和线程池类似,数据库连接池的作用是建立一些和数据库的连接供需要连接数据库的业务使用,避免了每次和数据库建立、销毁连接的性能消耗,通过设置连接池参数可以防止建立连接过多导致服务宕机等,以下介绍Java中主要使用的几种数据库连接池。
数据库连接池原理
首先业务程序操作数据库时,需要获取一个数据库的连接这就需要经过tcp的三次握手,建立连接后经过ssl等验证,然后执行sql语句返回数据,最终关闭连接执行四次挥手;整个过程而言如果没有慢sql的情况;tcp的三次握手四次挥手等占用时间反而比执行sql业务的时间更长,因此每次都建立连接将会消耗很多无用的时间,并且频繁建立导致系统不稳定,如果不加限制随意建立连接还可能导致服务宕机;所以此时可以通过连接池的思想(类似的还有线程池、常量池等)将创建的数据库连接维持在连接池中,重复使用该连接,并且设置连接池的参数避免创建连接过多导致服务宕机等。
配置好数据库连接池信息后,在项目启动时会去创建最小连接数数量的连接并放在连接池中,当业务需要数据库连接时,首先在连接池中查找是否有空闲的连接,如果有直接给业务使用,否则判断是否达到最大连接数,没有则创建新的连接给业务使用,如果已经达到则进入等待队列,等待连接池中有空闲连接时使用该连接,否则达到获取连接的超时时间抛出异常;同时空闲的连接在等待空闲超时时间后进行断开连接销毁连接,直到连接池中剩余连接数是最小连接数。
常用主流数据库连接池
比较老牌的数据库连接池,如C3P0等因为性能差,功能不齐全等原因在2019年之后作者就放弃了维护,因为出现了更加优秀的数据库连接池,所以这里就不作介绍,主要介绍目前最常用的两种数据库连接池;HikariCP和Druid连接池。
maven导入jar包查询jar包坐标信息
需要导入的共同的jar包(数据库连接驱动):
<!-- mysql数据库连接驱动,采用Java自带的spi机制实现,Java提供相关接口标准,每个数据库厂商提供自己的数据库驱动实现,spring boot指定了版本,所以这里可以不写版本 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency>
一、HikariCP
HiKariCP 是数据库连接池的一个后起之秀,号称性能最好,可以完美的 PK 掉其他连接池;是一个高性能的 JDBC连接池,基于 BoneCP 做了不少的改进和优化;spring boot 2.x 版本后默认使用的数据库连接池,也就是spring boot2.x之后只需要导入hikariCP的jar包就默认使用HikariCP连接池了,可以直接配置相关参数调整hikari数据库连接池参数即可;只需要加入数据库连接驱动jar包、mybatis等ORM框架就可连接操作数据库并使用连接池管理数据库连接。主要特点是性能非常高,为了达到这个目的主要做了两个优化:
1、常规数据库连接池都是将Statement存放在ArrayList中,而HikariCP自定义了FastList来替代ArrayList,主要对ArrayList的get()和remove()方法做了优化,这个List的主要作用是保证连接关闭时可以依次将数组中的所有Statement关闭;第一:取消ArrayList的get()方法的rangeCheck操作(检查索引是否越界)因为数据库连接池管理的List满足索引的合法性,能保证不会越界;第二:将ArrayList的remove()方法的从头开始遍历数组改为从尾部开始遍历数组(因为一般来说关闭List中保存的 Statement都是逆序关闭的,如果改为逆序遍历那么每次关闭只需要遍历第一个元素即可,提升了效率)这种优化只是基于特定场景的优化,相对来说ArrayList的使用范围更广,比如rangeCheck可以快速抛出异常,逆序遍历也只是场景会逆序遍历,大多数情况获取元素是随机的。
2、使用ConcurrentBag优化阻塞队列,目前主流数据库连接池实现方式,基本都是用两个阻塞队列来实现。一个用于保存空闲数据库连接的队列 idle,一个用于保存忙碌数据库连接的队列 busy;当获取连接时会返回一个空闲连接并将这个空闲连接从 idle 队列移动到 busy 队列,而业务释放连接时将数据库连接从 busy 移动到 idle。这种方式将并发问题交给了阻塞队列处理,实现简单,但 jdk 中的阻塞队列是用Lock机制实现的,在高并发场景下锁的竞争对性能影响很大,所以性能会有所下降;因此HikariCP创建了ConcurrentBag来替代阻塞队列。ConcurrentBag主要实现流程:
四个变量:
a、存储所有的数据库连接的共享队列 sharedList(CopyOnWriteArrayList类型)
b、线程本地存储 threadList(该变量是ThreadLocal类型,避免了线程竞争,主要作用是保存某个线程获取的数据库连接信息,这样当前线程重复获取数据库连接时,如果在threadList中存在,说明以前获取过数据库连接,那么直接将这个对应的数据库连接返回给客户端使用)
c、等待数据库连接的线程数 waiters(AtomicInteger类型)
d、分配数据库连接的工具 handoffQueue(SynchronousQueue类型,这个变量是核心,负责分配数据库连接操作)
所有创建的连接都会通过add()方法添加到sharedList中。
当有客户端获取连接时通过handoffQueue进行分配连接给客户端,首先判断threadList中是否存在对应线程空闲连接,如果有,则返回一个空闲的连接;没有则去sharedList中查找一个空闲连接返回给客户端(CAS操作获取连接,因为该变量是多个线程共享),如果也没有则将请求线程进行等待;当客户端使用完数据库连接之后进行释放时,首先将数据库连接改为空闲状态,然后查看是否有等待线程,如果有等待线程则将该连接分配给等待线程,如果没有等待线程将该数据库连接保存在threadList中。
优化点总结:
1、字节码精简 :优化代码,编译后的字节码量极少,使得CPU缓存可以加载更多的程序代码;
2、优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
3、自定义集合类型(FastStatementList)代替ArrayList:避免ArrayList每次get()都要进行range check,避免调用remove()时的从头到尾的扫描(由于连接的特点是后获取连接的先释放);
4、自定义集合类型(ConcurrentBag):提高并发读写的效率;
5、其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究。
