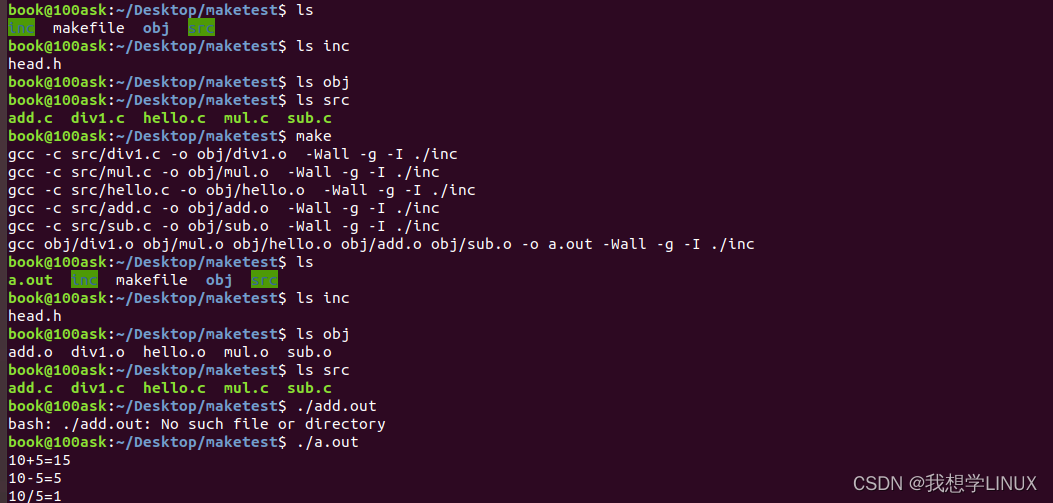
目录
- 0 摘要
- 1 引言
- 2 深度学习方法概述
- 2.1 监督式学习
- 2.2 无监督学习
- 2.2.1 自编码器 (Autoencoders)
- 2.2.2 生成对抗网络(GANs)
- 2.2.3 自监督学习
- 2.3. 半监督学习
- 2.4 提高性能的策略
- 2.4.1 注意力机制
- 2.4.2 领域知识
- 2.4.3 估计的不确定性
- 3 深度学习应用
- 3.1 分类
- 3.1.1 监督分类
- 3.1.2 无监督的方法
- 3.1.3 半监督学习
- 3.2 分割
- 3.2.1 基于监督学习的分割模型
- 3.2.2 基于无监督学习的分割模型
- 3.2.3 基于半监督学习的分割模型
- 3.3 检测
- 3.3.1 监督和半监督病变检测
- 3.3.2. 无监督病变检测(非预先指定的病变检测类型)
- 3.4 配准
- 3.4.1 深度迭代配准
- 3.4.2 监督配准
- 3.4.3 无监督配准
- 4 讨论
- 4.1 将深度学习和医学图像分析更好地结合起来
- 4.1.1 从特定任务的角度来看
- 4.1.2 论不同学习范式的视角
- 4.1.3 寻找更好的架构和流程
- 4.1.4 整合领域知识
- 4.2 迈向深度学习在临床环境中的大规模应用
- 4.2.1 图像数据集
- 4.2.2 性能评估
- 4.2.3 再现性
0 摘要
深度学习在开发新的医学图像处理算法方面获得了广泛的研究兴趣,基于深度学习的模型在各种医学成像任务中非常成功,以支持疾病检测和诊断。尽管取得了成功,但深度学习模型在医学图像分析中的进一步改进主要是由于缺乏大规模和良好注释的数据集。在过去的五年中,许多研究都集中在解决这一挑战上。在本文中,我们对这些最新的研究进行了回顾和总结,以提供深度学习方法在各种医学图像分析任务中的应用的全面概述。重点介绍了基于分类、分割、检测和 图像配准 等不同应用场景的无监督和半监督深度学习在医学图像分析中的最新进展和贡献。我们还讨论了主要的技术挑战,并提出了未来研究工作中可能的解决方案。
1 引言
在目前的临床实践中,癌症和/或许多其他疾病的检测和诊断的准确性取决于个别临床医生(例如放射科医生、病理学家)的专业知识(Kruger等人,1972年),这导致阅读和解释医学图像的读者之间存在很大差异。为了解决和克服这一临床挑战,许多计算机辅助检测和诊断(CAD)方案已经开发和测试,旨在帮助临床医生更有效地读取医学图像,并以更准确和客观的方式做出诊断决策。这种方法的科学原理是,使用计算机辅助定量图像特征分析可以帮助克服临床实践中的许多负面因素,包括临床医生专业知识的广泛差异,人类专家的潜在疲劳以及缺乏足够的医疗资源。
虽然早期的CAD方案是在20世纪70年代发展起来的(Meyers et al, 1964;Kruger et al, 1972;Sezaki和Ukena, 1973), CAD方案的进展加速自20世纪90年代中期以来(Doi等人,1999),由于开发和集成更先进的机器学习方法或模型到CAD方案。对于传统的CAD方案,一个常见的开发过程包括三个步骤:目标分割、特征计算和疾病分类。例如,Shi等人(2008)开发了一种CAD方案来实现数字乳房x光片的质量分类。首先使用改进的主动轮廓算法从背景中分割出包含目标质量的roi (Sahiner et al ., 2001)。然后利用大量的图像特征量化病灶的大小、形态、边缘几何、纹理等特征。从而将原始像素数据转换为具有代表性的特征向量。最后,在特征向量上应用基于LDA(线性判别分析)的分类模型对肿块恶性肿瘤进行识别。
相比之下,对于基于深度学习的模型,roi内部的隐藏模式是通过深度神经网络的分层架构逐步识别和学习的(LeCun et al, 2015)。在这个过程中,输入图像的重要属性会逐渐被识别和放大,用于某些任务(如分类、检测),而不相关的特征会被衰减和过滤掉。例如,描绘可疑肝脏病变的MRI图像带有像素阵列(Hamm等人,2019),每个条目被用作深度学习模型的一个输入特征。模型的前几层可以初步获得一些基本的病变信息,如肿瘤的形状、位置和方向。下一批层可以识别并保持与病变恶性相关的特征(如形状、边缘不规则),而忽略无关的变化(如位置)。相关特征将由后续更高层以更抽象的方式进一步处理和组合。当增加层数时,可以实现更高层次的特征表示。在整个过程中,隐藏在原始图像中的重要特征被基于一般神经网络的模型以自学的方式识别出来,从而不需要人工开发特征。
由于其巨大的优势,深度学习相关方法已经成为CAD领域的主流技术,并被广泛应用于各种任务中,如疾病分类(Li et al ., 2020a;Shorfuzzaman and Hossain, 2021;张等,2020a;Frid-Adar等,2018a;Kumar等人,2016,2017),ROI分割(Alom等人,2018;Yu et al ., 2019;Fan et al ., 2020),医学目标检测(Rijthoven et al ., 2018;Mei等,2021;Nair等,2020;Zheng et al ., 2015)和图像配准(Simonovsky et al ., 2016;Sokooti et al, 2017;Balakrishnan et al, 2018)。在各种深度学习技术中,监督学习最早被用于医学图像分析。虽然它已经成功地应用于许多应用中(Esteva等人,2017;Long等人,2017),在许多情况下,监督模型的进一步部署主要受到大多数医疗数据集规模有限的阻碍。与计算机视觉中的常规数据集相比,医学图像数据集通常包含相对较少的图像(例如,少于10,000),并且在许多情况下,只有一小部分图像被专家注释。为了克服这一限制,无监督和半监督学习方法在过去三年中受到了广泛的关注,它们能够(1)生成更多用于模型优化的标记图像,(2)从未标记的图像数据中学习有意义的隐藏模式,以及(3)为未标记的数据生成伪标签。
已经有很多优秀的评论文章总结了深度学习在医学图像分析中的应用。Litjens等人(2017)和Shen等人(2017)回顾了相对早期的深度学习技术,这些技术主要基于监督方法。最近,Yi等人(2019)和Kazeminia等人(2020)回顾了生成对抗网络在不同医学成像任务中的应用。Cheplygina等人(2019)调查了如何在诊断或分割任务中使用半监督学习和多实例学习。Tajbakhsh等人(2020)研究了各种方法来处理数据集限制(例如,稀缺或弱注释),特别是在医学图像分割中。相比之下,本文的一个主要目标是阐明医学图像分析领域如何从深度学习的一些最新趋势中获益,该领域经常受到有限的注释数据的瓶颈。我们的调查与最近的综述论文有两个特点:全面和技术导向。“全面”体现在三个方面。首先,我们强调了属于“非监督”类别的各种有前途的方法的应用,包括自监督、无监督、半监督学习;同时,我们不会忽视监督方法的持续重要性。其次,我们介绍了上述学习方法在四种经典医学图像分析任务(分类、分割、检测和配准)中的应用,而不是只涉及具体的任务。特别是,我们详细讨论了基于深度学习的目标检测,这在最近的综述论文中很少被提及(2019年以后)。我们着重于胸部x线、乳房x光、CT和MRI图像的应用。所有这些类型的图像都有许多共同的特征,这些特征由同一部门(放射科)的医生解释。我们还提到了一些应用于其他图像领域(如组织病理学)的一般方法,但有可能用于放射学或MRI图像。第三,解释了这些任务的最先进的体系结构/模型。例如,我们总结了如何从自然语言处理中适应医学图像分割的transformer,这是现有的综述论文中尚未提到的。在“技术导向”方面,我们详细回顾了非监督方法的最新进展。特别是,自我监督学习正在迅速成为一个有前途的方向,但尚未在医学视觉的背景下进行系统的审查。广泛的受众可能从这项调查中受益,包括具有深度学习、人工智能和大数据专业知识的研究人员,以及临床医生/医学研究人员。
本调查如下(图1):第2节深入概述了深度学习的最新进展,重点是无监督和半监督方法。此外,还讨论了三种重要的性能增强策略,包括注意机制、领域知识和不确定性估计。第3节总结了深度学习技术在四个主要任务中的主要贡献:分类、分割、检测和配准。第4节讨论了进一步改进模型的挑战,并提出了基于深度学习的医学图像分析模型大规模应用的未来研究方向的可能观点。
2 深度学习方法概述
根据训练数据集的标签是否存在,深度学习可以大致分为监督学习、无监督学习和半监督学习。在监督学习中,所有的训练图像都被标记,并使用图像-标签对来优化模型。对于每个测试图像,优化后的模型将生成一个可能性评分来预测其类别标签(LeCun et al, 2015)。对于无监督学习,模型将分析和学习没有标签的底层模式或隐藏数据结构。如果只有一小部分训练数据被标记,则模型从标记的数据中学习输入输出关系,并通过从未标记的数据中学习语义和细粒度特征来加强模型。这种类型的学习方法被定义为半监督学习(van Engelen and Hoos, 2020)。在本节中,我们首先简要介绍了监督学习,然后主要回顾了无监督学习和半监督学习的最新进展,它们可以在有限的注释数据下方便地执行医学成像任务。本文将相应地介绍这两种学习范式的流行框架。最后,我们总结了三种可以与不同学习范式相结合的策略,包括注意机制、领域知识和不确定性估计,以提高医学图像分析的性能。
2.1 监督式学习
卷积神经网络( C N N CNN CNN)是一种广泛应用于医学图像分析的深度学习架构(Anwar et al.,2018)。 C N N CNN CNN 主要由卷积层和池化层组成。图 2 显示了在医学图像分类任务中的一个简单 C N N CNN CNN。 C N N CNN CNN 直接将图像作为输入,然后通过卷积层、池化层和全连接层进行转换,最后输出基于类别的图像可能性。
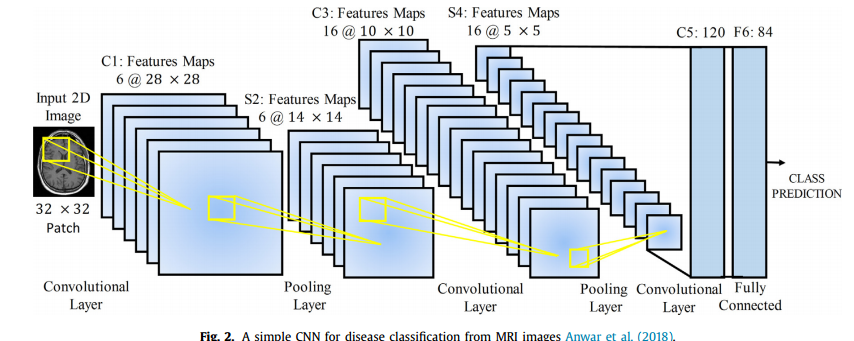
在每个卷积层 l l l 中,使用一堆核 W = W 1 , … , W k W ={W_1,…,W_k} W=W1,…,Wk 从输入图像中提取特征,并添加偏差 b = b 1 , … , b k b ={b_1,…,b_k} b=b1,…,bk,生成新的特征映射 W i l x i l + b i l W^l_i x^l_i + b^l_i Wilxil+bil。然后应用一个非线性变换,一个激活函数 σ ( . ) σ(.) σ(.),得到 x k l + 1 = σ ( W i l x i l + b i l ) x^{l+1}_k = σ (W^l_i x^l_i + b^l_i) xkl+1=σ(Wilxil+bil)作为下一层的输入。在卷积层之后,加入池化层来降低特征映射的维数,从而减少参数的数量。平均池化和最大池化是两种常见的池化操作。对其余层重复上述过程。在网络的末端,通常使用全连接层通过 s i g m o i d sigmoid sigmoid或 s o f t m a x softmax softmax函数生成类的概率分布。预测的概率分布给出了每个输入实例的标签 y ´ y´ y´,因此可以计算损失函数 L ( y ´ , y ) L(y´,y) L(y´,y),其中 y y y 为实际标签。通过最小化损失函数对网络参数进行迭代优化。
2.2 无监督学习
2.2.1 自编码器 (Autoencoders)
自编码器广泛应用于降维和特征学习(Hinton and Salakhutdinov, 2006)。最简单的自编码器,最初被称为 a u t o − a s s o c i a t o r auto-associator auto−associator (Bourlard and Kamp, 1988),是一种只有一个隐藏层的神经网络,它通过最小化输入与其从潜在表示重建之间的重建损失来学习输入数据的潜在特征表示。简单自编码器的浅层结构限制了其表示能力,而具有更多隐藏层的深层自编码器可以提高其表示能力。通过堆叠多个自编码器并以贪婪的分层方式优化它们,深度自编码器或堆叠自编码器( S A E SAE SAE)可以比浅层自编码器学习更复杂的非线性模式,从而更好地概括外部训练数据(Bengio等,2007)。 S A E SAE SAE由一个编码器网络和一个解码器网络组成,它们通常是对称的。为了进一步迫使模型学习具有理想特征的有用潜在表示,可以将稀疏自编码器(Ranzato等人,2007)中的稀疏性约束等正则化项添加到原始重建损失中。其他正则化自编码器包括去噪自编码器(Vincent et al ., 2010)和收缩自编码器(Rifai et al ., 2011),两者都被设计为对输入扰动不敏感。
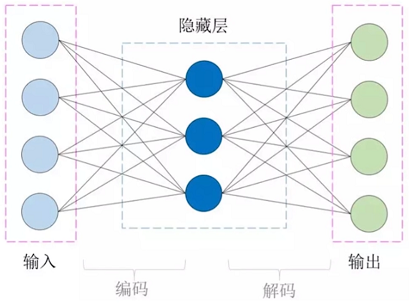
自编码器是一种输入等于输出的模型,全连接神经网络组成最简单的自编码器只有三层结构,中间的隐藏层才是我们需要关注的地方,以隐藏层为界限,左边是编码器,右边是解码器,所以在训练过程中,输入才能在经过编码后再解码还原成原来的模样,原始数据和输出数据的误差称为 重构误差。
假如我们通过一组数据训练出了我们的自编码器,然后我们拆掉了自编码器的解码器,既可以利用剩下的编码器来表征我们的数据了,隐藏层的神经元的数目远低于输入层,那么就相当于我们用更少的特征(神经元)去表征我们的输入数据,从而达到 降维 的功能
- 稀疏自编码器:即普通的自编码器的隐藏层加一个 L 1 L1 L1正则项,也就是一个训练惩罚项,这样我们训练出的编码器表征的特征就更加稀疏,从而能得到很少且有用的特征项
- 降噪编码器:就是输入换成了加噪的数据集,输出用原来的数据集去训练的自编码器,目的是习得降噪功能
与上述经典的 a u t o e n c o d e r s autoencoders autoencoders不同,变分 a u t o e n c o d e r autoencoder autoencoder ( V A E VAE VAE) (Kingma威林,2014)在概率性的工作方式学习观测数据之间的映射空间 x ∈ R m x∈R^m x∈Rm 和潜在的空间 z ∈ R n ( m > > n ) z∈R^n(m>>n) z∈Rn(m>>n)。作为一个潜变量模型, V A E VAE VAE制定这个问题作为观察样品的最大化对数似 l o g p ( x ) = l o g ∫ p ( x ∣ z ) p ( z ) d z log p(x) =log ∫p (x | z) p (z) dz logp(x)=log∫p(x∣z)p(z)dz, p ( x ∣ z ) p (x | z) p(x∣z)可以很容易地使用神经网络建模,和 p ( z ) p (z) p(z)是一个先验分布(如高斯)的潜在空间。然而,积分是难以处理的,因为它不可能对整个潜在空间进行采样。因此,根据贝叶斯规则,后验分布 p ( z ∣ x ) p(z|x) p(z∣x)也变得难以处理。为了解决这个棘手的问题, V A E VAE VAE 的作者提出,除了使用解码器建模 p ( x ∣ z ) p (x | z) p(x∣z) 外,编码器还学习近似未知后验分布的 q ( z ∣ x ) q(z|x) q(z∣x)。最终,对于 l o g p ( x ) log p (x) logp(x)可以导出一个可处理的下界,也称为证据下界(EBLO)。
