列表的介绍
定义100个变量,每个变量存放一个学生的姓名可行吗?有更好的办法吗?
答:
列表
一、列表的格式
定义列的格式:[元素1, 元素2, 元素3, ..., 元素n]
变量tmp的类型为列表
tmp = ['xiaoWang',180, 65.0]列表中的元素可以是不同类型的
二、使用下标获取列表元素
namesList = ['xiaoWang','xiaoZhang','xiaoHua']print(namesList[0])print(namesList[1])print(namesList[2])结果:
xiaoWangxiaoZhangxiaoHua列表的数据操作
我们对于可变数据(例如,列表,数据库等)的操作,一般包含增、删、改、查四个方面。
一、添加元素
添加元素有一下几个方法:
- append 在末尾添加元素
- insert 在指定位置插入元素
- extend 合并两个列表
append
append会把新元素添加到列表末尾
#定义变量A,默认有3个元素 A = ['xiaoWang','xiaoZhang','xiaoHua'] print("-----添加之前,列表A的数据-----A=%s" % A) #提示、并添加元素 temp = input('请输入要添加的学生姓名:') A.append(temp) print("-----添加之后,列表A的数据-----A=%s" % A)insert
insert(index, object) 在指定位置index前插入元素object
strs = ['a','b','m','s']strs.insert(3,'h')print(strs) # ['a', 'b', 'm', 'h', 's']extend
通过extend可以将另一个集合中的元素逐一添加到列表中
a = ['a','b','c']b = ['d','e','f']a.extend(b)print(a) # ['a', 'b', 'c', 'd', 'e', 'f'] 将 b 添加到 a 里print(b) # ['d','e','f'] b的内容不变二、修改元素
我们是通过指定下标来访问列表元素,因此修改元素的时候,为指定的列表下标赋值即可。
#定义变量A,默认有3个元素 A = ['xiaoWang','xiaoZhang','xiaoHua'] print("-----修改之前,列表A的数据-----A=%s" % A) #修改元素 A[1] = 'xiaoLu' print("-----修改之后,列表A的数据-----A=%s" % A)三、查找元素
所谓的查找,就是看看指定的元素是否存在,以及查看元素所在的位置,主要包含一下几个方法:
- in 和 not in
- index 和 count
in, not in
python中查找的常用方法为:
- in(存在),如果存在那么结果为true,否则为false
- not in(不存在),如果不存在那么结果为true,否则false
#待查找的列表 nameList = ['xiaoWang','xiaoZhang','xiaoHua'] #获取用户要查找的名字 findName = input('请输入要查找的姓名:') #查找是否存在 if findName in nameList: print('在列表中找到了相同的名字') else: print('没有找到')结果1:(找到)
