在Mysql中,如何定位慢查询呢?
表象:页面加载过慢、接口压测响应时间过长(超过1s)
原因:聚合查询 多表查询 表数据量过大查询 深度分页查询
方案:MySQL自带慢日志
需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志 long_query_time=2
配置完毕之后,重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息 /var/lib/mysql/localhost-slow.log
定位好之后,如何分析慢查询呢?
可以采用EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息



MYSQL支持的存储引擎有哪些, 有什么区别 ?
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。

InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后,InnoDB是默认的 MySQL 存储引擎。
索引的底层数据结构了解过嘛 ?
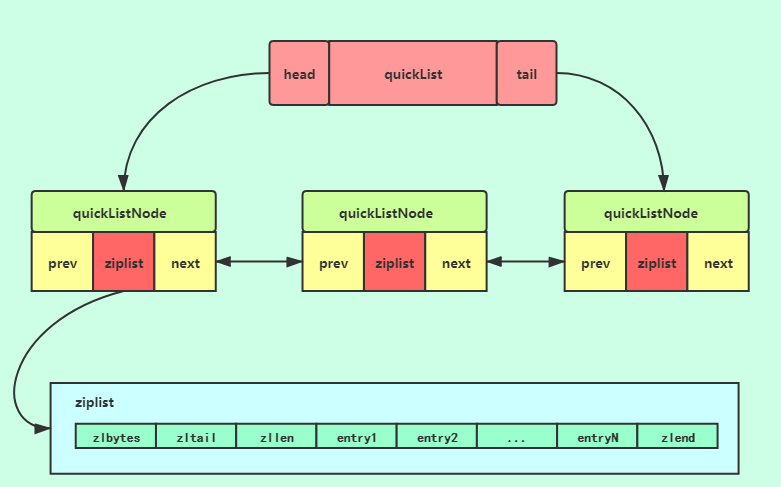
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
阶数更多,路径更短
磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
B+树便于扫库和区间查询,叶子节点是一个双向链表
知道什么叫覆盖索引嘛 ?
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到
使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select *
MYSQL超大分页怎么处理 ?
覆盖索引+子查询
索引创建原则有哪些?
1). 数据量较大,且查询比较频繁的表
2). 常作为查询条件、排序、分组的字段
3). 字段内容区分度高
4). 内容较长,使用前缀索引
5). 尽量联合索引
6). 要控制索引的数量
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
什么情况下索引会失效 ?
违反最左前缀法则
范围查询右边的列,不能使用索引
不要在索引列上进行运算操作, 索引将失效
字符串不加单引号,造成索引失效。(类型转换)
以%开头的Like模糊查询,索引失效
并发事务带来哪些问题?怎么解决这些问题呢?MySQL的默认隔离级别是?
并发事务的问题:
脏读:一个事务读到另外一个事务还没有提交的数据
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”。
隔离级别:
READ UNCOMMITTED 未提交读
READ COMMITTED 读已提交
REPEATABLE READ 可重复读
SERIALIZABLE 串行化
解释一下MVCC
MySQL中的多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突
隐藏字段:
trx_id(事务id),记录每一次操作的事务id,是自增的
roll_pointer(回滚指针),指向上一个版本的事务版本记录地址
undo log:
回滚日志,存储老版本数据
版本链:多个事务并行操作某一行记录,记录不同事务修改数据的版本,通过roll_pointer指针形成一个链表
readView解决的是一个事务查询选择版本的问题
根据readView的匹配规则和当前的一些事务id判断该访问那个版本的数据
不同的隔离级别快照读是不一样的,最终的访问的结果不一样
RC :每一次执行快照读时生成ReadView
RR:仅在事务中第一次执行快照读时生成ReadView,后续复用
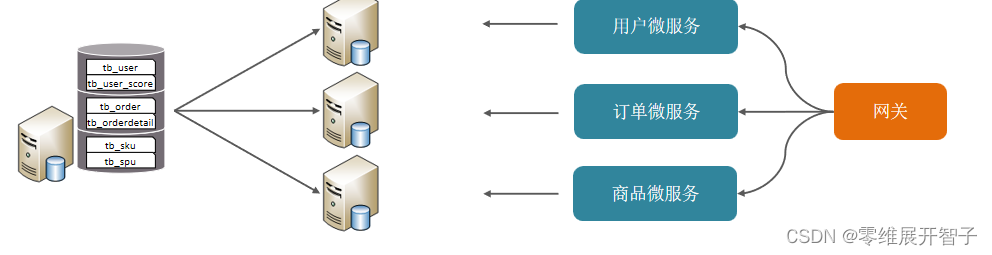
分库分表
场景:
项目业务数据逐渐增多,或业务发展比较迅速
优化已解决不了性能问题(主从读写分离、查询索引…)
IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
垂直分库:
垂直分表:
把不常用的字段单独放在一张表
把text,blob等大字段拆分出来放在附表中
冷热数据分离
减少IO过渡争抢,两表互不影响
水平分库:
解决了单库大数量,高并发的性能瓶颈问题
提高了系统的稳定性和可用性
水平分表:
优化单一表数据量过大而产生的性能问题;
避免IO争抢并减少锁表的几率;








![8th参考文献:[8]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.](https://img-blog.csdnimg.cn/08322314740f425daeb21e42a7d2c012.jpeg#pic_center)
