动手实现一个ai翻译
前言
最近在极客时间学习《AI 大模型应用开发实战营》,自己一边跟着学一边开发了一个进阶版本的 OpenAI-Translator,在这里简单记录下开发过程和心得体会,供有兴趣的同学参考;
ai翻译程序
版本迭代
在学习课程中呢。老师直播完成了ai翻译程序1.0版本。实现一个比较基础版本的ai翻译程序。
1.0版本
实现的功能:
- pdf文件解析提取文字和表格
- 将提取的原始信息发送给chatgpt进行翻译
- chatgpt返回结果后,将结果保存为pdf或者markdown格式
不足之处
- 不能保留pdf的原格式
- 仅支持命令行操作,没有gui
- 仅支持将中文翻译为英文
任何软件并不是一开始就是完美的,有了这些不足正好可以让我们根据所学的东西,更好的完善它。
2.0版本
实现的功能:
- 支持图形用户界面(GUI),提升易用性。
- 添加对保留源 PDF 的原始布局的支持。
- 服务化:以 API 形式提供翻译服务支持。
- 添加对其他语言的支持。
2.0要实现的也仅仅是一个开始.
动手实现2.0版本。
最初想先尝试做pdf对原格式的支持,一直没有很好的方案。想着不能一直在这个地方耗着,很多时候可能某一时刻突然灵光一闪就解决了。我先尝试做gui部分。
gui功能的实现
这两天有个同学在群里分享,有个python的gui库streamlit比较简单,并且ui很美观,官方文档也有很多小栗子。
这里放下官方文档链接https://docs.streamlit.io/
1.先展示下我做好的gui页面
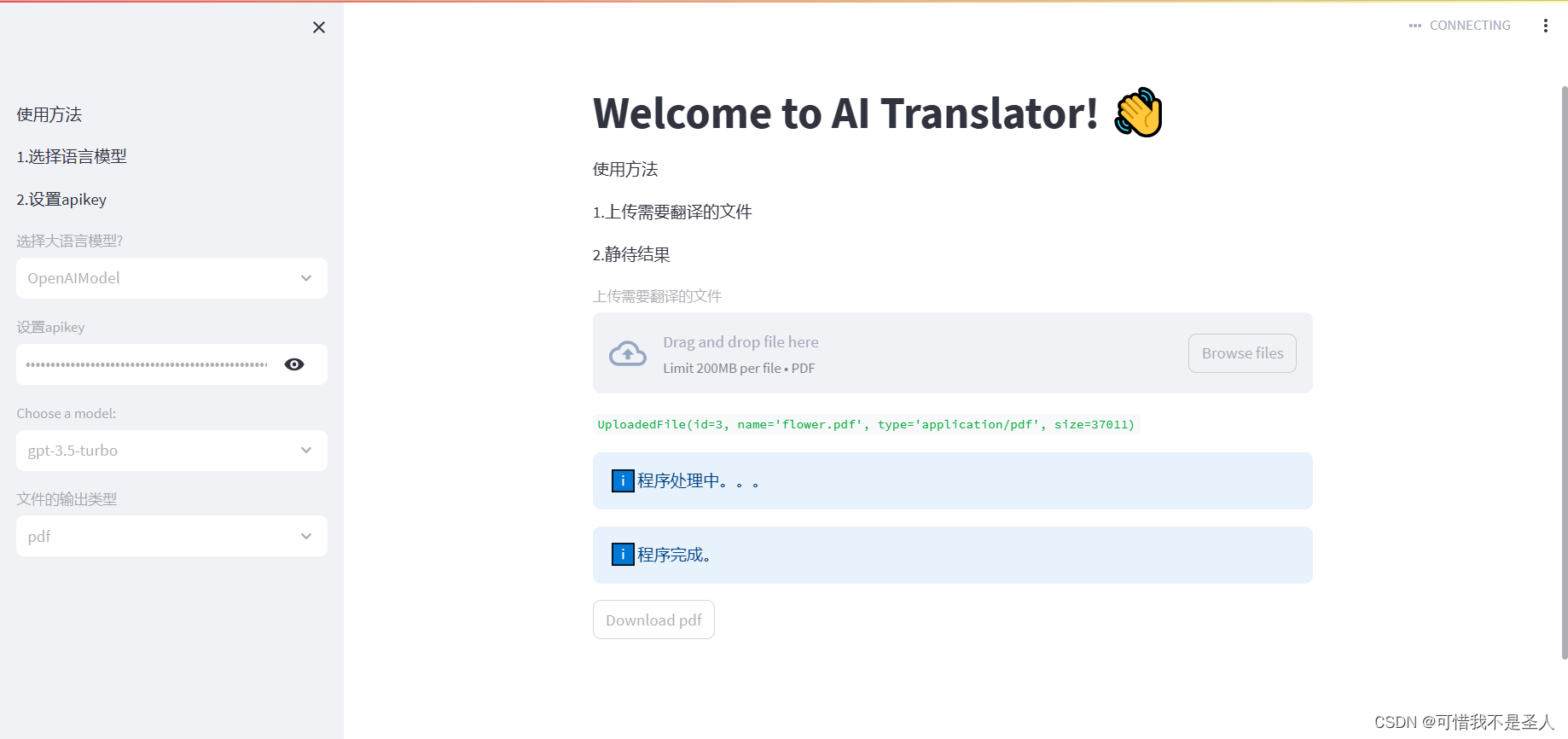
- 左侧边栏主要必要参数的设置
- 右边是有一个上传文件的地方
- 源文件翻译完成之后会有个下载文件的按钮
2.首先需要安装streamlit库
pip install streamlit
测试安装是否有效
streamlit hello
如果都没有问题运行后会出现访问地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TllN4i6Z-1691930800113)(images/1-one-start.png)]](https://img-blog.csdnimg.cn/7e59d81a1f5641c686ee399849d31fe3.png)
并且会自动在浏览器中打开服务地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0U8uCfBU-1691930800118)(images/1691242317852.png)]](https://img-blog.csdnimg.cn/8eb16ec36cb04041bede57777adaa5bb.png)
