文章目录
- 背景
- 分析
- 问题来了
- 比较一开始的情况
- 解决方式
背景
之前有分析过一次类似问题,最终结论是在keyby之后,其中有一个key数量特别庞大,导致对应的subtask压力过大,进而使得整个job不再继续运作。在这个问题解决之后,后续又再次出现了积压的情况,针对这个问题进行排查分析。
分析
通过以下这张图,可以看到当前它是没有数据积压的。
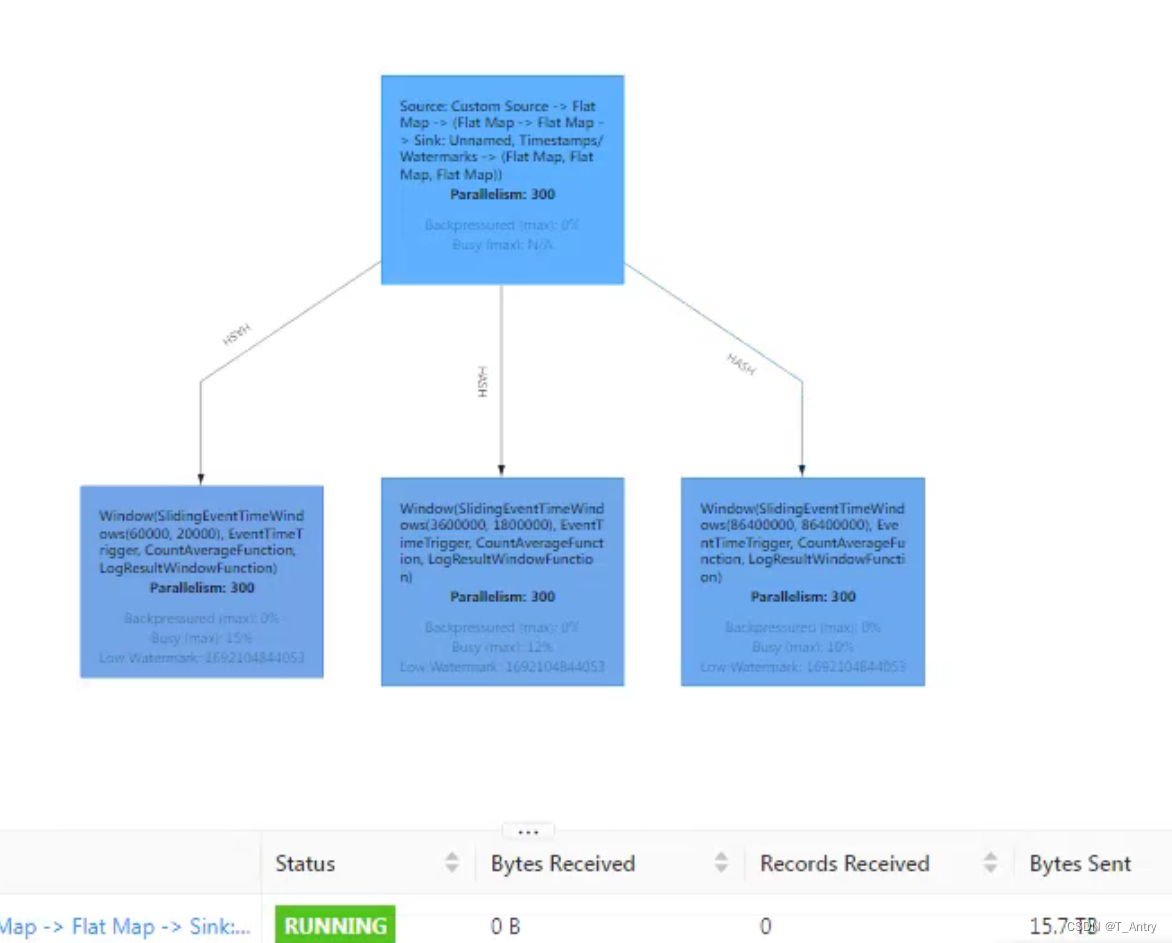
可以看到source-map-map-sink/map都放在了同一个task中,因为Flink的operator chain(算子链)机制,数据是通过调用链接算子的processElement()方法,直接将数据推给下游处理了。这里有300个并行度,也就是有300个subtask,每个算子之间都是一一对应的,如果其中一个并行度的源一直没有消费到数据,那么它的下游就一样会是空闲的

