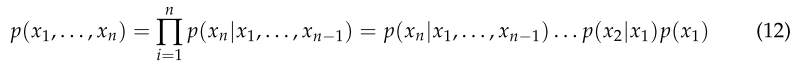前言

我们身边的人脸识别有车站检票,监控人脸,无人超市,支付宝人脸支付,上班打卡,人脸解锁手机。
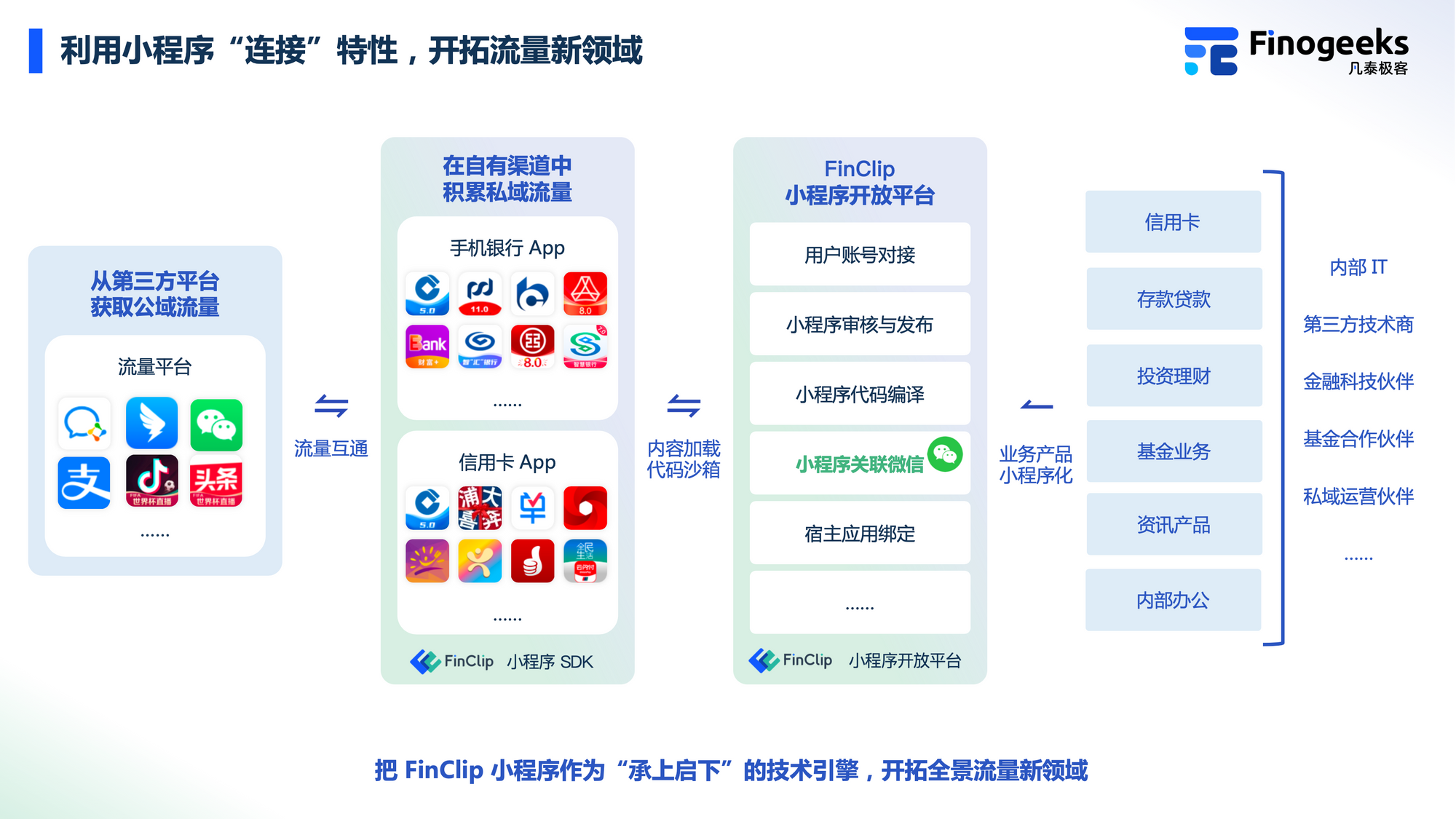
人脸检测是人脸识别系统组成的关键部分之一,其目的是检测出任意给定图片中的包含的一个或多个人脸,是人脸识别、表情识别等下游任务的基础。人脸识别是通过采集包含人脸的图像或视频数据,通过对比和分析人脸特征信息从而实现身份识别的生物识别技术,是人脸识别系统的核心组件。
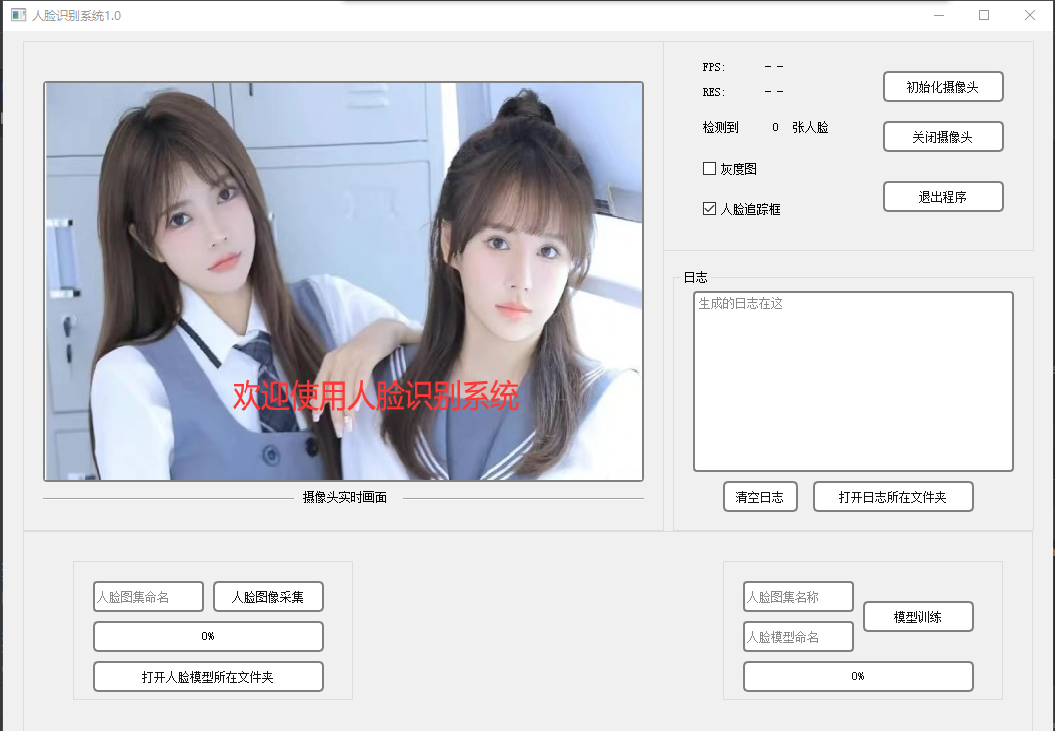
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍基于OpenCV的人脸识别和模型训练系统。适合新手学习,下面展示效果图:
效果图
大家也可以看看我之前写的文章:
基于OpenCV的人脸识别![]() https://broken.blog.csdn.net/article/details/129634466?spm=1001.2014.3001.5502
https://broken.blog.csdn.net/article/details/129634466?spm=1001.2014.3001.5502
基于OpenCV的图片和视频人脸识别![]() https://broken.blog.csdn.net/article/details/129760012?spm=1001.2014.3001.5502
https://broken.blog.csdn.net/article/details/129760012?spm=1001.2014.3001.5502
OpenCV 简介
OpenCV 的全称是 Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV 是由英特尔公司发起并参与开发,以 BSD 许可证授权发行,可以在商业和研究领域中免费使用。OpenCV 可用于开发实时的图像处理、计算机视觉以及模式识别程序。该程序库也可以使用英特尔公司的 IPP 进行加速处理。
OpenCV 用 C++语言编写,它的主要接口也是 C++语言,但是依然保留了大量的 C 语言接口。该库也有大量的Python、Java and MATLAB/OCTAVE(版本 2.5)的接口。这些语言的 API 接口函数可以通过在线文档获得。如今也提供对于 C#、Ch、Ruby、GO 的支持。
安装 OpenCV 模块
OpenCV 已经支持 python 的模块了,直接使用 pip 就可以进行安装,命令如下:
pip install opencv-pythonXML文件名称
我们安装完open-cv库之后,会在文件夹data中看到这样的一个文件夹haarcascades。该文件夹包含了所有 OpenCV 的人脸检测的XML 文件,这些可用于检测静止图像、视频和摄像头所得到图像中的人脸。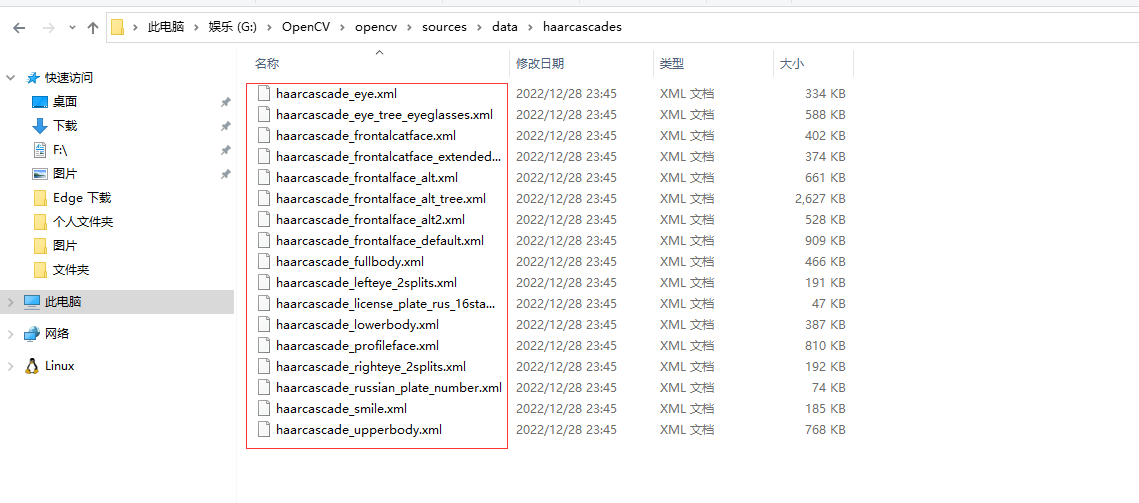
我们今天要用到的就是第一个,后面也会说到。
人脸检测器(默认):haarcascade_frontalface_default.xml
人脸检测器(快速 Harr):haarcascade_frontalface_alt2.xml
人脸检测器(侧视):haarcascade_profileface.xml
眼部检测器(左眼):haarcascade_lefteye_2splits.xml
眼部检测器(右眼):haarcascade_righteye_2splits.xml
