简介
本文介绍了在RDK X5上,如何从HuggingFace的原始模型权重(safetensors)经过量化和编译,的到llama.cpp推理框架所需要的GGUF格式的模型,然后演示了如何使用llama.cpp运行量化后的DeepSeek-R1-Distill-Qwen-1.5B模型。
所有操作均可在RDK X5板卡上运行,同时,本文也放了一份量化好的模型也放在了百度网盘。
链接: https://pan.baidu.com/s/16ltA-6nzLA5FzkSbOvdTcQ?pwd=wxn4 提取码: wxn4
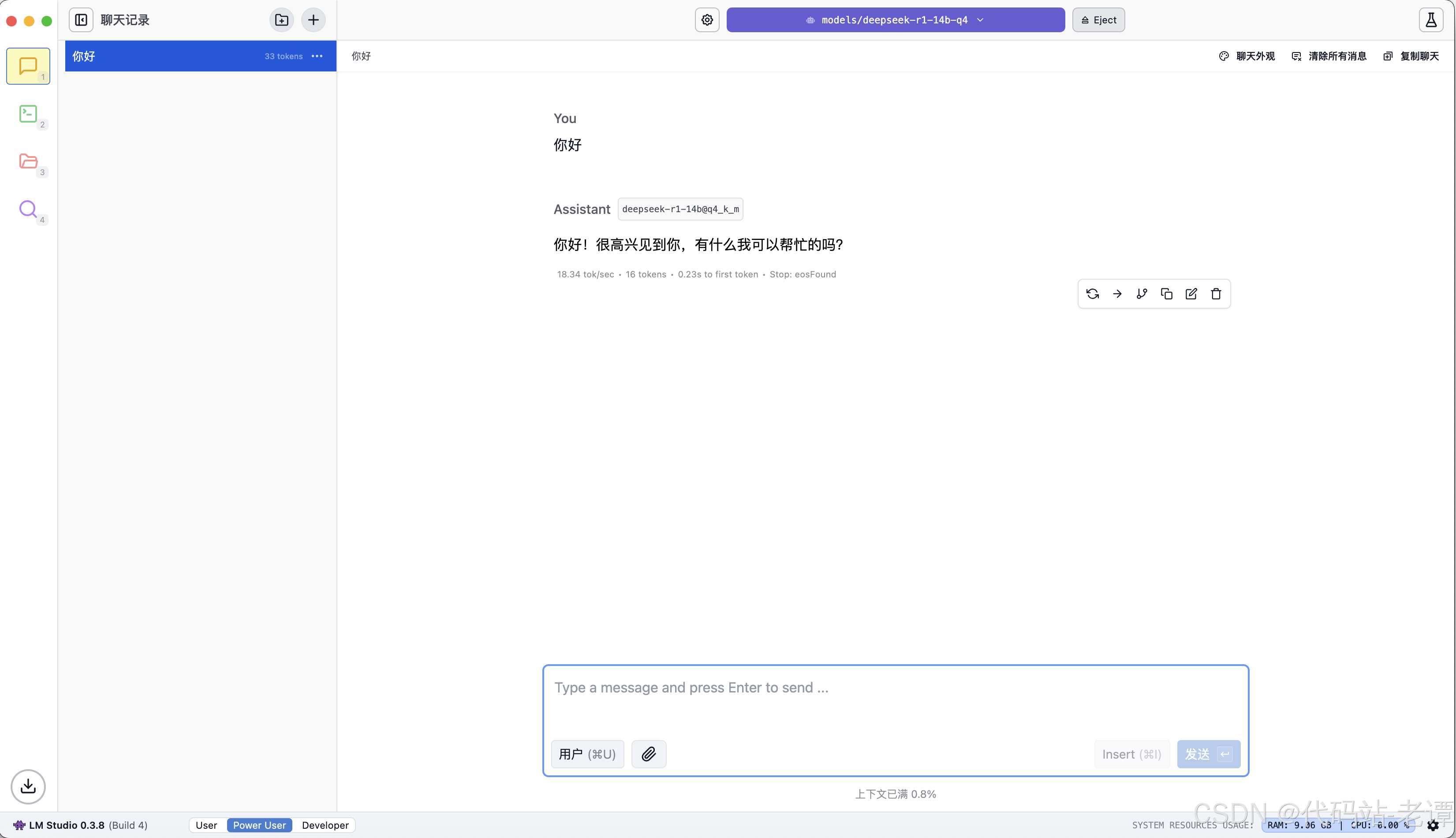
长思维链对话展示

演示视频:https://www.bilibili.com/video/BV1hkFaeeEgw
步骤参考
注: 所有的操作均基于地瓜机器人RDK X5板卡最新的RDK OS系统操作, 都在板卡上操作, 请根据实际情况修改对应的路径, 请不要直接复制粘贴运行。
拉取并编译最新的llama.cpp项目
拉取
git clone https://github.com/ggerganov/llama.cpp.git
拉取下来后的llama.cpp的项目结构如下, 新的commit可能结构略有不同, 但是基本的步骤不会变化.
