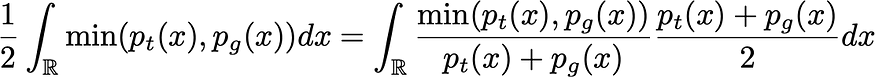目录
- 前言
- 1. cuOSD
- 1.1 Description
- 1.2 Getting started
- 1.3 For Python Interface
- 1.4 Demo
- 1.5 Performance Table
- 2. cuOSD案例
- 2.1 环境配置
- 2.2 simple案例
- 2.3 segment案例
- 2.4 segment2案例
- 2.5 polyline案例
- 2.6 comp案例
- 2.7 perf案例
- 3. cuOSD浅析
- 3.1 simple_draw函数
- 4. 补充知识
- 4.1 YUV简介
- 4.2 YUV格式
- 4.3 YCbCr简介
- 4.4 YUV和YCbCr
- 4.5 HDTV和SDTV
- 4.6 Alpha通道
- 结语
- 下载链接
- 参考
前言
学习 Lidar_AI_Solution 项目中的 cuOSD(CUDA On-Screen Display Library)
本文主要对 cuOSD 库进行简单分析并使用,博主为初学者,欢迎交流讨论,若有问题欢迎各位看官批评指正!!!😄
1. cuOSD
Copy自:https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution/tree/master/libraries/cuOSD/README.md
使用单个 CUDA 核绘制所有元素(Line、RotateBox、Circle、Rectangle、Text、Arrow、Point、Clock)
- Line:通过插值算法(最近邻插值或线性插值)绘制直线
- RotateBox:支持使用不同的边框颜色和填充颜色绘制
- Circle:支持使用不同的边框颜色和填充颜色绘制
- Rectangle:支持使用不同的边框颜色和填充颜色绘制
- Text:支持 stb_truetype 和 pango-cairo 后端,允许通过 TFF 或者使用 font-family 读取字体
- Arrow:通过 3 条线组合成箭头
- Point:通过插值算法(最近邻插值或线性插值)绘制点
- Clock:基于文本支持的时间绘图

1.1 Description
cuOSD 支持以下 pipeline 过程:
-
NV12 Block Linear → In-place OSD(with alpha)→ NV12 Block Linear
-
NV12 Pitch Linear → In-place OSD(with alpha)→ NV12 Pitch Linear
-
RGBA → In-place OSD(with alpha)→ RGBA
cuOSD 支持使用用户提供的属性绘制以下元素:
| Element Type | Element Attribute |
|---|---|
| Point | center x, center y, radius, color |
| Line | start x, start y, end x, end y, thickness, color, interpolation |
| Circle | center x, center y, radius, thickness, border color, background color |
| Rectangle | left, top, right, bottom, thickness, border color, background color |
| Rotated Rectangle | center x, center y, width, height, yaw, thickness, color |
| Arrow | start x, start y, end x, end y, arrow size, thickness, color, interpolation |
| Text | left upper x, left upper y, utf-8 text, font size, border color, background color |
| Clock | left upper x, left upper y, format, time, font size, border color, background color |
| Box Blur | left, top, right, bottom, kernel size |
| Segment Mask | left, top, right, bottom, thickness, seg mask, seg width, seg height, seg threshold, border color, seg color |
| Polyline | line points, thickness, is closed, border color, interpolation, fill color |
| rgba source | center x, center y, width, height, device buffer in rgba |
| nv12 source | center x, center y, width, height, device buffer in nv12, mask color, block linear |
- yaw:从 Y 轴开始的旋转角度,顺时针 +,单位为 rad
1.2 Getting started
文本绘制可使用在线和离线方式生成 text bitmap
- Online:在系统目录中搜索指定字体名称的 TFF 文件,然后使用 stb_truetype 库生成 bitmap
- Offline:生成具有预定义字符范围和字体大小的自定义 nvfont 文件,然后在 cuOSD 初始化过程中加载 nvfont 文件
运行 cuOSD demo tests
$ cd cuOSD && make run
$ ./cuosd --help
Usage:./cuosd simple./cuosd comp --line./cuosd perf --input=3840x2160/BL --font=data/my.nvfont --line=100 --rotatebox=100 --circle=100 --rectangle=100 --text=100 --arrow=100 --point=100 --clock=100 --save=output.png --seed=31./cuosd perf --input=1280x720/BL --font=data/my.nvfont --load=data/std-random-boxes.txt --save=output.png --seed=31Command List:./cuosd simpleSimple image rendering and save result to jpg file../cuosd comp --lineBenchmark test of drawing 100 lines using the same configuration as nvOSD../cuosd perf --input=3840x2160/BL --font=data/my.nvfont --line=100 --rotatebox=100 --circle=100 --rectangle=100 --text=100 --arrow=100 --point=100 --clock=100 --save=output.png --seed=31./cuosd perf --input=1280x720/BL --font=data/my.nvfont --load=data/std-random-boxes.txt --save=output.png --seed=31Perf test for given config.Prameters:--input: Set input size and format, Syntax format is: [width]x[height]/[format]format can be 'BL', 'PL', 'RGBA'--load: Load elements from file to rendering pipeline.--line: Add lines to rendering pipeline--rotatebox: Add rototebox to rendering pipeline--circle: Add circles to rendering pipeline--rectangle: Add rectangles to rendering pipeline--text: Add texts to rendering pipeline--arrow: Add arrows to rendering pipeline--point: Add points to rendering pipeline--clock: Add clock to rendering pipeline--save: Sets the path of the output. default does not save the output--font: Sets the font file used for text contexting.--fix-pos: All elements of the same kind use the same coordinates, not random--seed: Set seed number for random engine
1.3 For Python Interface
- 编译 pycuosd.so
$ make pycuosd
$ python test/pytest.py
OpenCV 971.628 ms
cuOSD 222.903 ms
Save result to output.png
1.4 Demo
在 1280x720/BL 输入上绘制 50 个矩形和 50 个带背景色的文本,在 Jetson-Orin, JP-5.0.2 GA 上耗时 1033.72 us

1.5 Performance Table
| Environment | Jetson-AGX Orin 64GB, JP-5.0.2 GA, BATCH=1, CPU@2201.6MHz, GPU@1300MHz, EMC@3199MHz, VIC@729.6MHz | |||
|---|---|---|---|---|
| Description | CLs for performance test: | |||
| SDK | cuOSD | nvOSD | ||
| Image Format | 1920x1080/BL | 1920x1080/PL | 1920x1080/RGBA | 1920x1080/RGBA |
| 100 Rect [us] | 598.81 | 598.99 | 616.60 | 24947(VIC)/2321(CPU) |
| 100 Text [us] | 935.02 | 934.92 | 967.30 | 6945 (CPU) |
| 100 Line [us] | 263.41 | 263.25 | 270.68 | 2586(CPU) |
| 100 Circle [us] | 226.71 | 226.86 | 230.15 | 14474(CPU) |
| 100 Arrow [us] | 520.76 | 521.06 | 534.42 | 3855(CPU) |
2. cuOSD案例
2.1 环境配置
由于 cuOSD 仅依赖于 CUDA,因此如果在系统环境变量中已经添加 CUDA 路径,则可以直接 make run 运行看效果,如果没有把 CUDA 添加到系统环境变量中,则手动指定下即可,如下所示:
# Makefile 第 22 行
CUDA_HOME := /usr/local/cuda-11.6
指定好之后,二话不说直接执行 make run 看下能否成功执行,如下图所示:

OK!成功运行了,起码整个代码没有问题,我们可以执行 ./cuosd --help 看看参数说明,如下图所示:

2.2 simple案例
案例我们一个个来看,首先是 simple 案例,simple_draw 函数的主要目的是在给定的图像上渲染一系列的检测框和文本。它从一个文本文件中读取检测框数据,并在给定的图像上渲染这些检测框和对应的文本。渲染完成后,它将图像保存为 “output.png”。
执行如下图所示:

运行结果如下图所示:

2.3 segment案例
segment 函数的目的是在给定的图像上渲染一系列的分割掩码和文本。它从一个文本文件中读取检测框数据,并在给定的图像上渲染这些分割掩码和对应的文本。渲染完成后,它将图像保存为 “output.png”。
执行如下图所示:

运行效果如下图所示:

2.4 segment2案例
segment2 主要目的是在一个指定的图像上渲染一个分割掩码,并测试此渲染操作的性能。它首先加载两个图像(一个主图像和一个掩码),然后在主图像上渲染掩码,并保存结果。接下来,它使用 CUDA 事件来测量渲染的性能,并将结果输出到控制台。最后,它保存渲染后的图像,并清理所有使用的资源。
执行如下图所示:

运行效果如下图所示:

2.5 polyline案例
polyline 主要目的是在一个指定的图像上渲染一个折线,并保存渲染后的图像。首先,它初始化一个 CUDA 流并创建一个图像。然后,它在这个图像上绘制一个折线,这个折线具有指定的顶点、宽度、颜色和填充颜色。最后,它保存渲染后的图像,并清理所有使用的资源。
执行如下图所示:

运行效果如下图所示:

2.6 comp案例
comp 的主要目的是在不同的图像格式上多次绘制图形元素,并评估这些操作的性能。该函数首先解析命令行参数以确定要绘制哪些图形元素,然后对于每种图像格式,它都会绘制这些元素,并测量执行时间。最后,它会打印性能数据并保存修改后的图像


2.7 perf案例
perf 的主要目的是评估在不同条件下(例如不同的图像格式、不同数量的图形元素等)绘图的性能。它首先解析命令行参数以确定要绘制哪些图形元素和相关设置,然后在指定的图像上绘制这些元素,并测量执行时间。最后,它会打印性能数据并可能保存修改后的图像。
执行完成后博主出现 Segmentation fault(core dumped) 错误,不知道是哪里出现了问题,博主后续也没有去调试分析,先这样吧。
3. cuOSD浅析
3.1 simple_draw函数
我们从 simple_draw 函数出发来简单分析下代码是如何运行的,代码如下:
static int simple_draw() {cudaStream_t stream = nullptr;checkRuntime(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking));printf("Simple draw.\n");auto context = cuosd_context_create();gpu::Image* image = gpu::create_image(1280, 720, gpu::ImageFormat::RGB);gpu::set_color(image, 255, 255, 255, 255, stream);gpu::copy_yuvnv12_to(image, 0, 0, 1280, 720, "data/image/nv12_3840x2160.yuv", 3840, 2160, 180, stream);gpu::save_image(image, "input.png", stream);std::ifstream in("data/std-random-boxes.txt", std::ios::in);std::string line;int nline = 0;const char* font_name = "data/simhei.ttf";while(getline(in, line)) {if (line.empty() || line[0] == '#') continue;auto words = split_with_tokens(line.c_str(), ",", true);if (nline == 0) {nline++;continue;}if (words[0] == "detbox") {if (words.size() != 9) {printf("Invalid number of detbox element. The accept format is [type, left, top, right, bottom, thickness, name, confidence, font_size]\n");break;}int left = std::atoi(words[1].c_str());int top = std::atoi(words[2].c_str());int right = std::atoi(words[3].c_str());int bottom = std::atoi(words[4].c_str());int thickness = std::atoi(words[5].c_str());std::string name = words[6];std::string confidence = words[7];int font_size = std::atoi(words[8].c_str());cuosd_draw_rectangle(context, left, top, right, bottom, thickness, {0, 255, 0, 255}, {0, 0, 255, 100});cuosd_draw_text(context, (name + " " + confidence).c_str(), font_size, font_name, left, top, {0, 0, 0, 255}, {255, 255, 0, 255});}nline++;}cuosd_apply(context, image, stream);cuosd_context_destroy(context);printf("Save to output.png\n");gpu::save_image(image, "output.png", stream);checkRuntime(cudaStreamDestroy(stream));return 0;
}
这个函数提供了一个简单的示例,展示了如何使用 cuOSD 库的功能在图像上绘制检测框和相关文本。
simple_draw 函数首先创建了一个非阻塞的 CUDA 流,用于后续 GPU 的并行操作,然后创建了一个 cuOSD 库的 context 用于管理上下文。由于我们读取的是 3840x2160 的 YUV 格式数据,要将其转换成为 RGB 格式,因此我们通过 gpu::create_image 在 GPU 上创建了一个 1280x720 大小的 RGB 空白图像
那你可能会问,为什么 YUV 格式的图像是 3840x2160 大小的,而转换成 RGB 格式只有 1280x720 的大小?那它其实是进行了缩放的,它将宽高等比例缩小了3倍
我们来看下函数 gpu::copy_yuvnv12_to 是如何将 YUV 数据转换成 RGB 图像的,在这个函数里我们首先通过 load_yuvnv12 函数加载文件中的 YUV 数据,具体来说我们会先判断 YUV 的宽高是否能整除 2,然后将 YUV 文件以二进制的方式读入,读入后我们会对 YUV 的 size 进行一个检查,确保我的读入的 YUV 图像的尺寸没有问题,具体代码如下:
static Image* load_yuvnv12(const char* file, int width, int height, cudaStream_t stream) {...// check yuv sizesize_t file_size = infile.tellg();size_t y_area = width * height;size_t except_size = y_area * 3 / 2;if (file_size != except_size) {fprintf(stderr, "Wrong size of yuv image : %lu bytes, expected %lu bytes\n", file_size, except_size);return nullptr;}...}
那你可能会困惑,我们期望的 YUV 的尺寸为什么会是 width * height * 3 / 2 呢?这需要你了解 YUV 格式的数据存储的方式,这里简单说明下,具体细节可看 4.2 小节
首先 YUV 存储格式有多种,这里的 YUV 采用的是 NV12 的格式,如下图所示,也就是说我们会先存储所有像素点 Y,紧接着 UV 交错存储。而 YUV 的采样格式也存在多种,一般最常见的就是 4:2:0,即每四个 Y 分量共用一组 UV 分量,因此对于一个 3840x2160_NV12 的 YUV 的图像我们说的宽高 3840x2160 其实指的是 Y 分量的大小,而 UV 分量是交错存储的,它的高度只有 Y 分量高度的一半,所以 NV12 格式的 YUV 图像整体大小为 width x height + width x height / 2 = width x height * 3 / 2,其中第一部分是 Y 分量的大小,第二部分是 UV 分量的大小,因此我们在 load_yuvnv12 函数中看到了上面的 size 检查代码。

