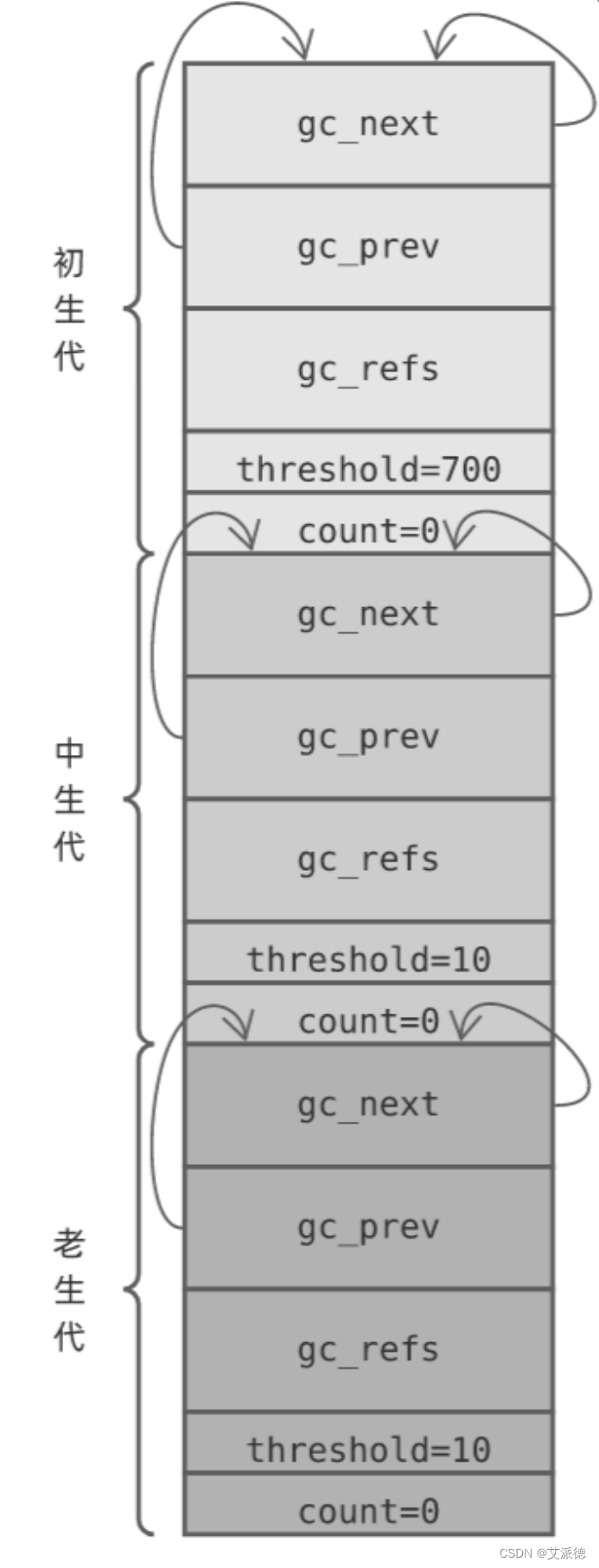
计算机的语言:汇编指令集
也就是指令集。本书主要介绍 MIPS 指令集。
汇编指令
算数运算:
add a,b,c # a=b+c
sub a,b,c # a=b-c
MIPS 汇编的注释是 # 号。
由于MIPS中寄存器大小32位,是基本访问单位,因此也被称为一个字 word。MIPS汇编有32个寄存器。寄存器数量是与指令集可行性相关的,不是说摩尔定律越多越好。
接下来把上述抽象字母替换为寄存器表示:
# f=(g+h)-(i+j)
# f,g,h,i,j in s0,s1,s2,s3,s4add $t0,$s1,$s2
add $t1,$s3,$s4
sub $s0,$t0,$t1
MIPS汇编中寄存器用$+两个字符表示。
然后是从存储器中取数据的指令。
# g=h+A[8]
# g,h in s1,s2
# A address in s3
lw $t0,8($s3) # 用这种方式拿出来
add $s1,$s2,$t0
MIPS采用大端编址,也就是高字节存入低地址。
最低有效位:最右边的位,也就是 MIPS[31:0]的0位。
最高有效位:31位。
如果按字节寻址,正确的偏移量是 offset*4.
比如:计算A[12]=h+A[8],h在s2,A在s3中。
lw $t0,32($s3)
add $t0,$s2,$t0
sw $t0,48($s3) # 写回
常数操作:比如 s1+AddrConstant4 里存储了常量4,我们可以 lw $t0,AddConstant4($s1) 把常数取出来。
或者,直接使用立即数。
addi $s3,$s3,4 #加立即数需要用 addi
立即数运算速度快且能耗低。
$zero 寄存器存的是常数0,因为比如数据传送指令可以看做是加0指令,这样可以简化数据传送指令和加法指令合并。
根据使用频率定义一些常数是加速大概率事件的方法之一。
数字存储分为无符号数和补码表示的有符号数,具体算法也不再详细展开~
指令组成
t0-t7是寄存器8-15,s0-s7是寄存器16-23.
比如指令 add $t0,$s1,$s2 机器语言表示(十进制)为:

首先开头的0字段和结尾的32字段代表 add 指令。
17 18是两个源操作数s1 s2。
8是目的操作数t0.
第五个字段没用到置0.