tree llama.cpp -L 1
llama.cpp
├── AUTHORS
├── ci
├── cmake
├── CMakeLists.txt
├── CMakePresets.json
├── CODEOWNERS
├── common
├── CONTRIBUTING.md
├── convert_hf_to_gguf.py
├── convert_hf_to_gguf_update.py
├── convert_llama_ggml_to_gguf.py
├── convert_lora_to_gguf.py
├── docs
├── examples
├── flake.lock
├── flake.nix
├── ggml
├── gguf-py
├── grammars
├── include
├── LICENSE
├── Makefile
├── media
├── models
├── mypy.ini
├── Package.swift
├── pocs
├── poetry.lock
├── prompts
├── pyproject.toml
├── pyrightconfig.json
├── README.md
├── requirements
├── requirements.txt
├── scripts
├── SECURITY.md
├── Sources
├── spm-headers
├── src
└── tests
编译
cd llama.cpp # 进入llama.cpp项目目录
cmake -B build
cmake --build build --config Release -j7
设置环境变量
PATH=<path to your llama.cpp project>/llama.cpp/build/bin:$PATH`
可以写入~/.bashrc文件, 例如:
PATH=/media/rootfs/99_projects/deepseekr1_llama.cpp/llama.cpp/build/bin:$PATH
source ~/.bashrc
使用以下命令测试编译和设置成功
llama-cli -h
会打印以下内容
----- common params -----
-h, --help, --usage print usage and exit
--version show version and build info
--verbose-prompt print a verbose prompt before generation (default: false)
-t, --threads N number of threads to use during generation (default: -1)(env: LLAMA_ARG_THREADS)
-tb, --threads-batch N number of threads to use during batch and prompt processing (default:same as --threads)
-C, --cpu-mask M CPU affinity mask: arbitrarily long hex. Complements cpu-range(default: "")... ...--simple-io use basic IO for better compatibility in subprocesses and limitedconsolesexample usage:text generation: llama-cli -m your_model.gguf -p "I believe the meaning of life is" -n 128chat (conversation): llama-cli -m your_model.gguf -p "You are a helpful assistant" -cnv
获取DeepSeek-R1-Distill-Qwen-1.5BB的HuggingFace权重
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B: https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
对应的权重文件目录如下:
DeepSeek-R1-Distill-Qwen-1.5B/
├── config.json
├── generation_config.json
├── gitattributes
├── LICENSE
├── model.safetensors
├── README.md
├── tokenizer_config.json
└── tokenizer.json
使用llama.cpp对模型权重进行量化和转化, 的到GGUF格式的模型
注: 这里需要根据实际情况修改模型路径, HuggingFace的模型权重路径是一个文件夹
cd llama.cpp # 进入llama.cpp项目目录python3 convert_hf_to_gguf.py ../DeepSeek-R1-Distill-Qwen-1.5B \--outtype q8_0 \--verbose --outfile ../gguf/DeepSeek-R1-Distill-Qwen-1.5B-q8_0.ggufpython3 convert_hf_to_gguf.py ../DeepSeek-R1-Distill-Qwen-1.5B \--outtype bf16 \--verbose --outfile ../gguf/DeepSeek-R1-Distill-Qwen-1.5B-bf16.gguf
转化约占用约 2 分钟, 占用RDK X5的内存约 0.4 GB, 转化过程日志参考:
INFO:hf-to-gguf:Loading model: DeepSeek-R1-Distill-Qwen-1.5B
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model part 'model.safetensors'
INFO:hf-to-gguf:output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 151936}
INFO:hf-to-gguf:token_embd.weight, torch.bfloat16 --> Q8_0, shape = {1536, 151936}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.0.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.0.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.0.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.0.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.0.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.0.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.0.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.0.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.0.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.1.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.1.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.1.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.1.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.1.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.1.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.1.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.1.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.1.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.1.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.1.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.1.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.10.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.10.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.10.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.10.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.10.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.10.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.10.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.10.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.10.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.10.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.10.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.10.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.11.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.11.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.11.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.11.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.11.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.11.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.11.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.11.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.11.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.11.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.11.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.11.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.12.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.12.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.12.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.12.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.12.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.12.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.12.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.12.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.12.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.12.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.12.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.12.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.13.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.13.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.13.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.13.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.13.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.13.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.13.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.13.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.13.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.13.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.13.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.13.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.14.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.14.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.14.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.14.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.14.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.14.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.14.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.14.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.14.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.14.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.14.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.14.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.15.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.15.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.15.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.15.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.15.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.15.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.15.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.15.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.15.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.15.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.15.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.15.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.16.