🧑💻作者名称:DaenCode
🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。
😎人生感悟:尝尽人生百味,方知世间冷暖。
📖所属专栏:Redis从头学

文章目录
- 🌟前言
- 🌟List数据类型分析
- 🌟List类型实战应用场景
- 热销榜单功能
- 生活中的例子
- 排序规则
- 仿造示例
- 最终效果
- 🌟写在最后
🌟前言
之前的篇章对Redis的String数据类型已经做出了具体分析,并举例说明了其具体的实战场景本文就结合List数据类型结构的特性,一起探讨其实战中的应用场景,并以天猫热销榜单为例。
🌟List数据类型分析
Redis中的List数据类型是一种有序、可重复、可变长度的数据结构。它支持在列表的两端进行快速的插入、删除和查找操作,因此非常适合用于处理队列、栈以及任务列表等场景。
List数据类型可以存储多个相同或不同类型的元素,并且可以按照插入顺序进行访问。Redis提供了一系列的命令来操作List,包括向列表头部或尾部插入元素、在指定位置插入元素、获取指定位置的元素、删除列表中的元素等。有关其操作命令请参照【Redis从头学-3】5个表格带你学会使用Redis五大数据类型常用命令
List数据类型的主要特点:
- 有序性:列表中的元素按照插入顺序排列,可以根据索引位置进行访问。
- 可重复性:列表允许存储重复的元素。
- 动态长度:列表可以根据需要进行动态扩展或收缩,没有固定的长度限制。
- 快速操作:插入和删除元素的时间复杂度为O(1),在列表头部和尾部进行插入和删除操作非常高效。
🌟List类型实战应用场景
通过上述对List类型的分析,可以结合实际需求选择适合List类型结构的场景。本文主要演示排行榜功能的演示代码。
- 消息队列:可以通过List实现简单的消息队列,将消息按顺序插入到列表尾部,消费者从列表头部取出消息进行处理。
- 时间线:将新的动态信息按照时间顺序插入到列表头部,就可以实现类似社交媒体的时间线功能。
- 排行榜:可以对热销的商品进行榜单排序。
热销榜单功能
生活中的例子