当然底层表示是32位二进制数。MIPS 指令都是32位。

op:操作码。
rs rt:两个源操作数寄存器。
rd:目的操作数寄存器。
shamt:位移量。
funct:功能码,op的变体比如 addi。
但是这种指令格式的缺陷在于长度有时候不够,比如我们要处理的地址或者立即数用5位表示不了(5位归根结底只能表示32个数)。
因此引入了I型指令(用于立即数的指令。上述指令是R型指令,用于寄存器)

最后一个大字段用于表示地址偏移量或者立即数。
两者都是32位指令,因此复杂度没提升太多。但是计算机又怎么判断哪个是R指令,哪个是I指令呢?通过不同的op来判断具体指令格式。
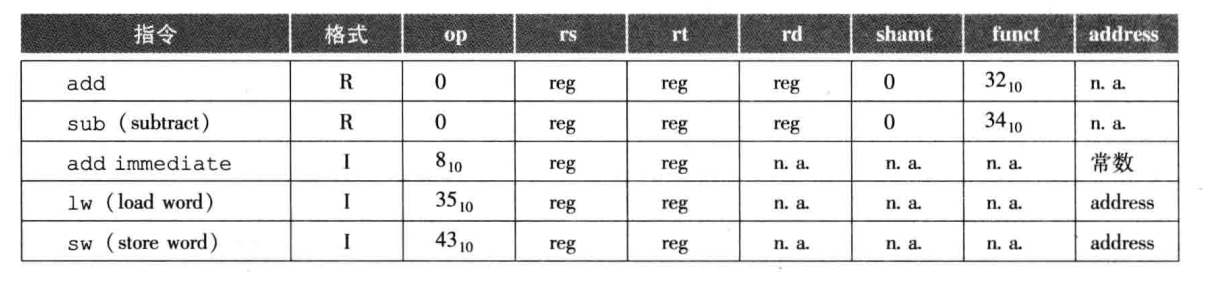
比如lw,代表rs rt是寄存器,后面所有位都是addr值。
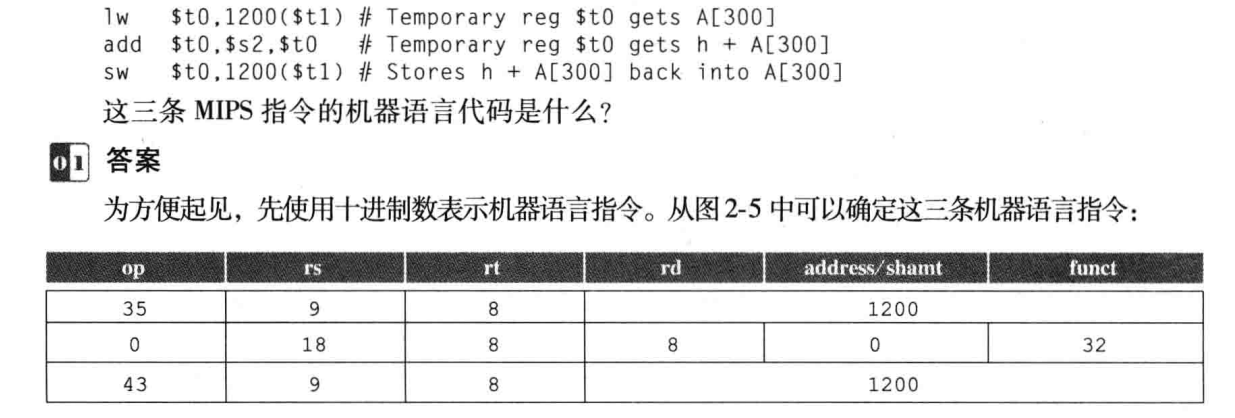
上例展示了两种不同指令的机器码。如果没有rd用第二个源操作数寄存器rt代替。
左移:
sll $t2,$s0,4 # t2=s0<<4
and $t0,$t1,$t2 #t0=t1 & t2
or $t0,$t1,$t2 #t0=t1 | t2
nor $t0,$t1,$t2 #t0=~(t1 | t2), 其中一个是0的话相当于 not

条件跳转:
beq $s1,$s2,L1 #两者相等则跳转到L1处
bne $s1,$s2,L1
比如: if(i==j)f=g+h;else f=g-h;
bne $s3,$s4,Else
add $s0,$s1,$s2
j Exit
Else:sub $s0,$s1,$s2
Exit:
循环跳转:类似的跳转比较方法。
Loop: #循环体
bne $s0,$s1,Exit #如果两者不等,跳出循环
j Loop
Exit:
小于指令:
slt $t0,$s3,$s4 #t0=1 if s3<s4
sltu $t0,$s3,$s4 #无符号数
slti $t0,$s3,10 #带立即数的比较
因为遵循简单性原则,没有“小于则跳转”的指令。当然我们可以先用slt,再用beq判断t0的值,这样两条简单的指令效率也会更高。
过程(函数)
一个抽象的概念,程序执行中的一部分过程,类似函数。过程不需要知道调用者的全部信息,只需要知道自己完成过程所需要的部分。
涉及到:传入参数,移交控制权给过程,过程返回后获取指定的存储区域来获取过程的返回值。
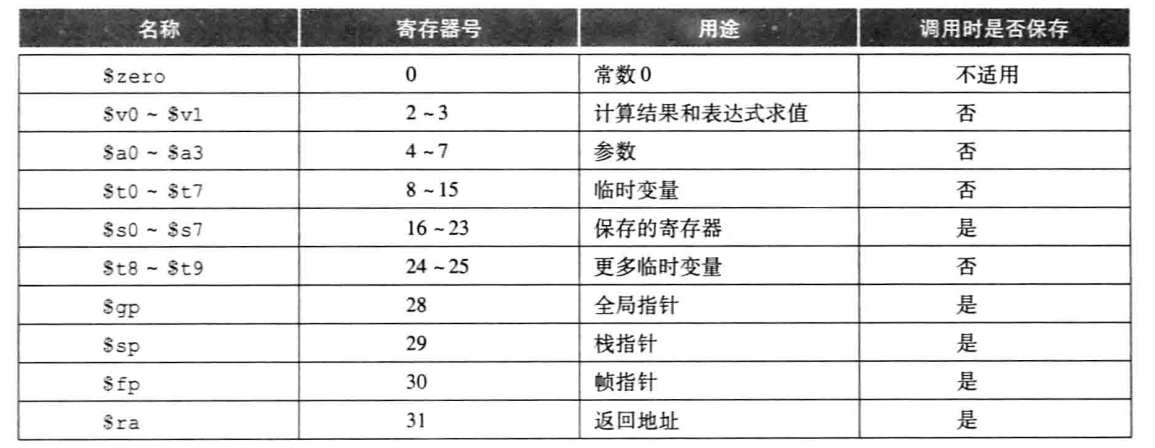
a0~a3是传入参数,v0 v1是函数返回值,ra是返回起始点的返回地址寄存器。
jal:jump and link,跳转并且把返回值存入ra。然后使用 jr 指令跳回。jr 是无条件跳转到后面寄存器中存储的地址。
jr ra
调用函数的部分是调用者 caller。被调用的函数是 callee。
jal 其实就是把 pc+4 的值存入 ra。
栈
比如函数里我们需要用到更多的寄存器,不止这5个。
我们可以先把原来寄存器的值压入栈,然后把那些寄存器给栈。
栈 sp 还是高地址向低地址增长。