嘴部检测器:haarcascade_mcs_mouth.xml
鼻子检测器:haarcascade_mcs_nose.xml
身体检测器:haarcascade_fullbody.xml
人脸检测器(快速 LBP):lbpcascade_frontalface.xml
部分核心代码
人脸检测与识别是机器视觉领域最热门的研究方向之一,本文详细介绍了人脸识别与模型训练系统。本系统实现了集人脸识别、训练人脸模型在内的多项功能:包括通过摄像头进行人脸的实时识别,博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至本文绑定的资源地址。
PS:也可以基于这个继续开发其他功能,什么本地照片识别训练,什么人脸管理功能等等,大家如果感兴趣可以研究。
导入库
本博文最难安装的库大概就是Open-cv库了,大家如果安装遇到了什么问题,可以看看我之前的文章,或者评论区留言,百度搜索都可以。
from PyQt5.QtWidgets import QApplication, QMainWindow, QMessageBox, QTableWidgetItem, QProgressBar
from PyQt5.QtGui import QImage, QPixmap, QTextCursor
from PyQt5.QtCore import QBasicTimer
import sys
import cv2
import numpy as np
from datetime import datetime
import numpy
import os
import random
from PIL import Image
from face_ui import Ui_FaceDetection
控件函数
在这里,有两个路径,一个是日志所在的路径,一个是打开人脸模型文件所在文件夹的路径,大家也可以自行修改这个路径,这个是相对路径,不会因为在不同盘而不能运行。
def initUI(self): # 控件回调函数(按钮绑定对应功能函数)self.pushButton_cameraon.clicked.connect(lambda: self.callcamera('on')) # 初始化摄像头self.pushButton_cameraoff.clicked.connect(lambda: self.callcamera('off')) # 关闭摄像头self.pushButton_openlogfolder.clicked.connect(lambda: self.openfolder('.\OpenCV_face')) # 打开日志文件所在文件夹(绝对路径)self.pushButton_opendbfolder.clicked.connect(lambda: self.openfolder('.\OpenCV_face\model_training\existed_model')) # 打开人脸模型文件所在文件夹(绝对路径)self.pushButton_exit.clicked.connect(self.closeevent) # 退出程序self.checkBox_trackingbox.setChecked(True) # 人脸追踪框默认勾选self.checkBox_grayscale.setChecked(False) # 灰度图框默认不选self.pushButton_catchfaces.setEnabled(False) # 人脸图像采集按钮默认不可选self.pushButton_catchfaces.clicked.connect(self.catch_faces) # 