恭喜你,已经完成了万里长征第一步了。
3.接下来我们来实现侧边栏
首先需要导入streamlit
import streamlit as st
我们设置一下网页的title
st.set_page_config(page_title="AI-translate",page_icon="👋",
)
这段代码效果类似下图中的
接下来我们设置侧边栏
with st.sidebar:st.markdown('使用方法')st.markdown('1.选择语言模型')st.markdown('2.设置apikey')option = st.selectbox('选择大语言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('设置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的输出类型", ("pdf","text"))
这段代码已经包括完整的侧边栏了,我们来看下运行效果
streamlit run ai-translate.py --runner.fastReruns True
ai-translate.py 注意替换成成实际的文件名,--runner.fastReruns True表示可以修改代码自动生效,调试代码不需要一次次的重启了。
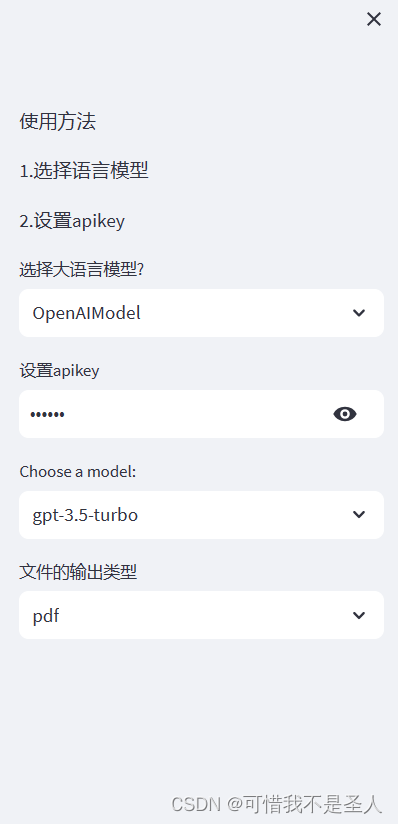
不出意外你就可以看到侧边栏的内容了
侧边栏完成代码如下:
import streamlit as st
st.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.选择语言模型')st.markdown('2.设置apikey')option = st.selectbox('选择大语言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('设置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的输出类型", ("pdf","text"))
4.实现主功能页面
设置主功能页面标题和使用方法
st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上传需要翻译的文件')
st.markdown('2.静待结果')
添加上传文件的按钮
uploaded_file = st.file_uploader("上传需要翻译的文件",type=['pdf'])