比如函数计算 f=(g+h)-(i+j) 求和。传入四个参数是 a0-a3,f存到 s0 里,以及过程中两个加法运算需要用到两个临时变量 t0 t1。因此这三个寄存器的值需要入栈保存。
入栈代码:
addi $sp,$sp,-12
sw t0,8($sp)
sw t1,4($sp)
sw s0,0($sp)
运算结束后 s0 寄存器中的值应该交给 一个返回值寄存器
add $v0,$s0,$zero
出栈代码:
lw t0,8($sp)
lw t1,4($sp)
lw s0,0($sp)
addi $sp,$sp,+12
不过实际上,MIPS 规定是 s0-s7 系列寄存器要存,callee 存和恢复。t0-t9 系列不用。
嵌套过程
不调用其他过程的过程叫叶过程。不过我们知道只由叶过程组成的程序很少。
非叶过程必须压栈所有必须保留的寄存器,caller 保存 a0-a3 参数寄存器和 t0-t9 临时寄存器,callee 保存 s0-s7 保存寄存器和 ra 返回地址。callee 保存的寄存器能保证调用时和返回时的值是一样的,而临时寄存器和参数寄存器返回时值可变。 因此如果 caller 自己留着 t 系列有用你就自己保存一下,别指望 callee 保存;没用就不用存。
比如一个递归代码,c 语言表示如下:
int fact(int n)
{if(n<1)return 1;else return n*fact(n-1);
}
MIPS 汇编代码:
首先先盘点一下非叶过程要用的寄存器。
-
计算步骤比较简单不用保存临时寄存器。
-
n 是 a0 参数需要保存。
-
ra 需要保存。
-
s0-s7 没用到。
也就是只有 a0 ra 需要保存。然后再判断一下在什么位置保存?caller 还是 callee?
每次调用 fact 函数时,fact 函数是 callee,自己保存 ra。如果 fact 又递归调用了下一个自己,那么他自己又变成了 caller,需要保存 a0. (或者另一种逻辑:每次都保存 ra 和 a0,如果递归调用了自己则恢复 ra a0,否则不用恢复 ra a0 因为值没变)
fact:addi $sp,$sp,-8sw $ra,4($sp)sw $a0,0($sp)slti $t0,$a0,1 # 判断是否 <1beq $t0,$zero,L1 # >=1 则准备进入下一层循环addi $v0,$zero,1addi $sp,$sp,8jr $ra # ra a0 值没变,这里把栈指针恢复一下,返回值赋值一下就结束函数了L1:addi $a0,$a0,-1jal fact # 递归调用非叶过程lw $ra,4($sp)lw $a0,0($sp)addi $sp,$sp,8 # 恢复寄存器原值mul $v0,$a0,$v0 # 乘上本轮递归的 njal $ra
补充:全局和 static 变量是静态的,静态变量存放在静态数据区中,在过程进入和退出过程中也存在,而动态变量只在过程中存在,在过程进入和退出过程中不存在。MIPS 有一个 global pointer $gp 指向静态数据区。
递归过程开销还是比较大的,尽量用迭代代替会好一些?