l o g p ( x ) ≥ E L B O = E q ( z ∣ x ) [ l o g p ( x ∣ z ) ] − K L [ q ( z ∣ x ) ∣ ∣ p ( z ) ] log p(x)≥ELBO = E_{q(z|x)}[log p(x|z)]−KL[q(z|x)||p(z)] logp(x)≥ELBO=Eq(z∣x)[logp(x∣z)]−KL[q(z∣x)∣∣p(z)],其中 K L KL KL代表 K u l l b a c k − L e i b l e r Kullback-Leibler Kullback−Leibler散度。第一项可以理解为重建损失,测量输入图像与从潜在表示重建的对应图像之间的相似性。第二项计算近似后验和高斯先验之间的散度(表1-4)。
后来提出了不同的 V A E VAE VAE 扩展来学习更复杂的表示。尽管概率工作机制允许其解码器生成新数据,但 V A E VAE VAE 无法具体控制数据生成过程。Sohn等人(2015)提出了所谓的条件 V A E VAE VAE ( C V A E CVAE CVAE ),其中编码器和解码器学习的概率分布都是使用外部信息(例如图像类)条件化的。这使得 V A E VAE VAE能够生成结构化的输出表示。另一项研究探索在潜在空间中施加更复杂的先验。例如,Dilokthanakul等人(2016)提出了高斯混合 V A E VAE VAE ( G M V A E GMVAE GMVAE),该方法使用了先前的高斯混合,从而在潜在空间中获得更高的建模容量。我们建议读者参考最近的一篇论文(Kingma和Welling, 2019),以了解 V A E VAE VAE及其扩展的更多细节。
2.2.2 生成对抗网络(GANs)
生成对抗网络(GANs)是一类用于生成建模的深度网络,由Goodfellow等人(2014年)首次提出。对于这个架构,一个估计生成模型的框架被设计成直接从所需的底层数据分布中提取样本,而不需要显式地定义概率分布。它由两个模型组成:生成器 G G G和鉴别器 D D D。生成模型 G G G将从先验分布 P z ( z ) P_z (z) Pz(z)中采样的随机噪声向量 z z z作为输入,通常是高斯分布或均匀分布,然后将 z z z映射到数据空间为 G ( z , θ g ) G(z, θ_g) G(z,θg),其中 G G G是参数为 θ g θ_g θg的神经网络。表示为 G ( z ) G(z) G(z)或 x g x_g xg的假样本与训练数据 P r ( x ) Pr(x) Pr(x)中的真实样本相似,这两种类型的样本被发送到 D D D中。鉴别器是第二个参数化为 θ d θ_d θd的神经网络,它输出一个样本来自训练数据而不是 G G G的概率 D ( x , θ d ) D(x,θ_d) D(x,θd)。训练过程就像玩一个极大极小的双人游戏。对判别网络 D D D进行优化,以最大限度地提高给假样本和真实样本分配正确标签的对数似然,对生成模型 G G G进行训练,以最大限度地提高 D D D犯错的对数似然。通过对抗过程,期望 G G G逐渐估计底层数据分布并生成真实样本。
在此基础上,从两个方面改进了GAN的性能:1)不同的损失(目标)函数和2)条件设置。对于第一个方向,Wasserstein GAN (WGAN)是一个典型的例子。在WGAN中,提出了Earth-Mover (EM)距离或通常称为Wasserstein距离的Wasserstein-1来取代原始Vanilla GAN中的Jensen-Shannon (JS)散度,并测量真实数据分布与合成数据分布之间的距离(Arjovsky et al, 2017)。WGAN的批评者的优点是在JS发散饱和并导致梯度消失的地方提供有用的梯度信息。WGAN还可以提高学习的稳定性,缓解模式崩溃等问题
无条件生成模型不能显式地控制被合成数据的模式。为了指导数据生成过程,条件GAN (cGAN)是通过使用附加信息(即类标签)调节其生成器和鉴别器来构建的(Mirza和Osindero, 2014)。具体而言,将噪声向量z和类标号c共同提供给G;真实/虚假数据和类标签c一起作为d的输入,条件信息也可以是图像或其他属性,不局限于类标签。此外,辅助分类器GAN (ACGAN)提出了另一种策略,使用标签条件反射来改善图像合成(Odena等,2017)。与cGAN的鉴别器不同,ACGAN中的D不再提供类条件信息。除了分离真假图像,D还负责重建类标签。当强制D执行额外的分类任务时,ACGAN可以轻松生成高质量的图像。
2.2.3 自监督学习
在过去的几年中,无监督表示学习在自然语言处理(NLP)中取得了巨大的成功,其中大量未标记的数据可用于预训练模型(例如bert, Kenton和Toutanova, 2019)并学习有用的特征表示。然后在下游任务(如问答、自然语言推理和文本摘要)中对特征表示进行微调。在计算机视觉中,研究人员已经探索了一个类似的管道——首先训练模型以无监督的方式从原始未标记的图像数据中学习丰富而有意义的特征表示,然后在标记数据的各种下游任务中对特征表示进行微调,如分类、目标检测、实例分割等。然而,在相当长的一段时间里,这种做法并不像NLP那样成功,相反,监督预训练一直是主要的策略。有趣的是,我们发现近两年这种情况正朝着相反的方向发生变化,越来越多的研究表明,自监督预训练的效果要高于监督预训练。
在最近的文献中,术语“自我监督学习”与“无监督学习”交替使用;更准确地说,自监督学习实际上是指一种深度无监督学习的形式,输入和标签是在没有外部监督的情况下从未标记的数据本身创建的。这项技术背后的一个重要动机是避免监督任务,这些任务通常是昂贵和耗时的,因为需要建立新的标记数据集或在某些领域(如医学)获得高质量的注释。尽管标记数据稀缺且成本高,但在许多领域通常存在大量廉价的未标记数据未被利用。未标记的数据可能包含有价值的信息,这些信息要么很弱,要么没有出现在标记的数据中。自监督学习可以利用未标记数据的力量来提高监督任务的性能和效率。由于自监督学习比监督学习涉及更广泛的数据,以自我监督的方式学习的特征可以在现实世界中更好地泛化。自我监督可以通过两种方式进行:基于预训练任务的方法和基于对比学习的方法。由于基于对比学习的方法近年来受到了广泛的关注,我们将重点关注这一方向的更多工作。
预训练任务是为了学习下游任务的代表性特征而设计的,但预训练本身并不是真正感兴趣的(He et al, 2020)。预训练任务通过隐藏每个输入图像的特定信息(例如,通道,补丁等)来学习表征,然后从图像的剩余部分预测缺失信息。例子包括图像绘制(Pathak等人,2016)、着色(Zhang等人,2016)、相对补丁预测(Doersch等人,2015)、拼图(Noroozi和Favaro, 2016)、旋转(Gidaris等人,2018)等。然而,学习表征的可泛化性在很大程度上依赖于手工制作的预训练任务的质量(Chen et al, 2020a)。
对比学习依赖于所谓的对比损失,这至少可以追溯到(Hadsell et al ., 2006;Chopra et al ., 2005)。后来使用了这种对比损失的许多变体(Oord等人,2018;Chen et al ., 2020a;Chaitanya et al ., 2020)。从本质上讲,原始损失及其后续版本都强制执行一个相似度度量,对于正(相似)对最大化,对于负(不相似)对最小化,以便模型可以学习判别特征。下面我们将介绍对比学习的两个代表性框架,即动量对比(MoCo) (He et al ., 2020)和SimCLR (Chen et al ., 2020a)。
MoCo将对比学习描述为字典查找问题,该问题要求编码查询与其匹配键相似。如图3(a)所示,给定图像x,编码器对图像进行编码,产生特征向量,该特征向量用作查询(q)。同样地,使用另一个编码器,字典可以通过特征{k0, k1, k2,…}(也称为键)从大量图像样本{x0, x1, x2,…}中构建。在MoCo中,如果编码查询q和键来自同一图像的不同作物,则认为它们相似。假设存在一个与q匹配的字典键(k+),则将这两个项视为正对,而将字典中的其他键视为负对。作者使用InfoNCE (Oord et al, 2018)计算正对的损失函数如下:
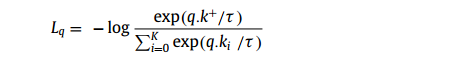
从所有图像的采样子集中建立,大型字典对于良好的准确性非常重要。为了使字典更大,作者将以前图像批次的特征表示维护为一个队列:新键加入队列,旧键退出队列。因此,字典由来自当前批次和以前批次的编码表示组成。然而,这可能导致密钥编码器快速更新,使字典键不一致,也就是说,它们与编码查询的比较不一致。因此,作者建议在密钥编码器上使用动量更新来避免快速变化。这个键编码器被称为动量编码器。
SimCLR是另一个流行的对比学习框架。在这个框架中,如果两个增强图像来自同一个例子,则认为它们是正对;如果不是,它们就是负的一对。使正图像对特征表示的一致性最大化。如图3(b)所示,SimCLR由四个部分组成:(1)随机图像增强;(2)编码器网络(f(.))从增强图像中提取特征表示;(3)将特征表示映射到低维空间的小型神经网络(多层感知器(MLP)投影头)(g (.));(4)对比损失计算。第三个组件使SimCLR不同于它的前辈。以前的框架,如MoCo,直接计算特征表示,而不是首先将它们映射到低维空间。正如MoCo v2 (Chen et al ., 2020b)所证明的那样,该组件在获得令人满意的结果方面进一步证明了其重要性。
值得注意的是,由于自监督对比学习是非常新的,在撰写本文时,诸如MoCo和SimCLR等最新进展在医学图像分析领域的广泛应用尚未建立。尽管如此,考虑到现有文献中报道的自我监督学习的有希望的结果,我们预计应用这种新技术分析医学图像的研究可能很快就会爆发。此外,自监督预训练具有成为监督预训练的强大替代方案的巨大潜力。
2.3. 半监督学习
与只能在未标记数据上工作以学习有意义的表示的无监督学习不同,半监督学习(SSL)在模型训练期间结合了标记和未标记的数据。特别是,SSL适用于有限的标记数据和大规模但未标记数据可用的场景。这两种类型的数据应该是相关的,这样,未标记数据所携带的附加信息就可以用来补偿标记数据。我们有理由期望未标记的数据会带来平均的性能提升——对于只使用有限的标记数据执行任务来说,可能越多越好。事实上,这个目标已经被探索了几十年,20世纪90年代已经见证了在文本分类中应用SSL方法的兴起。半监督学习书籍(Chapelle et al, 2009)是读者掌握SSL与经典机器学习算法之间联系的良好来源。有趣的是,尽管其潜在的积极价值,作者提出的实证发现,未标记的数据有时会恶化的性能。然而,这一实证发现似乎在最近的深度学习文献中发生了变化——越来越多的作品(主要来自计算机视觉领域)报道,深度半监督方法通常比高质量的监督基线表现得更好(Ouali et al, 2020)。即使改变标记和未标记数据的数量,仍然可以观察到一致的性能改进。同时,深度半监督学习已成功应用于医学图像分析领域,降低了标注成本,取得了更好的性能。我们将流行的SSL方法分为三类:(1)基于一致性正则化的方法;(2)基于伪标注的方法;(3)基于生成模型的方法。
第一类方法都有一个相同的想法,即如果应用了一些扰动(例如,添加噪声,数据增强),则对未标记示例的预测不应该发生显着变化。SSL模型的损失函数一般由两部分组成。更具体地说,给定一个未标记的数据示例x及其扰动版本x³,SSL模型输出logits fθ (x)和fθ (x³)。在未标记的数据上,目标是通过最小化均方误差d(fθ (x), fθ (x))来给出一致的预测,这导致了未标记数据上的一致性(无监督)损失Lu。在标记的数据上,计算交叉熵监督损失Ls。通过一致性约束进行正则化的SSL模型示例包括Ladder Networks (Rasmus et al ., 2015)、ρModel (Laine and Aila, 2017)和Temporal Ensembling (Laine and Aila, 2017)。最近的一个例子是平均教师范式(Tarvainen和Valpola, 2017),由教师模型和学生模型组成(图4)。学生模型通过最小化未标记数据上的Lu和最小化标记数据上的Ls来优化;教师模型作为学生模型的指数移动平均线(EMA),用于指导学生模型进行一致性训练。最近,诸如无监督数据增强(UDA) (Xie等人,2020)和MixMatch (Berthelot等人,2019)等几项工作将SSL的性能提升到了一个新的水平。
对于伪标记(Lee, 2013), SSL模型本身为未标记的示例生成伪注释;伪标记样例与标记样例联合使用来训练SSL模型。该过程经过多次迭代,伪标签的质量和模型的性能都得到了提高。naïve伪标记过程可以与Mixup增强相结合(Zhang等人,2018a),以进一步提高SSL模型的性能(Arazo等人,2020)。伪标注也可以很好地用于多视图协同训练(Qiao et al ., 2018)。对于每个视图的标记样例,共同训练学习一个单独的分类器,然后使用该分类器为未标记的数据生成伪标签;协同训练最大化了在未标记示例的每个视图之间分配伪注释的一致性。
对于第三类方法,gan和VAEs等半监督生成模型更侧重于解决目标任务(例如分类),而不仅仅是生成高保真样本。这里我们简要地说明了半监督GAN的机制。使GAN适应半监督设置的一个简单方法是修改鉴别器来执行额外的任务。例如,在图像分类任务中,Salimans et al(2016)和Odena(2016)通过强迫DCGAN充当分类器来改变DCGAN的判别器。对于未标记的图像,鉴别器的功能与普通GAN一样,提供输入图像为实的概率;对于已标记的图像,鉴别器除了生成真实概率外,还预测其类别。然而,Li等人(2017)证明,单个鉴别器可能无法同时实现这两个任务的最佳性能。因此,他们引入了一个独立于生成器和鉴别器的附加分类器。这种由三个组件组成的新架构被称为三重gan
2.4 提高性能的策略
2.4.1 注意力机制
