目录
一、Transformer的核心思想
1. 自注意力机制(Self-Attention)
2. 多头注意力(Multi-Head Attention)
二、Transformer的架构
1. 整体结构
2. 编码器层(Encoder Layer)
3. 解码器层(Decoder Layer)
三、关键技术与细节
1. 位置编码(Positional Encoding)
2. 掩码机制(Masking)
3. 前馈神经网络(FFN)
四、训练与优化
1. 损失函数
2. 优化技巧
五、Transformer的应用与变体
1. 经典应用
2. 变体模型
六、Transformer的优势与局限
1. 优势
2. 局限
七、vision transformer
1.Vision Transformer的核心思想
2.ViT架构的关键组件
(1) 图像分块与嵌入(Patch Embedding)
(2) 位置编码(Positional Encoding)
(3) Transformer Encoder
(4) 分类头(Classification Head)
3. 数据处理与训练流程
4. MindSpore实现特点
5. ViT与传统CNN的对比
6.关键代码片段(简化版)
Transformer 模型是2017年由Google提出的一种革命性的深度学习架构(但不是一种AI框架,区别于Tensorflow,可以理解为一种算法),主要用于序列到序列(Seq2Seq)任务(如机器翻译、文本生成等)。它的核心创新在于完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),转而依赖自注意力机制(Self-Attention)捕捉序列中元素之间的全局依赖关系。Transformer通过自注意力机制彻底改变了序列建模方式,成为现代NLP的基石。其设计启发了BERT、GPT等划时代模型,并扩展到了计算机视觉、语音处理等领域。
一、Transformer的核心思想
1. 自注意力机制(Self-Attention)
- 目标:为序列中的每个位置(如单词)分配不同的权重,表示该位置对其他位置的依赖程度。
- 输入:三个向量(Query, Key, Value),均来自同一输入序列的线性变换。
- 计算步骤:
1. 相似度计算:通过Query和Key的点积计算每对位置之间的相关性。
2. 缩放(Scaling):除以根号下维度(
),防止点积值过大导致梯度消失。
3. Softmax归一化:得到权重矩阵(注意力分数)。
4. 加权求和:用权重矩阵对Value向量加权求和,得到最终输出。
公式:

2. 多头注意力(Multi-Head Attention)
- 动机:单次注意力可能只关注局部信息,多头机制允许模型同时关注不同子空间的信息。
- 实现:将Q、K、V分别拆分到多个头(如8个头),每个头独立计算注意力,最后拼接结果并通过线性层融合。
二、Transformer的架构

1. 整体结构
- 编码器(Encoder):由N个相同层堆叠而成(原论文N=6)。
解码器(Decoder):同样由N个层堆叠,每个层比编码器多一个交叉注意力(Cross-Attention)模块。
2. 编码器层(Encoder Layer)
每层包含两个子模块:
1. 多头自注意力(Multi-Head Self-Attention):处理输入序列的内部依赖。
2. 前馈神经网络(Feed-Forward Network, FFN):两层全连接层(中间用ReLU激活)。
残差连接(Residual Connection)和层归一化(Layer Normalization)应用于每个子模块后。
3. 解码器层(Decoder Layer)
每层包含三个子模块:
1. 掩码多头自注意力(Masked Multi-Head Self-Attention):防止解码时看到未来信息。
2. 交叉注意力(Cross-Attention):将解码器的Query与编码器的Key、Value交互。
3. 前馈神经网络(FFN)。
- 同样使用残差连接和层归一化。
三、关键技术与细节

1. 位置编码(Positional Encoding)
- 问题:Transformer没有RNN/CNN的顺序处理能力,需显式注入位置信息。
- 方法:使用正弦和余弦函数生成位置编码,与输入向量相加。

2. 掩码机制(Masking)
- 解码器自注意力掩码:掩盖未来位置,确保预测第t步时只能看到前t-1步的信息。
- 填充掩码(Padding Mask):忽略无效的填充位置(如补齐序列的0)。
3. 前馈神经网络(FFN)
- 结构:两层全连接,中间维度扩大(如输入维度512 → 中间2048 → 输出512)。
公式:![]()
四、训练与优化
1. 损失函数
- 交叉熵损失(Cross-Entropy Loss),用于分类任务(如预测下一个词)。
2. 优化技巧
- 学习率预热(Learning Rate Warmup):逐步增加学习率,避免初始阶段不稳定。
- 标签平滑(Label Smoothing):防止模型对标签过于自信,提升泛化能力。
五、Transformer的应用与变体
1. 经典应用
- 机器翻译(原始论文任务)。
- BERT:仅用编码器,通过掩码语言模型预训练。
- GPT系列:仅用解码器,自回归生成文本。
2. 变体模型
- Vision Transformer(ViT):将图像分块后输入Transformer。
- Longformer:改进注意力机制,处理长序列。
- T5:统一的文本到文本框架。
六、Transformer的优势与局限
1. 优势
- 并行计算效率高(相比RNN)。
- 长距离依赖捕捉能力强。
- 灵活适应多种任务(如文本、图像、语音)。
2. 局限
- 计算复杂度与序列长度平方成正比(O(n²))。
- 对位置编码的依赖较强,可能影响泛化。
七、vision transformer