过程帧
有些过程内部一部分寄存器也要压栈,这部分寄存器和局部变量片段叫做过程帧或活动记录。
部分 MIPS 软件会使用 $fp 帧指针和 $sp 共同标识哪一部分是过程帧,也有的软件会使用寄存器来保存过程帧的指针。
帧指针还可以保存超过4个的参数,超出部分可以根据帧指针在内存中找到其位置。
当然一个很重要的原则还是:过程返回前,必须把这一部分恢复为空。
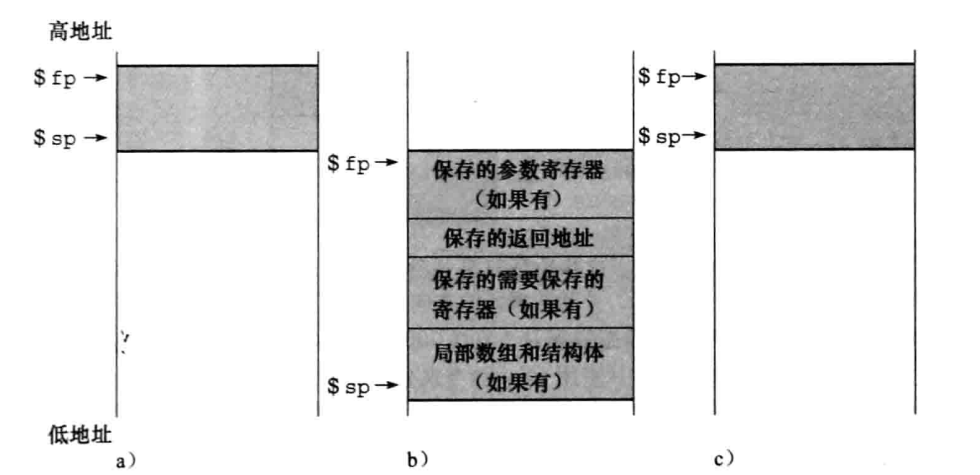
代码段
在堆中要为静态变量和动态数据提供空间。
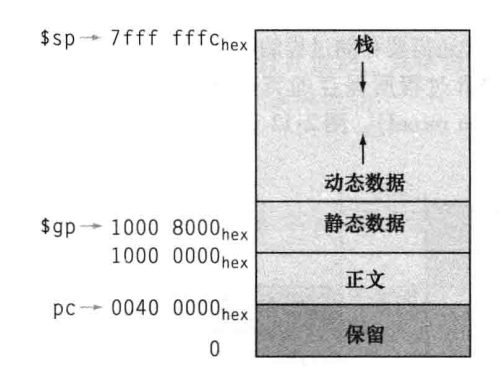
正文:代码段。
静态数据:全局和 static 变量。
动态:动态变量。
c语言中分配释放堆空间通过显式的 malloc 和 free 函数。缺点在于忘记手动释放容易导致内存泄露,释放早了又会产生 dangling pointer 悬摆指针,程序指向不想指向的位置。而 java 就会自动内存分配和回收无用单元 XD
这是 MIPS 保存的寄存器约定。这算作是一种加速大概率事件,因为统计证明保存8个寄存器和10个暂存器在大多数时候已经足够。
人机交互
如今计算机大多使用8位字节来表示字符,又名 ASCII 码。
lb sb:只读取写入一个字节,到目标寄存器的最右边八位。
字符通常被组合成字符串的形式。标志字符串长度有三种方案:1. 字符串首位是其长度;2. 使用单独的变量存储字符串长度;3. 使用特殊的结束符标识字符串的结束,c语言采用的是方案3,使用 \0 标识。
比如对于一个字符串复制的实现,c语言的逻辑为:循环遍历一位位复制字符,直到碰到 \0 为止。
假设目标数组和源数组基址在 $a0 $a1 中,i 存储在 $s0 中。
strcpy:addi $sp,$sp,-4sw $s0,0($sp)add $s0,$zero,$zero # i置0L1:add $t1,$a1,$s0 # t1存放源数组的当前指针lbu $t2,0($t1) # 无符号字节读取add $t3,$a0,$s0 # t1存放目标数组的当前指针sbu $t2,0($t3)beq $t2,$zero,L2 # 跳出结束复制addi $s0,$s0,1 # 这里和之前以字为单位做处理不同,我们是以字节为单位做处理,因此i++而不是i+4L2:lw $s0,0($sp)addi $sp,$sp,4jr $ra
java 采用的是更通用的 Unicode (现如今大多数 Web 页面采用的方案)保存字符,单位是16位。MIPS 可以直接通过 lh sh lhu shu 来读取写入半字长正好一个字符长。因此 java 字符串占用内存是 c 的两倍,但是字符串操作更快。
java 使用一个字来存储字符串总长。
因为 MIPS 的栈地址必须按字对齐,因此 c 中一个 char 8位,哪怕有5个 char,也会分配8个 char 的长度来对齐2字。java 的半字也是类似的需要对齐机制。
32位立即数
正常立即数都是16位的嘛,但是我们有时候需要他更长,到 32位。
lui load upper immediate 指令可以把16位立即数复制到寄存器的高16位中。

这样比如一个32位数我们可以先 lui 前16位到一个寄存器中,再插入低16位 ori。
MIPS 中有一个专门的 $at 寄存器来临时存储32位立即数。
不过需要注意使用32位立即数和16位立即数,比如 addi 和逻辑操作时高16位都是参与运算的(16位立即数的高16位逻辑运算视作全0)。
寻址
J 系列跳转指令是6位操作码+26位跳转地址,跳转范围是2^26.
条件分支 b 系列指令因为还需要位存放待比较的寄存器,构造为6位操作码+5位寄存器1+5位寄存器2+16位地址。
如果这个16位地址就代表目标地址,那就局限了能跳转的地址范围是 2^16 个字,那程序总长不能超过这个范围了,那也太没意思了。
为此,采取的方案是:这16位地址是偏移地址,跳转方式是当前基址+16位偏移地址(一位符号位,也就是±2^15)。因为大部分循环指令 条件指令都小于 2^15(这也是一种加速大概率事件),所以这种做法很够用。这种方法叫做 PC 相对寻址。
而且 MIPS 地址都是按字对齐的,所以相较字节地址,能寻址范围扩大了4倍,比如 j 系列寻址范围是 2^28 的字节地址。
但是 PC 地址不是32位的吗?实际上其中只有低28位可以被跳转指令修改。如果程序大小超过了 2^28,需要通过寄存器跳转方式跳转。

b 系列是相对寻址,且相对下一条指令,也就是 80016 处的 addi $s3,$s3,1 跳转到 80032 处的 Exit,即 8+80016.