注意力源于灵长类动物的视觉处理机制,它选择相关感官信息的子集,而不是使用所有可用的信息进行复杂的场景分析(Itti et al, 1998)。受这种专注于输入的特定部分的想法的启发,深度学习研究人员将注意力整合到开发不同领域的先进模型中。基于注意力的模型在与自然语言处理(NLP)相关的领域取得了巨大的成功,例如机器翻译(Bahdanau等人,2015;Vaswani et al, 2017)和图像字幕(Xu et al, 2015;You et al, 2016;Anderson et al, 2018)。一个突出的例子是Transformer架构,它完全依赖于自关注来捕获输入和输出之间的全局依赖关系,而不需要顺序计算(Vaswani et al, 2017)。注意机制在计算机视觉任务中也很流行,例如自然图像分类(Wang et al ., 2017;Woo等人,2018;Jetley et al ., 2018), segmentation (Chen et al ., 2016;Ren and Zemel, 2017)等。在处理图像时,注意力模块可以自适应地学习“参加什么”和“在哪里”,以便模型预测以最相关的图像区域和特征为条件。根据图像中被关注位置的选择,注意机制大致可以分为软注意和硬注意两类。前者确定性地学习所有位置的特征加权平均,而后者随机抽取特征位置的一个子集来参加(Cho et al, 2015)。由于硬注意不可微,软注意尽管在计算上更昂贵,却得到了更多的研究努力。根据这一可微分机制,不同类型的注意得到了进一步发展,如(1)空间注意(Jaderberg等人,2015),(2)通道注意(Hu等人,2018a),(3)空间和通道注意的结合(Wang等人,2017;Woo等人,2018)和(4)自我关注(Wang等人,2018)。读者可以参考Chaudhari等人(2021)的优秀评论,了解注意力机制的更多细节。
2.4.2 领域知识
大多数成熟的深度学习模型最初设计用于分析自然图像,当直接应用于医学图像任务时,可能只产生次优结果(Zhang等人,2020a)。这是因为自然图像和医学图像在本质上是非常不同的。首先,医学图像通常表现出高度的类间相似性,因此一个主要挑战在于提取细粒度的视觉特征,以了解对做出正确预测很重要的细微差异。其次,典型的医学图像数据集比包含数万到数百万图像的基准自然数据集要小得多。这阻碍了计算机视觉中高度复杂的模型在医学领域的直接应用。因此,如何定制医学图像分析模型仍然是一个重要的问题。一种可能的解决方案是集成适当的领域知识或特定于任务的属性,这已被证明有利于促进学习有用的特征表示并降低医学成像环境中的模型复杂性。在这篇综述文章中,我们将提到各种领域知识,例如MRI和CT图像中的解剖信息(Zhou et al ., 2021, 2019a),体积图像中的三维空间上下文信息(Zhang et al ., 2017;庄等,2019;Zhu等人,2020a)、同一患者的多实例数据(Azizi等人,2021)、患者元数据(Vu等人,2021)、放射学特征(Shorfuzzaman和Hossain, 2021)、随附图像的文本报告(Zhang等人,2020a)等。对如何将医学领域知识整合到网络设计中有兴趣的读者可以参考Xie等人(2021a)的工作。
2.4.3 估计的不确定性
当涉及到具有高安全性要求的临床环境(例如癌症诊断)时,可靠性是关键问题。模型预测容易受到数据噪声和推理误差等因素的影响,因此需要量化不确定性并使结果可信(Abdar et al, 2021)。不确定性估计常用的技术包括贝叶斯近似(Gal和Ghahramani, 2016)和模型集合(Lakshminarayanan等人,2017)。Monte Carlo dropout (MC-dropout)等贝叶斯方法(Gal和Ghahramani, 2016)围绕着近似神经网络参数的后验分布。集成技术结合多个模型来测量不确定性。对不确定性估计感兴趣的读者可以参考Abdar等人(2021)的综合综述。
3 深度学习应用
3.1 分类
医学图像分类是计算机辅助诊断(CADx)的目标,其目的是区分良性病变和恶性病变,或者从输入图像中识别某些疾病(Shen et al ., 2017;van Ginneken et al, 2011)。基于深度学习的CADx方案在过去十年中取得了巨大的成功。然而,深度神经网络通常依赖于足够的注释图像来保证良好的性能,这一要求可能不容易被许多医学图像数据集满足。为了缓解缺乏大型注释数据集的问题,已经使用了许多技术,而 迁移学习 无疑是最主要的范例。除了迁移学习之外,其他几种学习范式,包括无监督图像合成、自监督和半监督学习,在有限的注释数据下显示出了巨大的性能增强潜力。我们将在下面的小节中介绍这些学习范式在医学图像分类中的应用。
3.1.1 监督分类
从AlexNet (Krizhevsky等人,2012)开始,各种具有越来越深的网络和更大的表示容量的端到端模型被开发出来用于图像分类,例如VGG (Simonyan和Zisserman, 2015), GoogleLeNet (Szegedy等人,2015),ResNet (He等人,2016)和DenseNet (Huang等人,2017)。这些模型取得了优异的结果,使深度学习不仅在开发高性能CADx方案方面成为主流,而且在医学图像处理的其他子领域也成为主流。
然而,深度学习模型的性能在很大程度上取决于训练数据集的大小和图像注释的质量。在许多医学图像分析任务中,特别是在3D场景中,由于数据采集和注释困难,建立足够大且高质量的训练数据集可能具有挑战性(Tajbakhsh等人,2016;Chen et al ., 2019a)。监督迁移学习技术(Tajbakhsh et al ., 2016;Donahue et al ., 2014)通常用于解决训练数据不足的问题并提高模型的性能,其中ResNet (He et al ., 2016)等标准架构首先在源域中使用大量自然图像(例如ImageNet (Deng et al ., 2009))或医学图像进行预训练,然后将预训练的模型转移到目标域并使用更少的训练样本进行微调。Tajbakhsh等人(2016)表明,经过充分微调的预训练cnn的表现至少与从头训练的cnn一样好。事实上,迁移学习已经成为各种模式下图像分类任务的基石(de Bruijne, 2016),包括CT (Shin等人,2016)、MRI (Yuan等人,2019)、乳房x光检查(Huynh等人,2016)、x射线检查(Minaee等人,2020)等。
什么是迁移学习?
- 利用数据,任务,模型间的相似性,将训练好的内容应用到新的任务上被称为迁移学习
- 由于这一过程发生在两个领域间,已有的知识和数据,也就是被迁移的对象被称为源域,被赋予“经验”的领域被称为目标域。
迁移学习不是具体的模型,更像是解题思路,我们使用迁移学习的原因有很多:
- 比如目标领域的数据太少,需要标注数据更多的源域的帮助
- 有时是为了节约训练时间,有时是为了实现个性化应用
在监督分类范式中,不同类型的注意力模块被用于提高性能和更好的模型可解释性(Zhou et al ., 2019b)。Guan等人(2018)介绍了一种基于ResNet-50的注意力引导CNN (He et al, 2016)。使用来自全局x射线图像的注意力热图来抑制大的不相关区域,并突出显示包含胸腔疾病判别线索的局部区域。该模型有效地融合了全局和局部信息,取得了良好的分类性能。在另一项研究中,Schlemper等人(2019)将注意力模块分别纳入VGG (Baumgartner等人,2017)和U-Net (Ronneberger等人,2015)的变体网络中,用于2D胎儿超声图像平面分类和3D CT胰腺分割。每个注意力模块被训练关注输入图像中的局部结构子集,这些局部结构包含对目标任务有用的显著特征。
3.1.2 无监督的方法
无监督图像合成:经典的数据增强(例如,旋转,缩放,翻转,平移等)简单但有效地创建更多的训练实例以获得更好的性能(Krizhevsky et al, 2012)。然而,它不能给现有的训练样例带来很多新的信息。鉴于gan具有学习隐藏数据分布和生成真实图像的优势,gan已被用作医学领域中更复杂的数据增强方法。
什么是 GAN(生成对抗网络)?
- GAN,即生成对抗网络,其包含三个部分,生成、判别和对抗
- 生成器负责依据随机向量产生内容(文本、图片、音频等),取决于你想要生成什么
- 判别器负责判断接收到的内容是否是真实的,通常会给出一个概率,代表内容的真实程度
- 对抗指的是GAN的交替训练过程 。以图片为例,生成器生成的假图片与原来的真图片一起交给判别器,让它学习区分二者,给真的高分,给假的低分。当判别器可以熟练判断现有图片后,再让生成器以从判别器获得的高分图片为目标,不断生成更“好”的假图片,直到能骗过判别器,重复这一过程,直到判别器对任何图片的预测概率都接近0.5,也就是无法分辨图片的真假,就停止训练
- GAN的目的,生成足够以假乱真的内容
Frid-Adar等人(2018b)利用DCGAN合成高质量的样本,在有限的数据集上改进肝脏病变分类。该数据集仅包含182个肝脏病变,包括囊肿、转移和血管瘤。由于训练GAN通常需要大量的示例,因此作者应用经典的数据增强(例如,旋转,翻转,平移,缩放)来创建近90,000个示例。基于gan的合成数据增强显著提高了分类性能,灵敏度和特异性分别从78.6%和88.4%提高到85.7%和92.4%。在他们后来的工作中(Frid-Adar等人,2018a),作者进一步将病变合成从无条件设置(DCGAN)扩展到 条件设置(ACGAN)。ACGAN的生成器以侧信息(病变分类)为条件,鉴别器在合成新样本的同时预测病变分类。然而,我们发现基于acgan的合成增强的分类性能比无条件增强的分类性能弱。
为了缓解数据稀缺,特别是缺乏阳性癌症病例,Wu等(2018a)采用条件结构(cGAN)生成真实病变,用于乳房x线照片分类。传统的数据增强方法也用于生成足够的样本来训练GAN。该发生器具有恶性/非恶性标记,可以控制产生特定类型病变的过程。对于每个非恶性斑块图像,使用另一个恶性病变的分割掩码在其上合成一个恶性病变;对于每个恶性图像,去除其病灶,合成一个非恶性斑块。尽管基于gan的增强方法取得了比传统数据增强方法更好的分类性能,但改进幅度相对较小,不足1%。
基于自监督学习的分类:最近的自监督学习方法在缺乏足够注释的医疗任务中显示出巨大的潜力(Bai等人,2019;陶等,2020;Li et al ., 2020a;Shorfuzzaman and Hossain, 2021;Zhang et al ., 2020a)。该方法适用于大量医学图像可用,但只有一小部分图像被标记的情况。相应地,模型优化分为两个步骤,即自监督预训练和监督微调。该模型最初使用未标记的图像进行优化,以有效地学习代表图像语义的良好特征(Azizi et al, 2021)。自我监督的预训练模型之后进行监督微调,以在后续分类任务中获得更快更好的性能(Chen et al ., 2020c)。在实践中,自我监督可以通过预训练任务(Misra and Maaten, 2020)或对比学习(Jing and Tian, 2020)来创建,具体如下。
自监督学习
- 自监督学习是一种无需人工标注的训练方法,通过利用数据内在的结构和信息来生成监督信号,从而学习有用的表示或模型。
- 自监督学习的核心思想是根据数据内在的结构和特征进行训练。它利用输入数据中的某种隐含结构或信息进行“伪标签”的生成,然后使用这些“伪标签”来训练模型。
- 例如,在图像处理领域,可以将图像旋转一定角度作为自监督任务,然后让模型预测图像的旋转角度。在这个过程中,模型自主地学习到了图像的空间关系和特征提取能力,而无需人工标注的标签。
基于自我监督的预训练任务分类利用常见的预训练任务,如旋转预测(Tajbakhsh等人,2019)和魔方恢复(Zhuang等人,2019;Zhu et al ., 2020a)。Chen等人(2019b)认为,现有的预训练任务,如相对位置预测(Doersch等人,2015)和局部上下文预测(Pathak等人,2016)只导致医学图像数据集的边际改进;作者设计了一种基于语境还原的预训练任务。这种新的伪装任务分为两个步骤:对损坏图像进行无序修补和恢复原始图像。上下文恢复预训练策略提高了医学图像分类的性能。Tajbakhsh等人(2019)利用三个预训练任务,即旋转(Gidaris等人,2018)、着色(Larsson等人,2017)和基于wgan的补丁重建,对分类任务的模型进行预训练。预训练后,使用标记样例训练模型。在医学领域,基于预训练任务的预训练比随机初始化和迁移学习(ImageNet预训练)对糖尿病视网膜病变分类更有效。
对于自监督对比分类,Azizi et al .(2021)采用自监督学习框架SimCLR (Chen et al ., 2020a)训练模型(ResNet50和ResNet-152的更宽版本)用于皮肤病分类和胸部x射线分类。他们首先使用未标记的自然图像,然后使用未标记的皮肤科图像和胸部x光片对模型进行预训练。特征表征是通过最大化正图像对之间的一致性来学习的,正图像对要么是同一图像的两个增强示例,要么是来自同一患者的多个图像。预先训练的模型使用更少的标记皮肤病学图像和胸部x光片进行微调。这些模型在胸部x线分类的平均AUC上比使用ImageNet预训练的模型高出1.1%,在皮肤病分类的前1名准确率上高出6.7%。MoCo (He et al ., 2020;Chen等人,2020b)是另一个流行的自监督学习框架,用于医学分类任务的预训练模型,例如从CT图像中诊断COVID-19 (Chen等人,2021a)和胸部x射线中的胸腔积液识别(sowrrajan等人,2021)。此外,研究表明,自监督对比预训练可以从领域知识的融合中获益。例如,Vu等人(2021)利用患者元数据(患者编号、图像横向性和研究编号)从多张胸部x线图像中构建并选择阳性对进行MoCo预训练。与之前的对比学习方法(sowrrajan et al ., 2021)和ImageNet预训练相比,该方法仅使用1%的标记数据进行胸腔积液分类,平均AUC分别提高了3.4%和14.4%。
3.1.3 半监督学习
与仅从未标记数据中学习有用特征表示的自监督方法不同,半监督学习需要通过不同的方式将未标记数据与标记数据集成,以训练模型以获得更好的性能。Madani等人(2018a)采用半监督方式训练的GAN (Kingma等人,2014)在标记数据有限的胸部x射线中进行心脏病分类。与普通GAN不同(Goodfellow等人,2014),这种半监督GAN使用未标记和标记数据进行训练。对其鉴别器进行了改进,不仅可以预测输入图像的真实性,还可以预测真实数据的图像类别(正常/异常)。当增加标记示例的数量时,基于半监督GAN的分类器始终优于监督CNN。半监督GAN在其他数据有限的分类任务中也很有用,例如CT肺结节分类(Xie等,20119a)和超声心动图左心室肥厚分类(Madani等,2018b)。除了半监督对抗方法,基于一致性的半监督方法,如ρ -Model (Laine和Aila, 2017)和Mean Teacher (Tarvainen和Valpola, 2017)也被用于利用未标记的医学图像数据进行更好的分类(Shang等人,2019;Liu et al ., 2020a)。
