文章目录
- 一、缓存穿透
- 1. 什么是缓存穿透
- 2. 解决方案
- 2.1 无效的key存放到Redis
- 2.2 引入布隆过滤器
- 2.3 如何选择:
- 二、缓存击穿
- 1. 什么是缓存击穿
- 2. 解决方案
- 三、缓存雪崩
- 1. 什么是缓存雪崩
- 2. 解决方案
- 2.1 均匀过期
- 2.2 热点数据缓存永远不过期
- 2.3 采取限流降级的策略
- 四、缓存预热
- 1. 什么是缓存预热
- 2. 解决方案
- 2.1 工程启动时进行缓存的加载
- 2.2 采用定时任务脚本来刷新缓存
- 2.3 提前加载热点数据到缓存
- 2.4 总结
一、缓存穿透
1. 什么是缓存穿透
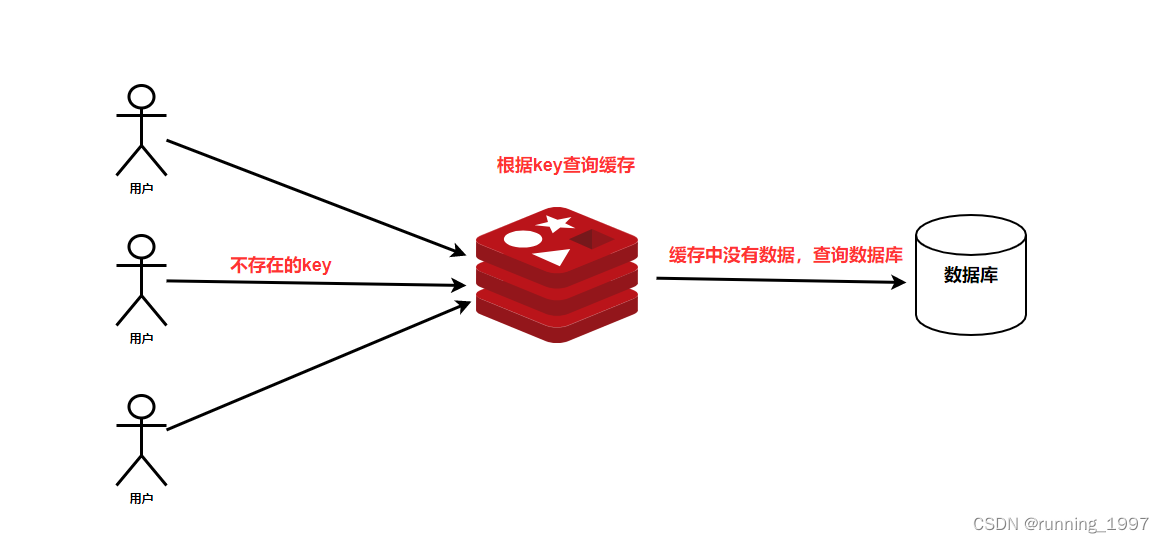
缓存穿透是指用户请求的数据在缓存中不存在,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍。如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间内大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住而宕机崩溃。
缓存穿透的关键在于在Redis中查不到指定的key值,与缓存击穿的根本区别在于传入的key在Redis中确实不存在。如果黑客传入大量不存在的key,那么大量的请求将直接打到数据库上,这是非常危险的情况。因此,在日常开发中,我们需要对参数进行良好的校验,对于一些非法的参数或不可能存在的key,应直接返回错误提示。
如下图:
2. 解决方案
2.1 无效的key存放到Redis
当Redis无法找到数据且数据库中也无法找到数据时,我们可以将该无效的key存放到Redis中,并将其值设置为"null",同时设置一个极短的过期时间。这样,在后续出现查询这个key的请求时,就可以直接返回null,而无需再查询数据库。然而,这种处理方式存在一个问题,即如果传入的不存在的key每次都是随机的,那么将其存放到Redis中就没有意义。
2.2 引入布隆过滤器
可以在使用缓存之前,引入布隆过滤器来判断某个key是否存在。布隆过滤器具有一定的误判率,但如果布隆过滤器判定某个key不存在,那么可以确定该key一定不存在;而如果判定某个key存在,则很大概率上是存在的(存在一定的误判率)。因此,我们可以将数据库中的所有key都存储在布隆过滤器中,然后在查询Redis之前,先通过布隆过滤器查询该key是否存在。如果布隆过滤器判定该key不存在,就可以直接返回,无需访问数据库,从而减轻了对底层存储系统的查询压力。这种方式可以有效地提高系统的性能和查询效率。
2.3 如何选择:
- 针对一些恶意攻击,攻击带过来的大量key是随机,那么我们采用第一种方案就会缓存 大量不存在key的数据。那么这种方案就不合适了,我们可以先对使用布隆过滤器方案进行过滤掉 这些key。
- 所以,针对这种key异常多、请求重复率比较低的数据,优先使用第二种方案直接过滤 掉。而对于空数据的key有限的,重复率比较高的,则可优先采用第一种方式进行缓存。
二、缓存击穿
1. 什么是缓存击穿
缓存击穿和缓存雪崩是两种类似的现象。缓存雪崩指的是在某一时刻,大规模的缓存失效,导致大量的请求直接访问数据库,从而引起数据库的压力剧增。而缓存击穿则是指某个热点的缓存失效,导致大量的并发请求集中到该缓存上,但由于缓存失效,这些请求无法从缓存中获取数据,只能直接访问数据库,进而导致数据库压力剧增。