结果2:(没有找到)
说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index用来查找元素所在的位置,如果未找到则会报错;count用来计算某个元素出现的次数。它们的使用和字符串里的使用效果一致。
>>> a = ['a', 'b', 'c', 'a', 'b']>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last): File "<stdin>", line 1, in <module>ValueError: 'a' is not in list>>> a.index('a', 1, 4)3>>> a.count('b')2>>> a.count('d')0四、删除元素
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
列表元素的常用删除方法有:
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除
del
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']print('------删除之前------movieName=%s' % movieName)del movieName[2]print('------删除之后------movieName=%s' % movieName)pop
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']print('------删除之前------movieName=%s' % movieName)movieName.pop()print('------删除之后------movieName=%s' % movieName)remove
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']print('------删除之前------movieName=%s' % movieName)movieName.remove('指环王')print('------删除之后------movieName=%s' % movieName)五、排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。
>>> a = [1, 4, 2, 3]>>> a
[1, 4, 2, 3]>>> a.reverse() # 逆置,不排序>>> a[3, 2, 4, 1]>>> a.sort() # 默认从小到大排序>>> a[1, 2, 3, 4]>>> a.sort(reverse=True) # 从大到小排序>>> a[4, 3, 2, 1]列表的循环遍历
1. 使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
namesList = ['xiaoWang','xiaoZhang','xiaoHua']length = len(namesList) # 获取列表长度i = 0while i<length: print(namesList[i]) i+=1结果:
xiaoWangxiaoZhangxiaoHua2. 使用for循环