j 系列是直接寻址,20000*4=80000 跳转。

这也是一种有趣的思想,我说总是感觉条件取反汇编和正常 if 思维不太一样呢。
MIPS 的寻址模式总的来说有以下几种:
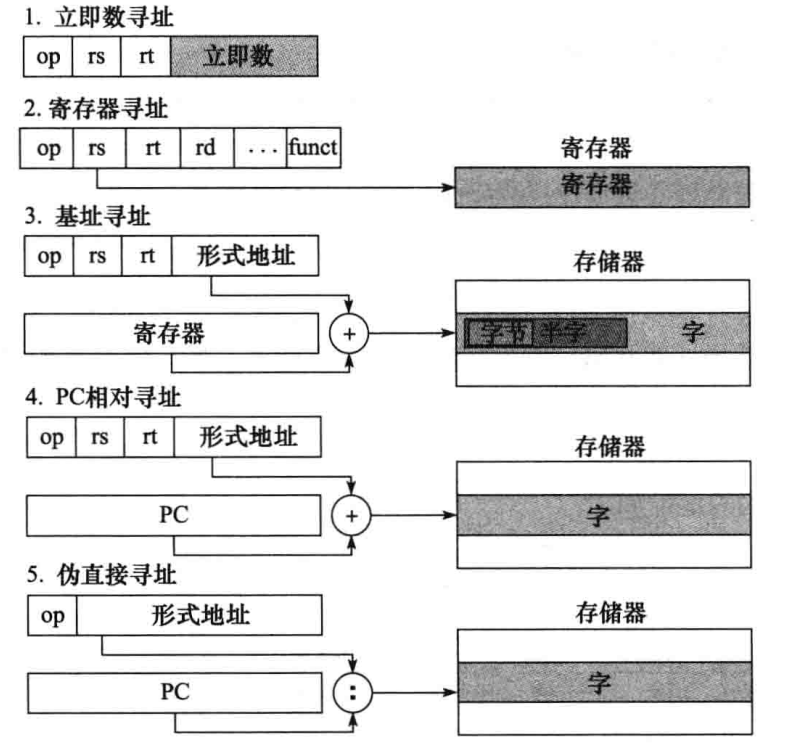
基址寻址:给定寄存器中地址+偏移地址。
伪直接寻址:PC 高位和26位形式地址拼接而成。
虽然本书中 MIPS 是32位寻址,但几乎所有微处理器都可以扩展到64位寻址,向上兼容。
并行与同步指令
并行执行任务时同步机制就比较重要,防止数据竞争。
这里和学操作系统的时候感觉很像。通过互斥锁对一组数据进行原子读写操作。
我们采用指令对:链接取数+条件存数 ll+sc 来实现。
again: addi $t0,$zero,1 ; 尝试上锁=1ll $t1,0($s1) ; 获取 s1 初始值sc $t0,0($s1) ; 保存 s1 值。如果发现 ll 获取值和 sc 保存值不同,t0 置零beq $t0,$zero,again ; 如果 t0 又变成0了,执行失败,重新执行add $s4,$zero,$t1 ; 做操作
后面章节还会再深入展开滴。
翻译执行程序
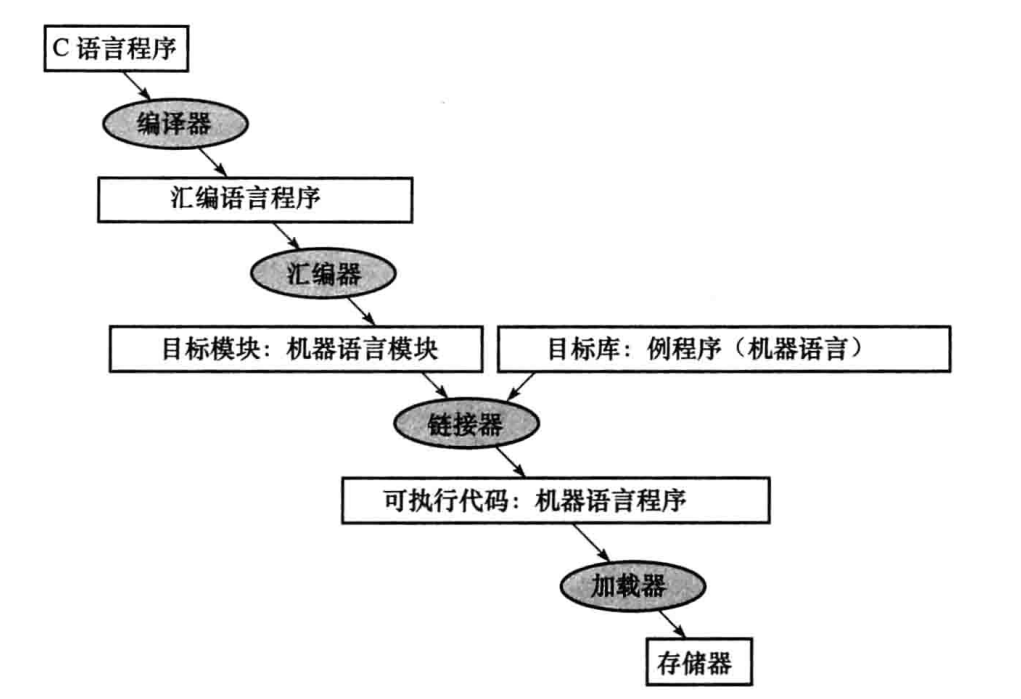
早期硬件存储容量小且编译器效率不高,都是写汇编的。
汇编器支持一些机器语言的变种,比如 move 指令,实际是 add $t0,$zero,$t0 ,汇编器也能翻译,但是其实没有 move 指令,这类指令叫伪指令。
汇编器将,叫符号表。
汇编文件生成的目标文件包含:
- 目标文件头:描述目标文件组成,大小,位置等信息。
- 代码段
- 静态数据段
- 重定位信息:一些依赖于绝对地址的指令和数据。
- 符号表:未定义的剩余标记(如分支和数据传输指令中的标号都放到一个表中待查阅,表中数据由标号和地址成对组成),如外部引用。
- 调试信息。
链接器将各个机器语言目标文件组合起来变为可执行文件。这其中主要经历的步骤如下:
- 根据文件中的重定位信息和符号表,把各个文件中的旧地址组合起来做成新地址。为什么不一开始就生成可执行文件并设定好新地址,而非要各个文件编译成单独目标文件后再重新修改?因为这样修改效率更快。
- 解析完外部链接后,链接器再决定所有模块在内存中的位置并用重定位的绝对地址表示。先处理绝对的地址,再布局剩下的相对地址。
总的来说可执行文件和目标文件是相同格式的,但是其中不包含未解决的引用(除非是一些外部链接,比如链接到库函数)。
例题:如下是 A B 两个目标文件,链接并给出更新后的地址。
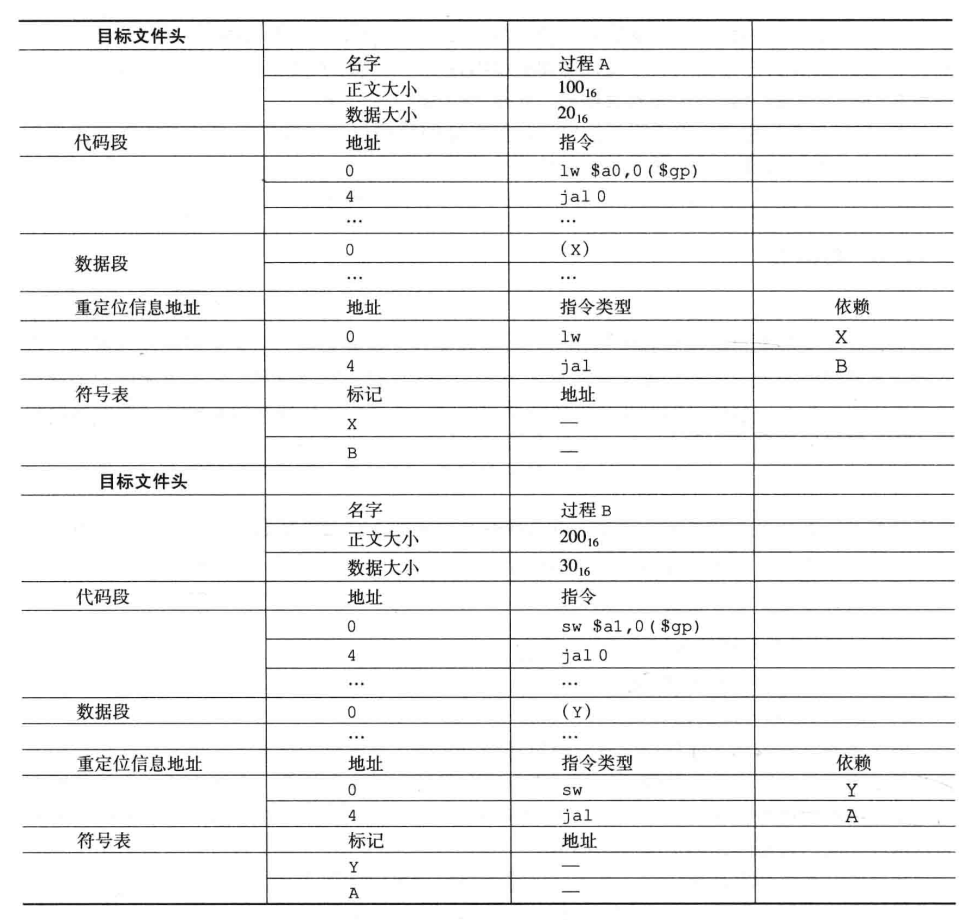