采集人脸图像self.pushButton_trainmodel.setEnabled(False) # 模型训练按钮默认不可选self.pushButton_trainmodel.clicked.connect(self.train_model) # 人脸模型训练self.lineEdit_faceimagessetname.setReadOnly(True) # 人脸图集命名默认不可用self.lineEdit_inputfacemodelname.setReadOnly(True) # 人脸图集输入默认不可用self.lineEdit_facemodelname.setReadOnly(True) # 人脸模型命名默认不可用# 进度条用self.timer1 = QBasicTimer()self.step1 = 0self.timer2 = QBasicTimer()self.step2 = 0下面展示了进度条的功能:

调用摄像头并显示画面
我们这里主要实现的功能就是调用本地的摄像头,大家也可以修改代码,调用手机的摄像头。这里的功能也就是我们效果图中显示画面的地方。
def callcamera(self, status): # 调用摄像头并显示画面、分辨率和帧率cap = cv2.VideoCapture(700) # 掉调用本地摄像头if cap.isOpened(): # 检测摄像头是否调用成功# 初始化摄像头后启用已下控件self.pushButton_catchfaces.setEnabled(True)self.pushButton_trainmodel.setEnabled(True)self.lineEdit_faceimagessetname.setReadOnly(False)self.lineEdit_inputfacemodelname.setReadOnly(False)self.lineEdit_facemodelname.setReadOnly(False)while True:# 手动关闭摄像头#!需要点击两次关闭摄像头键才能清空屏幕if status == 'off':cap.release()cv2.destroyAllWindows()# 摄像头关闭时重置以下控件self.pushButton_catchfaces.setEnabled(False)self.pushButton_trainmodel.setEnabled(False)self.lineEdit_faceimagessetname.setReadOnly(True)self.lineEdit_inputfacemodelname.setReadOnly(True)self.lineEdit_facemodelname.setReadOnly(True)self.label_showfps.setText(' --')self.label_showres.setText(' --')self.label_showfacesnum.setText('0')self.realTimeCaptureLabel.clear()breakret, frame = cap.read() # 读取图像(frame就是读取的视频帧,对frame处理就是对整个视频的处理)if not ret: # 没有帧了直接退出循环breakglobal height, width, depthheight, width, depth = frame.shape下面是关于摄像头操作的截图:

核心代码——人脸识别
这里就是最为核心的代码,人脸识别功能,我们在这个调用官方的模型,大家这里的路径要改,我的路径这里是:
C:\Users\18483\AppData\Local\Programs\Python\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml大家只要找到怎么python安装的位置就可以了,后面的路径都是一样的,大家可以用这个更方便自己找到对应的文件。
Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml下面,我们看看这一块的功能怎么实现,并简单介绍一下:
def face_detection(self, frame, trackornot): # 人脸检测face_detector = cv2.CascadeClassifier(r'C:\Users\18483\AppData\Local\Programs\Python\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml') # 调用官方的人脸数据模型faces = face_detector.detectMultiScale(frame) # 使用detectMultiScale函数检测frame中的人脸,并将人脸的坐标返回给facesif isinstance(faces, tuple): # 未检测到人脸返回tuple类型数据,用于人脸数量的判断self.label_showfacesnum.setText('0')return self.cv22image(frame)elif isinstance(faces, numpy.ndarray): # 检测到人脸返回numpy.ndarray类型数据,用于人脸数量的判断self.label_showfacesnum.setText('%s' % len(faces))cv2.waitKey(30)if trackornot == 'track': # 打开人脸追踪框for a, b, c, d in faces:cv2.rectangle(frame, pt1=(a, b), pt2=(a + c, b + d), color=[0, 0, 255],thickness=2) # 在已检测到的人脸上绘制一个红色方框return self.cv22image(frame)elif trackornot == 'not': # 取消人脸追踪框return self.cv22image(frame)这个函数的工作流程如下:
- 首先,它创建了一个CascadeClassifier对象,这个对象加载了一个已经训练好的人脸检测模型。这个模型文件是
haarcascade_frontalface_alt.xml,这是一个专门用于检测人脸的模型。 - 接着,它使用
detectMultiScale函数在输入的帧(frame)中检测人脸。这个函数会返回一个numpy数组,数组中的每个元素是一个二元组,表示一个人脸的位置和大小。 - 如果
detectMultiScale函数没有检测到任何人脸,那么它会返回一个tuple类型的值。在这种情况下,函数会更新显示人脸数量的标签,并返回未改变的帧。 - 如果检测到了人脸,那么它会返回一个numpy数组。在这种情况下,函数会更新显示人脸数量的标签,然后根据
trackornot参数来决定是否在检测到的人脸周围绘制一个红色的矩形框。如果trackornot为'track',那么会在每个人脸周围绘制矩形框,并返回处理后的帧;如果trackornot为'not',那么直接返回未改变的帧。
这个函数的功能就是进行人脸检测,并根据需要决定是否在检测到的人脸周围绘制矩形框。
格式转化
在这里,我们还要调用一个函数,把cv2生成的画面转化为pyqt支持的格式并返回。