随后我们在 CPU 上开辟了一块空间 host_memory,将 YUV 文件中的数据读取到分配的内存中,接下来在 GPU 上也开辟了一块内存空间 output,然后将 CPU 上的 YUV 图像数据通过 cudaMemcpyAsync 从 host 上复制到 device 上,这里的 Y 分量和 UV 分量分别复制到了 output→data0 和 output→data1。最后进行流同步确保所有异步复制操作都完成,然后就是释放主机内存,返回 output
这就是整个 YUV 图像数据加载的过程,它会读取一个 NV12 格式的 YUV 文件并将其内容复制到 GPU 上的一个图像对象中。
是不是很像 tensorRT 模型推理的过程,先准备图像数据,然后分别开辟一块 CPU 和 GPU 空间,把我们图像数据放到 CPU 上,然后利用 cudaMemcpyAsync 将 CPU 上的图像数据放到 GPU 上,然后进行一系列预处理、推理等过程🤔
我们再回到 copy_yuvnv12_to 函数中,拿到了 GPU 上的 YUV 图像数据,我们会根据最终想要的图像格式启动不同的 CUDA 核函数,在这里我们当然是希望 YUV 图像数据转换为 RGB 图像,因此我们启动的核函数就是 copy_nv12_to_rgb,代码如下:
if (image->format == ImageFormat::RGB) {dim3 block(32, 32);dim3 grid((dst_w + block.x - 1) / block.x, (dst_h + block.y - 1) / block.y);copy_nv12_to_rgb<<<grid, block, 0, stream>>>((unsigned char*)image->data0, dst_x, dst_y, dst_w, dst_h, image->width, image->height,(unsigned char*)yuv->data0, (unsigned char*)yuv->data1, yuv->width, yuv->height);
}
可以看到开启的线程数是目标 RGB 图像的宽和高即 1280x720,我们来简单看下传入 CUDA 核函数的参数:
- (unsigned char*)image->data0:代表 RGB 图像数据
- dst_x:0,代表目标图像 x 起点
- dst_y:0,代表目标图像 y 起点
- dst_w:1280,代表目标图像宽度
- dst_h:720,代表目标图像高度
- image->width:1280,RGB 图像宽度
- image->height:720,RGB 图像高度
- (unsigned char*)yuv->data0:Y 分量
- (unsigned char*)yuv->data1:UV 分量
- yuv->width:3840,YUV 图像的宽度
- yuv->height:720,YUV 图像的高度
OK!看完了参数,我们来看看核函数内部具体是如何实现将 YUV 图像复制到 RGB 上的,代码如下:
static __global__ void copy_nv12_to_rgb(unsigned char* rgb, int dst_x, int dst_y, int dst_w, int dst_h, int dst_width, int dst_height,unsigned char* nv12_y, unsigned char* nv12_uv, int nv12_w, int nv12_h
) {int ix = (blockDim.x * blockIdx.x + threadIdx.x);int iy = (blockDim.y * blockIdx.y + threadIdx.y);if (ix >= dst_w || iy >= dst_h) return;int nx = ix * nv12_w / (float)dst_w;int ny = iy * nv12_h / (float)dst_w;unsigned char value_y = nv12_y [(ny + 0) * nv12_w + nx ];unsigned char value_u = nv12_uv[(ny / 2) * nv12_w + round_down2(nx) + 0];unsigned char value_v = nv12_uv[(ny / 2) * nv12_w + round_down2(nx) + 1];ix += dst_x;iy += dst_y;yuv2rgb(value_y, value_u, value_v, rgb[(iy * dst_width + ix) * 3 + 0], rgb[(iy * dst_width + ix) * 3 + 1], rgb[(iy * dst_width + ix) * 3 + 2]);
}
首先一进来就是线程索引的计算,是一个 2-dim 的 Layout,因此只有 ix 和 iy。通过内置变量 blockDim、blockIdx、threadIdx 来完成计算,具体计算方式可以查看 YOLOv5推理详解及预处理高性能实现,大家如果对之前的 warpAffine 核函数熟悉的话这应该不在话下
然后我们会计算源图像 YUV 的坐标 nx 和 ny,这里是一个关键部分,因为 RGB 图像(目标图像)和 YUV 图像(源图像)可能有不同的尺寸,我们需要为每个目标像素找到一个对应的源像素,这点是通过线性插值完成的。类似于仿射变换中的双线性插值
接下来我们会通过 nx 和 ny 获取 Y、U 和 V 的值,值得注意的是,NV12 格式中 U 和 V 是交替存储的,而且每四个 Y 像素共享一个 UV 像素,因此 UV 分量的高度其实只有 Y 分量的一半,这也是为什么我们除以 2 并使用 round_down2 函数的原因,round_down2 函数的功能是给定无符号整数 num 向下舍入最近的偶数。这个可能有点难理解,大家需要仔细对照 NV12 格式的存储图像,多画画
Y、U、V 的值我们拿到了,要填充的 R、G、B 的位置我们也知道了,现在就是要进行转换了,给你一个 Y、U、V 的值怎么转换成对应的 R、G、B 呢?当然肯定是有一套公式的,那么在代码中我们是通过 yuv2rgb 这个函数实现的,它就是我们提到的 YUV 到 RGB 的转换公式,它获取 Y、U 和 V 值,并为 RGB 图像的每个通道计算对应的 R、G 和 B 值,函数实现代码如下:
static void __host__ __device__ __forceinline__ yuv2rgb(unsigned char y, unsigned char u, unsigned char v, unsigned char& r, unsigned char& g, unsigned char& b) {int c = ((int)y - 16) * 298;int d = (int)u - 128;int e = (int)v - 128;r = u8cast(( (c + 409 * e + 128) ) >> 8);g = u8cast(( (c - 100 * d - 208 * e + 128) ) >> 8);b = u8cast(( (c + 516 * d + 128) ) >> 8);
}
那你可能会好奇,这个公式到底咋来的呢?
博主去网上搜了一圈,并没有发现比较明确和权威的转换说明,于是乎去维基百科中查到了如下的转换公式,参考自 YUV conversion to/from RGB


可以看到转化公式不止一个,这是因为不同的色彩标准导致的,而 HDTV 和 SDTV 是两种不同的电视信号标准,更多细节请查看 4.5 小节
仔细对比你会发现无论是那个转换矩阵都貌似也对不上呀,难道说维基百科中的转换是错的?还是说代码写错了?
这里就有一个细节需要大家留意了,特别注意,在 yuv2rgb 函数中其实是使用了标准的 YCbCr 到 RGB 的转换公式。注意,虽然我们经常说 YUV,但在这种情况下,我们实际上是指 YCbCr,这是一个稍微不同的颜色空间
因此,当你傻乎乎的去维基百科上面查找 YUV2RGB 的公式时,你会发现它和代码中的公式根本对应不上,因为你要查找的其实是 YCbCr2RGB 的公式,维基百科中的 YCbCr2RGB 的转换公式如下,参考自 YCbCr-ITU-R_BT.601_conversion


