在之前的文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(一)” 中,我们详细描述了如何结合 ChatGPT 及 Elasticsearch 来进行搜索。它使用了如下的架构:
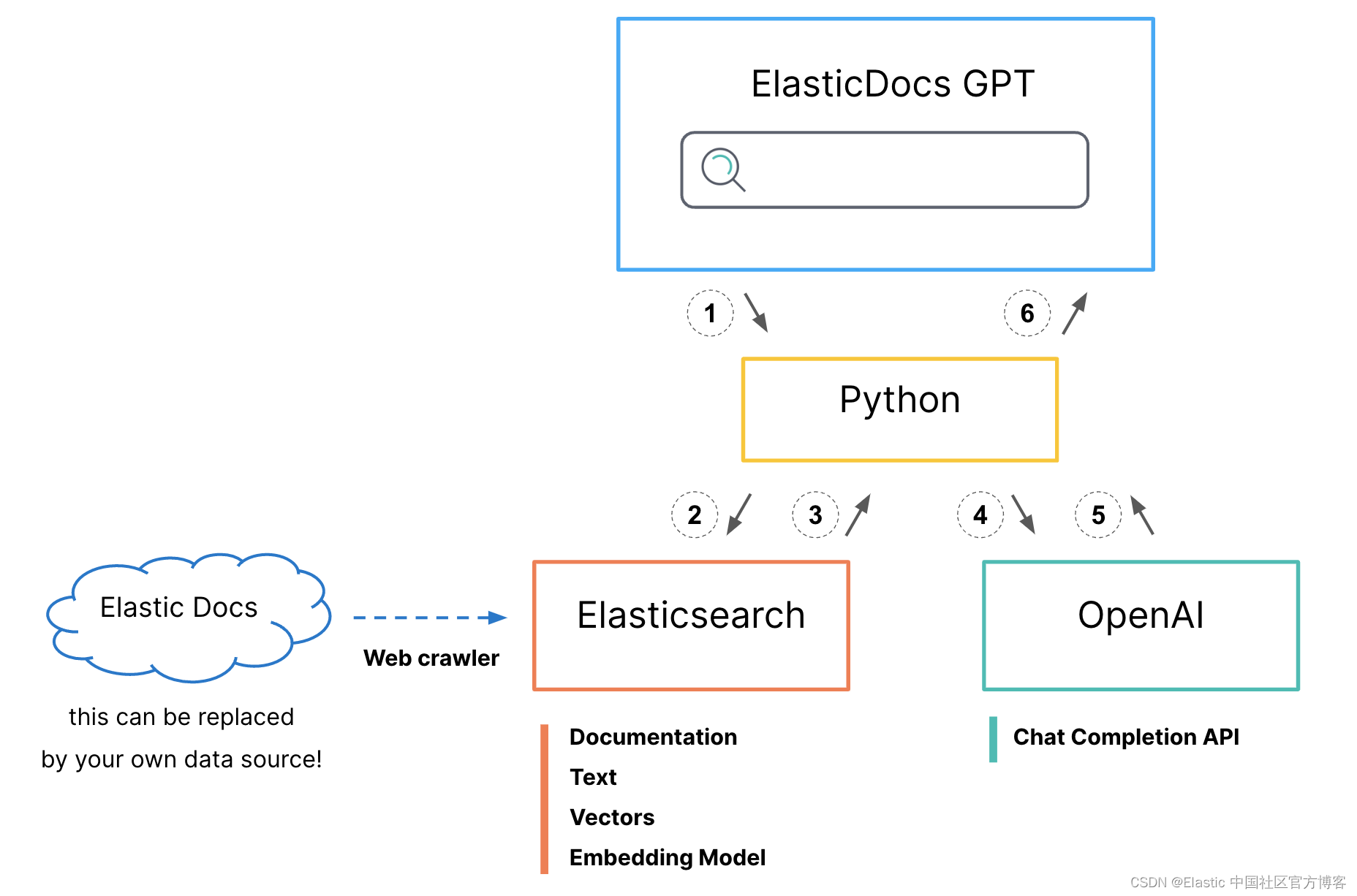
在今天的文章中,我们来详细描述实现这个的详细步骤。这个项目的源码在地址 GitHub - jeffvestal/ElasticDocs_GPT: Combining the search power of Elasticsearch with the Question Answering power of GPT。我们可以通过如下的命令来进行下载:
git clone https://github.com/jeffvestal/ElasticDocs_GPT在下面的展示中,我将使用最新的 Elastic Stack 8.7.0 来进行展示。
ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据
安装及准备
Elasticsearch
我们可参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch。特别地,我们需要按照 Elastic Stack 8.x 的安装指南来进行安装。
在 Elasticsearch 终端输出中,找到 elastic 用户的密码和 Kibana 的注册令牌。 这些是在 Elasticsearch 第一次启动时打印的。

