Feature Store 特征库
- 特征库的主要目的是什么?
- 特征库的五个主要组件
- 组成一:Serving 服务
- 组成二:Storage 存储
- 组成三:Transform 转换
- 组成四:Monitoring 监控
- 组成五:Feature Registry 功能注册表

Feature Store 特征库,是传统机器学习中的一个概念,它能确保输入模型的数据是最新和相关的。为什么特征库可以保证是最新的和最相关的,请看后文;
特征库的主要目的是什么?
“作为模型与数据之间的接口。”
Feature Store 特征库旨在解决在构建和运行可操作的 ML 应用程序时遇到的所有数据管理问题。其是一种专门用于 ML 的数据系统,它可以:
- 运行将原始数据(raw data)转换为特征值的数据管道(data pipelines);
- 存储和管理特征数据本身,以及;
- 为训练和推理目的持续提供特征数据;
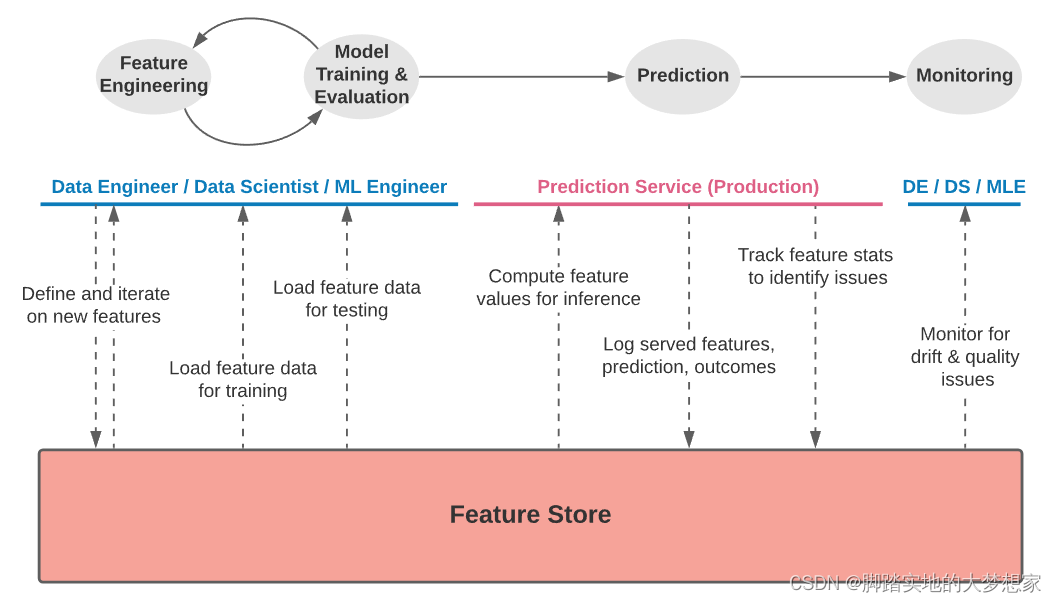
特征库是整个 ML 项目生命周期中特征数据和元数据的中心枢纽。特征库中的数据可用于:
- 特征探索和工程设计;
- 模型迭代、训练和调试;
