前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。CBAM(Convolutional Block Attention Module) 是一种用于前馈卷积神经网络的简单而有效的注意力模块,它是一种结合了通道(channel)和空间(spatial)的注意力机制模块,相比于SE-Net只关注通道注意力机制可以取得更好的结果。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
目录
🚀1.注意力机制原理
🚀2.CBAM论文
🚀3.CBAM方法介绍
🚀4.添加CBAM注意力机制的方法
💥💥步骤1:在common.py中添加CBAM模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改yolov5s_CBAM.yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:修改train.py中的'--cfg'默认参数
🚀5.添加C3_CBAM注意力机制的方法(在C3模块中添加)
💥💥步骤1:在common.py中添加CBAMBottleneck和C3_CBAM模块
💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.注意力机制原理
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言,模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。 🍃
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。🍃
一般而言,注意力机制可以分为:通道注意力机制、空间注意力机制和二者的结合。
空间注意力机制(关注每个通道的比重),通道注意力机制(关注每个像素点的比重),比较典型的如SENet,而CBAM则是二者的结合。🌱
🚀2.CBAM论文
论文题目:《CBAM:Convolutional Block Attention Module》
论文地址: https://arxiv.org/pdf/1807.06521.pdf代码实现: https://github.com/luuuyi/CBAM.PyTorch
论文(2018年)提出了一种轻量的注意力模块( CBAM,Convolutional Block Attention Module ),可以在通道和空间维度上进行 Attention 。论文在 ResNet 和 MobileNet 等经典结构上添加了 CBAM 模块并进行对比分析,同时也进行了可视化,发现 CBAM 更关注识别目标物体,这也使得 CBAM 具有更好的解释性。🌾

由论文可知,CBAM的网络结构包括通道注意力机制和空间注意力机制。作者将二者串联搭建,且通道注意力模块在前,空间注意力模块在后。
经过实验,作者发现:串联搭建比并联搭建效果好,先进行通道注意力比先空间注意力效果好。🌾
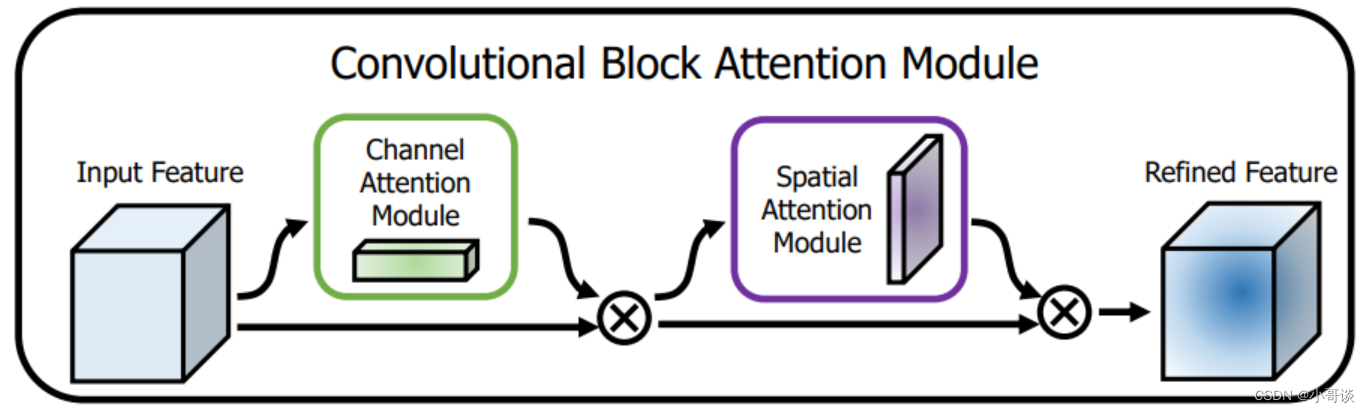
🚀3.CBAM方法介绍
卷积神经网络(CNN)在计算机视觉任务中取得了显著的成功。为了进一步提高CNN的性能,研究人员提出了一种名为“卷积神经网络注意力模块”(Convolutional Block Attention Module, CBAM)的注意力机制。CBAM旨在自动学习输入特征图的空间和通道注意力权重,从而更好地捕捉图像中的局部信息和全局上下文。🌟
CBAM包括两个主要组成部分: 空间注意力模块和通道注意力模块。它们可以作为插件,轻松地集成到现有的 CNN 架构中,以提高性能。
