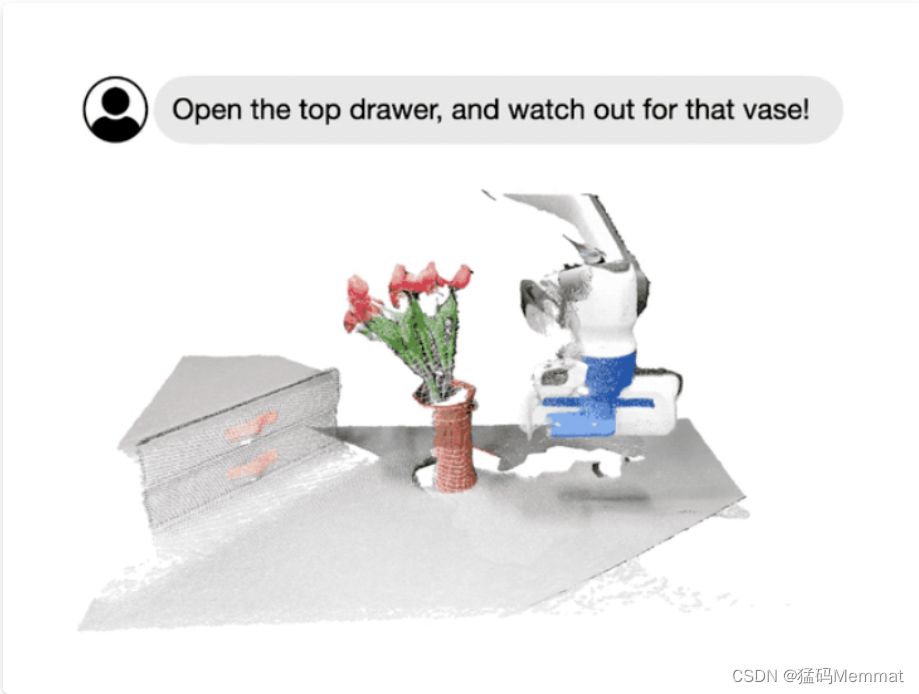
今天,我们主要围绕Foundational Models,即基础模型这个概念,向大家全面阐述一个崭新的视觉系统。例如,通过 SAM,我们可以轻松地通过点或框的提示来分割特定对象,而无需重新训练;通过指定图像或视频场景中感兴趣的区域,我们可以与模型进行多轮针对式的交互式对话;再如李飞飞团队最新展示的科研成果所示的那样,我们可以轻松地通过语言指令来操作机器人的行为。
该术语首次由Bommasani等人在《Stanford Institute for Human-Centered AI》中引入。基础模型定义为“通过自监督或半监督方式在大规模数据上训练的模型,可以适应其它多个下游任务”。
具体地,我们将一起讨论一些典型的架构设计,这些设计结合了不同的模态信息,包括视觉、文本、音频;此外,我们还将着重讨论不同的训练目标,如对比式学习和生成式学习。随后,关于一些主流的预训练数据集、微调机制以及常见的提示模式,我们也将逐一介绍。
最后,希望通过今天的学习让大家对基础模型在计算机视觉领域的发展情况,特别是在大规模训练和不同任务之间的适应性方面的最新进展有一个大致的认知。共勉。
1.背景介绍
