数据库操作:
在MongoDB中,文档集合存在数据库中。
要选择使用的数据库,请在mongo shell程序中发出 use <db> 语句
// 查看有哪些数据库
show dbs;// 如果数据库不存在,则创建并切换到该数据库,存在则直接切换到指定数据库。
use school;// 查看当前所在库
db;// 删除 先切换到要删的库下
use school;// 删除当前库
db.dropDatabase();集合操作:
MongoDB将文档存储在集合中。集合类似于关系数据库中的表。
如果不存在集合,则在您第一次为该集合存储数据时,MongoDB会创建该集合。
// 选择所在数据库
// 如果数据库不存在,则创建并切换到该数据库,存在则直接切换到指定数据库。
use dbdb;// 增加集合
// 方式一:当第一个文档插入时,集合就会被创建并包含该文档
db.student.insertOne({"name": "张三","age": 12});// 方式二:创建一个空集合
db.student1;// 查看数据库中有哪些集合
// 方式一:
show collections;// 方式二:
show tables;// 删除数据库中的集合
db.student.drop();文档操作:
MongoDB将数据记录存储为BSON文档。BSON是 {
{
field1: value1,
field2: value2,
field3: value3,
...
fieldN: valueN
}
字段的值可以是任何BSON 数据类型,包括其他文档,数组和文档数组。例如,以下文档包含各种类型的值:
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}
上面的字段具有以下数据类型:
-
_id拥有一个ObjectId。
-
name包含一个包含字段first和last的_嵌入式文档_。
-
birth和death保留_Date_类型的值。
-
contribs拥有_字符串数组_。
-
views拥有_NumberLong_类型的值
字段名称
段名称是字符串。
文档对字段名称有以下限制:
-
字段名称
_id保留用作主键;它的值在集合中必须是唯一的,不可变的,并且可以是数组以外的任何类型。
-
字段名称不能包含
null字符。
-
顶级字段名称不能以美元符号(
$)字符开头。否则,从MongoDB 3.6开始,服务器允许存储包含点(即
.)和美元符号(即$)的字段名称。
重要
MongoDB查询语言不能总是有效地表达对字段名称包含这些字符的文档的查询(请参阅SERVER-30575)
在查询语句中添加支持之前,不推荐在字段名称中使用$和 .,官方MongoDB的驱动程序不支持。
BSON文档可能有多个具有相同名称的字段。但是,大多数MongoDB接口都使用不支持重复字段名称的结构(例如,哈希表)来表示MongoDB。如果需要处理具有多个同名字段的文档,请参见驱动程序文档。
内部MongoDB流程创建的某些文档可能具有重复的字段,但是_任何_ MongoDB流程都_不会_向现有的用户文档添加重复的字段。
字段值限制
MongoDB 2.6至MongoDB版本,并将featureCompatibilityVersion(fCV)设置为"4.0"或更早版本
对于索引集合,索引字段的值有一个最大索引键长度限制。有关详细信息,请参见Maximum Index Key Length。
点符号
MongoDB使用_点符号_访问数组的元素并访问嵌入式文档的字段。
数组
要通过从零开始的索引位置指定或访问数组的元素,请将数组
名称与点(.)和从零开始的索引位置连接起来,并用引号引起来:
"<array>.<index>"
例如,给定文档中的以下字段:
{
...
contribs: [ "Turing machine", "Turing test", "Turingery" ],
...
}
要指定contribs数组中的第三个元素,请使用点符号"contribs.2"。
有关查询数组的示例,请参见:
-
查询数组
-
查询嵌入式文档数组
也可以看看
-
$[\]用于更新操作的所有位置运算符,
-
$[/<identifier/>]过滤后的位置运算符,用于更新操作,
-
$ 用于更新操作的位置运算符,
-
$ 数组索引位置未知时的投影运算符
-
在数组中查询带数组的点符号示例。
嵌入式文档
要使用点符号指定或访问嵌入式文档的字段,请将嵌入式文档名称与点(.)和字段名称连接在一起,并用引号引起来:
"<embedded document>.<field>"
例如,给定文档中的以下字段:
{
...
name: { first: "Alan", last: "Turing" },
contact: { phone: { type: "cell", number: "111-222-3333" } },
...
