文章目录
- 一、什么是LLM
- 二、LLM从海量文本中学习到了什么?
- 三、LLM的知识到底存储到了网络中的什么地方
- 四、如何修改LLM中的某些知识?
- 五、如何平衡训练数据量、模型参数、增加epoch的关系
- 六、思维链promting是啥
- 七、代码预训练增强LLM推理能力
- 八、近年来的大模型
- 九、预训练数据集概览
- 十、InstructGPT模型微调数据集
- 十一、指令微调数据集格式
- 十二、训练数据准备阶段
- 参考文档
一、什么是LLM
LLM其实就是large language model,大语言模型。
AGI其实就是Artificial General Intelligence,通用人工智能。
如果对“最终任务”进一步进行分类,又大致可以分为两大不同类型的任务:自然语言理解类任务和自然语言生成类任务。如果排除掉“中间任务”的话,典型的自然语言理解类任务包括文本分类、句子关系判断、情感倾向判断等,这种任务本质上都是分类任务,就是说输入一个句子(文章),或者两个句子,模型参考所有输入内容,最后给出属于哪个类别的判断。自然语言生成也包含很多NLP研究子方向,比如聊天机器人、机器翻译、文本摘要、问答系统等。生成类任务的特点是给定输入文本,对应地,模型要生成一串输出文本。这两者的差异主要体现在输入输出形式上
NLP各种任务其实收敛到了两个不同的预训练模型框架里:
- 对于自然语言理解类任务,其技术体系统一到了以Bert为代表的“双向语言模型预训练+应用Fine-tuning”模式;
- 对于自然语言生成类任务,其技术体系统一到了以GPT 2.0为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt”模式。
如果是以fine-tuning方式解决下游任务,Bert模式的效果优于GPT模式;若是以zero shot/few shot prompting这种模式解决下游任务,则GPT模式效果要优于Bert模式。
ChatGPT向GPT 3.5模型注入新知识了吗?应该是注入了,这些知识就包含在几万人工标注数据里,不过注入的不是世界知识,而是人类偏好知识。所谓“人类偏好”,包含几方面的含义:首先,是人类表达一个任务的习惯说法。比如,人习惯说:“把下面句子从中文翻译成英文”,以此表达一个“机器翻译”的需求,但是LLM又不是人,它怎么会理解这句话到底是什么意思呢?你得想办法让LLM理解这句命令的含义,并正确执行。所以,ChatGPT通过人工标注数据,向GPT 3.5注入了这类知识,方便LLM理解人的命令,这是它“善解人意”的关键。其次,对于什么是好的回答,什么是不好的回答,人类有自己的标准,例如比较详细的回答是好的,带有歧视内容的回答是不好的,诸如此类。这是人类自身对回答质量好坏的偏好。人通过Reward Model反馈给LLM的数据里,包含这类信息。总体而言,ChatGPT把人类偏好知识注入GPT 3.5,以此来获得一个听得懂人话、也比较礼貌的LLM。
可以看出,ChatGPT的最大贡献在于:基本实现了理想LLM的接口层,让LLM适配人的习惯命令表达方式,而不是反过来让人去适配LLM,绞尽脑汁地想出一个能Work的命令(这就是instruct技术出来之前,prompt技术在做的事情),而这增加了LLM的易用性和用户体验。是InstructGPT/ChatGPT首先意识到这个问题,并给出了很好的解决方案,这也是它最大的技术贡献。相对之前的few shot prompting,它是一种更符合人类表达习惯的人和LLM进行交互的人机接口技术。
二、LLM从海量文本中学习到了什么?