排序规则

仿造示例
通过上述生活中的例子,来描述一个热销榜单的应用场景。实际场景要比这个复杂的多哦,这里只是感受List数据类型的结构。
实现步骤:
- 创建一个洗面奶实体类WashMilk。字段内容包含字段包含id、品牌名称、好评率、成交额、回购人数、累计销量等。
- 按照加权平均算法得出综合权衡的平均值。根据好评率、成交额、回购人数、累计销量因素,对洗面奶进行排序。
- 存入Redis中。使用rightPushAll。因为排序是按降序排序的,所有要从右插入,最大值才能展现在第一个。
若序列为:5,4,3,2,1。则按右插法,最终结果为
5
4
3
2
1
左插法,结果为:
1
2
3
4
5
加权平均算法介绍:
加权平均算法(Weighted Average Algorithm)是一种常见的统计算法,用于计算一组数据的加权平均值。在加权平均算法中,每个数据点都有一个对应的权重,权重可以表示数据的重要性或贡献度。
加权平均算法的计算公式如下:
加权平均值 = (数据点1 × 权重1 + 数据点2 × 权重2 + ... + 数据点n × 权重n) / (权重1 + 权重2 + ... + 权重n)
其中,数据点1、数据点2等表示要计算加权平均值的数据点,权重1、权重2等表示对应数据点的权重。
加权平均算法适用于以下场景:
- 数据点具有不同的重要性或权重,需要考虑这些差异并进行加权处理。
- 某些数据点可能对结果产生较大的影响,而某些数据点可能对结果影响较小,需要根据权重进行调节。
- 数据点的权重可能随时间、条件或其他因素而变化,可以动态调整计算结果。
举例来说,假设你要计算一组考试成绩的加权平均值,其中不同科目的权重不同,例如数学的权重为0.4,英语的权重为0.3,物理的权重为0.3。
你可以按照如下方式计算加权平均值:
加权平均值 = (数学成绩 × 0.4 + 英语成绩 × 0.3 + 物理成绩 × 0.3) / (0.4 + 0.3 + 0.3)
通过加权平均算法,可以根据不同数据点的权重,将其贡献度考虑在内,得出一个综合权衡的平均值。这个平均值更能反映数据的实际情况和重要性。
简易代码:
@Testvoid hotRank(){String DAILY_RANK_KEY="hotRank:daily";//模拟数据库查询到的数据WashMilk washMilk=new WashMilk(1,"香奈儿",0.65,10000,800,100000);WashMilk washMilk2=new WashMilk(2,"至本",0.85,60040,10000,25465);WashMilk washMilk3=new WashMilk(3,"兰蔻",0.60,343543,6000,4534);WashMilk washMilk4=new WashMilk(4,"雅诗兰黛",0.67,50000,800,3655);WashMilk washMilk5=new WashMilk(5,"欧莱雅",0.99,10000,40000,42443);WashMilk washMilk6=new WashMilk(6,"薇姿",0.65,32443,800,43244);WashMilk washMilk7=new WashMilk(7,"娇韵诗",0.82,10000,800,5435654);WashMilk washMilk8=new WashMilk(8,"相宜本草",0.95,65476,3214,4000);WashMilk washMilk9=new WashMilk(9,"佰草集",0.90,432535,800,3435);WashMilk washMilk10=new WashMilk(10,"倩碧",0.75,23423,4356,180000);List<WashMilk> washMilkList=new ArrayList<>();//将数据添加到list集合。Stream.of(washMilk,washMilk2,washMilk3,washMilk4,washMilk5,washMilk6,washMilk7,washMilk8,washMilk9,washMilk10).forEach(washMilkList::add);//通过加权平均法,对上述洗面奶综合排序Collections.sort(washMilkList, new Comparator<WashMilk>() {@Overridepublic int compare(WashMilk o1, WashMilk o2) {double wm1Score = o1.getGoodRate() * 0.4 + o1.getTurnover() * 0.3 + o1.getRepurchaseCount() * 0.2 + o1.getTotalSales() * 0.1;double wm2Score = o2.getGoodRate() * 0.4 + o2.getTurnover() * 0.3 + o2.getRepurchaseCount() * 0.2 + o2.getTotalSales() * 0.1;return Double.compare(wm2Score, wm1Score); // 按照降序排序}});//存入到redis中redisTemplate.opsForList().rightPushAll(DAILY_RANK_KEY,washMilkList);System.out.println(redisTemplate.opsForList().range(DAILY_RANK_KEY,0,-1));}
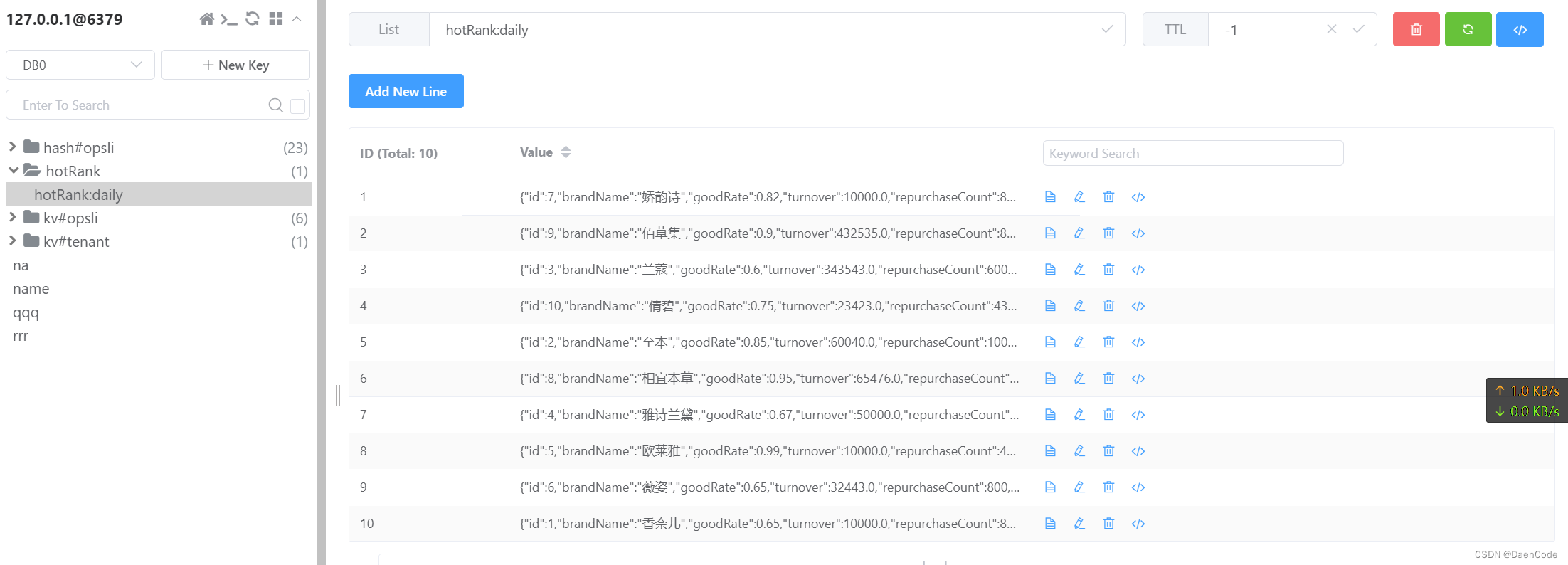
最终效果
最终效果展示如下图所示
🌟写在最后
有关于Redis中的List数据类型实战应用场景到此就结束了。功能演示代码的逻辑简单,目的是理解List数据类型的应用,实际场景的逻辑根据具体需求而定。感谢大家的阅读,希望大家在评论区对此部分内容散发讨论,便于学到更多的知识。