近年来,基础模型取得了显著的成功,特别是通过大型语言模型(LLMs),主要归因于数据和模型规模的大幅扩展。例如,像GPT-3这样的十亿参数模型已成功用于零/少样本学习,而无需大量的任务特定数据或模型参数更新。与此同时,有5400亿参数的Pathways Language Model(PaLM)在许多领域展现了先进的能力,包括语言理解、生成、推理和与代码相关的任务。
反观视觉领域,诸如CLIP这样的预训练视觉语言模型在不同的下游视觉任务上展现了强大的零样本泛化性能。这些模型通常使用从网络收集的数百上千万图像-文本对进行训练,并提供具有泛化和迁移能力的表示。因此,只需通过简单的自然语言描述和提示,这些预训练的基础模型完全被应用到下游任务,例如使用精心设计的提示进行零样本分类。
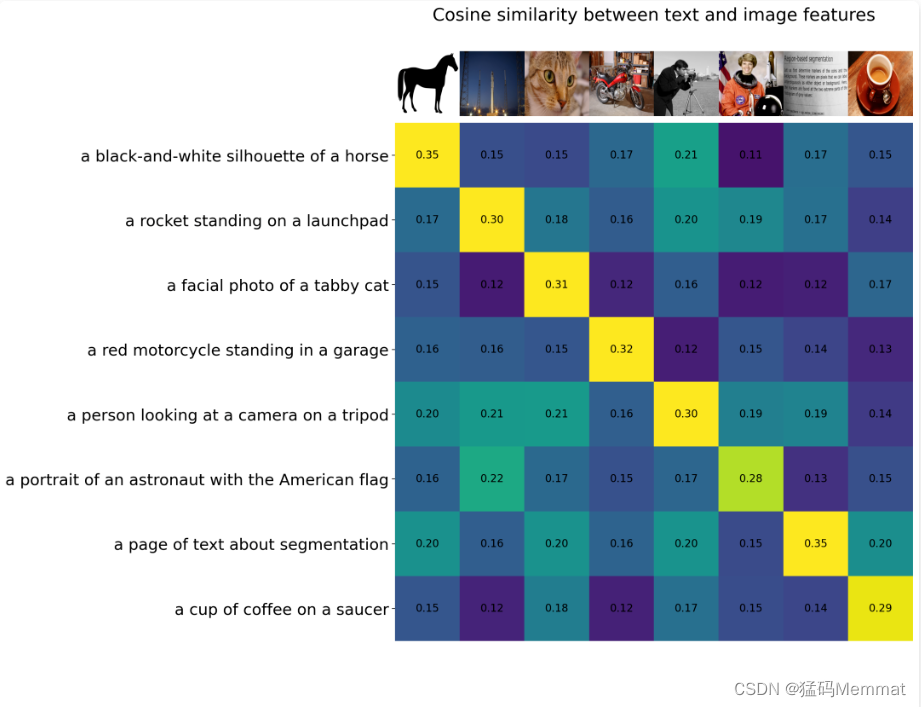
除了此类大型视觉语言基础模型外,一些研究工作也致力于开发可以通过视觉输入提示的大型基础模型。例如,最近 META 推出的 SAM 能够执行与类别无关的分割,给定图像和视觉提示(如框、点或蒙版),指定要在图像中分割的内容。这样的模型可以轻松适应特定的下游任务,如医学图像分割、视频对象分割、机器人技术和遥感等。
当然,我们同样可以将多种模态一起串起来,组成更有意思的管道,如RAM+Grounding-DINO+SAM:
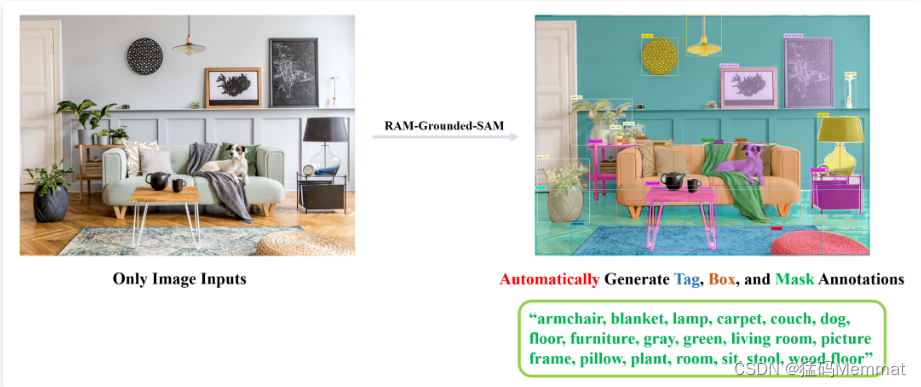
这里我们用 RAM 提取了图像的语义标签,再通过将标签输入到 Grounding-DINO 中进行开放世界检测