导入hikari的jar包:
<dependency><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId><version>3.4.5</version>
</dependency>
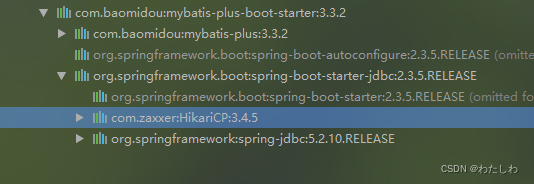
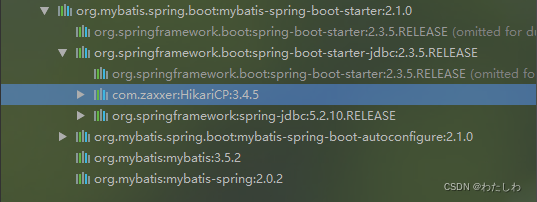
由于spring boot 2.x版本后默认使用hikariCP,此时配置好数据库连接参数,操作数据库时就已经使用了Hikari连接池,但一般操作数据库时还需要导入ORM框架,这里以mybatis-plus为例,当我们导入mybatis-plus的starter或mybatis的starter之后,都会导入 spring-boot-starter-jdbc jar包而 spring-boot-starter-jdbc jar包里面又会导入 HikariCP jar包,所以项目使用 mybatis-plus 作为ORM框架之后,如果导入对应的starter那么此时不需要再导入 HikariCP jar包,直接做 HikariCP 的相关配置即可(如果采用spring-boot-starter-data-jpa作为ORM框架也会导入spring-boot-starter-jdbc jar包)。
mybatis-plus的starter
mybatis的starter
导入mybatis-plus框架:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version></dependency>
配置hikariCP参数:
server:port: 9001 #服务端口号
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver #数据库连接驱动,如果是5.7以上版本的mysql数据库驱动就需要cj,5.7以下版本的mysql数据库驱动不要写cjurl: jdbc:mysql://127.0.0.1:3306/test?setUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true #数据库地址username: root #数据库登录账号password: root #数据库登录密码type: com.zaxxer.hikari.HikariDataSource #默认值就是com.zaxxer.hikari.HikariDataSource,所以该配置可以省略hikari: #以下为hikaricp相关配置auto-commit: true #是否自动提交池中返回的连接,默认值为true,一般是有必要自动提交上一个连接中的事物的,如果为false,那么就需要应用层手动提交事物minimum-idle: 30 #连接池中允许的最小连接数,默认值:10maximum-pool-size: 30 #连接池中允许的最大连接数,默认值:10,建议最大最小连接数指定一样,这样就可以维持连接池中固定的连接,避免连接池中有时连接数过少的情况idle-timeout: 30000 #一个连接空闲状态的最大时长(毫秒),超时则被释放(retired),默认值:10分钟pool-name: testHikari #连接池名称max-lifetime: 1800000 #一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),默认值:30分钟,建议设置比数据库超时时长少30秒,数据库断开空闲连接的超时时长默认8小时connection-timeout: 30000 #等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 默认值:30秒connection-test-query: SELECT 1 #数据库连接测试语句, ping的形式更高效,ping的形式验证连接只能通过超时进行验证,也就是需要在url(spring.datasource.url)中指定参数 socketTimeout=250 ,并将该配置注释validation-timeout: 5000 #数据库连接被测试存活的最长时间(毫秒),默认值:5秒#mybatis-plus相关配置
mybatis-plus:mapper-locations: classpath:/mapper/*.xml #指定xml文件所在目录global-config:db-config:id-type: auto #主键默认数据库自动生成logic-delete-value: 1 #逻辑删除字段,1表示逻辑删除logic-not-delete-value: 0 #逻辑删除字段,0表示未删除此时整合好数据库连接及连接池配置,编写代码测试:
entity:
package com.database.pool.testpool.entity;import com.baomidou.mybatisplus.annotation.*;@TableName("test_idcard")
public class TestIdcardEntity {/*** 主键*/@TableId(type= IdType.AUTO)private String id;/*** 姓名*/private String name;/*** 身份证号*/private String idcard;/*** 联系电话*/private String phone;/*** 备注*/private String remark;/*** 数字*/private boolean number;public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getIdcard() {return idcard;}public void setIdcard(String idcard) {this.idcard = idcard;}public String getPhone() {return phone;}public void setPhone(String phone) {this.phone = phone;}public String getRemark() {return remark;}public void setRemark(String remark) {this.remark = remark;}public boolean getNumber() {return number;}public void setNumber(boolean number) {this.number = number;}@Overridepublic String toString() {return "TestIdcardEntity{" +"idNumber=" + id +", name='" + name + '\'' +", idcard='" + idcard + '\'' +", phone='" + phone + '\'' +", remark='" + remark + '\'' +'}';}
