Imperceptible Adversarial Attack via Invertible Neural Networks
作者:Zihan Chen, Ziyue Wang, Junjie Huang*, Wentao Zhao, Xiao Liu, Dejian Guan
解决的问题:虽然视觉不可感知性是对抗性示例的理想特性,但传统的对抗性攻击仍然会产生可追踪的对抗扰动。
代码:https://github.com/jjhuangcs/AdvINN
类型:黑盒 目标攻击
摘要:
作者利用可逆神经网络(AdvINN)方法进行对抗性攻击,生成鲁棒且难以察觉的对抗性示例。AdvINN利用INN的信息保留属性,添加目标类的指定信息、删除与原始类别不同的信息来生成对抗样本。
引言部分引出对抗攻击示例
虽然对抗样本的存在可能会阻碍深度学习在风险敏感领域的应用,但它进一步促进了对深度学习鲁棒性的研究。
现有对抗样本的类别:
- 在原始图像上添加扰动来生成对抗样本:FGSM系列的对抗攻击方法+混合其他类别的信息来生成对抗样本,这种方法可能会导致噪声被感知和图像存储容量的增加;
- 在原始图像上丢弃部分信息来生成对抗样本,这种方法可能会影响目标攻击的性能。
方法
给定一张良性图像 x c l n x_{cln} xcln,其标签为 c c c,作者的目标是通过丢弃类 c c c的discriminant information和添加target image x t g t x_{tgt} xtgt的对抗细节,同时能够通过残差图像 x r x_r xr解析添加和丢弃的特征信息。方案的整体概述如下图所示:
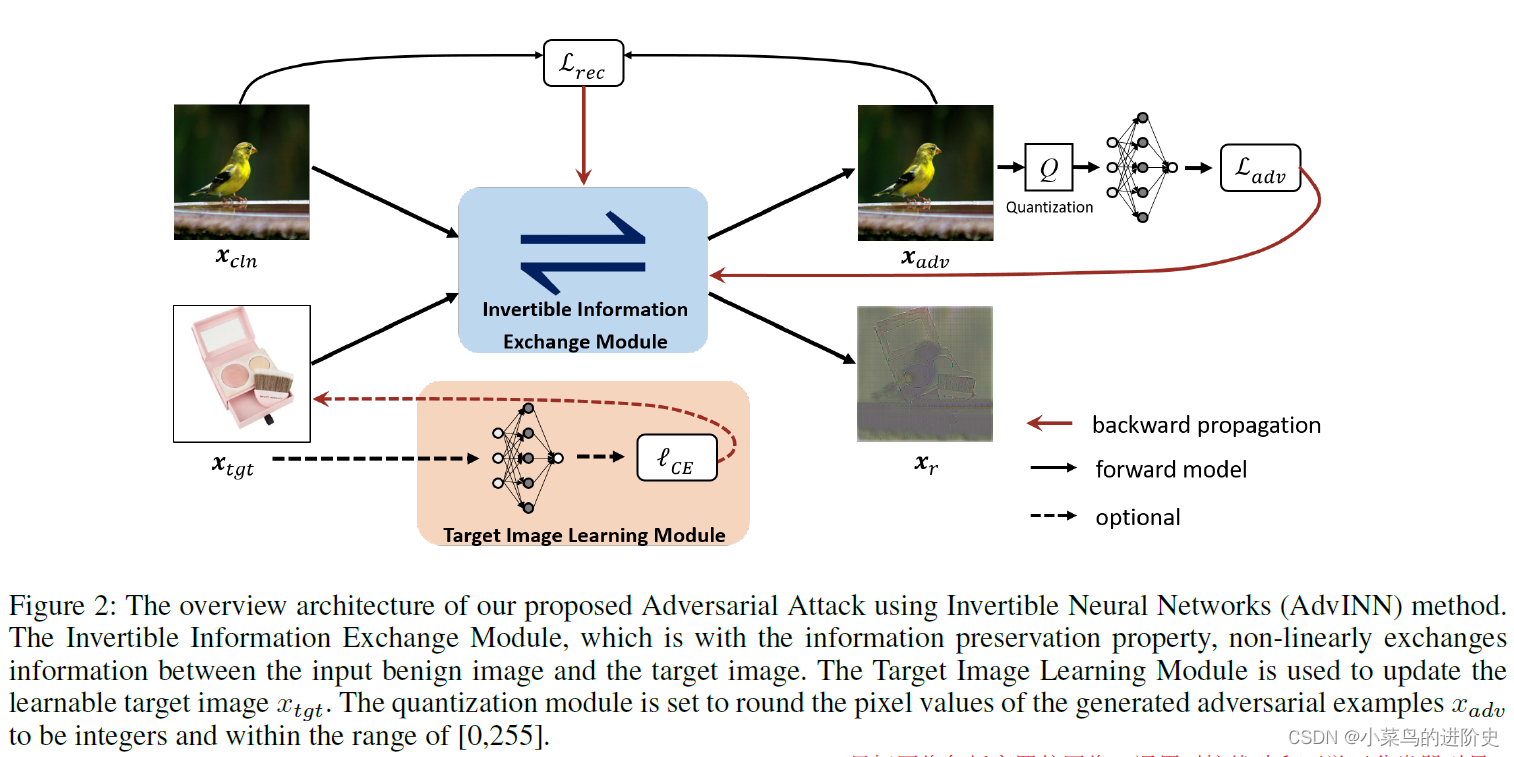
( x a d v , x r ) = f θ ( x c l n , x t g t ) ({x_{adv}},{x_r}) = {f_\theta }({x_{cln}},{x_{tgt}}) (xadv,xr)=fθ(xcln,xtgt)
- IIEM模块: θ \theta θ是 f θ ( ⋅ ) {f_\theta }({\cdot}) fθ(⋅)的参数,由Invertible Information Exchange Module (IIEM), Target Image Learning Module (TILM) 和loss functions三个模块组成用于优化;IIEM由损失函数驱动,通过执行 x c l n {x_{cln }} xcln和 x t g t {x_{tgt}} xtgt的信息交换来生成对抗图像。由于IIEM的保留属性,输入图像 ( x c l n , x t g t ) ({x_{cln}},{x_{tgt}}) (xcln,xtgt)和输出图像 ( x a d v , x r ) ({x_{adv}},{x_{r}}) (xadv,xr)是相同的且 ( x a d v , x r ) = f θ − 1 ( x c l n , x t g t ) ({x_{adv}},{x_r})= {f_\theta }^{ - 1}({x_{cln }},{x_{tgt}}) (xadv,xr)=fθ−1(xcln,xtgt)。AdvINN生成对抗样本的目标函数定义如下:
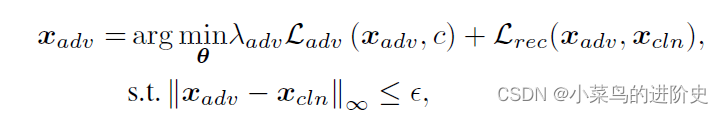
L a d v ( ⋅ ) \mathcal{L_{adv}}( \cdot ) Ladv(⋅)表示对抗损失, L r e c ( ⋅ ) \mathcal{L_{rec}}( \cdot ) Lrec(⋅)表示重构损失, λ a d v {\lambda _{adv}} λadv 表示正则参数, ε \varepsilon ε表示对抗扰动预算。
-target image选择: target image是对抗信息的来源,可以从highest confidence target image (HCT)、universal adversarial perturbation (UAP)或online learned classifier guided target image( CGT)中选择;
Invertible Information Exchange Module (IIEM)
该模块主要包括离散小波变换和仿射偶尔两个模块,示意图如下:
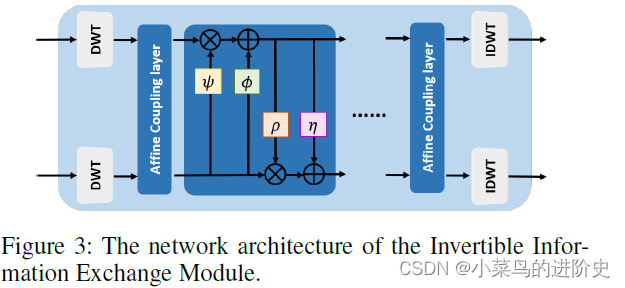
- 离散小波变换:作者使用离散小波变换(正文使用的是哈儿小波变换)用以区分输入干净和目标图像分解为低频和高频成分。分解低频和高频特征有助于修改输入图像的高频成分,因而可以产生更不易察觉的对抗样本(注意:修改高频成分生成的对抗样本更不易被察觉。)离散小波变换 T ( ⋅ ) \mathcal{T}(\cdot) T(⋅)中,输入图像 x x x可被转换成小波域 T ( x ) \mathcal{T}(x) T(x),该域上包含一个低频子带特征和3个高频子带特征。在IIEM的输出端,逆离散小波变换 T − 1 ( ⋅ ) {\mathcal{T}^{-1}}( \cdot ) T−1(⋅)用于重构特征到图像域。
- 仿射耦合模块:可逆信息交换模块由 M M M个Affine Coupling Blocks(仿射耦合模块)组成。 w c l n i w_{cln }^i wclni和 w t g t i w_{tgt}^i wtgti表示第 i i i个Affine Coupling Blocks的输入特征, w c l n i = T ( x c l n ) w_{cln }^i = T({x_{cln }}) wclni=T(xcln), w t g t i = T ( x t g t ) w_{tgt}^i = T({x_{tgt}}) wtgti=T(xtgt)。第 i i i个Affine Coupling Blocks的前向过程可表示为:
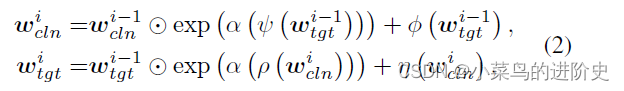