我们记下这个密码,并在下面的配置中进行使用。同时它也会生成相应的证书文件:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.7.0
$ cd config/certs/
$ ls
http.p12 http_ca.crt transport.p12保存密码、注册令牌和证书路径名。 你将在后面的步骤中需要它们。如果你对这些操作还不是很熟的话,请参考我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。
安装 Kibana
我们接下来安装 Kibana。我们可以参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana” 来进行我们的安装。特别地,我们需要安装 Kibana 8.2 版本。如果你还不清楚如何安装 Kibana 8.2,那么请阅读我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。在启动 Kibana 之前,我们可以修改 Kibana 的配置文件如下。添加如下的句子到 config/kibana.yml 中去:
config/kibana.yml
enterpriseSearch.host: http://localhost:3002然后,我们使用如下的命令来启动 Kibana:
bin/kibana
我们在浏览器中输入上面输出的地址然后输入相应的 enrollment token 就可以把 Kibana 启动起来。
Java安装
你需要安装 Java。版本在 Java 8 或者 Java 11。我们可以参考链接来查找需要的 Java 版本。
App search 安装
我们在地址 https://www.elastic.co/downloads/app-search 找到我们需要的版本进行下载。并按照页面上相应的指令来进行按照。如果你想针对你以前的版本进行安装的话,请参阅地址 https://www.elastic.co/downloads/past-releases#app-search。
等我们下载完 Enterprise Search 的安装包,我们可以使用如下的命令来进行解压缩:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.7.0 kibana-8.7.0
elasticsearch-8.7.0-darwin-aarch64.tar.gz kibana-8.7.0-darwin-aarch64.tar.gz
enterprise-search-8.7.0.tar.gz
$ tar xzf enterprise-search-8.7.0.tar.gz
$ cd enterprise-search-8.7.0
$ ls
LICENSE NOTICE.txt README.md bin config lib metricbeat如上所示,它含有一个叫做 config 的目录。我们在启动 Enterprise Search 之前,必须做一些相应的配置。我们需要修改 config/enterprise-search.yml 文件。在这个文件中添加如下的内容:
config/enterprise-search.yml
allow_es_settings_modification: true
secret_management.encryption_keys: ['q3t6w9z$C&F)J@McQfTjWnZr4u7x!A%D']
elasticsearch.username: elastic
elasticsearch.password: "*CpJpvlY4A+nqDeCv5l="
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.7.0/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
在上面,请注意 elasticsearch.password 是我们在 Elasticsearch 安装过程中生成的密码。elasticsearch.ssl.certificate_authority 必须根据自己的 Elasticsearch 安装路径中生成的证书进行配置。在上面的配资中,我们还没有配置 secret_management.encryption_keys。我们可以使用上面的配置先运行,然后让系统帮我们生成。在配置上面的密码时,我们需要添加上引号。我发现在密码中含有 * 字符会有错误的信息。我们使用如下的命令来启动:
bin/enterprise-search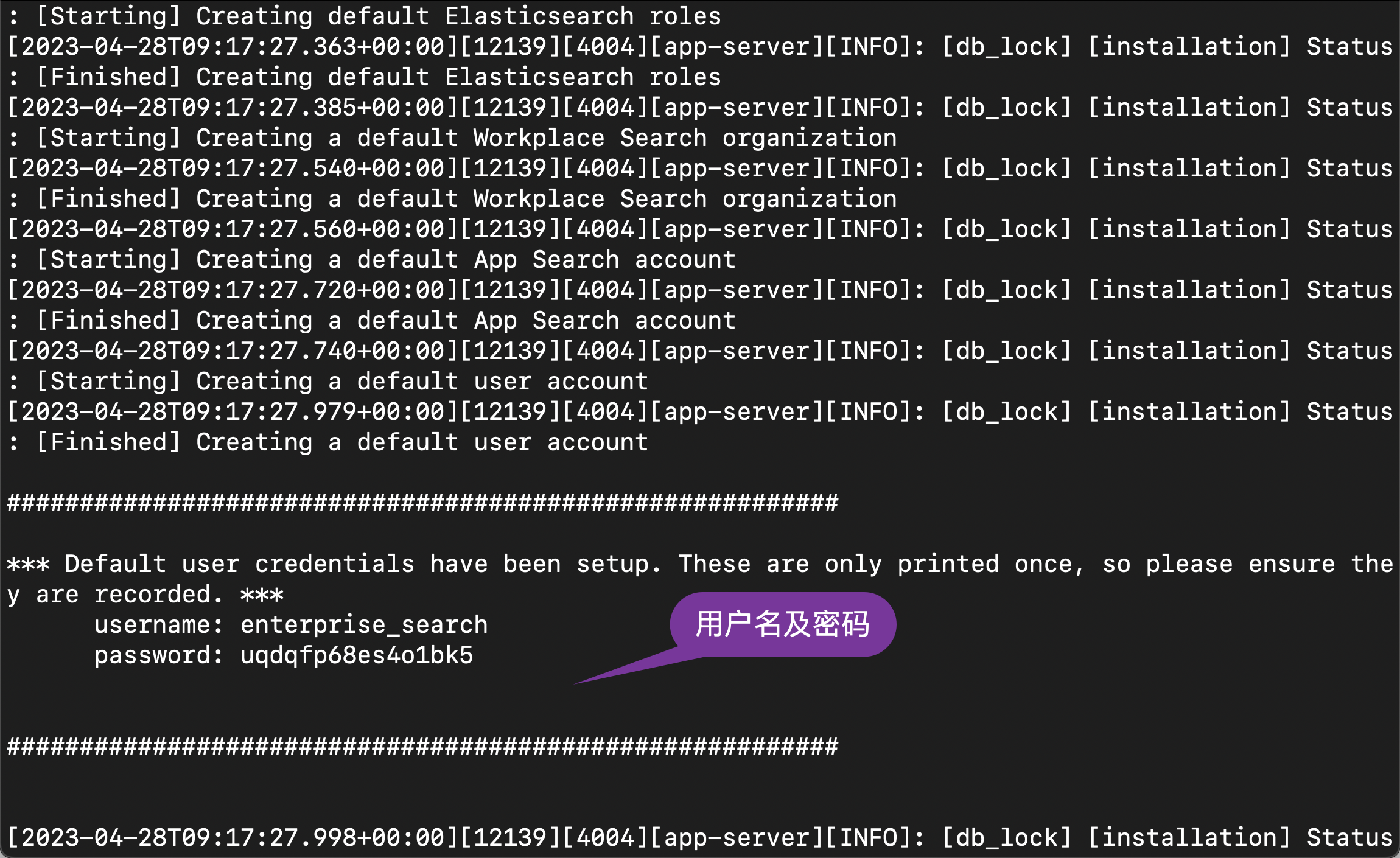
在启动的过程中,我们可以看到生成的用户名及密码信息:
username: enterprise_searchpassword: uqdqfp68es4o1bk5我们记下这个用户名及密码。在启动的过程中,我们还可以看到一个生成的 secret_session_key:
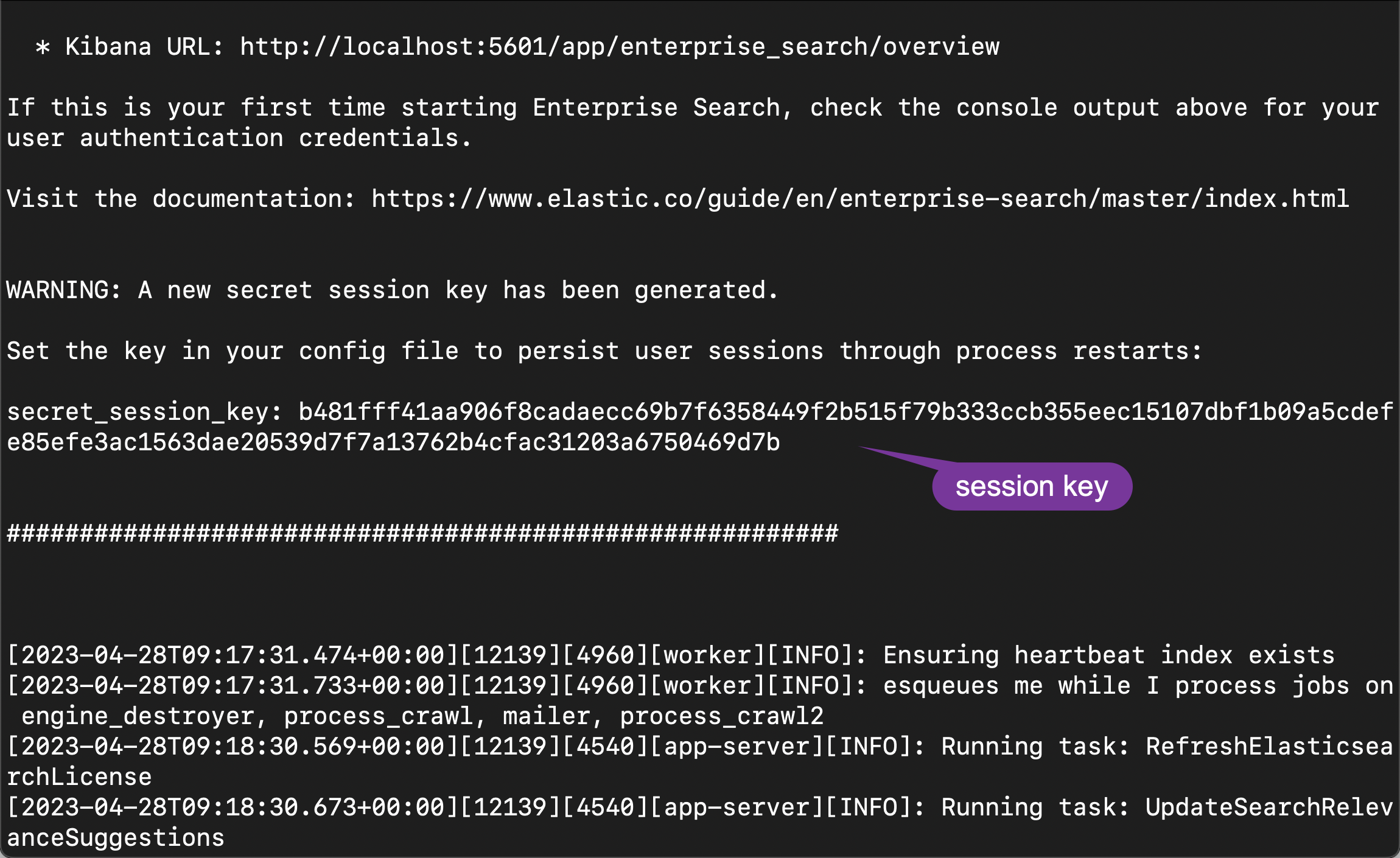
我们也把它拷贝下来,并添加到配置文件中去:
config/enterprise-search.yml
allow_es_settings_modification: true
secret_management.encryption_keys: ['q3t6w9z$C&F)J@McQfTjWnZr4u7x!A%D']
elasticsearch.username: elastic
elasticsearch.password: "*CpJpvlY4A+nqDeCv5l="
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.7.0/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601secret_session_key: b481fff41aa906f8cadaecc69b7f6358449f2b515f79b333ccb355eec15107dbf1b09a5cdefe85efe3ac1563dae20539d7f7a13762b4cfac31203a6750469d7b
feature_flag.elasticsearch_search_api: true为了能够使得我们能够在 App Search 中使用 Elasticsearch 搜索,我们必须设置
feature_flag.elasticsearch_search_api: true。 我们再次重新启动 enterprise search:
./bin/enterprise-search 这次启动后,我们再也不会看到任何的配置输出了。这样我们的 enterprise search 就配置好了。
安装 eland
Eland 可以通过 pip 从 PyPI 安装。在安装之前,我们需要安装好自己的 Python。
$ python --version
Python 3.10.2可以使用 Pip 从 PyPI 安装 Eland:
python -m pip install eland也可以使用 Conda 从 Conda Forge 安装 Eland:
conda install -c conda-forge eland希望在不安装 Eland 的情况下使用它的用户,为了只运行可用的脚本,可以构建 Docker 容器:
git clone https://github.com/elastic/eland
cd eland
docker build -t elastic/eland .
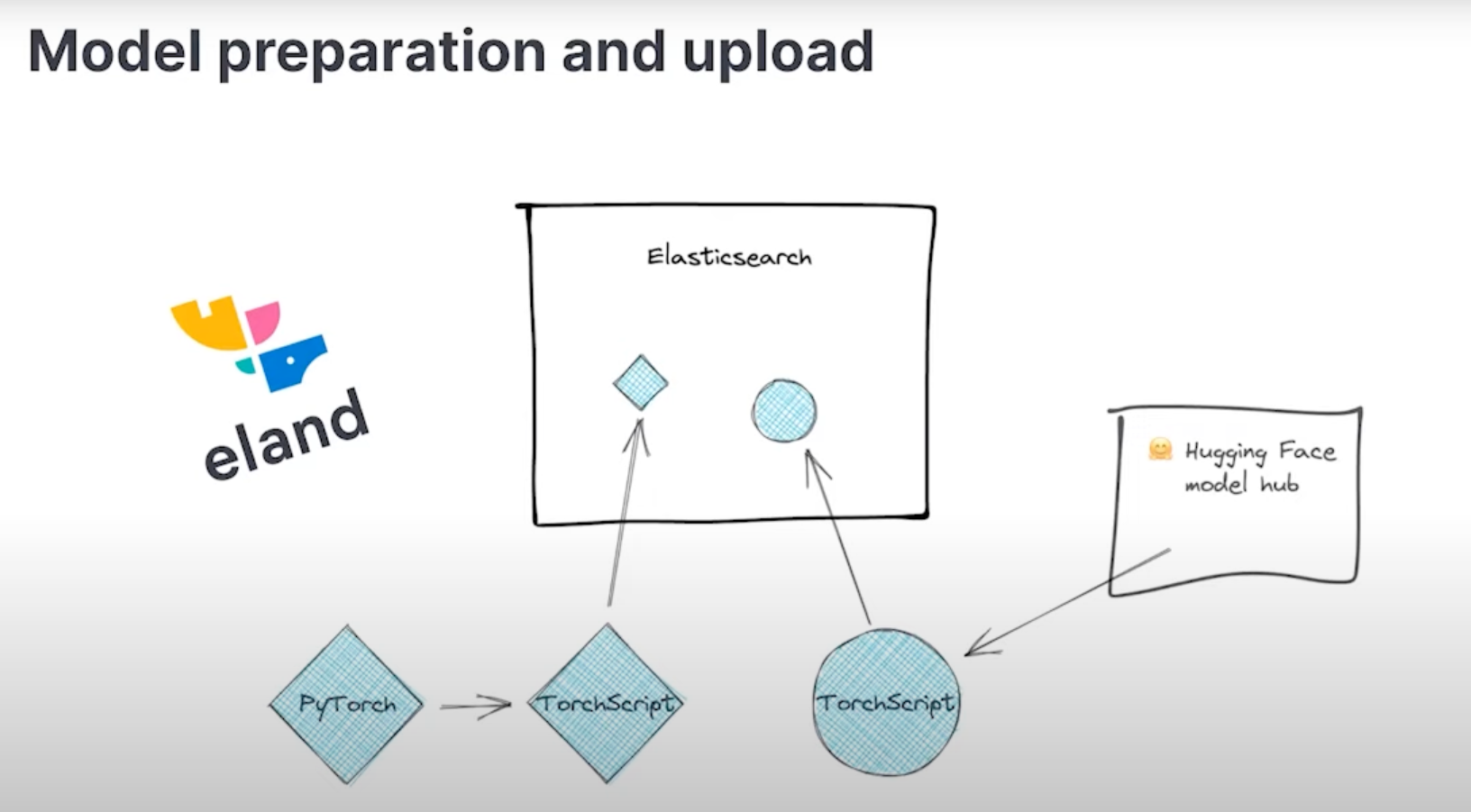
Eland 将 Hugging Face 转换器模型到其 TorchScript 表示的转换和分块过程封装在一个 Python 方法中; 因此,这是推荐的导入方法。
- 安装 Eland Python 客户端。
- 运行 eland_import_hub_model 脚本。 例如:
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner - 指定 URL 以访问你的集群。 例如,https://<user>:<password>@<hostname>:<port>。
- 在 Hugging Face 模型中心中指定模型的标识符。
- 指定 NLP 任务的类型。 支持的值为 fill_mask、ner、text_classification、text_embedding, question_answering 和 zero_shot_classification。
启动白金试用
因为机器学习是一个订阅功能,我们需要在 Kibana 中进行启动。有关更多关于订阅的信息,请访问 订阅 | Elastic Stack 产品和支持 | Elastic。


