引言
这是论文Glancing Transformer for Non-Autoregressive Neural Machine Translation的笔记。
传统的非自回归文本生成速度较慢,因为需要给定之前的token来预测下一个token。但自回归模型虽然效率高,但性能没那么好。
这篇论文提出了Glancing Transformer,可以只需要一次解码,并行地文本生成。并且效率不输于Transformer这种自回归方法。
简介
Transformer变成了最广泛使用的机器翻译架构。尽管它的表现很好,但Transformer的解码是低效的因为它采用序列自回归因子分解来建模概率,见下图1a。最近关于非自回归Transformer(non-autoregressive transformer,NAT)的研究的方向是并行解码目标token来加速生成。然而,纯粹(vanilla)的NAT在翻译质量上仍然落后于Transformer。NAT假设给定源句子后目标token是条件独立的(图1b)。作者认为NAT的条件独立假设阻碍了学习目标句子中单词的相关性(依赖关系)。这种相关性是至关重要的,通常Transformer通过从左到右解码来显示地捕获它。
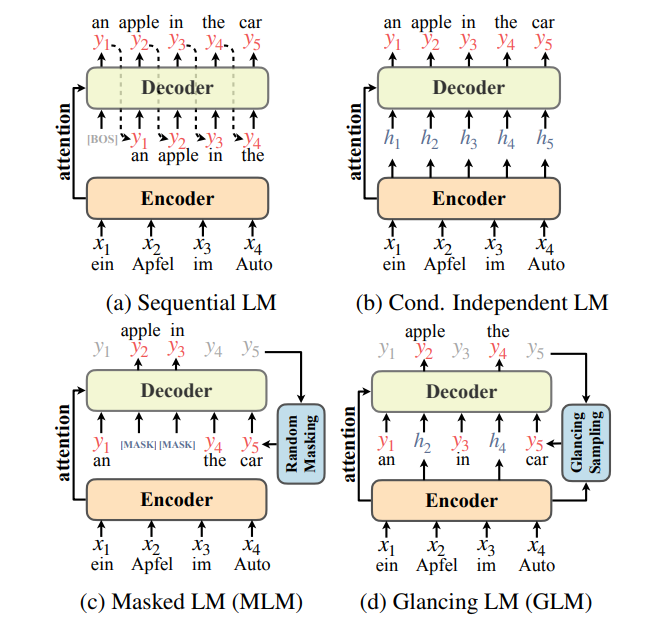
也有一些补救方法提出了来捕获单词的相关性,同时保留并行解码。他们的共同思想是通过迭代解码目标token,每次解码都使用掩码语言模型进行训练(图1c)。因为这些模型需要多次解码,它的生成速度显著低于纯粹的Transformer。而仅单次生成的方法表现比自回归Transformer差很多。