1. 学到了“语言类知识”
语言类知识指的是词法、词性、句法、语义等有助于人类或机器理解自然语言的知识。关于LLM能否捕获语言知识有较长研究历史,自从Bert出现以来就不断有相关研究,很早就有结论,各种实验充分证明LLM可以学习各种层次类型的语言学知识,这也是为何使用预训练模型后,各种语言理解类自然语言任务获得大幅效果提升的最重要原因之一。另外,各种研究也证明了浅层语言知识比如词法、词性、句法等知识存储在Transformer的低层和中层,而抽象的语言知识比如语义类知识,广泛分布在Transformer的中层和高层结构中。
2. 学到了“世界知识”
世界知识指的是在这个世界上发生的一些真实事件(事实型知识,Factual Knowledge),以及一些常识性知识(Common Sense Knowledge)。比如“拜登是现任美国总统”、“拜登是美国人”、“乌克兰总统泽连斯基与美国总统拜登举行会晤”,这些都是和拜登相关的事实类知识;而“人有两只眼睛”、“太阳从东方升起”这些属于常识性知识。关于LLM模型能否学习世界知识的研究也有很多,结论也比较一致:LLM确实从训练数据中吸收了大量世界知识,而这类知识主要分布在Transformer的中层和高层,尤其聚集在中层。而且,随着Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加(可参考:BERTnesia: Investigating the capture and forgetting of knowledge in BERT)。其实,你把LLM看作是一种以模型参数体现的隐式知识图谱,如果这么理解,我认为是一点问题也没有的。
“When Do You Need Billions of Words of Pre-training Data?”这篇文章研究了预训练模型学习到的知识量与训练数据量的关系,它的结论是:对于Bert类型的语言模型来说,只用1000万到1亿单词的语料,就能学好句法语义等语言学知识,但是要学习事实类知识,则要更多的训练数据。这个结论其实也是在意料中的,毕竟语言学知识相对有限且静态,而事实类知识则数量巨大,且处于不断变化过程中。而目前研究证明了随着增加训练数据量,预训练模型在各种下游任务中效果越好,这说明了从增量的训练数据中学到的更主要是世界知识。
三、LLM的知识到底存储到了网络中的什么地方
比如 “中国的首都是北京”这条知识,以三元组表达就是<北京,is-capital-of,中国>,其中“is-capital-of”代表实体间关系。这条知识它存储在LLM的哪里呢?
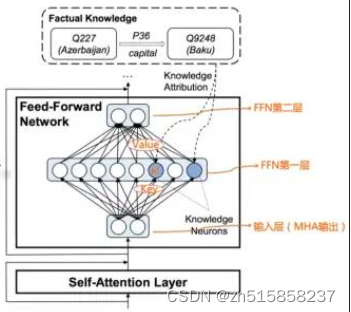
“Transformer Feed-Forward Layers Are Key-Value Memories”给出了一个比较新颖的观察视角,它把Transformer的FFN看成存储大量具体知识的Key-Value存储器。FFN的第一层是个MLP宽隐层,这是Key层;第二层是MLP窄隐层,是Value层。FFN的输入层其实是某个单词对应的MHA的输出结果Embedding,也就是通过Self Attention,将整个句子有关的输入上下文集成到一起的Embedding,代表了整个输入句子的整体信息。
我们假设上图的节点 就是记载<北京,is-capital-of,中国>这条知识的Key-Value存储器,它的Key向量,用于检测”中国的首都是…”这个知识模式,它的Value向量,基本存储了与单词“北京”的Embedding比较接近的向量。当Transformer的输入是“中国的首都是[Mask]”的时候, 节点从输入层探测到这个知识模式,所以产生较大的响应输出。我们假设Key层其它神经元对这个输入都没有任何响应,那么对应的Value层的节点,其实只会接收到“北京”这个Value对应的单词embedding,并通过 的大响应值,进行了进一步的数值放大。于是,Mask位置对应的输出,就自然会输出“北京”这个单词。
四、如何修改LLM中的某些知识?