这样我们就启动了试用功能。
获得 API key 与 OpenAI API 连接
要向 ChatGPT 发送文档和问题,我们需要一个 OpenAI API 帐户和密钥。 如果你还没有帐户,可以创建一个免费帐户,你将获得初始数量的免费积分。
- 转到 https://platform.openai.com 并单击 “Signup”。 你可以完成使用电子邮件地址和密码或使用 Google 或 Microsoft 登录的过程。
创建帐户后,你需要创建一个 API 密钥:
- 单击 API Keys。
- 单击创 Create new secret key。
- 复制新密钥并将其保存在安全的地方,因为你将无法再次查看该密钥。

我们把上面的 API key 保存下来。这个 key 将在下面被使用。
上传模型至 Elasticsearch
为了方便上传模型,根据仓库里的文件修改成如下的一个文件:
main.py
from pathlib import Path
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
from elasticsearch import Elasticsearch
from elasticsearch.client import MlClientimport getpassUSERNAME = "elastic"
PASSWORD = "*CpJpvlY4A+nqDeCv5l="
ELATICSEARCH_ENDPOINT = "localhost:9200"
ELASTCSEARCH_CERT_PATH = "/Users/liuxg/elastic/elasticsearch-8.7.0/config/certs/http_ca.crt"
CERT_FINGERPRINT = "5a4b34414532c53698e4006e6c2b2c1c8d90d4a9d1bd995198fe6e902de00a35"# es_cloud_id = getpass.getpass('Enter Elastic Cloud ID: ')
# es_user = getpass.getpass('Enter cluster username: ')
# es_pass = getpass.getpass('Enter cluster password: ') url = f'https://{USERNAME}:{PASSWORD}@{ELATICSEARCH_ENDPOINT}'
print("url: " + url)es = Elasticsearch(url, ca_certs = ELASTCSEARCH_CERT_PATH, verify_certs = True)
resp = es.info()# es = Elasticsearch(ELATICSEARCH_ENDPOINT,
# ssl_assert_fingerprint = (CERT_FINGERPRINT),
# basic_auth=(USERNAME, PASSWORD),
# verify_certs = False)
# resp = es.info(print((resp))hf_model_id='sentence-transformers/all-distilroberta-v1'
tm = TransformerModel(hf_model_id, "text_embedding")#set the modelID as it is named in Elasticsearch
es_model_id = tm.elasticsearch_model_id()# Download the model from Hugging Face
tmp_path = "models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)# Load the model into Elasticsearch
ptm = PyTorchModel(es, es_model_id)
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config) s = MlClient.start_trained_model_deployment(es, model_id=es_model_id)
s.bodystats = MlClient.get_trained_models_stats(es, model_id=es_model_id)
stats.body['trained_model_stats'][0]['deployment_stats']['nodes'][0]['routing_state']有关如何在 Python 中连接 Elasticsearch 的知识,请阅读我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
我们运行上面的 Python 应用:
pip -q install eland elasticsearch sentence_transformers transformers torch==1.11
python3 main.py
我们回到 Kibana 界面去查看:

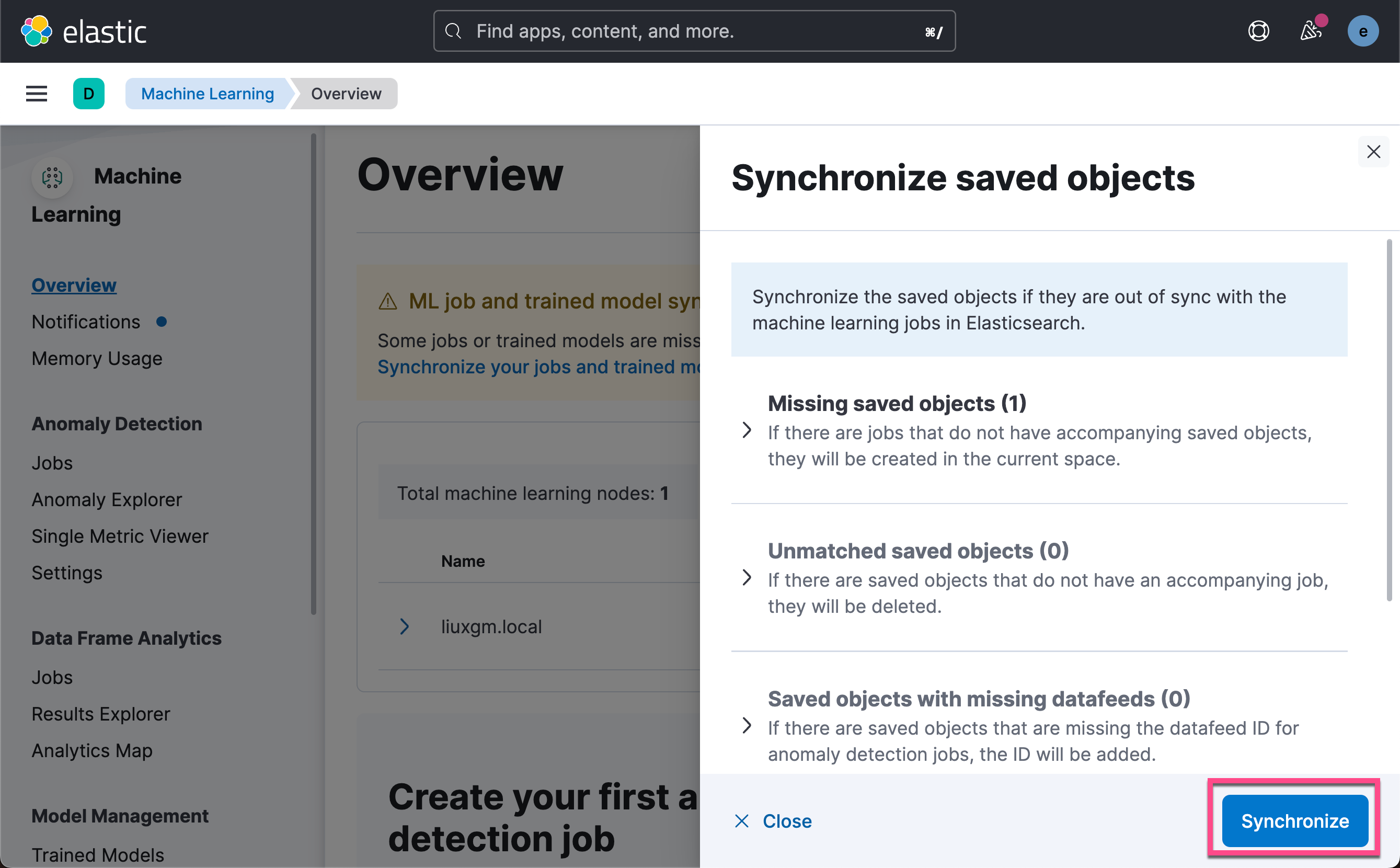

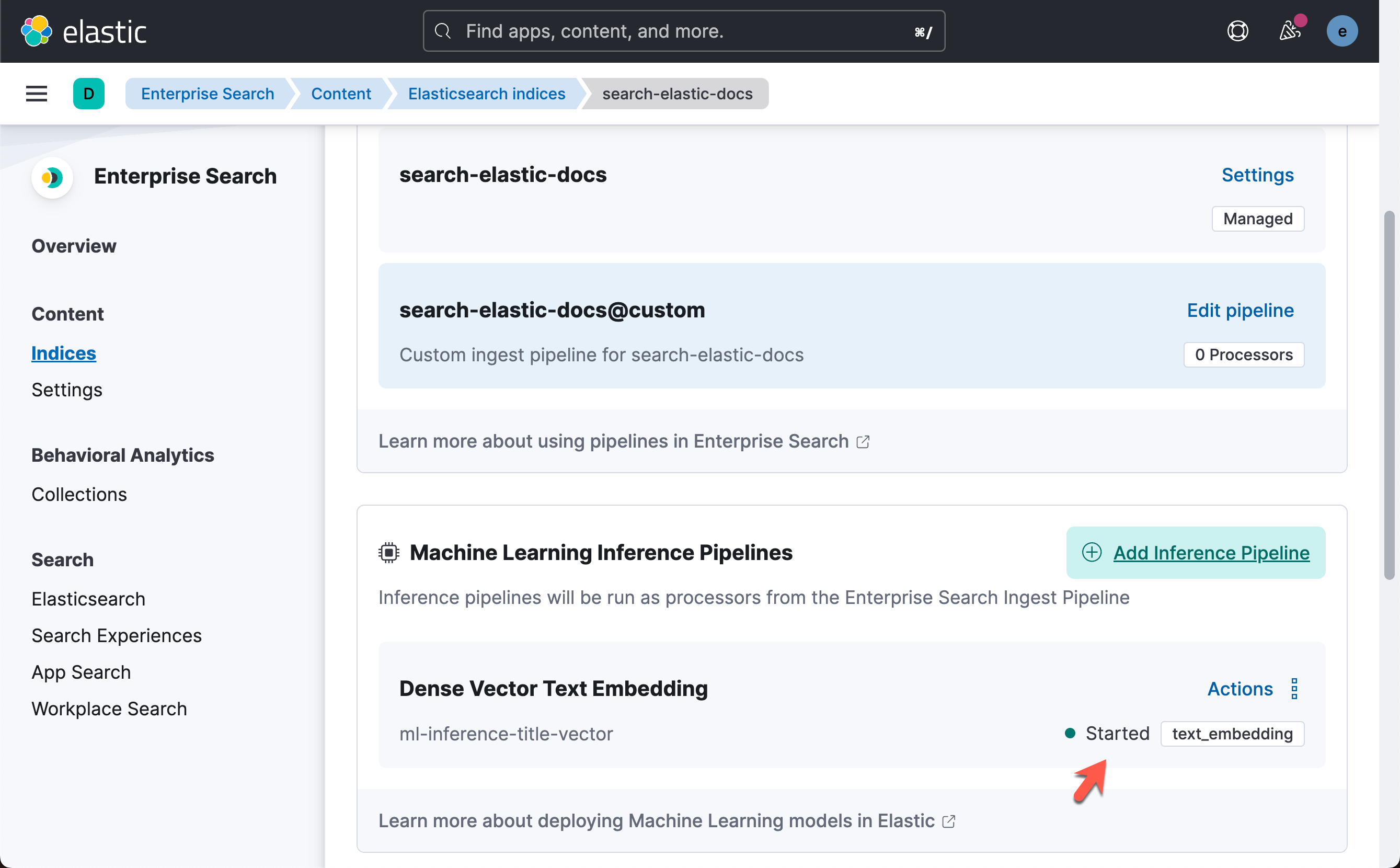
从上面的输出中,我们可以看到模型已经加载成功。我们可以看到它的状态是 started。
Elasticsearch 索引和网络爬虫
接下来我们将创建一个新的 Elasticsearch 索引来存储我们的 Elastic 文档,将网络爬虫配置为自动抓取这些文档并为其编制索引,并使用摄取管道为文档标题生成向量。
请注意,你可以在此步骤中使用你的专有数据,以创建适合你的领域的问答体验。