- 特征发现和共享;
- 为推理模型提供生产服务;
- 运行状况监控等;
特征库通过实现协作,为 ML 组织带来规模经济效益。当一个特征在特征库中注册后,它就可以立即被整个组织的其他模型重用。这就减少了数据工程工作的重复,并允许新的 ML 项目利用经过策划的生产就绪特征库进行启动。
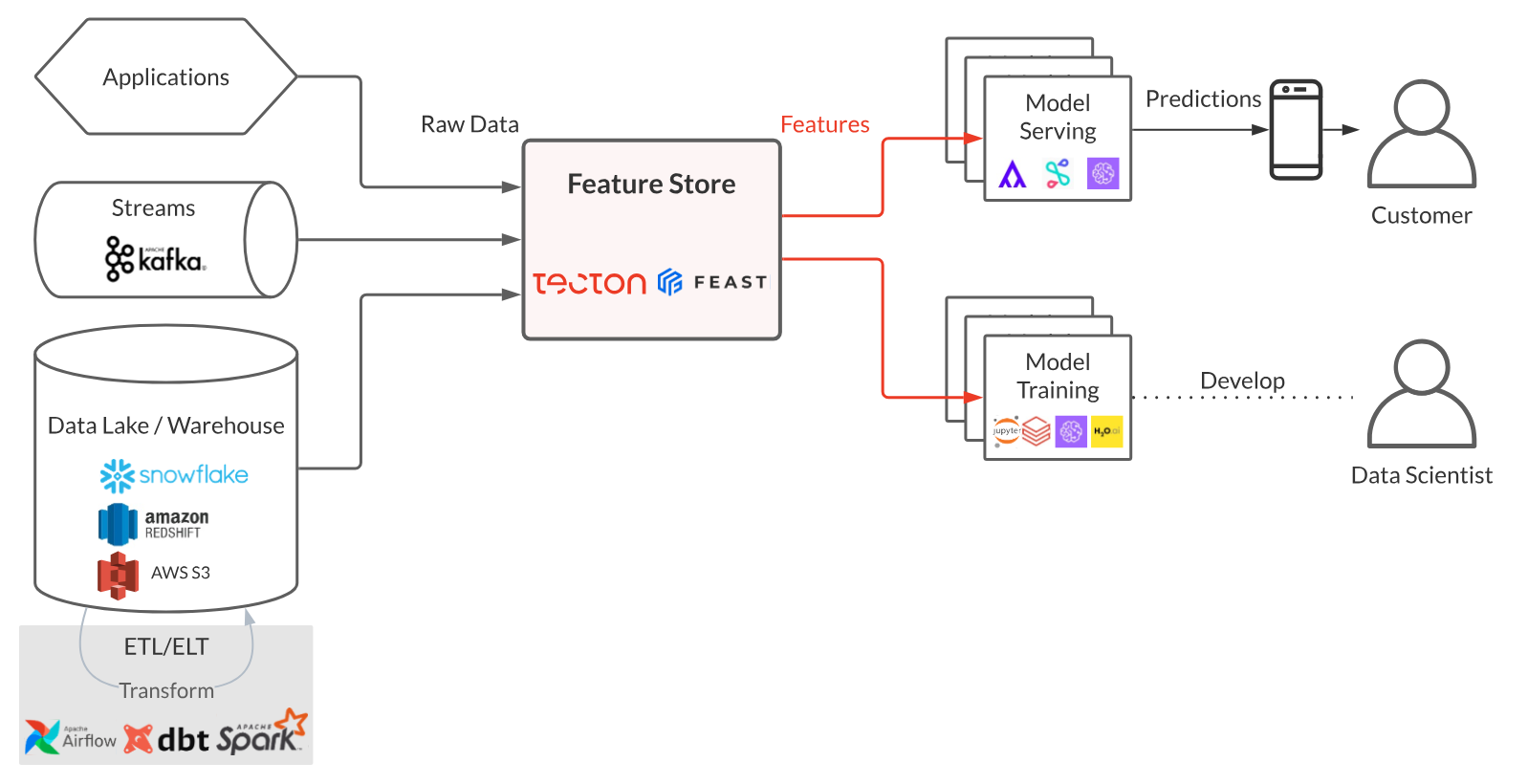
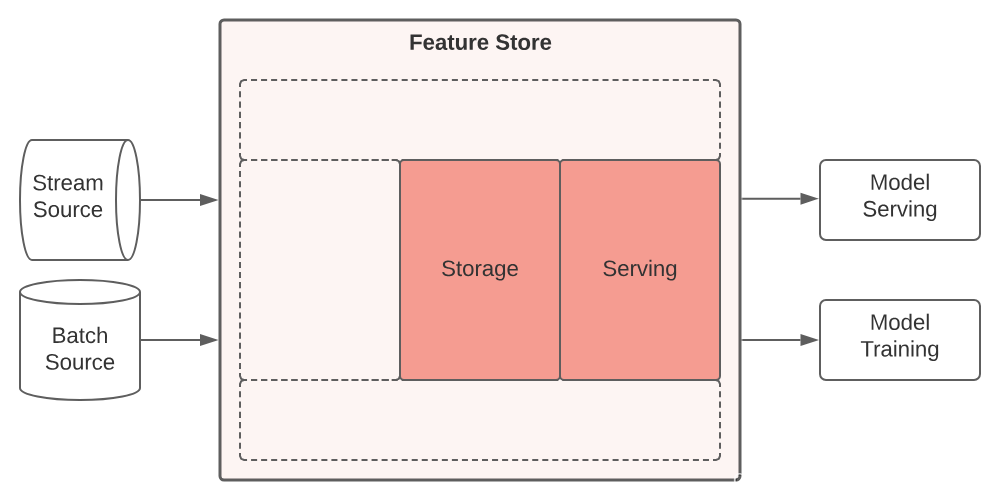
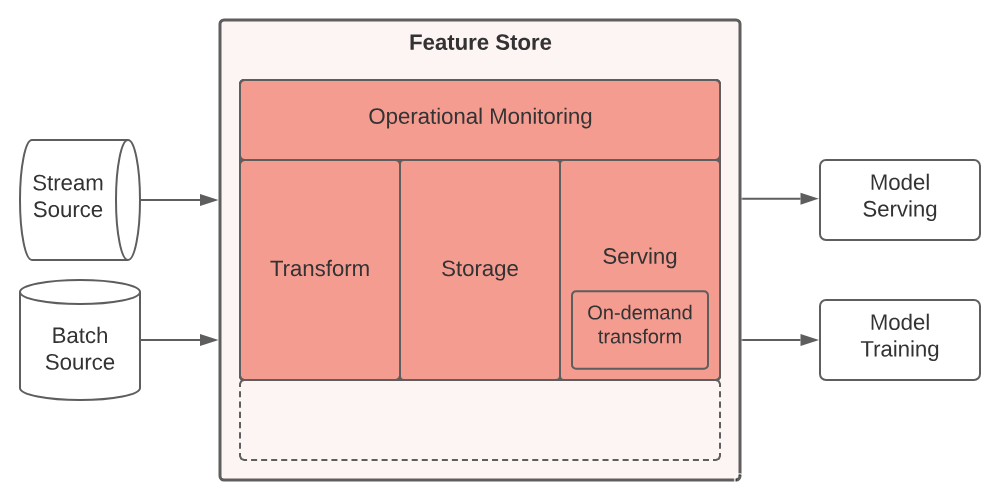
特征库设计为模块化系统,可根据部署环境进行调整。功能存储通常由五个主要组件组成。下面我们将介绍这些组件,并描述它们在支持可运行的 ML 应用程序中的作用。
特征库的五个主要组件
特征库有 5 个主要组件:
- 转换(Transformation);
- 存储(Storage);
- 服务(Serving);
- 监控(Monitoring);
- 功能注册表(Feature Registry)
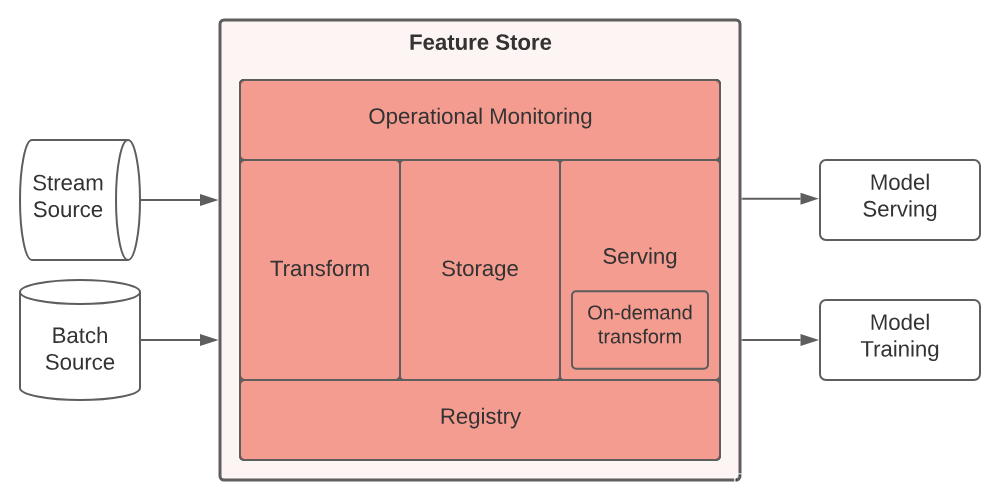
组成一:Serving 服务