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.16.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.16.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.16.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.16.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.16.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.16.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.16.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.16.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.16.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.16.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.16.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.17.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.17.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.17.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.17.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.17.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.17.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.17.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.17.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.17.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.17.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.17.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.17.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.18.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.18.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.18.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.18.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.18.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.18.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.18.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.18.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.18.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.18.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.18.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.18.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.19.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.19.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.19.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.19.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.19.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.19.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.19.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.19.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.19.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.19.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.19.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.19.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.2.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.2.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.2.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.2.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.2.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.2.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.2.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.2.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.2.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.2.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.2.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.2.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.20.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.20.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.20.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.20.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.20.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.20.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.20.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.20.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.20.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.20.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.20.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.20.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.21.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.21.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.21.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.21.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.21.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.21.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.21.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.21.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.21.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.21.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.21.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.21.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.22.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.22.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.22.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.22.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.22.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.22.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.22.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.22.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.22.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.22.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.22.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.22.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.23.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.23.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.23.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.23.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.23.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.23.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.23.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.23.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.23.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.23.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.23.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.23.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.24.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.24.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.24.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.24.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.24.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.24.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.24.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.24.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.24.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.24.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.24.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.24.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.25.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.25.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.25.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.25.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.25.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.25.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.25.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.25.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.25.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.25.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.25.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.25.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.26.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.26.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.26.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.26.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.26.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.26.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.26.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.26.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.26.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.26.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.26.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.26.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.27.