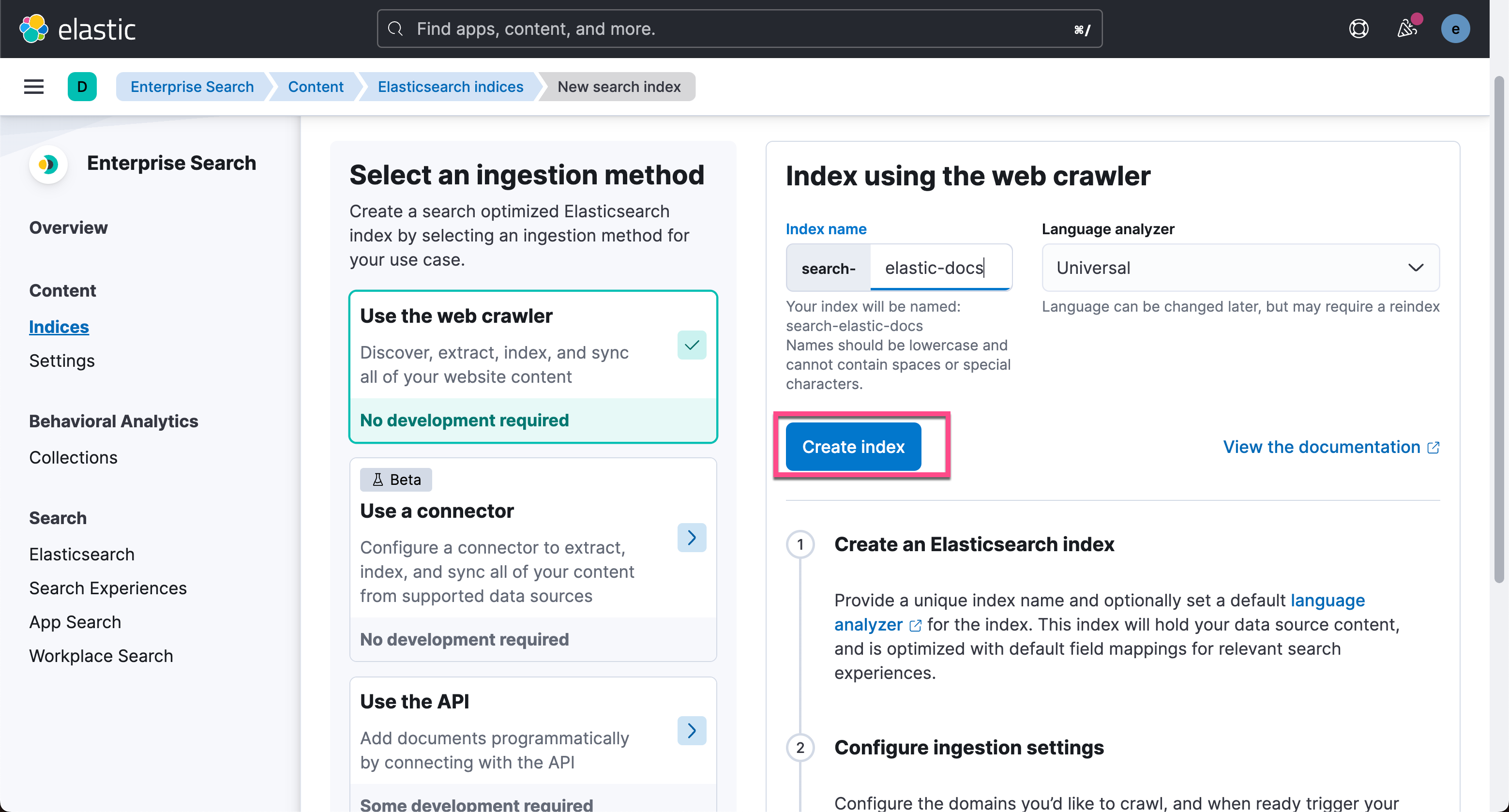



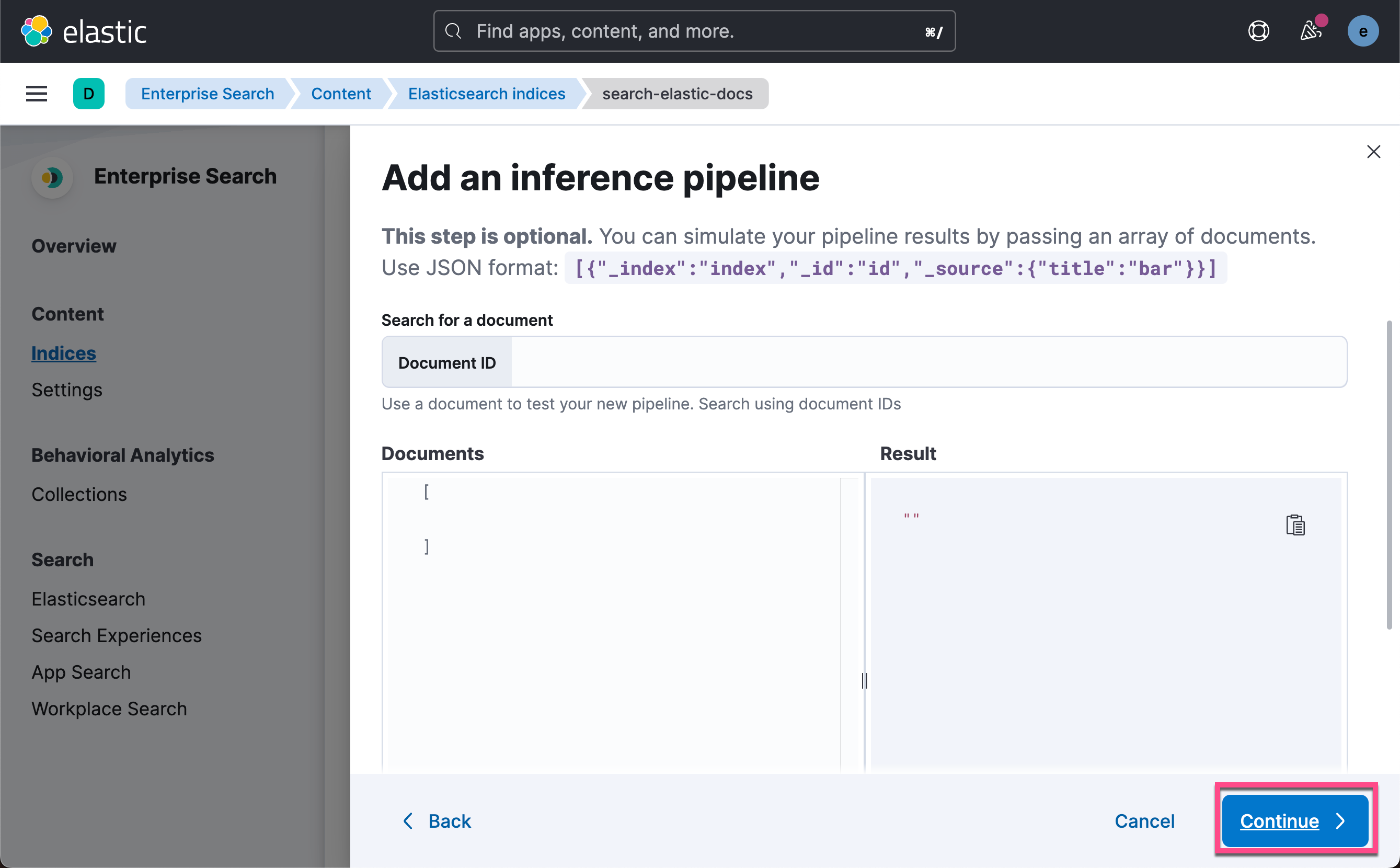

我们接着去 Dev Tools,并打入如下的命令:
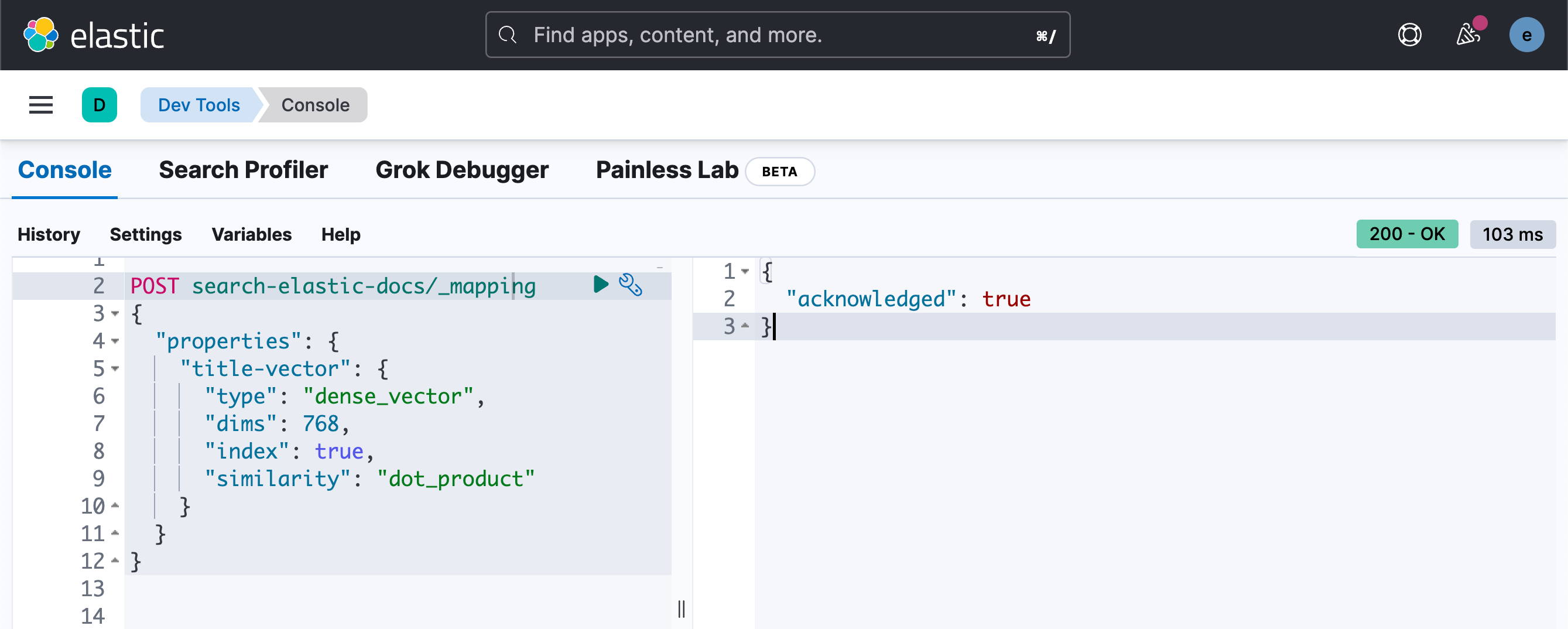
POST search-elastic-docs/_mapping
{"properties": {"title-vector": {"type": "dense_vector","dims": 768,"index": true,"similarity": "dot_product"}}
} 
接下来,我们来配置网络爬虫以爬取 Elastic Docs 站点:




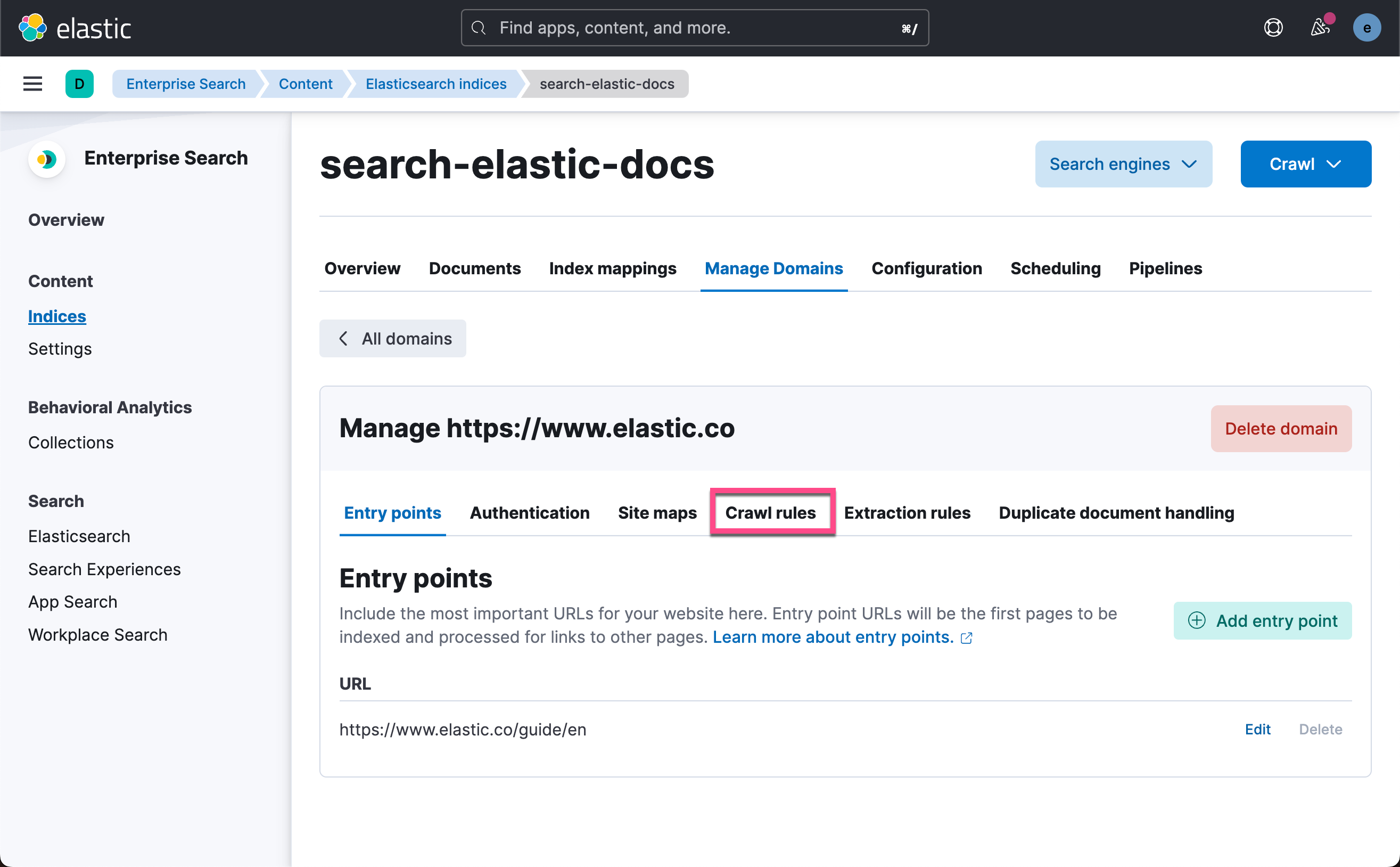
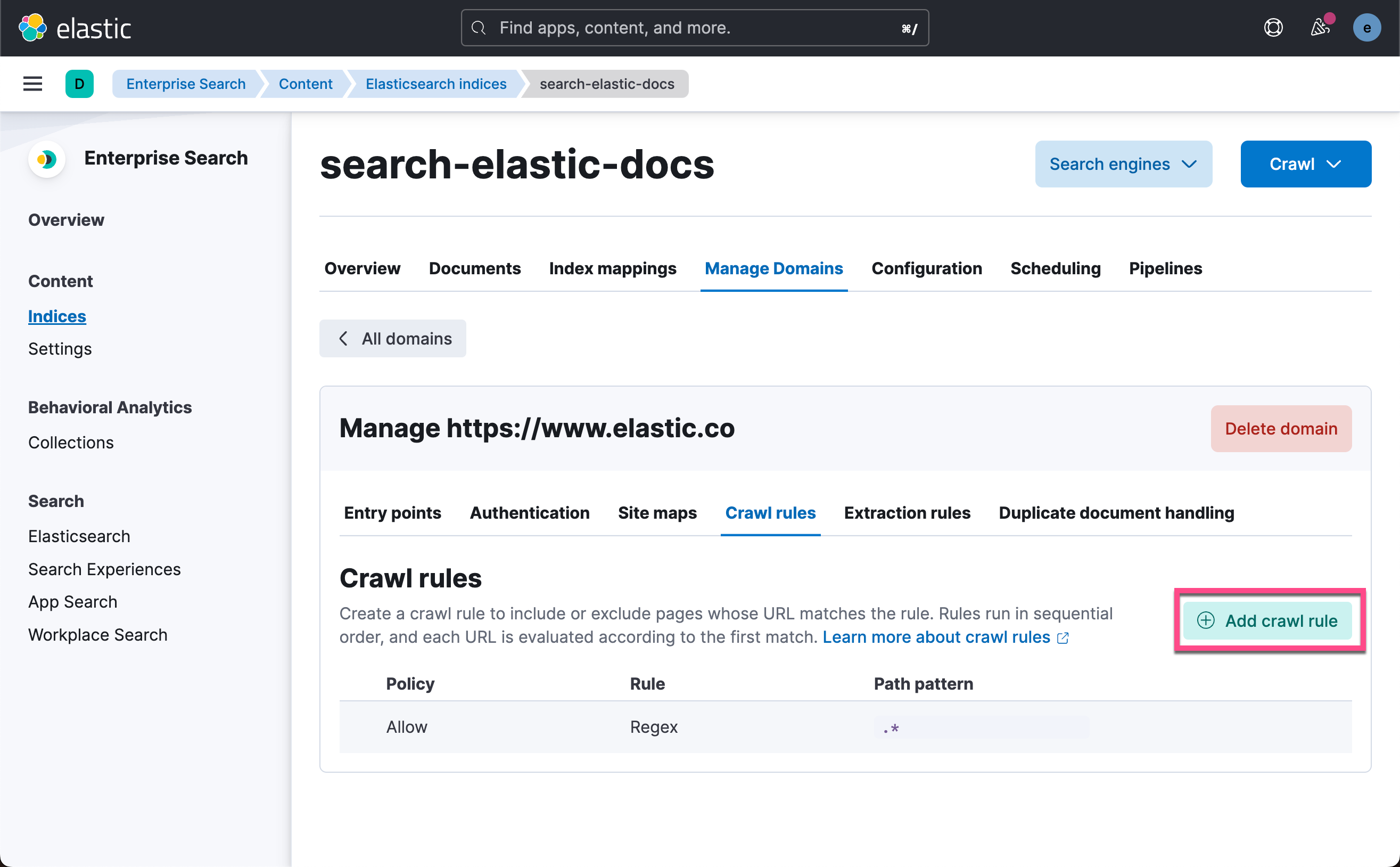
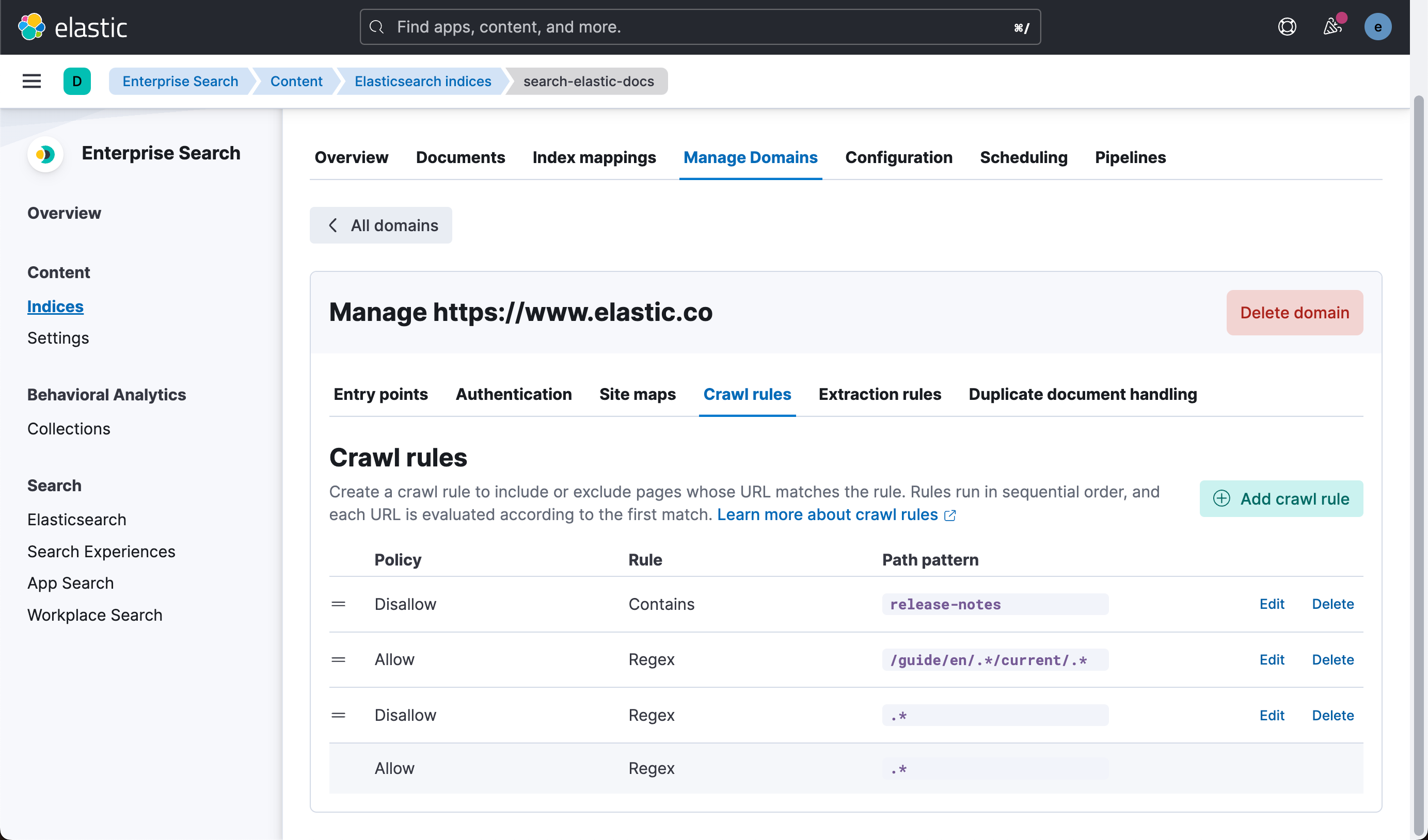
我们从下开始输入,直到顶部。我们输入如下的字符串:
release-notes
/guide/en/.*/current/.*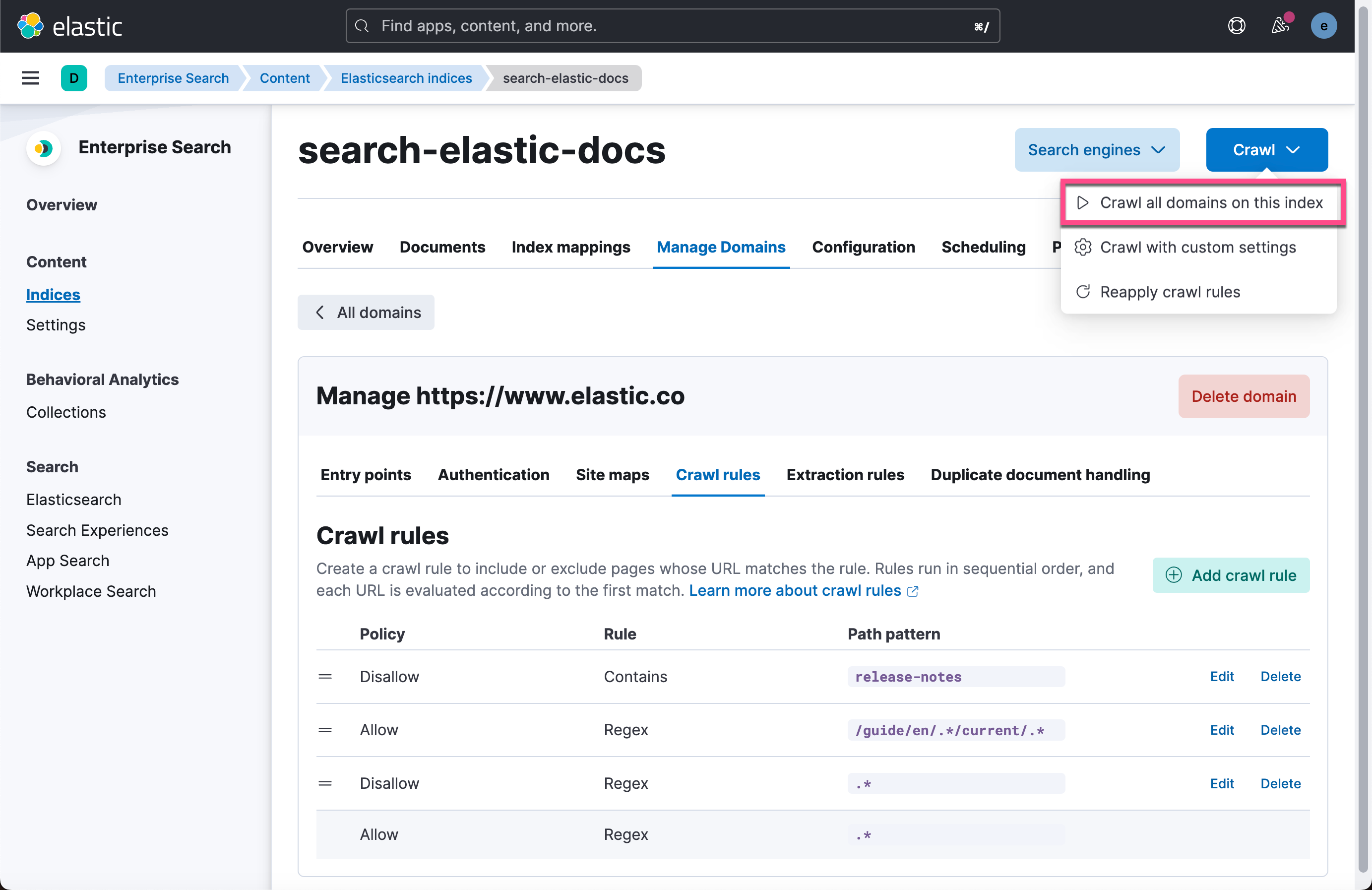
Elasticsearch 的网络爬虫现在将开始爬取文档站点,为标题字段生成向量,并对文档和向量建立索引。