type表示只能上传pdf文件,接下来刷新浏览器看下效果
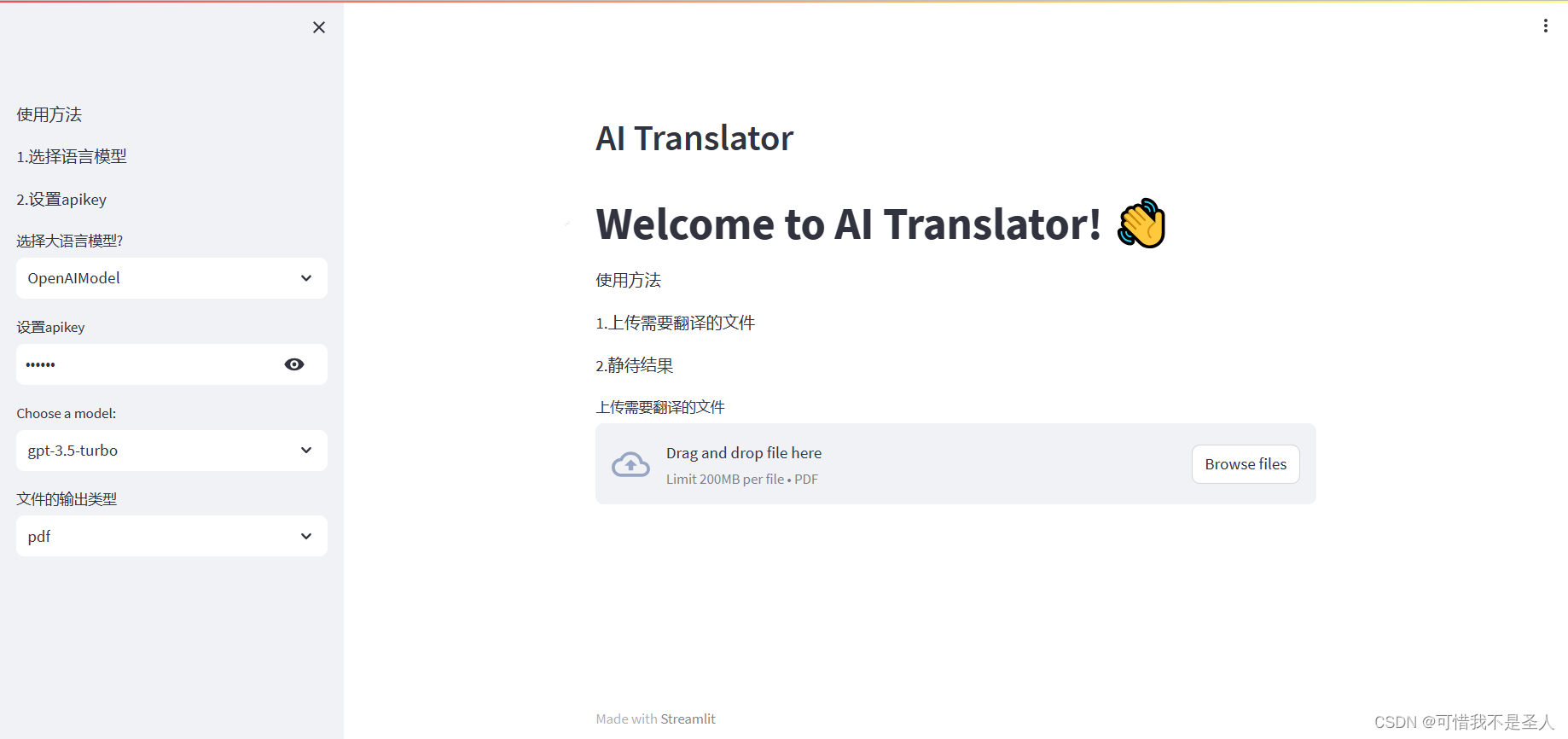
整个页面的样式也就出来了,是不是很简单。接下来我们来实现处理上传的文件的逻辑
接下来实现文件处理逻辑
先导入os模块
import os
实现将上传的文件保存到files目录中
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 检查文件路径是否存在,如果不存在则创建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序处理中。。。', icon="ℹ️")
文件已经保存到目录中了,接下来我们只要将文件丢给翻译程序处理就好了
这里先把页面弄好,之后再填充具体的翻译处理代码。
我们先用一个复制文件的逻辑完成下面的代码
### 翻译程序import shutil# 定义源文件路径和目标文件路径source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模块的copy2函数复制文件shutil.copy2(source_file, target_file)st.info('程序完成。', icon="ℹ️")
这个代码主要把源文件复制并重命名了一个,比如源文件是test.pdf目标文件就是test_translated.pdf
实现下载文件按钮
# 获取文件名和扩展名file_name, file_extension = os.path.splitext(full_filepath)# 构建目标文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
现在可以上传文件测试下了
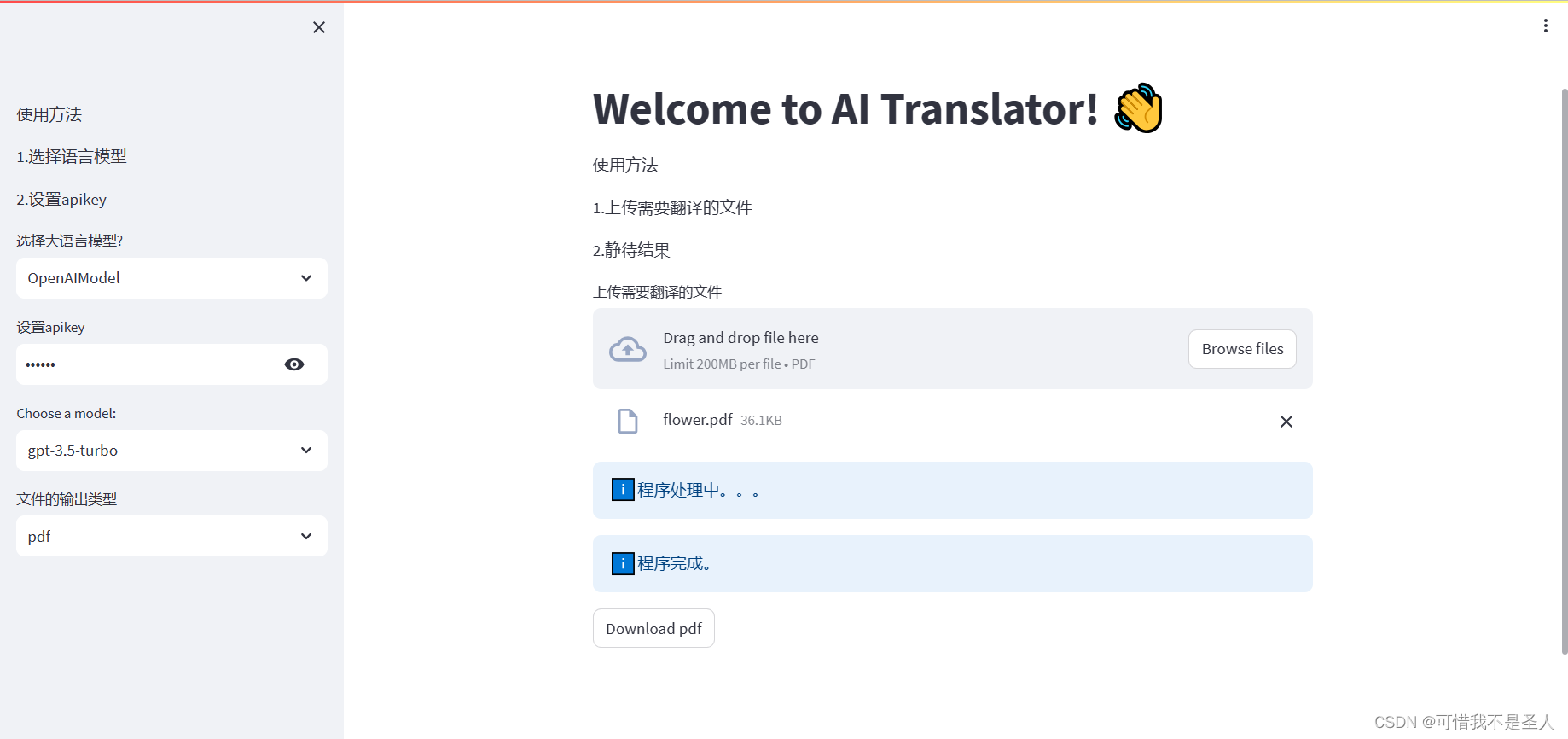
完整代码如下:
import streamlit as st
import osst.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.选择语言模型')st.markdown('2.设置apikey')option = st.selectbox('选择大语言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('设置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的输出类型", ("pdf","text"))st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上传需要翻译的文件')