Θ \Theta Θ表示两个矩阵对应相乘, α \alpha α表示一个sigmod 函数乘以一个常数因子, ψ ( ⋅ ) , ρ ( ⋅ ) , η ( ⋅ ) \psi ( \cdot ),\rho ( \cdot ),\eta ( \cdot ) ψ(⋅),ρ(⋅),η(⋅)表示dense network architecture。给定第M个仿射耦合模块的输出,利用逆小波变换可获得对抗图像和残差图像: x a d v = T − 1 ( w c l n M ) , x r = T − 1 ( w t g t M ) {x_{adv}} = {T^{ - 1}}(w_{cln }^M),{x_r} = {T^{ - 1}}(w_{tgt}^M) xadv=T−1(wclnM),xr=T−1(wtgtM) - 信息保留属性:由于DWI和IDWT的可逆性, ( w c l n M , w t g t M ) (w_{cln }^M, w_{tgt}^M) (wclnM,wtgtM)可以被保存在 ( x a d v , x r ) ({x_{adv}}, {x_r}) (xadv,xr), ( w c l n i − 1 , w t g t i − 1 ) (w_{cln }^{i - 1},w_{tgt}^{i - 1}) (wclni−1,wtgti−1)可以被保存在 ( w c ln i , w t g t i ) (w_{c\ln }^{i },w_{tgt}^{i}) (wclni,wtgti)
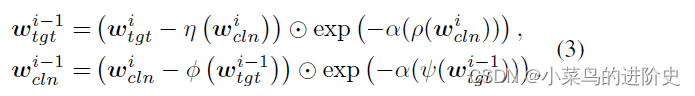
IIEM是完全可逆,输出图像 ( x a d v , x r ) ({x_{adv}},{x_r}) (xadv,xr)和输入图像 ( x c l n , x t g t ) ({x_{cln}},{x_tgt}) (xcln,xtgt)包含相同的信息。他们之间的联系可表示如下:
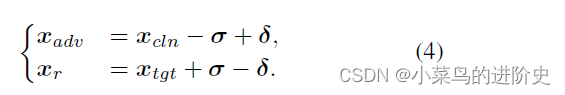
σ \sigma σ表示干净图像上丢弃的信息, δ \delta δ表示添加到干净图像上目标图像的判别信息。
目标图像选择和学习(Target image selection and learning)
- 选取最高置信类的图像:选取最高置信的图像作为目标图像可能包含大量目标类的无关信息,例如背景纹理和其他的类的信息。这将会影响攻击成功率和寻优过程;
- 通用对抗扰动:作者沿用该方法,利用优化后的通用对抗摄动作为目标图像,加快收敛速度;
- 目标图像学习模块:该模块学习分类器引导的目标图像,而不是使用固定的图像作为目标图像。目标图像被设置为一个可学习的变量,该变量用一个恒定的图像初始化(即所有像素设置为0.5),然后根据攻击分类器的梯度进行更新。这样,自适应生成的目标图像可以嵌入目标类的更多判别信息,从而辅助生成对抗样例。
学习细节
整个网络的总体损失定义如下:
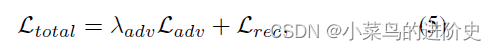
L a d v {\mathcal{L}_{adv}} Ladv表示对抗损失用于定位正确的优化方向和加速收敛速度,

实验:
- 数据集: ImageNet-1K
- 基准:PGD,CW, Drop, PerC-AL,SSAH
- 指标:感知性、攻击能力
- 受害者模型:ResNet50
- 感知性评估+目标攻击性能评估+鲁棒性评估(JPEG、bit-depth reduction、NRP and NRP_resG)+消融实验