同理,YCbCr2RGB 的转换公式由于色彩标准的不同也存在多个,这里拿代码中使用的公式的色彩标准(BT.601)为例,其中第一个公式包含了四舍五入,第二个公式则没有,我们将上面的第二个公式进行化简后可以得到如下的公式:
R D ′ = 1.164 ⋅ ( Y ′ − 16 ) + 1.596 ⋅ ( C R − 128 ) G D ′ = 1.164 ⋅ ( Y ′ − 16 ) − 0.392 ⋅ ( C B − 128 ) − 0.813 ⋅ ( C R − 128 ) B D ′ = 1.164 ⋅ ( Y ′ − 16 ) + 2.017 ⋅ ( C B − 128 ) \begin{aligned} R_D' &= 1.164 \cdot (Y'-16)+1.596 \cdot (C_R-128) \\ G_D' &= 1.164 \cdot (Y'-16)- 0.392 \cdot (C_B-128) -0.813 \cdot (C_R-128) \\ B_D' &= 1.164 \cdot (Y'-16) +2.017 \cdot (C_B-128) \end{aligned} RD′GD′BD′=1.164⋅(Y′−16)+1.596⋅(CR−128)=1.164⋅(Y′−16)−0.392⋅(CB−128)−0.813⋅(CR−128)=1.164⋅(Y′−16)+2.017⋅(CB−128)
你会发现这和我们在网上搜到的 YUV2RGB 的公式一样,可参考文章 YUV 格式与 RGB 格式的相互转换公式及C++ 代码
那它是如何和我们的代码中的公式对应上的呢?我们将维基百科中的公式转换为整数数学,并以 8 位精度放大所有系数,我们将得到:
R D ′ = ( Y ′ − 16 ) × 298 + ( C R − 128 ) × 409 256 G D ′ = ( Y ′ − 16 ) × 298 − ( C B − 128 ) × 100 − ( C R − 128 ) × 208 256 B D ′ = ( Y ′ − 16 ) × 298 + ( C B − 128 ) × 516 256 \begin{aligned} R_D' &= \frac{(Y'-16) \times 298 + (C_R-128) \times 409}{256} \\ G_D' &= \frac{(Y'-16) \times 298 -(C_B-128) \times 100 - (C_R-128) \times 208}{256} \\ B_D' &= \frac{(Y'-16) \times 298 +(C_B-128) \times 516}{256} \end{aligned} RD′GD′BD′=256(Y′−16)×298+(CR−128)×409=256(Y′−16)×298−(CB−128)×100−(CR−128)×208=256(Y′−16)×298+(CB−128)×516
可以看到和代码中的差不多,为什么说差不多而不是一模一样呢?是因为代码中还加上了 128 来确保四舍五入,同时代码是通过移位来除以 256 的
那你可能会问,为什么都要转换成整数再进行计算呢?直接用小数相乘不就行了嘛?🤔
那其实这样做的目的是出于对性能和精度的考虑,首先计算效率方面,整数运算通常比浮点数更快,尤其是在 GPU 上,整数操作的吞吐量可能更高,其次是存储和带宽方面,整数通常需要较少的存储空间和带宽。我们还注意到除以 256 这个操作,代码中是利用位操作来实现的,这主要是因为像 GPU 这样的并行硬件中,位操作可以更高效地在多个数据上同时执行,这是一个优化技巧,可以加速计算实现高性能处理
那你可能会想明明是 YUV2RGB 的转换,为什么会扯到 YCbCr2RGB 上呢?其实 YUV 和 YCbCr 这两个术语有时候指的是一回事,具体可以参考 4.4 小节
OK,YUV2RGB 的公式转换搞定了,我们再回到核函数 copy_nv12_to_rgb 中讨论下几个问题
第一个问题就是我们的 YUV 图像是 3840x2160 大小,而我们准备的 RGB 图像只有 1280x720 的,一个 YUV 像素对应一个 RGB 像素,那么我们也应该准备一个同样大小的 RGB 图像才对,而我们准备的 RGB 图像只有 YUV 的三分之一大小,那这个是怎么完成的呢?
其实这个我们之前说到了,这里再回顾下,它是通过如下代码实现的:
int nx = ix * nv12_w / (float)dst_w;
int ny = iy * nv12_h / (float)dst_w;
ix,iy 其实可以看作 RGB_1280x720 上的某个像素点的 x,y 坐标,同样 nx,ny 可以看作 YUV_3840x2160 上的某个像素点的 x,y 坐标,可以看到对于 RGB 图像中的每个像素,我们并不是简单地从 YUV 图像中选取对应的像素,而是根据比例来确定要选取的像素,这实际上是一个插值操作。当前的 RGB 的宽度刚好是 YUV 的宽度的三分之一,那么每隔两个像素,RGB 图像取 YUV 图像的一个像素,这就是所谓的下采样。去 YUV 源图像取值然后填充到 RGB 目标图像这个操作有点像 warpAffine 的味道了
那细心的看官可能会发现在 ny 的计算中我们除以的是 dst_w,正常来说不是除以 dst_h 吗?是不是博主 copy 错了?🤔那其实是没有,源码就是这么写的,博主也没有做任何改变
博主尝试对比了除以 dst_w 和 dst_h 发现对结果没有影响,人眼确实看不出啥区别,但是博主发现在其它核函数的实现过程中,例如 copy_nv12_to_rgba 中除以的却是 dst_h,那可能是个 bug 吧,博主使用的代码下载于 2023/8/6日
后面请教了下杜老师,发现确实是个 bug,杜老师已经提交 commit 修复了,大家可以正常使用了,修复时间为 2023/8/19日
第二个探讨的问题是四个 Y 分量共用一组 UV 分量,这四个 Y 分量具体是指那四个?

上图描述得非常清楚了,从右边的采样图可以看出是上下的四个 Y 共用一组 UV,而并不是连续四个 Y 分量,左边的存储图也可以看出来,例如第一行的两个 Y 和第二行的两个 Y 共享一组 UV 分量。
第三个探讨的问题是关于 YUV2RGB 公式转换问题,那其实博主在其它文章中有看到说在 Keith Jack 写的 Video Demystified 这本书中有提到不同颜色空间之间的转换关系,这边把书籍分享给大家:
-
PDF在线链接:https://doc.lagout.org/Others/Demystified%20Series/VideoDemystified.pdf
-
PDF下载链接:Baidu Driver【pwd:1234】
在这本书的第 19 页就提到了在 BT.601 标准下的关于 YCbCr 和 RGB 的转换公式,如下图所示:

OK!那么以上就是 copy_yuvnv12_to 函数的分析,该函数将读取的 YUV 源图像复制到 RGB 图像中,后续我们的绘制都是在 RGB 图像中实现的,我们分析了这么久,竟然还没有谈论到如何利用 cuOSD 库去绘制矩形框和文本上,还只是简单分析了如何将 YUV 图像转换为 RGB 图像。😂
那我们重新回到 simple_draw 函数这,经过 copy_yuvnv12_to 函数我们总算是拿到了我们想要绘制的 RGB 图像,同时将转换的 RGB 图像保存为 “input.png”。之后,我们读取了一个 TXT 文件,该文件包含了多个检测框的信息,如位置、名称、置信度、字体大小,我们会对文件进行解析,获取每个检测框的信息,最终将获取到的框信息通过 cuosd_draw_rectangle 函数绘制每个检测框,通过 cuosd_draw_text 函数绘制与每个检测框关联的文本,展示检测物体的名称和置信度。
完成所有绘制操作后,利用 cuosd_apply 函数将这些绘图操作应用到图像上,生成最终的输出图像。最后,将带有检测框和文本的图像保存为 “output.png”,并释放 context 和 stream 等资源。整个过程确保了图像的快速加载、转换和绘制,充分利用了 GPU 的高效并行计算能力。
我们重点来看 cuosd_draw_rectangle 和 cuosd_draw_text 两个绘制函数
首先是矩形框绘制函数 cuosd_draw_rectangle,我们先来看下它的参数:
- context:管理上下文
- (left,top,right,bottom):检测框信息
- thickness:边框厚度
- border_color:边框颜色
- bg_color:背景颜色
其它参数好理解,就是这个颜色的类型 cuOSDColor 为什么会要提供四个参数呢?像我们平时利用 opencv 绘制的时候不是只要提供 r,g,b 通道的数值就行吗?我有注意到它是一个结构体,定义如下:
typedef struct _cuOSDColor {unsigned char r;unsigned char g;unsigned char b;unsigned char a;
} cuOSDColor;
可以看到它多了一个 a 参数,a 在 cuOSDColor 结构体中代表 alpha 通道,也被称为透明度或不透明度通道。更多细节可看 4.6 小节内容
一进来,函数先将 context 指针类型从 cuOSDContext* 转换为 cuOSDContextImpl*,有点类似于接口模式,cuOSDContext 是一个抽象类型,它隐藏了真正的 cuOSDContextImpl 结构的细节,通过转换,函数可以访问和操作 cuOSDContextImpl 结构体的所有成员和功能,cuOSDContextImpl 结构体的定义如下:
struct cuOSDContextImpl : public cuOSDContext{unique_ptr<Memory<TextLocation>> text_location;unique_ptr<Memory<int>> line_location_base;vector<shared_ptr<cuOSDContextCommand>> commands;vector<shared_ptr<cuOSDContextCommand>> blur_commands;unique_ptr<Memory<unsigned char>> gpu_commands; // TextCommand, RectangleCommand etc.unique_ptr<Memory<BoxBlurCommand>> gpu_blur_commands; // TextCommand, RectangleCommand etc.unique_ptr<Memory<int>> gpu_commands_offset; // sizeof(TextCommand), sizeof(TextCommand) + sizeof(RectangleCommand) etc.shared_ptr<TextBackend> text_backend;#ifdef ENABLE_TEXT_BACKEND_PANGOcuOSDTextBackend text_backend_type = cuOSDTextBackend::PangoCairo;#elsecuOSDTextBackend text_backend_type = cuOSDTextBackend::StbTrueType;#endifbool have_rotate_msaa = false;int bounding_left = 0;int bounding_top = 0;int bounding_right = 0;int bounding_bottom = 0;
};
然后函数会检查传入的坐标,确保它是正常的即左坐标小于右坐标,上坐标小于下坐标,这有助于防止矩形被错误绘制。接着我们会去判断边框的透明度和背景颜色,确保没问题后,我们创建了一个绘制矩形命令的共享指针 cmd,通过 cmd 定义需要绘制矩形框的各种属性,最后将这个 cmd 添加到 context 的命令列表 commands 中,随后如果 thickness 不等于 -1,我们又再次创建了一个矩形框绘制指令 cmd,然后又填充了一堆属性数值,这边还填充了两个框的属性,最后将这个 cmd 添加到了 context 的命令列表 commands 中。
噢,我已经迷糊了😵,有一堆困惑,我们一个个来看吧
首先我们来梳理下矩形框的绘制流程:
它并不像 opencv 绘制图像一样,给我框信息然后把它绘制到图像中。我们在这里首先创建了一个矩形框绘制结构体 RectangleCommand 的智能指针,并在这个结构体中填入了我们绘制所需要的一些属性,然后将智能指针 push 到 context 中的 commands 中存储下来,最后我们应该是通过函数 cuosd_apply 来处理这些指令并在 GPU 上进行实际渲染。那这样的设计可以将绘图指令的创建和实际的渲染操作分开,允许更多的优化和灵活性,同时可以利用 GPU 的并发能力实现高性能。
然后就是我的第一个困惑,明明我们只需要绘制一个矩形框,那么创建一个 cmd 矩形框绘制指令就行了,为什么在 cuosd_draw_rectangle 中创建了两个 cmd 呢?🤔
博主有注意到在第一个 cmd 中有将 thickness 设置为了 -1,而在 RectangleCommand 结构体的描述中 thickness = -1 表示填充模式,因此博主认为第一个 cmd 是用来填充整个矩形区域的,为了实现透明度的效果,而第二个 cmd 才是真正的绘制带指定厚度的边框的,也就是我们实际的矩形框,因为代码在绘制前有判断如果 thickness 等于 -1 则直接返回,此时代表的是填充模式。
然后就是我的第二个困惑,为什么 RectangleCommand 结构体有这么多参数需要指定呢?正常不是只需要 left,top,bottom,right 几个参数吗?🤔
那我们先来看看 RectangleCommand 结构体的定义,如下所示:
// RectangleCommand:
// ax1, ..., dy1: 4 outer corner points coordinate of the rectangle
// ax2, ..., dy2: 4 inner corner points coordinate of the rectangle
// a1 ------ d1
// | a2---d2 |
// | | | |
// | b2---c2 |
// b1 ------ c1
// thickness: border width in case > 0, -1 stands for fill mode
struct RectangleCommand : cuOSDContextCommand{int thickness = -1;bool interpolation = false;float ax1, ay1, bx1, by1, cx1, cy1, dx1, dy1;float ax2, ay2, bx2, by2, cx2, cy2, dx2, dy2;RectangleCommand();
};
其实结构体的描述已经非常清楚了,我们来看下面的示例:
// a d
// b c
在当前情形中,一个矩形框我们是通过四个坐标来描述的,如上所示 a,b,c,d;其中 ax1,ay1 代表 a 点的 x,y 坐标,bx1,by1 代表 b 点的 x,y 坐标,cx1,cy1 代表 c 点的 x,y 坐标,dx1,dy1 代表 d 点的 x,y 坐标。
其次 cmd 还有一些属性,如 bounding_left、bounding_right 等,其实是 RectangleCommand 父类 cuOSDContextCommand 的一些属性,cuOSDContextCommand 结构体的定义如下:
// cuOSDContextCommand includes basic attributes for color and bounding box coordinate
struct cuOSDContextCommand{CommandType type = CommandType::None;unsigned char c0, c1, c2, c3;int bounding_left = 0;int bounding_top = 0;int bounding_right = 0;int bounding_bottom = 0;
};
它包括的是一些最基本的元素,比如边界框的左上、右下坐标等
第三个困惑是为什么在第二个 cmd 创建矩形框绘制命令中,对两个框的属性进行了赋值操作,正常不是一个框就行吗?🤔
首先,我们来仔细看下 RectangleCommand 结构体的描述:
// RectangleCommand:
// ax1, ..., dy1: 4 outer corner points coordinate of the rectangle
// ax2, ..., dy2: 4 inner corner points coordinate of the rectangle
// a1 ------ d1
// | a2---d2 |
// | | | |
// | b2---c2 |
// b1 ------ c1
// thickness: border width in case > 0, -1 stands for fill mode
从上述描述可以看出,结构体中提到了两套坐标点集 ax1, …, dy1 和 ax2, …, dy2,它们分别代表矩形的外部和内部角点坐标。结构体的图示进一步描述了这两套坐标的关系,其中 a1, b1, c1, d1 代表外部矩形,而 a2, b2, c2, d2 代表内部矩形。
在 cuosd_draw_rectangle 函数中,当为矩形指定了一个 thickness 时,它会使用这两套坐标来绘制矩形的边框。外部矩形(用 ax1, …, dy1 表示)的坐标是根据指定的 left, top, right, bottom 以及一半的 thickness 计算得出的。内部矩形(用 ax2, …, dy2 表示)的坐标是根据指定的 left, top, right, bottom 以及另一半的 thickness 计算得出的。
因此,这两套坐标共同定义了一个带有指定厚度的矩形边框。外部矩形定义了边框的外边界,而内部矩形定义了边框的内边界。通过这种方式,您可以绘制一个带有特定厚度的矩形边框,而不仅仅是一个薄薄的线条。
OK!以上就是关于 cuosd_draw_rectangle 函数的分析,下面我们来简单分析下文本绘制函数 cuosd_draw_text 的具体实现,我们先来看下它的参数:
- context:管理上下文
- utf8_text:绘制的文本内容,由 name + confidence 组成
- font_size:文本字体大小
- font:字体名称
- x,y:文本绘制的起始坐标
- border_color:文本边框的颜色
- bg_color:文本背景颜色
首先一进来,还是将 cuOSDContext* 类型的 context 转换为 cuOSDContextImpl* 类型,然后会检查当前 context 是否存在一个文本后端,如果没有则会根据 context 的 text_backend_type 创建一个新的文本后端,如果创建后依旧不存在,则会打印错误信息并返回。
接下来我们会使用文本后端输入的 utf8_text 分割为单词列表,如果单词列表为空或者字体大小小于等于 0 则函数将返回,然后我们会调整 font_size 字体大小放大 3 倍,为了和 nvOSD 效果保持一致。随后,我们使用文本后端测量了文本的宽度、高度和 y 偏移量,如果背景色的透明度 a 不为 0,则我们会在文本周围以填充的方式绘制一个背景矩形,直接调用的就是 cuosd_draw_rectangle 函数,最后,和之前分析矩形框绘制类似,我们将一个新的 TextHostCommand 文本绘制命令添加到 context 的命令列表中。