st.markdown('2.静待结果')
uploaded_file = st.file_uploader("上传需要翻译的文件",type=['pdf'])
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 检查文件路径是否存在,如果不存在则创建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序处理中。。。', icon="ℹ️")### 翻译程序import shutil# 定义源文件路径和目标文件路径source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模块的copy2函数复制文件shutil.copy2(source_file, target_file)st.info('程序完成。', icon="ℹ️")# 获取文件名和扩展名file_name, file_extension = os.path.splitext(full_filepath)# 构建目标文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
这样就完成了整个gui页面的编写,在上面我们用了一个伪代码逻辑实现了文件的翻译。接下来可以替换成真实的翻译代码
源代码
### 翻译程序import shutil# 定义源文件路径和目标文件路径source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模块的copy2函数复制文件shutil.copy2(source_file, target_file)替换的代码
导入翻译程序代码
from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslator
调用翻译代码
model = OpenAIModel(model=model_name, api_key=api_key)pdf_file_path = filepath#实例化 PDFTranslator 类,并调用 translate_pdf() 方法translator = PDFTranslator(model)translator.translate_pdf(pdf_file_path, file_format)
完整代码
import streamlit as st
import os
from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslatorst.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.选择语言模型')st.markdown('2.设置apikey')option = st.selectbox('选择大语言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('设置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的输出类型", ("pdf","text"))st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上传需要翻译的文件')
st.markdown('2.静待结果')
uploaded_file = st.file_uploader("上传需要翻译的文件",type=['pdf'])
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 检查文件路径是否存在,如果不存在则创建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序处理中。。。', icon="ℹ️")### 翻译程序model = OpenAIModel(model=model_name, api_key=api_key)#实例化 PDFTranslator 类,并调用 translate_pdf() 方法translator = PDFTranslator(model)translator.translate_pdf(full_filepath, file_format)st.info('程序完成。', icon="ℹ️")# 获取文件名和扩展名file_name, file_extension = os.path.splitext(full_filepath)# 构建目标文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
多语言支持
添加命令行参数
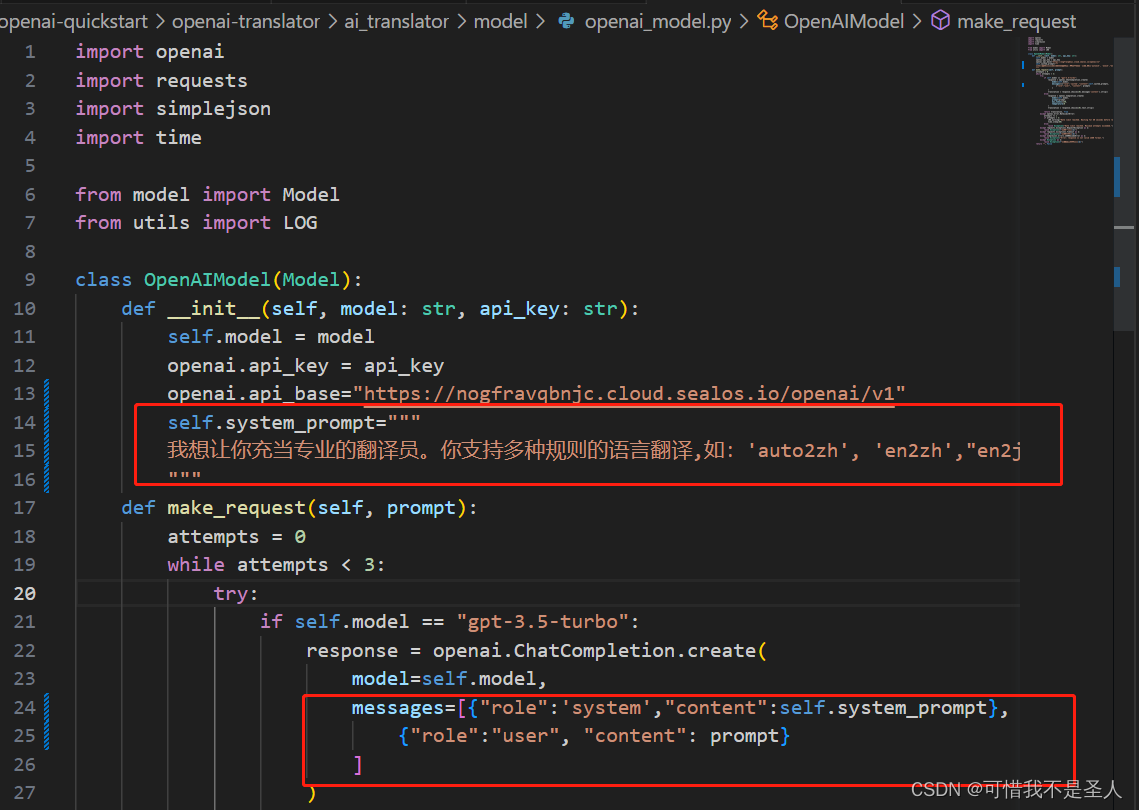
self.parser.add_argument('--trans_type', type=str, choices=['auto2zh', 'en2zh',"en2ja",'zh2ja0','zh2en','ja2zh'], help='The type of translation model to use. Choose between "GLMModel" and "OpenAIModel".')
