GBM是一种集成学习算法,它结合了多个弱学习器(通常是决策树)来构建一个强大的预测模型。GBM使用“Boosting”的技术来训练弱学习器,这种技术是一个迭代的过程,每一轮都会关注之前轮次中预测效果较差的样本,以便更专注地对它们进行建模。这有助于逐步减少整体预测误差。
#1 清空
rm(list = ls())
gc()
#2 导入包
library("survival")
library("gbm")
help(package="gbm")
#3 拆分训练集和测试集
data<-lung
set.seed(123)
train <- sample(1:nrow(data), round(nrow(data) * 0.70))
train <- data[train, ]
test <- data[-train, ]
#4 建立模型
set.seed(123)
gbm_model <- gbm(Surv(time, status) ~ .,#建模distribution = "coxph",#分布data = train,#数据n.trees = 5000,#树数量shrinkage = 0.1,#学习率或步长减少interaction.depth = 5,#每棵树的最大深度n.minobsinnode = 10,#最小观测次数在树的终末节点cv.folds = 10#交叉验证次数
)
plot(gbm_model)#通过“积分”其他变量,绘制所选变量的边际效应。
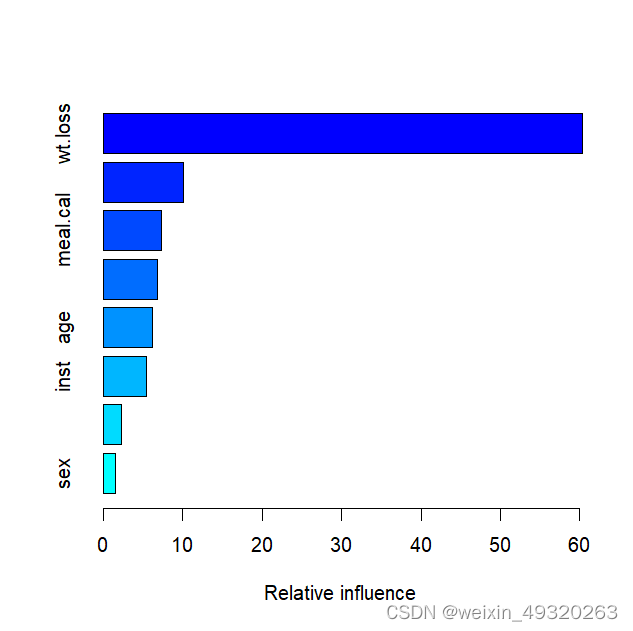
summary(gbm_model)#绘图,从高到低显示因素的相对重要性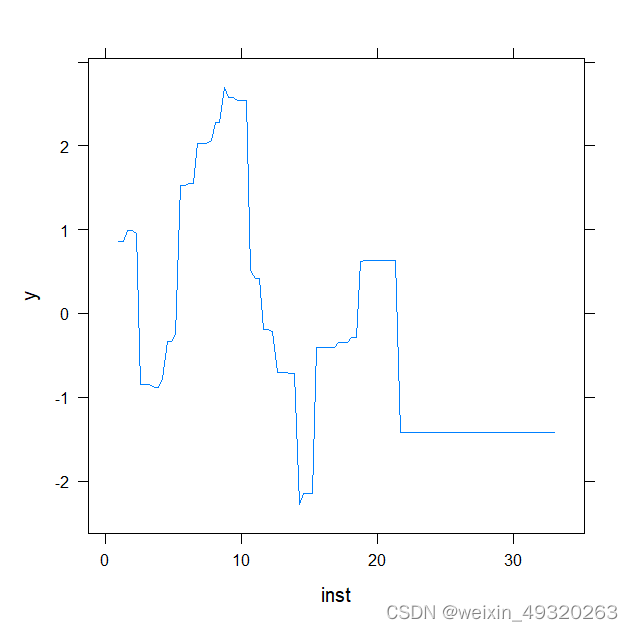
#5 预测
best.iter <- gbm.perf(gbm_model, plot.it = TRUE, method = "cv")
pred_train <- predict(gbm_model, train, n.trees = best.iter)
pred_test <- predict(gbm_model, test, n.trees = best.iter)
#6 模型评价
#计算ROC
library(survivalROC)
roc_area <- survivalROC(Stime=train$time,status=train$status,marker =pred_train,predict.time=100,method="KM")
# 计算C-index
Hmisc::rcorr.cens(-pred_train, Surv(train$time, train$status))
Hmisc::rcorr.cens(-pred_test, Surv(test$time, test$status))
#7 计算生存概率
# 计算累积
CH<- basehaz.gbm(train$time, train$status, pred_train, t.eval = 300, cumulative = TRUE)
exp(-exp(pred_test)*CH)