3.2 分割
医学图像分割,即从背景区域中识别病变、器官和其他子结构的像素或体素集,是医学图像分析中的另一项具有挑战性的任务(Litjens et al ., 2017)。在分类和检测等所有常见的图像分析任务中,分割需要最强的监督(大量高质量的注释)(Tajbakhsh et al ., 2020)。自2015年推出以来,UNet (Ronneberger等人,2015)可能已成为分割医学图像最知名的架构;随后,提出了不同的U-Net变体,以进一步提高分割性能。从最近的文献中,我们观察到U-Net和视觉转换器的结合(Dosovitskiy等人,2020)对最先进的性能做出了贡献。此外,许多基于半监督和自监督学习的方法也被提出,以减轻对大型注释数据集的需求。因此,在本节中,我们将(1)回顾原始的U-Net及其重要的变体,并总结有用的性能增强策略;(2)介绍U-Net与transformer的结合,以及Mask RCNN (He et al ., 2017);3)涵盖自监督和半监督的分割方法。由于最近的研究主要集中在以监督的方式应用transformer对医学图像进行分割,因此我们有意将基于transformer的架构的介绍置于监督分割部分。然而,应该注意的是,这种分类并不意味着基于transformer的架构不能用于半监督或无监督设置,或其他医学成像任务。
3.2.1 基于监督学习的分割模型
U-Net及其变体:在卷积网络中,由更高层学习的高级粗粒度特征捕获有利于整个图像分类的语义;相比之下,低层学习的底层细粒度特征包含了精确定位的有用细节(即为每个像素分配一个类标签)(Hariharan et al, 2015),这对图像分割很重要。U-Net是建立在全卷积网络上的(Long et al, 2015), U-Net的关键创新是在对立的卷积层和反卷积层之间建立了所谓的跳过连接,它成功地将不同层次学习到的特征连接在一起,提高了分割性能。同时,跳跃式连接也有助于将网络的输出恢复到与输入相同的空间分辨率。U-Net以二维图像作为输入,生成多个分割图,每个分割图对应一个像素类。
在基本架构的基础上,Drozdzal等(2016)进一步研究了长短跳跃连接对生物医学图像分割的影响。他们的结论是,添加短跳连接对于训练深度分割网络很重要。在一项研究中,Zhou等人(2018)声称U-Net的编码器和解码器子网之间的纯跳过连接导致语义上不同的特征映射的融合;他们提出在融合特征图之前先减少语义差距。在提出的unet++模型中,简单的跳跃连接被嵌套的密集的跳跃连接所取代。该架构在四种不同的医学图像分割任务中表现优于U-Net和wide U-Net。
除了重新设计跳跃连接外,Çiçek等人(2016)用3D操作替换了所有2D操作,将2D U-Net扩展到3D U-Net,用于稀疏注释图像的体积分割。此外,miletari等人(2016)提出了V-Net用于3D MRI前列腺体积分割。U-Net和V-Net在架构上的主要区别在于前向卷积单元(图5(A))变为残差卷积单元(图5©),因此V-Net也被称为残差U-Net。针对前景和背景体素数量不平衡的问题,提出了一种基于Dice系数的损失函数。为了解决带注释卷的稀缺性,作者使用随机非线性转换和直方图匹配增强了他们的训练数据集。Gibson等(2018a)提出了Dense V-network,改进了V-Net二值分割的损失函数,支持腹部CT图像的多器官分割。虽然作者遵循了V-Net架构,但他们用三个密集特征堆栈的序列取代了其相对较浅的下采样网络。紧密连接层和浅V-Net结构的结合证明了其在提高分割精度方面的重要性,与多图谱标签融合(MALF)方法相比,所提出的模型对所有器官的Dice得分都有显著提高。
Alom等人(2018)在设计基于U-Net的分割网络时,提出将循环卷积神经网络(RCNN) (Ming and Xiaolin, 2015)和ResNet (He et al, 2016)的架构优势整合起来。在他们的第一个网络(RU-Net)中,作者使用RCNN的循环卷积层(RCL)取代了U-Net的前向卷积单元(图5(b)),这有助于积累有用的特征以改善分割结果。在他们的第二个网络(R2U-Net)中,作者使用ResNet的残差单元进一步修改了RCL(图5(d)),它通过使用快捷连接的身份映射来学习残差函数,从而允许训练非常深度的网络。两种模型都获得了比U-Net和剩余U-Net更好的分割性能。密集卷积块(Huang et al ., 2017)也证明了其在增强肝脏和肿瘤CT体积分割性能方面的优势(Li et al ., 2018)。
除了重新设计的跳过连接和修改的架构外,基于U-Net的分割方法还受益于对抗性训练(Xue et al ., 2018;Zhang et al ., 2020b),注意机制(Jetley et al ., 2018;Anderson et al, 2018;Oktay等人,2018;Nie et al, 2018;Sinha and Dolz, 2021)和不确定性估计(Wang et al ., 2019a;Yu et al ., 2019;Baumgartner et al, 2019;Mehrtash et al, 2020)。例如,Xue等人(2018)开发了一种用于脑肿瘤分割的对抗网络,该网络由两部分组成:分割器和批评家。分割器是一个类似u - net的网络,它在给定输入图像的情况下生成分割映射;预测图和ground-truth分割图被发送到批评家网络中。交替训练这两个分量最终会得到良好的分割结果。Oktay等人(2018)提出将注意门(AGs)纳入U-Net架构,以抑制背景区域的不相关特征,并突出通过跳过连接传播的重要显著特征。注意:在CT胰腺分割中,U-Net的表现始终优于U-Net。Baumgartner等人(2019)开发了一种分层概率模型来估计前列腺MR和胸部CT图像分割中的不确定性。作者采用变分自编码器来推断专家注释中的不确定性或模糊性,并使用单独的潜在变量来模拟不同分辨率下的分割变化。
用于分割的变压器:变压器是一组编码器-解码器网络架构,用于NLP中序列到序列的处理(Chaudhari等人,2021)。一个关键的子模块被称为多头自注意(MSA),其中多个并行的自注意层被用来同时为每个输入生成多个注意向量。与基于卷积的U-Net及其变体不同,变形金刚依赖于自注意机制,该机制具有从输入图像中学习复杂、长期依赖关系的优势。在医学图像分割的背景下,有两种适应变形金刚的方法:混合和纯变形金刚。混合方法结合了cnn和transformer,而后者不涉及任何卷积操作
Chen等人(2021b)提出了TransUNet,这是第一个基于transformer的医学图像分割框架。这种架构以级联的方式结合了CNN和Transformer,其中一个的优点用来弥补另一个的局限性。如前所述,基于卷积运算的U-Net及其变体已经取得了令人满意的结果。由于跳跃式连接,来自编码器的包含精确定位信息的低级别/高分辨率CNN特征被解码器利用,从而实现更好的性能。然而,由于卷积的固有局部性,这些模型在建模远程关系时通常很弱。另一方面,尽管基于自关注机制的Transformer可以很容易地捕获远程依赖关系,但作者发现单独使用Transformer不能提供满意的结果。这是因为它只专注于学习全局上下文,而忽略了学习包含重要定位信息的低级细节。因此,作者建议将来自CNN特征的低层空间信息与来自Transformer的全局背景相结合。如图6(b)所示,TransUNet采用跳线连接的编码器/解码器设计。编码器由一个CNN层和几个Transformer层组成。首先需要将输入图像分割成小块并进行标记。然后利用CNN对输入patch生成特征映射。不同分辨率的CNN特征通过跳过连接传递给解码器,从而保留了空间定位信息。然后,对特征映射序列进行补丁嵌入和位置嵌入。嵌入的序列被发送到一系列Transformer层中以学习全局关系。每个Transformer层由一个MSA块组成(Dosovitskiy等,2020b;Vaswani等人,2017)和多层感知器(MLP)块(图6(a))。最后一个Transformer层产生的隐藏特征表示被重构并逐渐被解码器上采样,从而输出最终的分割掩码。TransUNet在CT多器官分割任务中表现出优于其他竞争方法(如注意力U-Net)的性能
在另一项研究中,Zhang等(2021)采用了不同的方法将CNN和Transformer结合起来。TransFuse模型不是首先使用CNN提取底层特征,然后通过Transformer层传递特征,而是以并行的方式将CNN和Transformer两个分支结合在一起。Transformer分支由几个层组成,将嵌入的图像补丁序列作为输入,以捕获全局上下文信息。最后一层的输出被重塑成二维特征图。为了恢复更精细的局部细节,这些地图在三种不同的比例尺上采样到更高的分辨率。相应地,CNN分支使用三个基于resnet的块在三个不同的尺度上从局部到全局提取特征。两个分支具有相同分辨率尺度的特征通过一个独立的模块进行选择性融合。融合的特征可以同时捕获低层次的空间背景和高层次的全局背景。最后,利用多层融合特征生成最终的分割掩码。TransFuse在前列腺MRI分割中取得了较好的效果
除了2D图像分割,混合方法也适用于3D场景。Hatamizadeh等人(2022)提出了一种基于unet的架构,对MRI脑肿瘤和CT脾脏进行体积分割。与2D案例类似,3D图像首先被分成若干块。然后对输入图像体序列进行线性嵌入和位置嵌入,然后送入编码器。编码器由多个Transformer层组成,从嵌入序列中提取多尺度全局特征表示。在不同尺度上提取的特征都被上采样到更高的分辨率,然后通过跳过连接与解码器的多尺度特征合并。在另一项研究中,Xie等(2021b)研究了在3D多器官分割任务中如何降低transformer的计算复杂度和空间复杂度。为了实现这一目标,他们用可变形的自关注模块替换了普通Transformer中的原始MSA模块(Zhu et al, 2021a)。这个注意力模块只关注一小部分关键位置,而不是平等地对待所有位置,从而大大降低了复杂性。此外,他们提出的架构CoTr与TransUNet的精神相同——CNN生成特征图,用作变形金刚的输入。不同之处在于,CoTr中的CNN提取的不是单尺度的特征,而是多尺度的特征图。
对于仅Transformer范例,Cao等人(2021)提出了swan - unet,这是第一个用于医学图像分割的类似unet的纯Transformer架构。swan - unet有一个对称的编解码器结构,不使用任何卷积操作。编码器和解码器的主要组成部分是(1)Swin Transformer模块(Liu et al ., 2021)和(2)修补合并或扩展层。Swin Transformer模块采用了移位的窗口方案,在计算自关注方面具有较好的建模能力和较低的复杂度。因此,作者使用它来提取图像补丁嵌入的输入序列的特征表示。随后的补丁层向下采样特征表示/映射到较低的分辨率。这些下采样的地图进一步通过其他几个Transformer块并修补合并层。同样,解码器也使用Transformer块进行特征提取,但它的补丁扩展层将采样特征映射扩展到更高的分辨率。与U-Net类似,通过跳过连接将上采样特征映射与来自编码器的下采样特征映射融合。最后,解码器输出像素级分割预测。该框架在多器官CT和心脏MRI分割任务中取得了满意的效果。
请注意,为了确保良好的性能并减少训练时间,到目前为止引入的大多数基于transformer的分割模型都是在大型外部数据集(例如ImageNet)上进行预训练的。有趣的是,研究表明,变形金刚也可以通过利用计算效率高的自关注模块(Wang et al ., 2020a)和新的训练策略来整合高级信息和更精细的细节(Valanarasu et al ., 2021),在没有预训练的情况下产生良好的结果。此外,Hatamizadeh等人(2022)和Xie等人(2021b)在将基于transformer的模型应用于3D医学图像分割时发现,预训练并没有显示出性能的提高。
Mask r-cnn用于分割:除了上述基于UNet和transformer的方法外,另一种架构Mask RCNN (He et al, 2017)最初是为像素级实例分割而开发的,在医疗任务中取得了很好的效果。由于它与Faster RCNN (Ren et al ., 2015, 2017)密切相关,后者是一种基于区域的用于目标检测的CNN,因此Mask RCNN的细节及其与检测架构的关系将在后面详细阐述。简而言之,Mask RCNN具有(1)与Faster RCNN一样的区域建议网络(RPN)以产生高质量的区域建议(即可能包含对象),(2)RoIAlign层以保持roi及其特征映射之间的空间对应关系,以及(3)除了与Faster RCNN一样的边界框预测之外,还有一个用于二进制掩码预测的并行分支。值得注意的是,Feature Pyramid Network (FPN) (Lin et al ., 2017a)被用作Mask RCNN的主干来提取多尺度特征。FPN有自底向上和自顶向下的两种途径来提取和合并金字塔层次结构中的特征。自底向上路径从高分辨率(语义弱特征)提取到低分辨率(语义强特征)的特征映射,而自顶向下路径则相反。在每个分辨率下,自顶向下路径生成的特征通过跳过连接被自底向上路径的特征增强。这种设计可能会使FPN看起来像U-Net,但主要区别在于FPN在所有分辨率尺度上独立预测,而不是一个。
Wang等人(2019b)在Mask RCNN框架内提出了一种用于3D医学图像分割的体积关注(volume attention, VA)模块。这个注意力模块可以利用三维CT体沿z方向的上下文关系。更具体地说,不仅从目标图像(以目标CT切片为中间的3个相邻切片)中提取特征金字塔,而且从一系列相邻图像(也是3个CT切片)中提取特征金字塔。然后在每一层将目标金字塔和相邻的特征金字塔连接起来,形成一个中间金字塔,该中间金字塔在z轴上携带远程关系。最后,在中间金字塔和目标金字塔上应用空间注意和通道注意,形成最终的特征金字塔进行掩模预测。使用该VA模块,Mask RCNN可以在分割中实现更低的误报。在另一项研究中,Zhou等人(2019c)将unnet++和Mask RCNN结合起来,得到了Mask RCNN++。如前所述,UNet++使用重新设计的嵌套和密集的跳过连接展示了更好的分割结果,因此作者使用它们来取代掩码RCNN内部FPN的普通跳过连接。使用所提出的模型可以观察到很大的性能提升。