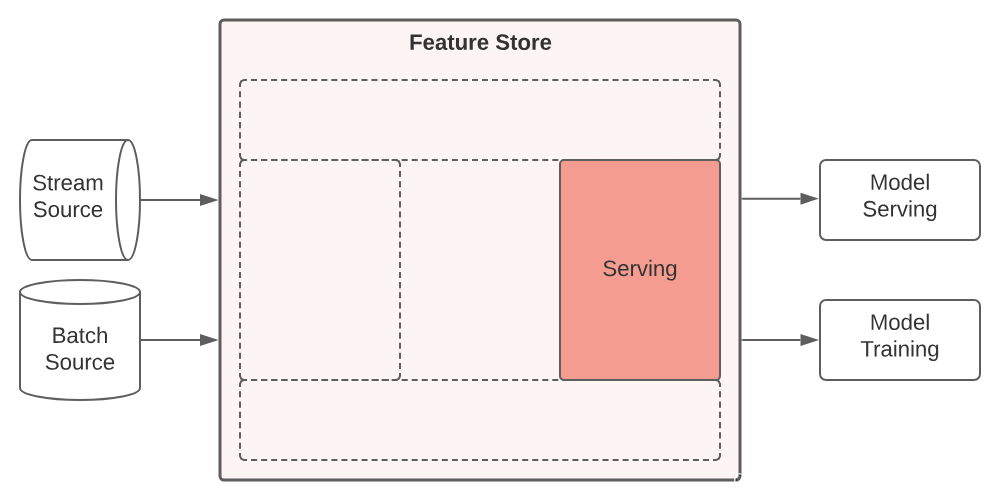
特征存储为模型提供特征数据。这些模型需要在训练和服务过程中保持一致的特征视图。用于训练模型的特征定义必须与在线服务中提供的特征完全匹配。如果两者不匹配,就会产生训练-服务偏差,从而导致灾难性的、难以调试的模型性能问题。
特征存储抽象掉了用于生成特征的逻辑和处理过程,为用户提供了一种简便、规范的方式,让他们可以在需要的所有环境中一致地访问公司中的所有特征。
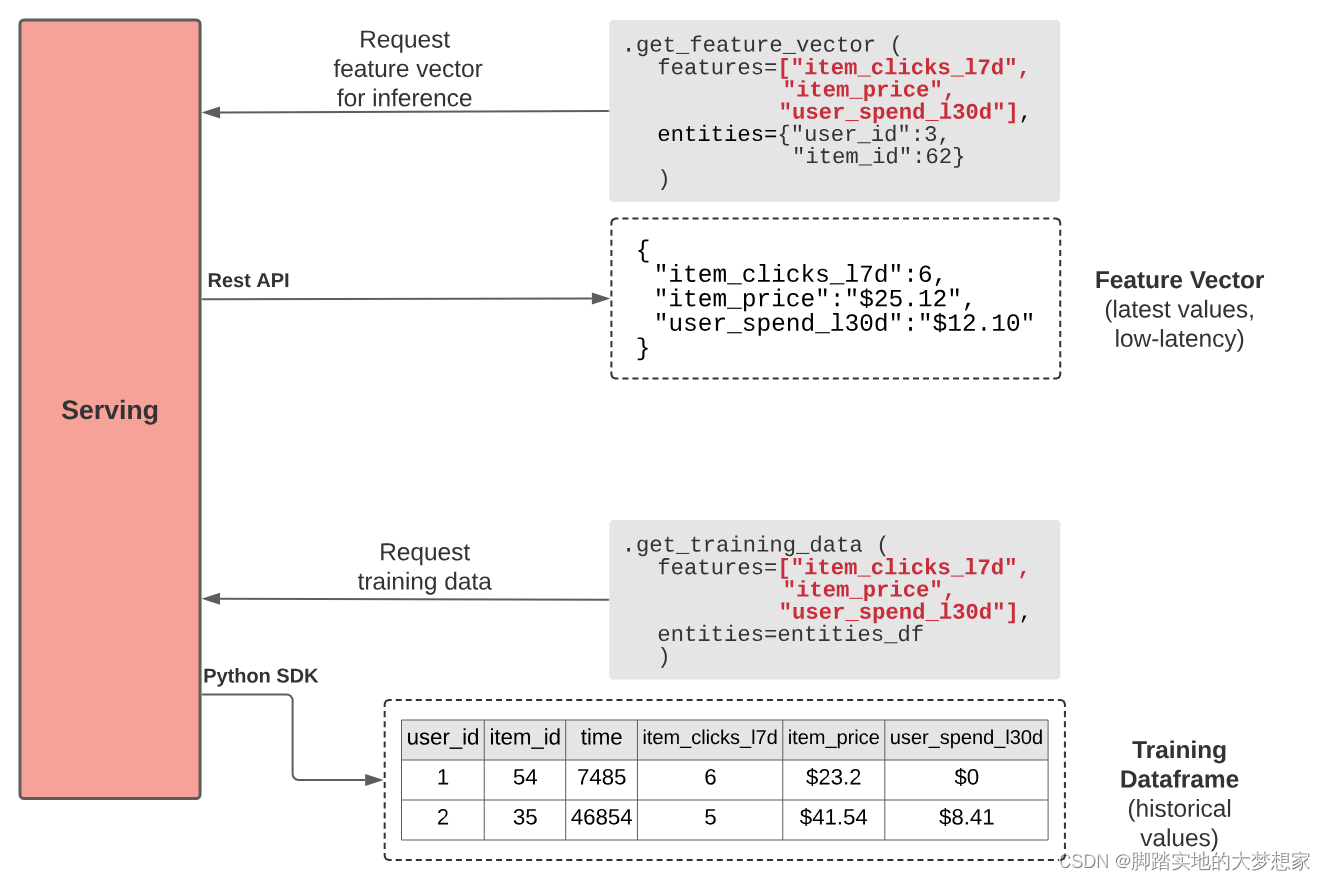
离线检索:
在离线检索数据(如用于训练)时,通常通过笔记本电脑友好型特征存储 SDK 来访问特征值。它们为用于训练模型的每个示例提供正确的时间点状态视图(又称 “时间旅行”)。
在线服务:
对于在线服务,特征存储每次提供由最新特征值组成的单一特征向量。响应通过由低延迟数据库支持的高性能应用程序接口 Rest API 提供。
组成二:Storage 存储
特征存储可持久保存特征数据,以支持通过特征服务层进行检索。它们通常包含在线和离线存储层,以支持不同特征服务系统的要求。