既然我们已知具体的某条世界知识存储在某个或者某些FFN节点的参数里,自然会引发另外一个问题:我们能否修正LLM模型里存储的错误或者过时的知识呢?比如对于问题:“英国的现任首相是谁?”鉴于近年来英国首相频繁更迭,你猜LLM更倾向输出“鲍里斯”还是更青睐“苏纳克”?很明显训练数据中包含“鲍里斯”的数据会更多,这种情况很大可能LLM会给出错误回答,于是我们就有修正LLM里存储的过时知识的必要性。
如果归纳下,目前有三类不同方法来修正LLM里蕴含的知识:
第一类方法从训练数据的源头来修正知识。“Towards Tracing Factual Knowledge in Language Models Back to the Training Data”这篇文章的研究目标是:对于指定的某条知识,我们是否可以定位到是哪些训练数据导致LLM学会了这条知识?答案是肯定的,这意味着我们可以逆向追踪到某条知识对应的训练数据源头。如果利用这项技术,假设我们想要删除某条知识,则可首先定位到其对应的数据源头,删除数据源,然后重新预训练整个LLM模型,这样即可达成删除LLM中相关知识的目的。但是这里有个问题,如果修正一小部分知识,我们就需要重新做一次模型预训练,这样做明显成本太高。所以这种方法不会太有发展前景,可能比较适合那种对于某个特定类别数据的一次性大规模删除场合,不适合少量多次的常规知识修正场景,比如可能比较适合用来做去除偏见等去toxic内容的处理。
第二类方法是对LLM模型做一次fine-tuning来修正知识。一个直观能想到的方法是:我们可以根据要修正成的新知识来构建训练数据,然后让LLM模型在这个训练数据上做fine-tuning,这样指导LLM记住新的知识,遗忘旧的知识。这个方法简单直观,但是也有一些问题,首先它会带来灾难遗忘问题,就是说除了忘掉该忘的知识,还忘掉了不该忘的知识,导致这么做了之后有些下游任务效果下降。另外,因为目前的LLM模型规模非常大,即使是做fine-tuning,如果次数频繁,其实成本也相当高。对这种方法感兴趣的可以参考“Modifying Memories in Transformer Models”。