}
-
要指定在字段中命名
last的name字段,请使用点符号"name.last"。
-
要在字段
number中的phone文档中 指定contact,请使用点号"contact.phone.number"。
有关查询嵌入式文档的示例,请参见:
-
查询嵌入/嵌套文档
-
查询嵌入式文档数组
文件限制
文档具有以下属性:
文档大小限制
BSON文档的最大大小为16 MB。
最大文档大小有助于确保单个文档不会使用过多的RAM或在传输过程中占用过多的带宽。要存储大于最大大小的文档,MongoDB提供了GridFS API。有关GridFS的更多信息,请参见mongofiles和驱动程序的文档。
文档字段顺序
除_以下情况_外,MongoDB会在执行写操作后保留文档字段的顺序:
-
该
_id字段始终是文档中的第一个字段。
-
包含renaming字段名称的更新可能会导致文档中字段的重新排序。
_id字段
在MongoDB中,存储在集合中的每个文档都需要一个唯一的 _id字段作为主键。如果插入的文档省略了该_id字段,则MongoDB驱动程序会自动为该_id字段生成一个ObjectId。
这也适用于通过使用upsert:true更新操作插入的文档。
该_id字段具有以下行为和约束:
-
默认情况下,MongoDB 在创建集合期间会在
_id字段上创建唯一索引。
-
该
_id字段始终是文档中的第一个字段。如果服务器首先接收到没有该_id字段的文档,则服务器会将字段移到开头。
-
该
_id字段可以包含除数组之外的任何BSON数据类型的值。
警告
为确保复制正常进行,请勿在_id 字段中存储BSON正则表达式类型的值。
以下是用于存储值的常用选项_id:
-
使用一个ObjectId。
-
使用自然的唯一标识符(如果有)。这样可以节省空间并避免附加索引。
-
生成一个自动递增的数字。
-
在您的应用程序代码中生成一个UUID。为了在集合和
_id索引中更有效地存储UUID值,请将UUID存储为BSONBinData类型的值。在以下情况下,
BinData更有效地将类型为索引的键存储在索引中:-
二进制子类型的值在0-7或128-135的范围内,并且
-
字节数组的长度为:0、1、2、3、4、5、6、7、8、10、12、14、16、20、24或32。
-
-
使用驱动程序的BSON UUID工具生成UUID。请注意,驱动程序实现可能会以不同的方式实现UUID序列化和反序列化逻辑,这可能与其他驱动程序不完全兼容。有关UUID互操作性的信息,请参阅驱动程序文档。
注意
大多数MongoDB驱动程序客户端将包括该_id字段,并ObjectId在将插入操作发送到MongoDB之前生成一个;但是,如果客户发送的文档中没有_id 字段,则mongod会添加该_id字段并生成ObjectId。
文档结构的其他用途
除了定义数据记录外,MongoDB还在整个文档结构中使用,包括但不限于:查询过滤器,更新规范文档和索引规范文档。
查询过滤器文档
查询过滤器文档指定确定用于选择哪些记录以进行读取,更新和删除操作的条件。
您可以使用 <field>:<value> 表达式指定相等条件和查询运算符 表达式。
{
<field1>: <value1>,
<field2>: { <operator>: <value> },
...
}
有关示例,请参见:
-
查询文档
-
查询嵌入/嵌套文档
-
查询数组
-
查询嵌入式文档数组
更新规范文档
更新规范文档使用更新运算符来指定要在db.collection.update()操作期间在特定字段上执行的数据修改。
{
<operator1>: { <field1>: <value1>, ... },
<operator2>: { <field2>: <value2>, ... },
...
}
有关示例,请参阅更新规范。
索引规范文档
索引规范文档定义了要索引的字段和索引类型:
{ <field1>: <type1>, <field2>: <type2>, ... }
原文链接:
Documents — MongoDB Manual
MongoDB CRUD操作
创建操作
创建或插入操作会将新文档添加到集合中。 如果该集合当前不存在,则插入操作将创建该集合。
MongoDB提供以下将文档插入集合的方法:
-
db.collection.insertOne() 3.2版中的新功能
-
db.collection.insertMany() 3.2版中的新功能
在MongoDB中,插入操作针对单个集合。 MongoDB中的所有写操作都是单个文档级别的原子操作。
单条增加
db.test.insertOne({Key:Value,......,Key:Value})
user={"name":"egon","age":10,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'BJ'}
}db.test.insertOne(user)db.test.insertOne({"name":"egon","age":10,'hobbies':['music','read','dancing'],'adder':{'country':'China','city':'BJ'}
});多条批量增加:
db.user.insertMany([ , , , , ,])的形式
// 多条批量增加
// db.user.insertMany([ , , , , ,])的形式
user1={"_id":11,"name":"alex","age":8,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'weifang'}
}user2={"_id":12,"name":"wupeiqi","age":8,'hobbies':['music','read','run'],'addr':{'country':'China','city':'hebei'}
}user3={"_id":13,"name":"yuanhao","age":8,'hobbies':['music','drink'],'addr':{'country':'China','city':'heibei'}
}user4={"_id":14,"name":"jingliyang","age":8,'hobbies':['music','read','dancing','tea'],'addr':{'country':'China','city':'BJ'}
}user5={"_id":15,"name":"jinxin","age":8,'hobbies':['music','read',],'addr':{'country':'China','city':'henan'}
}