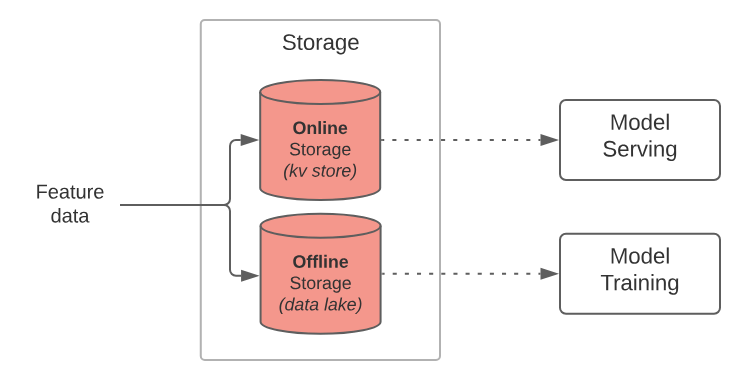
在线存储:
在线存储层用于持久保存特征值,以便在推理过程中进行低延迟查找。它们通常只存储每个实体的最新特征值。在线存储通常是最终一致的,对于大多数 ML 用例来说,没有严格的一致性要求。它们通常使用 DynamoDB、Redis 或 Cassandra 等键值存储来实现。
离线存储:
离线存储层通常用于存储数月或数年的特征数据,以备训练之用。离线特征存储数据通常存储在数据仓库或数据湖中,如 S3、BigQuery、Snowflake 和 Redshift。为离线特征存储扩展现有数据湖或数据仓库通常是首选,以防止出现数据孤岛。
组成三:Transform 转换
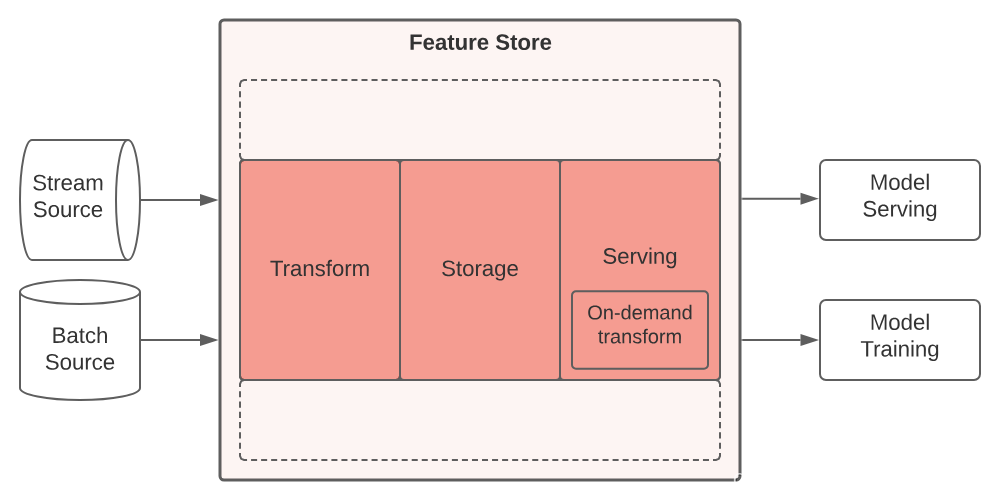
运行中的 ML 应用程序需要定期将新数据处理为特征值,这样模型才能使用最新的数据构建的新模型进行预测。特征库既能管理和协调产生这些值的数据转换,也能接收外部系统产生的值。特征库管理的转换是通过通用特征注册表(如下所述)中的定义来配置的。
特征存储通常与三种主要类型的数据转换进行交互:
| Feature Type | Definition | Common input data source | Example |
|---|---|---|---|
| Batch Transform | 仅用于静态数据的转换 | 数据湖、数据仓库、数据库 | 用户国家、产品类别 |
| Streaming Transform | 应用于流媒体源的转换 | Kafka, Kinesis, PubSub | 在过去 30 分钟内,每个用户在每个垂直方向上的点击次数,在过去一小时内,每个列表的浏览次数 |
| On-Demand Transform | 根据预测时可用的数据生成特征的变换。这些特征无法预先计算 | 面向用户的应用程序 | 用户当前是否在支持的位置?列表与搜索查询的相似度得分 |
它的一个主要优点是可以方便地在同一机型中同时使用不同类型的功能。
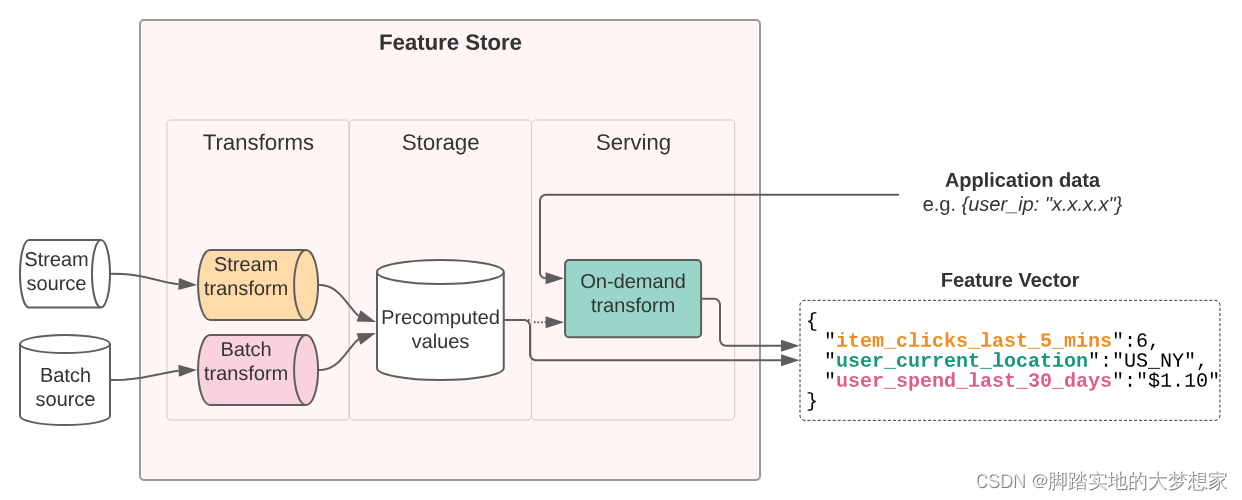
上图中,三个 Feature Vector 中的信息:
"item_clicks_last_5_mins"属于 Streaming Transform 特征类型,来自于 Stream Source;"user_current_location"属于 