另外一类方法直接修改LLM里某些知识对应的模型参数来修正知识。假设我们想要把旧知识<英国,现任首相,鲍里斯>,修正到<英国,现任首相,苏纳克>。首先我们想办法在LLM模型参数中,定位到存储旧知识的FFN节点,然后可以强行调整更改FFN中对应的模型参数,将旧知识替换成新的知识。可以看出,这种方法涉及到两项关键技术:首先是如何在LLM参数空间中定位某条知识的具体存储位置;其次是如何修正模型参数,来实现旧知识到新知识的修正。关于这类技术的细节,可以参考“Locating and Editing Factual Associations in GPT”和“Mass-Editing Memory in a Transformer”。理解这个修正LLM知识的过程,其实对于更深入理解LLM的内部运作机制是很有帮助的。
五、如何平衡训练数据量、模型参数、增加epoch的关系
研究证明:当我们独立增加训练数据量、模型参数规模或者延长模型训练时间(比如从1个Epoch到2个Epoch),预训练模型在测试集上的Loss都会单调降低,也就是说模型效果越来越好。
既然三个因素都重要,那么我们在实际做预训练的时候,就有一个算力如何分配的决策问题:假设用于训练LLM的算力总预算(比如多少GPU小时或者GPU天)给定,那么是应该多增加数据量、减少模型参数呢?还是说数据量和模型规模同时增加,减少训练步数呢?此消彼长,某个要素规模增长,就要降低其它因素的规模,以维持总算力不变,所以这里有各种可能的算力分配方案。最终OpenAI选择了同时增加训练数据量和模型参数,但是采用早停策略(early stopping)来减少训练步数的方案。因为它证明了:对于训练数据量和模型参数这两个要素,如果只单独增加其中某一个,这不是最好的选择,最好能按照一定比例同时增加两者,它的结论是优先增加模型参数,然后才是训练数据量。假设用于训练LLM的算力总预算增加了10倍,那么应该增加5.5倍的模型参数量,1.8倍的训练数据量,此时模型效果最佳。
