注意: 本文案例采用 PostgreSQL 作为案例,与 MySQL 语法有些许不同。
目录
- 1. SQL 完整查询语句
- 2. SQL 执行顺序
- 3. 案例
1. SQL 完整查询语句
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias][left | right | inner join table_name2] -- 联合查询[WHERE ...] -- 指定结果需满足的条件[GROUP BY ...] -- 指定结果按照哪几个字段来分组[HAVING] -- 过滤分组的记录必须满足的次要条件[ORDER BY ...] -- 指定查询记录按一个或多个条件排序[LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- 指定查询的记录从哪条至哪条


2. SQL 执行顺序
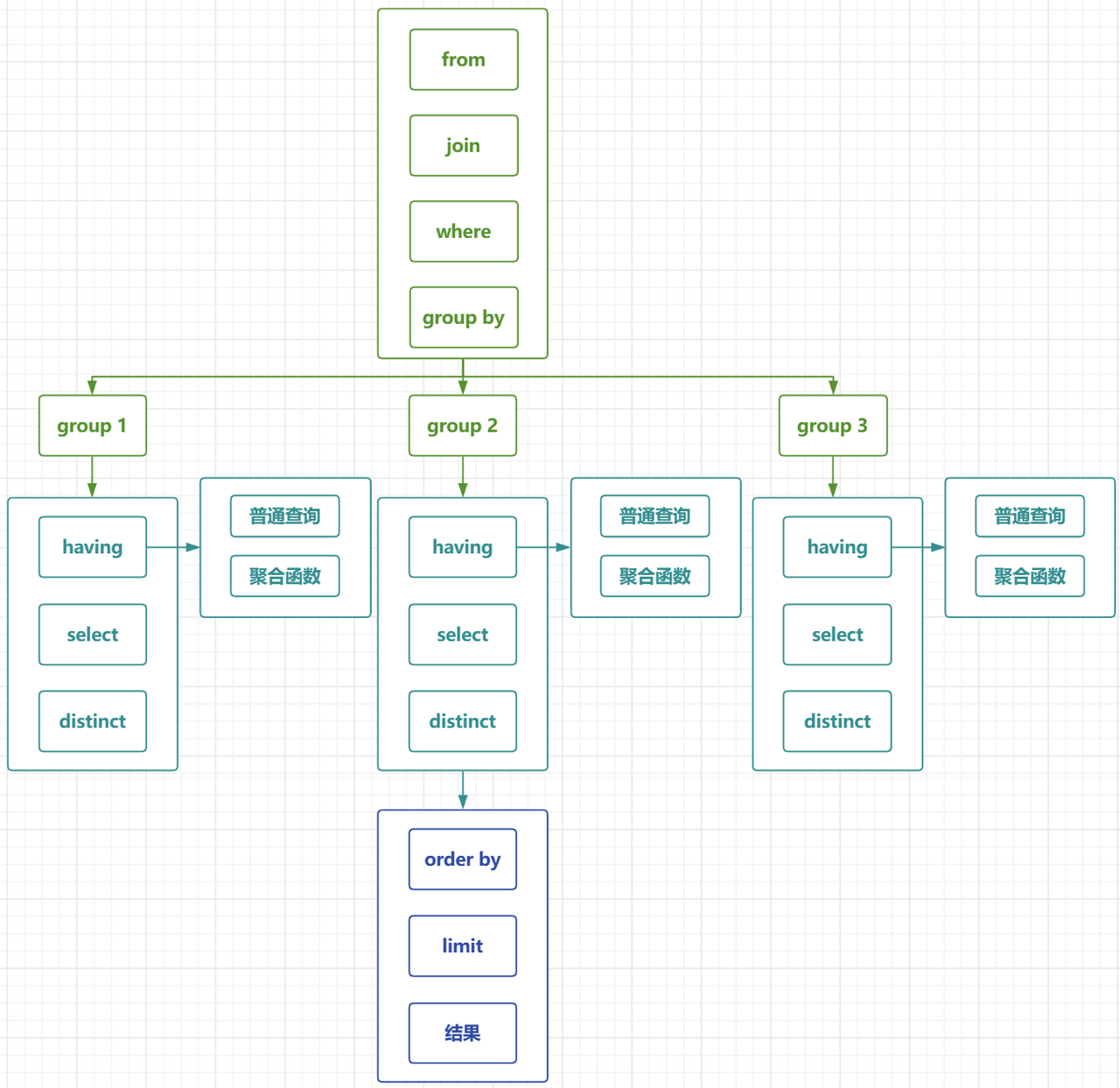
- 先执行
from、join来确定表之间的连接关系,获取初步数据 where初步筛选数据group by分组- 各组分别执行
having中的普通筛选或聚合函数筛选 - 将获取到的所有数据和
select字段进行匹配(如果是聚合函数的查询结果,select 的查询结果会新增一条字段) - 查询结果去重
distinct - 合并各组的查询结果,按照
order by的条件进行排序 limit对结果进行分页处理
3. 案例
-
表:


-
流程分析:
-
from&join确定要查哪些表FROM"t_user" AS uINNER JOIN "t_salary" AS s ON u.uid = s.u_id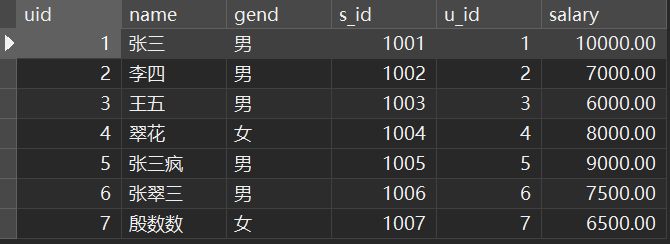
-
where对数据进行初步筛选WHEREs.salary > 7000
-
group by对数据进行分组注意:
- group by 分组的是 where 初步筛选之后的数据
- group by 是根据某一项或多项对数据进行分组
- 由此,其他项的数据会被重合
- 所以,pg 会要求其他项数据 必须出现在 GROUP BY 子句中或者在聚合函数中使用,保证数据的真实性
GROUP BY-- 因为 u.uid = s.u_id,所以只需要写一个 uid 就行uid,"name", gend, s_id, salary
-
having筛选数据注意:
- having 筛选的是分组(group by)后的数据
- having 的筛选条件可以是聚合函数,也可以是普通条件,但 where 不能用聚合函数
HAVINGgend = '男'
-
select distinct匹配要返回的字段,并去重SELECT DISTINCTu.uid "人员编号","name" AS "姓名",gend AS "性别",s_id AS "薪资序列",sum(salary) "薪水"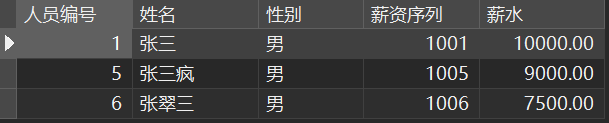
-
order by对要返回的数据进行排序注意:
- order by 的字段必须出现在 select 中
- desc——倒序排列,asc——顺序排列(默认)
ORDER BYSUM ( salary ) DESC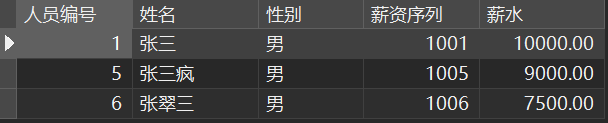
-
limit分页显示最终的数据注意:
- pg 中 limit 的用法与 mysql 有所不同
- limit 1 (只写一个数字)代表要取出哪条数据,这里是取出第一条数据
- limit 2 offset 0 (写两个数字)第一个数字代表要取出第几条,第二个表示从哪里开始取,这里是从第一个数据开始取第二条数据
LIMIT 1
LIMIT 1 OFFSET 1
-




![[Go版]算法通关村第十三关青铜——数字数学问题之统计问题、溢出问题、进制问题](https://img-blog.csdnimg.cn/c8ecf754cc75450fbc4abff585341e2c.png)





![java八股文面试[java基础]——异常](https://img-blog.csdnimg.cn/c0a4aea23c394ca6aa3085108a5c508d.png)