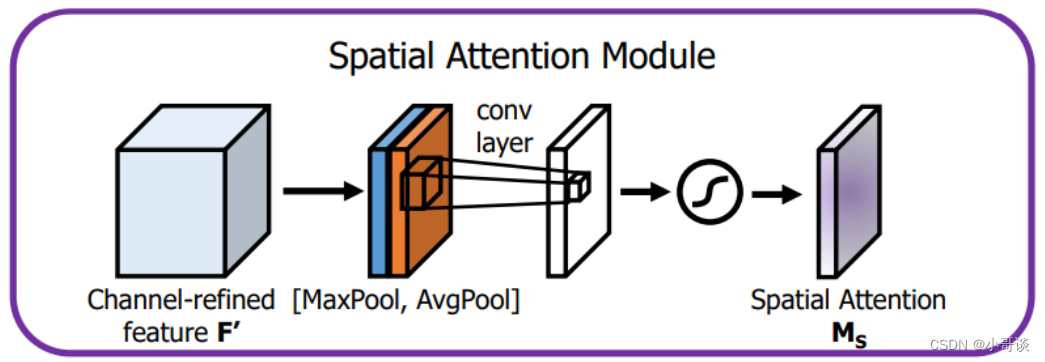
空间注意力模块 (Spatial Attention Module) : 空间注意力模块的目的是为输入特征图的每个位置分配一个注意力权重。这些权重可帮助网络集中注意力于感兴趣的区域。
空间注意力模块主要包括以下步骤:👇
- a.对输入特征图进行全局平均池化和全局最大池化操作。
- b.将池化后的特征图按通道相加,得到两个1维向量。
- c.对这两个向量进行点积,形成一个注意力权重矩阵。
- d.将注意力权重矩阵应用于输入特征图,得到空间注意力调整后的特征图。
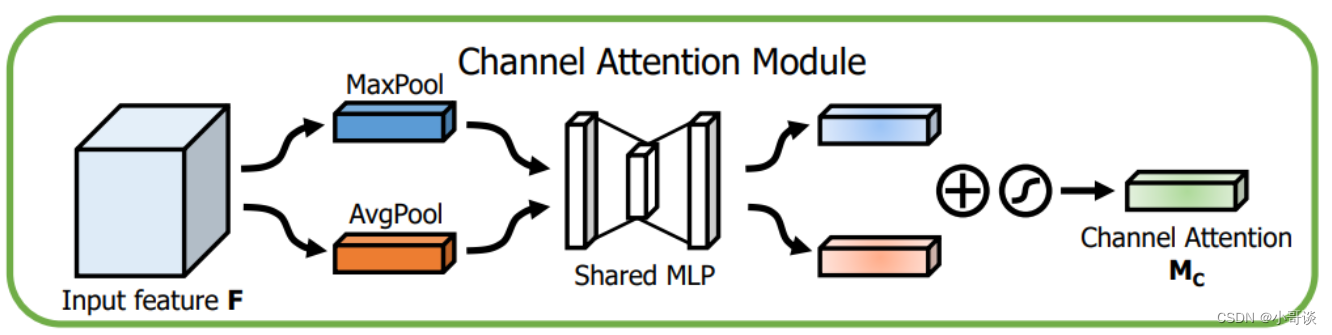
通道注意力模块 (ChannelAttention Module) : 通道注意力模块旨在为输入特征图的每个通道分配一个权重,从而强调重要的通道并抑制不太重要的通道。
通道注意力模块主要包括以下步骤:👇
- a.对输入特征图进行全局平均池化和全局最大池化操作。
- b.使用全连接层 (MLP) 学习每个通道的权重。
- c.将学到的权重应用于输入特征图,得到通道注意力调整后的特征图。
最后,将空间注意力模块和通道注意力模块的输出相加,形成CBAM调整后的特征图。这个特征图可以继续传递到CNN的下一层。
实验证明,CBAM在各种计算机视觉任务上都能显著提高性能,如图像分类、目标检测和语义分割等。它是一种通用的注意力机制,可以与任何卷积神经网络架构相结合。🌾
说明:♨️♨️♨️
CBAM的核心:
应用了Channel Attention Module(通道注意模块)和Spatial Attention Module(空间注意模块)的结合,对输入进来的特征层分别进行通道注意力模块和空间注意力模块的处理。
其中,通道注意力用于处理特征图通道的分配关系,而空间注意力可使神经网络更加关注图像中对分类起决定作用的像素区域而忽略无关紧要的区域。同时对这两个维度进行注意力的分配增强了注意力机制对模型性能的提升效果。