六、思维链promting是啥
思维链(few-shot CoT,Chain of Thought)Prompting,这个方向目前是LLM推理研究的主方向。

CoT的主体思想其实很直白;为了教会LLM模型学会推理,给出一些人工写好的推理示例,示例里把得到最终答案前,一步步的具体推理步骤说清楚,而这些人工写的详细推理过程,就是思维链Prompting,具体例子可参照上图中蓝色文字部分。CoT的意思是让LLM模型明白一个道理;就是在推理过程中,步子不要迈得太大,否则很容易出错,改变思维模式,化大问题为小问题,步步为营,积小胜为大胜。最早明确提出CoT这个概念的文章是“Chain of thought prompting elicits reasoning in large language models”,论文发布于22年1月份,虽然做法很简单,但是应用CoT后LLM模型的推理能力得到了巨大提升,GSM8K数学推理测试集准确率提高到60.1%左右。
七、代码预训练增强LLM推理能力
以“Self Consistency”方法为例,在大多数据集合上的性能提升,都直接超过了20到50个百分点,这是很恐怖的性能提升,而其实在具体推理模型层面,我们什么也没做,仅仅是预训练的时候除了文本,额外加入了程序代码而已。
越大的LLM模型学习效率越高,也就是说相同训练数据量,模型越大任务效果越好,说明面对的即使是同样的一批训练数据,更大的LLM模型相对规模小一些的模型,从中学到了更多的知识。