}dao:
package com.database.pool.testpool.dao;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.database.pool.testpool.entity.TestIdcardEntity;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface TestIdcardDao extends BaseMapper<TestIdcardEntity> {
}service:
package com.database.pool.testpool.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.database.pool.testpool.entity.TestIdcardEntity;public interface TestIdcardService extends IService<TestIdcardEntity> {
}serviceImpl:
package com.database.pool.testpool.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.database.pool.testpool.dao.TestIdcardDao;
import com.database.pool.testpool.entity.TestIdcardEntity;
import com.database.pool.testpool.service.TestIdcardService;
import org.springframework.stereotype.Service;@Service
public class TestIdcardServiceImpl extends ServiceImpl<TestIdcardDao, TestIdcardEntity> implements TestIdcardService {
}controller:
package com.database.pool.testpool.controller;import com.database.pool.testpool.entity.TestIdcardEntity;
import com.database.pool.testpool.service.TestIdcardService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RequestMapping("/test")
@RestController
public class TestController {@Autowiredprivate TestIdcardService testIdcardService;/*** 测试身份证表详情查询*/@GetMapping("/info/{id}")public TestIdcardEntity info(@PathVariable("id") Integer id){TestIdcardEntity testIdcard = testIdcardService.getById(id);return testIdcard;}}测试接口:

二、Druid
在实际项目中,企业使用最多的数据库连接池就是 Druid,是目前国内使用范围最广的数据源产品,Druid 是阿里巴巴推出的一款开源的高性能数据源产品,Druid 支持所有JDBC 兼容的数据库,包括 Oracle、MySQL、SQL Server 和 H2等等;性能上低于HikariCP但提供有非常完善的管理监控功能及可视化界面,并且历经高并发的检验。
主要包括三部分:
a、DruidDriver 代理Driver,能够提供基于Filter-Chain横式的插件体系
b、DruidDataSource 高效可管理的数据库连接池
c、SOLParser SQL解析器
Druid 不属于 Spring Boot 内部提供的技术,它属于第三方技术,可以通过以下两种方式进行整合:
a、自定义整合 Druid
b、通过 starter 整合 Druid(starter由阿里提供)
同样采用mybatis-plus作为ORM框架
mybatis-plus-boot-starter 会导入 HikariCP 的jar包,使用Druid时建议将 HikariCP 的jar包排除
<!-- ORM框架,mybatis-plus的starter,用于Mapper层的操作 --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version><!-- 排除 HikariCP jar包 --><exclusions><exclusion><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId></exclusion></exclusions></dependency>
1、spring boot 自定义整合 Druid
导入jar包:
<!-- druid连接池核心包,不是spring boot官方提供的组件一般没有定义默认版本,所以需要指定版本 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency>
配置文件设置:
server:port: 9001 #服务端口号