1.Vision Transformer的核心思想

ViT将图像处理任务转化为类似自然语言处理(NLP)的序列建模问题,通过Transformer Encoder结构替代传统的卷积神经网络(CNN)。核心思想如下:
- 图像分块(Patch Embedding):将输入图像分割为固定大小的图像块(如16x16像素),每个块被展平为一个向量,作为Transformer的输入序列。
- 位置编码(Positional Encoding):由于Transformer本身不具备空间位置感知能力,需为每个图像块添加位置编码,以保留图像的空间信息。
- 类标记(Class Token):在输入序列前添加一个可学习的类标记(Class Token),用于最终分类任务。
2.ViT架构的关键组件

(1) 图像分块与嵌入(Patch Embedding)
- 输入图像(如224x224)被划分为多个固定大小的块(如16x16),每个块展平为向量(如16x16x3=768维)。
- 通过线性投影(`nn.Dense`)将每个块映射到嵌入空间,生成Patch Embeddings。
- 示例操作:
# MindSpore中的分块与嵌入实现
self.patch_embedding = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)
(2) 位置编码(Positional Encoding)
- 为每个图像块添加位置编码,编码方式可以是可学习的参数(`nn.Embedding`)或预定义的固定编码。
- 位置编码与Patch Embeddings相加,形成最终的输入序列。
(3) Transformer Encoder
- 由多个Multi-Head Self-Attention层和Feed-Forward Network(FFN)堆叠而成。
- Self-Attention:通过计算序列内各元素间的相关性,捕捉全局依赖关系。
- Layer Normalization(LN -- 层标准化)和残差连接:确保训练稳定性和梯度流动。
- MindSpore中可以使用`nn.TransformerEncoderLayer`实现单层Transformer。
(4) 分类头(Classification Head)
- 取类标记对应的输出向量,通过多层感知机(MLP)进行分类。
self.classifier = nn.Dense(embed_dim, num_classes)
3. 数据处理与训练流程
- 图像预处理:标准化(如ImageNet均值/方差)、调整大小、分块。
- 数据增强:随机裁剪、翻转、颜色扰动等(使用MindSpore的`transforms`模块)。
- 训练优化:使用交叉熵损失函数、AdamW优化器,支持分布式训练和混合精度加速。
4. MindSpore实现特点
- 动态图模式(PyNative):灵活调试模型结构。
- 混合精度训练:通过`model.train`的`amp_level`参数加速训练。
- 分布式训练支持:结合`set_auto_parallel_context`实现多卡并行。
5. ViT与传统CNN的对比

6.关键代码片段(简化版)
VisionTransformer模块的实现
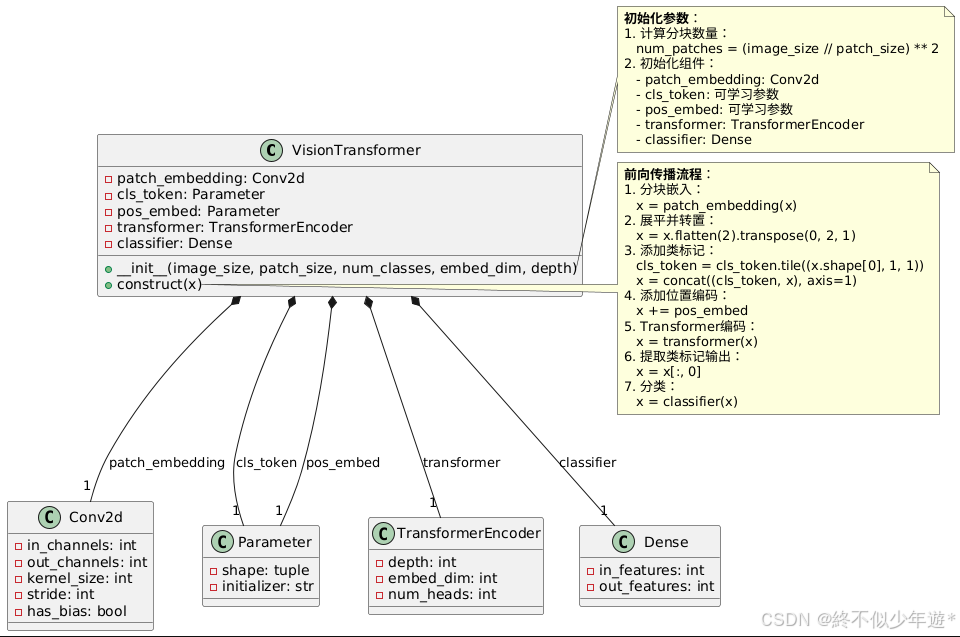
import mindspore.nn as nnclass VisionTransformer(nn.Cell):def __init__(self, image_size=224, patch_size=16, num_classes=1000, embed_dim=768, depth=12):super().__init__()
num_patches = (image_size // patch_size) ** 2
self.patch_embedding = nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)
self.cls_token = Parameter(initializer('normal', (1, 1, embed_dim)))
self.pos_embed = Parameter(initializer('normal', (1, num_patches + 1, embed_dim)))
self.transformer = nn.TransformerEncoder(depth, embed_dim, num_heads=12)
self.classifier = nn.Dense(embed_dim, num_classes)def construct(self, x):
x = self.patch_embedding(x) # 分块嵌入
x = x.flatten(2).transpose(0, 2, 1)
cls_token = self.cls_token.tile((x.shape[0], 1, 1))
x = ops.concat((cls_token, x), axis=1) # 添加类标记
x += self.pos_embed # 位置编码
x = self.transformer(x) # Transformer编码
x = x[:, 0] # 提取类标记输出
x = self.classifier(x)return x
参考文档:Vision Transformer图像分类 — MindSpore master 文档



