while 循环是一种基本的遍历列表数据的方式,但是最常用也是最简单的方式是使用 for 循环
namesList = ['xiaoWang','xiaoZhang','xiaoHua']for name in namesList: print(name)结果:
xiaoWangxiaoZhangxiaoHua3. 交换2个变量的值
# 使用中间变量
a = 4b = 5c = 0c = aa = bb = cprint(a)print(b)练习
手动实现冒泡排序(难)
nums = [5, 1, 7, 6, 8, 2, 4, 3]for j in range(0, len(nums) - 1):
for i in range(0, len(nums) - 1 - j): if nums[i] > nums[i + 1]: a = nums[i] nums[i] = nums[i+1] nums[i+1] = aprint(nums)有一个列表names,保存了一组姓名names=['zhangsan','lisi','chris','jerry','henry'],再让用户输入一个姓名,如果这个姓名在列表里存在,提示用户姓名已存在;如果这个姓名在列表里不存在,就将这个姓名添加到列表里。
1. 列表嵌套
类似while循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
此处重点掌握怎么操作被嵌套的列表
>>> schoolNames = [... [1, 2, 3],... [11, 22, 33],... [111, 222, 333]... ]>>> schoolNames[1][2] # 获取数字 3333>>> schoolNames[1][2] = 'abc' # 把 33 修改为 'abc'>>> schoolNames
[[1, 2, 3], [11, 22, 'abc'], [111, 222, 333]]>>> schoolNames[1][2][2] # 获取 'abc' 里的字符c'c'也就是说,操作嵌套列表,只要把要操作元素的下标当作变量名来使用即可。
2. 应用
一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配
import random
# 定义一个列表用来保存3个办公室
offices = [[],[],[]]# 定义一个列表用来存储8位老师的名字
names = ['A','B','C','D','E','F','G','H']i = 0for name in names: index = random.randint(0,2) offices[index].append(name)i = 1for tempNames in offices: print('办公室%d的人数为:%d'%(i,len(tempNames))) i+=1 for name in tempNames: print("%s"%name,end='') print("\n") print("-"*20)列表推导式
所谓的列表推导式,就是指的轻量级循环创建列表
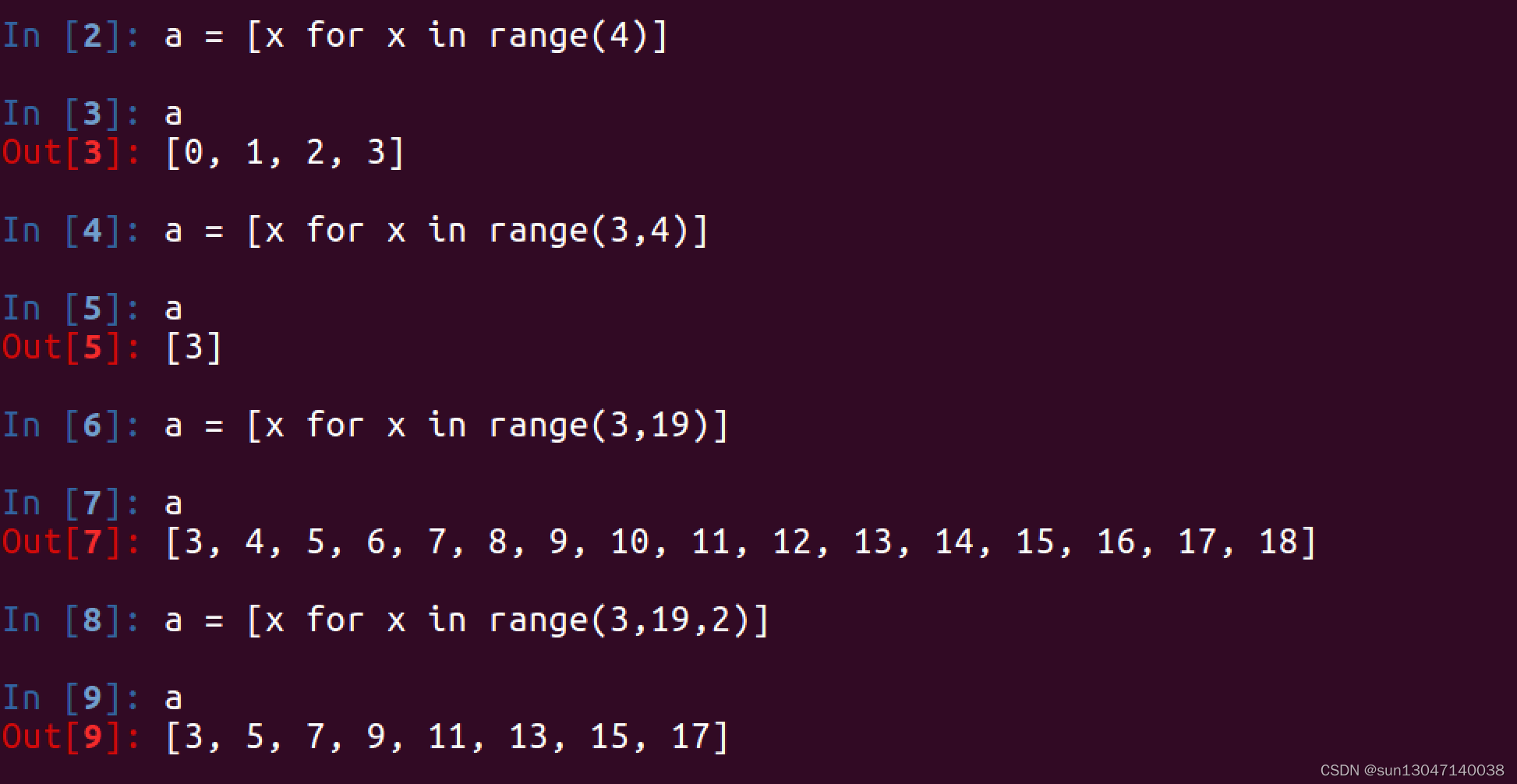
2. 在循环的过程中使用if
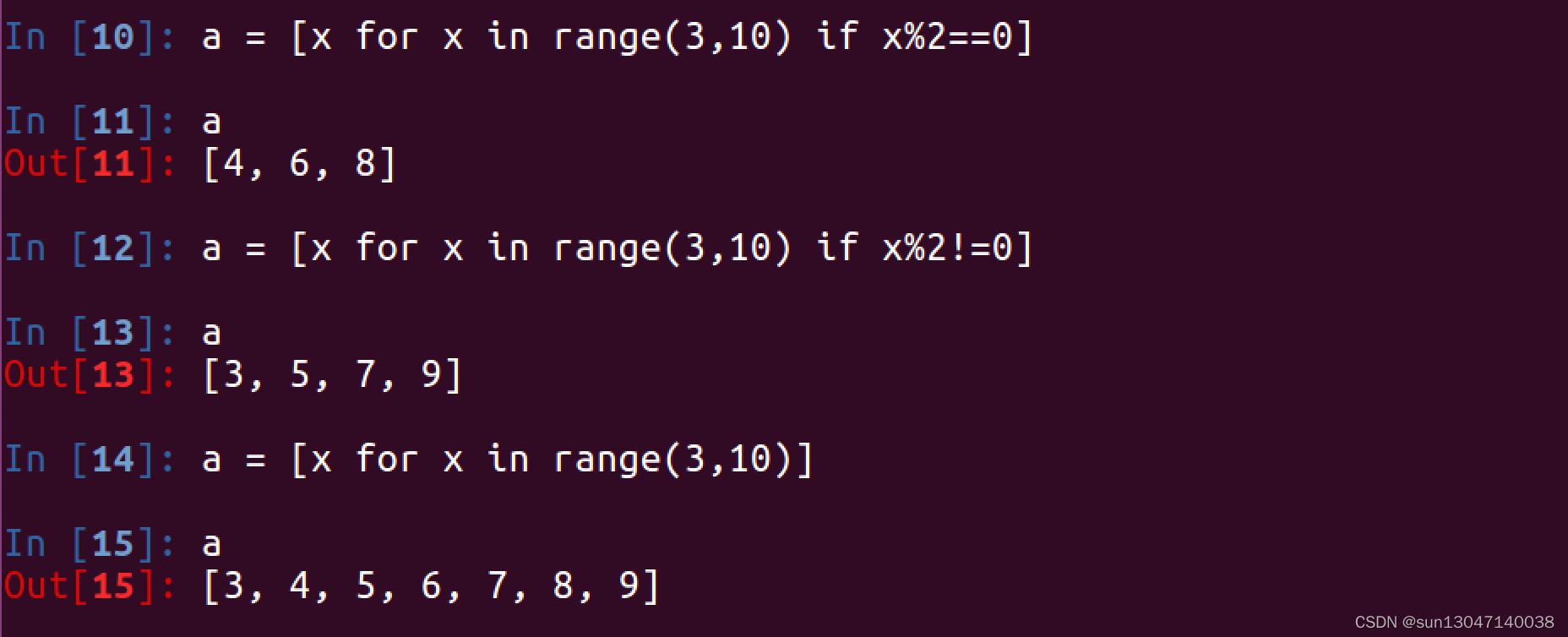