- 处理外部引用。A 引用了 XB,B引用了 YA。
- 代码段从 0x400000 处开始,数据段从 0x10000000 处开始,所以 A 代码段是 0x400000-0x400100(过程 A 文件头标识了他的正文大小,没有用到 0x400100),数据段是 0x10000000-0x10000020,B 紧随其后,代码段是 0x400100-0x400300,数据段是 0x10000020-0x10000050。
- 两者第一条跳转指令是跳转到对方的第一条指令位置。jal:伪直接寻址,则 jal 跳转地址就是对方第一条指令的地址,a 是跳到 400100,b 是跳到 400000. 再加上 jal 跳转规则是丢弃最左边两位(实际跳转是基址+4* jal),两者实际跳转地址是 100040 和 100000. 指令是递增增长的
- gp 初始地址是 0x10008000,存取数据是依靠基址寄存器存取,实际取指地址想取到 0x10000000 的话偏移量应为 0x8000. 大端数据是递减增长的
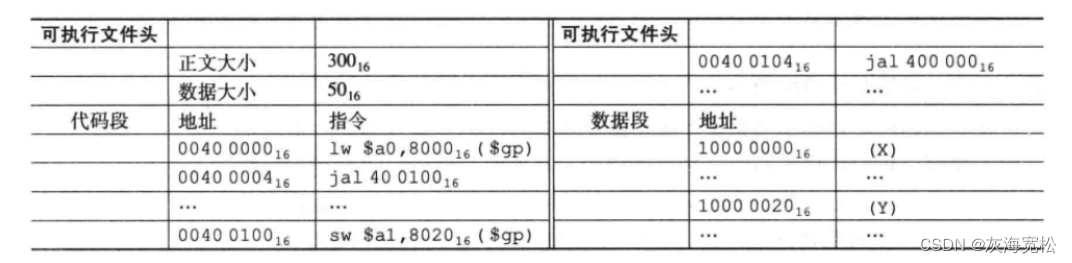
创建好了可执行文件后,加载器来把数据指令放入内存。
- 读取文件头,知晓代码段和数据大小;
- 创建足够大的正文和数据空间;
- 复制数据指令;
- 主函数参数复制入栈顶,栈指针指向空;
- 跳转到启动例程,复制参数并调用程序的 main 函数;main 函数返回时,调用 exit 终止程序。
前面提到的这种链接方式是静态链接,缺点在于如果库函数更新了,之前连接过的库函数也没变。而且也会导致尽管不是用到了库中的所有内容,库还是会被全部加载进来,程序会很大。
而动态链接 DLL 是运行的时候才链接库。一开始的动态链接也是会添加所有库中的内容的,晚过程连接的 DLL 是只会链接调用的例程。
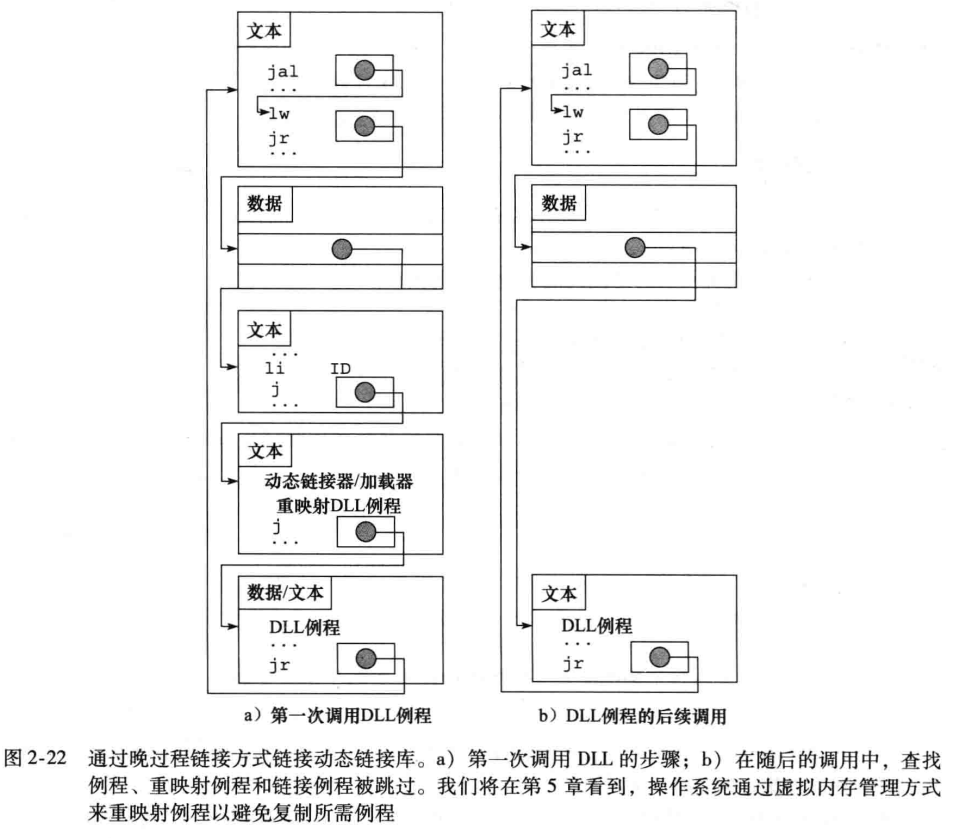
第二次就避免了一些间接跳转。
java 程序的执行经过两个步骤。
- javac 编译 java 语言变为 class 二进制字节文件。
- jvm 逐条解释翻译字节码文件。
jvm 效率太低了,后来又出现了 JIT 即时编译器辅助,会将运行频繁的代码块认定为“热点代码”,编译为与本地平台相关的机器码并进行优化来提高效率。
项目示例:sort

sll $t0,$a1,2
add $t1,$a0,$t0
lw $t2,0($t1)
lw $t0,4($t1)
sw $t0,4($t1)
sw $t2,0($t1)
jr ra

循环1:
move $s0,$zero