🚀4.添加CBAM注意力机制的方法
💥💥步骤1:在common.py中添加CBAM模块
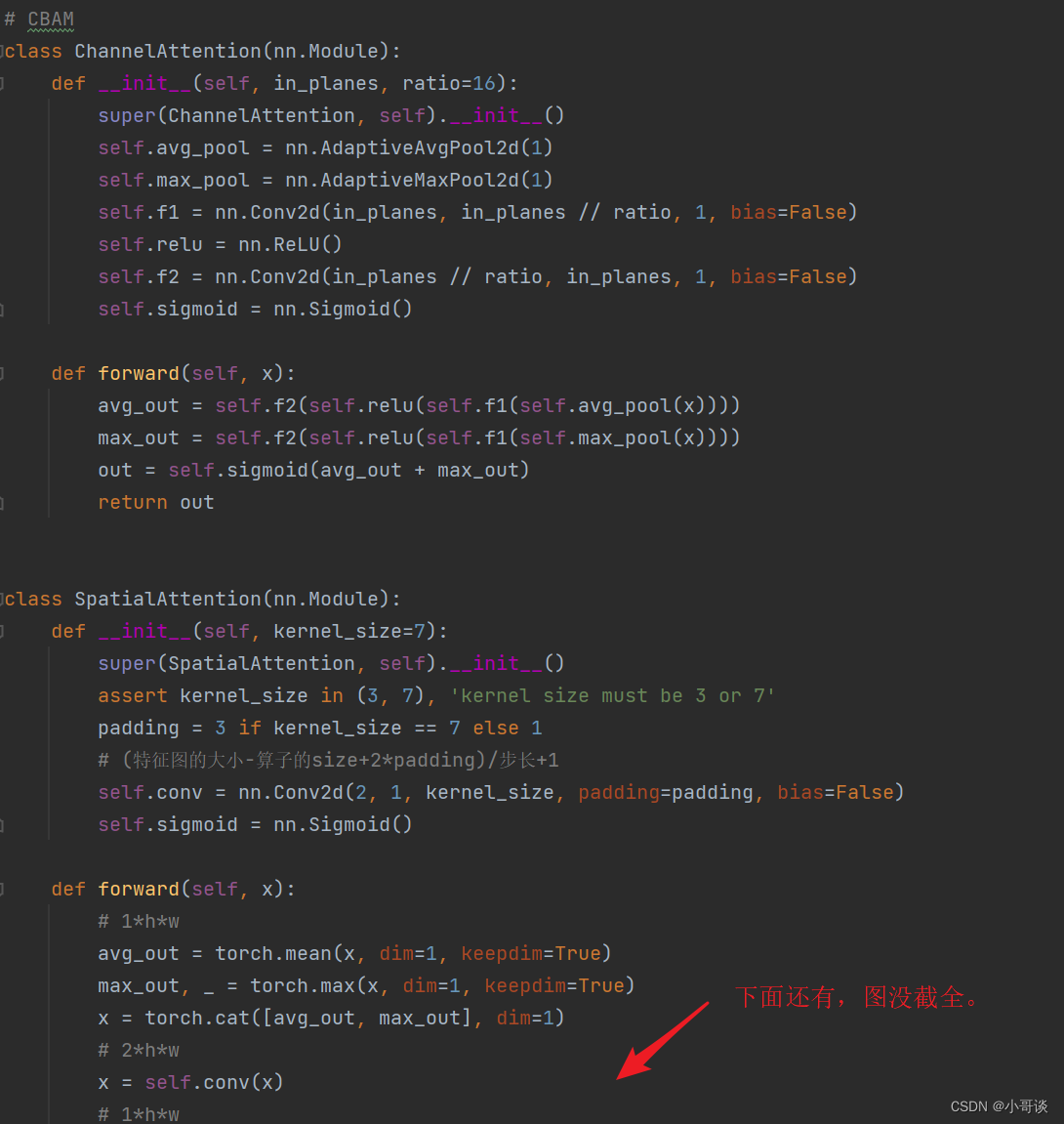
将下面的CBAM模块的代码复制粘贴到common.py文件的末尾。
# CBAM
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu = nn.ReLU()self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))max_out = self.f2(self.relu(self.f1(self.max_pool(x))))out = self.sigmoid(avg_out + max_out)return outclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1# (特征图的大小-算子的size+2*padding)/步长+1self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 1*h*wavg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)#2*h*wx = self.conv(x)#1*h*wreturn self.sigmoid(x)class CBAM(nn.Module):def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansionsuper(CBAM, self).