db.user.insertMany([user1,user2,user3,user4,user5]);db.user.insertMany([{"_id":6,"name":"alex","age":10,'hobbies':['music','read','dancing'],'addr':{'country':'China','city':'weifang'}
},{"_id":7,"name":"wupeiqi","age":20,'hobbies':['music','read','run'],'addr':{'country':'China','city':'hebei'}
},{"_id":8,"name":"yuanhao","age":30,'hobbies':['music','drink'],'addr':{'country':'China','city':'heibei'}
},{"_id":9,"name":"jingliyang","age":40,'hobbies':['music','read','dancing','tea'],'addr':{'country':'China','city':'BJ'}
},{"_id":10,"name":"jinxin","age":50,'hobbies':['music','read',],'addr':{'country':'China','city':'henan'}
}]);读取操作
读取操作从集合中检索文档; 即查询集合中的文档。 MongoDB提供了以下方法来从集合中读取文档:
-
db.collection.find()
您可以指定查询过滤器或条件以标识要返回的文档。
查的形式有很多,如比较运算、逻辑运算、成员运算、取指定字段、 对数组的查询、使用正则、获取数量,还有排序、分页等等
注:在MongoDB中,用到方法都得用 $ 符号开头
一、比较运算:
=,!= ('$ne') ,> ('$gt') ,< ('$lt') ,>= ('$gte') ,<= ('$lte')
等于:{ " _id " : 3 }
// select * from db1.user where id = 3
db.user.find({"_id":3
});不等于: { " _id " : { " $ne " : 3 }}
// select * from db1.user where id != 3
db.user.find({"_id":{"$ne":3}
});大于:{ " _id " : { " $gt " : 3 }}
// select * from db1.user where id > 3
db.user.find({"_id":{"$gt":3}
});大于等于:{" _id " : { " $gte " : 3 }}
// select * from db1.user where id >= 3
db.user.find({"_id":{"$gte":3}
});小于: {" age " : {" $lt " : 3 }}
// select * from db1.user where age < 3
db.user.find({"age":{"$lt":3}
});小于等于: {" _id " : {" $lte " : 9 }}
// select * from db1.user where id <= 9
db.user.find({"_id":{"$lte":9}
});二、逻辑运算:
MongoDB中字典内用逗号分隔多个条件是and关系,或者直接用$and,$or,$not(与或非)
$and 和:
MongoDB中字典内用逗号分隔多个条件是and关系,
// select * from db1.user where id >=3 and id <=6;
db.user.find({"_id":{"$gte":3,"$lte":6}
});
// select * from db1.user where id >=3 and id <=4 and age >=40;
db.user.find({"_id":{"$gte":3,"$lte":4},"age":{"$gte":40}});db.user.find({"$and":[{"_id":{"$gte":3,"$lte":4}},{"age":{"$gte":40}}]
});
$or 或:
// select * from db1.user where id >=0 and id <=1 or id >=4 or name = "yuanhao";
db.user.find({"$or":[{"_id":{"$lte":1,"$gte":0}},{"_id":{"$gte":4}},{"name":"yuanhao"}]
})$mod 取余:
// select * from db1.user where id % 2 = 1;
db.user.find({"_id":{"$mod":[2,1]}
});
$not 或:
// select * from db1.user where id % 2 != 1;
db.user.find({"_id":{"$not":{"$mod":[2,1]}}
});三、成员运算:
成员运算无非in和not in,MongoDB中形式为$in , $nin
$in[ ] 包含列表中的数据
// select * from db1.user where age in (20,30,31);
db.user.find({"age":{"$in":[20,30,31]}
});$nin[ ] 不包含列表中的数据
// select * from db1.user where name not in ('alex','yuanhao');
db.user.find({"name":{"$nin":['Stefan','Damon']}
});四、正则:正则定义在/ /内
// MongoDB: /正则表达/i
// select * from db1.user where name regexp '^j.*?(g|n)$';
// 匹配规则:j开头、g或n结尾,不区分大小写
db.user.find({'name':/^j.*?(g|n)$/i
});五、查看指定字段:0表示不显示1表示显示
// 查询_id 等于 7 数据,只展示 name、age 字段
// select name,age from db1.user where id=7;
db.user.find({'_id':7
},{'_id':0,'name':1,'age':1
});
六、对数组的查询:
查hobbies中有dancing的人
db.user.find({"hobbies":"dancing"
});查询子文档有"country" : "China"的人
addr 字段中 {key = country value = China}
db.user.find({"addr.country":"China"
});

查看既有dancing爱好又有tea爱好的人