for1tst:slt $t0,$s0,$a1beq $t0,$zero,$exit1...for loop 2...addi $s0,$s0,1j for1tst
exit1:
循环2:不要动循环1里的 s 寄存器,可以随便重新改 t 寄存器。
addi $s1,$s0,-1
for2snd:slti $t0,$s1,0bne $t0,$zero,$exit2sll $t1,$s1,2add $t2,$t1,$a0lw $t3,0($t2)lw $t4,4($t2)slt $t0,$t4,$t3beq $t0,$zero,$exit2...swap...addi $s1,$s1,-1j for2snd
exit2:
swap 调用:先存原来的参数寄存器,再修改参数寄存器。
# 传参
move $s2,$a0
move $s3,$a1
move $a0,$s2
move $a1,$s1jal swap
最后在合并之前,开头和结尾我们还要加上对保存换源寄存器的操作。我们用到了 s0-s3,所以要保存 s0-s3 和 ra。
sort:addi $sp,$sp,-20sw $ra,16($sp)sw $s3,12($sp)sw $s2,8($sp)sw $s1,4($sp)sw $s0,0($sp)move $s2,$a0move $s3,$a1 # 不管是否要调用,先存一下参数move $s0,$zerofor1tst:slt $t0,$s0,$a1beq $t0,$zero,$exit1addi $s1,$s0,-1for2snd:slti $t0,$s1,0bne $t0,$zero,$exit2sll $t1,$s1,2add $t2,$t1,$a0lw $t3,0($t2)lw $t4,4($t2)slt $t0,$t4,$t3beq $t0,$zero,$exit2move $a0,$s2move $a1,$s1jal swapaddi $s1,$s1,-1j for2sndexit2:addi $s0,$s0,1j for1tstexit1:lw $ra,16($sp)lw $s3,12($sp)lw $s2,8($sp)lw $s1,4($sp)lw $s0,0($sp)addi $sp,$sp,20jr $ra
调用 swap 函数的部分也许可以通过内联的方式优化,即把交换操作直接展开而不是调用函数,减少跳转开销。但是因此代码量增加,如果 cache 缺失率增加,反而得不偿失了。
另外,实际上 $sp 总是保存4个参数寄存器 -16. 因为 c 会有一个可变参数 vararg 选项,允许一个指针参数。
数组与指针
数组是下标*4 加到数组基址上,指针是数组基址+=4.