3.2.2 基于无监督学习的分割模型
对于医学图像分割,为了缓解对大量带注释的训练数据的需求,研究者采用生成模型进行图像合成,以增加训练样例的数量Zhang et al . (2018b);Zhao et al . (2019a)。与此同时,利用未标记医学图像的力量似乎是一个更受欢迎的选择。与困难和昂贵的高质量带注释的数据集相比,未标记的医学图像通常是可用的,通常有大量。给定一个具有有限地面真值注释的小型医学图像数据集和一个相关但未标记的大型数据集,研究人员探索了自监督和半监督学习方法,以从未标记的数据集中学习有用的和可转移的特征表示,这将分别在本节和下一节中讨论。
自监督预训练任务:由于通过预训练任务和对比学习进行的自我监督可以从未标记的数据集中学习到丰富的语义表示,因此自监督学习通常用于预训练模型,并在有限的注释示例可用时更准确有效地解决下游任务(例如医学图像分割)Taleb等(2020)。预训练任务既可以根据应用场景设计,也可以从计算机视觉领域使用的传统任务中选择。对于前一种类型,Bai等人(2019)通过预测心脏MR图像分割的解剖位置设计了一种新的预训练任务。通过预训练任务的自学习特征被转移到一个更具挑战性的任务,即准确的心室分割。与从头开始训练的标准U-Net相比,该方法具有更高的分割精度,特别是当只有有限的注释可用时
对于后一种类型,Taleb等人(2020)将执行借口任务从2D扩展到3D场景,并研究了几种借口任务(例如旋转预测、拼图、相对补丁定位)在3D医学图像分割中的有效性。对于脑肿瘤分割,他们采用了U-Net架构,并在一个大型未标记数据集(约22,000个MRI扫描)上执行借口任务来预训练模型;然后在更小的标记数据集(285次MRI扫描)上对学习到的特征表示进行微调。3D借口任务比2D借口任务表现得更好;更重要的是,所提出的方法有时优于监督预训练,表明自学习特征具有良好的泛化能力。
通过添加其他类型的信息,也可以提高自监督预训练的性能。Hu等人(2020)实现了一个上下文编码器(Pathak等人,2016),执行语义绘制作为借口任务,他们将来自超声图像的DICOM元数据作为弱标签,以提高预训练特征的质量,促进两种不同的分割任务。
基于自监督对比学习的方法:对于这种方法,早期的研究,如Jamaludin等人(2017)的工作,采用原始对比损失(Chopra等人,2005b)来学习有用的特征表示。近三年来,随着人们对自我监督对比学习的兴趣激增,对比损失已经从最初的版本发展到更强大的版本(Oord等人,2018),用于从未标记的数据集中学习具有表现力的特征表示。Chaitanya等人(2020)声称,尽管Chen等人(2020a)的对比损失适用于学习图像级(全局)特征表示,但它并不能保证学习对每像素分割很重要的独特的局部表示。他们提出了一种局部对比损失方法来捕获局部特征,从而提供互补信息以提高分割性能。同时,据我们所知,在计算全局对比损失时,这些作者首先利用了体积医学图像(例如CT和MRI)中存在结构相似性的领域知识。在低注释的MR图像分割中,该方法显著优于其他半监督和自监督方法。此外,研究表明,所提出的方法可以进一步受益于Mixup等数据增强技术(Zhang等人,2018a)。
3.2.3 基于半监督学习的分割模型
半监督一致性正则化:常用的是平均教师模型。Yu等人(2019)在平均教师框架的基础上引入了不确定性估计(Kendall and Gal, 2017),以便从MR图像中更好地分割3D左心房。他们认为,在一个未标记的数据集上,教师模型的输出可能是嘈杂和不可靠的;因此,除了生成目标输出外,还对教师模型进行了修改,以估计这些输出的不确定性。具有不确定性意识的教师模型可以为学生模型提供更可靠的指导,而学生模型又可以反过来改进教师模型。平均教师模型也可以通过转换一致策略得到改进(Li et al ., 2020b)。在一项研究中,Wang等人(2020b)提出了一种半监督框架,用于从带有噪声标签的CT扫描中分割COVID-19肺炎病变。他们的框架也是基于均值教师模型;他们没有使用预定义的值更新教师模型,而是使用学生模型分割损失的动态阈值自适应地更新教师模型。同样,学生模型也被教师模型自适应地更新。为了同时处理噪声标签和前景背景不平衡,作者开发了一个广义版本的Dice损失。作者本着与U-Net相同的精神设计了分割网络,但在新的跳过连接(Pang等人,2019)、多尺度特征表示(Chen等人,2018a)等方面做了一些改变。最后,将带有骰子损失的分割网络与平均教师框架相结合。该方法对标记噪声具有较高的鲁棒性,在肺炎病灶分割中取得了较好的效果
半监督伪标记:Fan等人(2020)提出了一种半监督框架(Semi-InfNet),以解决CT图像分割COVID-19肺部感染时缺乏高质量标记数据的问题。为了为未标记的图像生成伪标签,他们首先使用50个标记的CT图像来训练他们的模型,该模型为少量未标记的图像生成伪标签。然后将新的伪标记样例纳入原始标记训练数据集中,重新训练模型,为另一批未标记的图像生成伪标签。重复这个过程,直到1600张未标记的CT图像都被假标记。经过标记和伪标记的例子都被用来训练Semi-InfNet,其性能大大超过了其他前沿的分割模型,如UNet++。除了半监督学习策略外,模型中还有三个关键组成部分负责良好的性能:并行部分解码器(PPD) (Wu等人,2019a),反向注意(RA) (Chen等人,2018b)和边缘注意(Zhang等人,2019)。PPD可以聚合输入图像的高级特征,并生成一个全局地图,表明肺部感染区域的大致位置;EA模块利用底层特征对边界细节进行建模,RA模块进一步将粗略估计细化为精确的分割图。
半监督生成模型:作为最早将生成模型扩展到半监督分割任务的工作之一,Sedai等人(2017)利用两个vae从视网膜眼底图像中分割视杯。第一个VAE通过图像重建,从大量未标记的图像中学习特征嵌入;第二个VAE在较少数量的标记图像上训练,将输入图像映射到分割掩码。换句话说,作者使用第一个VAE对未标记的数据执行辅助任务(图像重建),这可以帮助第二个VAE更好地实现使用标记数据的目标目标(图像分割)。为了利用第一个VAE学习到的特征嵌入,第二个VAE同时重建了第一个VAE的分割掩码和潜在表示。利用来自未标记图像的附加信息提高了分割精度。在另一项研究中,Chen等人(2019c)也采用了类似的思想,在未标记数据上引入辅助任务,以便在有限的标记数据下进行图像分割。具体而言,作者提出了一种半监督分割框架,该框架由用于分割的类unet网络(目标目标)和用于重建的自编码器(辅助任务)组成。与之前的研究分别训练两个vae不同,该框架下的分割网络和重构网络共享同一个编码器。另一个不同之处在于,输入图像的前景和背景部分分别重构/生成,并通过注意机制获得各自的分割标签。这种半监督分割框架在不同的标记/未标记数据分割中优于其同行(例如,完全监督的cnn)。
除了上述方法外,研究人员还探索了结合特定领域的先验知识来定制半监督框架,以获得更好的分割性能。先验知识变化很大,例如解剖先验(He等人,2019)、图谱先验(Zheng等人,2019)、拓扑先验(Clough等人,2020)、语义约束(Ganaye等人,2018)和形状约束(Li等人,2020c)等等。
3.3 检测
一个自然图像可能包含属于不同类别的对象,每个对象类别可能包含几个实例。在计算机视觉领域,目标检测算法用于检测和识别图像中是否存在某些目标类别的任何实例(Sermanet et al ., 2014;Girshick et al, 2014;Russakovsky et al, 2015)。往届作品(Shen et al ., 2017;Litjens等人,2017)回顾了2015年之前框架的成功应用,如OverFeat (Sermanet等人,2014;Ciompi等人,2015年)、RCNN (Girshick等人,2014年)和基于全卷积网络(FCN)的模型(Long等人,2015年;Dou et al ., 2016;Wolterink et al, 2016)。作为比较,我们旨在总结最近的目标检测框架(自2015年以来)的应用,例如Faster RCNN (Ren等人,2015),YOLO (Redmon等人,2016)和RetinaNet (Lin等人,2017b)。在本节中,我们将首先简要回顾几个最近的里程碑检测框架,包括单阶段和两阶段检测器。值得注意的是,由于这些检测框架经常用于监督和半监督环境,我们在这些学习范式下引入它们。然后,我们将介绍这些框架在特定类型病变检测和通用病变检测中的应用。最后,我们将介绍基于 GAN 和 VAE 的无监督病变检测。
3.3.1 监督和半监督病变检测
检测框架概述:RCNN框架(Girshick et al ., 2014)是一个多级管道。尽管RCNN在目标检测方面取得了令人印象深刻的成绩,但它也有一些缺点,即多级管道使得训练速度慢且难以优化;单独提取每个区域建议的特征使得训练在磁盘空间和时间上都很昂贵,并且也减慢了测试速度(Girshick, 2015)。这些缺陷启发了最近的几个里程碑检测器,它们可以分为两组(Liu et al, 2020b):(1)两阶段检测框架(Girshick, 2015;Ren等,2015,2017;Dai等人,2016),其中包括一个单独的模块,用于在边界框识别之前生成区域建议(预测类概率和边界框坐标);(2)单阶段检测框架(Redmon et al ., 2016;Redmon and Farhadi, 2017;Liu et al ., 2016;Lin等人,2017b;法律与邓,2020;Duan等人,2019),在不分离生成区域建议的过程的情况下,以统一的方式预测边界框。在图像中,区域建议是可能包含对象的潜在区域或候选边界框的集合(Liu et al ., 2020b)。
两阶段检测器:与RCNN不同,Fast RCNN框架(Girshick, 2015)是一个端到端检测管道,采用多任务损失来联合分类区域建议和回归边界框。Fast RCNN中的区域建议是在共享的卷积特征映射上生成的,而不是在原始图像上生成,从而加快了计算速度。然后应用兴趣区域池层将所有的区域建议扭曲成相同的大小。这些调整使得快速RCNN的检测性能更好更快,但速度仍然受到计算区域建议处理效率低下的瓶颈。在Faster RCNN框架(Ren et al, 2015,2017)中,区域建议网络(RPN)取代了选择性搜索方法,有效地从锚盒中生成高质量的区域建议。锚框是一组预先确定的候选框,具有不同的大小和宽高比,用于捕获特定类别的对象(Ren et al, 2015)。从那时起,锚框在顶级检测框架中发挥了主导作用。Mask RCNN (He et al, 2017)与Faster RCNN密切相关,但它最初是为像素级对象实例分割而设计的。掩码RCNN也有一个RPN来提出候选对象边界框;这个新框架通过添加一个额外的分支来扩展Faster RCNN,该分支将二进制对象掩码输出到预测类和边界框偏移量的现有分支。RCNN使用特征金字塔网络(Feature Pyramid Network, FPN) (Lin et al ., 2017a)作为主干,提取各种分辨率尺度的特征。除了实例分割之外,Mask RCNN还可以用于目标检测,具有很好的准确性和速度。
一级检测器Redmon等(2016)提出了一种单级框架YOLO;他们没有使用单独的网络来生成区域建议,而是将目标检测视为一个简单的回归问题。使用单个网络直接预测对象类别和边界框坐标。YOLO也不同于基于区域建议的框架(例如,Faster CNN),它从整个图像全局学习特征,而不是从局部区域学习。尽管速度更快、更简单,但YOLO比faster RCNN有更多的定位误差和更低的检测精度。后来,作者提出了YOLOv2和YOLO9000 (Redmon and Farhadi, 2017),通过整合不同的技术来提高性能,包括批处理归一化、使用良好的锚盒、细粒度特征、多尺度训练等。Lin等人(2017b)认为,单阶段检测器性能滞后的主要原因是前景类和背景类之间的不平衡(即,训练过程被来自背景的大量简单示例所主导)。为了解决类不平衡问题,他们提出了一种新的焦点损失,可以削弱简单样例的影响,增强难样例的贡献。所提出的框架(RetinaNet)显示出比当时最先进的两级探测器更高的检测精度。Law和Deng(2020)提出了CornerNet,并指出锚盒在目标检测框架(尤其是单阶段检测器)中的普遍使用会导致诸如正样例和负样例之间的极端不平衡、训练缓慢、引入额外的超参数等问题。作者没有设计一组锚盒来检测边界框,而是将边界框检测定义为检测一对关键点(左上角和右下角)(Newell等人,2017;Tychsen-Smith and Petersson, 2017)。尽管如此,由于无法充分利用裁剪区域内的可识别信息,CornerNet生成了大量不正确的边界框(Duan et al, 2019)。Duan等人(2019)在CornerNet的基础上提出了CenterNet,该方法使用一个关键点三元组(包括一对角点和一个中心关键点)来检测每个对象。与CornerNet不同,CenterNet可以在每个提出的区域中提取更多可识别的视觉模式,从而有效地抑制不准确的边界框(Duan et al, 2019)。
特定类型的医疗对象(如病变)检测:常见的计算机辅助检测(CADe)任务包括检测肺结节(Gu et al ., 2018;Xie et al ., 2019b),乳腺肿块(AkselrodBallin et al ., 2017;Ribli et al ., 2018)、淋巴结(Zhu et al ., 2020b)、硬化症病变(Nair et al ., 2020)等。一般检测框架最初是为自然图像中的一般物体检测而设计的,但不能保证医学图像中病变检测的满意性能,主要有两个原因:(1)与自然物体相比,病变的尺寸可能非常小;(2)病变和非病变通常具有相似的外观(例如质地和强度)(Tao等,2019;Tang et al, 2019)。为了在医疗领域提供良好的检测性能,这些框架需要通过不同的方法进行调整,例如结合领域特定特征,不确定性估计或半监督学习策略,如下所示。