$all : [ " dancing " , " tea " ] 包含集合中所有的数据
db.user.find({"hobbies":{"$all":["dancing","tea"]}
});查看第2个爱好为dancing的人
. 1 是数组中的下标
db.user.find({"hobbies.1":"dancing"
});查看所有人的第2个到第3个爱好
$slice : [ 1 , 2 ] 取下标为 1 , 2 的数据
db.user.find({},{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":[1,2]},
});查看所有人最后两个爱好,第一个{}表示查询条件为所有,第二个是显示条件
$slice : -2 取后俩位
db.user.find({},{"_id":0,"name":0,"age":0,"addr":0,"hobbies":{"$slice":-2},
});
七、对查询结果进行排序:
sort() 1代表升序、-1代表降序
// 按name字段升序
db.user.find().sort({"name":1,});// 按_id字段升序 age 降序
db.user.find().sort({"age":-1,'_id':1});八、分页:
limit表示取多少个document(文件),
skip代表跳过几个document(文件)
// 前两个
db.user.find().limit(2).skip(0); // 第三个和第四个
db.user.find().limit(2).skip(2); // 第五个和第六个
db.user.find().limit(2).skip(4);
九、获取数量:count()
// 查询年龄大于30的人数
// 方式一:
db.user.count({'age':{"$gt":30}
});// 方式二:
db.user.find({'age':{"$gt":30}
}).count();
十、查找所有
db.user.find(); db.user.find({})十一、去重 distinct()
db.user.distinct("age");十二、查找key为null的项
db.t2.find({"b":null
});十三、MongoDB聚合
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}] |
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
管道操作符实例
1、$project实例
db.article.aggregate({ $project : {title : 1 ,author : 1 ,}});这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.article.aggregate({ $project : {_id : 0 ,title : 1 ,author : 1}});2、$match实例
db.articles.aggregate( [{ $match : { score : { $gt : 70, $lte : 90 } } },{ $group: { _id: null, count: { $sum: 1 } } }] );$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
3、$skip实例
db.article.aggregate({ $skip : 5 });经过$skip管道操作符处理后,前五个文档被"过滤"掉。
更新操作
更新操作会修改集合中的现有文档。 MongoDB提供了以下更新集合文档的方法:
-
db.collection.updateOne() 3.2版中的新功能
-
db.collection.updateMany() 3.2版中的新功能
-
db.collection.replaceOne() 3.2版中的新功能
列子1:
$$NOW 当前时间
创建一个示例students学生集合(如果该集合当前不存在,则插入操作将创建该集合):
db.students.insertMany([{ _id: 1, test1: 95, test2: 92, test3: 90, modified: new Date("01/05/2020") },{ _id: 2, test1: 98, test2: 100, test3: 102, modified: new Date("01/05/2020") },{ _id: 3, test1: 95, test2: 110, modified: new Date("01/04/2020") }
])查询集合:
db.students.find()以下db.collection.updateOne()操作使用聚合管道使用**_id**更新文档:3
db.students.updateOne( { _id: 3
}, [ { $set: {"test3": 98, modified: "$$NOW"}
} ]
);具体地说,管道包括$set阶段,该阶段将test3字段(并将其值设置为98)添加到文档中,并将修改后的字段设置为当前日期时间。 对于当前日期时间,该操作将聚合变量NOW 用于(以访问变量,以**$$**为前缀并用引号引起来)。
列子2:
$replaceRoot
$mergeObjects
$$ROOT
创建一个示例students2集合(如果该集合当前不存在,则插入操作将创建该集合):
db.students2.insertMany([{"_id": 1,quiz1: 8,test2: 100,quiz2: 9,modified: new Date("01/05/2020")},{"_id": 2,quiz2: 5,test1: 80,test2: 89,modified: new Date("01/05/2020")},])db.students2.updateMany({}, [{$replaceRoot: {newRoot:{$mergeObjects: [{quiz1: 0,quiz2: 0,test1: 0,test2: 0}, "$$ROOT"]}}},{$set: {modified: "$$NOW"}}
])具体来说,管道包括:
-
$replaceRoot 阶段,带有 $mergeObjects表达式,可为quiz1,quiz2,test1和test2字段设置默认值。 聚集变量ROOT 指的是正在修改的当前文档(以访问变量,以**$$**为前缀并用引号引起来)。 当前文档字段将覆盖默认值。
-
$set 阶段用于将修改的字段更新到当前日期时间。 对于当前日期时间,该操作将聚合变量NOW用于(以访问变量,以**$$**为前缀并用引号引起来)。
列子3:
$switch
$switch :{
元素:[