3. 2个for循环

4. 3个for循环
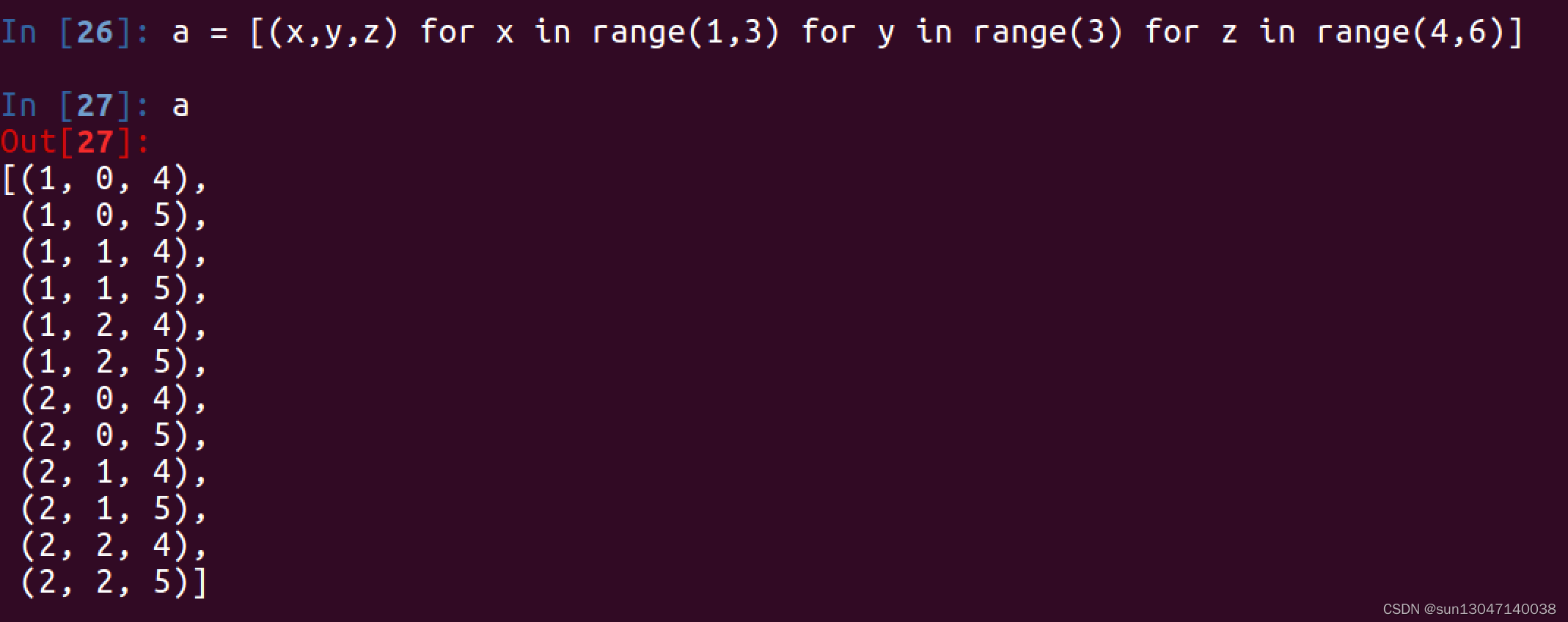
列表的复制
查看以下代码,说出打印的结果。
a = 12b = ab = 13print(b)print(a)nums1 = [1, 5, 8, 9, 10, 12]nums2 = nums1nums2[0] = 100print(nums2)print(nums1)思考:
- 为什么修改了 nums2里的数据,nums1的数据也会改变?
Python中的赋值运算都是引用(即内存地址)的传递。对于可变类型来说,修改原数据的值,会改变赋值对象的值。
- 怎样nums1和nums2变成两个相互独立不受影响的列表?
使用列表的 方法,或者 模块就可以赋值一个列表。
列表的方法
使用列表的方法,可以直接将原来的列表进行复制,变成一个新的列表,这种复制方式是浅复制。
nums1 = [1, 5, 8, 9, 10, 12]nums2 = nums1.() # 调用列表的方法,可以复制出一个新的列表nums2[0] = 100# 修改新列表里的数据,不会影响到原有列表里的数据
print(nums2)print(nums1)模块的使用
除了使用列表的方法以外,Python还提供了模块来复制一个对象。模块提供了浅复制和深复制两种方式,它们的使用方式相同,但是执行的效果有一定的差异。
浅拷贝
浅拷贝是对于一个对象的顶层拷贝,通俗的理解是:拷贝了引用,并没有拷贝内容。
import
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']# 浅拷贝只会拷贝最外层的对象,里面的数据不会拷贝,而是直接指向
words2 = .(words1)words2[0] = '你好'words2[2][0] = 'no'print(words1) # ['hello', 'good', ['no', 'ok'], 'bad']# wrods2 里的 yes 被修改成了 noprint(words2) # ['你好', 'good', ['no', 'ok'], 'bad']深拷贝
深拷贝是对于一个对象所有层次的递归拷贝。
import
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']# 深拷贝会将对象里的所有数据都进行拷贝
words2 = .deep(words1)words2[0] = '你好'words2[2][0] = 'no'print(words1) # ['hello', 'good', ['yes', 'ok'], 'bad']print(words2) # ['你好', 'good', ['no', 'ok'], 'bad']切片
列表和字符串一样,也支持切片,切片其实就是一种浅拷贝。
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']words2 = words1[:]words2[0] = '你好'words2[2][0] = 'no'print(words1) # ['hello', 'good', ['no', 'ok'], 'bad']print(words2) # ['你好', 'good', ['no', 'ok'], 'bad']