def cv22image(self, frame): # 将cv2生成的画面转化为pyqt支持的格式并返回frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB, frame)image = QImage(frame.data, width, height, width * depth, QImage.Format_RGB888)cv2.waitKey(30)return image核心代码——人脸采集功能
def catch_faces(self): # 人脸采集 #!捕获到的画面中无论有没有人脸都会采集,建议改为有人脸捕获,无人脸跳过atlas_name = self.lineEdit_faceimagessetname.text() # 返回给atlas_name的值是人脸图像集名,不能为中文# 判断保存路径是否存在images_path = './OpenCV_face/model_training/collected_images/%s/' % atlas_nameif os.path.exists(images_path):passelse:os.mkdir(images_path)if len(atlas_name) == 0:QMessageBox.information(self, 'Info', '请为人脸图像集命名', )passelse:cap = cv2.VideoCapture(700) # 调用本地摄像头num = 1self.logOutput('Info:人脸图像[%s]采集开始' % atlas_name)这段代码的功能是进行人脸采集。它首先从界面获取人脸图像集的名称(atlas_name),然后检查保存路径是否存在,如果不存在则创建该路径。接下来,如果atlas_name为空,它会弹出一个信息框提示用户为人脸图像集命名。如果atlas_name不为空,它会打开本地摄像头并开始采集人脸图像。
模型训练
接下来,就是核心代码模型训练,把我们之前采集的照片训练成我们自己的模型。
def train_model(self): # 人脸模型训练import time# 设置控件input_atlas_name = self.lineEdit_inputfacemodelname.text() # 获取需要训练的人脸图集的名称facemodel_name = self.lineEdit_facemodelname.text() # 获取人脸模型的名称if len(input_atlas_name) == 0:QMessageBox.information(self, 'Info', '请输入人脸图集名称')passelif len(facemodel_name) == 0:QMessageBox.information(self, 'Info', '请为人脸模型命名')passelse:# 输入路径ids = []faces_samples = []try:self.logOutput('Info:人脸模型[%s]训练开始' % facemodel_name)# 进度条for i in range(1, 101):self.step2 = iself.progressBar_trainmodel.setValue(i)if i == 101:self.timer2.stop()breaktime.sleep(0.2)atlas_path = './OpenCV_face/model_training/collected_images/%s/' % input_atlas_name # 需要训练的人脸图集的路径images_paths = [os.path.join(atlas_path, i) for i in os.listdir(atlas_path)]face_detector = cv2.CascadeClassifier(r"C:\Users\18483\AppData\Local\Programs\Python\Python39\Lib\site-packages\cv2\data\haarcascade_frontalface_alt.xml")