{case: { $get:[ 元素,数值 ] },then:" 数值 "},
{case: { $get:[ 元素,数值 ] },then:" 数值 "},
{case: { $get:[ 元素,数值 ] },then:" 数值 "},
],
default: "F"
}
创建一个示例students3集合(如果该集合当前不存在,则插入操作将创建该集合):
db.students3.insert([{ "_id" : 1, "tests" : [ 95, 92, 90 ], "modified" : ISODate("2019-01-01T00:00:00Z") },{ "_id" : 2, "tests" : [ 94, 88, 90 ], "modified" : ISODate("2019-01-01T00:00:00Z") },{ "_id" : 3, "tests" : [ 70, 75, 82 ], "modified" : ISODate("2019-01-01T00:00:00Z") }
]);以下 db.collection.updateMany()操作使用聚合管道以计算的平均成绩和字母成绩更新文档。
db.students3.updateMany({ }, [{ $set: { average : { $trunc: [ { $avg: "$tests" }, 0 ] }, modified: "$$NOW" } }, { $set: { grade: { $switch: { branches: [ { case: { $gte: [ "$average", 90 ] }, then: "A" }, { case: { $gte: [ "$average", 80 ] }, then: "B" }, { case: { $gte: [ "$average", 70 ] }, then: "C" }, { case: { $gte: [ "$average", 60 ] }, then: "D" } ],default: "F" } } } }])-
$set阶段来计算测试数组元素的截断平均值,并将修改后的字段更新为当前日期时间。 要计算截断的平均值,此阶段使用**$avg和$trunc 表达式。 对于当前日期时间,该操作将聚合变量NOW 用于(以访问变量,以$$**为前缀并用引号引起来).
-
一个$set 阶段,用于使用$switch 表达式根据平均值添加年级字段。
例子4:
$concatArrays
创建一个示例students4集合(如果该集合当前不存在,则插入操作将创建该集合):
db.students4.insertMany([{ "_id" : 1, "quizzes" : [ 4, 6, 7 ] },{ "_id" : 2, "quizzes" : [ 5 ] },{ "_id" : 3, "quizzes" : [ 10, 10, 10 ] }
])以下db.collection.updateOne()操作使用聚合管道将测验分数添加到具有**_id**的文档中:2
db.students4.updateOne( { _id: 2 },[ { $set: { quizzes: { $concatArrays: [ "$quizzes", [ 8, 6 ] ] } } } ]
)例子5:
$addFields
$map
$add
$multiply
$$celsius
创建一个示例temperatures集合,其中包含摄氏温度(如果该集合当前不存在,则插入操作将创建该集合):
db.temperatures.insertMany([{ "_id" : 1, "date" : ISODate("2019-06-23"), "tempsC" : [ 4, 12, 17 ] },{ "_id" : 2, "date" : ISODate("2019-07-07"), "tempsC" : [ 14, 24, 11 ] },{ "_id" : 3, "date" : ISODate("2019-10-30"), "tempsC" : [ 18, 6, 8 ] }
])以下db.collection.updateMany()操作使用聚合管道以华氏度中的相应温度更新文档:
db.temperatures.updateMany( { },[{ $addFields: { "tempsF": {$map: {input: "$tempsC",as: "celsius",in: { $add: [ { $multiply: ["$$celsius", 9/5 ] }, 32 ] }}} } }]
)具体来说,管道由$addFields阶段组成,以添加一个新的数组字段tempsF,其中包含华氏温度。 要将tempsC数组中的每个摄氏温度转换为华氏温度,该阶段将$map表达式与$add和 $multiply表达式一起使用。
// 常规修改操作:
// 设数据为{'name':'武松','age':18,'hobbies':['做煎饼','吃煎饼','卖煎饼'],'addr':{'country':'song','province':'shandong'}}
// update db1.user set age=23,name="武大郎" where name="武松";
// 覆盖式
db.user.updateOne({"name":"潘金莲"},{$set:{"age":23,"name":"武大郎"}});
// 得到的结果为{"age":23,"name":"武大郎"}// 局部修改:$set
db.user.updateOne({"name":"武松"},{"$set":{"age":15,"name":"潘金莲"}});
// 得到的结果为{"name":"潘金莲","age":15,'hobbies':['做煎饼','吃煎饼','卖煎饼']}// 改多条:将multi参数设为true
db.user.updateMany({"_id":{"$gte":5,"$lte":7}},{$set:{"age":53}},{multi: true,upsert: false, writeConcern: true });
db.getCollection("user").find({}).sort({_id: 1}).limit(21)
// 有则修改,无则添加:upsert参数设为true
db.user.updateOne({"name":"EGON"},{"$set":{"name":"EGON","age":28,}},{"upsert":true});// 修改嵌套文档:将国家改为日本
db.user.updateOne({"name":"潘金莲"},{"$set":{"addr.country":"Japan"}});// 修改数组:将第一个爱好改为洗澡
db.user.updateOne({"name":"潘金莲"},{"$set":{"hobbies.1":"洗澡"}});// 删除字段:不要爱好了
