es 概念
Elasticsearch是分布式实时搜索、实时分析、实时存储引擎,简称(ES)成立于2012年,是一家来自荷兰的、开源的大数据搜索、分析服务提供商,为企业提供实时搜索、数据分析服务,支持PB级的大数据。 -- 公司网站: https://www.elastic.co
基于Apache Lucene 开源搜索引擎,Lucene是目前公认的性能最好,最先进的,功能最全的搜索引擎
lElasticsearch使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,通过简单RESTfulAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。 超出你的想像,从10亿的数据查出一条只需要1-2秒内。
l实时分析 ,实时搜索 ,可分布,可扩展到上百台PB机器。
l著名的gitHub网站 用es来搜索 20TB的数据。包括13**亿文件与1300亿行**的代码。
l集群:多台Es服务器的结合的统称叫ES集群,一个集群包含多台服务器,多个节点。
l 节点:一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。
-
索引(Index):
-
索引是Elasticsearch中的主要数据容器,类似于关系型数据库中的表。它是一种逻辑容器,用于组织和存储具有相似结构的文档。
-
每个索引都有一个唯一的名称,用于在Elasticsearch中标识和引用它。
-
索引定义了文档的存储方式、分片和副本配置等信息。
-
-
类型(Type)(已弃用):
-
在较早的Elasticsearch版本中,索引内部可以包含不同类型的文档,每种类型表示不同的数据结构。例如,在一个名为"people"的索引中,可以有"employee"类型和"customer"类型。
-
类型有助于对不同类型的文档进行分类,但从Elasticsearch 7.0版本开始,多类型的支持已被弃用,一个索引只能包含一种类型的文档。
-
-
文档(Document):
-
文档是Elasticsearch中的基本数据单元,类似于关系型数据库中的行。每个文档表示一条具体的数据记录。
-
文档由一组字段(Fields)组成,每个字段存储特定的数据。字段可以是文本、数字、日期等各种类型。
-
每个文档都有一个唯一的标识,称为文档ID。
-
关系:
-
在一个索引内,您可以存储多个文档。
-
文档可以有不同的字段,这些字段可以是各种数据类型,如字符串、数字、日期等。
-
类型(Type)在较新的Elasticsearch版本中已被弃用,所以现在一个索引只包含一种类型的文档。
-
索引为文档提供了逻辑容器,帮助您组织和存储数据,同时也定义了数据的分片和副本配置。
-
每个文档都有一个唯一的文档ID,通过该ID可以准确地检索和更新文档。
总结:索引是数据的逻辑容器,文档是基本的数据单位,类型(现已弃用)曾用于在索引内部区分不同的数据结构。从Elasticsearch 7.0版本开始,推荐使用单一类型的索引结构来组织和存储文档。
-
分片(Shard):
-
分片是将索引数据分割成更小的单元,以便分布式存储和处理数据。每个索引可以被分成多个分片。
-
每个分片是一个独立的、自包含的数据单元,它包含了索引的部分数据以及相关的索引结构信息。
-
分片允许Elasticsearch将数据分布到多个节点上,从而实现数据的并行处理和更高的吞吐量。
-
默认情况下,每个索引包含5个主分片,您可以在创建索引时指定主分片的数量。
-
-
复制分片(Replica Shard):
-
复制分片是每个主分片的副本,它用于提高系统的可靠性和读取性能。
-
每个主分片可以有零个或多个复制分片。复制分片的数量决定了索引的冗余性和查询的并行性。
-
复制分片分布在不同的节点上,当主分片或节点发生故障时,复制分片可以继续提供服务,确保数据的可用性。
-
默认情况下,每个主分片有一个复制分片,总的数据副本数量(主分片+复制分片)为2。
-
关系:
-
每个索引都被分成多个主分片,主分片可以分布在集群中的不同节点上,实现数据的分布式存储和并行处理。
-
每个主分片可以有零个或多个复制分片,复制分片提供数据的冗余副本和更高的读取性能。
-
主分片和其对应的复制分片构成了数据的多副本存储,确保了数据的高可用性和容错能力。
-
分片和复制分片的数量共同决定了索引的性能、可靠性和吞吐量。适当的分片和复制策略是为了满足不同的应用场景需求。
总结:分片和复制分片是Elasticsearch中实现分布式存储、提高性能和可靠性的关键机制。分片将索引数据切分成小单元,实现并行处理,而复制分片提供数据的冗余和读取性能增强。它们共同构成了Ela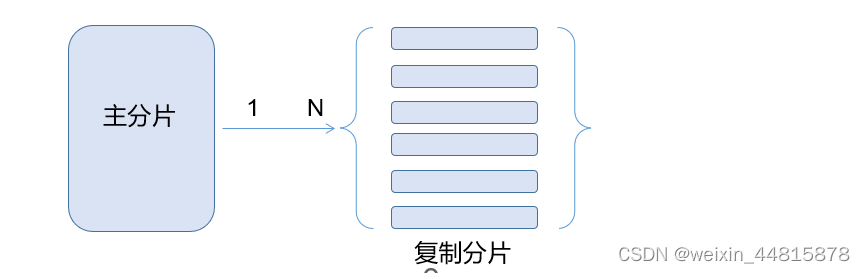 sticsearch集群的核心架构。
sticsearch集群的核心架构。