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.27.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.27.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.27.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.27.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.27.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.27.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.27.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.27.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.27.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.27.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.27.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.3.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.3.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.3.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.3.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.3.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.3.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.3.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.3.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.3.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.3.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.3.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.3.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.4.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.4.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.4.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.4.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.4.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.4.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.4.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.4.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.4.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.4.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.4.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.4.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.5.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.5.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.5.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.5.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.5.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.5.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.5.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.5.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.5.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.5.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.5.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.5.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.6.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.6.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.6.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.6.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.6.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.6.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.6.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.6.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.6.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.6.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.6.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.6.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.7.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.7.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.7.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.7.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.7.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.7.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.7.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.7.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.7.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.7.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.7.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.7.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.8.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.8.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.8.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.8.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.8.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.8.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.8.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.8.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.8.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.8.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.8.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.8.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.9.attn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.9.ffn_down.weight, torch.bfloat16 --> Q8_0, shape = {8960, 1536}
INFO:hf-to-gguf:blk.9.ffn_gate.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.9.ffn_up.weight, torch.bfloat16 --> Q8_0, shape = {1536, 8960}
INFO:hf-to-gguf:blk.9.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.9.attn_k.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.9.attn_k.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:blk.9.attn_output.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.9.attn_q.bias, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:blk.9.attn_q.weight, torch.bfloat16 --> Q8_0, shape = {1536, 1536}
INFO:hf-to-gguf:blk.9.attn_v.bias, torch.bfloat16 --> F32, shape = {256}
INFO:hf-to-gguf:blk.9.attn_v.weight, torch.bfloat16 --> Q8_0, shape = {1536, 256}
INFO:hf-to-gguf:output_norm.weight, torch.bfloat16 --> F32, shape = {1536}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 131072
INFO:hf-to-gguf:gguf: embedding length = 1536
INFO:hf-to-gguf:gguf: feed forward length = 8960
INFO:hf-to-gguf:gguf: head count = 12
INFO:hf-to-gguf:gguf: key-value head count = 2
INFO:hf-to-gguf:gguf: rope theta = 10000
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 7
INFO:hf-to-gguf:Set model tokenizer
DEBUG:hf-to-gguf:chktok: [151646, 198, 4710, 14731, 65497, 7847, 1572, 2303, 78672, 10947, 145836, 320, 8252, 8, 26525, 114, 378, 235, 149921, 30543, 320, 35673, 99066, 97534, 8, 25521, 227, 11162, 99, 247, 149955, 220, 18, 220, 18, 18, 220, 18, 18, 18, 220, 18, 18, 18, 18, 220, 18, 18, 18, 18, 18, 220, 18, 18, 18, 18, 18, 18, 220, 18, 18, 18, 18, 18, 18, 18, 220, 18, 18, 18, 18, 18, 18, 18, 18, 220, 18, 13, 18, 220, 18, 496, 18, 220, 18, 1112, 18, 220, 146394, 97529, 241, 44258, 233, 146568, 44258, 224, 147603, 20879, 115, 146280, 44258, 223, 146280, 147272, 97529, 227, 144534, 937, 104100, 18493, 22377, 99257, 16, 18, 16, 19, 16, 20, 16, 35727, 21216, 55460, 53237, 18658, 14144, 1456, 13073, 63471, 33594, 3038, 133178, 79012, 3355, 4605, 4605, 13874, 13874, 73594, 3014, 3014, 28149, 17085, 2928, 26610, 7646, 358, 3003, 1012, 364, 83, 813, 566, 594, 1052, 11, 364, 787, 498, 2704, 30, 364, 44, 537, 2704, 358, 3278, 1281, 432, 11, 364, 35, 498, 1075, 1045, 15243, 30, 1205, 6, 42612, 264, 63866, 43]
DEBUG:hf-to-gguf:chkhsh: b3f499bb4255f8ca19fccd664443283318f2fd2414d5e0b040fbdd0cc195d6c5
DEBUG:hf-to-gguf:tokenizer.ggml.pre: 'deepseek-r1-qwen'
DEBUG:hf-to-gguf:chkhsh: b3f499bb4255f8ca19fccd664443283318f2fd2414d5e0b040fbdd0cc195d6c5
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type bos to 151646
INFO:gguf.vocab:Setting special token type eos to 151643
INFO:gguf.vocab:Setting special token type pad to 151643
INFO:gguf.vocab:Setting add_bos_token to True
INFO:gguf.vocab:Setting add_eos_token to False
INFO:gguf.vocab:Setting chat_template to {% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:../gguf/DeepSeek-R1-Distill-Qwen-1.5B-q8_0.gguf: n_tensors = 339, total_size = 1.9G
Writing: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.89G/1.89G [01:35<00:00, 19.9Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to ../gguf/DeepSeek-R1-Distill-Qwen-1.5B-q8_0.gguf
使用llama.cpp运行GGUF格式的模型
注: 这里需要根据实际情况修改模型路径, HuggingFace的模型权重路径是一个文件夹
llama-cli \
-m gguf/DeepSeek-R1-Distill-Qwen-1.5B-q8_0.gguf \
-n 2048 -c 2048 \
-p "You are a helpful assistant" -co -cnv \
--threads 8
测试提问:
你是谁?
写一段春联吧!
谢谢你,能否用刚刚春联的样式,写一首四句话的古诗?