日志
我们在此版本中还加入了日志的功能,我们把它保存在了一个log.txt文件中。
def logOutput(self, log): # 日志time = datetime.now().strftime('[%Y/%m/%d %H:%M:%S]') # 获取当前系统时间log = time + ' ' + log + '\n'with open('./OpenCV_face/log.txt', 'a+') as f: # 将日志写入本地日志文件f.write(log)self.textBrowser_showlog.moveCursor(QTextCursor.End)self.textBrowser_showlog.insertPlainText(log) # 输出日志self.textBrowser_showlog.ensureCursorVisible() # 自动滚屏下面是该功能区域的截图:
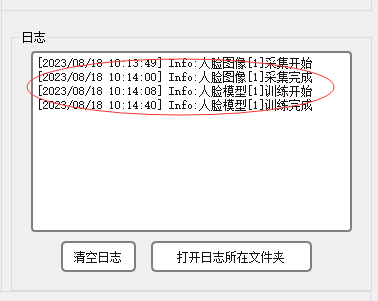
打开文件夹
def openfolder(self, path): # 打开文件夹folder_path = path# 异常捕获,当要打开的文件夹路径不存在时输出报错日志try:os.startfile(folder_path)except Exception as error:self.logOutput('Error:打开文件夹失败,请检查路径(%s)是否存在' % path)退出程序
def closeevent(self, cap): # 关闭并退出程序answer = QMessageBox.question(self, '退出', '确定要退出吗?', QMessageBox.Yes | QMessageBox.No, QMessageBox.No)if answer == QMessageBox.Yes:cv2.destroyAllWindows()app.quit()else:passface_ui
这个是我们最后页面的UI代码,博主不才,可能不是很好看,大家也可以尝试优化这些代码。下面给大家展示UI的部分代码,由于篇幅有限。
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_FaceDetection(object):def setupUi(self, FaceDetection):FaceDetection.resize(1050, 820)FaceDetection.setObjectName("FaceDetection")self.groupBox_facedetect = QtWidgets.QGroupBox(FaceDetection)self.groupBox_facedetect.setGeometry(QtCore.QRect(20, 10, 641, 491))self.groupBox_facedetect.setTitle("")self.groupBox_facedetect.setAlignment(QtCore.Qt.AlignCenter)self.groupBox_facedetect.setObjectName("groupBox_facedetect")self.realTimeCaptureLabel = QtWidgets.QLabel(self.groupBox_facedetect)self.realTimeCaptureLabel.setGeometry(QtCore.QRect(20, 40, 601, 401))self.realTimeCaptureLabel.setStyleSheet("border: 2px solid grey; border-radius: 4px; color: rgb(20,20,20); background-color: #FFFFFF; text-align: center;}QProgressBar::chunk {background-color: rgb(100,200,200); border-radius: 10px; margin: 0.1px; width: 1px;")self.realTimeCaptureLabel.setFrameShape(QtWidgets.QFrame.Box)self.realTimeCaptureLabel.setAlignment(QtCore.Qt.AlignCenter)self.realTimeCaptureLabel.setObjectName("realTimeCaptureLabel")self.label_realtimescreen = QtWidgets.QLabel(self.groupBox_facedetect)self.label_realtimescreen.setGeometry(QtCore.QRect(280, 440, 91, 31))self.label_realtimescreen.setObjectName("label_realtimescreen")self.line_2 = QtWidgets.QFrame(self.groupBox_facedetect)self.line_2.setGeometry(QtCore.QRect(380, 450, 241, 16))self.line_2.setFrameShape(QtWidgets.QFrame.HLine)self.line_2.setFrameShadow(QtWidgets.QFrame.Sunken)self.line_2.setObjectName("line_2")self.line_3 = QtWidgets.QFrame(self.groupBox_facedetect)self.line_3.setGeometry(QtCore.QRect(20, 450, 251, 16))self.line_3.setFrameShape(QtWidgets.QFrame.HLine)self.line_3.setFrameShadow(QtWidgets.QFrame.Sunken)self.line_3.setObjectName("line_3")界面展示
这个我们软件的主界面:




下载链接
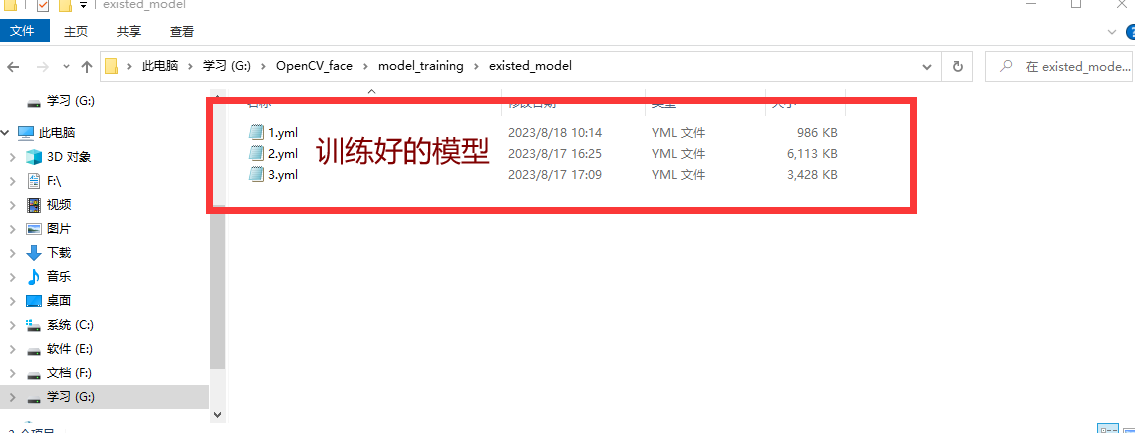
若您想获得博文中涉及的实现完整全部程序文件(包括图片,py, UI文件等,如下图),这里已打包上传至博主的CSDN下载资源。

注意:本资源已经过调试通过,下载后可通过Pycharm运行;运行界面的主程序为face_decognition.py。为确保程序顺利运行,请配置Python版本:3.9,或以上版本。我们这里的文件夹默认在代码的路径下。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。