在放射学和组织病理学领域,结合特定领域的特征一直是一种流行的选择。在放射学领域,体积图像(如CT扫描)中固有的三维空间上下文信息已在许多研究中得到利用(Roth等,2016;Dou et al ., 2017;Yan等,2018a;廖等人,2019)。例如,在肺结节检测任务中,Ding等(2017)认为以VGG-16网络(Liu and Deng, 2015)为骨干的原始Faster RCNN (Ren et al ., 2015)无法捕获肺小结节的代表性特征;他们在Faster RCNN的最后引入了一个反卷积层,以恢复在检测小物体时很重要的细粒度特征。在反卷积特征映射上,应用FPN从二维轴向切片中提出结节候选区域。为了降低误报率,作者提出使分类网络看到候选结节的全部上下文。他们没有使用2D CNN,而是选择了3D CNN来利用候选区域的3D上下文,这样就可以捕获更多独特的特征来进行结节识别。该方法在LUNA16基准数据集上的结节检测排名第一(Setio et al ., 2017)。Zhu等人(2018)也考虑了肺部CT图像的3D特性,设计了3D Faster RCNN用于结节检测。为了有效地学习结节特征,3D更快的RCNN具有类似unet的结构(Ronneberger et al ., 2015),并使用紧凑的双路径块构建(Chen et al ., 2017)。值得注意的是,尽管3D CNN在提高检测性能方面有效,但与2D CNN相比,3D CNN也有缺点,包括消耗更多的计算资源,需要更多的努力来获取3D边界框注释(Yan et al ., 2018a;Tao等人,2019)。在最近的一项研究中,Mei等人(2021)建立了一个包含超过40,000个注释肺结节的大型数据集(PN9),用于训练基于cnn的3D模型。作者通过利用多个连续CT切片之间存在的相关性,提高了模型检测大小肺结节的能力。给定一个切片组,采用基于非局部操作的模块(Wang et al ., 2018)来获取特征映射中不同位置和不同通道的远程依赖关系。此外,由于每个浅层ResNet块可以在同一尺度上生成携带有用空间信息的特征图,因此作者通过合并3个不同块产生的多尺度特征来减少假阳性结节候选。
在组织病理学领域,Rijthoven等人(2018)提出了一种改进版本的YOLOv2 (Redmon和Farhadi, 2017),用于全片图像(WSI)中的淋巴细胞检测。基于对淋巴细胞的先验知识(例如,平均大小,无重叠),作者通过只保留几层,简化了原23层的YOLO网络。由于事先知道WSI中没有淋巴细胞的棕色区域包含许多硬负样本,作者还设计了一种采样策略,以强制检测模型在训练过程中关注这些硬负样本。该方法将F1-score提高了3%,速度提高了4.3倍。在他们后来的工作中,SwiderskaChadaj等人(2019)修改了YOLO架构,在更多样化的乳腺癌、前列腺癌和结肠癌WSI数据集中进一步检测淋巴细胞;然而,它的性能不如基于U-Net的检测架构,后者首先对每个像素进行分类,然后使用后处理技术产生检测结果。改进的YOLO结构对不同染色技术的鲁棒性最低。
最近,半监督方法已被用于提高医疗目标检测的性能(Gao等,2020;Qi et al, 2020)。例如,Wang等人(2020c)开发了原始焦点损失的广义版本(Lin等人,2017b),以处理计算半监督损失函数中的软标签。他们从两个方面修改了半监督方法MixMatch (Berthelot et al ., 2019),使其适用于3D医学图像检测。首先将FPN应用于未标记的CT图像(没有病变注释)以生成伪标记的对象实例。然后通过Mixup增强将伪标记的示例与具有真值注释的示例混合。然而,最初的Mixup增强(Zhang等人,2018a)是为分类任务设计的,其中标签是图像类别;作者将这种增强技术应用于以边界框形式进行注释的病灶检测任务。在肺结节检测中,半监督学习方法比监督学习基线表现出显著的性能增益。
此外,不确定性估计是另一种有助于检测小物体的有用技术(Ozdemir等人,2017;Nair et al, 2020)。例如,在多发性硬化症病变检测任务中,不确定性主要来自小病变和病变边界,Nair等(2020)探索使用不确定性估计来提高检测性能。具体来说,计算了四种不确定性度量:训练数据的预测方差(Kendall and Gal, 2017)、蒙特卡罗(MC)样本的方差、预测熵和互信息。由这些措施形成的阈值被用来过滤掉最不确定的候选病变,从而提高检测性能。
通用病变检测:传统的病变检测器专注于特定类型的病变,但对一次性从整个人体中识别和定位不同类型的病变的研究兴趣越来越大(Yan等人,2018a, 2019;Tao等人,2019;Yan等,2020;Cai et al, 2020;Li et al ., 2020d)。DeepLesion是一个庞大而全面的数据集(32 K个病灶),包含肺结节、肝脏肿瘤、腹部肿块、盆腔肿块等多种病变类型(Yan et al ., 2018b, 2018c)。Tang等(2019)提出了基于Mask RCNN的ULDor通用病变检测方法。Mask RCNN需要真实遮罩病变;然而,DeepLesion数据集不包含这样的注释掩码。使用RECIST (Response Evaluation Criteria In Solid Tumors)注释(Eisenhauer et al, 2009),作者通过对每个病变区域的椭圆拟合来估计真实掩模。此外,使用硬负例对模型进行重新训练以减少误报。Yan等人(2019)通过强制使用多任务检测器(MULAN)共同进行病变检测、标记和分割,进一步提高了通用病变检测的性能。以前的研究表明,将不同的任务组合在一起可以相互提供互补的信息,从而提高单个任务的性能(Wu et al ., 2018b;Tang et al, 2019)。MULAN是由Mask RCNN (He et, 2017)改进而来,有三个头分支。检测分支预测每个提出的区域是否为病变,并对边界框进行回归;标签分支为每个病变建议预测185个标签(如身体部位、病变类型、强度、形状等);分割分支为每个提议的区域输出一个二值掩码(病变/非病变)。MULAN显著优于以往的病变检测模型,如ULDor (Tang et al ., 2019)和3DCE (Yan et al ., 2018a)。此外,Yan等人(2020)最近表明,从异质病变数据集和部分标签中学习也可以提高检测性能。
除了上述策略外,注意机制是提高病变检测的另一种有效方法。Tao等人(2019)在DeepLesion数据集上训练了通用病变检测器,以及注意机制(Wang等人,2017;引入了Woo等人,2018),将3D上下文和空间信息整合到基于R-FCN的检测架构中(Dai等人,2016)。上下文关注模块输出一个矢量,表示从不同轴向CT切片中学习到的特征的重要性,因此检测框架可以自适应地聚合来自不同切片的特征(即增强相关的上下文特征);空间注意模块输出一个权重矩阵,这样可以放大特征图上的判别区域,从而可以很好地学习到更丰富、更具代表性的小病变特征。尽管使用的切片少得多,但所提出的方法显示了显著的性能改进。Li等人(2019)提出了一种基于FPN的架构,其注意力模块可以整合临床知识。在临床实践中,放射科医生检查多个CT窗口以准确诊断病变是很常见的。作者首先使用三个FPNs从三个频繁检查的窗口生成特征图;然后使用注意力模块(Woo et al ., 2018)来重新加权来自不同窗口的特征映射。为了进一步提高性能,还结合了病变位置的先验知识。
我们观察到,无论是在特定类型的病变检测还是通用病变检测中,两阶段检测器由于其高性能和鲁棒性仍然相当普遍;但是,单独提出区域建议可能会妨碍制定精简的CADe计划。最近的几项研究表明,单级探测器也可以获得良好的检测性能(Pisov等人,2020;Lung等,2021;Zhu et al ., 2021b)。我们预测,如果适当调整先进的无锚单级检测器(例如CenterNet (Duan et al, 2019))以适应医学图像的独特性,从长远来看,它将吸引更多的关注,甚至成为比两级检测器更好的选择,用于开发新的CADe方案。
3.3.2. 无监督病变检测(非预先指定的病变检测类型)
如上小节所述,无论是特定类型还是通用病变检测,都需要一定数量的监督来训练一级或二级检测器。为了建立监督,需要在训练检测器之前预先指定病变类型。一旦训练完毕,检测器就无法检测到训练数据集中没有包含的病变。相反,无监督的病变检测不需要ground-truth注释,因此不需要预先指定病变类型。无监督检测具有检测任意类型病变的潜力(Baur et al, 2021),但其性能无法与全监督/半监督方法相比。尽管如此,它仍可用于建立可疑区域的粗略检测,并提供成像生物标志物候选物。
为了避免潜在的混淆,我们做以下两点澄清。首先,本小节中介绍的方法源于“无监督异常检测”,因为在医学图像中,将脑肿瘤等病变视为一种异常是很自然的。术语“异常检测”将在上下文中频繁使用。其次,需要注意的是,在文献中,“异常检测”经常与另一个术语“异常分割”一起出现(Baur et al, 2021)。这是因为它们本质上是两个紧密相连的任务——一旦在图像中检测到异常区域,就可以通过对检测图应用二值化阈值来获得分割图。换句话说,适用于一个方向的方法通常适用于另一个方向,因此读者将看到术语“异常分割”。
无监督异常检测的核心假设是,无监督模型可以捕捉到图像中正常部分(如健康组织和解剖结构)的底层分布,但肿瘤等异常部分偏离了规范分布,因此可以检测到这些异常。常用的估计规范分布的模型主要来源于VAE和GAN的概念,这些无监督模型的成功多见于MRI。值得注意的是,Baur等人(2021)回顾了各种基于自编码器的脑MR图像异常分割方法。作者对这些模型进行了彻底的比较,并对成功的应用提出了许多有趣的见解。本文得出的一个重要结论是,在不考虑运行时间的情况下,基于恢复的方法通常比基于重建的方法表现得更好。与这篇全面的综述论文相反,我们将简要介绍基于重建的方法,并将重点放在最近与基于恢复的检测相关的工作上。
在基于重建的范式中,基于AE或AE的模型将图像投影到低维潜在空间中,然后根据其潜在表示重建原始图像。仅使用健康图像进行训练,并优化模型以产生低逐像素重建误差。当不健康图像通过模型时,正常区域的重建误差较低,而异常区域的重建误差较高。Uzunova等人(2019)使用CVAE来学习健康图像斑块的潜在表征。除了重建误差外,他们还进一步假设健康斑块和不健康斑块的潜在表征之间存在较大距离。将这两个距离结合在一起,基于cvae的模型在肿瘤mri上给出了合理的分割结果。值得注意的是,作者利用斑块的相对位置作为条件,将局部环境纳入CVAE。位置相关条件可以提供健康和不健康组织的额外先验信息,以提高性能
在基于恢复的范式中,待恢复的目标要么是(1)最优潜在表示,要么是(2)输入异常图像的健康对应。基于GAN和基于vae的方法都已被应用,但GAN通常用于第一种类型的潜在表示恢复。虽然GAN的生成器可以很容易地将潜在向量映射回图像,但它缺乏进行逆映射的能力,即从图像到潜在空间,这在计算异常评分中很重要。这是许多将GAN应用于异常检测的工作所解决的关键问题。作为一项开创性的工作,Schlegl等人(2017)提出了所谓的AnoGAN来获得逆映射,作者首先使用健康图像预训练GAN(生成器和鉴别器)来学习规范分布,并保持该模型的权重固定。然后给定输入图像(正常或异常),在潜空间(关于潜变量)进行梯度下降以恢复相应的最优潜表示。更具体地说,优化是由两种组合损失,即残差损失和判别损失指导的。残差损失与前面提到的重建误差一样,衡量的是真实输入图像与生成器从潜在变量生成的图像之间逐像素的不相似性。同时,将这两种类型的图像送入鉴别器网络,并使用一个中间层对它们进行特征提取。计算中间特征表示的差值,导致识别损失。最后,在对潜在变量进行优化后,作者使用这两种损失来计算异常分数,表明输入图像是否包含异常区域。AnoGAN提供了良好的性能,但迭代优化是耗时的。在他们的后续工作中,Schlegl等人(2019)通过引入一个额外的编码器,提出了一个更有效的fAnoGAN模型,该模型可以执行从图像空间到潜在空间的快速逆映射。与开发AnoGAN类似,他们首先使用健康图像预训练WGAN,并再次保持模型的权重固定。然后使用固定权值的生成器作为无需进一步训练的声发射的解码器,而使用AnoGAN中引入的两个损失函数的组合来训练该声发射的编码器。经过充分训练后,编码器网络可以有效地将图像映射到潜在空间,只需一次前向传递。稍早于f-AnoGAN, Baur et al(2018)提出了所谓的AnoVAEGAN,将VAE和GAN结合起来进行快速逆映射。在该框架中,GAN的生成器和VAE的解码器是同一个网络,使用VAE的编码器学习逆映射。因此,需要训练编码器、解码器和鉴别器三个组成部分。这里的损失函数不同于AnoGAN和f-AnoGAN,但仍然存在重构误差。此外,与这两种基于补丁的模型相比,AnoVAEGAN直接将整个MR图像作为输入,从而可以捕获和利用可能对异常分割有价值的全局上下文。
对于第二种类型,恢复输入图像的健康副本意味着,如果输入包含异常区域,则期望在恢复版本中删除它们,而保留其余正常区域。因此,可以获得输入图像和恢复图像之间的像素级不相似性映射,并可以检测异常。成功的恢复通常依赖于最大后验估计(MAP)。具体来说,被最大化的后验由健康图像的规范分布和数据一致性项组成(Chen et al, 2020d)。规范分布可以通过VAE或其变体建模,其训练由ELBO指导,ELBO是对VAE原始目标函数的估计(Kingma和Welling, 2014)。至于数据一致性项,它控制着恢复图像与输入图像相似的程度。在从MR图像中检测脑肿瘤的任务中,You等(2019)首先使用GMVAE捕获无病变MR图像的分布,并采用总变异范数进行数据一致性正则化。然后,这两个元素共同引导MAP估计中的优化,从而迭代地恢复异常输入的健康对应。最近,Chen等人(2021c)在他们的后续工作中声称,ELBO可能不是VAE原始损失函数的良好近似值。因此,这种不准确的损失可能导致学习不准确的规范分布,使迭代优化中的梯度计算偏离真实方向。为了解决这个问题,作者提出用局部高斯分布的导数来代替ELBO的梯度。当在MR图像中检测胶质母细胞瘤和胶质瘤时,与其他方法相比,该方法在低假阳性率下具有更高的准确性。此外,与以往大多数依赖2D MR切片的工作不同,作者将3D信息纳入VAE的训练中,以进一步提高性能。
3.4 配准
配准是将两幅或多幅图像对齐到一个具有匹配内容的坐标系中的过程,也是许多医学图像分析任务中的重要步骤。图像配准可以分为刚性和可变形(非刚性)两组。在刚性配准中,所有图像像素均匀地经历一个简单的变换(例如旋转),而可变形配准旨在建立图像之间的非均匀映射。近年来,与该研究主题相关的深度学习应用越来越多,特别是在可变形图像配准方面。与综述文章(Haskins et al, 2020)的组织结构类似,我们调查中基于深度学习的医学图像配准方法分为三组:(1)深度迭代配准;(2)监督配准;(3)无监督配准。感兴趣的读者可以参考其他几篇优秀的综述论文(Fu et al ., 2020;Ma et al ., 2021b),以获得更全面的配准方法。
3.4.1 深度迭代配准