TextHostCommand 结构体的定义如下:
struct TextHostCommand : cuOSDContextCommand{TextCommand gputile;vector<unsigned long int> text;unsigned short font_size;string font_name;int x, y;TextHostCommand(const vector<unsigned long int>& text, unsigned short font_size, const char* font, int x, int y, unsigned char c0, unsigned char c1, unsigned char c2, unsigned char c3) {this->text = text;this->font_size = font_size;this->font_name = font;this->x = x;this->y = y;this->c0 = c0;this->c1 = c1;this->c2 = c2;this->c3 = c3;this->type = CommandType::Text;}
};
cuosd_draw_text 整体工作流程如下:
首先,它确保有一个有效的文本后端来处理文本相关的操作。然后,它将输入的UTF-8文本分割为单词列表,并测量这些单词的尺寸。接着,它根据需要在文本周围绘制背景矩形。最后,它创建一个代表文本绘制请求的命令,并将这个命令添加到命令列表中。
OK!以上就是关于 **cuosd_draw_text **文本绘制函数的分析。
我们 context 的命令列表中已经存储着各种框和文本的绘制指令,我们来看下具体是如何将这些指令绘制在图像上的,也就是 cuosd_apply 函数的具体实现
main.cpp 中的 cuosd_apply 函数中就传入了 context,image 以及 stream 三个参数,它实际调用的是 cuosd.cpp 中的 cuosd_apply 函数,我们来看下在 cuosd.cpp 中该函数的具体实现,我们先来看下它的参数:
-
context:管理上下文
-
data0,data1:图像数据,对于 RGB 图像而言只需要 data0
-
width,stride,height:width 和 height 代表图像宽高,而 stride 代表图像的行跨度,通常是图像宽度和像素大小的乘积,但有时为了内存对齐会稍微大一些。在这里 stride = width * 3 = 1280 x 3 = 3840,其中 3 代表 R、G、B 三个通道
-
format:图像格式(如 RGB、YUV 等)
-
stream:CUDA 流
-
launch_and_clear:布尔变量,是否启动渲染命令并清楚
首先 context 转换为 cuOSDContextImpl* 类型,然后检查下是否有渲染命令,以及 context 的命令队列是否为空,如果有且命令队列不为空则继续执行
接下来调用了 cuosd_text_perper 函数为渲染做准备,这涉及计算文本的大小和位置等,随后计算了渲染命令的边界框,遍历命令队列将所有的渲染命令从主机(CPU)内存复制到设备(GPU)内存中,最后调用 cuosd_launch 函数实现渲染命令绘制
所以说还没绘制,真正还要去看 cuosd_launch 函数的具体实现😱,麻了麻了,它的参数和 cuosd_apply 一致,这边就跳过分析了
首先它会将 context 转换为 cuOSDContextImpl*,然后判断是否存在渲染命令以及命令队列是否为空,如果是则函数直接返回,并打印警告信息。接下里准备文本位图数据,并调用核心 CUDA 渲染核函数 cuosd_launch_kernel:
- 这是核心的渲染核函数,它在 GPU 上执行
- 传递的参数包括目标图像的数据、尺寸和格式、文本渲染的相关数据、渲染命令的数据以及其他必要的信息。
- 这些参数为核心渲染函数提供了所有必要的信息,使其能够在目标图像上渲染文本、矩形、圆等图形。
我们来简单看下这个核函数,它其实并不是真正的执行函数,它只是一个分发函数,它根据传入的图像格式和其他参数,选择合适的核函数进行执行。这个分发函数确保对于不同的输入类型和配置,都能选择到正确的核函数进行处理。在这个分发函数中,实际的绘制工作是由 cuosd_launch_blur_kernel_impl 和 cuosd_launch_kernel_impl 这两个函数完成的,cuosd_launch_kernel 只是根据传入参数选择合适的函数进行调用。
我们来重点关注下渲染的实现函数 cuosd_launch_kernel_impl 的具体实现
注意:真正渲染部分的代码实现博主还没来得及仔细看(后续有时间再补充吧😂),只是经过 chatGPT 的分析后简单过了一遍,这里把 chatGPT 的分析 copy 了过来,具体逻辑需要各位看官自己去分析了。
该函数 cuosd_launch_kernel_impl 是一个模板函数,它将绘制指令应用到提供的图像数据上。此函数根据传入的图像格式和是否进行旋转/多重采样抗锯齿(MSAA)来渲染。具体来看,函数的主要逻辑如下:
- 模板参数:
- ImageFormat format:图像的格式,如RGB、RGBA等。
- bool have_rotate_msaa:表示是否进行旋转或MSAA处理。
- 修正边界坐标:
- bounding_left、bounding_top、bounding_right、bounding_bottom 代表需要绘制的区域的边界。函数首先修正这些坐标值,确保它们落在有效的图像范围内。
- 使用 round_down2 函数进一步修正 bounding_left 和 bounding_top,使其向下舍入到最近的偶数。
- 计算边界宽度和高度:
- 根据修正后的边界坐标计算需要渲染的区域的宽度和高度。
- 如果宽度或高度小于 1,将输出一个警告并返回,因为这意味着没有任何内容需要绘制。
- 核函数配置:
- dim3 block(16, 8) 定义了每个 CUDA block 的线程布局。
- dim3 grid 计算了启动的 CUDA blocks 的数量。这里,grid 的维度计算确保覆盖整个绘制区域。
- 核函数调用:
- 调用 render_elements_kernel 核函数,该核函数实际上处理了绘制的工作。这个函数在 GPU 上执行,并处理渲染任务。它使用 format 和 have_rotate_msaa 参数来确定如何处理图像数据。
- 错误检查:
- 使用 cudaPeekAtLastError 函数来检查核函数调用是否有任何错误。如果有错误,将输出一个错误消息。
这个函数的主要工作是设置正确的绘制边界、计算核函数的配置和调用核函数。真正的绘制逻辑是在 render_elements_kernel 核函数中实现的,这是一个在 GPU 上运行的函数,用于应用提供的绘制指令到图像数据上。
最后的最后我们来看下最最最核心的核函数 render_elements_kernel 的具体实现:
这是一个 CUDA 核函数,用于将各种绘制指令渲染到图像上。核函数是在 GPU 上运行的,处理大量并行操作。函数首先确定当前的像素位置,然后根据提供的绘制指令进行渲染。以下是函数的详细分析:
- 模板参数:
- ImageFormat format: 图像格式,例如 RGB、RGBA 等。
- bool have_rotate_msaa: 表示是否进行旋转或 MSAA 处理。
- 函数参数:
- bx, by: 边界起始位置,用于定位要渲染的区域。
- text_locations, text_bitmap, text_bitmap_width, line_location_base: 文本渲染所需的相关数据。
- commands, command_offsets, num_command: 绘制指令的数据。
- image0, image1: 图像数据指针。
- image_width, stride, image_height: 图像的宽度、行宽和高度。
- 确定像素位置: 根据 CUDA 的 blockIdx、blockDim 和 threadIdx 计算当前像素的位置 (ix, iy)。如果像素位置超出图像边界,函数会立即返回,不进行任何操作。
- 遍历绘制指令: 核函数遍历所有的绘制指令。对于每个绘制指令:
- 检查像素是否在命令的边界内。如果不在,则跳过此命令。
- 根据命令类型,调用相应的绘制函数。例如,对于矩形命令,调用 do_rectangle 函数。
- 处理文本命令: 对于文本命令,函数会遍历所有文本位置并调用 render_text 函数进行渲染。
- 处理其他命令: 对于其他命令(如圆、线段、多边形填充等),核函数会调用相应的渲染函数。
- 检查是否需要混合: 如果 context_color 中的所有颜色都是透明的(alpha 值为 0),则不需要进行任何混合操作。
- 混合操作: 使用 BlendingPixel 函数进行混合操作。这将基于 context_color 和原始图像数据进行混合。
总之,render_elements_kernel 核函数为每个像素执行绘制操作。它首先确定像素位置,然后遍历所有的绘制指令,根据命令类型调用相应的渲染函数。最后,它使用混合函数将绘制的结果与原始图像数据进行混合。
那其实这还没完,真实的绘制还要去调用诸如 do_rectangle、render_text 等函数,那这些函数里面可能还套着具体实现的函数,反正就是各种套娃,博主的能力和精力有限,这次就先分析到这吧😂
OK!以上就是关于 simple_draw 函数的简单分析,若有问题欢迎各位看官讨论😃
4. 补充知识
4.1 YUV简介
参考自:Y’UV-Wikipedia
YUV 是一种颜色空间,经常用于数字视频编码。它将图像信息分为亮度成分(Y)和两个色差成分(U和V),其中,Y 表示图像的亮度信息(Luminance、Luma),而 U 和 V 表示图像的色彩信息(Chrominance、Chroma)。值得注意的是,关于词源 Y、U、V 并非缩写,用字母 Y 表示亮度可以追溯到 XYZ 基色的选择,而选择 U 和 V 是为了将 U 和 V 轴与其他色彩空间(如x和y色度空间)中的轴区分开来
Y(亮度或灰度):它代表了黑白图像的亮度信息,也是人眼对图像的主要感知。在一个黑白电视或显示器上,只有 Y 信号会被使用
U和V(色度、色差或色彩信息):它们描述了颜色信息,与 RGB 颜色空间中的蓝色和红色分量相对应。U 和 V 的平均值通常为 0,而其范围通常被规范化为 [-0.5,0.5]
YUV 颜色编码通常用于视频压缩,因为人眼对亮度信息(Y)比色彩信息(U和V)更为敏感。因此,为了减少数据量,通常会对U和V进行子采样,这意味着U和V的分辨率可能比Y低。
那你可能会好奇,为什么我们会在 cuOSD 库中使用到 YUV 格式的图像数据呢?正常不都是 RGB 的图像数据吗?🤔
那相比于 RGB 的图像数据,YUV 格式的图像数据在视频编码和传输场景中是具有一些优势的,主要体现在以下几个方面:(from chatGPT)
1. 压缩效率高: YUV 格式能够更好地利用人眼对亮度变化的敏感性和对色度变化的不敏感性。由于人眼对亮度信息的分辨率要高于色度信息,YUV 格式将亮度信息(Y)和色度信息(U、V)分开存储,可以实现更高的压缩效率。在视频编码中,可以对亮度信息进行更高效的压缩,而对色度信息进行较轻的压缩,从而减小文件大小。
2. 色度子采样: 在 YUV 格式中,色度(U、V)的采样可以降低色度分量的分辨率,从而减少存储和传输的数据量。这种色度子采样在某些情况下不会明显影响视觉质量,因为人眼对色度细节不敏感。
3. 适合视频编码: 许多视频编码标准,如 H.264 和 HEVC,都是基于 YUV 格式的数据进行压缩编码的。在编码过程中,利用 YUV 格式的特点可以更有效地压缩和储存视频流。
4. 传输效率: 对于实时视频传输,YUV 格式能够更有效地传输视频数据,因为它可以减小数据量,提高传输效率。
4.2 YUV格式
参考:图像基础知识之YUV
描述:原图中的绘制似乎和博主的理解存在部分偏差,博主对其进行了修改
YUV 格式有两大类:packed 和 planar,其中 planar 还分为平面存储和平面打包格式
- 对于 packed 的 YUV 格式,每个像素点的 Y,U,V 是连续交错存储的
- 对于 planar 的 YUV 格式,先连续存储所有像素点的 Y,紧接着存储所有像素点的 U,然后是所有像素点的 V(平面存储格式),或者紧接着 UV 交错存储(平面打包格式)
YUV 常见的编码格式 planar 如下图所示:


W 即图像的宽度,H 即图像的高度,Stride 表示图像行的跨度,超出 W 部分为填充数据,主要目的是为了字节对齐,一般以 16 字节或者 32 字节对齐居多
从左侧数据存储结构图看出高度(H)是分层次的,YV12 三层和 NV12 两层,这个层次结构被称为 Plane,即 YV12 在代码中用 Plane[0] 表示 Y 数据的起始地址,Plane[1] 表示 V 数据的起始地址,Plane[1] 表示 U 数据的起始地址。而 NV12 的 UV 是在一个 Plane 中交错存放,因此用两个 Plane 表示即可
从右侧数据结构排布图可见 YV12 和 NV12 都是 YUV 4:2:0 采样,即每四个 Y 共用一组 UV 分量,已用颜色表明,例如 Y1、Y2、Y7、Y8 共用 U1、V1,并在内存中连续分布
YUV 主要的采样格式有 YCbCr 4:2:0、YCbCr 4:2:2 以及 YCbCr 4:2:0
YUV 4:4:4 采样,每一个 Y 对应一组 UV 分量
YUV 4:2:2 采样,每两个 Y 共用一组 UV 分量
YUV 4:2:0 采样,每四个 Y 共用一组 UV 分量
用下面一幅图来直观地表示采集的方式,其中 Y 分量用 ⚫️ 表示,而 UV 分量用 ⚪️ 表示