__init__()self.channel_attention = ChannelAttention(c1, ratio)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):out = self.channel_attention(x) * x# c*h*w# c*h*w * 1*h*wout = self.spatial_attention(out) * outreturn out具体如下图所示:
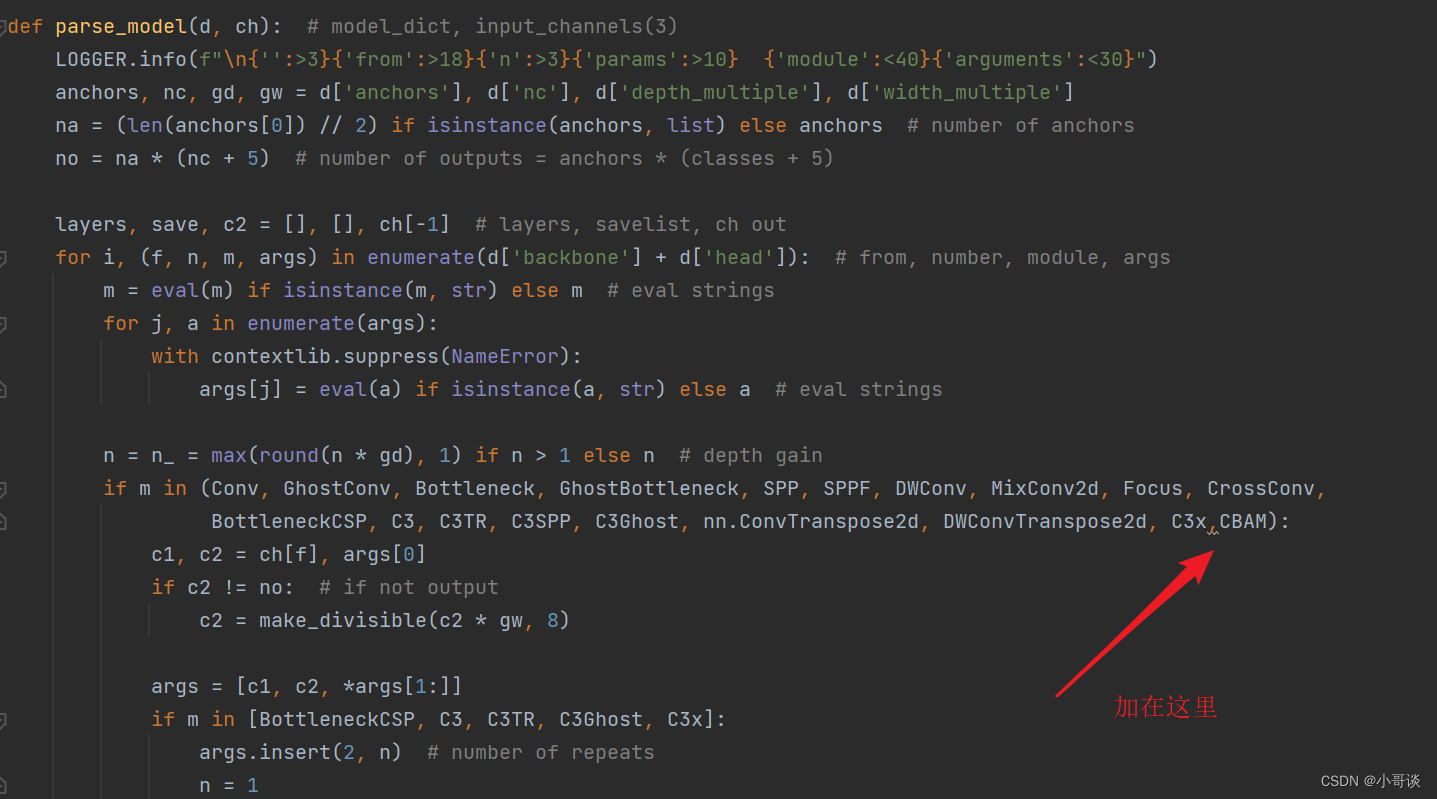
💥💥步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数,然后将CBAM添加到这个注册表里。
💥💥步骤3:创建自定义yaml文件
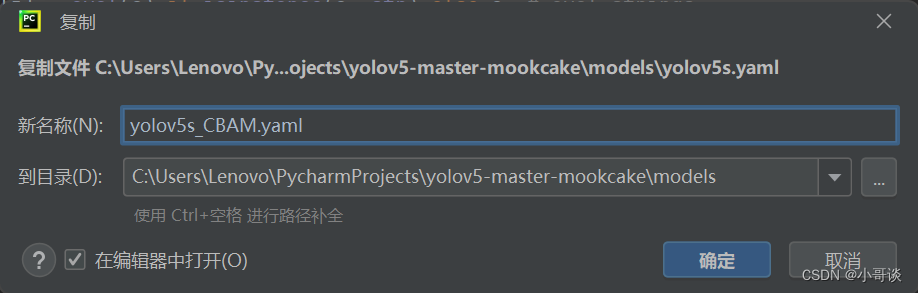
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_CBAM.yaml。
💥💥步骤4:修改yolov5s_CBAM.yaml文件
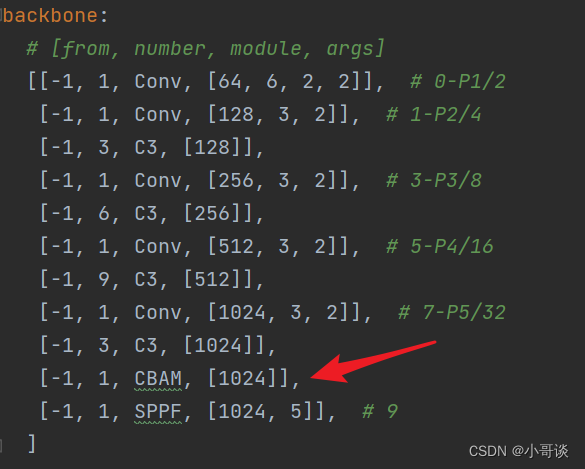
本步骤是修改yolov5s_CBAM.yaml,将CBAM添加到我们想添加的位置。在这里,我将[-1,1,CBAM,[1024]]添加到SPPF的上一层,即下图中所示位置。
说明:♨️♨️♨️
注意力机制可以加在Backbone、Neck、Head等部分,常见的有两种:一种是在主干的SPPF前面添加一层;二是将Backbone中的C3全部替换。不同的位置效果可能不同,需要我们去反复测试。
这里需要注意一个问题,当在网络中添加新的层之后,那么该层网络后面的层的编号会发生变化。原本Detect指定的是[17,20,23]层,所以,我们在添加了CBAM模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24]。