在深度迭代配准中,深度学习模型学习量化目标/运动图像与参考/固定图像之间相似性的度量;然后,将学习到的相似度度量与传统优化器结合使用,迭代更新经典(即非基于学习的)转换框架的配准参数。例如,Simonovsky等人(2016)使用5层CNN学习度量来评估对齐的3D脑MRI T1-T2图像对之间的相似性,然后将学习到的度量纳入连续优化框架中完成可变形配准。这种基于深度学习的度量优于手动定义的相似性度量,例如多模态注册的互信息(Simonovsky等人,2016)。从本质上讲,这项工作与Cheng等人(2018)的先前方法最为相关,该方法使用带有堆叠去噪自编码器的FCN预训练来估计2D CT-MR补丁对的相似性;这两部作品的主要区别在于网络架构(CNN vs. FCN)、应用场景(3D vs. 2D)和训练策略(从零开始vs.预训练)。对于T1-T2加权MR图像和CT-MR图像,Haskins等人(2019)声称学习一个好的相似性度量相对容易,因为这些多模态图像共享大的相似视图或简单的强度映射。他们将深度相似度量扩展到更具挑战性的场景,3D MR - TRUS前列腺图像配准,其中两种成像模式之间存在很大的外观差异。
总之,“深度相似性”可以避免手动定义相似性度量,对于建立像素到像素和体素到体素的对应关系很有用。深度相似性仍然是一个重要的研究方向,它经常与其他几个术语如“度量学习”和“描述符学习”交替提到(Ma et al, 2021b)。请注意,与强化学习相关的方法也可以用于隐式量化图像相似性,但我们不会扩展这个主题,因为强化学习超出了本文的讨论范围。相反,更先进的基于深度相似的方法(例如,对抗性相似)将在无监督注册小节中进行审查。
3.4.2 监督配准
尽管深度迭代配准取得了成功,但经典配准框架中学习相似度度量然后进行迭代优化的过程对于实时配准来说太慢了。相比之下,一些监督配准方法只需一步即可直接预测变形场/变换,而无需迭代优化。这些方法通常需要地面真值扭曲/变形场,这些场可以合成/模拟(Uzunova等人,2017),手动注释或通过经典配准框架获得。对于3D可变形图像配准,Sokooti等(2017)开发了基于多尺度cnn的模型,直接预测图像对之间的位移向量场(dvf)。为了使他们的训练数据集更大、更多样化,他们首先人工生成具有不同空间频率和幅度的dvf,然后对生成的dvf进行数据增强,得到了大约100万个训练样例。训练后的形变图像一次性配准,与传统的b样条配准方法性能接近。
除了来自地面真实变形场的监督外,有时还结合图像相似度量来提供更准确配准的额外指导。这种组合被称为“双重监督”。在最近的一项研究中,Fan等人(2019a)开发了一种双监督双指导的脑MR图像配准训练策略。在大地真值引导下,计算了大地真值场与预测变形场的差值。在图像相似度指导下,利用预测变形场计算模板图像与被变形图像之间的差值。前一种指导使网络收敛更快,后一种指导进一步细化训练,得到更准确的配准结果。
3.4.3 无监督配准
基于无监督学习的注册近年来受到了广泛关注(Zhao et al ., 2019b;Kim等人,2019),主要有两个原因:(1)通过传统的配准方法获得地面真值扭曲场很麻烦;(2)用于模型训练的形变类型有限,导致在未见图像上的表现不理想。作为与无监督注册相关的早期工作之一,Wu等人(2016)认为基于监督学习的注册方法不能很好地泛化新数据;他们采用卷积堆叠自编码器(Lee et al ., 2011)从固定和运动图像中提取特征,以提高配准性能
Balakrishnan等人(2018)提出了一种不需要监督信息(例如,真实注册字段或解剖标志)的无监督配准模型(图7中的VoxelMorph)。该模型由卷积U-Net和空间变压器网络(STN)两部分组成。作者将3D MR脑容量配准作为参数函数,并使用U-Net架构对其进行建模。编码器的输入是运动图像和固定图像的拼接,解码器输出配准字段。利用空间变换网络(Jaderberg et al ., 2015),利用学习到的配准域对运动图像进行翘曲,得到固定图像的重构版本。通过最小化重建图像与固定图像之间的差异,VoxelMorph可以更新参数以生成所需的变形场。这种无监督的配准框架能够以更快的数量级运行,但与经典的配准算法对称归一化(SyN)相比,其性能具有竞争力(Avants等人,2008)。在后来的一篇论文中(Balakrishnan et al, 2019),作者扩展了VoxelMorph以利用辅助分割信息(解剖分割图),扩展模型显示出更高的配准精度。在此之前,一些研究表明,在没有体素级变换的基础真理的情况下,仅使用辅助解剖信息可以实现准确的跨模态配准(Hu et al ., 2018c, 2018d)。注意,包含相应解剖结构的分割信息通常被称为“弱监督配准”。
DLIR是另一个著名的无监督注册框架(de Vos et al ., 2019),它是对先前工作(de Vos et al ., 2017)的扩展。DLIR有四个阶段,逐步执行图像配准。第一阶段设计用于仿射图像配准(AIR),其余三个阶段用于可变形图像配准(DIR)。在AIR阶段,CNN将固定图像和运动图像作为输入对,输出仿射变换参数的预测,从而得到仿射对齐的图像对。在随后的DIR阶段,这些对齐后的图像对作为一个新的CNN的输入,其输出是一个b样条位移向量作为变形场。利用该字段可以得到可变形配准的图像对,并通过其余两个DIR阶段进一步细化配准结果。
上述的无监督配准框架都是利用人工定义的相似度指标和一定的正则化项来设计损失函数。例如,VoxelMorph的损失函数包括一个相似性度量(均方误差,互相关(Avants等人,2008)),用于量化扭曲图像与固定图像之间的体素对应关系,以及一个正则化项,用于控制扭曲图像的空间平滑性(Balakrishnan等人,2019)。尽管经典相似度度量在单模态配准中是有效的,但在大多数多模态配准中,它们的成功率低于深度相似度度量。为此,提出了在无监督机制下学习的高级深度相似度量,以获得更好的多模态配准结果。一个值得注意的例子是Fan等人(2019b)提出的对抗性相似性。具体来说,作者提出了一个无监督的对抗网络,具有基于unet的生成器和基于cnn的鉴别器。生成器接受两个输入图像量(运动图像和固定图像)并输出一个变形场,而鉴别器通过将负图像对(使用预测场扭曲的固定图像和运动图像)与正图像对(固定图像和参考图像)的相似性进行比较,确定它们是否配准良好。利用鉴别器的反馈来改进自身,训练生成器生成尽可能精确的变形以欺骗鉴别器。这种无监督的对抗相似网络在单模态脑MRI图像配准和多模态骨盆图像配准方面取得了令人满意的结果。
4 讨论
4.1 将深度学习和医学图像分析更好地结合起来
4.1.1 从特定任务的角度来看
使用深度学习的医学图像分析的进展遵循一个滞后但与计算机视觉相似的时间表。然而,由于医学图像和自然图像之间的差异,直接使用计算机视觉方法可能不会产生令人满意的结果。为了获得良好的性能,需要解决医学成像任务所特有的挑战。对于分类任务,成功的关键在于提取相对于某些类别的高度判别特征。这对于类间差异较大的域来说相对容易(例如,许多公共胸部x射线数据集的准确率通常超过90%),但对于类间相似性高的域来说可能很难。例如,乳房x线照片分类的性能总体上不是很好(例如,在私人数据集上通常看到70 ~ 80%的准确率),因为在存在重叠的异质纤维腺组织的情况下,很难捕获乳腺肿瘤的鉴别特征(Geras等,2019)。细粒度视觉分类(FGVC)的概念(Yang et al ., 2018)旨在识别视觉相似对象之间的细微差异,可能适合于学习具有高类间相似性的独特特征。但需要注意的是,我们特意收集了基准的FVGC数据集,使所有的图像样本一致表现出高的类间相似性。因此,在这些数据集上开发和评估的方法可能不容易适用于医疗数据集,其中只有一部分而不是所有图像表现出高度的类间相似性。尽管如此,我们相信,如果对FVGC方法进行适当的修改,将对医学图像分类中具有高判别能力的特征表示的学习有价值。其他可能增强特征识别能力的方法包括使用注意模块、局部和全局特征、领域知识等。
分类角度
从边界盒预测的过程可以看出,医学目标检测比分类要复杂。当然,检测面临着分类固有的挑战。同时,也存在着额外的挑战,特别是小尺度物体(如肺小结节)的检测和分类不平衡。一级检测器在检测大型物体时通常表现得与两级检测器相当,但在检测小型物体时则表现得更加困难。已有的研究表明,在单级和两级检测器中使用多尺度特征可以极大地缓解这一问题。一种简单而有效的方法是图像金字塔(Liu et al ., 2020b),即从同一图像的多个尺度中独立提取特征。这种方法可以帮助放大小对象以获得更好的性能,但计算成本高且速度慢。但它适用于对速度要求不高的医学检测任务。另一种有用但更快的方法是特征金字塔,它利用来自不同卷积层的多尺度特征映射。尽管有多种方法可以构建特征金字塔,但经验法则是有必要将高分辨率特征图与强、高级语义融合在一起。这在检测小物体中起着重要作用,如FPN所示(Lin et al, 2017a)。
卷积神经网络由浅到深,语义信息越来越丰富,但特征图越来越小,分辨率越来越低,解决方案是接将浅层和高层的特征图连接起来,将浅层的信息传递到深层,以解决深层特征图容易忽略小目标的问题。
类别不平衡是由于检测器需要评估大量的候选区域,但只有少数包含感兴趣的对象。换句话说,类别平衡严重偏向于负面例子(例如,背景区域),其中大多数都是简单的负面例子。大量容易的底片的存在会压倒训练过程,导致糟糕的检测结果。两阶段检测器可以比单阶段检测器更好地处理这种类别不平衡问题,因为大多数负面提议在区域候选阶段被过滤掉。就一级检测器而言,最近的研究表明,放弃锚盒的主导使用可以在很大程度上缓解类不平衡(Duan et al, 2019)。然而,大多数医学目标检测方法仍然是基于锚点的。在不久的将来,我们期望在医疗物体检测中看到更多的 anchor-free、one-stage detectors 的探索
检测角度
医学图像分割结合了分类和检测的挑战。就像检测一样,类别不平衡是2D和3D医学分割任务中的常见问题。另一个类似的挑战是分割小的病变(如MRI多发性硬化症)和器官(如腹部CT扫描的胰腺)。此外,这两个挑战往往交织在一起。通过调整指标/损失来评估分割性能,例如Dice系数(Milletari等人,2016)、广义Dice (Sudre等人,2017)、焦点损失的集成(Abraham和Khan, 2019)等,这些问题在很大程度上得到了缓解。然而,这些指标是基于区域的(即,分割误差是以像素为单位计算的)。这可能导致有关结构、形状和轮廓的宝贵信息的丢失,这些信息对后期诊断/预后很重要。因此,我们认为有必要开发非基于区域的指标,为基于区域的指标提供补充信息,以获得更好的分割性能。目前这方面的研究很少(Kervadec et al, 2019)。我们希望在未来看到更多。
此外,结合局部和全局背景、注意机制、多尺度特征和解剖线索等策略通常有助于提高对大物体和小物体的分割精度。在这里,我们要强调 Transformers 的巨大潜力,因为它们具有强大的建模远程依赖关系的能力。尽管远程依赖关系有助于实现准确的分割,但大多数基于cnn的方法并没有明确地关注这方面。依赖关系大致有两种类型,即片内依赖关系(CT或MRI切片内的像素关系)和片间依赖关系(CT或MRI切片之间的像素关系)(Li et al, 2020e)。最近的研究表明,基于 transformer 的方法在这两种情况下都很强大(Chen et al ., 2021b;Valanarasu et al, 2021)。视觉 Transformers 在医学图像分割尤其是3D图像分割中的应用还处于起步阶段,更多的试验工作可能很快就会出现。
分割角度
医学图像配准与以前的任务有很大的不同,因为它的目的是找到两个图像之间的像素或体素对应关系。一个独特的挑战是难以获得可靠的真实配准,这些配准要么是合成生成的,要么是由传统的配准算法产生的。无监督方法在解决这一问题方面显示出很大的希望。然而,许多无监督配准框架(例如de Vos等人,2019)由多个阶段组成,以从粗到精的方式配准图像。尽管性能良好,但多阶段框架会增加计算复杂度,使训练变得困难。最好是开发具有尽可能少的阶段并且可以端到端进行训练的配准框架。
图像配准角度
4.1.2 论不同学习范式的视角
尽管在放射图像分析的背景下,深度学习在不同的任务中取得了巨大的成功,但进一步的性能改进主要受到对大量注释数据集的需求的阻碍。监督迁移学习可以极大地缓解这个问题,通过使用相关/不相关数据集(例如ImageNet)上预训练的模型的权重初始化模型的权重(针对目标任务)。除了广泛使用的迁移学习之外,还有两个可能的方向:(1)利用GAN模型扩大标记数据集;(2)利用自监督和半监督学习模型挖掘大量未标记医学图像的信息
GAN在医学图像合成和半监督学习方面显示出巨大的前景;但一个挑战是如何在GAN的生成器和目标任务(例如,分类器,检测器,分割器)之间建立强连接。与传统的数据增强(例如,旋转、重新缩放和翻转)相比,缺乏这种连接可能会导致细微的性能提升(Wu等人,2018a)。生成器和分类器之间的连接可以通过使用半监督GAN来加强,其中判别器被修改为分类器(Salimans等,2016)。还可以采用几种训练策略:识别一个可以显著促进良好半监督分类的“坏”生成器(Dai等人,2017);共同优化生成器、鉴别器和分类器的三重组件(Li et al ., 2017)。探索新的方法来有效地建立生成器和特定的医学图像任务之间的连接,以获得更好的性能是有意义的。此外,GAN通常需要至少数千个训练样例才能收敛,这限制了它在小型医疗数据集上的适用性。这一挑战可以通过使用对抗性学习的经典数据增强来部分解决(FridAdar等人,2018a, 2018b)。此外,如果存在与目标数据集具有结构、纹理和语义相似性的相对大量的医学图像,则预训练生成器和/或鉴别器可能有助于更快的收敛和更好的性能(Rubin et al, 2019)。同时,最近一些新的增强机制,如可微增强(Zhao et al ., 2020)和自适应鉴别器增强(Karras et al ., 2020)使GAN能够在数据有限的条件下有效地生成高保真图像,但尚未应用于任何医学图像分析任务。我们期望这些新方法在未来医学图像分析领域的研究中也能显示出良好的性能。