当模型参数规模未能达到某个阀值时,模型基本不具备解决此类任务的任何能力,体现为其性能和随机选择答案效果相当,但是当模型规模跨过阀值,LLM模型对此类任务的效果就出现突然的性能增长。也就是说,模型规模是解锁(unlock)LLM新能力的关键,随着模型规模越来越大,会逐渐解锁LLM越来越多的新能力。思维链(Chain of Thought)Prompting是典型的增强LLM推理能力的技术,能大幅提升此类任务的效果。
问题是,为何LLM会出现这种“涌现能力”现象呢?上述文章以及“Emergent Abilities of Large Language Models”给出了几个可能的解释:
一种可能解释是有些任务的评价指标不够平滑。比如说有些生成任务的判断标准,它要求模型输出的字符串,要和标准答案完全匹配才算对,否则就是0分。所以,即使随着模型增大,其效果在逐步变好,体现为输出了更多的正确字符片段,但是因为没有完全对,只要有任何小错误都给0分,只有当模型足够大,输出片段全部正确才能得分。也就是说,因为指标不够平滑,所以不能体现LLM其实正在逐步改善任务效果这一现实,看起来就是“涌现能力”这种外在表现。
另外一种可能的解释是:有些任务由若干中间步骤构成,随着模型规模增大,解决每个步骤的能力也在逐步增强,但是只要有一个中间步骤是错的,最终答案就是错的,于是也会导致这种表面的“涌现能力”现象。
如果你细想,会发现In Context Learning是个很神奇的技术。它神奇在哪里呢?神奇在你提供给LLM几个样本示例 <x1,y1>,<x2,y2>,…,<xn,yn>,然后给它xm,LLM竟然能够成功预测对应的ym。听到这你会反问:这有什么神奇的呢?Fine-tuning不就是这样工作的吗?你要这么问的话,说明你对这个问题想得还不够深入。