如下程序示例是数组清零的两种实现:

对比其他指令集
- ARM 架构:
- ARM(Advanced RISC Machines)是一种精简指令集计算机(RISC)架构,广泛用于移动设备、嵌入式系统、嵌入式芯片和微控制器等领域。
- ARM 设计注重能效和低功耗,因此在移动设备领域表现出色。
- ARM 架构具有多个版本和变体,包括 ARMv7、ARMv8 等,其中 ARMv8 引入了 64 位执行模式(AArch64)。
- x86 架构:
- x86 架构是一种复杂指令集计算机(CISC)架构,主要用于个人计算机、服务器和桌面系统。
- x86 架构的代表性处理器包括 Intel 的 Pentium、Core i 系列和 AMD 的 Ryzen 系列。
- x86 架构在性能和功能上具有很高的灵活性,适用于广泛的计算任务。
- MIPS 架构:
- MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集计算机(RISC)架构,早期在工作站和嵌入式系统中广泛使用。
- MIPS 设计注重简化指令集,以提高执行效率。
- 尽管在一些领域使用逐渐减少,但MIPS架构仍然在某些嵌入式、网络设备和嵌入式控制器中有所应用。
by gpt
比如,arm 的比较和条件分支:MIPS 是把比较结果存在一个寄存器中,ARM 是比较结果设置为条件码,包括:负数,零,进位,溢出。比如 CMP 比较将两个寄存器值相减,结果设置条件码。
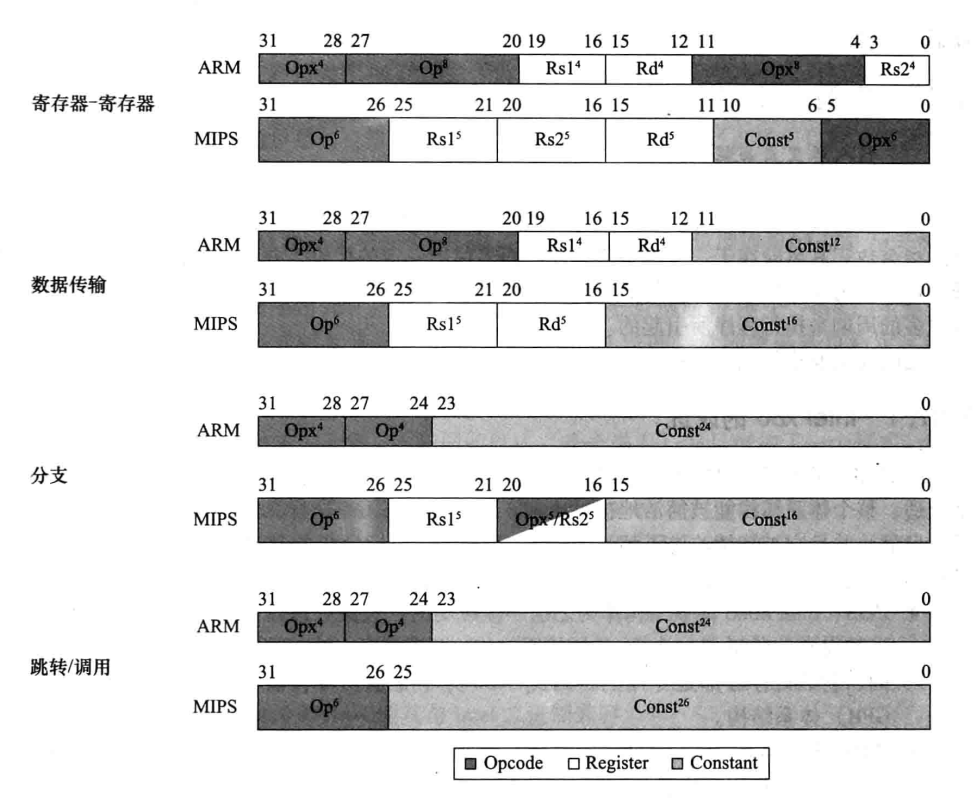
这样 arm 拥有的寄存器数量少一倍(16个)但是仍然能完成任务,而且某些情况下根据条件码会直接跳过不需要执行的指令,节省代码空间的同时也节省了运行时间。
arm 的立即数:4+8 的扩展形式。

也支持对第二个寄存器参数做移位操作,同样位数能表示更多数据。
arm 也支持对寄存器组操作,通过16位掩码决定加载 / 复制16位寄存器中的哪些寄存器。
x86 的缺点主要在于寻址范围有限,而且 cisc 拖慢效率。
总的来说,MIPS 指令规整,长度统一,只采用32个寄存器来保证对速度的要求,通过加速大概率事件等思想来优化指令组成。