db.user.updateOne({"name":"潘金莲"},{"$unset":{"hobbies":""}});加减操作:$inc
// 年龄都+1
db.user.updateMany({},{"$inc":{"age":1}});// 年龄都-10
db.user.updateMany({},{"$inc":{"age":-10}},);添加删除数组内元祖$push $pop $pull
// $push的功能是往现有数组内添加元素
// 为名字为武大郎的人添加一个爱好read
db.user.updateOne({"name":"武大郎"},{"$push":{"hobbies":"read"}});// 为名字为武大郎的人一次添加多个爱好tea,dancing
db.user.updateOne({"name":"武大郎"},{"$push":{"hobbies":{"$each":["tea","dancing"]}}});// $pop的功能是按照位置只能从头或从尾即两端删元素,
// 类似于队列。1代表尾,-1代表头
// {"$pop":{"key":1}} 从数组末尾删除一个元素db.user.updateOne({"name":"武大郎"},{"$pop":{"hobbies":1}
});// {"$pop":{"key":-1}} 从头部删除
db.user.updateOne({"name":"武大郎"},{"$pop":{ "hobbies":-1}
});// $pull可以自定义条件删除
db.user.updateMany({'addr.country':"China"},{"$pull":{"hobbies":"read"}});避免重复添加 $addToSet 即多个相同元素要求插入时只插入一条
db.urls.insertOne({"_id":1,"urls":[]});db.urls.updateOne({"_id":1},{"$addToSet":{"urls":{"$each":['http://www.baidu.com','http://www.baidu.com','http://www.xxxx.com']}}});
限制大小"$slice",只留最后n个
db.user.updateOne({"_id":6},{"$push":{"hobbies":{"$each":["read",'music','dancing'],"$slice":-2 // 保留后两位}}
});排序The $sort element value must be either 1 or -1"
注意:不能只将"$slice"或者"$sort"与"$push"配合使用,且必须使用"$each"
db.user.updateOne({"_id":7},{"$push":{"hobbies":{"$each":["read",'music','dancing'],// 保留后一位"$slice":-1, // 倒序"$sort":-1}}
});附加方法
以下方法还可以更新集合中的文档:
-
db.collection.findOneAndReplace().
-
db.collection.findOneAndUpdate().
-
db.collection.findAndModify().
-
db.collection.save().
-
db.collection.bulkWrite().
聚合管道更新
从MongoDB 4.2开始,您可以将聚合管道用于更新操作。 通过更新操作,聚合管道可以包括以下阶段:
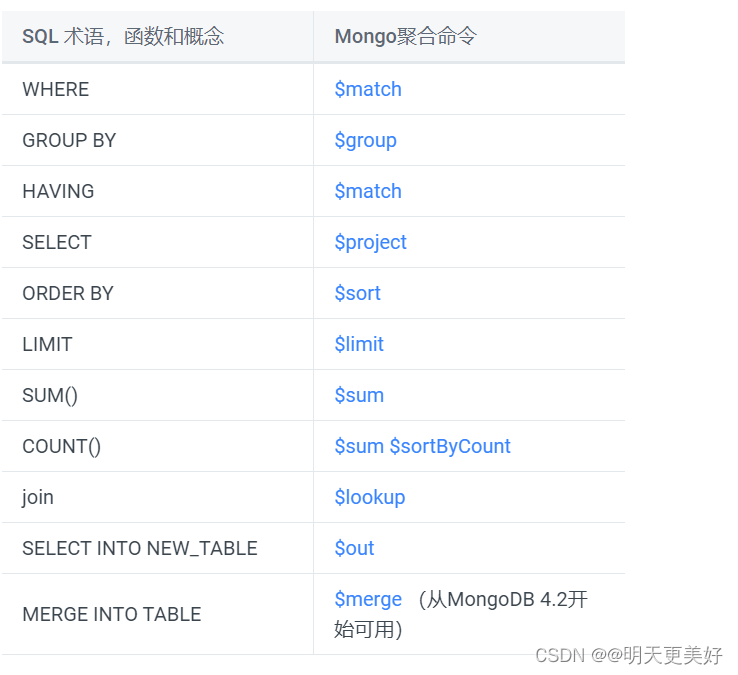
| $addFields | $set |
| $project | $unset |
| $replaceRoot | $replaceWith |
使用聚合管道允许使用表达性更强的update语句,比如根据当前字段值表示条件更新,或者使用另一个字段的值更新一个字段。
在MongoDB中,更新操作针对单个集合。 MongoDB中的所有写操作都是单个文档级别的原子操作。
您可以指定标准或过滤器,以标识要更新的文档。 这些过滤器使用与读取操作相同的语法。
聚合操作:
我们在查询时肯定会用到聚合,在MongoDB中聚合为aggregate,聚合函数主要用到
$match $group $avg $project $concat
$match和 $group:相当于sql语句中的where和group by{"$match":{"字段":"条件"}},可以使用任何常用查询操作符$gt,$lt,$in等
// select * from db1.emp where post='公务员';
db.emp.aggregate({"$match":{"post":"公务员"}});// select * from db1.emp where id > 3 group by post;
db.emp.aggregate({"$match":{"_id":{"$gt":3}}},{$group:{"_id":"$post",'avg_salary':{$avg:"$salary"}}});
db.emp.aggregate({"$match":{"_id":{"$gt":5}}},{"$group":{"_id":"$post"}})
// select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate({"$match":{"_id":{"$gt":3}}},{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},{"$match":{"avg_salary":{"$gt":10000}}});
//可将分组字段传给$group函数的_id字段即
{"$group":{"_id":分组字段,"新的字段名":聚合操作符}}// 按照性别分组
{"$group":{"_id":"$sex"}}; // 按照职位分组
{"$group":{"_id":"$post"}}; 按照多个字段分组,比如按照州市分组
{"$group":{"_id":{"state":"$state","city":"$city"}}}; 分组后聚合得结果,类似于sql中聚合函数的聚合操作符:$sum、$avg、$max、$min、$first、$last
// select post,max(salary) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}
});// 取每个部门最大薪资与最低薪资
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}
});// 如果字段是排序后的,那么$first,$last会很有用,比用$max和$min效率高
