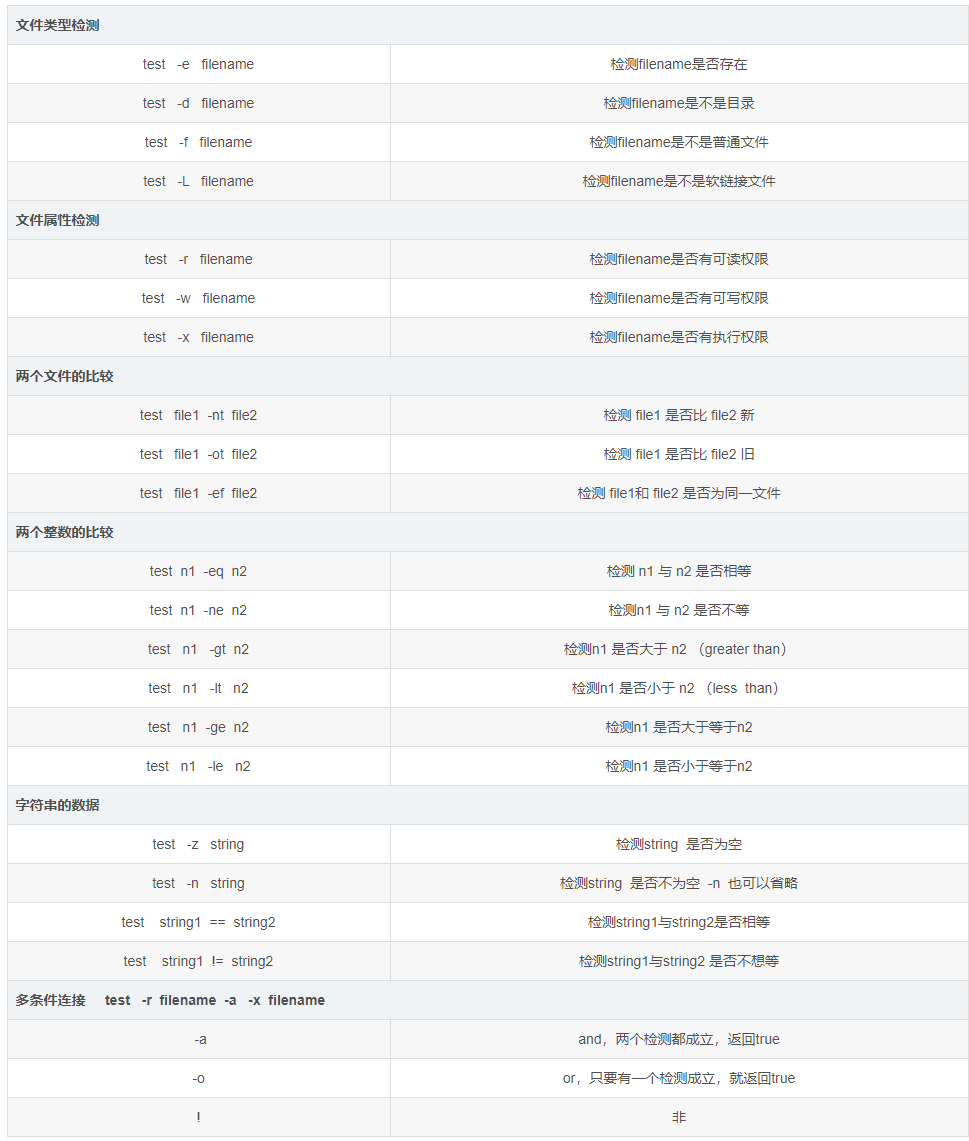
正则中的三种模式,贪婪匹配、非贪婪匹配和独占模式。
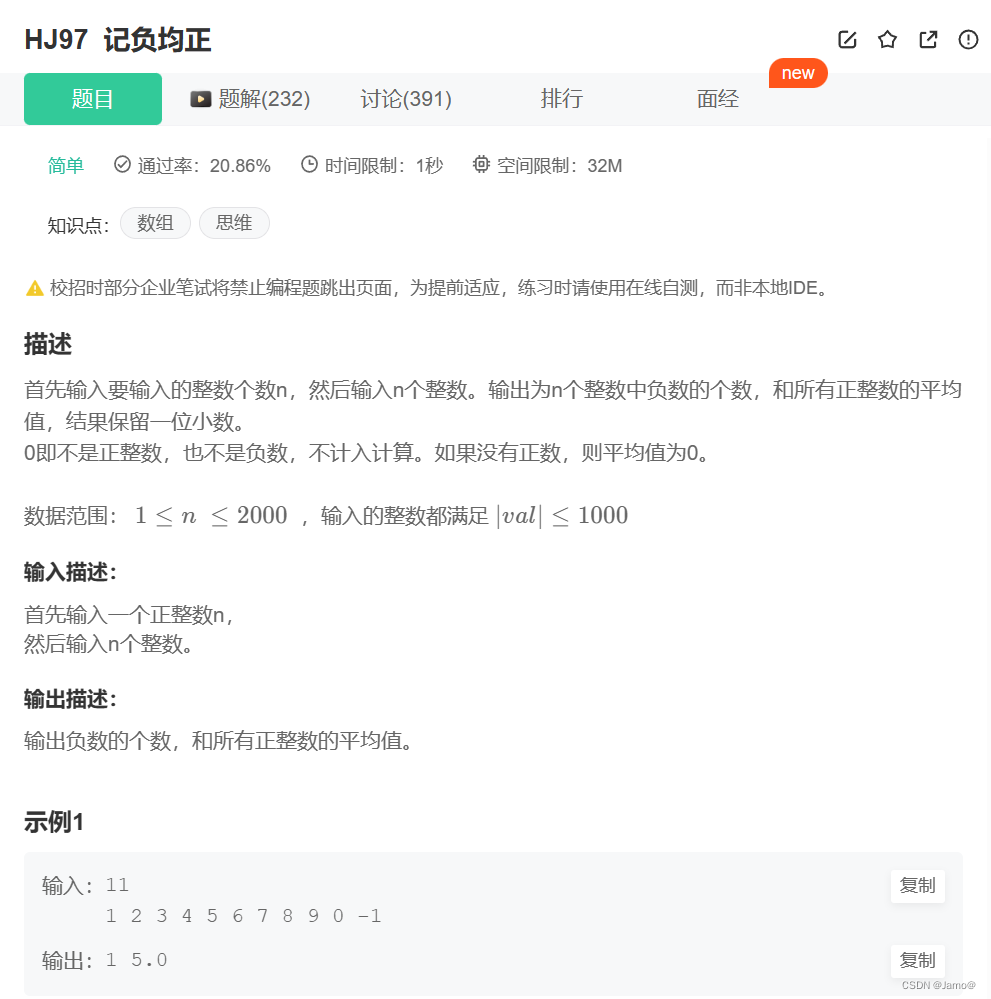
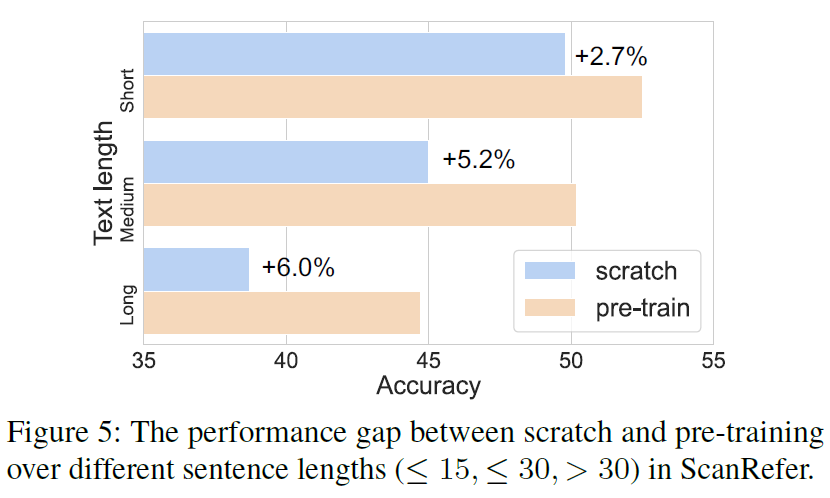
在这 6 种元字符中,我们可以用 {m,n} 来表示 (*)(+)(?) 这 3 种元字符:
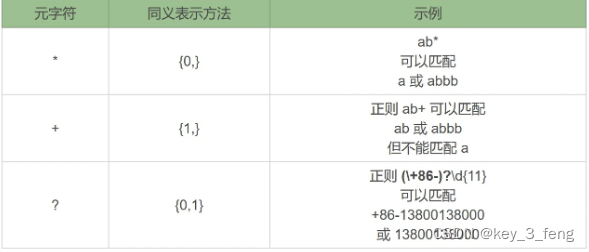
贪婪模式,简单说就是尽可能进行最长匹配。非贪婪模式呢,则会尽可能进行最短匹配。正是这两种模式产生了不同的匹配结果。
贪婪匹配(Greedy)
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
非贪婪匹配(Lazy)
如何将贪婪模式变成非贪婪模式呢?我们可以在量词后面加上英文的问号 (?),正则就变成了 a*?