我们回到 Dev Tools 进行查看:

我们可以看到一个叫做 .ds-logs-elastic_crawler-default-2023.04.28-000001 的索引 及 search-elastic-docs 已经生成。如果我们查看的话,我们可以看到一些结果:

我们可以看到 title-vector 是一个矢量字段。它是一个 768 维的向量。这个可以被用于我们来做搜索。随着时间的推移,我们会发现 search-elastic-docs 的大小在不断地变化,并且一直在增大:

我们需要等一段时间。直至它完成。
搜索数据
一旦数据完全被爬完,我们可以修改下载下来的文件,并做如下的修改:
elasticdocs_gpt.py
import os
import streamlit as st
import openai
from elasticsearch import Elasticsearch# This code is part of an Elastic Blog showing how to combine
# Elasticsearch's search relevancy power with
# OpenAI's GPT's Question Answering power
# https://www.elastic.co/blog/chatgpt-elasticsearch-openai-meets-private-data# Code is presented for demo purposes but should not be used in production
# You may encounter exceptions which are not handled in the code# Required Environment Variables
# openai_api - OpenAI API Key
# cloud_id - Elastic Cloud Deployment ID
# cloud_user - Elasticsearch Cluster User
# cloud_pass - Elasticsearch User Passwordprint("App started...")USERNAME = "elastic"
PASSWORD = "*CpJpvlY4A+nqDeCv5l="
ELATICSEARCH_ENDPOINT = "localhost:9200"
ELASTCSEARCH_CERT_PATH = "/Users/liuxg/elastic/elasticsearch-8.7.0/config/certs/http_ca.crt"
CERT_FINGERPRINT = "5a4b34414532c53698e4006e6c2b2c1c8d90d4a9d1bd995198fe6e902de00a35"openai.api_key = os.environ['openai_api']
model = "gpt-3.5-turbo-0301"# Connect to Elastic Cloud cluster
def es_connect(cid, user, passwd):es = Elasticsearch(cloud_id=cid, http_auth=(user, passwd))return esdef es_connect_with_cert():url = f'https://{USERNAME}:{PASSWORD}@{ELATICSEARCH_ENDPOINT}'es = Elasticsearch(url, ca_certs = ELASTCSEARCH_CERT_PATH, verify_certs = True)return es# Search ElasticSearch index and return body and URL of the result
def search(query_text):# cid = os.environ['cloud_id']# cp = os.environ['cloud_pass']# cu = os.environ['cloud_user']# es = es_connect(cid, cu, cp)es = es_connect_with_cert()# Elasticsearch query (BM25) and kNN configuration for hybrid searchquery = {"bool": {"must": [{"match": {"title": {"query": query_text,"boost": 1}}}],"filter": [{"exists": {"field": "title-vector"}}]}}knn = {"field": "title-vector","k": 1,"num_candidates": 20,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": query_text}},"boost": 24}fields = ["title", "body_content", "url"]index = 'search-elastic-docs'resp = es.search(index=index,query=query,knn=knn,fields=fields,size=1,source=False)body = resp['hits']['hits'][0]['fields']['body_content'][0]url = resp['hits']['hits'][0]['fields']['url'][0]return body, urldef truncate_text(text, max_tokens):tokens = text.split()if len(tokens) <= max_tokens:return textreturn ' '.join(tokens[:max_tokens])# Generate a response from ChatGPT based on the given prompt
def chat_gpt(prompt, model="gpt-3.5-turbo", max_tokens=1024, max_context_tokens=4000, safety_margin=5):# Truncate the prompt content to fit within the model's context lengthtruncated_prompt = truncate_text(prompt, max_context_tokens - max_tokens - safety_margin)response = openai.ChatCompletion.create(model=model,messages=[{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": truncated_prompt}])return response["choices"][0]["message"]["content"]st.title("ElasticDocs GPT")# Main chat form
with st.form("chat_form"):query = st.text_input("You: ")submit_button = st.form_submit_button("Send")# Generate and display response on form submission
negResponse = "I'm unable to answer the question based on the information I have from Elastic Docs."
if submit_button:resp, url = search(query)print(resp)prompt = f"Answer this question: {query}\nUsing only the information from this Elastic Doc: {resp}\nIf the answer is not contained in the supplied doc reply '{negResponse}' and nothing else"answer = chat_gpt(prompt)if negResponse in answer:st.write(f"ChatGPT: {answer.strip()}")else:st.write(f"ChatGPT: {answer.strip()}\n\nDocs: {url}")
在上面我们需要根据自己的配置修改如下的这个部分:
USERNAME = "elastic"
PASSWORD = "*CpJpvlY4A+nqDeCv5l="
ELATICSEARCH_ENDPOINT = "localhost:9200"
ELASTCSEARCH_CERT_PATH = "/Users/liuxg/elastic/elasticsearch-8.7.0/config/certs/http_ca.crt"
CERT_FINGERPRINT = "5a4b34414532c53698e4006e6c2b2c1c8d90d4a9d1bd995198fe6e902de00a35"我们可以以如下的方式来运行:
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
我们接下来,在命令行中打入如下的命令来把 Open AI 的 API key 设置到变量中去:
export openai_api="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"注意:你需要把自己申请的 key 替换上面的 key。

接下来,我们使用如下的命令来运行:

如上所示,它显示的两个 url 在我的电脑上不可用,单独它的端口地址是对的。我在浏览器中打开地址 http://localhost:8501:
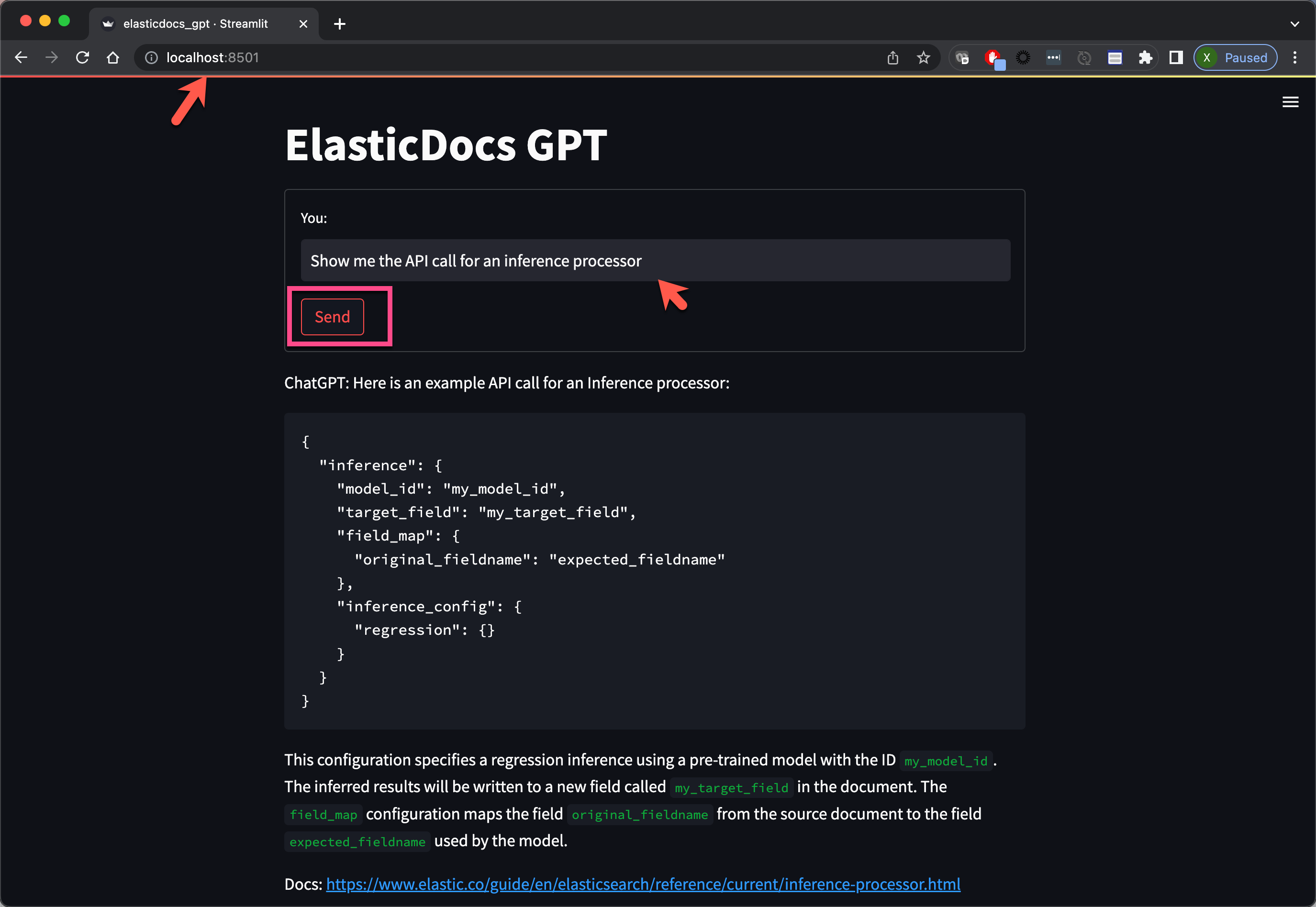
如上所示, 当我输入 “Show me the API call for an inference processor” 时,它显示如上所示的结果。我们再使用一个例子 “How do I add a new integration to elastic agent”:
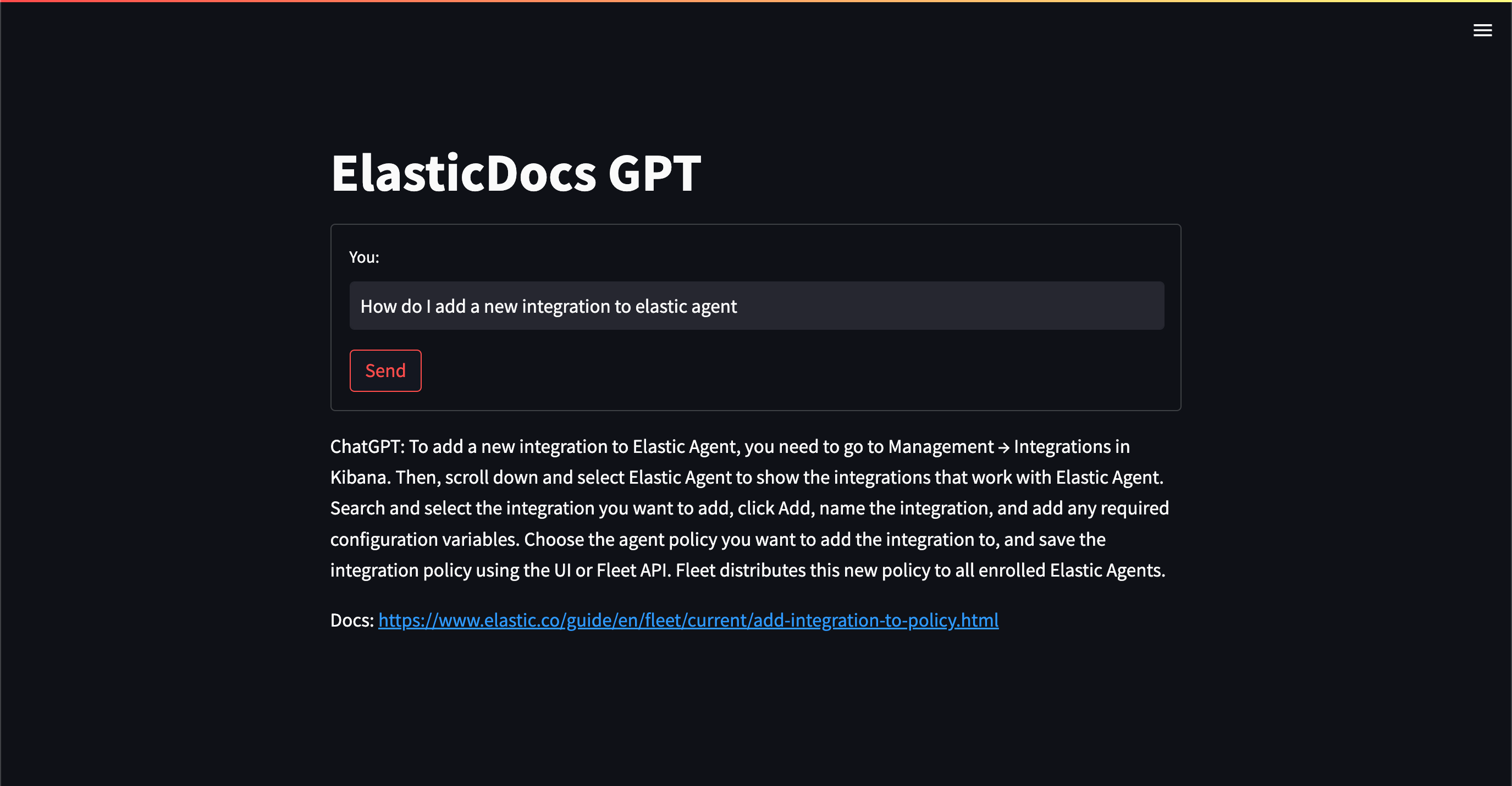
这个是在我们的数据还在爬的途中时生成的结果。如下是在完成一半的过程中搜索到的结果:

随着数据的增多,我们可以看到如下的结果:

如前所述,允许 ChatGPT 仅根据训练过的数据回答问题的风险之一是它容易产生错误答案的幻觉。 该项目的目标之一是为 ChatGPT 提供包含正确信息的数据,并让它制定答案。
我们等数据完全被爬完后,我们搜索 “How to install elasticsearch on macOS?”:


那么当我们给 ChatGPT 一个不包含正确信息的文档时会发生什么? 比如,让它告诉你如何造船(Show me how to build a boat)(Elastic 的文档目前没有涵盖)
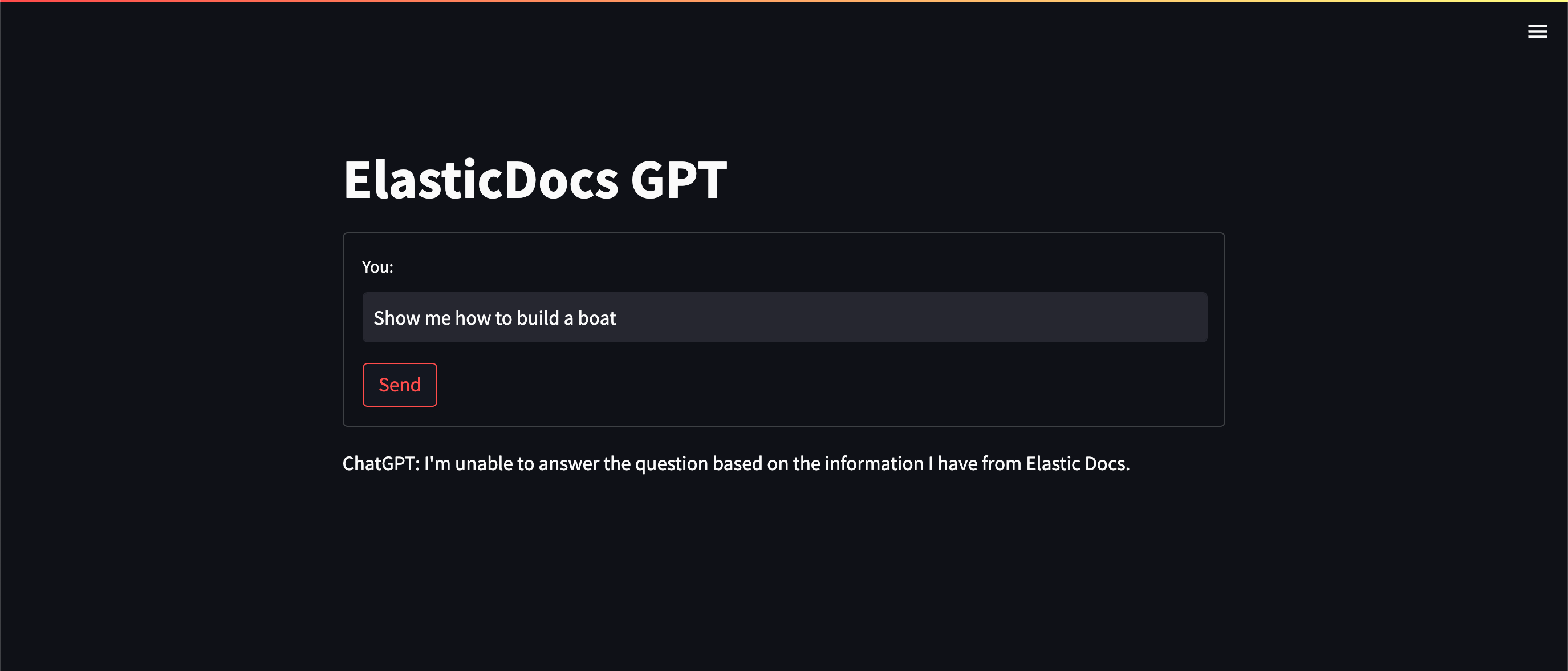
当 ChatGPT 无法在我们提供的文档中找到问题的答案时,它会退回到我们的提示指令,简单地告诉用户它无法回答问题。









![开发一个看番app[樱花动漫移动端app]](https://img-blog.csdnimg.cn/e9ea2fd596e0452fb1feefc4881af981.png)



![[EF]事务管理+批量删除](https://img-blog.csdnimg.cn/0e703298349b40ce92f24d6e39116483.png#pic_center)