db.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}
});// 求每个部门的总工资
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}
});// 求每个部门的人数
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}
});// 数组操作符
// {"$addToSet":expr};// 不重复
// {"$push":expr};// 重复// 查询岗位名以及各岗位内的员工姓名:select post,group_concat(name) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}
});
db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}
});// $project:用于投射,即设定该键值对是否保留。1为保留,0为不保留,可对原有键值对做操作后增加自定义表达式
// {"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}// #select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate({$project:{"name":1,"post":1,"new_age":{$add:["$age",1]}}
});
排序:$sort、限制:$limit、跳过:$skip
// {"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序
// {"$limit":n}
// {"$skip":n} #跳过多少个文档//例1、取平均工资最高的前两个部门
db.emp.aggregate({"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}},{"$sort":{"平均工资":-1}},{"$limit":2})
//例2、
db.emp.aggregate({"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}},{"$sort":{"平均工资":-1}},{"$limit":2},{"$skip":1})// 随机选取n个:$sample
// 集合users包含的文档如下
db.users.insertMany(
[{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true },
{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false },
{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true },
{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false },
{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true },
{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true },
{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }]);// 下述操作时从users集合中随机选取3个文档
db.users.aggregate([ { $sample: { size: 3 } } ]);// CREATE TABLE USERS(a Number, b Number)
db.users// INSERT INTO USERS VALUES(1, 1)
db.users.insertOne({'a':1, 'b':1});//SELECT a, b FROM USERS
db.users.find({}, {'a':1, 'b':1});//SELECT * FROM USERS
db.users.find();//SELECT a, b FROM USERS WHERE age=33 and name='Jack'
db.users.find({'age':33, 'name':'Jack'}, {'a':1, 'b':1});//SELECT * FROM USERS WHERE age=33 ORDER BY name
db.users.find({'age':33}).sort({'name': 1});//SELECT * FROM USERS WHERE age>33
db.users.find({'age':{'$gt':33}});//SELECT * FROM USERS WHERE age<33
db.users.find({'age':{'$lt':33}});//SELECT * FROM USERS WHERE name LIKE '%Jack%'
db.users.find({'name': '/Jack/'});//SELECT * FROM USERS WHERE name LIKE 'Jack%'
db.users.find({'name': '/^Jack/'});//SELECT * FROM USERS WHERE age>33 AND age < 40
db.users.find({'age':{'$gt':33, '$lt':40}});//SELECT * FROM USERS ORDER BY name DESC
db.users.find().sort({'name': -1});//SELECT * FROM USERS LIMIT 1
db.users.findOne();//SELECT * FROM USERS LIMIT 10 SKIP 20
db.users.find().limit(1).skip(1);//SELECT * FROM USERS WHERE age=33 or name='Jack'
db.users.find({
$or:[{"q1":true},{"name":"Jack"}
]});//SELECT DISTINCT last_name FROM USERS
db.users.distinct('name');//SELECT COUNT(*) FROM USERS
db.users.count();//SELECT COUNT(*) FROM USERS WHERE age=33
db.user.find({'age':21}).count();// UPDATE USERS SET name='LEE' WHERE age=33