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver #数据库连接驱动,如果是5.7以上版本的mysql数据库驱动就需要cj,5.7以下版本的mysql数据库驱动不要写cjurl: jdbc:mysql://127.0.0.1:3306/test?setUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true #数据库地址username: root #数据库登录账号password: root #数据库登录密码type: com.alibaba.druid.pool.DruidDataSource #默认值是com.zaxxer.hikari.HikariDataSource#mybatis-plus相关配置
mybatis-plus:mapper-locations: classpath:/mapper/*.xml #指定xml文件所在目录global-config:db-config:id-type: auto #主键默认数据库自动生成logic-delete-value: 1 #逻辑删除字段,1表示逻辑删除logic-not-delete-value: 0 #逻辑删除字段,0表示未删除创建druid配置类:
package com.database.pool.testpool.config;import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;@Configuration
public class DruidConfig extends WebMvcAutoConfiguration {@Bean@ConfigurationProperties("spring.datasource")//设置DataSource采用 spring.datasource 的配置public DataSource createDataSource(){DruidDataSource dataSource = new DruidDataSource();return dataSource;}}测试:

如果没有加入 DruidConfig 配置类,测试时报错如下:

2、spring boot starter 整合 Druid
不需要 DruidConfig 配置类
导入jar包:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency>
由于 druid-spring-boot-starter 中已经依赖了 druid 所以可以将第一种方式spring boot 自定义整合 Druid中导入的 druid 包去除

导入日志相关包(由于配置监控时采用log4j2,所以需要相关日志包)
<!-- spring boot web包starter,可以采用spring boot的方式编写controller层接口 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><!--排除logging,排除所有的日志依赖--><exclusion><artifactId>spring-boot-starter-logging</artifactId><groupId>org.springframework.boot</groupId></exclusion></exclusions></dependency><!-- 添加log4j2 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></dependency> <!--如果需要异步日志则导入异步日志依赖--><dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.3.4</version></dependency> <!-- 对lombok注解的支持 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
采用 spring boot starter 整合 Druid 总计导入包信息:
<dependencies><!-- spring boot核心包 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- spring boot web包starter,可以采用spring boot的方式编写controller层接口 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><!--排除logging,排除所有的日志依赖--><exclusion><artifactId>spring-boot-starter-logging</artifactId><groupId>org.springframework.boot</groupId></exclusion></exclusions></dependency><!-- 添加log4j2 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></dependency><!--如果需要异步日志则导入异步日志依赖--><dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.3.4</version></dependency><!-- mysql数据库连接驱动,采用Java自带的spi机制实现,Java提供相关接口标准,每个数据库厂商提供自己的数据库驱动实现 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency><!-- ORM框架,mybatis-plus的starter,用于Mapper层的操作 --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version><!-- 排除 HikariCP jar包 --><exclusions><exclusion><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId></exclusion></exclusions></dependency><!-- 对lombok注解的支持 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
Druid连接池配置:
spring:datasource:druid:initial-size: 5 #初始化连接数量max-active: 20 #最大连接数量min-idle: 10 #最小连接数量max-wait: 5000 #毫秒,从连接池中获取连接等待超时时间name: testDruid #连接池名称time-between-eviction-runs-millis: 5000 #间隔多久进行一次连接检测,检测需要关闭的空闲连接,毫秒min-evictable-idle-time-millis: 600000 #一个连接在连接池中最小空闲存在时间,毫秒max-evictable-idle-time-millis: 1200000 #一个连接在连接池中最长空闲存在时间,毫秒,建议设置为比8小时小,数据库默认连接空闲8小时进行断开连接validation-query: select 1 #检测连接是否可用的sql语句validation-query-timeout: 2000 #检测连接是否可用超时时间,毫秒test-on-borrow: false #默认false,从连接池获取连接时是否检测连接是否可用test-on-return: false #默认false,程序使用完连接连接池回收连接时,连接池是否判断连接是否可用test-while-idle: true #默认true,从连接池获取连接时是否判断连接为空闲状态,如果是空闲连接即使test-on-borrow为false也会验证连接是否可用phy-max-use-count: 1000 #每个连接最多使用次数,避免长时间使用相同连接造成服务器端负载不均衡pool-prepared-statements: false #是否开启PSCache,PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql建议关闭max-open-prepared-statements: 50 #如果开启PsCache,必须配置大于0,并且大于0时,pool-prepared-statements自动触发修改为true,在Druid中,不会存在oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,如100keep-alive: false #连接池中连接数量在min-idle以内的连接,且空闲时间超过max-evictable-idle-time-millis之后,是否执行keep-alive操作,即连接池中连接数量小于最小连接数时,这些连接空闲时间超过配置的最长空闲存在时间是否依然保持连接不断开删除连接
Druid监控配置:
stat:Druid内置提供一个StatFilter,用于统计监控信息。
wall:Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析;Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。
log4j2:日志记录的功能,可以把sql语句打印到 log4j2 供排查问题。
spring:datasource:druid:aop-patterns: "com.database.pool.testpool.dao.*" #spring监控,利用 aop 机制对指定接口的执行时间,jdbc数进行记录filters: stat,wall,log4j2 #启用哪些内置过滤器 (stat 必须,否则监控不到SQL,wall用于防火墙,log4j2日志记录)即启用哪些监控统计拦截的filterfilter: #配置监控信息stat:enabled: true #开启 DruidDataSource 状态监控即sql监控,只有开启后相关filter的配置才会生效db-type: mysql #数据库类型log-slow-sql: true #开启慢sql监控slow-sql-millis: 2000 #慢sql阈值,单位毫秒,即超过2s的sql认为是慢sql进行记录日志slf4j: #日志采用slf4j门面进行输出相关配置enabled: true #开启slf4j日志记录,只有开启后相关filter的配置才会生效statement-log-error-enabled: true #开启报错日志的记录statement-create-after-log-enabled: falsestatement-close-after-log-enabled: falseresult-set-open-after-log-enabled: falseresult-set-close-after-log-enabled: falseweb-stat-filter:enabled: true #开启statFilter即开启web-jdbc关联监控数据,只有开启后相关filter的配置才会生效url-pattern: /* #过滤所有url即所有url进行监控exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" #排除不必要的url监控路径session-stat-enable: true #开启session统计功能session-stat-max-count: 1000 #session的最大个数,默认100stat-view-servlet:enabled: true #开启statViewServlet即开启内置监控界面,默认false,只有开启后相关filter的配置才会生效url-pattern: /druid/* #访问内置监控页面的路径,内置监控页面首页是 当前服务的ip:端口/druid/index.htmlreset-enable: false #不允许清空统计数据重新计算即不允许重置统计信息login-username: druid #访问监控页面账号login-password: 123456 #访问监控页面密码allow: 127.0.0.1 #允许访问监控界面的地址,如果没有配置或为空,表示所有地址都允许访问,ip白名单deny: 192.168.0.1 #不允许访问监控界面的地址,如果allow和deny都存在的地址则优先deny生效,ip黑名单
连接池+监控+mybatis-plus总计配置:
server:port: 9001 #服务端口号