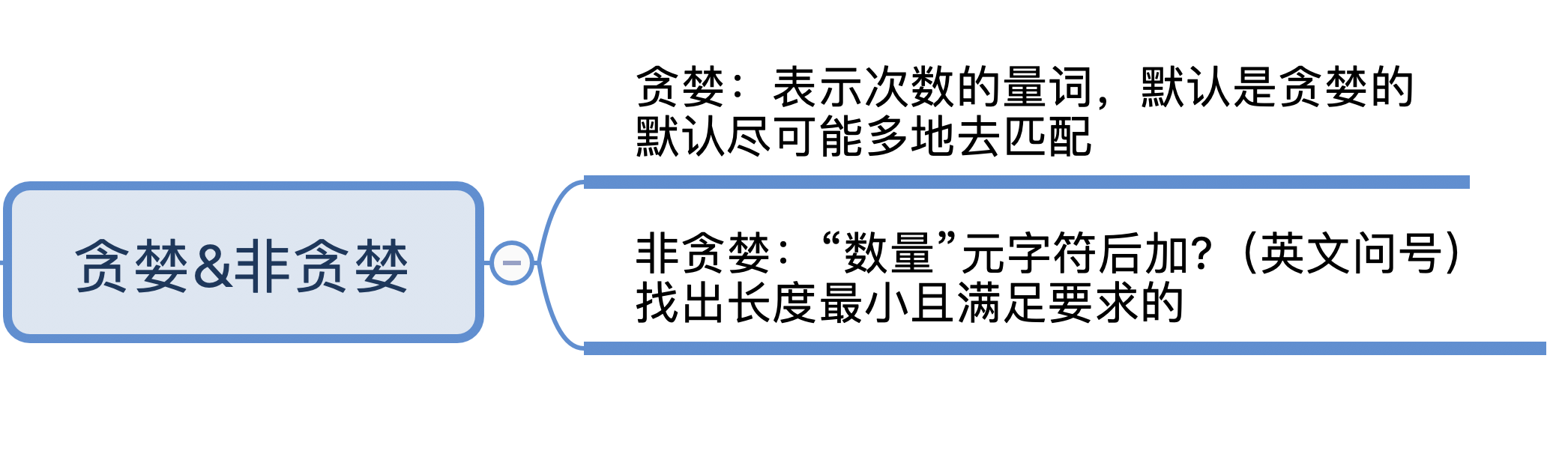
独占模式(Possessive)
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
如果你用 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯,这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容,匹配失败。如果是贪婪模式 a{1,3} 或非贪婪模式 a{1,3}? 都可以匹配上。
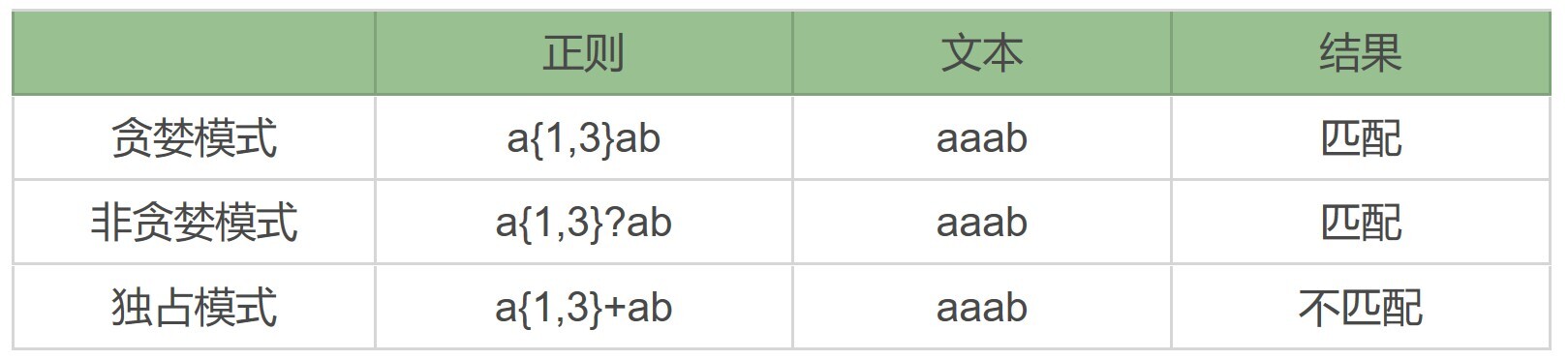
正则中量词默认是贪婪匹配,如果想要进行非贪婪匹配需要在量词后面加上问号。贪婪和非贪婪匹配都可能会进行回溯,独占模式也是进行贪婪匹配,但不进行回溯,因此在一些场景下,可以提高匹配的效率,具体能不能用独占模式需要看使用的编程语言的类库的支持情况,以及独占模式能不能满足需求。
此文章为8月Day19学习笔记,内容来源于极客时间《正则表达式入门课》,推荐该课程。