db.user.updateOne({'age':33}, {'$set':{'name':'LEE'}}, false, true);// UPDATE USERS SET age=age+10 WHERE name='LEE'
db.user.updateOne({'name':'LEE'}, {'$inc':{'age':10}}, false, true);// CREATE INDEX myindex ON users(name)
// 如果索引尚不存在,则在指定字段上创建索引。
db.user.ensureIndex({'name':1});// CREATE INDEX myindex ON users(name, ts DESC)
db.user.ensureIndex({'name':1, 'ts':-1});// DELETE FROM USERS WHERE name='Alex'
db.users.deleteMany({'name':'Alex'});删除操作
删除操作从集合中删除文档。 MongoDB提供以下删除集合文档的方法:
-
db.collection.deleteOne() 3.2版中的新功能
-
db.collection.deleteMany() 3.2版中的新功能
在MongoDB中,删除操作只针对单个集合。MongoDB中的所有写操作都是单个文档级别的原子 操作。
你可以指定查询过滤器或条件来标识要更新的文档,这里的过滤器和读操作的语法是一致的。
// 删
// 删除某个字段为空的, 会删除整条数据
db.getCollection("test").deleteOne({"adder": null});db.test.deleteOne({"adder": null});// 删除符合条件的第一个文档
// 第一个包含有 'age': 8的文档
db.user.deleteOne({ 'age': 8 });// 删除符合条件的全部
// 只要有内嵌文档,且内容含有country': 'China'的全都删除
db.user.deleteMany( {'addr.city': 'henan'} );// 删除id大于等于9的所有
db.user.deleteMany({"_id":{"$gte":9}});// 删除id大于7的所有
db.user.deleteMany({"_id":{"$gt":7}});// 删除id小于等于3的所有
db.user.deleteMany({"_id":{"$lte":3}});// 删除id小于5的所有
db.user.deleteMany({"_id":{"$lt":5}});// 删除全部 等于是清空该集合(表)
db.user.deleteMany({});增删改查练习
// 查询岗位名以及各岗位内的员工姓名
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})
// 查询岗位名以及各岗位内包含的员工个数
db.emp.aggregate({$group:{"_id":"$post","count":{"$sum":1}}})
// 查询公司内男员工和女员工的个数
db.emp.aggregate({$group:{"_id":"$sex","count":{"$sum":1}}})
// 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资
db.emp.aggregate({$group:{"_id":"$post","avg":{"$avg":"$salary"},"max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}});
// 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
db.emp.aggregate({$group:{"_id":"$sex","avg":{$avg:"$salary"}}})
db.emp.aggregate({"$group":{"_id":"$sex","avg_salary":{"$avg":"$salary"}}})
// 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
db.emp.aggregate({$group:{"_id":"$post","count":{$sum:1},"names":{"$push":"$name"}}},{$match:{count:{$lt:2}}},{$project:{"_id":0,"names":1,"count":1}});// 查询各岗位平均薪资大于10000的岗位名、平均工资
db.emp.aggregate({$group:{"_id":"$post","avg":{$avg:"$salary"}}
},{$match:{"avg":{$gt:10000}}},{$project:{"_id":1,"avg":1}});
// 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
db.emp.aggregate({"$group":{"_id":"$post","avg":{"$avg":"$salary"}}
},);db.emp.aggregate({"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}},{"$match":{"avg_salary":{"$gt":10000,"$lt":20000}}},{"$project":{"_id":1,"avg_salary":1}});// 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
db.emp.aggregate({"$sort":{"age":1,"hire_date":-1}
});
// 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
db.emp.aggregate({"$group":{"_id":"$post","avg":{$avg:"$salary"}}
},{"$match":{"avg":{"$gt":10000}}},{"$sort":{"avg":1}})
// 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个
db.emp.aggregate({$group:{"_id":"$post","avg":{$avg:"$salary"}}
},{$match:{"avg":{$gt:10000}}},{$sort:{"avg":-1}},{$limit:1},{$project:{"date":new Date,"平均工资":"$avg","_id":0}})