同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,我们刚才把CBAM加到了第9层,所以第9层之后的编号都需要加1,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。🌻
具体如下图所示。

💥💥步骤5:验证是否加入成功
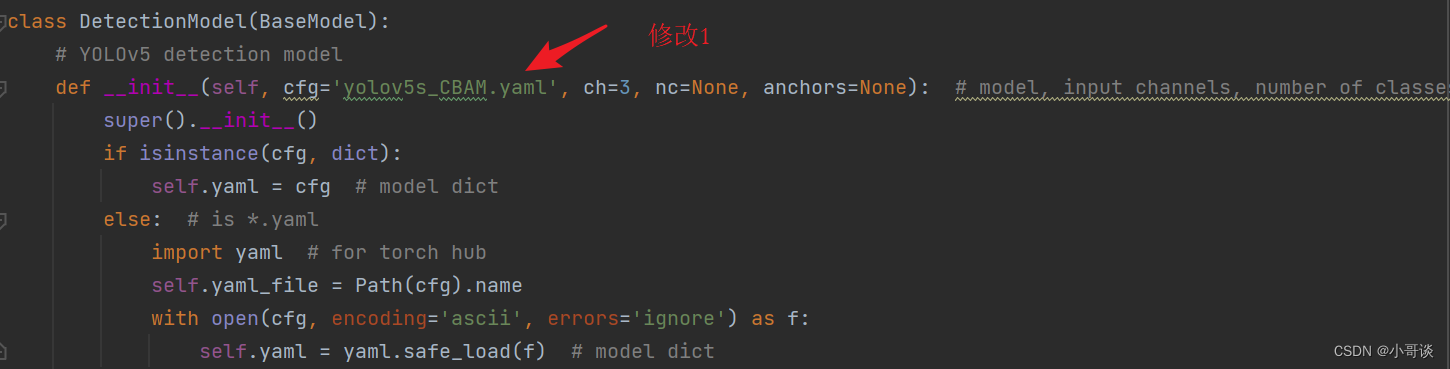
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_CBAM.yaml。
然后运行yolo.py,得到结果。
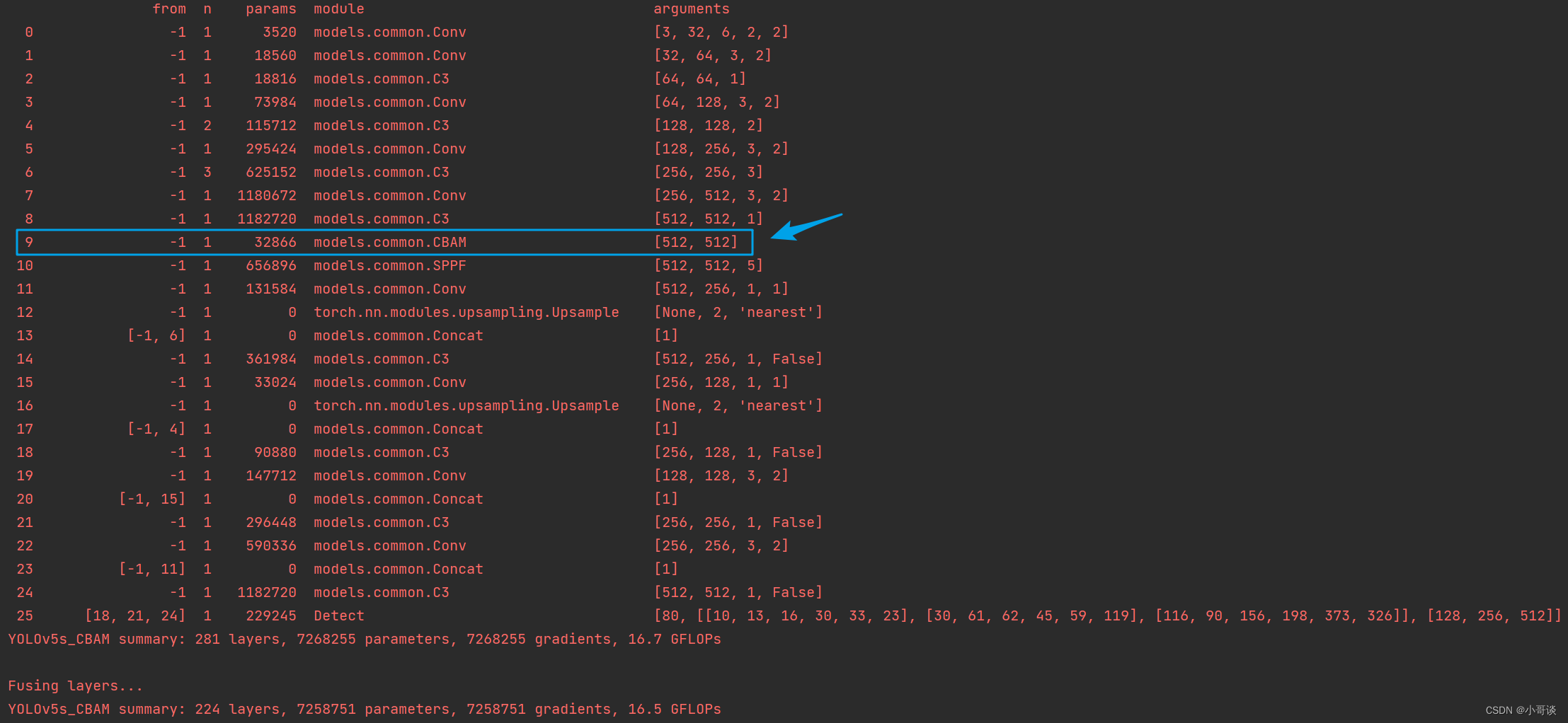
找到了CBAM模块,说明我们添加成功了。🎉🎉🎉
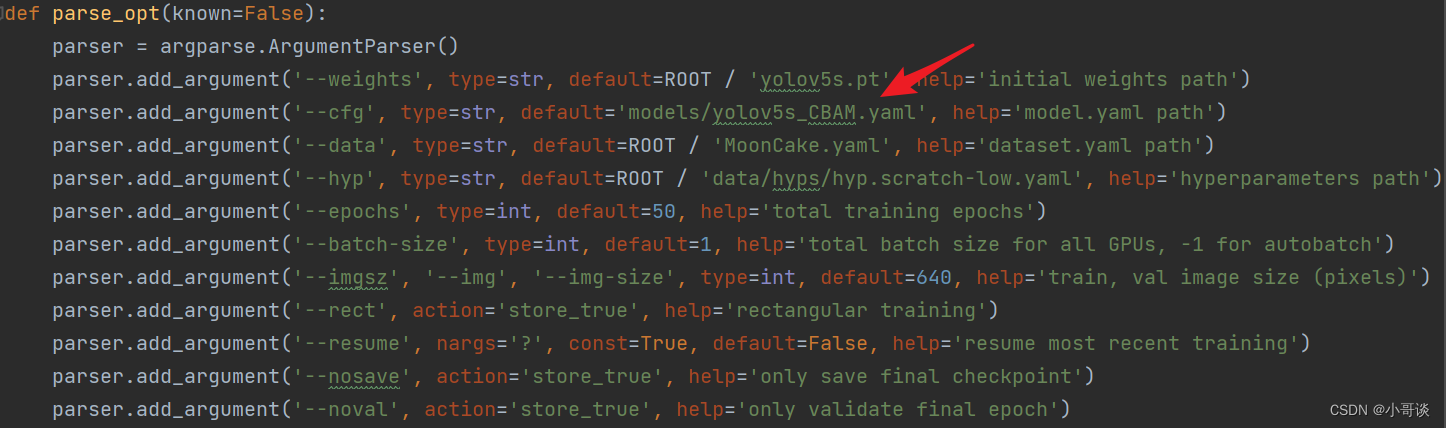
💥💥步骤6:修改train.py中的'--cfg'默认参数
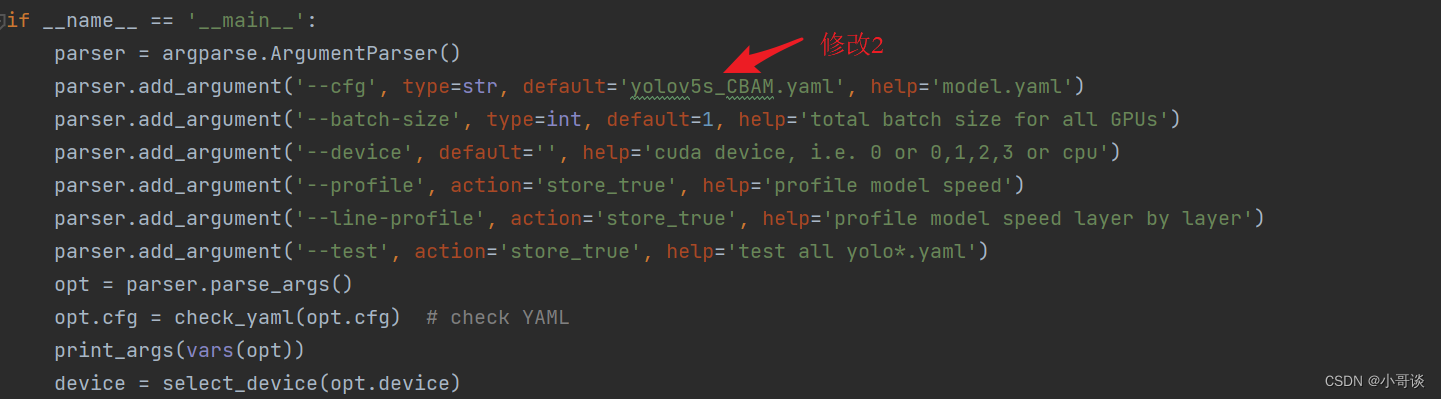
在train.py文件中找到 parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_CBAM.yaml',然后就可以开始进行训练了。🎈🎈🎈
🚀5.添加C3_CBAM注意力机制的方法(在C3模块中添加)
上面是单独添加注意力层,接下来的方法是在C3模块中加入注意力层。这个策略是将CBAM注意力机制添加到Bottleneck,替换Backbone中所有的C3模块。
💥💥步骤1:在common.py中添加CBAMBottleneck和C3_CBAM模块
将下面的代码复制粘贴到common.py文件的末尾。