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver #数据库连接驱动,如果是5.7以上版本的mysql数据库驱动就需要cj,5.7以下版本的mysql数据库驱动不要写cjurl: jdbc:mysql://127.0.0.1:3306/test?setUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true #数据库地址username: root #数据库登录账号password: root #数据库登录密码type: com.alibaba.druid.pool.DruidDataSource #默认值是com.zaxxer.hikari.HikariDataSourcedruid:initial-size: 5 #初始化连接数量max-active: 20 #最大连接数量min-idle: 10 #最小连接数量max-wait: 5000 #毫秒,从连接池中获取连接等待超时时间name: testDruid #连接池名称time-between-eviction-runs-millis: 5000 #间隔多久进行一次连接检测,检测需要关闭的空闲连接,毫秒min-evictable-idle-time-millis: 600000 #一个连接在连接池中最小空闲存在时间,毫秒max-evictable-idle-time-millis: 1200000 #一个连接在连接池中最长空闲存在时间,毫秒,建议设置为比8小时小,数据库默认连接空闲8小时进行断开连接validation-query: select 1 #检测连接是否可用的sql语句validation-query-timeout: 2000 #检测连接是否可用超时时间,毫秒test-on-borrow: false #默认false,从连接池获取连接时是否检测连接是否可用test-on-return: false #默认false,程序使用完连接连接池回收连接时,连接池是否判断连接是否可用test-while-idle: true #默认true,从连接池获取连接时是否判断连接为空闲状态,如果是空闲连接即使test-on-borrow为false也会验证连接是否可用phy-max-use-count: 1000 #每个连接最多使用次数,避免长时间使用相同连接造成服务器端负载不均衡pool-prepared-statements: false #是否开启PSCache,PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql建议关闭max-open-prepared-statements: 50 #如果开启PsCache,必须配置大于0,并且大于0时,pool-prepared-statements自动触发修改为true,在Druid中,不会存在oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,如100keep-alive: false #连接池中连接数量在min-idle以内的连接,且空闲时间超过max-evictable-idle-time-millis之后,是否执行keep-alive操作,即连接池中连接数量小于最小连接数时,这些连接空闲时间超过配置的最长空闲存在时间是否依然保持连接不断开删除连接aop-patterns: "com.database.pool.testpool.dao.*" #spring监控,利用 aop 机制对指定接口的执行时间,jdbc数进行记录filters: stat,wall,log4j2 #启用哪些内置过滤器 (stat 必须,否则监控不到SQL,wall用于防火墙,log4j2日志记录)即启用哪些监控统计拦截的filterfilter: #配置监控信息stat:enabled: true #开启 DruidDataSource 状态监控即sql监控,只有开启后相关filter的配置才会生效db-type: mysql #数据库类型log-slow-sql: true #开启慢sql监控slow-sql-millis: 2000 #慢sql阈值,单位毫秒,即超过2s的sql认为是慢sql进行记录日志slf4j: #日志采用slf4j门面进行输出相关配置enabled: true #开启slf4j日志记录,只有开启后相关filter的配置才会生效statement-log-error-enabled: true #开启报错日志的记录statement-create-after-log-enabled: falsestatement-close-after-log-enabled: falseresult-set-open-after-log-enabled: falseresult-set-close-after-log-enabled: falseweb-stat-filter:enabled: true #开启statFilter即开启web-jdbc关联监控数据,只有开启后相关filter的配置才会生效url-pattern: /* #过滤所有url即所有url进行监控exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" #排除不必要的url监控路径session-stat-enable: true #开启session统计功能session-stat-max-count: 1000 #session的最大个数,默认100stat-view-servlet:enabled: true #开启statViewServlet即开启内置监控界面,默认false,只有开启后相关filter的配置才会生效url-pattern: /druid/* #访问内置监控页面的路径,内置监控页面首页是 当前服务的ip:端口/druid/index.htmlreset-enable: false #不允许清空统计数据重新计算即不允许重置统计信息login-username: druid #访问监控页面账号login-password: 123456 #访问监控页面密码allow: 127.0.0.1 #允许访问监控界面的地址,如果没有配置或为空,表示所有地址都允许访问,ip白名单deny: 192.168.0.1 #不允许访问监控界面的地址,如果allow和deny都存在的地址则优先deny生效,ip黑名单#mybatis-plus相关配置
mybatis-plus:mapper-locations: classpath:/mapper/*.xml #指定xml文件所在目录global-config:db-config:id-type: auto #主键默认数据库自动生成logic-delete-value: 1 #逻辑删除字段,1表示逻辑删除logic-not-delete-value: 0 #逻辑删除字段,0表示未删除测试:

访问Druid监控界面(账号druid,密码123456):
idea创建spring boot项目整合mybatis-plus
Java日志框架JUL、Log4j、logback、log4j2使用