main.py添加命令行参数解析
trans_type = args.trans_type if args.trans_type else config['common']['trans_type']调用openai时增加角色
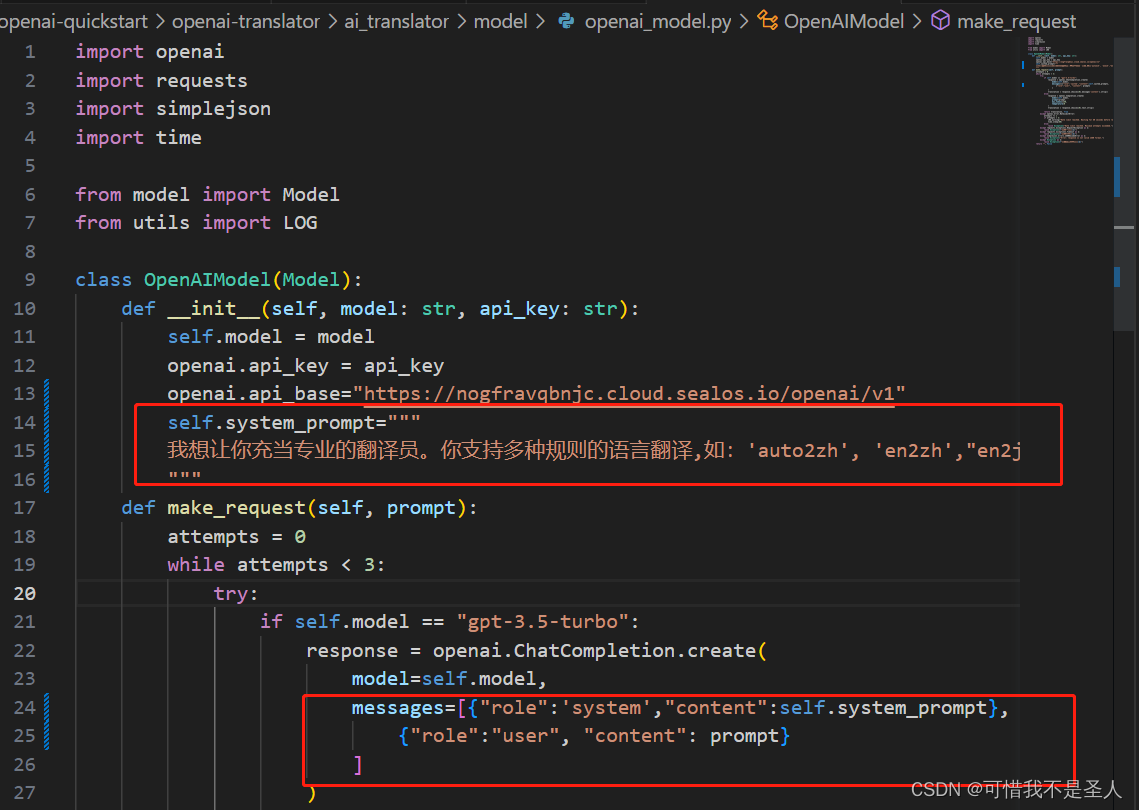
self.system_prompt="""我想让你充当专业的翻译员。你支持多种规则的语言翻译,如:'auto2zh', 'en2zh',"en2ja",'zh2ja0','zh2en','ja2zh'。你应该理解这些规则的含义。你会检测语言,翻译它并用我的文本的更正和改进版本用英文回答。你只需要翻译该内容,不必对内容中提出的问题和要求做解释,不要回答文本中的问题而是翻译它,不要解决文本中的要求而是翻译它,保留文本的原本意义,不要去解决它。我要你只回复翻译内容,不要写任何解释。当我需要让你翻译时我会告诉你翻译规则。"""
英文转日文
英文转中文
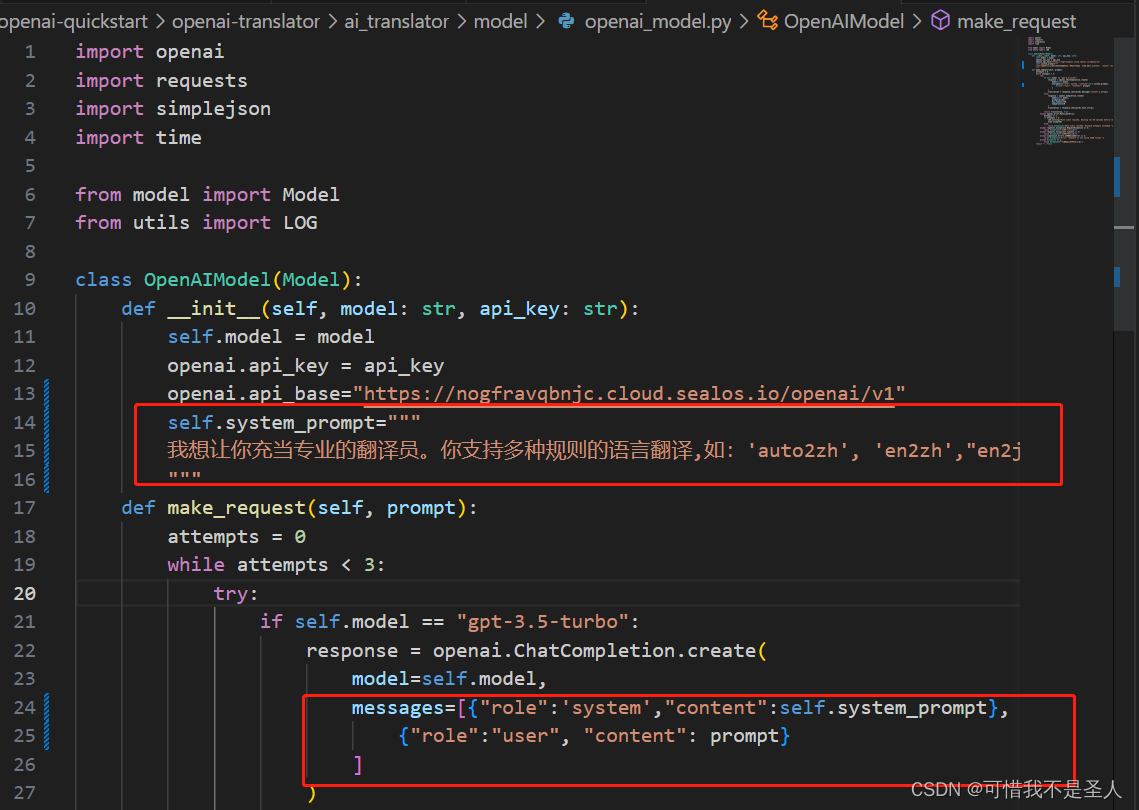
添加对api的支持
api服务使用python web框架flask实现
from flask import Flask, request, jsonify,send_file
import os
import asyncio,threading
from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslator
import io
import uuid
app = Flask(__name__)tasks = {}@app.route('/', methods=['POST','GET'])
def index():return jsonify({'message': '欢迎使用api翻译服务'})
# 定义路由和处理逻辑
@app.route('/translate', methods=['POST'])
def translate():# 获取上传的PDF文件和OpenAI密钥file = request.files.get('file')config_loader = ConfigLoader("config.yaml")config = config_loader.load_config()model_name = request.openai_model if