常见的 YUV 格式有 YUV420、YUV422 和 YUV444。在 YUV420 中,每两个像素共享一个 U 和一个 V 值,这意味着 U 和 V 的分辨率是 Y 的一半。在 YUV422 中,每两个像素共享一个 U 和一个 V 值,但与 YUV420 不同的是,它们只在水平方向上被子采样,而在垂直方向上保持与 Y 相同的分辨率。YUV444 则没有进行子采样,Y、U、V 三者的分辨率都相同。
需要注意的是,虽然 YUV 经常被称为 YCbCr,但这两者有些许差异,主要在于它们的定义和使用的系数。YCbCr 是 YUV 的数字版本,经常用于数字电视、DVD 和其他数字媒体。
4.3 YCbCr简介
参考自:YCbCr-Wikipedia
YCbCr 是一种颜色空间,用于数字视频。它与 RGB 颜色空间不同,RGB 颜色空间是基于红、绿、蓝三种颜色的加色混合。而 YCbCr 是从 RGB 颜色空间派生出来的,它将图像信息分为亮度信息(Y)和色度信息(Cb 和 Cr)
定义:YCbCr 不是绝对的颜色空间,它是 RGB 颜色空间的一个表示方法。YCbCr 通常用于视频压缩,例如 JPEG、MPEG 和 ITU-T 标准。YCbCr 的定义与 RGB 的定义有关,因此 YCbCr 的定义也因 RGB 的定义而异。
历史:YCbCr 的概念起源于 1940 年代的电视广播。当时,为了与黑白电视兼容,需要一种方法来表示彩色信息。这导致了 YUV 颜色空间的创建,YCbCr 是 YUV 的数字版本。
转换:从 RGB 到 YCbCr 的转换是线性的。转换公式涉及到一系列的乘法和加法操作。转换的具体公式取决于具体的 RGB 定义
应用:YCbCr 主要用于视频压缩。由于人眼对亮度信息比色度信息更敏感,所以在视频压缩中,色度信息通常被降采样,从而达到更高的压缩比
优点:YCbCr 的主要优点是它允许独立地处理亮度和色度信息。这使得在视频压缩中可以更有效的利用人眼的视觉特性
限制:YCbCr 颜色空间有其限制。例如,它不能表示 RGB 颜色空间中的所有颜色。此外,不同的设备可能会有不同的 YCbCr 定义,这可能导致颜色不一致的问题
4.4 YUV和YCbCr
YUV 和 YCbCr 都是颜色空间,但它们的应用和定义略有不同。YUV 最初是为模拟电视定义的,而 YCbCr 是为数字视频定义的。然而,随着时间的推移,这两个术语在某些上下文中被互换使用,特别是在数字视频领域。因此我们有时也称 YUV 为 YCbCr,特别是当人们谈论采样格式时,例如 YUV 4:2:0 或 YCbCr 4:2:0,它们通常指的是相同的东西:一种在色度上进行了下采样的视频格式。
YUV 和 YCbCr 的区别和联系如下:(from chatGPT)
定义和起源:
- YUV:起源于模拟电视广播。在彩色电视的早期,为了与黑白电视兼容,需要一种方法来表示彩色信息,这导致了 YUV 颜色空间的创建。其中,Y 代表亮度,U 和 V 代表色度
- YCbCr:是 YUV 的数字版本。它是为数字视频格式和编码标准,如 JPEG 和 MPEG,而设计的。其中,Y 代表亮度,Cb 和 Cr 代表色度。
应用领域:
- YUV:主要用于模拟电视广播
- YCbCr:主要用于数字视频和图片压缩
转换与范围:
- YUV:U 和 V 的范围通常是负数到正数
- YCbCr:Cb 和 Cr 的范围通常是 0 到一个正数
存储与采样:
- 对于 YUV 和 YCbCr,都有多种不同的采样方法,例如 4:4:4、4:2:2、4:2:0 等。这些采样方法描述了色度信号相对于亮度信号的采样率
- 4:2:0 采样:这是一种常见的采样方法,尤其在视频压缩中。对于每 4 个 Y(亮度)样本,只有一个 U 和一个 V 样本(或一个 Cb 和一个 Cr 样本)。这意味着色度信息被降采样了,从而达到更高的压缩比。这种方法利用了人眼对亮度信息比色度信息更敏感的特性。
总之,YCbCr 和 YUV 都是为了更有效地表示和传输视频信息而设计的颜色空间。它们的主要区别在于应用领域和定义。在存储和采样方面,它们都使用了类似的方法和技术。
4.5 HDTV和SDTV
HDTV 和 SDTV 是两种不同的电视信号标准,用于描述电视节目的分辨率和画质(from chatGPT)
HDTV(High-Definition Television) 是高清清晰度电视的缩写,它提供了比传统标准清晰度电视(SDTV)更高的分辨率。它常见的分辨率包括 720p、1080i 和 1080p。其中 “p” 代表逐行扫描,“i” 代表隔行扫描。HDTV 使用 BT.709 色彩标准,这是为高清晰度电视制定的国际标准。HDTV 主要用于现代电视广播、蓝光光盘、流媒体和其它高清内容的播放。
**SDTV(Standard-Definition Television)**是标准清晰度电视的缩写,它是传统的模拟电视广播格式。它常见的分辨率为 480i(在 NTSC 地区,如美国)和 576i(在 PAL 和 SECAM 地区,如欧洲)。SDTV 使用 BT.470 色彩标准,SDTV 主要用于早期的模拟电视广播和一些早期的数字电视广播。
随着技术的进步,HDTV 已经成为了主流,在电视机和显示器,现代电视广播,流媒体服务等都能看到它的身影;而 SDTV 逐渐被淘汰,在早期的电视广播和录像带,以及一些老式的 DVD 才能够看到它。
HDTV 和 SDTV 似乎有点熟悉,好像在哪里见过呢🤔
噢,对了我们在观看直播或者视频的过程中,可以选择不同分辨率,例如在 b 站上点开一个视频选择分辨率的时候可以看到 360P 流畅、480P 清晰、720P 高清、1080P 高清的字眼,其中高清和标清选项就是我们上面所说的 HD 和 SD,我们都知道高清通常具有更高的分辨率和更清晰的画质,而标清的分辨率和画质相对来说就比较糊,网速好的话都会去看高清,网速差可能会去选择标清
那我们在观看直播的时候经常还会看见超清、蓝光(蓝光4M、蓝光8M)、原画等字眼,这些术语其实通常用于描述更高级别的视频分辨率和画质,超越了标准的高清(HD)和标清(SD)
超清(UHD,Ultra High Definition):超清是高于高清(HD)的分辨率,通常指的是 4K 分辨率(3840x2160像素)。这提供了比高清更高的画质和更多的细节。
蓝光(Blu-ray):蓝光是一种高清的光盘格式,用于存储高质量的视频和音频。蓝光通常包含 1080p 分辨率的高清视频。
蓝光4M和蓝光8M:这些术语通常用于描述蓝光光盘的不同版本,其中数字表示每秒的数据传输速率。蓝光 4M 表示每秒传输 4 兆位数据,蓝光 8M 表示每秒传输 8 兆位数据。更高的数据传输速率通常意味着更高的视频质量和更多的细节。
原画:原画是指视频的最高分辨率和最高质量版本,通常是摄影或制作的最初版本。原画通常比 4K 甚至更高的分辨率。
4.6 Alpha通道
Alpha 通道是 RGBA 颜色模型的一部分,其中 R、G 和 B 代表红、绿和蓝通道,而 A 代表 alpha 通道。(from chatGPT)
Alpha 通道的作用是什么?
Alpha 通道定义了像素的不透明度。它的值通常在 0 到 255 之间:
0:完全透明。意味着此像素不会显示任何颜色,因为背后的任何内容都透过此像素显示。
255:完全不透明。像素将完全显示其 R、G、B 颜色值,不考虑背后的任何内容。
0~255:像素的透明度介于完全透明和完全不透明之间。这使得像素可以部分显示颜色,同时还可以显示背后的内容。
为什么需要 Alpha 通道?
图层混合:当多个图像或图形层叠加在一起时,alpha 通道允许每一层都有不同的透明度,从而实现复杂的图层混合效果。
非矩形图形:如果你有一个非矩形的图形或图像,alpha 通道可以使图像的某些部分完全透明,从而使图像看起来像任何形状。
平滑边缘:当绘制反走样的图形时,边缘像素可能不是完全不透明或完全透明。通过调整边缘像素的 alpha 值,可以使边缘看起来更加平滑和自然。
综上所述,alpha 通道为图像提供了更大的灵活性,允许更复杂的渲染和组合效果。
结语
本篇博客简单分享并记录了博主在学习 cuOSD 库的各种知识,首先跑了各种案例看了具体的效果,然后是对绘制矩形框和文本的函数进行了简单分析,最后就是博主在学习 cuOSD 的过程中补充的一些知识,包括 YUV、HDTV、SDTV、RGBA 相关。由于博主知识能力和精力有限,目前也只是分享了简单的使用,具体实现的细节需要各位看官自行了解了😄,感谢各位看到最后,创作不易,读后有收获的看官请帮忙👍⭐️
最后如果大家觉得这个 repo 对你有帮助的话,不妨帮忙点个 ⭐️ 支持一波!!!
下载链接
- Video Demystified.pdf【pwd:1234】
参考
-
cuOSD(CUDA On-Screen Display Library)
-
YUV conversion to/from RGB
-
YCbCr-ITU-R_BT.601_conversion
-
YUV 格式与 RGB 格式的相互转换公式及C++ 代码
-
https://doc.lagout.org/Others/Demystified%20Series/VideoDemystified.pdf
-
Y’UV-Wikipedia
-
图像基础知识之YUV
-
YCbCr-Wikipedia