通过这张图可以看到有的subtask根本就没有在处理数据,而有的处理的是大量的数据。那这种肯定不是我们想要的。这种情况,资源存在浪费。
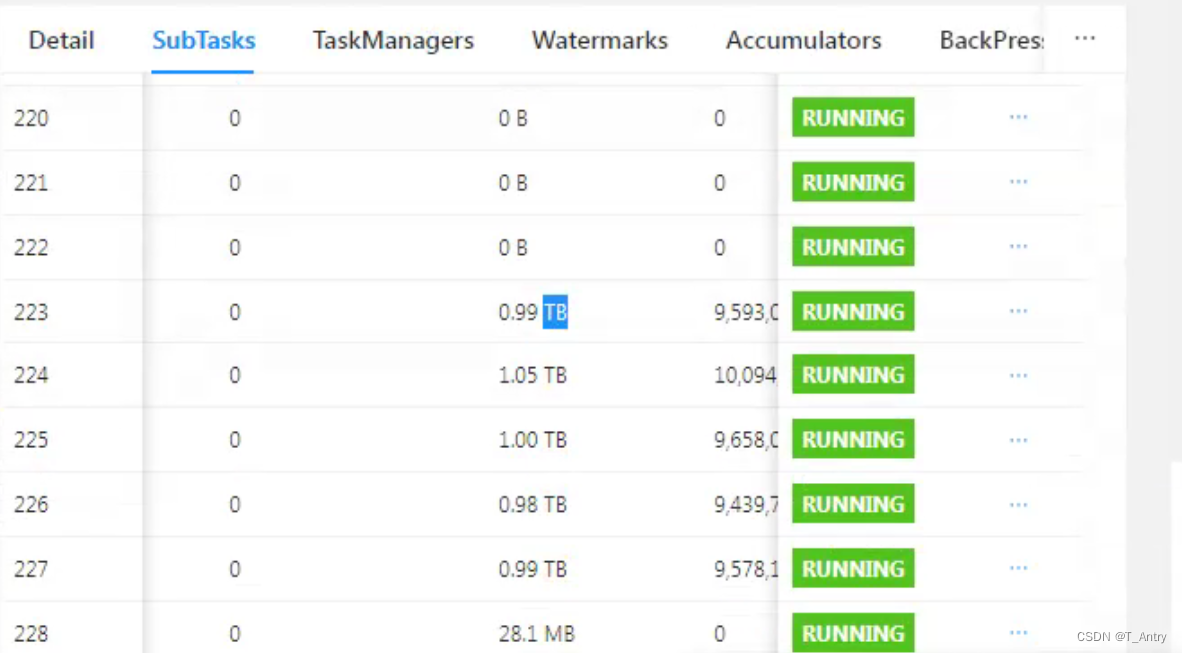
在前后并行度不一致的时候,task之间就会默认采用rebalance做负载均衡
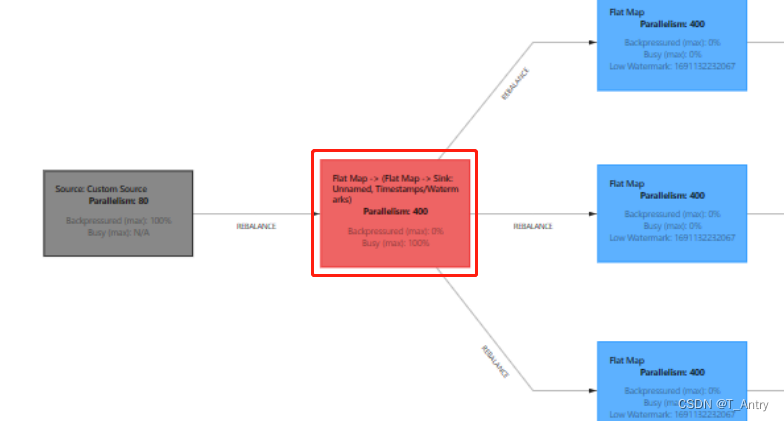
可以看到这种情况下,下游每个task处理的数据是比较平均的,在经过均衡之后

问题来了
到了这里就发现了个问题,竟然出现了严重的阻塞问题。
但仔细一看,并不是所有下游的subtask都是busy。
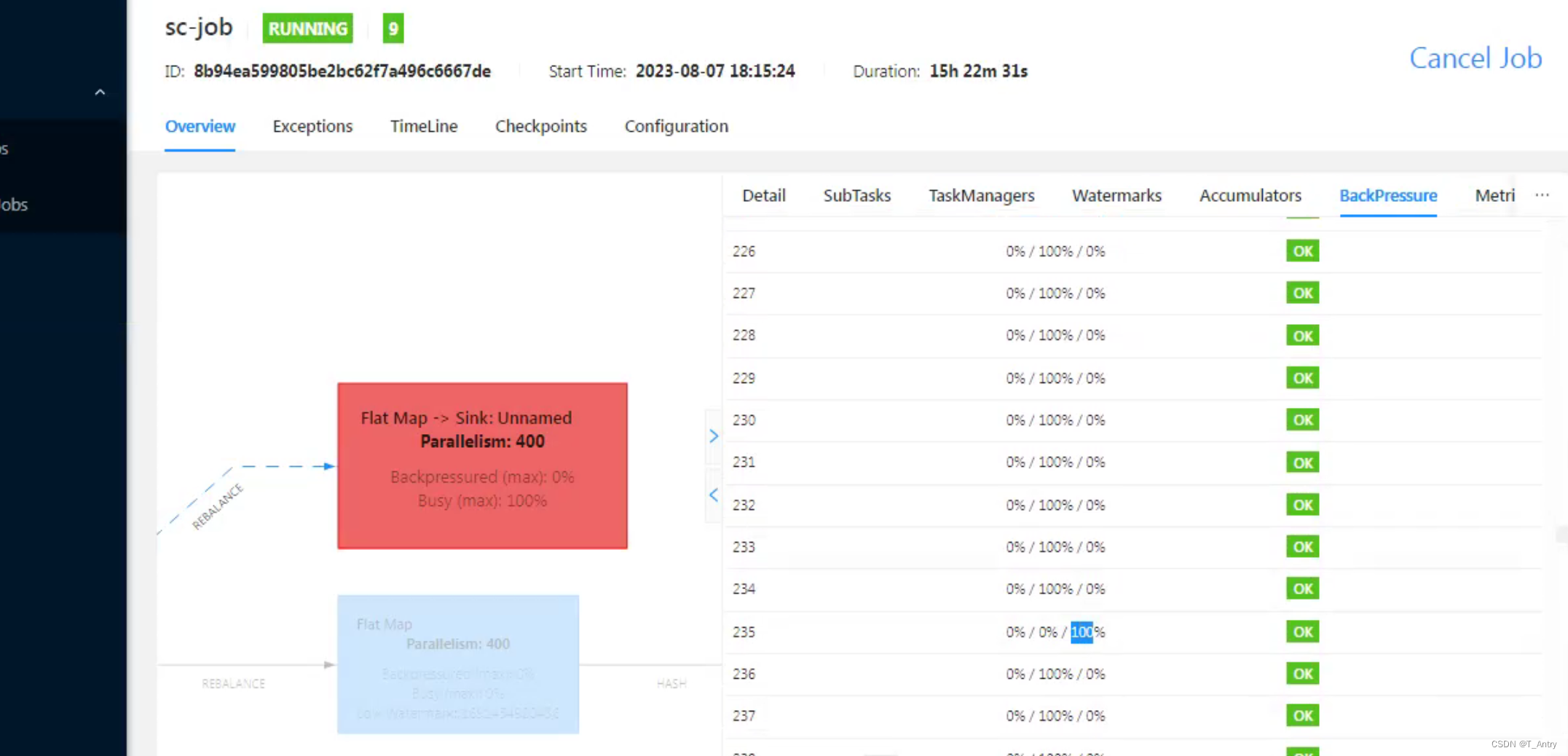
这种均衡之后部分阻塞的问题,经过代码,和实际的数据结合分析,我得出的结论是有一类数据,需要处理的时间是其他数据的几十倍。rebalance是轮询分配的,在某几个task接收到大量该类数据,导致它的运行压力直线上升,进而使得分配到此处时塞不进去了。即导致整体的阻塞。
比较一开始的情况
那么一开始为什么就没有阻塞呢,这一下就让人非常费解,明明rebalance负载均衡之后应该压力更小,更能够消费得过来才对,怎么现在就消费不来了呢。
在task中看到这样的日志,因为消费不来,很多该类topic的数据被丢弃了,因为没有阻塞,所以其他topic也就都能够正常消费。
解决方式
所以要解决这个问题的根本方式有两种
1、先把同一种数据需要耗费的时间与其他方式耗费时间差距较大的,进行缩小差距。
2、优化代码,让算子中的效率增加,处理每一条数据的时间减小
3、加大资源,增加并行度