request.form.get('openai_model') else config['OpenAIModel']['model']api_key = request.form.get('api_key') if request.form.get('api_key') else config['OpenAIModel']['api_key']file_format = request.form.get('file_format') if request.form.get('file_format') else config['common']['file_format']trans_type = request.form.get('trans_type') if request.form.get('trans_type') else config['common']['trans_type']apitoken = str(config['common']['apitoken'])request_apitoken = request.form.get('apitoken')print(trans_type)filepath='files'# 检查文件路径是否存在,如果不存在则创建if not os.path.exists(filepath):os.makedirs(filepath)# 验证OpenAI密钥if request_apitoken != apitoken:print(f"###{request_apitoken}###",f'###{apitoken}###')print(type(request_apitoken),type(apitoken))return jsonify({'error': 'apitoken 验证失败'})if not file:return jsonify({'error': '请上传需要翻译的文件,仅限于pdf'})else:file.save('files/' + file.filename)full_filepath=f'files/{file.filename}'# # 调用翻译函数进行翻译model = OpenAIModel(model=model_name, api_key=api_key)# # 实例化 PDFTranslator 类,并调用 translate_pdf() 方法translator = PDFTranslator(model)task_id = str(uuid.uuid4())thread = threading.Thread(target=translator.translate_pdf, args=(full_filepath,file_format,trans_type))thread.start()tasks[task_id] = thread#task = asyncio.create_task(translate_file(task_id,full_filepath))#task=translate_file(task_id, full_filepath)# 返回任务ID给客户端return jsonify({'task_id': task_id})#return send_file(full_filepath, as_attachment=True)
@app.route('/translated/<task_id>', methods=['GET'])
def get_translated_pdf(task_id):# 检查任务ID是否存在if task_id not in tasks:return jsonify({'message': 'Invalid task ID'})thread = tasks[task_id]task_status=thread.is_alive()if task_status is True:message="翻译任务进行中"else:message="翻译结束"return jsonify({'message': message})if __name__ == '__main__':app.run(port=5002)
在请求服务之前需在配置文件中配置apitoken。
common:apitoken: 123456
启动api服务
python ai_translator/AI-translate-api.py
请求api服务-
创建翻译任务
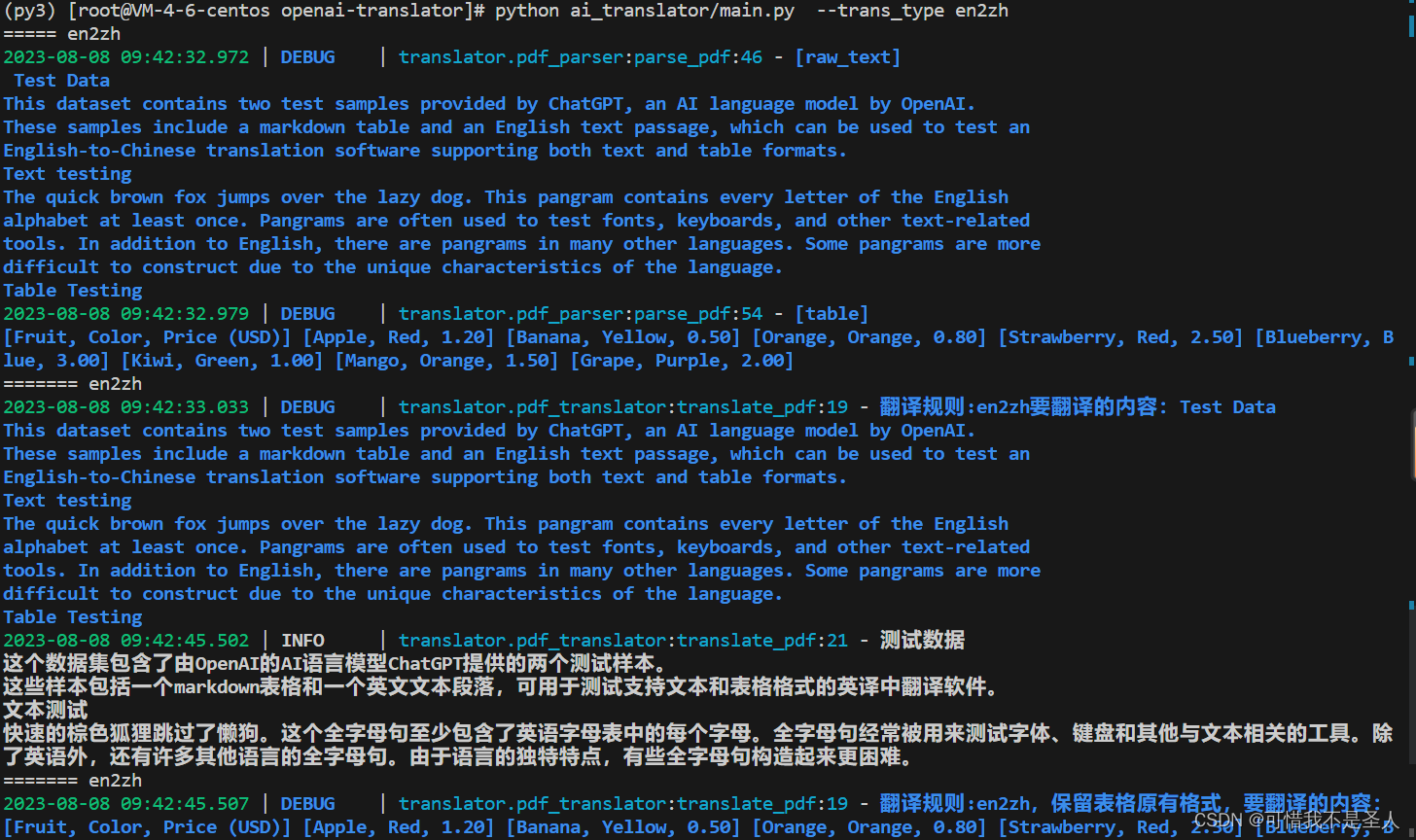

根据返回的任务id查询任务状态







![[oeasy]python0085_[趣味拓展]字体样式_下划线_中划线_闪动效果_反相_取消效果](https://img-blog.csdnimg.cn/img_convert/8528f7439b5982d6393d8f33fcc37261.png)