2. 解决方案
热点key不设置过期时间
三、缓存雪崩
1. 什么是缓存雪崩
- 如果在某一时刻,缓存中大量的key同时失效,那么会导致大量的请求直接访问数据库,从而给数据库带来巨大的压力。在高并发的情况下,这可能会导致数据库宕机的风险。如果运维人员立即重启数据库,很可能会再次引来新的请求流量,继续给数据库带来过大的压力。这种情况就被称为缓存雪崩。
- 造成缓存雪崩的关键在于在同一时间大量的key失效。
- 这种情况可能发生在两种情况下:一是Redis缓存宕机,导致所有的缓存都失效;二是缓存中的key设置了相同的过期时间,导致在同一时间大量的key同时过期失效。
2. 解决方案
2.1 均匀过期
可以采取均匀过期的策略,即设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致大规模缓存同时失效,进而造成大量数据库访问的情况。一种常见的做法是给每个key的失效时间添加一个随机值,这样可以确保缓存不会在同一时间大面积失效。
2.2 热点数据缓存永远不过期
为了防止热点数据缓存失效导致缓存雪崩,一种常见的做法是让热点数据的缓存永远不过期。这意味着,对于那些经常被访问的数据,我们可以设置它们的缓存过期时间为永久,使其始终保持在缓存中。通过这种方式,热点数据将始终可用,不会因为过期而导致大量的请求直接访问数据库,从而减轻数据库的压力。当然,为了避免缓存数据过期而导致数据不一致的问题,我们需要确保在更新数据时及时更新对应的缓存。这样一来,热点数据的缓存可以持续为系统提供快速响应,并有效地避免了因缓存失效而引发的缓存雪崩问题。
2.3 采取限流降级的策略
为了防止过多的请求对数据库造成压力过大导致系统崩溃,可以采取限流降级的策略。当系统的流量达到一定的阈值时,可以直接返回类似于“系统拥挤”等提示信息,以限制进一步的请求。通过这种方式,可以保证至少一部分用户能够正常使用系统,并且对于其他用户,即使需要多次刷新也能够最终获得结果。
四、缓存预热
1. 什么是缓存预热
- 缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
- 如里不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库 中,对数据库造成流量的压力。
2. 解决方案
2.1 工程启动时进行缓存的加载
2.2 采用定时任务脚本来刷新缓存
2.3 提前加载热点数据到缓存
2.4 总结
- 当数据量较小时,可以在工程启动时进行缓存的加载操作;
- 而当数据量较大时,可以采用定时任务脚本来刷新缓存;
- 而对于数据量过大的情况,可以优先保证热点数据提前加载到缓存中。
在启动过程中加载缓存可以减少对数据库的频繁访问,提高系统的并发处理能力。
定时任务脚本的使用可以定期刷新缓存,确保数据的及时更新。
而对于数据量过大的情况,提前加载热点数据到缓存中可以避免频繁的数据库查询,从而减轻数据库的压力。
通过合理的缓存策略和数据加载方式,可以优化系统的性能和稳定性。
![[ MySQL ] — 常见函数的使用](https://img-blog.csdnimg.cn/8039b9ae158b43a7a34ff8a79088bf00.png)
![C国演义 [第十二章]](https://img-blog.csdnimg.cn/ef799b9f95114cb197c9eb1e1143b2e6.png)