on-Demand Transform 特征类型,来自于 Application data;"user_spend_lasat_30_days"属于 Streaming Transform 特征类型,来自于 Stream Source;
模型的实时更新:
模型需要获取新的特征值来进行推理。特征存储通过持续定期地重新计算特征值来实现这一点。对转换作业进行协调,以确保新数据得到处理并转化为新的特征值。这些工作在与特征库相连的数据处理引擎(如 Spark 或 Pandas)上执行。
组成四:Monitoring 监控
当 ML 系统出现问题时,通常是数据问题。特征库在检测和发现此类问题方面具有独特的优势。它们可以计算所存储和提供的特征的指标,以描述正确性和质量。特征库可以监控这些指标,为 ML 应用程序的整体健康状况提供信号。
可根据用户定义的模式或其他结构标准对特征数据进行验证。在运行生产系统时,特征存储会跟踪与核心功能相关的运行指标:
- 与特征存储(可用性、容量、利用率、陈旧性)相关的指标;
- 与特征服务(吞吐量、延迟、错误率)相关的指标;
- 其他指标描述重要的相邻系统组件的运行情况,如外部数据处理引擎的运行指标(如作业成功率、吞吐量、处理滞后和处理率)。
功能存储可将这些指标提供给现有的监控基础设施。这样就可以使用生产堆栈中现有的可观察性工具来监控和管理 ML 应用程序的健康状况。通过了解哪些模型使用了哪些功能,特征库可以自动将警报和健康指标汇总到与特定用户、模型或消费者相关的视图中。
组成五:Feature Registry 功能注册表
所有特征库的一个重要组成部分是 标准化特征定义和元数据的集中注册中心,即功能注册表。该注册中心是组织内特征信息的唯一真实来源。

通过注册表,用户可以与功能存储进行互动。团队将注册表作为一个通用目录,用于在团队内和团队间探索、开发、协作和发布新定义。
注册表中的定义可配置功能存储系统行为。自动化作业使用注册表来安排和配置数据摄取、转换和存储。它构成了在特征库中存储哪些数据以及如何组织数据的基础。服务应用程序接口使用注册表来统一理解哪些特征值应该可用、谁应该能够访问它们以及如何提供服务。
本博文为学习记录型博文,欢迎社会各界人员一起讨论其可行性以及发展性;
本博文主要知识来源于 Techton Feast :https://www.tecton.ai/blog/what-is-a-feature-store/