Fine-tuning和In Context Learning表面看似都提供了一些例子给LLM,但两者有质的不同(参考上图示意):Fine-tuning拿这些例子当作训练数据,利用反向传播去修正LLM的模型参数,而修正模型参数这个动作,确实体现了LLM从这些例子学习的过程。但是,In Context Learning只是拿出例子让LLM看了一眼,并没有根据例子,用反向传播去修正LLM模型参数的动作,就要求它去预测新例子。既然没有修正模型参数,这意味着貌似LLM并未经历一个学习过程,如果没有经历学习过程,那它为何能够做到仅看一眼,就能预测对新例子呢?这正是In Context Learning的神奇之处。
能够有效增加LLM模型Instruct泛化能力的因素包括:增加多任务的任务数量、增加LLM模型大小、提供CoT Prompting, 以及增加任务的多样性。如果采取任意一项措施,都可以增加LLM模型的Instruct理解能力。
当模型规模足够大的时候,LLM本身是具备推理能力的,在简单推理问题上,LLM已经达到了很好的能力,但是复杂推理问题上,还需要更多深入的研究。
如果梳理现有LLM推理相关工作的话,我把它们归到两大类,体现出挖掘或促进LLM推理能力不同的技术思路:第一类研究比较多,可以统称为基于Prompt的方法,核心思想是通过合适的提示语或提示样本,更好地激发出LLM本身就具备的推理能力,Google在这个方向做了大量很有成效的工作。第二类做法是在预训练过程中引入程序代码,和文本一起参与预训练,以此进一步增强LLM的推理能力,这应该是OpenAI实践出的思路。比如ChatGPT肯定具备很强的推理能力,但它并不要求用户必须提供一些推理示例,所以ChatGPT强大的推理能力,大概率来源于使用代码参与GPT 3.5的预训练。
这两种思路其实大方向是迥异的:利用代码增强LLM推理能力,这体现出一种通过增加多样性的训练数据,来直接增强LLM推理能力的思路;而基于Prompt的方法,它并不会促进LLM本身的推理能力,只是让LLM在解决问题过程中更好地展示出这种能力的技术方法。可以看出,前者(代码方法)治本,后者治标。当然,两者其实也是互补的,但从长远看,治本的方法更重要。