自我监督可以通过借口任务或对比学习来构建,但对比学习似乎是一个更有前途的研究方向。这是因为,一方面,直接使用计算机视觉中的借口任务(例如拼图游戏)通常不足以确保学习放射图像的鲁棒特征表示。另一方面,设计新的借口任务可能很困难,这需要精细的操作。而不是设计各种借口任务,自我监督对比学习训练网络捕获有意义的特征表示,迫使它们对不同的增强视图保持不变,这可能在不同的下游任务上优于监督迁移学习,如医学图像分类和分割。尽管自监督对比学习的表现令人鼓舞,但其在放射图像分析中的应用仍处于探索阶段,如何合理利用这种新的学习范式是一个难题。为此,我们从以下三个方面提出建议:(1)充分利用对比学习和监督学习的优势。从现有的研究中,我们发现大多数医学图像分析采用两个单独的步骤:对未标记数据的对比预训练和对标记数据的监督微调。在预训练阶段,大多数研究依赖于相对较大的、未标记的数据集,以确保学习高质量的、可转移的特征,这些特征在使用有限的标记数据进行微调后可以产生更好的性能。然而,在缺乏大量未标记数据的任务中,对大量未标记数据的依赖可能会出现问题。为了扩大应用范围,需要用较少的未标记数据学习高质量的特征表示。一种可能的方法是将前面提到的两个单独的步骤统一为一个步骤,以便可以在对比学习中利用标签信息。这有点让人想起半监督学习,它同时利用未标记和标记数据来获得更好的性能。更具体地说,类标签可以通过将来自同一类的图像在较低维表示空间中更紧密地对齐来指导以更紧凑的方式构建正对和负对(Khosla et al, 2020)。以这种方式学习的特征需要更少的未标记数据,并且比仅通过自监督学习(即没有任何类标签)学习的特征更少冗余。(2)考虑到对比学习的某些特性,以获得更好的表现。例如,一项研究证明,对比学习从大量相似点中获益比从成对中获益更多(Saunshi et al, 2019)。这种启发式可能非常适合于从3D CT和MRI体积中学习具有连续解剖相似性的可转移特征。(3)针对对数据增强敏感的下游任务定制数据增强策略。在大多数现有的对比学习框架中,不同数据增强策略的组合对于学习代表性特征至关重要。例如,SimCLR对未标记的图像应用三种类型的变换,即随机裁剪、颜色失真和高斯模糊(Chen et al, 2020a)。然而,一些常用的增强技术可能不适用于医学图像。在放射学中,大多数图像以灰度呈现,颜色失真策略可能不合适。此外,在未标记医学图像的细粒度细节携带重要信息的情况下,在预训练阶段使用高斯模糊可能会破坏细节信息并降低特征表示的质量。因此,选择合适的数据增强策略以确保满意的下游性能是非常重要的。此外,自监督对比预训练目前受到大型模型(如ResNet-50 (4 ×), ResNet-152 (2 ×))的高计算复杂性的阻碍,这些模型需要大量的多核tpu (Chen et al, 2020a)。因此,开发新的模型或训练策略来提高计算效率应该是一个重要的方向。例如,Reed等人(2022)提出了一种分层预训练策略,使自监督预训练过程的收敛速度提高了80倍,并提高了跨不同任务的准确性
与自监督对比学习一样,最近的半监督方法,如FixMatch (Sohn et al ., 2020)严重依赖于高级数据增强策略来实现良好的性能。为了促进半监督学习在医学图像分析中的应用,有必要以数据集驱动和/或任务驱动的方式制定适当的增强策略。“数据集驱动”意味着为感兴趣的特定数据集找到最佳的增强策略。在过去,由于参数搜索空间非常非常大(例如Cubuk et al(2020)显示的1034种可能的增强策略),这并不容易实现。最近,人们提出了自动数据增强策略,如RandAugment (Cubuk等人,2020),以显着减少搜索空间。然而,在医学图像分析中,自动增强的概念在很大程度上仍未被探索。“任务驱动”意味着为具有多个数据集的特定任务(例如,MRI前列腺分割)找到合适的增强策略。这可以被视为数据集驱动增强的扩展,因此更具挑战性,但它可以帮助在一个数据集上开发的算法更好地推广到相同任务的其他数据集。
另一个问题是由于违反了半监督学习的基本假设——标记和未标记的数据来自相同的分布——而导致的潜在性能下降。事实上,在半监督方法应用于医学图像分析时,分布不匹配是一个常见的问题。考虑以下示例:在从CT切片中分割covid - 19肺部感染的任务中,假设您有一组标记的CT卷,其中包含相对平衡数量的感染切片和未感染切片,而可用的未标记CT卷可能不包含或只有少量感染切片。或者未标记的CT图像不仅包含COVID-19感染,还包含标记图像中没有的其他一些疾病类别(例如结核病)。如果未标记数据的分布与标记数据的分布不匹配会发生什么?现有研究表明,这将导致半监督方法的性能急剧下降,有时甚至比简单的监督基线更差(Oliver等人,2018;郭等人,2020)。因此,有必要调整半监督算法以容忍标记和未标记医疗数据之间的分布不匹配。作为一个相关领域,“领域适应”可能为实现这一目标提供见解。
4.1.3 寻找更好的架构和流程
深度学习在医学图像分析中的持续成功不仅源于不同的学习范式(无监督、半监督),而且可能在更大程度上源于随着时间的推移而提出的架构/模型。回顾过去,我们发现非微不足道的改进与“架构”的进展密切相关,例如AlexNet (Krizhevsky等人,2012),残差连接(He等人,2016),跳过连接(Ronneberger等人,2015),自我注意(Dosovitskiy等人,2020)等。正如Yuille和Liu(2021)所指出的那样,“鉴于这一进展历史,当然有可能更好的神经架构本身可以克服许多当前的限制”。我们讨论了可能有助于找到更好的体系结构的两个方面。首先,生物学和认知启发机制将继续在架构设计中发挥重要作用。深度学习神经网络最初是受到大脑环境架构的启发。近年来,受灵长类动物视觉注意机制的启发,注意力概念被成功地应用于自然语言处理和计算机视觉中,使模型专注于输入数据的重要部分,从而获得卓越的性能。一个突出的例子是基于自我关注的Transformer家族(Dosovitskiy等人,2020)。与基于cnn的主流模型相比,基于Transformer的架构在捕获输入和输出序列之间的全局/远程依赖关系方面做得更好。此外,cnn固有的归纳偏差(例如,翻译等方差和局部性)在Transformer中要少得多(Dosovitskiy等人,2020)。除了注意力机制之外,许多其他生物或认知机制,如人类语言的动态层次结构,无梯度下降的新对象和概念的一次性学习等(Marblestone et al, 2016),可能为设计更强大的架构提供灵感。其次,自动化架构工程可能有助于开发更好的架构。目前使用的架构大多来自人类专家,设计过程是迭代的,容易出错。部分由于这个原因,用于医学图像分析的模型主要改编自计算机视觉中开发的模型。为了避免手工设计的需要,研究人员提出了自动化架构工程,其中一个相关领域是神经架构搜索(NAS) (Zoph和Le, 2017)。然而,大多数现有的NAS研究都局限于图像分类(Elsken et al ., 2019),真正能够带来根本性变化的革命性模型并没有从这一过程中产生(Yuille and Liu, 2021)。尽管如此,NAS仍然是一个值得探索的方向。
在更广泛的层面上,具有自动配置功能的流程是可取的。尽管体系结构工程仍然面临许多困难,但开发能够自动配置其子组件(例如,在现有体系结构中选择和适应适当的体系结构)以获得更好性能的自动流程将有利于放射图像分析。目前,基于深度学习的流程通常涉及几个相互依存的子组件,如图像预处理和后处理,适应和训练网络架构,选择适当的损失,数据增强方法等。但设计选择往往太多,实验者无法手动找出最佳的管道。此外,为特定任务的一个数据集(例如,来自一家医院的CT图像)配置的高性能管道可能在同一任务的另一个数据集(例如,来自不同医院的CT图像)上表现不佳。因此,需要能够自动配置其子组件的管道来加快经验设计。属于这一范围的例子包括NiftyNet (Gibson等人,2018b),一种用于不同医疗应用的模块化流程,以及专门用于医学图像分割的nnU-Net (Isensee等人,2021)。我们期待更多的研究将从这条轨道上出来。
4.1.4 整合领域知识
领域知识是医学图像分析中一个重要但有时被忽视的方面,它可以为开发高性能的深度学习算法提供见解。如前所述,医学视觉中使用的大多数模型都改编自为自然图像开发的模型;然而,由于独特的挑战(例如,高类间相似性,标记数据的有限大小,标签噪声),医学图像通常更难以处理。如果使用得当,领域知识有助于减少时间和计算成本,从而缓解这些问题。对于具有较强深度学习背景的研究人员来说,利用弱领域知识相对容易,例如MRI和CT图像中的解剖信息(Zhou等人,2021,2019a)、来自同一患者的多实例数据(Azizi等人,2021)、患者元数据(Vu等人,2021)、放射学特征和图像附带的文本报告(Zhang等人,2020a)。另一方面,我们观察到有效地整合放射科医生熟悉的强大领域知识可能更加困难。一个例子是通过乳房x光检查来识别乳腺癌。每位患者可获得四张乳房x光片,包括两张左(L)和两张左®乳房的颅尾侧(CC)和中外侧斜(MLO)视图。在临床实践中,双侧差异(如LCC vs. RCC)和单侧对应(如LCC和LMLO)是放射科医生检测可疑区域和确定恶性肿瘤的重要线索。目前,能够可靠、准确地利用这些专家知识的方法很少。因此,需要更多的研究工作来最大限度地利用强领域知识。
4.2 迈向深度学习在临床环境中的大规模应用
尽管深度学习在学术界和工业研究机构中被广泛用于分析医学图像,但在临床实践中并没有像我们预期的那样产生重大影响。2019冠状病毒病是深度学习时代首次出现的全球大流行,在抗击疫情的早期阶段,这一点得到了明显反映。由于其广泛的医疗,社会和经济后果,这次大流行在很大程度上可以被视为检验深度学习算法在临床翻译中的现状的重大考验。疫情爆发后不久,世界各地的研究人员应用深度学习技术,主要分析疑似感染患者的胸部x光片和CT图像,旨在准确有效地诊断/预后疾病。为此,开发了许多基于深度学习和机器学习的方法。然而,在系统地回顾了截至2020年7月1日发表的169项研究中的200多个预测模型后,Wynants等人(2020)得出结论,所有这些模型都具有较高或不明确的偏倚风险,因此它们都不适合临床使用——每个模型都报告了中等或优异的表现;然而,由于模型过拟合、评估不当、数据源使用不当等原因,乐观结果存在高度偏倚。另一篇综述论文(Roberts et al, 2021)也得出了类似的结论——在回顾了从415项研究中选择的62项研究后,作者得出结论,由于方法学缺陷和/或潜在的偏见,所确定的深度学习和机器学习模型都不能用于COVID-19的临床诊断/预后。
除了COVID-19的例子之外,深度学习方法的高风险偏差确实是不同医学图像分析任务和应用中反复出现的问题(Nagendran等人,2020),这严重限制了深度学习在临床放射学中的潜力。虽然量化潜在的偏见是困难的,但如果处理得当,它可以减少。下面我们总结了可能导致结果偏倚的三个主要方面,并提出了我们的建议。
4.2.1 图像数据集
数据是深度学习的基础。在医学视觉领域,规模越来越大的医学图像数据集(例如,通常至少数百张图像)已经或正在开发中,以促进新算法的训练和测试。一个值得注意的例子是一年一度的MICCAI挑战,其中发布了不同疾病(例如癌症)的基准数据集,极大地促进了医学视觉的进步。然而,我们需要对单独使用单个公共数据集造成的潜在偏差保持谨慎——随着整个社区努力实现最先进的性能,该数据集可能存在整个社区的过拟合(Roberts et al, 2021)。这个问题已经被许多研究人员认识到,所以经常看到使用几个公共数据集和/或私有数据集来更全面地测试新算法的性能。通过这种方式,减少了社区范围的偏倚,但没有达到大规模临床应用的程度
通过纳入额外的数据来训练和测试模型,可以进一步降低社区范围的偏差。引入新数据的一种直接方式当然是数据管理,即通过与专家的集体工作,不断创建大型、多样化的数据集。与此不同,我们推荐一种不太直接但有效的方法——在道德和法律法规允许的情况下整合分散的私人数据集。医学图像分析社区可能会有一个总体印象,即似乎总是缺乏大量的、有代表性的、有标签的数据。不过,这只是部分正确。由于时间和成本的限制,许多已建立的公共数据集的大小和种类有限。另一方面,不同大小和难度级别的丰富医学图像源(标记和未标记)已经存在,但不方便“以孤岛的形式”存在(Yang et al ., 2019)。由于隐私保护和政治复杂性等因素,大多数现有数据源都是保密的,分散在不同国家的不同机构中。因此,在不涉及患者隐私的情况下,利用私人数据集甚至个人数据的统一潜力是可取的。实现这一目标的一个有希望的方法是联邦学习(Li et al, 2020f),它允许模型安全地访问敏感数据。联邦学习可以在多机构数据上协同训练深度学习算法,而无需在参与机构之间交换数据(Rieke et al, 2020)。虽然这项技术伴随着新的挑战,但它有助于学习更少偏见、更泛化、更健壮、性能更好的算法,从而更好地满足临床应用的需求。
4.2.2 性能评估
大多数医学图像分析研究论文通过常用的指标来报告模型的性能,例如分类任务的准确率和AUC,分割任务的Dice系数。虽然这些指标可以很容易地量化所提出的方法的技术性能,但它们往往不能反映临床适用性。最终,临床医生关心的是算法的使用是否会给患者护理带来有益的变化,而不是论文中报道的性能提升(Kelly et al, 2019)。因此,除了应用必要的指标外,我们认为研究团队与临床医生合作进行算法评估非常重要。
我们简单地提到建立协作评价的两个可能的方向。首先,让临床医生参与开放式临床问题的观点分享,论文写作,甚至会议和期刊的同行评审过程。例如,医疗保健机器学习(MLHC)会议为来自不同社区的成员提供了一个研究轨道和临床轨道,以交流见解。其次,衡量临床医生的表现和/或效率是否可以在深度学习算法的帮助下得到提高。一些研究探索了利用模型结果作为“第二意见”来促进临床医生的最终解释。例如,在从乳房x光片预测乳腺癌的任务中,McKinney等人(2020)评估了深度学习模型的补充作用。他们发现,该模型可以正确识别放射科医生遗漏的许多癌症病例。此外,在“重复阅读过程”(英国的标准做法)中,该模型显著减少了第二阅读者的工作量,同时保持了与共识意见相当的表现。
4.2.3 再现性
计算机视觉的快速发展与崇尚可重复性的研究文化密切相关。在医学图像分析中,越来越多的研究人员选择公开他们的代码,这大大有助于避免重复工作。更重要的是,良好的可重复性可以帮助深度学习算法获得更广泛人群(如研究人员、临床医生)的信任和信心,这有利于大规模的临床应用。为了使结果更具可重复性,我们建议在论文中特别注意描述数据选择。看到不同的研究从相同的公共数据集中选择不同的样本子集并不罕见。这可能会增加再现论文中所述结果的难度。Baltatzis等人(2021)在肺结节分类的案例研究中表明,数据的具体选择有利于证明所提出模型的优越性。如果数据样本发生变化,带有附加功能的高级模型可能表现不如简单基线。因此,有必要明确说明数据选择过程,使结果更具可重复性和说服力。
总之,深度学习是一项快速发展的技术,在疾病分类、分割、检测、图像配准等广泛的医学图像分析领域具有广阔的应用前景。尽管取得了重大的研究进展,但我们仍然面临许多技术挑战或陷阱(Roberts et al, 2021),以开发基于深度学习的CAD方案,从而实现高度的科学严谨性。因此,在基于深度学习的CAD方案被临床医生普遍接受之前,需要更多的研究努力来克服这些缺陷。

![java八股文面试[java基础]——CGLIB动态代理与JDK动态代理](https://img-blog.csdnimg.cn/ee9bd2c2eee24507996f63a51ee1bcea.png)