# CBAM
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu = nn.ReLU()self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))max_out = self.f2(self.relu(self.f1(self.max_pool(x))))out = self.sigmoid(avg_out + max_out)return outclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1# (特征图的大小-算子的size+2*padding)/步长+1self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 1*h*wavg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)#2*h*wx = self.conv(x)#1*h*wreturn self.sigmoid(x)class CBAMBottleneck(nn.Module):# ch_in, ch_out, shortcut, groups, expansion, ratio, kernel_sizedef __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, kernel_size=7):super(CBAMBottleneck, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2# 加入CBAM模块self.channel_attention = ChannelAttention(c2, ratio)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):# 考虑加入CBAM模块的位置:bottleneck模块刚开始时、bottleneck模块中shortcut之前,这里选择在shortcut之前x2 = self.cv2(self.cv1(x)) # x和x2的channel数相同# 在bottleneck模块中shortcut之前加入CBAM模块out = self.channel_attention(x2) * x2# print('outchannels:{}'.format(out.shape))out = self.spatial_attention(out) * outreturn x + out if self.add else outclass C3_CBAM(C3):# C3 module with CBAMBottleneck()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channelsself.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
在yolo.py文件的 parse_model函数中,加入CBAMBottleneck、C3_CBAM这两个模块。

💥💥步骤3:创建自定义yaml文件
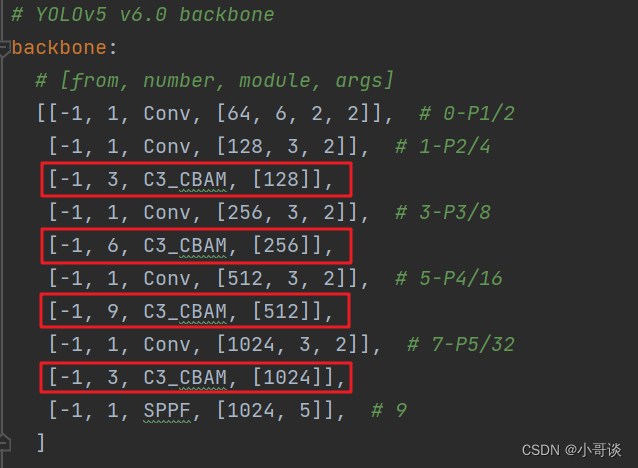
按照上面的步骤创建yolov5s_C3_CBAM.yaml文件,替换4个C3模块。
💥💥步骤4:验证是否加入成功
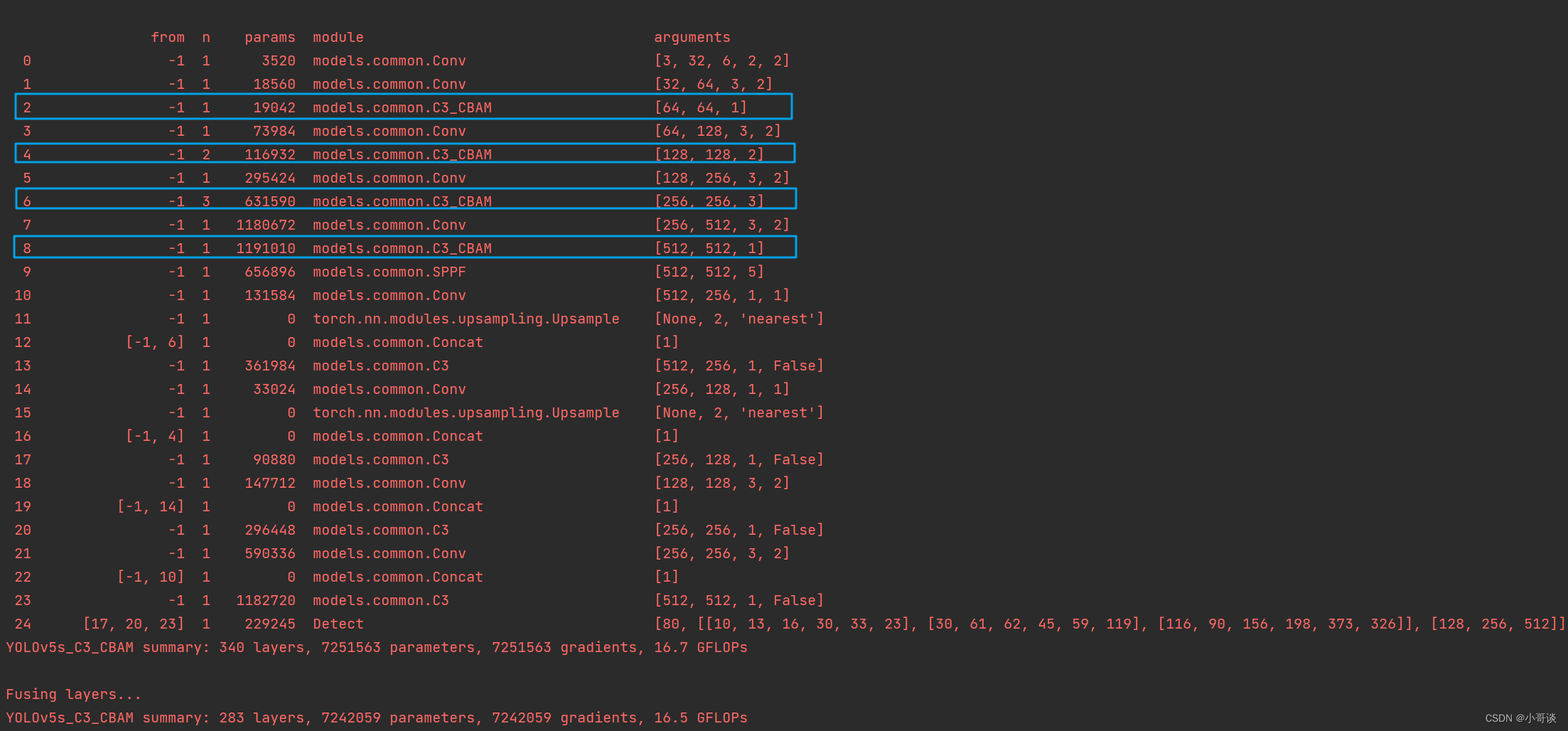
在yolo.py文件里配置刚才我们自定义的yolov5s_C3_CBAM.yaml,然后运行。
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_C3_CBAM.yaml',然后就可以开始进行训练了。🎈🎈🎈