利用代码增强LLM推理能力,这体现出一种通过增加多样性的训练数据,来直接增强LLM推理能力的思路;而基于Prompt的方法,它并不会促进LLM本身的推理能力,只是让LLM在解决问题过程中更好地展示出这种能力的技术方法。可以看出,前者(代码方法)治本,后者治标。当然,两者其实也是互补的,但从长远看,治本的方法更重要。
八、近年来的大模型
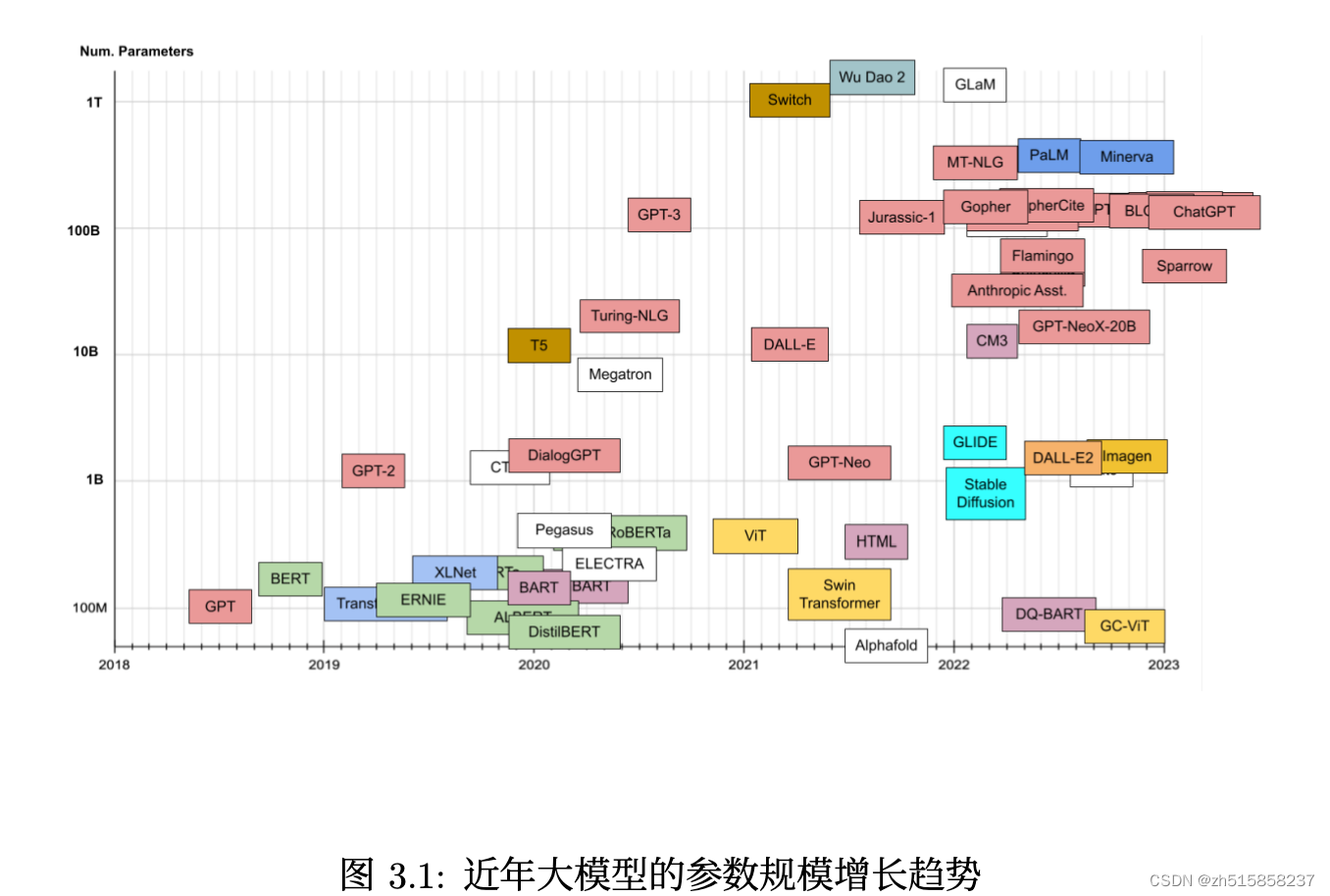
九、预训练数据集概览
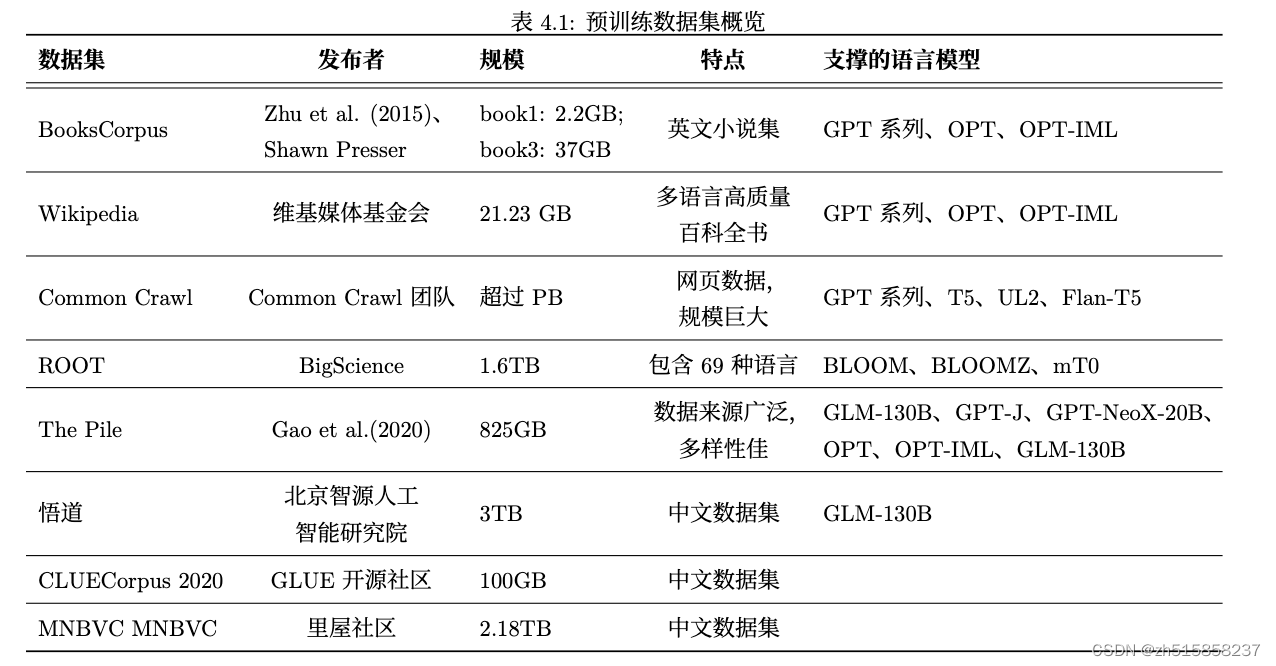
尽管目前已经开源了很多的预训练数据,但在训练大规模预训练语言模 型时,预训练数据依然是瓶颈,原因如下:(1)开源的预训练数据或多或少存 在噪音问题,特别是爬虫数据噪音问题严重,如何对预训练数据进行高质量地清洗和去重,是目前数据处理的核心与壁垒;(2)OpenAI 和 Google 使用 的高质量预训练数据集是闭源,无法获得,例如 Google 公司训练 Chinchilla 中使用的 2.1TB 的书籍数据库、3.1TB 的 Github 数据,OpenAI 公司训练 GPT 3 中使用的 WebText23、Books1、Books2 数据集。
自动爬取或收集的原始数据往往存在信息量低和含有噪声的问题,例如版本信息中只有“update”,缺少实质内容;回答中的代码片段可能与问题 无关等。因此,在使用数据之前,必须基于一定规则仔细进行筛选。
十、InstructGPT模型微调数据集
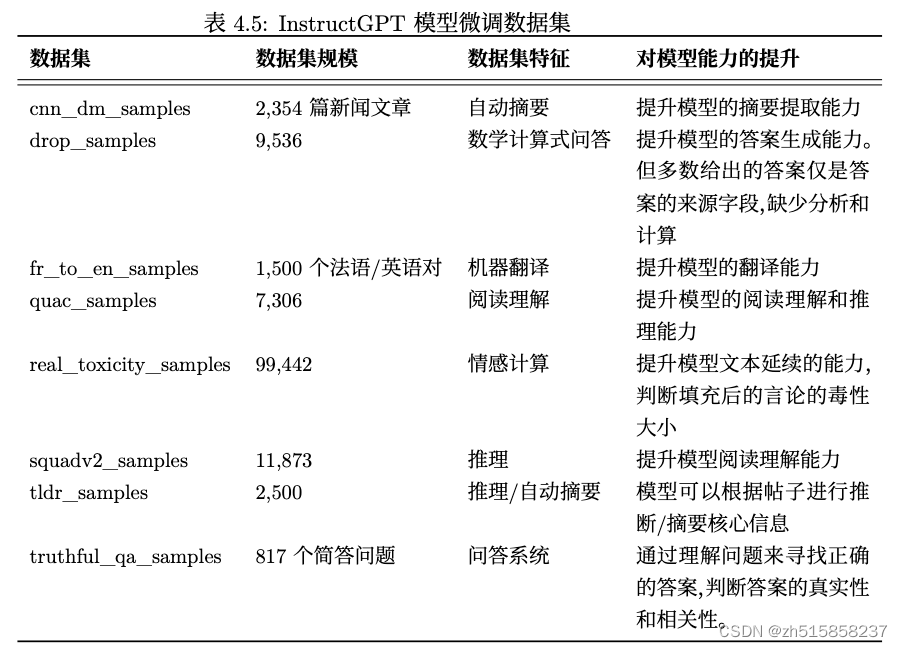
十一、指令微调数据集格式

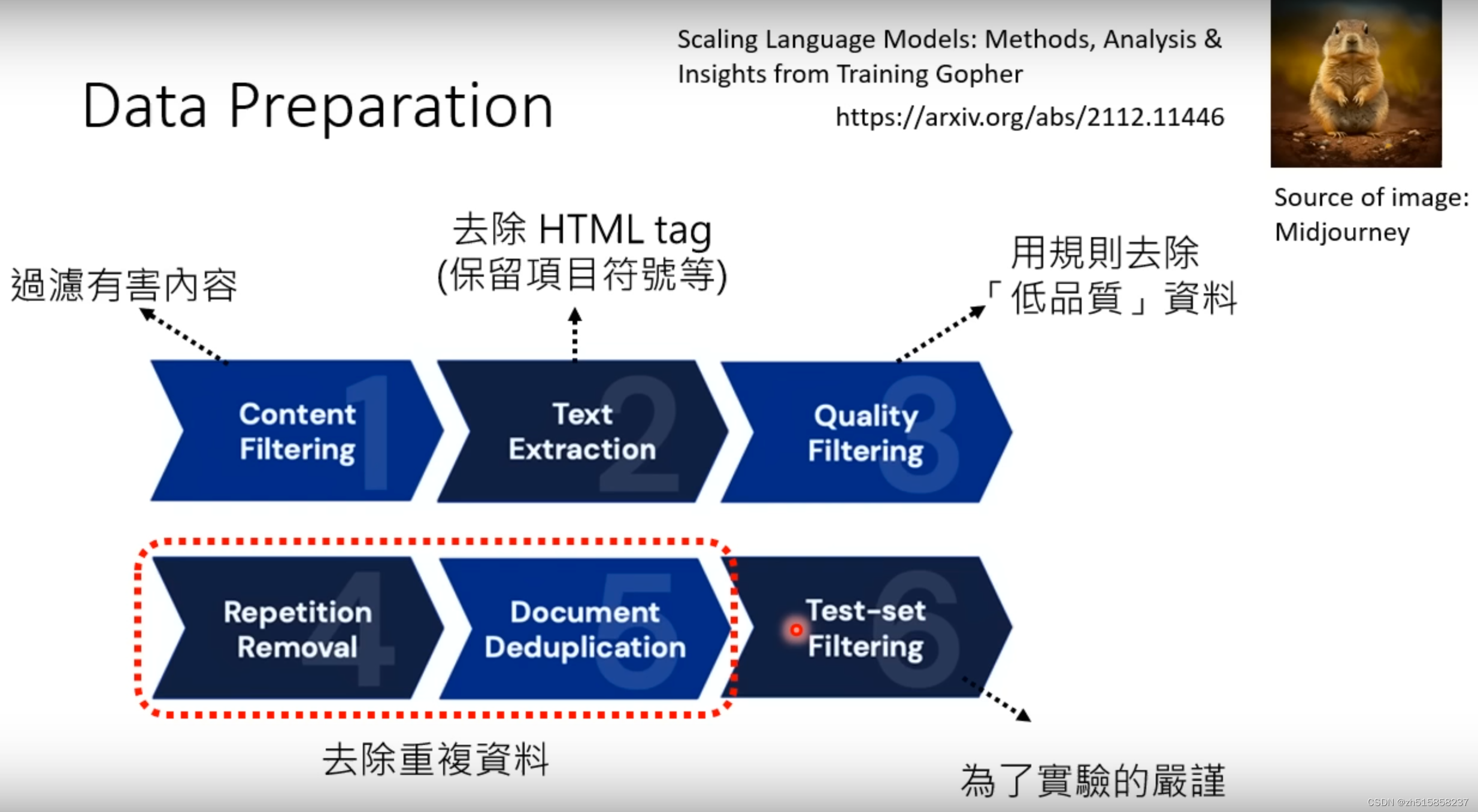
十二、训练数据准备阶段
参考文档
- 张俊林:由ChatGPT反思大语言模型(LLM)的技术精要
- 哈尔滨工业大学:ChatGPT调研报告